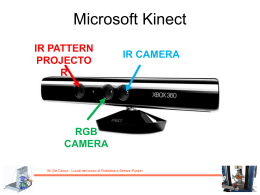
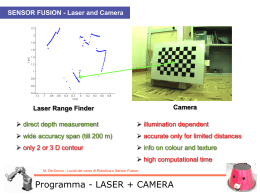
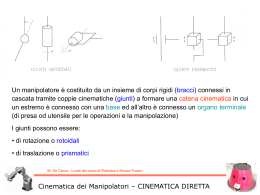
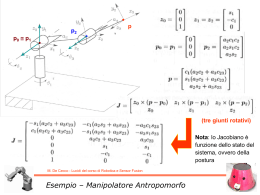
Abbiamo visto un esempio di applicazione del teorema, ma a noi interessa l’applicazione del Teorema di Bayes alla combinazione delle informazioni, ovvero al SENSOR FUSION! M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes Si consideri uno stato x a valori continui, ad esempio la distanza da un target, e un’osservazione z di questo stato La funzione densità di probabilità per la distribuzione delle osservazioni del valor vero dello stato, si supponga Gaussiana (anche detta Distribuzione Normale) in cui le osservazioni sono distribuite con media e varianza Si supponga di aver effettuato una misura zp si può ricavare la funzione di verosimiglianza (dalle informazioni circa il sensore): 2 1 ( z p x) P( z p x ) exp( ) 2 2 2 z z 1 Si voglia adesso combinarla con l’informazione precedente dello stato: 1 ( x xp ) P( x ) exp( ) 2 2 x 2 x 1 2 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano scalare Il teorema di Bayes può essere applicato direttamente per combinare questa informazione precedente con l’informazione del sensore P( x z ) P( z x ) P ( x ) P( z ) K P( z x ) P( x ) E quindi: 1 (x zp ) 1 1 (x xp ) P( x z p ) K P( z p x ) P( x ) K exp( ) exp( ) 2 2 2 z 2 x 2 z 2 x 2 1 1 ( x x )2 exp( ) 2 2 2 2 1 Dove: x2 z2 x 2 z 2 xp 2 p 2 x z x z 1 1 2 2 2 2 x z x z 2 2 z 2 x 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano scalare Una volta nota la proprietà simmetrica delle distribuzioni Gaussiane ossia che il prodotto di due distribuzioni Gaussiane è ancora una distribuzione Gaussiana con media e varianza espresse dalle precedenti equazioni, non è necessario effettuare ogni volta i calcoli sulle distribuzioni ma è sufficiente utilizzare direttamente le espressioni già note della media e della varianza risultanti. Questo risultato consente il calcolo in tempo reale in un’implementazione di data fusion basata su questi modelli probabilistici. Densità precedente, funzione di verosimiglianza e distribuzione posteriore E’ evidente che la distribuzione posteriore è ancora di tipo Gaussiano, come ci si aspetta, è situata in posizione interposta tra le altre due distribuzioni (rispetto alle rispettive medie) ed è una campana più stretta avendo una varianza minore delle due varianza originarie M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano scalare Si consideri il caso in cui lo stato x sia una variabile vettoriale continua e sia tale anche il vettore di osservazione z. La varianza diviene in questo caso una matrice (detta di covarianza): 1 Cx N x N i x xi x T i1 Nell’ipotesi che lo stato segua una distribuzione Normale (Gaussiana) di probabilità, la distribuzione precedente P(x) potrà essere rappresentata con una gaussiana multi-dimensionale del tipo: P( x ) 1 2 d det(Cx ) 1( x xp )T Cx 1( x xp ) e 2 dove d è la dimensione del vettore e xp il valor medio M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale Se perciò si ipotizza di effettuare un’osservazione z con un sensore la cui funzione di verosimiglianza relativa abbia matrice di covarianza Cz (matrice che rappresenta la ripetibilità del sensore): ( z p x )T Cz 1( z p x ) 1 P( z x ) e 2 2 det Cz 1 E’ infine possibile calcolare la distribuzione posteriore P(x|z), nello stesso modo dell’esempio precedente ma tenendo conto che le distribuzioni sono a valori vettoriali. Pertanto la distribuzione posteriore sarà ancora gaussiana, con matrice di covarianza pari al parallelo delle matrici di covarianza di partenza, ossia: C (C x 1 Cz 1 ) 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale L’espressione di C si può scrivere anche in modo più efficiente calcolando una sola inversione matriciale: Cx 1 Cz 1 Cx 1CzCz 1 Cz 1 (Cx 1Cz I )Cz 1 (Cx 1Cz Cx 1Cx )Cz 1 Cx 1 (Cz Cx )Cz 1 da cui C 1 x Cz 1 1 Cx (Cx Cz )Cz 1 1 1 Cz (Cx Cz ) 1Cx … perfettamente analogo al caso scalare in cui era: e quindi -1 C = Cz (Cx + Cz ) Cx z2 x2 2 2 2 1 2 2 z x z x x z2 2 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale Mentre la media della distribuzione posteriore risulterà essere: x = Cx (Cx + Cz )-1 zp + Cz (Cx + Cz )-1 x p … anche in questo caso perfettamente analogo al caso scalare in cui era: x2 z2 2 2 2 1 2 2 2 1 x 2 z x z p x x z p z x z xp 2 p 2 2 x z x z M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale Sensor Fusion tra distribuz. Normali bidimensionali 7 Graficamente una distribuzione Normale bidimensionale è rappresentata da una campana di Gauss le cui sezioni trasversali sono delle ellissi che rappresentano il luogo dei punti caratterizzati da uguale probabilità. 6.5 2 o t n e m e l e xp zp xf ellisse Cx ellisse Cz ellisse Cf 6 5.5 5 Nella matrice di covarianza sono contenute le informazioni sulle 4.5 dimensioni degli assi principali delle ellissi (autovalori della matrice) e sulla loro orientazione 4 1 1.5 2 2.5 3 3.5 elemento 1 (autovettori). Un esempio di quello che graficamente corrisponde alle Densità precedente, funzione di verosimiglianza e distribuzione posteriore equazioni appena ottenute è riportato in figura la distribuzione posteriore è ancora gaussiana, è situata in posizione interposta tra le altre due distribuzioni ed è un ellisse più stretto avendo una matrice di covarianza minore M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale Filtro Bayesiano ricorsivo tra distribuzioni Normali bidimensionali 7 xp zp xf ellisse Cx ellisse Cz ellisse Cf Ellissi di equi-probabilità nel caso in cui l’osservazione ottenuta e la relativa ellisse di incertezza restino sempre le stesse per 20 osservazioni/misure. L’ellisse della distribuzione posteriore converge con il proprio centro verso il valore osservato e va riducendosi sempre di più ad ogni iterazione 6.5 6 2 o t n e m e l e 5.5 5 4.5 4 1 1.5 2 2.5 3 elemento 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Caso Gaussiano vettoriale 3.5 Il teorema di Bayes si può applicare direttamente alla fusione delle informazioni provenienti da differenti sensori n Ciò che si vuole fare è ottenere la distribuzione posteriore P ( x Z ) dove l’insieme delle osservazioni è definito: Z n z1 Z1 ,..., zn Zn La distribuzione posteriore definisce la densità di probabilità dello stato x data l’informazione ottenuta dalle n osservazioni P( Z n x ) P( x ) P( x Z ) P( Z n ) n P( z1 , z2 ,..., zn x ) P( x ) P( z1 , z2 ,..., zn ) M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – combinazione di misure In pratica occorre conoscere completamente la distribuzione congiunta e P( z1, z2 ,..., zn x) , cioè la distribuzione congiunta di tutte le condizionata possibili combinazioni di osservazioni condizionata allo stato. Generalmente è possibile assumere che una volta definito lo stato x, l’informazione ottenuta dalla i-esima sorgente di informazione sia indipendente dall’informazione delle altre sorgenti, ovvero che i diversi strumenti di misura non interferiscano tra di loro e che quindi valga il principio di indipendenza condizionata: n P( z1 ,..., zn x ) P( z1 x )...P( zn x ) P( zi x ) i 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – combinazione di misure Dunque si ottiene: 1 n P( x Z ) P( Z ) P( x ) P( zi x ) n n i 1 Quindi la distribuzione posteriore su x, ovvero la probabilità aggiornata dello stato, è proporzionale al prodotto della distribuzione di probabilità precedente e delle distribuzioni di probabilità di ciascuna osservazione. La distribuzione marginale di Zn agisce come costante di normalizzazione. Tale relazione fornisce un metodo semplice per la fusione di informazioni da più sensori ed è chiamata gruppo indipendente di probabilità M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – combinazione di misure L’efficacia di questo metodo è basata sull’ipotesi che le osservazioni siano indipendenti tra loro quando condizionate al valore vero dello stato. Tale assunzione è ragionevole se lo stato a cui le osservazioni si riferiscono è la sola cosa che esse hanno in comune, perciò una volta che lo stato sia stato specificato è ragionevole assumere che le informazioni siano condizionalmente indipendenti. Ciò non sarebbe sicuramente corretto senza la condizionalità, ovvero sarebbe errato dire che le informazioni sono incondizionalmente indipendenti e quindi: n P ( z1 , z1 ,... zn ) P( zi ) i 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – combinazione di misure L’ipotesi di indipendenza condizionale non è detto che sia sempre ragionevole, ad esempio nel caso in cui un’osservazione può modificare sensibilmente lo stato tale ipotesi non è valida. Un esempio è rappresentato dalla misura con effetto di carico. Analizziamo prima un esempio in cui l’effetto di carico è assente: x Si voglia misurare la posizione lineare di un asse mediante due strumenti laser (quindi senza contatto) I due strumenti forniranno due misure condizionalmente indipendenti in quanto la loro misura dipenderà solo dallo stato del sistema e dalle caratteristiche di accuratezza di ogni singolo strumento preso singolarmente Laser 1 Laser 2 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Indipendenza condizionata - Esempio Supponiamo le misure abbiano una densità di probabilità normale ed effetto sistematico nullo: 1 ( z1 x )2 exp P( z1 x ) 2 2 2 z1 z1 1 1 ( z2 x ) 2 exp P ( z2 x ) 2 2 z2 2 z2 1 Dunque verrà fuori che: 1 ( z x )2 ( z x )2 P( z1 , z2 x ) exp 1 2 2 2 2 z1 z2 z2 2 z1 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Indipendenza condizionata - Esempio Rappresentiamo la probabilità congiunta Nel caso in cui si abbia z z 1 Come era lecito aspettarsi il valore massimo di probabilità si ottiene per entrambe le misure pari a zero 1 P( z1 , z2 x 0) 2 0.2 0.15 0.1 0.05 0 5 0 5 0 -5 -5 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Indipendenza condizionata - Esempio Analizziamo ora un esempio in cui l’effetto di carico è presente: Laser 1 Si voglia misurare la posizione lineare di un asse x mediante uno strumento laser ed un tastatore a riga Riga ottica a ottica che pone a contatto il tastatore 2 (encoder tastatore mediante una molla lineare con molla caricando la mensola per asicurare il connessa con la slitta di cui contatto) occorre controllare il moto I due strumenti forniranno due misure condizionalmente dipendenti in quanto la loro misura dipenderà dal fatto che entrambi sono connessi in misurazione In particolare sarà: P( z1 z2 , x) P( z1 x) (la misura z1 è riferita al laser, la z2 al tastatore) M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio Supponiamo le misure abbiano, oltre all’effetto di carico xc, una densità di probabilità normale: 1 ( z1 x ) 2 exp P( z1 x ) 2 2 2 z1 z1 1 1 ( z2 x xc ) 2 exp P ( z2 x ) 2 z2 2 z2 2 1 Proviamo a valutare cosa succede se (erroneamente!) ipotizziamo indipendenza condizionale: 1 ( z x )2 ( z2 x xc )2 P( z1 , z2 x ) exp 1 2 2 2 2 z1 z2 z2 z1 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio P( z1 , z2 x 0) Rappresentiamo la probabilità congiunta (errata) Nel caso in cui si abbia z z 1 1 2 xc 0.5 5 4 Inquadrando dall’alto la densità di probabilità si nota come essa abbia adesso il valore massimo in corrispondenza della coppia di valori [0, 0.5] Tale risultato è palesemente errato in quanto vorrebbe dire che l’evento congiunto [0, 0.5] ha la massima probabilità di verificarsi 3 2 Dovrebbe essere in [0.5, 0.5] 1 z2 0 -1 -2 Max in [0, 0.5] -3 -4 -5 5 4 3 2 1 0 -1 -2 -3 -4 -5 z1 Sappiamo invece che il massimo si Sappiamo infatti che, se il tastatore è a contatto e la slitta si trova deve avere per: P(0.5,0.5 x 0) in x=0, il tastatore indurrà effetto di carico pari a 0.5, e di conseguenza il laser misurerà il valore 0.5 con la massima verosimiglianza M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Indipendenza condizionata - Esempio Persistiamo nell’errore e valutiamo cosa succede se procediamo con la combinazione delle seguenti informazioni: z1 0.55 z2 0.45 n P( x z1 , z2 ) P( z1 , z2 ) P( x ) P( zi x ) 1 i 1 P( z1 , z2 ) P( x ) P( z1 x ) P( z2 x ) 1 Supponiamo di sapere che la corsa dell’azionamento è limitata entro [-1 1] ed a ciascun valore assegniamo stesso livello di probabilità, ovvero una funzione rettangolare di densità di probabilità per P(x) M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio 0.8 0.6 P( x ) 0.4 0.2 0 -5 -4 -3 -2 -1 0 1 2 3 4 5 -4 -3 -2 -1 0 1 2 3 4 5 -4 -3 -2 -1 0 1 2 3 4 5 0.4 0.3 P( z1 0.55 x) 0.2 0.1 0 -5 0.4 0.3 P( z2 0.45 x) 0.2 0.1 0 -5 x M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio P( x z1 , z2 ) P( z1 , z2 ) P( x ) P( z1 x ) P ( z2 x ) 1 0.7 Il valore massimo di probabilità per lo stato x condizionato alle misure 0.55 e 0.45 si ha per 0.25!!! 0.6 0.5 0.4 0.3 (dovrebbe essere invece 0) 0.2 0.1 0 -5 -4 -3 -2 -1 0 1 2 3 4 5 x M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio … torniamo indietro e cerchiamo di fare le cose per bene!!! Sappiamo che dobbiamo modellare la probabilità congiunta condizionata in maniera corretta!!! P( x z1 , z2 ) P( z1 , z2 ) P( x ) P( z1 , z2 x ) 1 Descriviamola a parole: se lo stato assume un valore x, entrambe le misure assumeranno una massima probabilità in x+xc con deviazione standard pari a zi, e quindi: Il modello matematico sarà: 1 ( z1 x xc )2 ( z2 x xc )2 P( z1 , z2 x ) exp 2 2 2 z1 z2 z1 z2 2 1 M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio P( x z1 , z2 ) P( z1 , z2 ) P( x ) P( z1 , z2 x ) 1 0.7 Il valore massimo di probabilità per lo stato x condizionato alle misure 0.55 e 0.45 adesso vale 0 0.6 0.5 0.4 0.3 0.2 0.1 0 -5 -4 -3 -2 -1 0 1 2 3 Notare: l’effetto sistematico è stato compensato M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Dipendenza condizionata - Esempio 4 5 x Il valore stimato mediante fusione è corretto (per questo caso particolare coincide con il valore presunto vero dello stato) La fusione delle informazioni di più sensori richiederebbe, in linea di principio, di memorizzare tutta l’informazione passata e, all’arrivo di una nuova k-esima informazione nella forma P(zk|x), di ricalcolare la probabilità complessiva aggiornata P(z1 … zk | x) Ma fortunatamente il teorema di Bayes si presta facilmente alla implementazione ricorsiva: Z k zk , Z k 1 P ( x, Z k ) P ( x Z k ) P( Z k ) Bayes P( zk , Z k 1 x ) P( x ) Nel caso in cui valga l’indipendenza condizionale P( zk x ) P( Z k 1 x ) P( x ) P( zk x ) P( x Z k 1 ) P( Z k 1 ) Bayes M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Forma ricorsiva P( x Z k ) P( Z k ) P( zk x ) P( x Z k 1 ) P( Z k 1 ) P( x Z ) k P ( zk x ) P ( x Z k 1 ) P( Z k ) / P ( Z k 1 ) P ( zk Z k 1 ) P( zk | Z k 1 ) Costante di normalizzazione P( x Z k ) P( zk | Z k 1 ) 1 P ( zk x ) P ( x Z k 1 ) Fusione al passo k Funzione di Fusione al passo k-1 verosimiglianza della nuova informazione al passo k M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Teorema di Bayes – Forma ricorsiva Nel caso le densità di probabilità possano essere modellate mediante distribuzione normale, la forma ricorsiva assume la seguente forma: k21 2 xk 2 z 2 x 2 k 2 k 1 k 1 k 1 1 k21 2 1 2 k 2 2 2 2 k 1 k 1 1 Filtraggio bayesiano dove: xk 1 2 k 1 zk 2 xk 2 k M. De Cecco - Lucidi del corso di Robotica e Sensor Fusion Forma ricorsiva – caso gaussiano
Scaricare