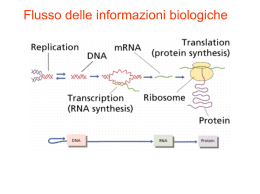
Dott.ssa Silvia Pellegrini Laboratorio Microarray Dipartimento di Patologia Sperimentale, Biotecnologie Mediche, Infettivologia ed Epidemiologia Tel. 050 2211251 e-mail: [email protected] Le scienze della vita sono attualmente al centro di una vera e propria rivoluzione 1953: modello di Watson e Crick Progetto Genoma Umano 1990 2003 Sequenziamento automatico secondo Sanger I sequenziatori automatici che impiegano il metodo di Sanger (ABI3730XL) hanno la capacità di generare 1–2 milioni di paia basi (bp) in 24 ore con una lunghezza di lettura di 550–800 bp e con un alto grado di accuratezza Altri genomi sequenziati Retrovirus Batteri S.Cerevisiae C.Elegans Drosophyla Zebrafish Zanzara Topo Ratto Cane Gatto Scimpanzé Genoma L’insieme di tutte le molecole di DNA presenti nel nucleo di ogni cellula Nell’uomo: 44 cromosomi autosomici 2 cromosomi sessuali Struttura del DNA cromosoma nucleo cellula Coppie di basi istoni Doppia elica gene della beta-globina umana 1 61 121 181 241 301 361 421 481 541 601 661 721 781 841 901 961 1021 1081 1141 1201 1261 1321 1381 1441 1501 1561 1621 1681 1741 1801 1861 1921 1981 2041 ccctgtggag ccagggctgg aactgtgttc tctgccgtta ggcaggttgg ggagacagag ttttcccacc tggggatctg gaaagtgctc tgccacactg gagtctatgg taggaagggg agtgtggaag cttttgttta atgccttaac aaaaaacttt catattcata catatttatg taattttgca cttatttcta tgcctctttg tatttctgca gctaatagca ggattattct tcccacagct tcaccccacc cccacaagta tccctaagtc gcctaataaa tactaaaaag caaaccttgg gctaatgcac ttcttgtaga ttgttttagc tcagccttga ccacacccta gcataaaagt actagcaacc ctgccctgtg tatcaaggtt aagactcttg cttaggctgc tccactcctg ggtgccttta agtgagctgc gacccttgat agaagtaaca tctcaggatc attcttgctt attgtgtata acacagtctg atctccctac ggttaaagtg tttgtaattt atactttccc caccattcta tataaatatt gctacaatcc gagtccaagc cctgggcaac agtgcaggct tcactaagct caactactaa aaacatttat ggaatgtggg gaaaatacac attggcaaca ggcttgattt tgtcctcatg ct gggttggcca cagggcagag tcaaacagac gggcaaggtg acaagacagg ggtttctgat tggtggtcta atgctgttat gtgatggcct actgtgacaa gttttctttc gggtacagtt gttttagttt tctttttttt acaaaaggaa cctagtacat tttattttct taatgtttta taaaaaatgc taatctcttt aagaataaca tctgcatata agctaccatt taggcccttt gtgctggtct gcctatcaga cgctttcttg actgggggat tttcattgca aggtcagtgc tatatcttaa gcccctgatg gcaggttaaa aatgtctttt atctactccc ccatctattg accatggtgc aacgtggatg tttaaggaga aggcactgac cccttggacc gggcaaccct ggctcacctg gctgcacgtg cccttctttt tagaatggga cttttatttg tcttctccgc atatctctga tactatttgg tttattttta atatgtgtac tttcttcttt ctttcagggc gtgataattt aattgtaact ctgcttttat tgctaatcat gtgtgctggc aagtggtggc ctgtccaatt attatgaagg atgatgtatt atttaaaaca actccatgaa cctatgcctt gttttgctat cactacccat aggagcaggg cttacatttg acctgactcc aagttggtgg ccaatagaaa tctctctgcc cagaggttct aaggtgaagg gacaacctca gatcctgaga ctatggttaa aacagacgaa ctgttcataa aatttttact gatacattaa aatatatgtg attgatacat acatattgac taatatactt aataatgata ctgggttaag gatgtaagag tttatggttg gttcatacct ccatcacttt tggtgtggct tctattaaag gccttgagca taaattattt taaagaaatg agaaggtgag attcatccct gctgtatttt ttgcttatcc agggcaggag cttctgacac tgaggagaag tgaggccctg ctgggcatgt tattggtcta ttgagtcctt ctcatggcaa agggcacctt acttcagggt gttcatgtca tgattgcatc caattgtttt attatactta gtaacttaaa tgcttatttg aatcattata caaatcaggg ttttgtttat caatgtatca gcaatagcaa gtttcatatt ggataaggct cttatcttcc ggcaaagaat aatgccctgg gttcctttgt tctggattct ctgaatattt atgagctgtt gctgcaacca cagaaaagga acattactta tgcatctctc Il contenuto di informazioni del DNA umano è dato dall’alternanza di 4 lettere A, G, T, C Flusso delle informazioni genetiche Alcuni dati sul genoma umano 3 miliardi di paia di basi 2% codificanti Circa 20.000 geni diversi Più di 10 milioni di variazioni Non siamo tutti uguali… Non esiste un’unica sequenza del genoma umano, ma circa il 10% dei 3 miliardi di paia di basi che compongono il genoma umano variano da individuo a individuo e costituiscono dei polimorfismi genetici. Polimorfismi genetici Forme alleliche diverse di una stessa sequenza presenti in più dell’1% degli individui di una popolazione I. Single Nucleotide--SNPs II. “indel” (inserzioni/delezioni) G TGACG A TG Variable Number of Tandem Repeats SNP (Single Nucleotide Polymorphism) Polimorfismi a singolo nucleotide ovvero cambiamenti di una base SNPs • Variazioni di sequenza comuni • Possono essere silenti • Possono avere un significato funzionale diretto (es. Cambio aminoacidico) • Possono essere semplicemente associati ad altre variazioni di sequenza con significato funzionale I polimorfismi possono essere responsabili di una diversa suscettibilità alle malattie… In questo caso le alterazioni geniche rappresentano fattori di suscettibilità, ciascuno dei quali contribuisce in una certa misura alla malattia, che si manifesterà soltanto quando i fattori di rischio nel loro insieme (geni e ambiente) superano una data soglia …come pure della variabilità individuale nella risposta alla terapia farmacologica Farmacogenetica Esamina le varianti genetiche che determinano la risposta ad un farmaco e studia il modo in cui queste varianti possono essere usate per prevedere il tipo di risposta •Farmaco giusto •dose giusta •paziente gusto Selezione sulla base di fattori predisponenti alle malattie Selezione sulla base di fattori responsabili di una diversa risposta al trattamento Terapia personalizzata diagnosi precoce Single SNP analysis Whole genome scans Next generation sequencing Confronto di efficienza tra diverse piattaforme per il sequenziamento 1000 genomes project (iniziato nel 2008 mira a sequenziare il genoma di 2500 La necessità di un approccio informatico alla ricerca nel settore biomedico deriva da questa recente esplosione di informazioni biologiche generate dalla comunità scientifica BIOINFORMATICA Disciplina situata all’interfaccia tra informatica e scienze biologiche (quali la biologia molecolare e la genetica) che applica algoritmi informatici per la risoluzione di problemi biologici Questa quantità enorme di informazioni è conservata e resa disponibile per l’intera comunità scientifica da tre organismi principali NCBI = National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov EMBL = European Molecular Biology Laboratory http://www.embl-heidelberg.de KEGG =Kyoto Encyclopedia of Genes and Genomes http://www.genome.jp/kegg/ creano Database di pubblico accesso diffondono informazioni biomediche sviluppano software per l’analisi di dati DNA RNA Proteine In ogni istante della propria vita ogni cellula umana contiene: •46 cromosomi (20.000 geni) •10-15.000 mRNA diversi Hanno tutte lo stesso genoma, perché queste cellule sono così diverse in morfologia e funzione? Fegato Corteccia cerebrale Muscolo liscio Perché esprimono geni diversi ESPRESSIONE GENICA E’ un processo molto complesso e finemente regolato che permette ad una cellula di rispondere dinamicamente sia agli stimoli ambientali che alle sue stesse necessità di cambiamento Misurare l’espressione di un gene significa.... Dare una valutazione quantitativa della presenza dei trascritti (molecole di mRNA) o delle proteine codificate da quel gene nelle cellule in esame Rapidi miglioramenti nella misurazione dell’espressione dei geni I microarray possono misurare l’espressione di tutti i geni noti in poche ore Misurare il trascrittoma Trascrittoma L'insieme di RNA messaggeri espressi da ogni cellula Proteoma L'insieme di proteine espresse da ogni cellula Tecnologia dei microarray Sfrutta la capacità di una data molecola di mRNA di ibridizzare con il DNA stampo da cui è stata generata Espressione genica differenziale: valuta le differenze nell’espressione genica tra due trascrittomi cellule trattate con un composto confronto con cellule non trattate un tessuto tumorale a confronto con uno sano Composto esogeno esogeno a Campione 1 Campione 2 RNA Cy5 cDNA Cy3 + Acquisizione dell’immagine mediante scanner Cy3 Cy5 L’intensità della fluorescenza è proporzionale alla quantità di molecola target nella soluzione e, quindi, costituisce una stima della quantità di RNA per ciascun gene espresso dalla cellula. Tipico esperimento Microarray Fonti di confondimento in un esperimento microarray • • • • • • • • Qualità dell’RNA estratto Retrotrascrizione Marcatura Deposizione delle sequenze sul vetrino Disomogeneità della superficie del vetrino Ibridazione Lavaggi Acquisizione dell’immagine REPLICHE SPERIMENTALI Stesso RNA testato su due vetrini distinti REPLICHE BIOLOGICHE RNA proveniente da campioni simili ma distinti Analisi computazionale dei dati
Scaricare