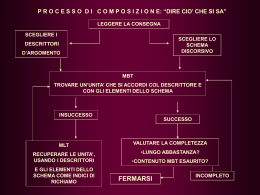
Indice
1 CATENE DI MARKOV
1.1
1.2
1.3
1.4
1.5
1.6
Introduzione . . . . . . . . . . . . . . . . . . . . .
Descrizione probabilistica delle catene di Markov .
Matrice di transizione, catene omogenee . . . . .
Classicazione degli stati . . . . . . . . . . . . . .
Teoria ergodica per le catene di Markov . . . . . .
Catene di nascita o morte . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2
2
6
11
18
27
38
2 PROCESSI STOCASTICI A TEMPI DISCRETI: TRATTAZIONE GENERALE
45
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
Premessa e prime denizioni . . . . . . . . . . . . . . . . . . . 45
La descrizione hilbertiana dei processi discreti . . . . . . . . . 53
La predizione lineare ottimale (caso nito) . . . . . . . . . . . 71
Operatori lineari in uno spazio di Hilbert e loro rappresentazione matriciale. Propagazione della covarianza . . . . . . . . 82
Operatori causali e processi con lo stesso ordine temporale . . 86
Innovazione processi regolari decomposizione di Cholesky . . 96
Il problema della predizione lineare ottimale caso innito . . . 102
Un'applicazone al ltro di Kalman-Bucy . . . . . . . . . . . . 106
3 I PROCESSI STAZIONARI
3.1
3.2
3.3
3.4
3.5
3.6
118
Processi stazionari in senso stretto . . . . . . . . . . . . . . . 118
Processi stazionari in senso debole . . . . . . . . . . . . . . . . 122
Funzione di covarianza: caratteristiche . . . . . . . . . . . . . 127
Lo spettro di potenza ed il calcolo spettrale . . . . . . . . . . 134
La predizione ottimale calcolo di M ed A dallo spettro . . . . 145
Problemi di stima della funzione di covarianza e dello spettro . 151
1
3.7 Processi semplici . . . . . . . . . . . . . . . . . . . . . . . . . 161
1 CATENE DI MARKOV
Premessa
Le catene di Markov costituiscono una particolare classe di processi stocastici, essendo costituite da una famiglia di variabili casuali denite in funzione
di un parametro mono-dimensionale o n-dimensionale discreto che interpreteremo come un tempo, n 2 N + f0 1 2 3 : : :g. Per esse quindi si puo
denire un \prima" e un \dopo" ed una corrispondenza con il principio di
causa ed eetto. La possibilita di individuare un senso obbligato (il \prima"
puo causare il \dopo" ma non puo essere il viceversa) determina anche la
trattazione matematica del problema.
Poiche il parametro varia per ipotesi in maniera discreta, il processo stocastico puo essere visto come la generalizzazione di una variabile tempo casuale
n-dimensionale: se X (n) = X0 X1 X2 : : : Xn]+ e una variabile le cui estrazioni sono in IRn+1 X (1) = X0 X1 X2 : : : Xn : : :]+ e una variabile casuale
in IR1(IR1 e il suo insieme di denizione) e ogni estrazione e rappresentata
da una successione di numeri reali.
1.1 Introduzione
Consideriamo ora tra le serie temporali quella classe il cui insieme di denizione e un reticolo in IR1, ottenuto dal prodotto cartesiano di sottoinsiemi
di IR discreti e niti. I punti di sono quindi successioni di numeri, ognuno
dei quali puo avere un valore scelto in un insieme discreto e nito di IR ogni
punto, ovvero ogni successione di questo tipo costituisce una realizzazione
del processo.
Le variabili marginali Xk di tali processi stocastici
X = fX0 X1 X2 : : : Xk : : :g non sono delle variabili casuali continue denite in IR, ma delle variabili casuali discrete con un numero nito di valori
argomentali.
Un esempio molto semplice e rappresentato dal lancio di una moneta innite
volte.
2
In tal caso, al variare di k Xk puo assumere solo due valori, testa o croce,
ovvero 0,1, ovvero -1,1, con probabilita 21 21 .
I valori che Xk puo assumere verranno di seguito indicati come stati del
sistema.
Fig.1.1.1
In Fig. 1.1.1 sono stati indicati i valori argomentali rispettivamente della marginale X0, della marginale (X0 X1), della marginale (X0 X1 X2) del
processo in esame. Essi sono ottenuti dal prodotto cartesiano dell'insieme discreto e nito (0,1) con se stesso 1, 2, volte rispettivamente per le marginali
a 2 e 3 dimensioni.
Un caso piu complesso e rappresentato dal RANDOM WALK 1 .
Gli stati del processo sono, al variare di k:
s0 = x0
s1 = x0 + x1
:::
sk = x0 + x1 + : : : + xk
:::
(1.1.1)
in cui xk e il risultato del \lancio di una moneta".
Non rientra, a rigore, nella classe delle catene di MARKOV, in quanto l'insieme dei
possibili stati del sistema varia da istante a istante e non e limitato nel tempo
1
3
Una tipica realizzazione del processo, puo essere rappresentata come in Fig.
1.1.2 quando xk puo assumere i valori (0,1)
Fig. 1.1.2
o come in Fig. 1.1.3
Fig. 1.1.3
quando xk puo assumere i valori (-1,1).
Caratteristica fondamentale di tali processi e che lo stato del sistema al tempo
k +1 dipende da quello al tempo k, ma e indipendente da come si e arrivati a
tale istante. In termini probabilistici cio si puo esprimere nel seguente modo:
P fSk+1 = sk+1jSk = sk Sk;1 = sk;1 : : : S0 = s0 g =
= P fSk+1 = sk+1jSk = sk g
(1.1.2)
4
Cio esprime la proprieta di Markov in senso debole.
Denizione 1.1.1: una CATENA DI MARKOV e un processo stocastico
il cui insieme di denizione e un reticolo in IR1 , in cui una qualunque
distribuzione condizionata soddisfa alla proprieta di Markov.
Osservazione 1.1.1: da un punto di vista sico, la proprieta di Markov
signica che, denito lo stato del sistema al tempo t, l'evoluzione successiva
del sistema stesso raccoglie come unica informazione sul suo passato proprio
il valore di xt , mentre la successive variazioni sono legate ad una qualche
causa stocastica, una \innovazione", indipendente dal passato.
Un notevole modello generale per leggi di questo tipo potrebbe essere
xk+1 = xk + g(xk "k+1)
(1.1.3)
che ovviamente traduce a tempi discreti una equazione dierenziale (o un
sistema di equazioni dierenziali se xk e una variabile pluridimensionale) del
tipo
x_ = g(x ")
(1.1.4)
Perche una equazione come la (1.1.4) dia luogo ad un processo di tipo markoviano basta assumere che "k+1 sia stocasticamente indipendente da "k;1 "k;2 : : :
in tal caso infatti, e facile vedere che e soddisfatta la (1.1.4). Per avere una
vera e propria catena di Markov, occorre anche supporre di discretizzare i
valori assunti da xk e che questi siano in numero limitato.
Riassumendo, nello studiare un particolare tipo di processi di Markov che
chiameremo Catene di Markov incontreremo sempre la seguente situazione:
sia dato un insieme discreto e nito dato l'insieme degli stati
S = fs1 s2 : : : smg 2 IR l'insieme degli eventi elementari del nostro processo e formato da un
reticolo regolare nito
r = S S : : : S : : : = S1 :
5
1.2 Descrizione probabilistica delle catene di Markov
Si consideri una catena associata ad una sequenza nita di tempi
k = 0 1 2 : : : N i possibili risultati si rappresentano in IRN +1 come una
successione di punti ognuno di coordinate (x0 x1 x2 : : : xN ) e l'insieme degli stati S e costituito da m valori reali qualsiasi o da m punti e sempre
possibile immaginare di trasformare la variabile x in modo tale che i nuovi
valori argomentali siano esattamente xk = i i = 1 2 : : : m. La descrizione
probabilistica di questa catena sara poi data dall'insieme delle probabilita
discrete
P fX0 = x0 X1 = x1 : : : XN = xN g = p(N ) (x0 x1 : : : xN ) :
(1.2.1)
Si noti che, come sempre nelle variabili a piu dimensioni, e la distribuzione
congiunta (1.2.1) che conta e non le singole distribuzioni
pi(xi) = P fXi = xi g
(1.2.2)
che sono invece le marginali della (1.2.1).
Il primo dubbio che si potrebbe avere e che, data la natura essenzialmente
discreta del problema, sia possibile, anche per una catena associata ad una
catena innita di tempi, denire una regola di probabilita assegnando le
probabilita punto a punto in , cioe per ogni singola realizzazione.
Dimostreremo tra breve che cio non e possibile perche possiede la potenza
del continuo. Tuttavia cominciamo a cercare di comprendere tale fatto con
un controesempio elementare.
Esempio 1.2.1: sia X = fX0 X1 : : :g la catena che rappresenta 1 lanci
indipendenti di una moneta, cos che ciascuna marginale Xi possa assumere
i valori 0 e 1 rispettivamente con probabilita 1/2, 1/2.
Sia
CN = fX0 = x0 X1 = x1 : : : XN = xN 8XN +1 8XN +2 : : :g (1.2.3)
un insieme in cui siano ssati i primi N + 1 valori. Le probabilita di tali insiemi devono coincidere con la (1.2.1) qualsiasi sia il valore di N e di
x0 x1 x2 : : : xN .
6
Nel nostro caso CN avra probabilita P (CN ) = 21N , cos che, ovviamente,
quando si cerchi la probabilita di una singola realizzazione
1
x = fx0 x1 : : : g = CN =
N =0
1
=
fX0 = x0 X1 = x1 : : : XN = xN g
(1.2.4)
\
\
N =0
risultera
1 =0
P
(
C
)
=
lim
P (x) = Nlim
N
!1
N !1 2N
(1.2.5)
Come si vede cio avviene per ogni realizzazione x, cos che appare ovvio che
la distribuzione su non puo essere ricostruita dalla probabilita delle singole
realizzazioni.
Come gia detto, cio che l'esempio precedente mette in luce e il fatto che ha la potenza del continuo e quindi, come per ogni insieme con tale cardinalita, una distribuzione di probabilita non puo essere denita sommando
probabilita di punti individuali.
Ne segue che, se vogliamo dare una descrizione probabilistica complessiva
della catena in IR1 occorrero arrivare a denire un'opportuna famiglia di
eventi (che deve anche essere una -algebra se si vuole che essa contenga tutte le unioni ed intersezioni numerabili di eventi) e le rispettive probabilita.
E logico poi richiedere che tale famiglia contenga come caso particolare insiemi del tipo (1.2.3) che chiameremo cilindri. Si tratta cioe di costruire una
distribuzione di probabilita, sull'insieme di IR1, che ammetta, per ogni N ,
le (1.2.2) come distribuzioni marginali.
La risposta ovvia, seppur alquanto astratta, al problema puo venire dal
seguente ragionamento:
supponiamo di saper assegnare ad ogni CN una probabilita P , che
soddis le seguenti condizioni di compatibilita (Kolmogorov):
X P fX0 = x0 X1 = x1 : : : XN = xN XN +1 = yg =
y
7
=
X p(N +1)fCN +1(x0 x1 : : : xN y)g =
y
(1.2.6)
= p(N ) fCN (x0 x1 : : : xN )g = P fX0 = x0 X1 = x1 : : : XN = xN g
che esprimono il fatto che ogni p(N ) puo essere vista come distribuzione
marginale di p(N +1) ,
deniamo una famiglia A di eventi che sia la minima -algebra di eventi
che contiene la sottofamiglia dei cilindri
fCN 8N x0 x1 : : : xN g supponiamo di poter estendere per continuita P da CN ad un qualsiasi
A 2 A (vi sono appositi teoremi che dimostrano che tale estensione
e possibile e noi ne vedremo tra breve una versione particolarmente
semplice),
in tal modo avremo denito una distribuzione di probabilita che soddisfa ai
requisiti minimali richiesti.
Naturalmente l'astrattezza del procedimento ci impedisce di comprendere
chiaramente la natura della distribuzione di probabilita cos costruita.
Lemma 1.2.1: ha la potenza del continuo.
Dimostriamo il lemma nel caso semplice che il sistema abbia solo due stati, cui
associamo i valori numerici (0,1) la dimostrazione puo essere generalizzata
in modo semplice al caso in cui il sistema abbia m stati distinti.
Sia # l'applicazione che fa corrispondere alla realizzazione x = fx0 x1 : : :g il
numero reale, compreso tra 0 e 1 (estremi inclusi)
#(x) = x0 12 + x1 212 + x2 213 + : : :
(1.2.7)
E ovvio che, potendo xk assumere al piu i valori 0 o 1,
cioe
#(x) 2 0 1]
(1.2.8)
#(x) : ! 0 1]
(1.2.9)
8
D'altro canto e facile anche vedere che per ogni r 2 0 1] esiste x tale che
#(x) = r
(1.2.10)
In eetti dalla (1.2.7), con ragionamento dicotomico, si vede che se 0 r < 21
si puo scegliere x0 = 0 e se 12 r 1 x0 = 1 se 0 r < 41 allora x1 = 0
e se invece 14 r < 12 x1 = 1 e cos via. Procedendo con tale criterio si
determina una successione fxk g tale che
XN 1 1
r ; xk k+1 < N +1
k=0 2 2
(1.2.11)
che, per N ! 1, dimostra la (1.2.10).
E bene notare che # non e biunivoca in eetti #;1 e non univoca per tutti i
punti con ascissa del tipo
r = 2kN (k intero 0 < k < 2N )
(1.2.12)
L'esempio
1 = 11 + 0 1 + 0 1 + : : : = 01 + 1 1 + 1 1 + : : :
2 2 22 23
2 22 23
(1.2.13)
dovrebbe essere su!ciente a chiarire il problema.
Tuttavia i numeri del tipo (1.2.12) costituiscono al piu un insieme numerabile,
cioe possono essere ordinati in una successione, cos che per tutti i casi in cui
i singoli punti hanno sempre probabilita zero come nell'Esempio 1.2.1, tale
insieme ha probabilita nulla e non muta i nostri calcoli probabilistici.
Comunque poiche ogni r 2 0 1] ha almeno una controimmagine in , resta
dimostrato che ha la potenza del continuo.
Osservazione 1.2.1: sia C N l'insieme
C N = fX0 = x0 X1 = x1 : : : XN = xN 8XN +1 : : :g
ci chiediamo quale sia l'immagine di C N secondo #.
9
(1.2.14)
Sara
frg = #(CN ) =
= x0 21 + : : : + xN 2N1+1 + 2N1+1 xN +1 12 + xN +2 212 + : : : =
= r0N + 2N1+1 t
(1.2.15)
con t reale arbitrario in 0,1].
Si vede che
#(C N ) = r0N r0N + 2N1+1
(1.2.16)
Inoltre, per quanto detto,
#;1 r0N r0N + 2N1+1 = (C N )
(1.2.17)
a meno possibilmente di una particolare successione (x0 x1 : : :), cioe di un
punto di che non appartiene a C N .
Ne deriva che, supposto di sapere a priori che nel processo in esame nessun
punto di possa avere una probabilita positiva, il problema di costruire
una distribuzione di probabilita in (cioe di costruire A e di estendervi
P , denita inizialmente solo su CN ), puo essere visto in immagine, tramite
#, come il problema di costruire una distribuzione di probabilita su 0,1] a
partire dai valori dati di probabilita per intervalli del tipo
(1.2.18)
P = r0N r0N + 2N1+1 = P (C N )
Si noti che le condizioni di Kolmogorov, indicando con
r0N = 2Nk+1
(1.2.19)
per k opportuno, diventano
P r 2 2Nk+1 k2N++11 =
(1.2.20)
=
P r 2 2Nk+1 + 2Ny+2 2Nk+1 + y2N++21
y=01
X
10
Esse devono essere valide, purche un singolo punto in 0,1] abbia sempre
probabilita 0.
Quindi il problema di denire una distribuzione di probabilita in a partire
dalle distribuzioni marginali (1.2.2) e sostanzialmente equivalente alla costruzione di una distribuzione di probabilita su 0,1] a partire dalla probabilita
nota per gli insiemi,
Fig. 1.2.1
probabilita rese consistenti tra loro dalla condizione (1.2.20).
Poiche tale problema ha soluzione unica in termini di distribuzione su IR,
altrettanto si puo dire per la questione originalmente posta in .
Come abbiamo detto questa argomentazione ha una ovvia generalizzazione
al caso in cui la catena in esame abbia m possibili valori.
Terminate queste considerazioni di carattere generale, passiamo ad esaminare
lo studio della evoluzione temporale della catena stessa, ovvero alla determinazione della distribuzione di probabilita tra gli stati al tempo t = k cioe
della distribuzione della variabile Xk , singolarmente presa.
1.3 Matrice di transizione, catene omogenee
Si abbia la seguente catena di Markov:
X0 X1 : : :
(1)
s1 p(0)
1 p1 : : :
(1)
s2 p(0)
2 p2 : : :
::: ::: ::: :::
si : : : : : : : : :
(1)
sm p(0)
m pm : : :
11
X1
p(1t)
p(2t)
:::
:::
pm(t)
:::
:::
:::
:::
:::
:::
(1.3.1)
in cui con si si indicano i possibili stati del sistema (i = 1 2 : : : m) e con
p(it) la probabilita che al tempo t il sistema si trovi nello stato si.
Si fa osservare che se le variabili casuali Xk fossero indipendenti tra di loro e
gli stati equiprobabili, saremmo nel caso lancio di un dado a m facce innite
volte, la distribuzione di probabilita ad ogni istante sarebbe nota probabilita
uguali fra loro e tutte pari a 1=m.
Nel caso in cui il processo soddis alla proprieta di Markov, invece, siamo in
grado di determinare tutte le distribuzioni p(t) se, come vedremo, e nota la
distribuzione ad un istante t e sono note le matrici di transizione del processo,
2 che andiamo a denire.
Supponiamo di conoscere la distribuzione del processo al tempo k sia
p(jk) = P fXk = j g la probabilita che il sistema al tempo k si trovi nello
stato j .
Dimostriamo che la probabilita che il sistema si trovi nello stato i al tempo
k + 1 e data da:
p(ik+1) = P fXk+1 = ijXk = j gp(jk)
(1.3.2)
X
j
e cioe la somma delle probabilita di tutti i percorsi che portano allo stato i
al tempo k + 1, passando per lo stato j al tempo k. Infatti:
la probabilita che il sistema si trovi nello stato i al tempo k + 1 e data da:
p(ik+1) =
P fX1 = 1 X2 = 2 : : : Xk = k Xk+1 = 1g (1.3.3)
X
1 2 :::k
ma
P fX1 = 1 X2 = 2 : : : Xk = k Xk+1 = ig =
= P fXk+1 = ijX1 = 1 X2 = 2 : : : Xk = k g P fX1 = 1 X2 = 2 : : : Xk = k g
(1.3.4)
essendo il processo di Markov
P fXk+1 = ijX1 = 1 X2 = 2 : : : Xk = k g =
= P fXk+1 = ijXk = k g
(1.3.5)
2
la matrice di transizione, in generale, varia da istante a istante.
12
e allora possiamo scrivere che
p(ik+1) =
X X
=
k 1 2 :::k;1
P fXk+1 = ijXk
X P fXk+1 = ijXk ; kg k
X P fXk = k Xk;1 = k;1 : : : X1 = 1g =
:::k;
X
P fXk+1 = ijXk = k gP fXk = k g
1 2
=
= k gP fX1 = 1 X2 = 2 : : : Xk = k g =
1
k
(1.3.6)
Denizione 1.3.1: si chiama matrice di transizione P (k) la matrice m m
i cui elementi sono dati da:
p(jik) = P fXk+1 = ijXk = j g
(1.3.7)
Essa realizza la transizione dalla distribuzione all'istante k a quella all'istante
k + 1 e precisamente
p(ik+1) = p(jik) p(jk)
X
j
p(k+1) = P (k)+p(k)
(1.3.8)
Percio tutta la storia dell'evoluzione della distribuzione puo essere ricostruita
con la successione
p(1) = P (0)+ p(0)
p(2) = P (1)+ P (0)+p(0)
:::
(1.3.9)
(
k
+1)
(
k
)+
(
k
;
1)+
(1)+
(0)+
(0)
=P P
:::P P p
p
Le matrici P (k) sono stocastiche, cioe soddisfano le due proprieta:
p(jik) 0
(1.3.10)
(
k
)
pji = P f8Xk+1jXk = j g = 1
X
i
13
Denizione 1.3.2: una catena di Markov con matrice di transizione costan-
te per ogni k e detta omogenea nel tempo.
In tal caso:
p(1) = P (0)+ p(0)
p(2) = P (1)+ P (0)+p(0) = (P +)2p(0)
:::
(1.3.11)
(
k
+1)
(
k
)+
(
k
;
1)+
(1)+
(0)+
(0)
+
k
+1
(0)
p
=P P
: : : P P p = (P ) p
Osservazione 1.3.1: da un punto di vista sico il concetto di omogenita e
legato alla invarianza per traslazione temporale della dinamica che governa
il sistema descritto dalla catena di Markov.
Cos ad esempio se il sistema segue una legge del tipo (1.1.3), se gli k hanno
tutti la stessa distribuzione, la probabilita di passare da Xk = j a Xk+1 = i
e pari alla somma delle probabilita di tutti quei valori di k+1 per cui
i = j + g(j k+1) poiche g e per ipotesi indipendente da k, anche questa probabilita non ne
dipende.
Esempio 1.3.1: ad esempio se
Xk+1 = Xk + k+1]mod3 se l'insieme degli stati e I = f0 1 2g e se
k ;1p 1q allora e chiaro che
fPji(k)g =
Stati al Stati al tempo k + 1
tempo k i = 0 1
2
j=0 0 p
q
1 p 0
q
2 q p
0
14
come si vede la matrice di transizione e appunto indipendente da k.
Esiste una maniera graca di rappresentare le matrici di transizione che
vediamo a partire da un esempio.
Esempio 1.3.2: si abbia la seguente matrice di transizione valida ad ogni
istante t = k:
0 1
0 p q
1 q p
in cui la colonna a sinistra della matrice indica gli stati al tempo k, la riga
sopra la matrice indica gli stati al tempo k + 1.
La probabilita che il sistema a partire dallo stato 0 al tempo k passi allo
stato 0 al tempo k + 1 e p (elemento della riga corrispondente allo stato
in considerazione al tempo k e della colonna corrispondente allo stato in
considerazione al tempo k + 1) e cos via.
15
Il grafo corrispondente e il seguente:
Fig. 1.3.1
in cui si indicano con i nodi gli stati possibili del sistema (in questo caso 2)
e con le frecce le transizioni, cui si associa la relativa probabilita.
Osservazione 1.3.2: generalizzando l'Esempio 3.2, possiamo ricavare la seguente regola che permette di istituire una corrispondenza biunivoca tra
matrici di transizione e gra orientati:
nella matrice di transizione consideriamo tutti e soli quegli elementi per
cui
p(jik) = P fXk+1 = ijXk = j g > 0
lasciando sottinteso che gli altri elementi sono necessariamente nulli
cos si crea un inventario delle coppie (j i) (per cui j e uno stato di
entrata al tempo k i e uno stato di uscita al tempo (k +1) tra cui esiste
una probabilita positiva di transizione dal tempo k al tempo k + 1
rappresentiamo gli stati del sistema con m punti nel piano, che saranno
i nodi del grafo: ad ogni coppia (j i) facciamo corrispondere una connessione (lato del grafo) orientata con una freccia da j ad i ad ogni lato
con freccia associamo un numero (intensita di "usso) corrispondente a
p(jik).
La corrispondenza inversa e del tutto evidente.
La rappresentazione cos introdotta e certamente espressione del funzionamento sico dell'evoluzione degli stati questa e utile particolarmente per catene omogenee in cui la matrice di transizione e quindi il suo grafo e sempre
la stessa al passare del tempo.
16
Esempio 1.3.3: si consideri ad esempio una catena di Markov omogenea
con matrice di transizione
0:5
0
0
P = 0
0
0
0
0:25 0 0 0:25 0
0 1 0
0 0
0 0 1
0 0
0:5 0:5 0
0 0
0 0 0
0 1
0 0 0
0 0
0 0 0 0:5 0:5
0
0
0
0
0
1
0
la sua rappresentazione mediante un grafo orientato sui suoi 7 stati e
Fig. 1.3.2
Fig. 1.3.2: i numeri tra parentesi rappresentano le probabilita di
transizione.
17
1.4 Classicazione degli stati
Denizione 1.4.1: si dice che lo stato j e comunicante con lo stato i se
esiste un tempo nito n per cui la probabilita di andare da j a i in n passi e
positiva
p(jin) > 0
(1.4.1)
Denizione 1.4.2: lo stato i e inessenziale se
( p(n) > 0
9(j n) ) pij(m) = 0
ij
(1.4.2)
8m
Denizione 1.4.3: se i non e inessenziale allora e essenziale, ovvero
( p(n) > 0
8j n 9m ) pij(m) > 0 oppure
ij
( p(n) = 0
ij
p(ijm) = 0
(1.4.3)
cioe e uno stato a cui, una volta visitato, si ha sempre la possibilita di tornare
in un tempo innito.
Sia S l'insieme degli stati della catena, esso e l'unione di stati inessenziali ed
essenziali
S =I E :
Denizione 1.4.4: se i comunica con j e j comunica con i, la coppia (i j )
e detta coppia di stati comunicanti.
Nel sottoinsieme E la probabilita di due stati di essere comunicanti e
riessiva: (i i) e comunicante in E , altrimenti i non potrebbe essere
essenziale
simmetrica: se i comunica con j ) j comunica con i:
18
Fig. 1.4.1
transitiva: se i comunica con j e j con k ) i comunica con k
Fig. 1.4.2
p(ikn+1) > p(jin) p(1)
jk > 0
p(ikh+m) > p(kih)p(jim) > 0
(1.4.4)
dunque la relazione binaria di essere stati comunicanti e una relazione di
equivalenza.
Pertanto gli stati essenziali si dividono in classi di equivalenza
disgiunte
\
E = Ei Ei Es = 0 i =
6 s
i
Lemma 1.4.1: non puo esistere una catena di Markov con un sistema S
fatto solo di stati inessenziali.
Per assurdo sia S fatta solo di stati inessenziali.
19
Fig. 1.4.3
Partiamo da i1 qualsiasi deve allora esistere i2 6= i1 ed n1 , tali che
8> (n )
< pi i > 0
>: p(imi) = 0
1
1 2
2 1
8m
(1.4.5)
ora ripartiamo da i2: deve esistere i3 6= i2 ed n2 tali che
8> (n )
< pi i > 0
>: p(imi) = 0
2
2 3
3 2
8m
(1.4.6)
Si noti che deve essere anche i3 6= i1 perche, per i3 = i1 , la prima delle (1.4.7)
risulterebbe in contraddizione con la seconda delle (1.4.6).
Inoltre deve anche essere
p(i3mi)1 = 0 8m
(1.4.7)
altrimenti
p(i3ni12+m) > p(i3mi)1 p(i1ni) 2 > 0 :
(1.4.8)
Procedendo in questo modo, si crea una catena che non puo mai essere percorsa all'indietro. Pertanto, ripetendo NI passaggi di questo tipo (NI =
20
numero totale di stati), ci si trova in uno stato i di I da cui non e possibile
uscire
P fXk = ijXk;i = ig = 1 se k NI
(1.4.9)
cioe e assorbente e quindi non inessenziale.
Lemma 1.4.2: sia data una catena di Markov fXng omogenea, i cui stati
siano divisi nei due sottinsiemi I , degli stati inessenziali, ed E , degli stati
essenziali. Ammesso che all'istante iniziale Xo 2 I , cioe che P fX0 2 I g = 1,
allora, quasi certamente, cioe con probabilita P = 1, la catena abbandona ad
un tempo nito l'insieme degli I , passando denitivamente in E .
L'aermazione signica che
P fXn 2 I 8njX0 2 I g = 0
(1.4.10)
infatti poiche il ritorno da E in I ha sempre probabilita P = 0, si ha che
Xn 2 I ) Xn;1 2 I ) Xn;2 2 I : : :
(1.4.11)
fXn 2 I g fXn;k 2 I g k = 0 : : : n
(1.4.12)
Xn 2 E ) Xn+1 2 E ) Xn+2 2 E : : :
(1.4.13)
cioe
mentre
cos che le sole realizzazioni di fXng che non passano denitivamente in E
sono quelle che stanno in I 8n.
Poiche la (1.4.12) implica che
P fXn 2 I g P fXn;k 2 I g
(1.4.14)
e poiche
P fXn 2 I 8ng = P fXn 2 I 8njX0 2 I g P fXn 2 I g 8n sso
21
(1.4.15)
ci bastera dimostrare che P fXn 2 I g e non solo decrescente, ma anche
tendente a zero per n ! +1 anzi, poiche P fXn 2 I g e decrescente, bastera
dimostrare che per una sottosuccessione nj (nj ! +1 j ! +1)
lim P fXnj 2 I g = 0
(1.4.16)
j !+1
Sia i0 un qualunque stato di I i0 2 I e supponiamo che x0 = i0 per denizione di stato inessenziale e seguendo il ragionamento del lemma precedente
si vede che per un qualche N nito
P fXN 2 E g = pi0 > 0
(1.4.17)
per la (1.4.13) allora si avra anche
P fXn 2 E 8n N g pi0
(1.4.18)
Poiche questo e vero per tutti gli stati i0 2 I (che sono in numero nito), e
chiaro che esistera un N su!cientemente grande ed un p abbastanza piccolo,
ma sempre p > 0, tali che
P fXN 2 E g = P fXN 2 E jX0 2 I g p
(1.4.19)
infatti
P fXN 2 E jX0 2 I g =
Ma allora
XP fX 2 EjX0 = i0gP fX0 = i0g N
i 2I
X
p P fX0 = i0 g = p
(1.4.20)
0
i0 2I
P fXN 2 I g = P fXN 2 I jX0 2 I g 1 ; p = q < 1 inoltre, essendo la catena omogenea, dovra anche essere, 8k
P fXN +k 2 I jXk 2 I g q < 1 :
(1.4.21)
(1.4.22)
Ora
P fX2N 2 I jX0 2 I g = P fX2N 2 I jXN 2 I gP fXN 2 I g 22
(1.4.23)
poiche
P fX2N 2 I jXN 2 E g = 0 (1.4.24)
cos che per la (1.4.21) e la (1.4.22)
P fX2N 2 I g = P fX2N 2 I jX0 2 I g q2 :
(1.4.25)
Procedendo analogamente si ha pure
P fXjN 2 I g qj ! 0 per j ! 1
(1.4.26)
cos che la (1.4.16) risulta dimostrata, con nj = jN ed il teorema e
provato.
Corollario 1.4.1: vale
lim P fXn 2 E g = 1
n!1
(1.4.27)
Dal Lemma 1.4.2 discende una prima classicazione qualitativa del processo
che stiamo analizzando: divisi gli stati nelle due classi I ed E , se il processo
nasce in E (X0 2 E ) allora vi rimane: se il sistema nasce in I , dopo un tempo
piu o meno lungo passa in E senza piu ritornare in I .
Il seguente lemma permette di specicare meglio il comportamento di fX g.
Lemma 1.4.3: se E si decompone in due classi disgiunte non comunicanti
E1 E2 .
9 nlim
!1 P fXn 2 E1 g = p1
9 nlim
!1 P fXn 2 E2 g = p2
(1.4.28)
P fXn+1 2 E1 g P fXn 2 E1 g
(1.4.29)
p1 + p 2 = 1
Infatti
23
perche
Xn 2 E1 ) Xn+1 2 E1
(1.4.30)
P fXn 2 E1 g P fXn 2 E2g
(1.4.31)
e quindi le successioni
sono crescenti, limitate superiormente e percio hanno limite, inoltre
p1 + p2 = nlim
!1 P fXn 2 E1 g + nlim
!1 P fXn 2 E2 g =
= nlim
!1 P fXn 2 E g = 1
(1.4.32)
Cio implica che il comportamento di evoluzione asintotica di una distribuzione iniziale di probabilita
P fX0 = ig = p(0)
i
(1.4.33)
abbia le seguenti caratteristiche:
se X0 2 I dopo un certo tempo n Xn va in E , inoltre Xn tende
a distribuirsi tra le classi irriducibili di E con una certa distribuzione di probabilita asintotica si osservi che in generale la distribuzione
asintotica tra gli Ek dipende dalla distribuzione iniziale (1.4.33)
24
Fig. 1.4.4
se invece X0 2 E allora X0 appartiene ad una delle classi disgiunte di
equivalenza Ek e vi rimane per sempre.
In conclusione, si puo dire che il comportamento asintotico di una catena di
Markov si riassume nel fatto che prima o poi lo stato della catena cadra in
una delle classi disgiunte degli stati essenziali e cio avverra con probabilita
calcolabile. Una volta raggiunta una delle Ei ci chiediamo ancora quale sara
il comportamento della catena in tale classe questo sara l'oggetto di studio
del prossimo paragrafo almeno per alcuni casi relativamente semplici.
Esempio 1.4.1: riprendiamo l'Esempio 1.3.3 e chiaro che 1 e uno stato
inessenziale in quanto il sistema quando lo abbandona non puo piu ritornarvi.
Tolto lo stato 1 il grafo di Fig. 1.3.2 si decompone automaticamente in due
classi disgiunte
E1 f2 3 4g E2 f5 6 7g :
E chiaro che ciascuna delle due classi e fatta da stati essenziali. Al di la del
fatto che appare intuitivo per motivi di simmetria che
1
lim
P
f
X
2
E
g
=
n
1
n!1
2
1
lim
P
f
X
2
E
g
=
n
2
n!1
2
25
proviamo a dimostrare anche direttamente che cio e vero a partire dalla
matrice di transizione del processo. A questo scopo e utile osservare che
poiche il fenomeno che vogliamo studiare e la transizione 1 ! E1 e 1 ! E2 ,
mentre per ora non ci interessa sapere cosa succede all'interno di ogni classe,
e utile costruire uno schema ridotto della catena in cui le classi E1 E2 siano
condensate in due unici stati. Si perviene cos allo schema ridotto di Fig.
1.4.5
Fig. 1.4.5: p + q + r = 1
che nel caso dell'Esempio 1.3.2 corrisponde a
p = 1=2 q = r = 1=4 :
La matrice di transizione corrispondente al grafo ridotto e dunque
p q r
P= 0 1 0 :
0 0 1
Supposto che al tempo zero il sistema si trovasse in 1, che e l'unico caso
signicativo per noi, cos che
p(0)+ = j1 0 0j
e facile vericare che (cfr. (1.3.11)
X
n;1 !
n;1 ! X
pk :
pk r
p(n)+ = P (0)+pn = pn q
k=0
k=0
26
Quindi passando al limite per n ! 1 si trova direttamente
q lim P fX = 3g = r
lim
P
f
X
=
1
g
=
0
lim
P
f
X
=
2
g
=
n
n
n
n!1
n!1
1 ; p n!1
1;p
che e appunto quanto ci aspettavamo.
1.5 Teoria ergodica per le catene di Markov
Supposto di esserci ristretti ad una catena omogenea costituita da un unica
classe di stati essenziali e comunicanti, ci chiediamo quale sia il comportamento della catena stessa, ovvero come si distribuisca la probabilita tra gli
stati essenziali, quando il tempo di evoluzione del sistema tende ad 1. Poiche l'evoluzione nel tempo della distribuzione di probabilita tra gli stati di
una catena omogenea e legata alla matrice di transizione e alla distribuzione
di probabilita iniziale, secondo la (1.3.11), occorrera studiare come agisce
(P +)k sui vettori di probabilita quando k ! 1.
Studiamo questo problema dapprima ponendo la forte ipotesi semplicatrice
che la matrice di transizione P (o la sua trasposta che per comodita chiameremo A) sia costituita tutta da elementi positivi, ovvero che tutti gli stati
siano comunicanti ad un passo con probabilita positiva vedremo piu oltre
come rilassare almeno parzialmente tale ipotesi.
Sia
1
1
e = 1 Sia A la matrice
aij = pji 0 < m pij M < 1 allora il fatto che P sia stocastica si traduce nella utile relazione
e+A = : : : aij : : :] = : : : pji = 1 : : :] = e+
X
X
i
i
27
(1.5.1)
(1.5.2)
Sia N il numero degli stati del processo descritto dalla catena di Markov in
esame al tempo k la distribuzione di probabilita tra gli stati sara un vettore
di IRN . Introduciamo in IRN una norma (L1 ) denita come
jr j =
X jrj j
(1.5.3)
j
Come si vede se p e una distribuzione di probabilita , il vettore corrispondente
avra jpj = 1 in IRN secondo tale norma.
Osservazione 1.5.1: se p e una distribuzione di probabilita (cioe
pi 0 e+p = 1), allora q = Ap e pure una distribuzione di probabilita.
Infatti
e+q = e+(Ap) = (e+A)p = e+p = 1
e inoltre
qi =
(1.5.4)
X aij pj = X pj pji 0
j
(1.5.5)
j
Quindi, poiche la matrice A governa la transizione da un vettore di probabilita ad un altro, avremo che, per per un vettore di probabilita p0 qualsiasi
jA+`p0 j = jA`;1p0 j = : : : = jp0 j = 1 :
(1.5.6)
Lemma 1.5.1: consideriamo il sottospazio R? = fv : e+v = 0g
A trasforma R? in se stesso.
Infatti
se e+v = 0 ! e+(Av) = (e+A)v = e+ v = 0 .
Ora in maniera particolare ci interessa studiare il comportamento di A quando essa agisce su R?, considerato come sottospazio di IRN , con la stessa
norma.
In generale avremo, sfruttando la proprieta di stocasticita di A,
jAvj =
X j X aij vj j X X jaij jjvj j = X jvj j X jaij j = X jvj j(1.5.7)
i
j
i
j
j
28
i
j
che dimostra che A, come trasformazione lineare di R?, e una trasformazione
non espansiva, ovvero jAj 1. In realta sfruttando a pieno l'ipotesi (1.5.1)
dimostreremo che la A e una contrazione in R?.
Lemma 1.5.2: in R? vale
jAvj jvj
<1
(1.5.8)
Fissato v sono ssati due insiemi di indici I + I ; tali che
vj 0 j 2 I +
vj < 0 j 2 I ;
Si noti che
e inoltre
X vj = 0 ! X vj = X(;vj )
(1.5.10)
X jvj j = X vj + X (;vj ) = 2 X vj
(1.5.11)
e+ v = 0 )
jv j =
(1.5.9)
j
i2I
j
I;
I+
Fissato v consideriamo
ui = aij vj =
X
j
j 2I ;
+
j 2I
+
X aij vj ; X aij (;vj )
j 2I
j 2I ;
+
(1.5.12)
sia ci il segno di ui
ci = +1 se ui > 0
ci = ;1 se ui < 0
allora
X juij = X ciui = X vj X ciaij
i
i
j
i
(1.5.13)
I ci non sono tutti concordi poiche e+u = 0, quindi, ricordando la (1.5.1)
X jciaij j 1 ; 2m = < 1
i
29
(1.5.14)
Percio
X juij X jvj jj X ciaij j X jvj j
i
j
i
(1.5.15)
j
ovvero, ogni volta che si applica A ad un vettore di R?, la sua norma si
contrae di .
Ci serviremo di tale risultato per dimostrare il teorema seguente.
Teorema 1.5.1: (sullo stato limite). Se A e stocastica, se m = min pij > 0
e se p0 e una distribuzione iniziale di probabilita
( i p0i = 1 p0i 0) allora Anp0 ammette limite
lim Anp0 = p
n!1
P
P
(1.5.16)
tale che p e una distribuzione di probabilita, ovvero (pi 0 i pi = 1)
il limite (1.5.16) va inteso nel senso della norma di IRN , ovvero in senso
ordinario per le componenti.
1. La dierenza tra due distribuzioni di probabilita p ; q e sempre in R?.
Infatti
e+(p ; q) = e+p ; e+q = 0
(1.5.17)
2. Consideriamo la dierenza
An+`p0 ; Anp0 = An(A` ; I )p0
e notiamo che
v = (I ; A`)p0 = p0 ; A`p0 2 R?
Percio, ricordando la (1.5.6) ed osservando che
jvj jp0j + jA`p0j 2jp0j = 2
si ha
(1.5.18)
8`
(1.5.19)
(1.5.20)
jAn+`p0 ; Anp0 j = jAnvj jAn;1vj : : : njvj 2nn;!
!10 (1.5.21)
30
Corollario 1.5.1: la distribuzione p e temporalmente invariante.
Infatti
n
n+1
Ap = A nlim
!1 A p0 = nlim
!1 A p0 = p
(1.5.22)
Cio signica che se il processo, ad esempio al tempo 0 ha una distribuzione
come p, allora, in tutti gli istanti successivi, manterra la stessa distribuzione.
Corollario 1.5.2: la distribuzione invariante p e unica.
Infatti
se p1 p2 sono invarianti
An(p1 ; p2) = p1 ; p2
inoltre poiche p1 ; p2 2 R?, per il Lemma 1.5.2
quindi
(1.5.23)
An(p1 ; p2 )n;!
!10
(1.5.24)
p1 = p2
(1.5.25)
Dunque p e un attrattore stabile per il sistema evolutivo descritto da An p0.
Si noti che n qui abbiamo supposto che valesse l'ipotesi
aij = pji 0 < m pji M < 1 (1.5.26)
per ottenere una cos forte restrizione dimostriamo il seguente teorema:
Teorema 1.5.2: condizione suciente anche Anp0 tenda ad una distribu-
zione stazionaria e che
(Ak )ij m > 0
per qualche k ssato.
31
(1.5.27)
In eetti, sfruttando il Teorema 1.5.1 sullo stato limite, si ha immediatamente
lim (Ak )np0 = p (1.5.28)
n!1
vogliamo pero qui dimostrare che e proprio
lim Anp0 = p :
n!1
Infatti
(An+` ; An )p0 = An(A` ; I )p0 = Akm A v
avendo posto
n = km + ( < k) e v = (A1 ; I )p0 2 R?
Essendo A v 2 R?
(1.5.30)
(1.5.31)
jvj 2 jAj 1
(1.5.32)
jAkmjR? = j(Ak )mjR? m
(1.5.33)
j(An+` ; An)p0j m jAj jvj;!
0
n!1
(1.5.34)
e per il Lemma 1.5.2
si trova:
(1.5.29)
Osservazione 1.5.2: la condizione sopra citata e solo su!ciente e comunque vi sono dei casi in cui non e soddisfatta, come dimostra il seguente
semplice esempio
Fig. 1.5.1
32
0 1
con matrice di transizione P = A = 1 0 infatti in tal caso A2n+1 = A
e A2n = I cosicche tale condizione non e soddisfatta per alcuna potenza di
A.
Si noti che in questo caso, partendo da uno stato iniziale pq (p + q = 1)
si trova alternativamente p2n = pq p2n+1 = pq , che quindi non da in
generale una successione convergente, tranne che se p = q = 1=2. In questo
caso lo stato p = q = 1=2 e anche lo stato invariante per A.
Lemma 1.5.3: p puo essere caratterizzato oltre che dalla relazione Ap = p
(le componenti pi sono proporzionali ai minori della prima riga di A ; I ),
anche dalla seguente notevole proprieta
lim An = pe+
(1.5.35)
n!1
P
Infatti sia p0 qualunque (normalizzato con la condizione i p0i = 1)
allora
Anp0 = An(I ; pe+)p0 + Anpe+p0 = An(p0 ; p) + pe+p0 !
! pe+p0 (= p)
(1.5.36)
perche e+p0 = 1 p0 ; p 2 R? e An (p0 ; p) ! 0.
Quindi
p1 p1 (1.5.37)
An ! pe+ = p
2 p
2 pn pn 3
77
5
2
66
4
Poiche A e il trasposto della matrice di transizione, saranno le righe di
quest'ultima, elevata alla n, a tendere a p.
Teorema 1.5.3: (teorema ergodico o legge dei grandi numeri).
Sia X = fX0 X1 : : :g una catena di Markov con matrice di transizione P =
A+, che ammette un unico stato limite sia
iN = numero degli Xk = i tra i primi N 33
allora risulta
N
i = p
lim
i
N !1 N
(1.5.38)
che rappresenta la probabilita dello stato i nella distribuzione limite p: il
limite va intero in media quadratica, cioe
iN lim E N = pi
N !1
N
2 i
lim N =0
N !1
1. Infatti ricordiamo che (teorema di Cesaro)
n
1
lim a = a ) Nlim
n!1 n
!1 N i an = a
X
Notiamo poi che si ha
iN
dove
i (xk ) =
N
X
= i(xk )
k=0
1
se xk = i
0 se xk =
6 i
Inoltre vale la relazione
E fi(Xk )g = 1 P fXk = 1g Ora sia
(1.5.39)
0 ei = 1 i
0 0
34
(1.5.40)
(1.5.41)
(1.5.42)
(1.5.43)
allora
P fXk = ig = e+i Ak p0
cosicche
+ k
+
k
+
lim E fi(Xk )g = klim
k!1
!1 ei A p0 = ei klim
!1 A p0 = ei p = pi
Quindi
X
n
1
lim
E fi (Xk )g = pi
N !1 N
k=1
cioe
iN lim E N
N !1
= pi
(1.5.44)
(1.5.45)
(1.5.46)
(1.5.47)
2. Dimostriamo ora la seconda della (1.5.30) a tal ne usiamo la relazione
N
N 2
N
(1.5.48)
2 Ni = E (Ni 2) ; E Ni
Calcoliamo
E
(1N )2 N2
X
= N12
XN Efi(Xk)i(X`)g =
k=0
`=0
(1.5.49)
XX
N
N N
1
2
2
= 2 E fi (Xk ) g + 2
N k=0
N k=0 `=k+1 E fi (Xk )i(X`)g
ma per la (1.5.33), essendo 2i = i ,
E fi(Xk )2g = E fi(Xk )g = P fXk = ig ! pi
percio
X
!
1 1 N E f (x )2 g pi (N ! 1)0
i k
N N k=0
N
35
(1.5.50)
(1.5.51)
Inoltre, osservando che i(j ) = ij per la (1.5.42),
E fi (Xk )i(X`)g = EXk fE fi(Xk )i (X`)K gg E fi(Xk )i(X`)jXk = j gP (Xk = j ) (1.5.52)
X
Xj Efi(x`)jXk = jgi(j)P (Xk = j) = Efi(X`)jXk = ig j
P fX` = ijXk = igP fXk = ig = e+i A1;k ei e+i Ak p0
Ma allora
XN Efi(Xk)(X`)g = e+Akp0 i
X e+A`;kei = e+Akp0(N ; k)e+ `=k+1
N
`=k+1
i
i
i
1
N ;k
X As! ei
(1.5.53)
N ;k
s=1
Dunque si ha, applicando il teorema di Cesaro e ricordando che An ! pe+,
N ;k
1
+
CN ;k = ei N ; k As eiN e+i pe+ ei = pi
(1.5.54)
!1
s=1
inoltre
X !
Bk = e+i Ak p0 ! pi per k ! 1
ed entrambe le successioni sono limitate.
In questa situazione e facile vedere che
X
X
(1.5.55)
2 N B C (N ; k) = lim 2 N p2(N ; k) =
lim
k N ;k
i
N !1 N 2
N !1 N 2
k=1
k=1
2 N (N + 1) = p2
p2i Nlim
(1.5.56)
i
!1 N 2 2
Quindi si ha:
N 2
N
N
(1.5.57)
2 Ni = E (Ni 2) ; E Ni p2i ; p2i = 0
36
Essenzialmente questo teorema aerma che, valutando su una realizzazione
unica la percentuale di occupazione dello stato i su N tempi e lasciando
tendere N ! 1, si ritrova la probabilita limite pi.
N
Poiche (1.5.37) e (1.5.38) implicano che Ni ! pi in probabilita, nel caso che
N ;1
! (pi);1 d'altro canto il limite
per ipotesi pi 6= 0 si avra anche Ni
di NiN puo essere interpretato come tempo medio di ritorno del sistema allo
stato i, percio, quanto dimostrato, si puo anche esprimere dicendo che il
tempo di ritorno allo stato i, su tutta una realizzazione, e pari all'inverso
della probabilita asintotica che il sistema si trovi in i.
Osservazione 1.5.3: il teorema ergodico che abbiamo qui dimostrato e naturalmente strettamente imparentato con la legge (debole) dei grandi numeri, che aerma che, dato un campione Bernoulliano di numerosita N , la
frequenza relativa fN (I ) di estrazioni appartenenti ad un intervallo I , tende
in media quadratica alla probabilita teorica p(I ). La notevole dierenza tra
questa legge e quanto dimostrato sopra sta nel fatto che per un campione
Bernoulliano le variabili X1 X2 : : : sono tutte indipendenti tra loro e tutte
uguali in distribuzione, mentre nel caso trattato qui le variabili non sono tra
loro indipendenti ne ugualmente distribuite.
Esempio 1.5.1: concludiamo il caso iniziato con l'Esempio 1.3.3, cercando
la distribuzione asintotica, se esiste, all'interno delle due classi essenziali
E1 E2 che sono chiaramente tra loro equivalenti. Per semplicita dunque
ci riduciamo ad una catena con tre stati con graco e matrice di transizione
P mostrati in Fig. 1.5.2.
37
Fig. 1.5.2
0
P = 0
1=2
1 0
0 1
1=2 0
In primo luogo ci si chiede se e possibile applicare il Teorema 1.5.2. In eetti
non e di!cile vedere che da P no a P 4 restano in P n degli elementi di
matrice nulli ad esempio partendo da 1 e chiaro che in 4 mosse la probabilita
di tornare a 1 e nulla.
Tuttavia e
1=4 1=4 1=8
5
P = 1=4 1=2 1=4
1=2 1=4 3=8
i cui elementi sono tutti positivi cos che vale la condizione (1.5.27). In tal
caso esiste la distribuzione asintotica p+ = jp1p2 p3j, tale che
p+ = p+P ne segue che la distribuzione asintotica e data da
1
1
p= 5 2 :
2
1.6 Catene di nascita o morte
Una catena di nascita o morte e una catena di Markov con probabilita di
transizione per uno stato intermedio i, rappresentata dal graco:
Fig. 1.6.1
38
ovvero tale che ogni stato comunichi solo con se stesso o con quelli adiacenti.
Agli estremi di questa catena si possono avere comportamenti diversi, tutti
compatibili con tale proprieta di base.
1.
Fig. 1.6.2
la connessione e ancora di tipo locale cioe limitata al piu vicino nel caso che
ra = 0 deve essere pa = 1, il che signica che la barriera e \ri"ettente"
2. caso \circolare"
i punti a e b possono essere disposti in un cerchio su cui si evidenzia che la
transizione e sempre al piu vicino
Fig. 1.6.3
3.
39
Fig. 1.6.4
Lo stato del sistema, raggiunto l'estremo a vi si ferma con P = 1.
La barriera a e allora detta \assorbente".
Osservazione 1.6.1: se in una catena vi e un solo estremo assorbente e gli
stati sono tutti comunicanti, lo stato limite nisce nell'estremo assorbente
con P = 1 cioe
X P fXm = a se m M Xm 6= a se m < M g =
=
M
P fX raggiunga a in un qualunque tempo nito g = 1
infatti in questo caso tutti gli stati sono inessenziali tranne a.
Osservazione 1.6.2: se vi sono due estremi a b assorbenti, questi costituiscono classi disgiunte, mentre tutti gli altri stati sono inessenziali.
Si vogliono trovare le probabilita del sistema di essere intrappolato in a o in
b (che chiameremo rispettivamente e ), essendo partito dallo stato x.
Si indichi con Bm(x) e Am (x) l'insieme delle realizzazioni in cui il sistema
arriva rispettivamente allo stato b e a per la prima volta all'istante m essendo
partito dallo stato x:
Bm (x) = fx xm = b a < xk < b k < mjx0 = xg
Am (x) = fx xm = a a < xk < b k < mjx0 = xg
(1.6.1)
Notiamo che Bm e disgiunto da Bm+1 Bm+2 e lo stesso vale per Am in quanto
le singole realizzazioni x sono tutte diverse tra loro pertanto posto
+1
M
B (x) = Bm (x) = Mlim
Bm (x) = Mlim
B M (x)
!1
!1
m=1
m=1
+1
M
A(x) = Am (x) = Mlim
Am (x) = Mlim
AM (x)
(1.6.2)
!1
!1
m=1
m=1
40
le probabilita cercate
1
(x) = P
fx xm = b a < xk < b se k < mjx0 = xg
(x) = P
"
"m
1=1
m=1
#
#
fx xm = a a < xk < b se k < mjx0 = xg
saranno date da
M
(x) = P fB (x)g = Mlim
!1 P fB (x)g = Mlim
!1 M (x)
M
(x) = P fA(x)g = Mlim
!1 P fA (x)g = Mlim
!1 M (x)
(1.6.3)
(1.6.4)
Ma
=
M (x) = P (B M ) =
P fa < xj < b 1 j < m
xm = b m = 1 2 : : : M jx0 = xg =
=
X P fa < xj < b 1 j < m
y
xm
XM P (Bm) =
m=1
= b 1 m M jx0 = x x1 = ygPxy
(1.6.5)
dove Pxy e la probabilita di passare allo stato y al tempo 1 essendo partiti
dallo stato x al tempo 0.
Per la proprieta di Markov, si ha
P fa < xj < b 1 j < m
xm = b 1 m M jx0 = x x1 = yg =
= P fa < xj < b 2 j < m
xm = b 2 m M jx1 = yg = M ;1(y)
(1.6.6)
Quindi
M (x) =
X PxyM ;1(y)
y
41
(1.6.7)
e per M ! 1
(x) =
X Pxy(y)
(1.6.8)
y
ovvero e invariante per la matrice di transizione e lo stesso vale per .
Osservazione 1.6.3: si noti che (x) e (x) non hanno nulla a che vedere
con lo stato limite p che e invece invariante per la matrice A = P +.
Osservazione 1.6.4: si osservi che vale
(x) + (x) = 1 8x
(1.6.9)
purche gli stati siano tutti connessi infatti in tal caso tutti gli stati tranne a
e b sono inessenziali.
Questa relazione, che vale per una qualunque catena con due stati assorbenti,
ci permette di ridurre la ricerca di (x) (x) ad una sola delle due funzioni,
ad esempio (x) usando la (1.6.8) ed il fatto che (a) = 0 (b) = 1 per
denizione.
Esempio 1.6.1: applichiamo il ragionamento sopra visto ad una catena
omogenea di vita o morte, la cui matrice di transizione quando si cataloghi
a come primo stato b come ultimo, e data da
1
q
0
P = 0 0 0
r p 0
q r p
0 q r
0 0 0
:
p 1
In tal caso, ricordando la (1.6.8), vale
(x) = p (x + 1) + r (x) + q (x ; 1) a < x < b (1.6.10)
(a) = 0 (se la catena parte in a non ne esce)
(1.6.11)
(b) = 1 (se la catena parte in b non ne esce ed e
sicuro che rimanga in b)
(1.6.12)
42
Posto r = 1 ; p ; q si trova
p (x + 1) ; (x)] = q (x) ; (x ; 1)]
(1.6.13)
#x = (x + 1) ; (x) = pq
(1.6.14)
#x = #x;1
(1.6.15)
#a = (a + 1) ; (a) = (a + 1)
(1.6.16)
cos che posto
si ha semplicemente
Poiche per x = a si ha
posto successivamente x = a + 1 a + 2 : : : si trova
#a+1 = #a = (a + 1)
#a+2 = 2 #a = 2 (a + 1)
:::
#b;1 = b;a;1 #a = b;a;1 (a + 1)
ovvero vale la relazione ricorsiva generale
(x + 1) ; (x) = x;a#a = x;a (a + 1)
(1.6.17)
(1.6.18)
Poiche
(x + 1) = (x + 1) ; (x) + (x) ; (x ; 1) + : : : +
+ (a + 1) ; (a) =
= x;a (a + 1) + x;a;1 (a + 1) + : : : + (a + 1)
(1.6.19)
ricordando che (a) = 0, si ha che
Xx k;a(a + 1) = (x + 1)
k=a
43
(1.6.20)
applicando questa relazione per x = b ; 1 e ricordando la (1.6.12), si trova
b;1
k;a (a + 1) = (b) = 1
(1.6.21)
X
k =a
da cui discendono le relazioni
(a + 1) = b;1 1
k;a
X
k=a
Xx k;a
(1.6.22)
1 + + : : : + x;a = 1 ; x+1;a (1.6.23)
(x + 1) = kb;=1a
Xk;a 1 + + : : : + x;a 1 ; x+1;a
k=a
che risolvono completamente il problema posto per puo essere ricavato
dalla (1.6.9).
44
2 PROCESSI STOCASTICI A TEMPI DISCRETI: TRATTAZIONE GENERALE
2.1 Premessa e prime denizioni
In questo capitolo si intende studiare una classe di processi stocastici assai
piu estesa di quella delle catene di Markov che purtuttavia mantiene una
decisiva semplicazione nella descrizione del suo comportamento in quanto il
\processo" e rappresentato da una famiglia di variabili casuali (v.c.) ordinate
per mezzo di un parametro n discreto
X = fXn n 2 Zg :
(2.1.1)
Qui le singole componenti Xn sono in generale v.c. in IR e non limitate ad
un numero discreto e nito di valori come nel caso delle catene.
Inoltre, per il tipo di scopo che si pregge il presente studio, supporremo
sempre che tutte le v.c. da noi usate abbiano media e varianza nite, cos da
poter usare il formalismo di L2() descritto nel quaderno Q4.
Dunque, in termini piu formali, dato uno spazio di probabilita f A P g
consideriamo una successione di v.c.
Xn = xn(!) n 2 Z (oppure n 2 Z + fn 0g) con Xn 2 L2() un processo stocastico a parametro discreto e per noi il vettore X fXng
con valori campionari x fxng 2 IR1 e con la distribuzione di probabilita
su IR1 PX denita da
PX (B ) = P f! x(!) 2 B g
(2.1.2)
8B 2 B, l'algebra di Borel in IR1 denita come la minima -algebra che
contiene tutti i cilindri (cfr. Q4 cap. 8).
Osservazione
2.1.1: una volta denita la distribuzione di probabilita PX
1
in IR , lo spazio di probabilita f A P g puo in tutto e per tutto essere
sostituito da fIR1 B PX g, nche ci si limita a considerare il processo stocastico X o sue funzioni, riportandoci cos ad una interpretazione di X come
una generalizzazione di una variabile N -dimensionale X N , passando da IRN
45
a IR1. Naturalmente questa operazione fara restringere la nostra attenzione da L2 () a L2(X ) che e un sottospazio chiuso del precedente costituito
da tutte le v.c. con varianza nita, funzioni di X che sono appunto quelle
che ci interessano anzi come vedremo tra breve la nostra analisi, limitandosi
all'ambito lineare, si restringera ad un sottospazio assai piu piccolo di L2(X ).
Avendo dotato X della sua distribuzione PX in IR1 e del tutto naturale
denire l'operatore di media E per una Y = g(X ), ovvero
EX fY g =
Z
IR1
g(x)dPX (x) :
(2.1.3)
Con tale operatore si possono denire i momenti di X , ad esempio i momenti
del 1 ordine
E fXig = i
(2.1.4)
E fXiXk g = Cik (2.1.5)
o del 2 ordine
oppure anche la funzione caratteristica
g(t) = E feit+xg
(t+ = ftn n 2 Zg) :
(2.1.6)
Il vettore di IR1
= fn n 2 Zg
(2.1.7)
e detto media del processo X , mentre la matrice (o operatore, trattandosi di
una matrice 1-dimensionale)
C fCik (i k) 2 Z Zg
(2.1.8)
e detta matrice, o operatore, di covarianza del processo X .
Diamo qualche primo esempio di processo stocastico a parametro discreto.
46
Esempio 2.1.1: il primo e piu semplice esempio di processo stocastico e il
cosiddetto rumore bianco (in senso stretto) che corrisponde ad una successione fXn n 2 Zg di v.c. stocasticamente indipendenti ed identicamente
distribuite.
Di fatto quando n 2 Z + questo modello generalizza la variabile campionaria di un campione bernoulliano al caso in cui si facciano innite estrazioni
indipendenti da una stessa v.c. X .
In questo caso e chiaro che
E fXng = (2.1.9)
2
E fXn+k Xng = X k0 (2.1.10)
dunque la media e un vettore con le componenti costanti, di solito si assume
= 0, mentre l'operatore di covarianza e proporzionale all'identita.
Esempio 2.1.2: (processo di Wiener discreto). Dato un processo di rumore
bianco f"ng a media nulla e con varianza "2 costruiamo fXn n 2 Z +g tramite
le formule ricorsive
Xn+1 = Xn + "n+1
X0 = 0
(n 2 Z +) :
(2.1.11)
Quindi il senso di questo processo, detto di Wiener, e di essere un integrale
(accumulatore) di rumore bianco nel tempo.
Lo schema (2.1.11) puo essere risolto esplicitamente per Xn+1, dando
n
X
Xn+1 = "k+1 :
(2.1.12)
E fXn+1g = 0
E fXn+k Xng = n"2 k 0
(2.1.13)
(2.1.14)
k=0
Da qui si vede che
Si osservi che a causa della denizione (2.1.11) il processo di Wiener fXng
gode della proprieta di Markov
E fXn+1jXn Xn;1 : : :g = E fXn+1jXng :
(2.1.15)
47
Notiamo anche che per il teorema centrale della statistica ci si puo aspettare
che Xn tenda a distribuirsi normalmente pr n ! 1.
Esempio 2.1.3: (processo di Poisson discreto). Sia f"ng una successione di
v.c. indipendenti del tipo testa o croce
"n =
e si ponga
0
1
q p
n
X
Xn = "k
k=1
n = 1 2 : : :
(2.1.16)
n = 1 2 : : : (2.1.17)
dunque Xn e un contatore del numero di successi nel tempo (variabile) n.
Sara
E fXng = np
E fXn+k Xng = npq k 0
(2.1.18)
(2.1.19)
Si osservi che in questo esempio, al contrario dei primi due, le v.c. Xn hanno
un insieme di valori argomentali discreto la peculiarita di questo processo e
che tale insieme f0 1 : : : ng varia al variare del tempo n. Per questo motivo,
benche fXng goda della proprieta di Markov, il processo non costituisce una
catena di Markov.
Esempio 2.1.4: sia ! = U ;1=2 1=2] una v.c. uniformemente distribuita
su ;1=2 1=2], poniamo
xn(!) = sin !n
n = 1 2 : : : :
(2.1.20)
Il processo X corrispondente ha ovviamente media nulla
E fXng =
Z 1=2
;1=2
sin !n d! = 0
48
(2.1.21)
e covarianza
Cn+kn = E fXn+k Xng =
(2.1.22)
1
=
2
= 1
cos !k ; cos !(2n + k)]d! =
2 ;1=2
1
k=0
2
0
k = 2` > 0
=
(;1)` 1 ; (;1)n
k = 2` + 1 > 0
2`+1 2n+2`+1
Esempio 2.1.5: sia ancora ! = U ;1=2 1=2] come nell'esempio 2.1.4 e si
prenda
(2.1.23)
xn(!) = sin(n 2 + 2!) :
Z
8>
<
>: h
i
Il processo X = fXng ha media nulla
Z 1=2 E fX g =
sin n + 2! d! = 0
n
(2.1.24)
2
;1=2
e covarianza
Cn+kn = E fXn+k Xng =
(2.1.25)
1=2
= 1
cos k ; cos(n + k + 4!) d! =
2 ;1=2
2
2
`
(;1)
k = 2` 0
:
= 1 cos k =
2
2
0
k = 2` + 1 > 0
Esempio 2.1.6:
(processi normali). Ricordiamo che dato un qualsiasi vettore 2 IR1 ed un operatore C Cnm in IR1 denito positivo nel senso che
Z h 8<
:
3
8 2 IR1 +C =
) +C 0 i
X X mnCnm < +1
n
m
(2.1.26)
Notiamo esplicitamente che se ad esempio n m 2 Z + la condizione + C < +1
signica
3
+ C = NMlim!1
Xn XM Cnmnm < +1 n=0 m=0
la modica di questo limite doppio nel caso che n m 2 Z e ovvia.
49
esiste in IR1 una distribuzione di probabilita P \normale con media e
covarianza C ". La distribuzione P e normale nel senso che, supposto che il
parametro n vari in Z +,
8N 2 Z + X N fX0 X1 : : : XN g
e una v.c. normale con media N f0 1 : : : N g e con covarianza
CN fCnm 0 n m N g :
(2.1.27)
Il processo X le cui componenti sono solo le componenti di x, ovvero Xn =
xn(x), e il processo normale con media e covarianza C .
Questo schema ha grandi applicazioni quando si sappiano costruire modelli
di operatori C che soddisno la condizione di denita positivita (2.1.26)
ritorneremo piu in la su questo argomento.
In Fig. 2.1 rappresentiamo una realizzazione con n da 0 a 100 per ognuno
degli esempi proposti in particolare il caso (f ) corrisponde ad un processo
gaussiano con
n = 0 Cn+kn = e;jkj = 0 1 :
(2.1.28)
Naturalmente non e possibile creare un repertorio di esempi che siano rappresentativi di tutti i possibili processi stocastici, tuttavia e utile formulare
qualche osservazione in merito al comportamento piu o meno stazionario dei
diversi processi.
50
Fig. 2.1.a
Fig. 2.1.b
Con stazionario intendiamo che un sottocampione, ad esempio di numerosita
10, preso in diverse epoche lungo la realizzazione presenta una signicativa
similarita statistica con gli altri ad esempio ha circa la stessa media e la
stessa varianza.
Fig. 2.1.c
51
Fig. 2.1.d
Fig. 2.1.e
Fig. 2.1.f
Cos vediamo che nel caso (2.1.a), nonostante la realizzazione sia la piu irregolare, la regolarita statistica e massima, invece il caso (2.1.b) e chiaramente
non stazionario perche costituito da onde che si amplicano nel tempo, mentre (2.1.c) si allontana sistematicamente, cioe anche come media, dall'asse
52
dell'ascisse. Ancora i casi (2.1.e), (2.1.f) si presentano con un aspetto signicativamente stazionario con pero la dierenza che (2.1.e) sembra piu
regolarmente periodico di (2.1.f) questa proprieta sono legate al fatto che la
media sia costante e che la covarianza Cn+kn sia funzione della sola k e non
di n, quindi anche la varianza Cnn sia costante, ovvero che la correlazione
tra le variabili Xn+k ed Xn dipenda solo dalla loro distanza nel tempo k e
non dall'epoca n
E f(Xn+k ; )(Xn ; )g = Cn+kn = C (k) :
(2.1.29)
E anche importante notare che nel caso (2.1.e) la covarianza e puramente
perioda in k mentre nel caso (2.1.f) essa tende a zero quando k ! 1 questo
fatto determina dierenze salienti tra i due processi.
2.2 La descrizione hilbertiana dei processi discreti
L'obiettivo che ci proponiamo in questo paragrafo e di caratterizzare in modo
compiuto le famiglie di funzioni lineari del processo X che siano contenute
in L2(X ).
Conveniamo di usare per gli elementi di L2(X ) la notazione semplice
X 2 L2
k x k2= E fX 2g
2
X Y 2 L < X Y >= E fXY g senza particolari indici per la norma ed il prodotto scalare.
Per comodita facciamo l'ipotesi che
= E fX g = 0 cio che in ogni caso non riduce la generalita della discussione successiva.
Notiamo allora che secondo la convenzione fatta possiamo porre
< Xn Xm >= Cnm < X X + >= E fX X +g = C :
Cominciamo osservando che se
2 R0 IR1 , fk k 0 jkj > N g
53
(2.2.1)
(2.2.2)
esiste sempre in L2(X ) la v.c.
X = +X =
XN kXk 2 L2(X ) ;N
(2.2.3)
poniamo per denizione
H0 = Span fXk k 2 Zg = fX = +X 2 R0 g :
(2.2.4)
H0 e ovviamente un sottospazio lineare di L2(X ) chiamiamo HX (o H (X ))
la chiusura di H0 in L2(X )
HX = H0]L2(X ) :
(2.2.5)
Per prima cosa vogliamo caratterizzare l'insieme f 2 IR1 +X 2 HX g
porremo poi
(2.2.6)
H` fX 2 HX X = + X 2 IR1g :
cioe l'insieme delle variabili in HX che sono eettivamente funzioni lineari di
X.
Osservazione 2.2.1: notiamo n da ora che H` sara un sottospazio lineare
di HX ma non necessariamente un sottospazio chiuso. Anzi qualora H` fosse
chiuso, deve necessariamente valere
H` HX
poiche e sempre
H0 H` HX
ed H0 e per denizione denso in HX .
Vale il seguente Teorema:
54
(2.2.7)
Teorema 2.2.1: sia 2 IR1 tale che +X = Nlim
!1
e anche
0 +C = NMlim!1
viceversa sia
XN kXk 2 HX allora
k=;N
XN XM nmCnm < +1 ;N ;M
2 HC f 2 IR1 +C < +1g
(2.2.8)
(2.2.9)
allora 9 la v.c. X = + X 2 L2 (X ) e quindi X 2 HX .
Dunque essenzialmente il teorema aerma che H` e l'immagine attraverso
l'operatore lineare
U = X +X
(2.2.10)
di HC , denito come in (2.2.9).
Nota: per semplicita di scrittura ma senza perdere in generalita supponiamo
che n 2 Z + cos che le serie
+X = Nlim
!1
XN nXn +C
n=1
XN XM
lim
nm Cnm
NM !1
n=1 m=1
abbiamo solo l'estremo superiore variabile.
Inoltre a livello di notazione porremo, per ogni 2 IR1 dato,
(N )+ = f1 2 : : : N 0 0 : : :g (2.2.11)
il simbolo N , che riguarda una successione costruita su un preciso sso,
non va poi confuso con fN g che viceversa indica una qualsiasi successione
in IR1 di componenti fNk g.
Supponiamo dunque che sia tale che
N +
X = +X = Nlim
!1( ) X 2 HX 55
(2.2.12)
cio ha tre conseguenze:
8N k (N )+X k2= (N )+CN a2 < +1
(2.2.13)
8N M j(N )CM j = j < (N )+X X +M > j (2.2.14)
k (N )+X k k (M )+X k a2 < +1
8N > N" opportuno 8p > 0
=k (N +p)+X ; (N )+X k2k (N +p ; N )+X k2=
(2.2.15)
= (N +p ; N )+C (N +p ; N ) < "2 :
Ma allora, ssato " 8N M > N" e 8p q > 0
NX+p MX+q
N X
M
X
n=1 m=1 nmCnm ; n=1 m=1 nmCnm =
= j(N +p)+CM +q ; (N )+CM j =
j < (N +p)+X (M +q )+X > ; < (N )+X (M )+X > j j < (N +p ; N )+X (M +q )+X > j + j < (N )+X (M +q ; M )+X > j k (N +p ; N )+X k k (M +q )+X k + k (N )+X k k (M +q ; M )+X k
2a "
dove si e usata la diseguaglianza di Schwarz, oltre alle (2.2.13), (2.2.14),
(2.2.15) dunque esiste il limite (2.2.8) ovvero 2 HC .
Viceversa se 2 HC , esiste il limite
lim (N )+CM = +C (2.2.16)
NM !1
56
ma allora, dall'identita
k (N )+X ; (M )+X k2= (N )+CN + (M )+CM ;
; 2(N )+CM (2.2.17)
prendendo il limite per N ed M ! 1 ed usando la (2.2.16) si ha
lim k (N )+X ; (M )+X k2 = 2+C ; 2+C = 0 NM !1
cos che f(N )+X g e una successione di Cauchy e dunque 9X 2 HX tale che
X = +X 2 HX L2(X ).
Notiamo tra l'altro che HC e uno spazio lineare in quanto
2 HC ) +X +X 2 HX ) ( + )+X 2 HX )
) + 2 HC :
Nella dimostrazione del Teorema 2.2.1 abbiamo piu volte usato un'utile identita che segnaliamo sotto forma di Corollario.
Corollario 2.2.1: l'operatore lineare U : HC ! H` denito da (2.2.10) e
una isometria se in HC si introduce la seminorma 4
jj2C = +C :
(2.2.18)
Infatti se 2 HC e quindi X 2 H` e chiaramente
N + N
N +
2
jj2C = +C = Nlim
!1( ) C = Nlim
!1 k ( ) X k =
= k +X k2=k X k2 0 :
(2.2.19)
Dunque l'operatore C e sempre semipositivo.
Denizione 2.2.1: diciamo che l'operatore C e positivo, C > 0, se
2 HC C = 0 ) = 0 :
(2.2.20)
Ricordiamo che una seminorma ha le stesse proprieta di una norma senonch
e non e
detto che valga jjC = 0 ) = 0:
4
57
Si puo dimostrare che tale denizione e equivalente a
2 HC +C = 0 ) = 0 :
(2.2.21)
Notiamo che la (2.2.20) e consistente in quante se 2 HC , allora C 2 IR1
per cui ha senso porre C = 0. In eetti poiche 8k
k
k = fk`g = f0 : : : 0 1 0 : : :g+ 2 R0 HC
esiste nito 8k
cioe C 2 IR1. 5
+k C = (C)k Osservazione 2.2.2: quando le (2.2.20) o (2.2.21) sono soddisfatte, jjC
data dalla (2.2.18) diventa una vera norma. Inoltre HC diventa uno spazio
pre-Hilbertiano ponendo
( )C = +C (2.2.22)
la denizione (2.2.20) e coerente in quanto se 2 HC ) ( + ) ( ; ) 2
HC e quindi e denita
+C = 14 f( + )+C ( + ) ; ( ; )+C ( ; )g :
(2.2.23)
Osservazione 2.2.3: se C non e positiva il processo X sore di una patologia che d'ora in avanti escluderemo sempre, ovvero esiste un tempo n tale
che Xn sia una funzione lineare di fXk k 6= ng. Infatti se e tale che
6= 0 +C =k +X k2 = 0 9n n 6= 0 e quindi si puo porre
Xn = ; 1
X kXk n k6=n
(2.2.24)
(2.2.25)
La (2.2.21) garantisce che esiste l'operatore C ;1 , denito sul range di C , cos che
C = ) = C ;1 tale relazione pero non ci dice che C ;1 e esprimibile come una
matrice cio e vero solo se il range di C contiene R0 .
5
58
la serie a secondo membro essendo ancora ovviamente convergente. La
(2.2.25) ci dice che conoscendo Xk k 6= n per una certa realizzazione e
possibile predire quasi certamente il valore di Xn.
Poiche a noi interessa solo il caso in cui questa prevedibilita quasi certa non
e possibile, escluderemo sempre che possa valere la (2.2.24).
Notiamo anche che (2.2.25) e conseguenza del fatto che
(2.2.26)
Xn 2 Span fXk k 6= ng]HX questa patologia puo vericarsi anche in casi in cui C > 0, come vedremo
nel seguente controesempio, percio sara proprio la (2.2.26) che considereremo
come condizione che non si verichi mai.
Esempio 2.2.1: sia fn n 0g un processo di rumore bianco con varianza
unitaria poniamo
X0 = 0 Xk = 0 + k :
L'operatore di covarianza di X e
1 1 1 1 1 2 1 1 C = 1 1 2 1 cos che
X
0 + +1 k
k=1+1
X
C = (0 + k=1 k ) + 1 = 0
+1
X
(0 + k) + 2 : : : k=1
implica
0 +
+1
X
k = 0 ) 1 = 2 = : : : = 0 ) 0 = 0 ) = 0 :
k=1
59
Dunque C e positiva e tuttavia
Xo 2 Span fXk x 1g]HX
in quanto
X
X
N
N
1
1
lim
Xk = Nlim
X0 + N k = X0 :
N !1 N
!1
k=1
k=1
Da questo controesempio appare chiaro che occorrera cercare una condizione
piu forte su C per giungere a garantirci che tutti gli elementi di HX siano
esprimibili come funzioni lineari di X ora tuttavia sottolineiamo qual e la
conseguenza dell'ipotesi C > 0.
Teorema 2.2.2: se C > 0, l'operatore U fC = +X g tra HC ed H` e
biunivoco.
Infatti ! X = + X e univoco per l'unicita del limite di (N )+X viceversa
se
X = +X = U = 0
e anche, ricordando che il prodotto scalare e continuo rispetto ai propri
elementi,
0 =< X X >=< X X + >= C ) = 0 :
Dunque U e invertibile e percio biunivoco.
Corollario 2.2.2: se C > 0 e se HC e uno spazio di Hilbert, ovvero se tale
spazio e completo, allora
H` HX :
(2.2.27)
In eetti se U e un'isometria biunivoca ogni successione Yn = +n X di Cauchy in H` e generata da una successione fng di Cauchy in HC , che quindi
ammette limite in HC ma allora Y = +X e in H` ed e il limite di Yn in
quanto
k Y ; Yn k2= j ; njC ! 0 :
Percio H` e chiuso in HX e quindi coincide con esso per la Osservazione 2.2.1.
60
L'importanza di questo corollario sta nel fatto che esso aerma che la proprieta (2.2.27) puo essere vericata guardando solo la struttura della matrice
di covarianza C e lo spazio HC da essa derivato.
Cerchiamo ora di vedere cosa possiamo guadagnare introducendo la condizione piu restrittiva che (2.2.26) non sia mai vericata.
A tale scopo poniamo
H(n) Span fXk k ng] H (n) Span fXk k > ng]
H(;n) Span fXk k 6= ng] :
(2.2.28)
Inoltre ricordiamo la denizione di successione biortogonale associata (che
chiameremo b.o.a.) alla successione fXng.
Denizione 2.2.2: fng e una successione b.o.a. a fXng se
< j Xk >= jk :
(2.2.29)
Teorema 2.2.3: se il processo X non puo mai essere predetto quasi certa-
mente, cioe se
Xn 2= H(;n) 8n (2.2.30)
allora esiste la successione fng b.o.a. a fXng.
Notiamo che H(;n) e sottospazio chiuso di HX , percio se e vera la (2.2.30)
esistera il vettore X n, proiezione ortogonale di Xn su H(;n) e per di piu
Xn 6= X n )k Xn ; X n k> 0 )k Xn k>k X n k :
Poniamo allora
Xn ; X n
n = Xn ; X n 2 =
k Xn ; X n k k Xn k2 ; k X n k2 risulta
8m 6= n < n Xm >= 0
perche per denizione n ? H(;n) Xm 2 H(;n), mentre
2
< n Xn >= k Xn k ;2 < Xn X n2 > = 1 k Xn k ; k X n k
61
(2.2.31)
cos che fng e la successione cercata.
Notiamo che in base all'Osservazione 2.2.3 se esiste fng b.o.a. ad fXng,
l'operatore C non puo che essere positivo, cos che, come si e gia detto,
(2.2.30) e una condizione piu stringente di C > 0.
Purtroppo l'esistenza di fng non e ancora su!ciente per garantire la (2.2.27)
come il seguente controesempio, simile all'Esempio 2.2.1, dimostra.
Esempio 2.2.2: sia fn n 0g un rumore bianco con varianza unitaria
poniamo
Xn = 0 + n n 1 e chiaro che fn n 1g stessa e una successione b.o.a. a fXng. Tuttavia il
vettore 0, che sta in HX in quanto
X
N
1
0 = Nlim
!1 N n=1 Xn non puo essere in H`. Infatti se
+1
+1
+1
k 1 0 = k Xk =
k 0 + k k X
X ! X
k=1
k=1
k=1
allora e anche, preso il prodotto scalare con j ,
j =< 0 j >= 0 ) 0 = 0
il che e assurdo per la condizione k 0 k= 1.
Osservazione 2.2.4: se X 2 H` X = +X , allora fng b.o.a. a fXng
permette di costruire direttamente da X , cioe realizza l'operatore U ;1 .
Infatti, se ad esempio n 2 Z +,
< X k >= Nlim
!1 <
XN nXn n >= k n=0
(2.2.32)
se n 2 Z la dimostrazione e analoga.
Per questo motivo fng e anche chiamata successione dei coe!centi biortogonali associati a fXng.
62
Osservazione
2.2.5: quando risulti H` = HX si avra che 8X 2 HX 9 2
+
HC X = X .
In questo caso si dice che fXng X e una base di Schauder dello spazio di
Hilbert HX . Tuttavia e noto
che per una semplice base di Schauder la conP
vergenza della serie X = n nXn e condizionata all'ordine in cui vengono
presi gli Xn. Se si vuole che cio non avvenga occorre richiedere che fXng
sia una cosiddetta base di Riesz, ovvero che valga una delle seguenti due
condizioni, che sono in un certo senso simili alla condizione di convergenza
assoluta per una serie numerica:
P nXn 2 HX ) X jnjXn 2 HX P nXn 2 HX ) X "nnXn 2 HX q.c.
(2.2.33)
(2.2.34)
dove "n e una successione di 1 presi a caso ed in modo indipendente.
E facile vedere che la (2.2.34) implica la condizione equivalente
+C < +1 )
X 2 Cnn < +1 n
n
(2.2.35)
la condizione (2.2.35) e essenzialmente solo una condizione su C . Introduciamo una nozione di equivalenza tra due operatori C D positivi in IR1.
Denizione 2.2.3: dati C > 0 D > 0 diciamo che C e D sono equivalenti
tra loro, cio che indicheremo con C D, se
+D +C +D > 0 :
(2.2.36)
E facile vedere che (2.2.36) e una relazione di equivalenza in particolare il
caso = > 0 corrisponde proprio a C = D.
Poiche la relazione tra operatori positivi A B
AB)
+A +B 8 per cui 9+A e una relazione di ordine parziale, riportiamo la (2.2.36) anche nella forma
equivalente
D C D :
(2.2.37)
63
Lemma 2.2.1: se C D valgono le seguenti proprieta:
1) 2 HC , 2 HD
2) se fn g e fondamentale in HC lo e anche in HD e viceversa
3) HC e uno spazio di Hilbert se lo e HD e viceversa, inoltre C D anche
se (2.2.36) e vericata solo 8 2 R0 .
Le 1) e 2) sono immediate.
Se HC e di Hilbert, cioe completo, e fng 2 HC e fondamentale 9 2 HC
tale che j ; njC ! 0 ma allora 2 HD per la 1) e inoltre
j ; njD 1 j ; njC ! 0
cioe anche HD e completo e percio di Hilbert.
Inne se (2.2.36) vale 8 2 IR0 preso un qualunque 2 HD e j ; N jD ! 0
per il Teorema 2.2.1 ma allora e anche j ; N jC ! 0 per la (2.2.36) e quindi
la (2.2.36) stessa vale 8 2 HD . Lo stesso vale 8 2 HC :
Dunque essenzialmente il Lemma 2.2.1 aerma che HC ed HD sono insiemisticamente coincidenti e topologicamente equivalenti.
Lemma 2.2.2: se D e un operatore matriciale diagonale
Dnm = Dnnm Dn > 0 8n HD e sempre uno spazio di Hilbert.
In eetti in questo caso, posto
D1=2 = f Dnnmg
p
(2.2.38)
si vede che
2 HD +D < +1 , = D1=2 2 `2 + = +D < +1 :
Dunque D1=2 e una isometria invertibile (in quanto Dn > 0) tra HD ed `2 ma allora poiche `2 e uno spazio di Hilbert e percio chiuso lo e anche HD .
Con cio abbiamo dimostrato tutte le proprieta necessarie per trarre le conclusioni che raccogliamo nel seguente teorema:
64
Teorema 2.2.4: sia D l'operatore diagonale costruito con la diagonale prin-
cipale di C ,
Dnm = Cnnnm (2.2.39)
se C D valgono le seguenti proprieta:
1) HC e completo e dunque uno spazio di Hilbert,
2) H` HX e quindi
8X 2 HX 9 2 HC X = +X cos che fXng e una base di (Schauder) di HX ,
3) fXng e una base di Riesz di HX ,
4) 9fng b.o.a. a fXng e tale successione e completa in HX .
5) l'operatore C ;1 e un operatore matriciale in IR1.
I punti 1), 2) e 3) sono gia stati provati. Quanto al punto 4), che e poi
connesso con il concetto di regolarita del processo che vedremo poi, l'esistenza
di fng deriva dall'osservazione che un qualunque elemento di H(;n) puo
essere scritto come
X=
X kXk 2 H(;n) 2 HC k6=n
perche fXk k 6= ng e a sua volta una base di Riesz di H(;n).
Ma allora anche X n avra tale rappresentazione e quindi
k Xn ; X n k2 Cnn +
X 2 Ckk] k6=n
Cnn > 0 cioe
Xn 2= H(;n) 8n
65
k
(2.2.40)
come richiesto dal Teorema 2.2.3.
Inoltre
X 2 HX ) X = + X < X k >= 0 8k ) k = 0 8k
)=0)X=0
cioe fk g e completo in HX .
Passiamo ora al punto 5) dapprima supponiamo che C abbia la diagonale
identica a 1, cos che C diventa una matrice di correlazione
Cnn = 1 ) D = I HD = `2 C = R :
(2.2.41)
In questo caso la condizione C D diventa R I e quindi HR HD `2
come insieme. In primo luogo R trasforma `2 in se infatti
2 `2 HR jRj2 = +R2 = +R1=2 RR1=2 =
jR1=2 j`2 = +R = jj2R 2jj2`2 (2.2.42)
tra l'altro (2.2.42) dimostra che se n ! in HR allora Rn ! R in `2 ,
cioe R e un operatore continuo in `2 . Il range dell'operatore R e denso in `2 infatti, essendo R simmetrica
2 `2 +R = 0 8 2 HR `2 ) R = 0 ) = 0 :
Inoltre il range di R e anche chiuso in `2. Infatti sia n = Rn n ! in
`2 allora
jn ; m j2R = (n ; m )+(n ; m) jn ; m j`2 jn ; mj`2 1 jn ; m jRjn ; m j`2 cioe
jn ; m jR 1 jn ; mj` 2
cos che n e convergente ad un qualche limite 2 HR. Ma allora
= lim n = lim Rn = R 66
cioe appartiene al range di R che risulta chiuso. Pertanto il range di R deve
essere tutto `2 e quindi range fRg R0 cos che se k = fk`g esistono in
`2 i vettori
S k = R;1k = fSk`g ( Sk`2 < +1) X
`
ma allora se =
P kk 2 `2 (P 2k < +1) e = R, e anche
X
X
= k S ` = Sk`` k
`
cioe R;1 ha una rappresentazione come matrice.
Tra l'altro da Rk fRk`g 2 `2 8k ed S k = R;1 k = fSk`g 2 `2 8k,
discende che tanto la matrice R quanto R;1 = S hanno righe (colonne) in
`2 :
Inne per una C generale, soddisfacente C D, osserviamo che si puo porre
C = D1=2RD1=2
con R matrice di correlazione ma allora
C ;1 = D;1=2R;1 D;1=2
cos che l'operatore C ;1 e associato alla matrice
;1=2 SnmCmm
;1=2 :
(C ;1)nm = Cnn
(2.2.43)
Osservazione 2.2.6: supponiamo che
8n D Cnn =k Xn k2 D (2.2.44)
CD,CI
(2.2.45)
allora
67
e se la (2.2.45) e soddisfatto e anche HC `2 in questo caso C e detto
positivo in senso stretto.
In eetti se vale (2.2.44) e
D + +D D + ) D I cos che C D ) C I e viceversa poiche e una relazione di equivalenza.
Dunque col Teorema 2.2.4 giungiamo alla conclusione che la condizione C D, complementata magari dalla (2.2.44), ci permette di procedere agevolmente ad un calcolo lineare in HX mediante la rappresentazione di un qualunque
X come X = +X resta naturalmente aperta la questione di come si possa
vericare tale condizione esaminando solo la matrice C . Torneremo in modo
piu soddisfacente su queste questioni analizzando i cosiddetti processi stazionari qui ci limitiamo a dare una condizione su!ciente assai semplice anche
se ben lontana dall'essere necessaria.
Lemma 2.2.3: si ponga
k = sup p jCn+knj Cn+kn+kCnn
n
se
0<
allora C D con
=1;2
X k < 1
(2.2.47)
2
k
X k = 1 + 2 X k :
k
In eetti notiamo che, se ad esempio n 2 Z ,
+1
+
2
C =
nCnn + 2
Cn+knn+k n X
XX
n
k=1
n
k=1
n
+1 X
X Cnn2 + 2X
jCn+knjjn+k jjnj n
n
68
(2.2.46)
(2.2.48)
+1 X p
X Cnn2 + 2X
p
k
Cn+kn+kjn+k j Cnnjnj n
n
n
k=1
+1 sX
X 2 X
X
Cnnn + 2
n
= +D (1 + 2
Analogamente
+C
k=1
+1
k
Xk) :
n
Cn+kn+k2n+k (
n
Cnn2n) =
k=1
+1 p
X
X
p
2
Cnnn ; 2 k Cn+kn+kjnnj Cnn k=1
n X
+1 !
1 ; 2 k +D :
k=1
Come si vede questo Lemma e basato su una maggiorazione abbastanza grezza, ciononostante esso serve a provare che comunque se la correlazione tra
Xn+k ed Xn va a zero abbastanza rapidamente con k ! 1 e per ogni n,
allora la nostra condizione puo essere soddisfatta.
Concludiamo il paragrafo stabilendo alcune proprieta utili dello spazio HX
quando valga la condizione (2.2.45), C I .
Lemma 2.2.4: se C I allora
1) = C ;1 X C = C ;1
2) X e b.o.a. a 3) 8X 2 HX vale
X = X + < X >= + < X X > :
(2.2.49)
(;1) sono gli elementi della rappresentazione
In primo luogo notiamo che se Clm
matriciale di C ;1, chiamato c;k il vettore corrispondente alla colonna di posto
69
k in C ;1, si ha c;k 2 `2 HC cos che posto
k = (c;k )+X ) k 2 HX cioe , denito come
= C ;1X 2 HX e un vettore in HX . Inoltre
< X + >= C ;1 < X X + >= C ;1 C = I (2.2.50)
cioe e b.o.a. a X . Ancora
C`k = (c;` )+Cc;k = +` c;k = (C ;1)`k
ed il punto 1) e provato.
Quanto al punto 2) basta trasporre (2.2.50)
< X + >= I
(2.2.51)
per vedere che X e b.o.a. a .
Inne notiamo che se C I , anche C = C ;1 I e quindi
8X 2 HX 9 X = + =< X X > anche 3) e allora provato.
Lemma 2.2.5: sotto le condizioni del Teorema 2.2.4 e
U = U ;1 :
(2.2.52)
Ricordiamo che U ;1 HX ! HC e per denizione tale che 8X X +
U ;1 X = U ;1 (X + ) :
Poniamo = U X = U (X +) e proviamo che . Ricordiamo che per
denizione di U 8 2 HC
(U +X )C =< X U >=< X X + > ma allora
( )C = (U + X )C =< +X X + >= ( )C
e quindi :
70
2.3 La predizione lineare ottimale (caso nito)
Gli strumenti teorici che abbiamo sviluppato nel x2.2 permettono di formulare e risolvere in modo assai semplice il problema di predire linearmente una variabile Y 2 HX a partire dalla conoscenza di altre variabili
fY` ` = 1 : : : mg 2 HX , che consideriamo come osservabili. La teoria qui
presentata e essenzialmente la versione a temi discreti di quella sviluppata
negli anni '40 e '50 da A. N. Kolmogorov e N. Wiener.
Supponiamo dunque che siano soddisfatte le condizione del Teorema 2.2.4.
Siano poi:
Y` = a+` X ` = 1 : : : m a` 2 HC
(2.3.1)
delle variabili osservabili che possiamo anche considerare come funzionali
lineari del processo notiamo che considerando Y = fY`g come una v.c. in
IRm, la (2.3.1) puo essere scritta come
Y = AX
(2.3.2)
A = fa`k ` = 1 : : : m k 2 Zg :
Ricordiamo che tutte le variabili gia considerate sono per ipotesi a media
nulla, cioe E fY g = 0.
Inoltre la matrice di covarianza di Y e data da
CY Y = E fY Y +g = fE (Y`Yk )g = fa+` Cak g = ACA+
(2.3.3)
Sia ora Y un'altra variabile di HX che potra percio essere espressa come
funzione lineare di X ,
Y = a+X (2.3.4)
il problema che ci poniamo e di trovare la migliore approssimazione di Y
mediante una combinazione lineare del vettore delle osservabili Y . Notiamo
che anche per Y si ha E fY g = 0,
(2.3.5)
Y2 = E fY 2g = a+Ca
e inoltre
CY Y = E fY Y g = E fAX X +ag = ACa :
71
(2.3.6)
Osserviamo che tutte le operazioni che coinvolgono la matrice A sono corrette perche coinvolgono un numero nito di prodotti di vettori in HC con
l'operatore C .
Ora si puo anche notare che il problema posto in realta si riduce ad un problema nito-dimensionale di regressione lineare della variabile Y sulle fY`g
tale problema visto in HX e inquadrato nel sottospazio a m + 1 dimensioni
SpanfY Y`g e consiste nel cercare il minimo della distanza
kY
; +Y k2=k Y
= E f(Y
m
X
; `Y` k2=
`=1
+
2
; Y ) g = Y2 ; 2+CY Y
(2.3.7)
+ + CY Y = :
Tale minimo e raggiunto dallo stimatore 6
Yb = b Y = CY Y CY;1Y Y
+
(2.3.8)
che geometricamente rappresenta la proiezione ortogonale di Y su SpanfY` g
chiameremo Y lo stimatore di Wiener-Kolmogorov (W.K.) di Y .
L'errore quadratico medio associato a questo stimatore e dato da
b
E 2 = E f(Y ; Yb )2 g =k Y ; Yb k2 =
=k Y k2 ; k Yb k2 = Y2 ; CY Y CY;1Y CY Y :
(2.3.9)
Come si vede, data l'interpretazione della distanza in HX , il nostro stimatore
Y minimizza l'errore quadratico medio di stima tra tutti gli stimatori lineari
e dunque in questo senso e ottimale dal punto di vista statistico.
b
Osservazione 2.3.1: nella soluzione (2.3.8) (2.3.9) del problema di stima
posto, l'aspetto innito dimensionale compare solo nella costruzione di Y2 CY Y
e CY Y cioe nelle regole di propagazione della varianza-covarianza da C alle
nuove variabili Y Y` dunque il Teorema 2.2.4 qui ha lo scopo di assicurare
che qualunque siano Y Y` 2 HX esistono i corrispondenti vettori di coe!cienti a a` dai quali varianza e covarianza di Y Y possono essere calcolate
quando pero a a` siano gia noti e magari siano nito-dimensionali, cos che
6
Si osservi che e CY Y = CY+ Y .
72
le (2.3.2) (2.3.5) (2.3.6) siano sempre ammissibili. Il problema posto ammette sempre la rappresentazione (2.3.7). Quanto alla soluzione (2.3.8), (2.3.9)
questa esiste ed e unica chiaramente solo se CY Y e una matrice invertibile.
Notiamo che da (2.3.3) risulta
+CY Y =
X `ka+Ca = (X `a )+C (X ka )
`k
`
k
`
`
k
P
k
e tale espressione, per le ipotesi su C , puo essere nulla solo se `a` 0, cioe
se i funzionali che deniscono le osservabili Y` non sono tra loro linearmente
indipendenti. Pertanto facendo l'ipotesi che le osservabili siano sempre linearmente indipendenti la matrice (nita e simmetrica) CY Y risulta positiva e
quindi invertibile, cos che (2.3.8) e (2.3.9) hanno senso.
Osserviamo anche che se CY Y e positivo, lo e anche CY;1Y cos che dalla (2.3.9)
risulta
E 2 < Y2 (2.3.10)
b
il che rende signicativo usare lo stimatore di W.K., Y .
biunivoca U ,
Osservazione 2.3.2: poiche tra HC ed HX esiste un'isometria
con inverso U , il problema di minimizzare k Y ; +Y k ha un'immagine
isometrica in HC , cioe
U Y = a U (+ Y ) = U (A+)+X ] = A+
ja ; A+jC = min e questo un problema di minimi quadrati in HC con soluzione
= (ACA+);1ACa = CY;1Y CY Y
b
ovvero
Yb = UA+ b = (A+)+X = CY Y CY;1Y Y
Osservazione 2.3.3: quanto visto per la predizione di una singola variabile
Y puo essere facilmente generalizzato alla predizione di un vettore V , di
variabili in HX . Dunque ora l'informazione di covarianza di V e di crosscovarianza con le osservabili Y sara data dalle seguenti formule
V = BX (Vk = b+k X ) ) CV V = BCB + CV Y = BCA+ :
73
Per trovare lo stimatore ottimale di V , deniamo
Y = b+V (Y2 = b+ CV V b) CY Y = ACB +b = CY V b
b
ed applichiamo le formule gia viste per lo stimatore W.K., Y come vedremo
risultera
Y = b+ V
b
b
con Vb indipendente da b e con cio il Vb cos trovato sara uniformemente
ottimale.
Ora
Yb = CY Y CY;1Y Y = b+CV Y CY;1Y Y
da cui appare chiaro che
Vb = CV Y CY;1Y Y :
(2.3.11)
Notiamo anche che da
E 2 = Y2 ; CY Y CY;1Y CY Y =
= b+CV V b ; b+CV Y CY;1Y CY V b
appare pure chiaro che la matrice di covarianza degli errori di stima e data
da
E = E f(V ; Vb )(V ; Vb )+g =
= CV V ; CV Y CY;1Y CY V :
(2.3.12)
Osserviamo anche che un qualsiasi altro stimatore lineare V~ di V ha una
matrice di covarianza degli errori E~ piu grande della E data dalla (2.3.12).
Osservazione 2.3.4: supponiamo che X sia un processo normale allora
ogni variabile X 2 HX e normale perche limite in media quadratica di
variabili normali. In questo caso come e noto la variabile di regressione
E fY jY g e una funzione lineare di Y e quindi anche il nostro stimatore
W.K., Yb e ottimale in tutto L2(), cioe e la funzione di Y in L2() che
da luogo alla minima varianza dell'errore di stima.
74
Esempio 2.3.1: sia fXn n 2 Z + X0 = 0g il processo di Wiener descritto
nell'Esempio 2.1.2, cos che
E fXng = 0 E fXn+k Xng = n"2 supponiamo per semplicita che "2 = 1.
Supponiamo che si sia osservato il processo al tempo n = 3 ottenendo il
valore
X3 = 6 b
vogliamo trovare le predizioni ottimali Xn ed i loro e.q.m di stima.
Notiamo che
3
Cn3 = E fXnX3 g = n3 nn <
3
cos che
Xbn = Cn3C33;1 X3 =
Inoltre
E2 = C
n
;1
nn ; Cn3 C33 C3n =
2n
n<3
6 n3
n; n
n<3
n;3 n3
2
3
Si noti che giustamente E3 = 0.
In Fig. 2.3.1 sono riportate sia la curva delle predizioni fXng, che dell'errore
di predizione fEng.
b
75
Fig. 2.3.1
Xn = || En = ; ; ;.
Esempio 2.3.2: sia fXn n 2 Zg un processo a media nulla e con covarianza
; jk2j
E fXn+mXng = 4e
:
b
X;1 ;1 Y = X = 1 1
Si sia osservato il vettore
e si voglia stimare
Y = Xn
con il suo e.q.m. En.
Fig. 2.3.2
Xn = || En = ; ; ;.
b
Risulta
1
CY Y = 4 e;1
;e;1 e;1 C ;1 = 1 e2 1
1 Y Y 4 e2 ; 1 ;e;1 1
76
; jn j CY Y = 4 e; jn; j e
cos che
bY = Xcn = CY Y CY;1Y XX;1 1 = e2e;2 1 he; jn
inoltre
e2 ;jn+1j ;jn;1j
2
; jn
+1
2
1
2
j
+1
2
En = 4 ; 4 e2 ; 1 e
b
+e
; 2e
; e; jn
j
+1
2
j ; jn;1j ;1
+1
2
2
i
:
Stime Xn ed e.q.m. En sono rappresentati in Fig. 2.3.2.
Esempio 2.3.3: sia Xn n 2 Z un processo a media nulla e con varianza
2
Ck = e; k2 :
Si e osservato il funzionale del processo
Y = 13 (X;1 + X0 + X1) = 1
e si vuole stimare il vettore
X;1 V = X0 X1 b
e la matrice di covarianza E del vettore degli errori di stima, V ; V .
Si noti che
1
e;1=2 e;2
e;1=2
CV V = 4 e;1=2 1
e;2 e;1=2 1
CY Y = 49 3 + 4e;1=2 + 2e;2
1 + e;1=2 + e;2
4
CV Y = 3 1 + 2e;1=2
1 + e;1=2 + e;2
77
cos che
0:9173 Vb = CV Y = CY;Y1 = 1:1654 0:9173 1:8696
E = CV V ; CV Y CY;Y1 = CY Y ;0:2806
;1:5894
;0:2806 ;1:5894 0:5611 ;0:2806 ;0:2806 1:8696 l'ovvia simmetria della soluzione e dovuta al fatto che il funzionale d'osservazione e simmetrico rispetto all'origine n = 0.
Si noti anche che mentre la matrice
CVb Vb = CV Y CY Y CY V
e necessariamente singolare in quanto si sono stimati 3 funzionali (le componenti di V ) da una sola osservazione, al contrario la matrice E non risulta
singolare.
Osservazione 2.3.5: osserviamo che la soluzione al problema di dare la migliore stima lineare di un vettore stocastico Y , noto un altro vettore stocastico
V , fornita dalle (2.3.11) e (2.3.12), e in sostanza la soluzione di un problema
nito-dimensionale per la quale, una volta assunto
E fV g = 0 E fY g = 0, occorre conoscere solo le covarianze e cross-covarianze
CY Y CV Y = CY+ V CV V :
(2.3.13)
La connessione tra la teoria dei processi stocastici e le applicazioni di questo
paragrafo sta tutta nelle regole di propagazione.
Y = AX (Yn = a+n X an 2 HC )
V = BX (Vm = b+mX bm 2 HC )
)
8> CY Y = ACA+
><
>> CY V = ACB+
: CV V = BCB+
: (2.3.14)
Estendiamo allora il caso esaminato ad un problema che pur essendo simile alla predizione di funzionali di X da altri noti, ne dierisce in quanto
introduce un rumore nel modello d'osservazione.
78
Dunque la variabile Y delle osservabili sara legata al processo X dal modello
lineare
Y = AX + (Y` = a+` X + `)
(2.3.15)
con
E f g = 0 E f +g = C E fX +g = 0 (2.3.16)
(2.3.17)
, che rappresenta qui l'errore di osservazione di Y , e a media nulla e spesso
(ma non sempre) e un rumore bianco cos che C = 2 I inoltre per semplicita e assunto linearmente indipendente dal processo X , cos che vale la
(2.3.17).
Da (2.3.15), (2.3.16) e (2.3.17) si ricava
(2.3.18)
CY Y = ACA+ + C CY V = ACB + inoltre e ovviamente CV V = BCB + come gia nella (2.3.14).
Una volta specicata la (2.3.18) si trova direttamente come stimatore W.K.
di V ,
(2.3.19)
V = CV Y CY;1Y Y = (BCA+)(ACA+ + C );1 Y
b
con matrice degli errori di stima
E = C ; CV Y CY;1Y = CY V =
= BCB + ; BCA+ACA+ + C ];1 ACB + :
Queste formule quando siano applicate al problema particolare,
Y` = X` + ` ` = 1 2 : : : N
V` = X`
b
(2.3.20)
(2.3.21)
cioe alla ricerca delle stime ottimali X` di X` a partire da osservazioni con
noise, danno
bX` = XN C`k (C + C )(kj;1)Yj
kj =1
79
` = 1 2 : : : N
ovvero
Xb = C (N ) C (N ) + C ];1Y (2.3.22)
C (N ) = fC`k ` k = 1 2 : : : N g :
(2.3.23)
E = C (N ) ; C (N ) C (N ) + C ];1C (N ) :
(2.3.24)
dove
Inoltre risulta
Il problema in questo caso e noto come problema di ltraggio del noise e la
soluzione (2.3.22), (2.3.24) e nota come ltro ottimale di Wiener.
Osserviamo anche che quando C = 0, cioe quando non ci sia noise di
osservazione, risulta X = Y e E = 0, come e logico aspettarsi.
Osserviamo ancora che lo stesso schema, con opportune modiche della matrice di covarianza, vale anche quando i \tempi" d'osservazione ` non siano
regolarmente spaziati come in (2.3.21).
Inne notiamo che la (2.3.24) puo essere anche scritta come
E = C ; C C (N ) + C ];1 C (2.3.25)
b
formula che puo risultare computazionalmente piu semplice, in particolare
quando C = 2I .
Esempio 2.3.4: sia fXn n 2 Zg un processo a media nulla e con matrice
di covarianza
Cn+kn =
4 ; jk j
0
jk j 3 :
jk j > 3
Supponiamo che si siano osservati i valori di X;1 X1 con noise bianco,
= 1 e indipendente dagli X il modello d'osservazione ed i valori osservati
risultano
Y1 = X;1 + ;1 Y01 = 2 :
Y2 = X1 + 1 Y02 = 2
80
b
Si vuole la predizione W.K. di Xn Xn ed il suo errore quadratico medio En.
Per l'evidente simmetria del problema ci limiteremo a stimare per n 0. Si
noti che in questo caso V = Xn,
4
CY Y = 2
2 + 1 0 C ;1 = 1 5 ;2 Y Y
4
0 1
21 ;2 5
CV V = 4
n=
CY
V
0
=
3
3
1
2
4
2
1
3
3
0
2
4
0
1
5
0 0 cos che risulta
36
24
12
6
Xbn = 36
0
21
21
21
21
21
En = 1.1952 0.8729 1.4800 1.6762 1.9396 2.000
Come si vede dove la correlazione con i funzionali osservati va a 0, cioe per
n 5, in mancanza di ulteriore informazione, la predizione va pure a 0 e
l'errore di stima va a 2, cioe al valore quadratico medio del processo.
81
Fig. 2.3.3
Xn = || En = ; ; ; ; Y0 = .
b
2.4 Operatori lineari in uno spazio di Hilbert e loro
rappresentazione matriciale. Propagazione della
covarianza
Ricordiamo in primo luogo alcuni elementi di teoria degli operatori.
L'operatore lineare A in HX (cioe tale che AX = Y 2 HX 8X 2 HX ) e
limitato se
k AX k a k X k (2.4.1)
in questo caso naturalmente A e continuo in tutto HX ed inoltre si puo porre
k A k= sup kk XA kk = inf fa k AX k a k X kg :
X
A ammette inverso se
AX = 0 ) X = 0 82
(2.4.2)
(2.4.3)
inoltre A;1 e limitato se e solo se
k AX k b;1 k X k
(2.4.4)
con b opportuna costante maggiore di zero. In eetti se Y = AX
X = A;1Y , la (2.4.4) implica che
k X k=k A;1Y k b k Y k (2.4.5)
cos che
k A;1 k= b :
(2.4.6)
Sia ora X fXng una base da cui HX e generato ad ogni operatore A
lineare limitato possiamo associare la successione
Y = fYng AX fAXng (2.4.7)
poiche X e una base in HX si ha per un opportuno vettore an,
Yn = a+n X = (AX )n (2.4.8)
cioe a+n e la riga n-esima dia una matrice innito-dimensionale A tale per cui
Y = AX AX
(2.4.9)
Osservazione 2.4.1: se X e una base di Riesz e C I a+n risulta essere un
vettore in `2 cos che le righe di A sono tutte in `2.
La conoscenza di A e in un certo senso equivalente a quello di A in quanto
ci permette di ricostruire come A agisce su un elemento qualunque di HX infatti se
X = +X 2 HX ( 2 `2 )
allora
AX = +AX = +AX =
= (A+)+X ovvero
AX = Y X = +X Y = +X ) A+ = :
83
(2.4.10)
Lemma 2.4.1: se A e limitato in HX A+ e limitato in HC .
Essendo A limitato per ipotesi, e pure
k A2 k= jj2C = jA+j2C a2 k X k= a2jj2C (2.4.11)
cos che A+ e un operatore limitato in HC :
Osservazione 2.4.2: si noti che vale anche il viceversa del Lemma 2.4.1,
ovvero se A+ e un operatore limitato in HC , allora
X = + X Y = (A+)+X AX = Y
denisce un operatore limitato in HX , in quanto
k AX k= jA+jC ajjC = a k X k
Vale dunque il seguente Teorema:
Teorema 2.4.1: la corrispondenza
A , A+
e una rappresentazione algebrica, isometrica rispetto alle norme uniformi di
A ed A+ rispettivamente in HX e in HC .
In eetti se A B sono limitati in HX e A+ B + sono le rispettive rappresentazioni matriciali, X = +X
BAX = B(A+ )+X = (B + A+)+X
cioe
BA , B +A+ :
(2.4.12)
+ jC
k
A
X
k
j
A
k A k= sup k X k = sup jj = jA+j
X
C
(2.4.13)
Inoltre, X = +X
84
Osservazione 2.4.3: come si e visto dal Lemma 2.4.1 se A e un operatore
limitato in HX A+ e limitato in HC in particolare posto
e+k A+ = (Aek )+ = 'k () (2.4.14)
e chiaro che 'k e un funzionale lineare e limitato su HC . Se ora supponiamo
che C I , si ha che HC `2 e quindi 'k ha come rappresentazione un
prodotto scalare in `2, per il Teorema di Riesz, 'k () = b+k (bk 2 `2), che
confrontata con la (2.4.14) mostra che Aek = colk A 2 `2.
Questa osservazione completa l'Osservazione 2.4.1 sulla struttura di A. notiamo anche che vale il seguente Lemma:
Lemma 2.4.2: se A+ e limitato in HC e se C I , cos che HC `2 , allora
anche A e limitato in HC .
Poiche HC `2 la verica della limitatezza di A puo essere fatta direttamente
in `2. Basta osservare che
jAj`2 = sup (A)+ = sup +A+ jA+jjj`2
(2.4.15)
jj=1
jj=1
Avendo concluso questa parte generale sulla rappresentazione matriciale degli
operatori limitati, possiamo ora passare ai due risultati principali del paragrafo. Intanto notiamo che ogni operatore limitato A genera dal processo X
un altro processo
(2.4.16)
Y = AX = AX come e ovvio dalla (2.4.16) Y 2 HX . Di questo nuovo processo ci interessa
ora capire come sia fatto l'operatore di covarianza e se la nuova successione
fYng possa essere usata come una base, magari una base di Riesz, in HX .
Teorema 2.4.2: (propagazione della covarianza). Sia A un operatore lineare limitato in HX e sia A(A+ ) la sua rappresentazione matriciale l'operatore
matriciale
CY Y = ACA+
(2.4.17)
rappresenta la covarianza di Y .
85
Basta vericare che
CYn Ym = E fYnYmg = E fa+n XX +amg = a+n Cam il che implica la (2.4.17).
Teorema 2.4.3: se X e una base di Riesz in HX e se Y = AX con A
lineare limitato ed A;1 e pure limitato in HX allora Y e una base di Riesz
in HX .
Rammentiamo che C D per ipotesi. Inoltre, essendo A limitato
k +Y k2= +CY Y =k A+X k2 k k +X k2= k+C
ed anche, essendo A;1 limitato,
k +Y k2 = +CY Y =k A+X k2 h k +X k2= h+C :
Ma allora
CY Y C D
ed Y e una base di Riesz per il Teorema 2.2.4
2.5 Operatori causali e processi con lo stesso ordine
temporale
In questo paragrafo considereremo l'indice k di Xk come un tempo discreto.
Sia A un operatore lineare e limitato in HX ed Y = AX .
Denizione 2.5.1: diciamo che A genera una trasformazione causale di X
se vale
AHn Hn 8n :
(2.5.1)
Notiamo che la (2.5.1) essenzialmente ci dice che conoscendo il processo X
no al tempo n si conosce anche Y no allo stesso tempo, infatti Yk =
AXk k n, appartiene anche lui ad Hn e quindi e esprimibile come
combinazione lineare degli Xi i n che sono noti.
86
Lemma 2.5.1: se A e il rappresentante matriciale di un operatore A casuale, allora A e una matrice triangolare bassa, ovvero
8m > n :
anm = 0
(2.5.2)
Se
Yn = AXn 2 Hn (2.5.3)
allora nella rappresentazione matriciale
Yn
deve anche essere
= a+X
n
=
+1
X
anmXm
m=;1
anm = 0 8m > n
se no la (2.5.3) non puo essere vericata.
Esempio 2.5.1: sia B l'operatore, detto backward, denito da
BXn = Xn;1 (2.5.4)
e chiaro che per B vale
BHn = Hn;1 Hn
e quindi B e causale.
Il rappresentante matriciale B di B ha come elementi
bnk = nk+1
ovvero ha una diagonale di 1 sulla prima sottodiagonale principale
87
(2.5.5)
...
i
...
0
i ::: ::: 0
B
1 0
1 0
1 0
1 0
1 ...
...
come risulta dal fatto che
b+n X =
(2.5.6)
X nk+1Xk = Xn;1 :
k
Osservazione 2.5.1: supponiamo che C I , cioe I C + I allora e
chiaro che B e un operatore limitato in quanto, posto X = X
X
X
k BX k2 = k n+1Xn k2= n+1m+1 Cnm X
2n+1 +C = k X k2 :
Inoltre anche B;1 sara un operatore limitato in quanto
X
k BX k2 =
n+1 m+1Cnm + C = k X k2 :
X 2 n
Osservazione 2.5.2: l'operatore B;1 = F , detto anche forward, e l'opera-
tore che fa scorrere in avanti il tempo del processo X , ovvero
F Xn = Xn+1
ed ha come rappresentante matriciale
88
(2.5.7)
i
...
0 1
0
i ::: ::: 0 1
F ffnk g = fn+1k g =
0 1
(2.5.8)
0 1
0
0 1
0 ...
...
come appare evidente F non e un operatore causale (anzi si potrebbe dire
che F e anti-causale).
Notiamo anche che gli operatori B ed F realizzano tutta l'evoluzione del
processo X a partire da un singolo elemento, ad esempio da X0 , essendo
Xn = B;nX0 = F nX0 :
(2.5.9)
...
Esempio 2.5.2: sia dato l'operatore
A = I ; aB (2.5.10)
detto operatore autoregressivo di ordine 1 A e un operatore limitato causale
ed inoltre se I C I e se
r
jaj < (2.5.11)
anche A;1 e un operatore limitato casuale. Infatti da (2.5.10) si vede che
AXn = Xn ; aXn+1
il che prova immediatamente che vale la (2.5.5), ovvero che A e causale. Il
rappresentante matriciale di A e
89
...
i
1
i ::: :::
A
...
1
;a
0
1
;a
0
1
;a
1
;a
1
... ...
ed e eettivamente una matrice triangolare bassa. Inoltre vale, usando i
risultati dell'Esempio 2.5.1,
r !
r !
k AX kk X k +jaj k BX k 1 + jaj k X k ovvero A e limitato. Ancora risulta
k AX kk X k ;jaj k BX k 1 ; jaj k X k
che, per la (2.4.4), dimostra che quando la (2.5.11) e soddisfatta A;1 e un
operatore limitato. Quanto alla causalita di A;1, notiamo in primo luogo
che la condizione (2.5.11) garantisce che
r
k aB k= jaj k B k jaj < 1 ne segue che vale la famosa espansione in serie di Neuman
+1
;
1
;
1
A = (I ; aB ) = ak Bk X
k=0
(2.5.12)
la serie essendo convergente (nella norma uniforme degli operatori) in quanto
k
n+p
X
ak Bk k
k=n+1
k=2
n+p
X
k
jaj
k=n+1
90
r !n+1
jaj q
1
1 ; jaj
Corrispondentemente il rappresentante di A;1 sara
i
. . . ...
i : : : ... 1
... a 1
+1
. . . a2 a 1
A;1 = ak B k =
k=0
. . . a3 a2 a 1
. . . a3 a2 a
. . . a3 a2
. . . a3
...
;! 0 8p :
n!1
0
X
1
a
a2
a3
...
1
a 1
a2 a 1
... ... ... ...
che mostra che anche A;1 e un operatore causale.
Operatori di tipo autoregressivo ed altri saranno studiati in piena generalita
nel prossimo capitolo sui processi stazionari.
Si puo notare che nei due esempi presentati il comportamento dell'operatore
inverso e diorme nel caso dell'Esempio 2.5.1, B;1 non e causale, mentre per
l'Esempio 2.5.2 A;1 e causale. La situazione e messa in chiaro dal seguente
Lemma:
Lemma 2.5.2: se l'operatore A istituisce una corrispondenza biunivoca di
Hn in se per ogni n, allora A;1, che certamente esiste ed e limitato, e pure
causale.
Il Lemma e pressoche tautologico in quanto se A e biunivoca Hn $ Hn,
allora
A;1Hn Hn
91
e percio A;1 e causale.
In eetti ritornando ai due esempi precedenti appare chiaro che
BHn Hn;1
e quindi B;1 F non e causale, mentre
+1
;
1
A = ak B k : Hn $ Hn
X
k=0
ed A;1 e causale.
Consideriamo ora un altro problema partendo da un processo X fXng
generiamo Y fYng mediante una trasformazione lineare. La questione
e: possiamo ritenere che il parametro n per Y abbia lo stesso signicato di
tempo che per X , ovvero l'ordine temporale di Y e lo stesso di X ?
Per rispondere a questa domanda possiamo pensare di usare gli operatori B
od F che generano l'evoluzione temporale di X . Notiamo che dalle denizioni
BXn = Xn;1 F Xn = Xn+1 appare chiaro che B F sono deniti specicamente in relazione ad X cos
che si potra anche scrivere B BX F F X .
Il nuovo processo Y avra anch'esso i propri operatori di evoluzione temporale
BY F Y la questione e se essi coincidono con quelli di X , ovvero se
B BX BY e F F X F Y
(2.5.13)
cos che si possa aermare anche che
BYn = Yn;1 F Yn = Yn+1 :
Denizione 2.5.2: diciamo che X e Y hanno lo stesso ordine (ovvero la
stessa cadenza) temporale se i rispettivi operatori di traslazione temporale
soddisfano la (2.5.13).
Di certo la (2.5.13) non e sempre vera come mostra il seguente controesempio.
92
Esempio 2.5.3: sia X un processo con operatore di backward B BX e sia
A la trasformazione lineare generata dalla matrice
i
...
i ::: 1
0
...
...
A=
1 ...
0 ::: ::: ::: 0
1 ::: ::: ::: 1
0
ovvero
1
...
... 0
...
1
0
1
1
...
Yk = Xk k 6= 0 1
Y0 = X1
Y1 = X0 Allora e chiaro da BY 6= B infatti
BY Y0 = Y;1
per denizione, mentre
BY0 = BX1 = X0 = Y1 6= Y;1 :
Alla domanda di quando X e Y abbiano lo stesso ordine temporale, ovvero
sia vericata la (2.5.13), risponde il seguente teorema:
Teorema 2.5.1: sia X una base di Riesz in HX e sia
Y = AX = AX
(2.5.14)
Y ha la stessa cadenza temporale di X se e solo se A ha una struttura di
Toeplitz, ovvero
A fank g fan;k g 93
(2.5.15)
ovvero la (2.5.14) e un'operazione di convoluzione
Yn =
X an;kXk
(2.5.16)
k
Se vale la (2.5.16), posto B BX , si ha
BYn =
X an;kBXk = X an;kXk;1 = X an;1;`X` Yn;1 k
k
percio e anche B BY .
Viceversa se
`
X ankXk = X ankXk;1 =
Xkan`+1X` Ynk;1 = X an;1`X`
BYn = B
=
`
`
allora, essendo fXng una base di Riesz, deve pure essere
an`+1 = an;1` cioe A e costante lungo le diagonali parallele alla diagonale principale, ovvero
ha una struttura di Toeplitz.
Corollario 2.5.1: supponiamo che A abbia un inverso limitato D A;1
allora anche la matrice D A;1 ha necessariamente la struttura di Toeplitz.
Infatti in tal caso e
X = DY
ed e contemporaneamente BY BX cos che D deve essere della forma
D fdn;k g per il Teorema 2.5.1.
Osservazione 2.5.3: se X e Y sono basi di Riesz allora fan;k g fdk;j g
2
devono essere vettori in ` ovvero
X a2 < +1 X d2 < +1 :
k
k
k
94
k
(2.5.17)
Quindi la condizione A D I , ovvero
X an;kdk;j = nj
k
(2.5.18)
puo essere studiata con un opportuno strumento come la trasformata di
Fourier.
In eetti moltiplicando la (2.5.17) per e;i2
jt e sommando su j si trova 7
X an;k X dk;j e;i2
jt X an;ke;i2
kt Xk d`ei2
ltj e;i2
nt X amei2
mt X d`ei2
lt `
X` e;i2
jtnj e;i2
ntm j
questa identita ci dice che le funzioni
a(t) =
X akei2
kt d(t) = X dkei2
kt che certamente sono in L2 (0,1) in conseguenza della (2.5.17), devono essere
tali che
a(t) d(t) 1 t 2 0 1] :
(2.5.19)
La (2.5.19) costituisce uno strumento sia teorico che pratico per lo studio di
D. Infatti la (2.5.19) ci dice che A;1 sara un operatore limitato se
d(t) a(t)];1
(2.5.20)
e una funzione in L2(0 1), cio che si verica ad esempio se
ja(t)j > 0 7
Lo scambio della somma e reso lecito dalle condizioni fang fdng 2 `2 .
95
inoltre quando tale condizione sia soddisfatta i coe!cienti dk che permettono
di costruire D possono essere ricavati anche numericamente come coe!cienti
di Fourier della a;1 (t) ovvero da
dk =
Z 1 ;i2
kt
0
e
a(t)];1dt :
(2.5.21)
Osservazione 2.5.4: quando A e contemporaneamente causale e tale da
mantenere l'ordine temporale, devono valere contemporaneamente le relazioni
ank = an;k ank = 0 k > n cos che si ha
n
+1
X
X
Yn =
an;k = Xk = ak Xn;k :
k=;1
k=0
(2.5.22)
2.6 Innovazione processi regolari decomposizione di
Cholesky
Associato ad un processo X fXng ed al tempo n con il suo naturale senso
di scorrimento deniamo un nuovo processo f"ng " detto innovazione di
X.
Denizione 2.6.1: supponiamo che
Xn 2= H(n;1) 8n
(2.6.1)
e poniamo
Xbn = Pn;1Xn
En =k Xn ; Xbn k (proiezione ortogonale su H(n;1) )
osservando che risulta sempre En 6= 0 per la (2.6.1) il processo f"ng e allora
denito da
b
"n = Xn E; Xn :
n
96
(2.6.2)
Notiamo che in sostanza "n e il vettore che denisce il complemento ortogonale di H(n;1) in H(n) ne segue che f"ng e una successione O.N. in quanto
se m 6= n, ad esempio m < n, "n ? H(n;1) H(m) mentre "m 2 H(m) .
Ci si puo chiedere se f"ng oltre ad essere O.N. in HX sia anche completa lo
studio di questa questione ha portato alla denizione di processo regolare.
Denizione 2.6.2: il processo fXng X e regolare se
\Hn = H :
n
(2.6.3)
A riguardo vale il seguente Lemma.
Lemma 2.6.1: se X non e regolare, allora H e temporalmente invariante,
ovvero
\
B H H :
\
\
(2.6.4)
Se X 2 H = Hn allora BX 2 BHn Hn;1 H .
n
n
n
Si noti anche che H , come intersezione di sottospazi chiusi e a sua volta un
sottospazio chiuso di HX .
Possiamo ora provare il teorema fondamentale sul problema della completezza.
Teorema 2.6.1: per HX vale la decomposizione in spazi complementari ortogonali
( HX = H Spanf"ng]
H ? Spanf"ng] :
(2.6.5)
Poiche HX = UN H(N ) ] si puo dimostrare il Teorema provando che 8N
( H(N ) = H Spanf"n n N g]
H ? Spanf"n n N g] :
97
A sua volta per vedere cio basta provare che
a) h 2 H )< h "n >= 0 8n N
b) h 2 H(N ) < h "n >= 0 8n N ) h 2 H .
a) h 2 H ) h 2 H(m) 8m dunque ssato m h 2 H(m;1) )
)< h "m >= 0 percio h ? Spanf"n n N g],
b) in primo luogo si noti che essendo H(N ) una successione crescente vale
n
N H(N ) = n H(n) = H
ora se h 2 H(N ) < h "n >= 0 8n N , allora
< h "N >= 0 ) h 2 H(N ;1) ma e anche < h "N ;1 >= 0 ) h 2 H(N ;2) e
cos via percio
T
T
h2
\ H(n) = H :
n
N
Corollario 2.6.1: il processo " f"ng costituisce una base ortonormale e
completa in HX se e solo se X e regolare.
Come sempre nei paragra precedenti, anche qui troviamo che se vale la
condizione che fXng sia una base di Riesz in HX , allora la situazione si
semplica.
Teorema 2.6.2: se X fXng e una base di Riesz in HX , ovvero se C D
(oppure addirittura C I ), allora " f"ng e una successione ortonormale
completa in HX ed il processo X e regolare.
Ricordiamo che
H(;n) = H(n;1) H (n+1) HX = H(;n) n]
ove n] e lo spazio monodimensionale generato da n che a sua volta e
ortogonale ad H(;n).
Ricordiamo anche che per il Teorema 2.2.4 se C D fng e una base di
Riesz, completa in HX . Allora
\
fX 2 H(;n) 8ng fX 2 H(;n)g )< X n >= 0 8n ) X = 0 n
98
\ H(;n) = :
ovvero e
n
Ma in questo caso risulta
H =
\ H(n;1) \ H(;n) n
n
cioe X e regolare ed f"g e completa per il Corollario al Teorema 2.6.1.
Osservazione 2.6.1: se C I anche il processo ottenuto da X invertendo
il tempo e regolare in quanto
H = H (n) \
n
\ H(;n) = n
e quindi anche la successione dell'innovazione \all'indietro" risulta ortonormale e completa.
Osservazione 2.6.2: per costruzione (cfr. (2.6.2)) appare ovvio che
Spanf"n n N g 2 H(N )
cos che, se C D(C I ), per il Teorema 2.6.2 e pure
Spanf"n n 2 N g] H(N ) :
(2.6.6)
Ma allora 8n si potra porre
n
X
Xn =
Mnk "k k=;1
essendo Xn ? f"n+1 "n+2 : : :g.
La (2.6.7) si scrive in forma matriciale
X = M"
(2.6.7)
(2.6.8)
con M triangolare bassa e dunque rappresentante di un operatore causale
M, denito dalla relazione
M"n = Xn
(2.6.9)
99
Teorema 2.6.3: l'operatore causale M con rappresentante M realizza la
decomposizione di Cholesky della matrice di covarianza C del processo X ,
ovvero
C = MM +
(2.6.10)
con M triangolare bassa.
Basta osservare che C" " I ed applicare la propagazione della covarianza a
(2.6.8).
Esempio 2.6.1: sia fXn n 1g un processo con covarianza
1 1 1 1 :::
2 2 2 ::: C
3 3 :::
4 :::
la decomposizione di C come in (2.6.10) e operata mediante la matrice M
1
1 1
0
C 1 1 1
... ... ... . . .
corrispondente a
n
Xn = "k :
X
k=1
Si osservi che in questo caso M ;1 = A puo essere trovata esplicitamente e
risulta
1
;1 1
0
A = M ;1 = 0 ;1 .1 . 0 0 .. ..
... ...
con questa matrice si puo invertire la (2.6.8) e trovare che
" = AX "n = Xn ; Xn;1 100
che costituisce la forma cosiddetta autoregressiva del processo X .
Esempio 2.6.2: sia fXng un processo con covarianza
... ... ...
1 a a2 : : :
C = 1;1a2
1 a a2 : : :
2
1 a a :::
... ... ...
si noti che C ha struttura di Toeplitz.
E facile vericare direttamente che C = MM + con M data da
... 0
... 1 0
+1
..
M= .. a 1 0
= ak B k
. . a2 a 1 0
k=0
3
2
a a a 1 0
... ... ... ...
ovvero
+1
Xn = ak "n;k :
X
X
k=0
Anche in questo caso M puo essere invertita dando luogo alla forma regressiva
" = AX
"n = Xn ; aXn;1
corrispondente a
...
... 1
0
;
1
A=M =
;a 1
= I ; aB .
;a 1
0
;a 1
... ...
101
Esempio 2.6.3: sia fXng un processo con covarianza
C=
... ...
. . . 1 + a2 ;a
0
;a 1 + a2 ;a
2
;a 1 + a ;a
... ... ...
0
e facile vericare che in questo caso
...
... 1
0
M=
;a 1
= I ; aB
;a 1
... ...
0
. .
.
..
A = M ;1 = . . .
.
mentre risulta
0
1
a
a2
a3
0
1
a
a2
...
0
1
a
...
0
1
...
+1
X k k
= a B :
k=0
0 . . . Si noti che essendo C una matrice con banda nita di ampiezza 1, altrettanto succede ad M , confermando cos questa regola della decomposizione di
Cholesky valida in dimensione nita.
2.7 Il problema della predizione lineare ottimale caso
innito
Riprendiamo qui la trattazione del problema visto nel x2.3, generalizzato in
questo caso all'ipotesi che si conoscano inniti valori del processo X , per
tutti i tempi m n, e che si voglia predire il processo stesso al tempo n + k.
102
Da un punto di vista astratto lo stimatore lineare e facilmente determinabile
in eetti se chiamiamo
b
(Xn+k )n = PnXn+k
(2.7.1)
con Pn proiettore ortogonale su Hn, il principio di Wiener-Kolmogorov di minimizzazione della distanza tra Xn+k , che dobbiamo predire, ed una funzione
lineare delle osservabili, il predittore,
bXn+k = Xn mXm (Xbn+k 2 Hn)
m=;1
ha come soluzione precisamente
Xbn+k = (Xbn+k )n :
(2.7.2)
Se poi teniamo conto che e anche
Hn SpanfXm m ng] Spanf"m m ng] (2.7.3)
e che f"mg e O.N.C., si vede che il risultato (2.7.2) puo essere posto sotto la
forma del Lemma seguente:
Lemma 2.7.1: il miglior predittore lineare di Xn+k secondo il criterio di
Wiener-Kolmogorov, basato sulla conoscenza di fXm m ng e dato da
n
X
b
(Xn+k )n =
Mn+km"m (2.7.4)
m=;1
inoltre l'errore quadratico medio di stima En2+kn e dato da
b
En2+kn =k Xn+k ; (Xn+k )n k2 =
n+k
X
M2
m=n+1
n+km
In eetti e chiaro per quanto detto che
n
X
b
(Xn+k )n =
m=;1
< "m Xn+k > "m 103
:
(2.7.5)
che congiuntamente alla relazione
Xn+k =
n+k
Xn Mn+km"m + X
Mn+kmm"m m=;1
m=n+1
(2.7.6)
tenendo conto dell'ortonormalita degli "m prova tanto la (2.7.4) che la (2.7.5)
Naturalmente la (2.7.4) ci ore una soluzione sensata solo nella misura in cui
si sia capaci di calcolare "m m n, dati Xm m n.
Allo scopo di risolvere il problema proviamo il seguente Lemma sull'operatore
M.
Lemma 2.7.2: sia C I , allora sia M che M;1 = A sono operatori
limitati in HX e quindi ammettono rappresentanti matriciali M M ;1 = A
inoltre A e causale, cioe A e triangolare bassa.
Sia X = +" risulta
MX = +M" = +X = +M" = (M + )+" cos che ricordando che " e O.N.C.,
k MX k2HX = +(MM + ) = +C + =k X k2HX ;
(2.7.7)
dove a b signica che ab e una quantia positiva limitata sia superiormente
che inferiormente. La (2.7.7) dimostra che M e M;1 sono limitati. Inoltre,
ricordando la (2.7.3), si vede che M crea una corrispondenza biunivoca di
Hn in se stesso e quindi per il Lemma 2.5.2 M;1 e causale, cioe M ;1 e
triangolare bassa.
In conseguenza di questo lemma si puo porre
" = M ;1 X = AX
(2.7.8)
ovvero
m
X
"m =
Am Xj :
j =;1
104
(2.7.9)
Usando questa soluzione nella (2.7.4) ed invertendo le sommatorie troviamo
la forma esplicita dello stimatore ottimale
(X n+k
#
n "X
n
X
)n =
Mn+kmAmj Xj :
j =;1 m=j
(2.7.10)
Si noti che nella (2.7.10) risulta sempre j n cos che i coe!cienti in parentesi quadra sono ben diversi da n+kj , che risulterebbe dal prodotto di una
intera riga di M per una intera colonna di A.
In ogni caso con le (2.7.10), (2.7.5) il problema della predizione lineare e
risolto a partire da X mediante il calcolo di M e di A = M ;1 .
Riprendiamo a questo proposito gli esempi visti nel x2.6.
Esempio 2.7.1: sia X come nell'Esempio 2.6.1 e si cerchi la predizione di
X3 dati X1 X2. Dalla (2.7.10) risulta
b
(X3) = (M31 A11 + M32 A21 )X1 + (M32 A22 )X2 X2 si osservi anche che
b
(Xm)2 = X2
per m > 2 :
Lo stesso risultato poteva immediatemente essre ricavato dalla forma autoregressiva
X3 = X2 + "3
da cui appare chiaro che
b
(X3 )2 = X2 E322 = 1 :
Esempio 2.7.2: supposto X come nell'Esempio 2.6.2, cerchiamo (Xbn+1)n.
Notiamo che
Mn+1m Anm = a 1 = a
mentre
Mn+1n;1An;1n;1 + Mn+1nAn;1n = a2 1 + a(;a) = 0
105
e cos via per tutti i j < n ; 1.
Percio
(Xn+1)n = aXn
b
ed inoltre
En2+1n = 1
Di nuovo la stessa conclusione poteva essere derivata dall'equazione autoregressiva
Xn+1 = aXn + "n :
Esempio 2.7.3: supposto X come nell'Esempio 2.6.3 cerchiamo
(Xn+1)n (Xn+2 )n risulta
+1
(Xn+1)n = ;a ak Xn;k
b
b
X
b
k=0
b
(Xn+2)n = 0 :
In questo caso il risultto si giustica osservando che
Xn+2 = "n+2 ; a"n+1
b
cos che Xn+2 ? Hn, cioe (Xn+2)n = 0.
Inoltre dalla forma autoregressiva " = AX si vede che
Xn+1 = "n+1 ; aXn ; a2 Xn;1 : : :
b
ed essndo "n+1 ? Hn, la formula di predizione di (Xn+1)n e corretta.
2.8 Un'applicazone al ltro di Kalman-Bucy
In estrema sintesi quanto sin qui fatto sul problema della predizione lineare
ottimale puo essere riassunto da due aermazioni:
il predittore lineare ottimale di una variabile in HX , sulla base di osser-
vazioni, e dato dalla proiezione ortogonale della variabile stessa sullo
spazio lineare generato delle osservabili
106
tutte le informazioni utili sui prodotti scalari in HX sono contenute
nella matrice C quando poi sia C I tutte le regole di calcolo lineare
nito-dimensionale si riportano senza cambiamenti di forma anche in
innite dimensioni (propagazione della covarianza, Cholesky, ecc.)
Vediamo ora un'applicazone di questo principio di proiezione ortogonale ad
un particolare schema, detto di Kalman-Bucy, che noi analizziamo solo in
versione lineare ed a tempi discreti n = 0 1 2 : : :
L'importanza di questo \ltro" sta nella sua versatilita nella modellizzazione
di sistemi lineari in evoluzione dinamica, nella estrema semplicita dei conti
richiesti e nella possibilita, proprio per la seplicita dei calcoli, di implementare
la predizione ottimale in modo ricorsivo in tempo reale.
Il modello che analizzeremo e costituito dalla equazione di evoluzione di un
sistema descritto tramite un vettore (nito-dimensionale) detto vettore di
stato X n, dipendente dal tempo n all'istante iniziale per semplicita supponiamo che il sistema parta da uno stato X 0 noto. Parallelamente, a partire
dal tempo n = 1, si compiono sul sistema delle osservazioni raccolte in un
vettore Y n che sono esclusivamente funzioni lineari dello stato X n allo stesso
tempo.
Il modello e dunque
X n+1 = Dn+1X n + Gn+1"n+1
(2.8.1)
(2.8.2)
Y n+1 = An+1X n+1 + Mn+1 n+1 dim X = p dim Y = q
Dn+1 matrice della dinamica del sistema
An+1 matrice delle osservazioni
"n disturbo del sistema
n errore di misura
su " e vengono fatte le seguenti ipotesi:
E f"ng = 0 E f"n"+m g = mn En
E f ng = 0 E f n +mg = mnNn
E f"n +m g = 0 :
Facciamo subito tre osservazioni.
107
(2.8.3)
(2.8.4)
(2.8.5)
Osservazione 2.8.1: la natura sica di "n, ovvero di disturbo di sistema che
guida l'evoluzione di stato, e in genere diversa da quella di n che rappresenta
solo un disturbo dell'osservazine del sistema.
Ad esempio se X rappresenta una particella sospesa in un liquido descritta mediante 6 gradi di liberta (posizione, velocita) mentre Y rappresenta la
misura ottica della sua posizione, " puo essere la somma degli impulsi esercitati in 1 secondo sulla particella dalle molecole del liquido (moto Browniano)
mentre rappresenta l'errore della misura ottica.
Osservazione 2.8.2: quando la matrice d'osservazione An sia invertibile in
tutti i tempi, lo schema (2.8.1), (2.8.2) puo essere ridotto all'evoluzione della
sola variabile Y n, tramite l'equazione
Y n+1 = An+1Dn+1 A;n 1Y n + An+1 Gn+1"n+1 +
+Mn+1 n+1 ; An+1Dn+1A;n 1 Mn n :
Questo pero non e aatto un caso generale, come gia l'esempio dell'Osservazione 2.8.1 mostra.
Osservazione 2.8.3: l'equazione dinamica (2.8.1) non contiene una succes-
sione di forze esterne F n, non stocastiche, come invece di solito si ha sicamente. Tuttavia essendo la (2.8.1) lineare, non e necessario trattare la parte
deterministica, osservando che se
X n+1 = Dn+1X n + Gn"n + F n posto
X n = X on + X n
X on+1 = Dn+1X on + F n X 00 = 0
la componente stocastica X n torna a soddisfare la stessa equazione (2.8.1)
senza termine forzante.
Il problema che vogliamo risolvere e quello di dare una predizione lineare ottimale (X n+1)n+1 di X n+1 basata sulla conoscenza della sequenza di
osservazioni Y 1 Y 2 : : : Y n+1.
b
108
L'idea e quella di risolvere il problema iterativamente aggiornando la miglior
predizione (X n+1)n (cioe basata su Y 1 Y 2 : : : Y n) con l'introduzione di Y n+1 anzi se (Y n+1 )n e la proiezione di Y n+1 sullo spazio generato da Y 1 : : : Y n,
si potra cercare (X n+1)n+1 come
b
b
b
b
b
(X n+1)n+1 = (X n+1)n + n+1
(2.8.6)
dove la componente n+1 e funzione (lineare) solo dell'innovazione
Y n+1 ; (Y n+1)n,
b
n+1 = 'n+1fY n+1 ; (Yb n+1)ng (2.8.7)
la nostra incognita sara precisamente 'n+1. Se chiamiamo
Hn = SpanfY 1 : : : Y ng (2.8.8)
possiamo osservare che "m m sono ortogonali ad Hn 8m > n. Pertanto
dalla (2.8.1) si ha
b
b
b
(X n+1)n = Dn+1(X n)n
(2.8.9)
La stima (X n)n ha come errore di predizione
enn = X n ; (Xb n)n
(2.8.10)
e noi supponiamo per ora di conoscere la covarianza
Qnn = E fenne+nng :
(2.8.11)
b
Sottraendo dalla (2.8.1) la (2.8.9) si trova l'errore di predizione di (X n+1 )n,
ovvero
en+1n = X n+1 ; (Xb n+1)n = Dn+1enn + Gn+1"n+1 :
Inoltre utilizzando la (2.8.2) si vede che
b
b
(Y n+1)n = An+1 (X n+1)n
109
(2.8.12)
(2.8.13)
che sottratta alla (2.8.2) stessa da
Yn+1 ; (Xb n+1)n = An+1 en+1n + Mn+1 n+1 :
(2.8.14)
Usando in sequenza le (2.8.14), (2.8.7), (2.8.6), (2.8.10) si arriva all'equazione
en+1n+1 = (I ; 'n+1An+1 )Dn+1en+1n ; 'n+1Mn+1 n+1 :
(2.8.15)
Osservando che enn "n+1 e n+1 sono tra loro incorrelati, ovvero ortogonali,
possiamo propagare la covarianza di enn(Qnn) a quella di en+1n+1(Qn+1n+1)
tramite le (2.8.15), (2.8.12) trovando
Qn+1n+1 = (I ; 'n+1An+1)Kn(I ; A+n+1'+n+1) +
+'n+1Mn+1 Nn+1Mn++1 '+n+1
(2.8.16)
Kn = E fen+1ne+n+1ng = Dn+1QnnDn++1 + Gn+1En G+n+1
(2.8.17)
dove
Ora notiamo che
TrQn+1n+1 = E fjen+1n+1j2g
e precisamente l'errore quadratico medio di predizione che deve essere minimizzato secondo il principio di Wiener-Kolmogorov. Dalla condizione
min TrQn+1n+1
n+1
ricaviamo l'equazione
'n+1 = KnA+n+1(An+1 KnA+n+1 + Mn+1 Nn+1Mn++1);1 :
(2.8.18)
Da 'n+1 inizia l'iterazione secondo il seguente schema: suppongo di conoscere
(X n)n e Qnn e poi
b
dalla (2.8.9) calcolo (Xb n+1 )n
dalla (2.8.13) calcolo (Yb n+1)n
110
dalla (2.8.17) calcolo Kn
dalla (2.8.18) calcolo 'n+1
dalla (2.8.7) e dalla (2.8.13) calcolo n+1
b
dalla (2.8.6) calcolo (X n+1 )n+1.
dalla (2.8.16), dalla (2.8.17) e dalla (2.8.18) calcolo Qn+1n+1
Cos un ciclo e completato.
Lo schema parte dalla posizione
(X 0 )0 = X 0 :
Q00 = 0
b
(2.8.19)
Illustriamo questo procedimento con un esempio estremamente semplice,
benche sicamente signicativo.
Esempio 2.8.1: si ha un sistema a 2 gradi di liberta, per esempi una particella su un asse, che si muove sotto la spinta di impulsi casuali non correlati nel tempo, partendo dall'origine in quiete. Discretizzando nel tempo
l'equazione del moto
x( = "
si ha l'equazione
xn+1 = 2xn ; xn;1 + "n+1 (2.8.20)
che, come si vede connette tre tempi diversi
Per ricondurci alla forma (2.8.1), ovvero ad un'equazione alle dierenze prime, poniamo
(2.8.21)
X n = x xn; x n+1
n
ovvero il vettore di stato costituito da posizione e velocita della particella.
Con questa posizione si puo riscrivere l'equazione (2.8.20) nella forma
X n+1 = x xn+1
=
(2.8.22)
n+2 ; xn
111
1
0
1
xn
0
=
1 xn+1 ; xn + 1 "n+1
= Dn+1X n + Gn+1"n+1
Dalla (2.8.24) si vede che
1
Dn+1 = 0
1
1
(2.8.23)
(2.8.24)
0 Gn+1 = 1 ed inoltre, supposto che "n+1 sia un rumore bianco,
En+1 = "2 :
Ora supponiamo che si osservi la velocita della particella, il che e sicamente
possibile mediante l'eetto Doppler l'equazione d'osservazione discretizzata
si puo allora scrivere
Yn+1 = xn+1 ; xn + n+1
= An+1 X n + n+1 dove sara ovviamente
e
(2.8.25)
An+1 = 1 1]
Mn+1 = 1 Nn+1 = 2 :
Lo stato iniziale del sistema (particella) in quiete sara poi
X0 = 0
Q00 = 0 :
(2.8.26)
Applicando le operazioni descritte nel paragrafo, troviamo il ltro di Kalman
denito iterativamente nel seguente modo: posto
b
qn
Qnn = r
n
rn
pn
e supposto di conoscere (X n)n, cio che puo essere inizializzato con (2.8.26)
tenendo conto che (X 0) = X 0 = 0, si trovano (X n+1)n+1 e Qn+1n+1 con le
b
b
112
posizioni
Kn =
kn
`n
`n = qn + pn + 2rn rn + pn
hn rn + pn
pn + "2
#n = qn + 4pn + 4rn + "2
n+1 =
'n+1 =
b
(X n+1)n+1 =
Qn+1n+1 =
=
+
Qn 1 Kn + `n bn = # hn + `n an bn (Yn+1 ; 1 2](Xb n)n)
1 1 0 1 (Xbn)n + n+1
qn+1 rn+1 rn+1 pn+1 =
1 ; an ;an kn `n 1 ; an
;bn 1 ; bn `n hn ;an
a2n anbn 2
a b b2 :
n n n
117
;bn +
1 ; bn 3 I PROCESSI STAZIONARI
3.1 Processi stazionari in senso stretto
In termini qualitativi un processo a tempi discreti e stazionario se esso e
indistinguibile, quanto a distribuzione in IR1, 8 da un qualsiasi altro processo
ottenuto dal primo per traslazione temporale.
Denizione 3.1.1: sia X un processo in IR1 con distribuzione di probabilita
PX su B(IR1) posto
Y = BX (3.1.1)
X e detto stazionario in senso stretto se risulta
PY = PX ovvero se 8A 2 B(IR1)
(3.1.2)
PY (A) = PX (BA) = PX (A)
(3.1.3)
Osservazione 3.1.1: se X e stazionario in senso stretto allora tutti i processi ottenuti da X per traslazione temporale, ovvero
(3.1.4)
Y = B k X 8k 2 Z hanno la stessa distribuzione.
Infatti 8A 2 B(IR1), per k > 0
PY (A) = PX B k (A)] = PX B (B k;1A)] =
= PX B k;1A] = PX B k;2A] : : : = PX A]
(3.1.5)
per la (3.1.3). Se k < 0 invece, basta riscrivere la (3.1.3) come
PX (A) = PX (B ;1A)
e ripetere lo stesso ragionamento
In tutto questo paragrafo prendiamo come IR1 lo spazio lineare delle successioni
illimitate nei due sensi
x fxn n = 0 1 2 : : :g :
8
118
Osservazione 3.1.2: poiche una distribuzione di probabilita su B(IR1) e
denita per il Teorema di Kolmogorov dalle probabilita su C , ovvero 8C 2
RN fx = : : : 0 x1 : : : xN 0 : : : (x1 : : : xN ) 2 C g
PX (C ) = PN (C ) (3.1.6)
condizione necessaria e su!ciente a!nche valga la (3.1.3) 8A 2 B(IR1) e che
la stessa relazione valga 8C 2 B(RN ) 8N .
Cioe X e Y devono avere le stesse distribuzioni marginali, ovvero
(X0) (X;1 X0 X1) (X;2 X;1 X0 X1 X2 )
ecc. devono avere le stesse distribuzioni di
(X;1) (X;2 X;1 X0)(X;3 X;2 X;1 X0 X1)
Usando poi l'invarianza nella forma generale (3.1.4) si vede che le seguenti
successioni di variabili
: : : (X;1) (X0) (X1) : : :
: : : (X;2 X;1) (X;1 X0) (X0 X1) : : :
: : : (X;3 X;2 X;1) (X;2 X;1 X0) (X;1 X0 X1) : : :
devono avere le stesse distribuzioni di probabilita rispettivamente in IR1 IR2 IR3
eccetera.
E facile vedere che cio comporta anche che per ogni n-pla i1 : : : in le variabili
(Xi1 : : : Xin ) (Xi1;k : : : Xin;k )
(3.1.7)
hanno identica distribuzione 8k 2 Z .
Osservazione 3.1.3: quando in particolare le distribuzioni marginali di X
siano esprimibili per mezzo di densita di probabilita , si avra per la (3.1.7),
fX0 (x) = fX1 (x) = fX;1 (x) = : : :
(3.1.8)
ed ancora
fX0Xk (x y) = fXn Xn+k (x y) 8n 2 Z :
119
(3.1.9)
In particolare dalla (3.1.8) discendono le relazioni
E fXng = 0 E fXn2g = C0 = 2 8n 2 Z
(3.1.10)
mentre dalla (3.1.9) si ha che
E fXn+k Xng = Cn+kn = Ck
8n k 2 Z :
(3.1.11)
Come si vede la seconda delle (3.1.10) e le (3.1.11) dicono che la matrice di
covarianza C di X e costante sulle diagonali parallele alla principale, ed e
quindi dimostrato il seguente Lemma:
Lemma 3.1.1: l'operatore matriciale di covarianza di un processo X stazio-
nario in senso forte ha la struttura di Toeplitz.
Notiamo ancora che la proprieta di stazionarieta in senso forte, riguardo
l'invarianza temporale di un processo, e una proprieta assai restrittiva in
eetti per descrivere un processo stazionario e necessario per cos dire un
numero molto piu piccolo di distribuzioni marginali in quanto queste devono
soddisfare le relazioni (3.1.7).
Questa proprieta della condizione di stazionarieta forte e ben caratterizzata
da un teorema sull'operatore di traslazione temporale B esteso in questo caso
a tutto lo spazio L2(X ).
Denizione 3.1.2: sia
Y = g(X ) 2 L2 (X ) (3.1.12)
BY = Bg(X ) = g(BX ) :
(3.1.13)
deniamo
Notiamo che la denizione e coerente con quella data per le funzioni lineari
g(X ) = +X in HX . Vale allora il seguente Teorema:
Teorema 3.1.1: l'operatore B relativo al processo stazionario in senso forte
X , e unitario in L2 (X ).
120
Infatti risulta
k Bg(X ) k2 2
L =
=
E fg2(BX )g =
Z
IR1
Z
g
IR1
2 (BX )dP
;1
Y (B Y ) =
g2(Y )dP
Z
X (X ) =
= E fg2(X )g =k g(X ) k2L2 :
g
IR1
2 (Y )dP
X (Y ) =
(3.1.14)
Questa stessa proprieta potrebbe essere enunciata in modo anche un po piu
generale come proprieta dell'operazione di media EX sulla distribuzione di X ,
dicendo che EX e invariante per traslazione temporale, ovvero che 8g(X ) 2
L1(X )
E fBg(X )g = E fg(BX )g = E fg(X )g :
(3.1.15)
Esempio 3.1.1: un processo X con componenti indipendenti ed identicamente distribuite, cioe un rumore bianco, e stazionario in quanto ssata la
n-pla (i1 : : : in) ed il cilindro C di base fxi1 2 I1 : : : xin 2 Ing con Ik intervalli
(ak bk ] in IR, se inoltre chiamiamo P0(I ) la distribuzione di X0 in IR,
P fX 2 C g =
Yn P0(Ik) =
k=1
= P fBX 2 C g = P fXi1;1 2 I1 : : : Xin;1 2 Ing :
Esempio 3.1.2: (processo normale).
Ricordando l'Esempio 1.6 del
Cap. 2, consideriamo un processo normale X a media nulla e con covarianza
C del tipo Toeplitz. Presa ora una n-pla (i1 : : : in) ed il corrispondente vettore (Xi1 : : : Xin ), ne chiamiamo Cn la matrice di covarianza (n-dimensionale),
con elementi
(Cn)`k = Ci`;ik :
Notiamo anche che il vettore (Xi1 ;1 : : : Xin;1 ) ha esattamente la stessa
matrice di covarianza Cn e quindi la stessa distribuzione su IRn.
Ora, dato un borelliano A in IRn, per un qualsiasi cilindro C con base
(xi1 : : : xin ) 2 A, risulta
1
;1=2x+Cn;1xdnx P (X 2 C ) = 2n=2(def
e
1
=
2
Cn )
A
Z
121
evidentemente P (BX 2 C ) ha lo stesso identico valore di P (X 2 C ) perche
la forma della densita di probabilita e la stessa. Dunque un processo normale
a media nulla e con matrice di covarianza di Toeplitz e stazionario in senso
forte.
3.2 Processi stazionari in senso debole
Come si e gia visto nel Lemma 3.1.1 un processo X stazionario, come sempre
a media nulla, ha una matrice di covarianza con la struttura di Toeplitz o,
equivalentemente, i prodotti scalari in HX
< Xn+k Xn >= Ck 8n k 2 Z
(3.2.1)
dipendono solo da k.
Poiche in questo testo ci limitiamo a sviluppare una teoria cosiddetta del
secondo ordine lavorando sostanzialmente nello spazio HX , la cui struttura e
intimamente legata alla forma di C , viene naturale chiedersi quali proprieta
siano garantite dalla sola condizione (3.2.1).
Denizione 3.2.1: un processo X a media nulla e detto stazionario in senso
debole (ed in seguito lo chiameremo semplicemente stazionario) se la sua
matrice di covarianza C soddisfa la condizione di Toeplitz (3.2.1). In tal
caso la funzione Ck = C (k), denita qui per gli argomenti interi k, e detta
funzione di covarianza.
Dalla Denizione 3.2.1 appare chiaro che ogni processo stazionario in senso
forte lo e anche in senso debole, il viceversa tuttavia non e aatto detto come
mostrato dal seguente controesempio.
Esempio 3.2.1: sia fXng un processo a componenti indipendenti con le
componenti pari con densita di probabilita
X0 X2 : : : f0(x) mentre le dispari hanno densita di probabilita
X1 X3 : : : f1(x) :
122
Supponiamo che f0 f1 siano diverse tra loro ma tali che per entrambe
E0fX g = E1 fX g = 0 E0fX 2 g = E1fX 2g = 1 :
Allora il processo X ha ovviamente media nulla, covarianza C = I e nello
stesso tempo non e stazionario in senso forte perche le componenti pari hanno
distribuzioni monodimensionali diverse dalle componenenti dispari.
Lemma 3.2.1: l'operatore matriciale C ha la struttura di Toeplitz se e solo
se
BCB + = C , BC = CB
(3.2.2)
Il Lemma puo essere dimostrato per applicazione diretta del prodotto BCB + ,
Ci+1k+1 = (BCB +)i+1k+1 = Cik :
(3.2.3)
La relazione tra questo Lemma ed i processi stazionari sta nel fatto che X e
stazionario se e solo se la sua covarianza C e di Toeplitz ma e pure stazionario
se e solo se posto Y = BX Y ha la stessa covarianza di X , cioe
CY Y = BCB + = C che appunto coincide con la (3.2.2).
Osservazione 3.2.1: il fatto che la matrice di Toeplitz C commuti con B ,
come nella seconda delle (3.2.2), e parte di un risultato molto piu generale che
concerne l'algebra delle matrici di Toeplitz che, ricordiamo, corrispondono ad
operazioni di convoluzione.
Tale risultato deriva tra l'altro dal fatto ovvio che una qualunque matrice di
Toeplitz T puo essere messa nella forma
+1
T=
tk B k (3.2.4)
k=;1
X
infatti B k e una matrice con coe!cienti nulli dappertutto fuorche sulla kesima diagonale dove valgono 1, pertanto tk e il valore costante dei coe!cienti
di T che stanno su tale diagonale.
123
Viceversa la (3.2.4) rappresenta sempre una matrice di Toeplitz. Poiche la
conoscenza di T e ovviamente equivalente alla conoscenza del vettore t =
ftk g, cioe di una sua riga, tra le matrici T si puo introdurre una nozione di
norma, mutuata da una norma per t a noi in particolare interessa la famiglia
T1 di matrici T del tipo (3.2.4) per cui
+1
jtk j < +1 :
(3.2.5)
k t k1 =
k=;1
X
Vale allora il seguente risultato:
Lemma 3.2.2: la famiglia T1 e un'algebra commutativa, ovvero 8T V 2 T1
TV = V T 2 T1 :
(3.2.6)
Usando la (3.2.4) e l'analoga rappresentazione di V si ha
+1
+1
W = TV =
Bp tp;k vk :
p=;1 k=;1
X X
Poiche, posto
+1
X
wp =
tp;k vk
k=;1
risulta
k w k1 =
(3.2.7)
(3.2.8)
+1
+1 X
+1
X
X
jwpj jtp;k jjvk j =
p=;1
p=;1 k=;1
= k t k1 k v k1 si ha che la serie (3.2.8) e convergente e quindi la (3.2.7) rappresenta veramente una matrice in T1 .
Inoltre dall'identita
+1
+1
wp =
tp;k vk =
thvp;h
k=;1
h=;1
X
X
124
appare chiaro che
W = TV = V T :
Usando il Lemma 3.2.1 e facile ora dimostrare il seguente Teorema:
Teorema 3.2.1: se X e stazionario B e un operatore unitario in HX , ovvero
(3.2.9)
8X 2 HX k BX k=k X k :
In eetti posto X = +X , risulta
k BX k2 =k +BX k= +BCB + = + C =k X k2 :
Si ricordi qui che a causa dell'identita
< X Y >= 41 (k X + Y k2 ; k X ; Y k2) (3.2.10)
per l'operatore unitario B vale anche l'identita
ovvero ancora
< BX BY >=< X Y >
(3.2.11)
BB+ = I B+ = B;1 = F :
(3.2.12)
Si osservi che le (3.2.12) valgono naturalmente sempre per le matrici B B +
ed F , ma solo per i processi stazionari valgono anche per i corrispondenti
operatori in HX .
Terminiamo questa prima caratterizzazione dei processi stazionari in senso
debole con un teorema tecnico di notevole importanza.
Teorema 3.2.2: se X e stazionario, il corrispondente processo di innovazione " ha la stessa cadenza temporale di X , ovvero
B" BX B :
125
(3.2.13)
Ricordando la Denizione 6.1 del Capitolo 2, si ha
"n = n(Xn ; Xbn)
(3.2.14)
dove
n = k Xn ; Xbn k;1
Xbn = proiezione ortogonale di Xn su Hn SpanfXk k ng] :
Dunque, ricordando che B : Hn ! Hn;1 e B : Hn;1 ! Hn;2
B"n = n(Xn;1 ; BXbn) 2 Hn;1 :
(3.2.15)
Inoltre, usando la (3.2.11) si vede che per k 2
< B"n BXn;k+1 >=< "n Xn;k+1 >= 0
(3.2.16)
perche "n e ortogonale ad Hn;1 d'altro canto la (3.2.16) puo essere riscritta
come
< B"n Xn;k >= 0 8k 2
(3.2.17)
B"n ? Hn;2 :
(3.2.18)
k B"n k=k "n k= 1 :
(3.2.19)
il che dimostra che
Inne, per la (3.2.9)
Le (3.2.15), (3.2.18) e (3.2.19) insieme dicono che
B"n = "n;1 (3.2.20)
questa dimostra esattamente che B B".
L'importanza di questo teorema non e tanto nella (3.2.16) in se quanto nelle
sue conseguenze, riassunte nel seguente Corollario.
126
Corollario 3.2.1: se X e stazionario e C D, gli operatori matriciali M
ed A (cfr. x2.6, x2.7) tali che
X = M" " = AX (3.2.21)
hanno la struttura di Toeplitz, cos che si puo scrivere
Xn =
"n =
+1
Xn Mnk"k = Xn mn;k"k = X
mk "n;k
k=;1
n
k=;1
n
k=0
k=;1
k=;1
k=0
+1
X AnkXk = X an;kXn = X
ak Xn;k :
(3.2.22)
(3.2.23)
Il Corollario deriva dall'applicazione del Teorema 2.5.1 alle (3.2.21), tenuto
conto del Teorema 3.2.2.
Si noti che per la propagazione della covarianza (cfr. Teorema 2.6.3) deve
essere
C = MM + (3.2.24)
poiche se M e una matrice di Toeplitz altrettanto lo e M + , questa relazione e coerente col fatto che pure C deve avere tale struttura. Esplicitando la (3.2.24) in componenti, si trova la relazione che lega il vettore c f: : : c2c1 c0c1c2 : : :g associato alla matrice (simmetrica C ) al vettore
m f: : : m2 m1m0 0 : : :g associato alla matrice (triangolare bassa) M , ovvero
+1
+1
+1
Cn =
mk mk;n = mhmh;jnj = mjnj+k mk :
(3.2.25)
k=;1
k=0
h=jnj
X
X
X
Nel Cap. 2 gli Esempi 1.1, 1.5, 3.2, 3.3, 3.4, 6.1, 6.2, 6.3 riguardano processi
stazionari altri esempi si vedranno nei prossimi paragra.
3.3 Funzione di covarianza: caratteristiche
Come si e visto nel x3.2 un processo stazionario X ha una matrice di covariazna C con struttura di Toeplitz cosicche C e completamente caratterizzata
127
da una sua riga (colonna) c le componenti di c in funzione del parametro
\tempo" k costituiscono la cosiddetta funzione di covarianza, che di volta in
volta scriveremo,
Ck ck C (k) :
(3.3.1)
Vogliamo caratterizzare C (k) ovvero denire condizioni necessarie e su!cienti a!nche C (k) sia una funzione di covarianza. Ovviamente tali condizioni
devono derivare dal fatto che
C fCkj g fC (k ; j )g
(3.3.2)
deve essere un operatore di covarianza, in IR1. Cominciamo col vedere alcune
condizioni necessarie:
1) C (k) deve essere pari
C (;k) = C (k)
(3.3.3)
C0 jC (k)j
(3.3.4)
2)
3) C (k) deve essere denita positiva, ovvero
XN XN jkj C (k ; j) > 0
k=;N j =;N
8N 8fk ;N
(3.3.5)
k N g 6= 0 :
La 1) deriva dal fatto che C deve essere simmetrica ed ha la struttura di
Toeplitz la 2), usando la Denizione 3.2.1, dice che per un coe!ciente di
correlazione vale
j(k)j = jCC(k)j 1 0
la 3) esprime la denita positivita di C . notiamo che se in piu si ha a che
fare con un processo X che e base di Riesz di HX la 3) deve essere sostituita
dalla condizione piu forte
128
3')
XN 2 XN kj C (k ; j) XN 2
k=;N
n
kj =;N
k=;N
k
con indipendenti da N (cfr. Teorema 2.2.4).
Notiamo anche che la 2) discende dalla 3) (o dalla 3'), cosicche non stupisce
che valga il seguente Lemma:
Lemma 3.3.1: una funzione C (k) che soddis 1) e 3) e funzione di cova-
rianza di un processo stazionario se inoltre vale la 3') allora X e regolare ed
e una base di Riesz in HX .
Questo Lemma non ha bisogno di particolari dimostrazioni in quanto e gia
stato illustrato nell'esempio 2.1.6 sulla costruzione dei processi normali, cui
occorre solo aggiungere che la condizione 3') garantisce che C I , cosicche
vale anche l'ultima conclusione, per il Teorema 2.2.4.
Notiamo anche che nell'Esempio 2.1.16 l'indice k variava sugli interi non
negativi, tuttavia la generalizzazione a ;1 < k < +1 e immediata.
Naturalmente una verica diretta delle condizioni 3) o 3') e assai di!cile,
tuttavia vedremo nel prossimo paragrafo un comodo criterio per tale verica. Qui ci accontentiamo di fornire una tabella (Tabella 3.1) di famiglie di
funzioni di covarianza oltre che alcuni Lemmi che permettono da queste di
costruire altri modelli.
A0
2 `
k
1 + 2
A0 = 1 = 2 ` = 1
Tab. 3.1.a
129
A0 1 ; Nk
A0 = 1 N = 5
Tab. 3.1.b
A0 cos !k
A0 = 1 ! = 10
Tab. 3.1.c
130
A0 e;jkj
A0 = 1 = 0:3
Tab. 3.1.d
A0 e;k2
A0 = 1 = 0:1
Tab. 3.1.e
A0 sin!k!k
A0 = 1
Tab. 3.1.f
131
A0 J0(k)
A0 = 1
Tab. 3.1.g
Naturalmente si potrebbero citare molti altri modelli di covarianza, tuttavia diamo qui delle regole utili per costruire nuove funzioni di covarianza,
combinandone altre gia note.
Prima di procedere notiamo che la funzione A0 cos !k non e una funzione
di covarianza di un processo regolare, in quanto essa torna periodicamente
al valore massimo A0 (quando ! e uguale a per un razionale) mostrando
che tra variabili del tipo Xn Xn+k , con !k = r`, esiste un coe!ciente di
correlazione = 1, cioe una perfetta dipendenza lineare. Questo modello
pero e utile in combinazione con altri.
Lemma 3.3.2: la funzione
C (k) = C1(k) + C2(k)
> 0
(3.3.6)
e una funzione di covarianza se lo sono C1(k) e C2 (k).
Lemma 3.3.3: la funzione
C (k) = C1(k) C2(k)
(3.3.7)
e una funzione di covarianza se lo sono C1 C2.
Infatti basta costruire un processo X con covarianza C1(k) ed un processo Y
indipendente con covarianza C2 (k). Allora il processo
V = Vn Vn = XnYn
132
e ovviamente a media nulla, stazionario e con covarianza C (k) data da (3.3.7).
Lemma 3.3.4: la funzione
+1
X
C (k) =
C1 (k ; `)C2(`)
`=;1
(3.3.8)
e una funzione di covarianza se lo sono C1 e C2 .
Ricordando il Lemma 3.2.2, dalla (3.3.8) si deduce che
C = C1C2
(3.3.9)
con C1 C2 due operatori matriciali di covarianza. D'altro canto si potra porre
C1 = M1 M1+
con M1 matrice di Toeplitz, cos che sempre per il Lemma 3.2.2, M1 e C2
commutano ma allora si puo scrivere,
C = M1C2 M1+ che dimostra che C e simmetrica e denita positiva, cioe una matrice di
covarianza.
Osservazione 3.3.1: nel riconoscere l'appartenenza di una funzione di covarianza ed una certa famiglia parametrica, si possono tenere in conto alcuni
elementi qualitativi che caratterizzano la funzione stessa. Tra questi citiamo
a) la presenza o meno di zeri e l'eventuale cadenza degli zeri
b) il comportamento nell'origine (con tangente nulla o negativa)
c) la rapidita di decadimento della funzione se non vi sono zeri, ovvero il
decadimento di massimi e minimi quando vi siano zeri.
133
Osservazione 3.3.2: se un processo stazionario X con covarianza C e funzione di covarianza C (k) e sottoposto ad una trasformazione T 2 T1 ,
Y = TX (Yn =
X tn;mXm)
m
per la propagazione della covarianza Y ha come operatore CY
CY = TCT + :
(3.3.10)
(3.3.11)
Mettendo la (3.3.11) in componenti si trova la relazione tra la funzione di
covarianza X C (k) e quella di Y CY (k), ovvero
+1
CY (n) =
tn;k C (k + j )tj (3.3.12)
kj =;1
X
dunque CY (k) e ottenuta da C (k) con una convoluzione ed una anti-convoluzione con tk .
Chiudiamo il paragrafo notando che vi sono altri modelli di covarianza direttamente derivabili dalle leggi di evoluzione dei processi, che considereremo
piu avanti.
3.4 Lo spettro di potenza ed il calcolo spettrale
Allo scopo di semplicare la presentazione seguente, faremo d'ora in poi
l'ipotesi fondamentale che C (k) 2 T1 ovvero che
+1
jC (k)j < +1 :
(3.4.1)
k=;1
Questa ipotesi signica tra l'altro che due componenti del processo stazionario X Xn+k ed Xn assai lontane nel tempo hanno tra loro una correlazione
sempre piu piccola, talche la condizione (3.4.1) sia vericata. In altri termini
il processo X perde memoria dei valori assunti a grande distanza nel tempo
passato.
Sotto l'ipotesi (3.4.1) la serie di Fourier con coe!cienti C (k) e assolutamente
uniformemente convergente, cos che ha signicato la denizione che diamo
qui di seguito.
X
134
Denizione 3.4.1: Si chiama densita spettrale la funzione
+1
X
f (p) =
C (k)ei2
kp :
(3.4.2)
k=;1
E ovvia conseguenza di quanto detto il seguente Lemma.
Lemma 3.4.1: la densita spettrale, che per semplicita chiameremo anche
spettro, e una funzione continua e periodica di periodo 1.
Osserviamo ancora che essendo C (k) una funzione pari, la (3.4.2) puo essere
riscritta come
N
X
f (p) = C0 + 2 C (k) cos 2kp(k)
k=1
(3.4.3)
il che dimostra che f (p) e una funzione reale pari.
Alcune proprieta fondamentali dello spettro, oltreche il suo nome, derivano
da un Lemma che qui dimostriamo dopo aver dato una nuova Denizione.
Denizione 3.4.2: chiameremo periodogramma del processo stazionario X ,
la funzione
X
2
N
IN (p) = 2N1+ 1
Xk ei2
kp :
k=;N
(3.4.4)
Ovviamente IN (p) e una funzione non negativa di p, continua e periodica
di periodo 1. Naturalmente IN (p) e anche una variabile casuale funzione di
X 8p.
Lemma 3.4.2: risulta
lim E fIN (p)g = f (p) N !1
(3.4.5)
pertanto e necessariamente
f (p) 0 8p :
135
(3.4.6)
In sostanza IN (p) e uno stimatore asintoticamente corretto dello spettro, che
risulta quindi essere una funzione non negativa.
Si ha
E fIN (p)g = 2N1+ 1 E
( XN
)
(kjXN=;N
Xk Xj ei2
(k;j)p =
X
N ;1
1
2
=
E
X + 2 cos 2p X`X`+1+
2N + 1 `=;N `
`=;N
N ;2
+2 cos 4p X`X`+2 + : : :
`=;N
1
= 2N + 1 f(2N + 1)C0 + 2 cos 2p 2NC1 + 2 cos 4p )
X
(2N ; 1)C2 + : : :g =
=
Poiche risulta
ed inoltre e
ottenendo
N
X
C0 + 2 cos 2kp 2N + 1 ; k Ck
2N + 1
k=1
(3.4.7)
cos 2kp 2N2N+ +1 ;1 k 1
P jC (k)j < +1 per ipotesi, nella (3.4.7) si puo passare al limite
+1
X
lim E fIN (p)g = C0 + 2 cos 2kpCk = f (p)
N !1
k=1
per la (3.4.3).
Riassumendo le caratteristiche della densita spettrale (condizioni necessarie),
per una covarianza che soddis la (3.4.1), si ha
1) f (p) e continua e periodica di periodo 1
1) f (p) e reale e pari
136
1) f (p) 0 8p.
Osservazione 3.4.1: se pensiamo a Xn come ad un fenomeno ondulatorio
nel tempo n, possiamo prendere IN (p) come una misura del quadrato dell'ampiezza dell'armonica di frequenza p contenuta in Xn e quindi la sua media,
per N grande, assume il signicato di potenza media dell'onda a frequenza
p, da cui il nome di spettro di potenza.
Osservazione 3.4.2: se ogni covarianza in T1 ammette uno spettro che
soddisfa le condizioni 1), 2), 3), non e vero il viceversa.
In particolare una funzione reale, continua, positiva pari e di periodo 1, non
e detto che abbia coe!cienti di Fourier
Ck = 1 +2ko f (p) cos 2kpdp
(3.4.8)
0
Z
che soddisfano la (3.4.1).
L'identicazione precisa della classe di queste funzioni ff (p)g non e semplice, tuttavia e facile dare una condizione su!ciente a!nche la (3.4.1) sia
vericata.
Lemma 3.4.3: se f (p) soddisfa 1), 2), 3) e se per di piu f 0(p) 2 L2 (0 1)
allora f (p) e lo spettro di una covarianza fCk g 2 T1 .
Se e
+1
X
f (p) = C0 + 2 cos 2kpCk k=1
con Ck dati dalla (3.4.8) e per di piu
+1
f 0(p) = ;4 sin 2kp kCk 2 L2 X
k=1
allora deve essere
+1
X
k2C 2 < +1 :
k=1
k
137
Ma in tal caso, applicando la diseguaglianza di Schwarz
1=2
+1
+1
+1
+1
1
1
2
jCk j = C0 +
jCk j k k C0 + 2 Ck k k2 < +1
k=;1
k6=0=;1
k=1
k=1
X
(X
X
Esempio 3.4.1: sia X un rumore bianco con covarianza
Ck = k02 X )
(3.4.9)
la densita spettrale in questo caso e data da
f (p) = 2 cioe la potenza e la stessa per tutte le frequenze, da cui il nome di rumore
bianco.
Esempio 3.4.2: sia X un processo stazionario con covarianza nita (cfr. ad
esempio il modello 2) del x3.3), ovvero
fCk g = fC0 C2 : : : CL 0 0 : : :g per k 0 in questo caso
L
X
f (p) = C0 + 2 Ck cos 2kp k=1
(3.4.10)
dunque lo spettro in questo caso e un polinomio trigonometrico di ordine
nito L.
Esempio 3.4.3: sia X un processo con covarianza (cfr. il modello 4) del
x3.3)
Ck = A0 e;jkj = A0 jkj ( = e; < 1) in questo caso, sommando la corrispondente serie di Fourier, si trova lo
spettro
0
(3.4.11)
f (p) = 1 ; Ccos
2p
e;2 = 2e; (< 1) :
C0 = A0 11 ;
+ e;2
1 + e;2
Si noti come anche in questo caso, essendo < 1, risulta f (p) > 0 8p.
138
Passiamo ora ad un risultato centrale di questo paragrafo che e la caratterizzazione delle funzioni di covarianza strettamente denite positive, cioe quelle
per cui C I , in termini di densita spettrale.
Per provare questo risultato ci verra utile un Lemma, che premettiamo
Lemma 3.4.4: sia (p) una funzione continua e limitata su (;1=2 1=2)
supponiamo che 8(2N + 1)-pla di numeri complessi (;N : : : N ) valga
Z 1=2 XN i2
kp2
(p) k e dp 0 ;1=2 k=;N
(3.4.12)
allora deve necessariamente essere
(p) 0 8p 2 (;1=2 1=2) :
(3.4.13)
Infatti sia '(p) una funzione liscia come in Fig. 3.4.1.
Essendo '(p) ad esempio continua e limitata e cos pure '0(p), in tutto
(;1=2 1=2) e potendo far s che cos sia per '(p), si puo porre per opportuni
k ,
+1
'(p) =
k ei2
kp
k=;1
con la serie uniformemente convergente, dovendo essere jk j < +1 (cfr.
Lemma 3.4.3).
p
p
X
P
139
Fig. 3.4.1
Dunque sara, uniformemente in p,
XN
2
kei2
kp :
'(p) = Nlim
!1 k=;N
(3.4.14)
Ora supponiamo per assurdo che
(p0 ) < 0 p0 2 (;1=2 1=2) ma allora dovra pure essere, per " opportuno,
(p) < 0 8p 2 p0 ; " p0 + "]C (;1=2 1=2) allora ssato " e di conseguenza la '(p) come in (3.4.14), consideriamo
'(p ; p0) =
=
con
XN
2
lim k ei2
k(p;p ) =
N !1 =;N
kX
2
N
lim k ei2
kp
N !1 0
k=;N
k = k e;i2
kp0
jk j = jk j :
140
(3.4.15)
Essendo
si trova
P jkj < +1, anche il limite in (3.4.15) sara uniforme in p e quindi
Z 1=2 XN i2
kp2
lim
(p) k e dp =
N !1 ;1=2
k=;N
Z 1=2
(p)'(p ; p0)dp < 0
;1=2
che e in contraddizione con la (3.4.12).
Possiamo ora enunciare il Teorema principale.
Teorema 3.4.1: sia f (p) lo spettro di un processo con covarianza C la
=
relazione
vale se e solo se
C I (I C I )
(3.4.16)
0 < f (p) (3.4.17)
Dimostriamo che (3.4.16) ! (3.4.17). La (3.4.16) signica che valgono le
relazioni
I ; C 0 C ; I 0 :
(3.4.18)
Prendiamo ad esempio la prima delle (3.4.18) questa implica che
8(;N : : : N ), complessi, 9
XN j kj ; Ck;j] 0 kj =;N
k
ma ricordando che
Ck =
ko =
(3.4.19)
Z 1=2 ;i2
kp
f (p)e
dp ;1=2
Z 1=2 ;i2
kp
;1=2
e
dp
Risolvendo i complessi k in parte reale ed immaginaria, k = ak + ibk , e facile vedere
che questa denizione di denita positivita e perfettamente equivalente a quella puramente
reale, essendo C una matrice reale simmetrica.
9
141
la (3.4.19) da
XN j Z 1=2 ; f (p)]ei2
(j;k)pdp = Z 1=2 ; f (p)] XN j ei2
jp2 dp 0
k
j=;N ;1=2
;1=2
kj =;N
e quindi per il Lemma 3.4.4 concludiamo che
; f (p) 0 :
In modo analogo si prova che
f (p) ; 0 :
Ora viceversa proviamo che (3.4.17) ! (3.4.16). Dalle identita
XN
2
Z
N
1=2
X
C =
k j Ck;j =
f (p) j ei2
jp dp
;1=2
j =;N
kj =;N
(3.4.20)
si vede immediatamente che
f (p) )
f (p) )
N
2 XW
Z
1=2 X
j ei2
jp = jj j2
C ;1=2 j=;N
j =;N
2
Z
N
N
1=2 X
X
i2
jp dp = C e
jj j2
j
;1=2 j=;N
j =;N
Dunque il Teorema 3.4.1 ci dice che tutte le proprieta di regolarita di un
processo X e della matrice di covarianza C gia commentate nel Cap. 2 e che
si riassumono nella condizione C I , possono essere vericate sullo spettro
f (p) del processo con la semplice condizione (3.4.17). Tra l'altro si noti che
per un processo stazionario che sulla diagonale di C ha la costante C0, le condizioni C D C I sono pienamente equivalenti. In particolare essendo
f (p) continua per ipotesi, la condizione f (p) deve essere automaticamente soddisfatta percio e la condizione f (p) > 0 che garantisce che X
sia una base di Riesz in HX .
142
Osservazione 3.4.3: ci si puo chiedere cosa avvenga invece se si assume che
f (p) si annulli in un intervallino, ad esempio in (p0 ; " p0 + ") (;1=2 1=2).
In questo caso in eetti e facile vedere, usando la stessa '(p) denita nel
Lemma 3.4.4, che
C =
Z 1=2
;1=2
f (p)'(p)dp = 0
per un vettore complesso non identicamente nullo di conseguenza la covarianza C non e denita positiva ma solo semidenita e una delle componenti
di X puo essere espressa come combinazione lineare delle altre, cio che abbiamo escluso n dall'inizio del Cap. 2. Resterebbe da caratterizzare il caso
in cui f (p) abbia degli zeri isolati o una successione di zeri, ma tale analisi
fuoriesce dallo scopo di questa trattazione.
Osservazione 3.4.4: si consideri ancora una trasformazione T 2 T1 di X ,
Y = TX (3.4.21)
con la formula (3.3.12) abbiamo caratterizzato la trasformazione dalla covarianza C (k) di X alla covarianza CY (k) di Y . Ci si chiede ora come si
trasformi lo spettro f (p) di X , in quello fY (p) del nuovo processo Y .
A questo scopo introduciamo la seguente denizione:
Denizione 3.4.3: data una T come in (3.4.21) deniamo funzione di tra-
sferimento la
+1
X
T (p) =
tk ei2
kp P
k=;1
(3.4.22)
Notiamo che la condizione k jtk j < +1 garantisce la convergenza uniforme
della serie a T (p) che percio in generale risulta essere una funzione continua
e periodica di periodo 1, ma non reale, ne con qualche tipo di simmetria.
Moltiplicando la (3.3.12) per ei2
np e sommando su tutti gli n 2 Z , sfruttando
i teoremi standard sulle convoluzioni, otteniamo la relazione
fY (p) = f (p)jT (p)j2
143
(3.4.23)
che e l'equivalente della propagazione della covarianza. Si noti che, come gia
sappiamo, vi sono molte trasformazioni che danno luogo alla stessa trasformazione spettrale e quindi alla stessa covarianza in eetti se V 2 T1 e tale
che
V (p) = T (p)ei(p)
(3.4.24)
con )(p) reale e chiaro che posto
W = VX si ha
fW (p) = f (p)jV (p)j2 = f (p)jT (p)j2 = fY (p) :
(3.4.25)
Un esempio importante di questa molteplicita lo si ha nella ricerca di un
\ltro" (cioe di una trasformazione T ) sbiancante per un processo X dato,
con spettro f (p) che soddisfa la (3.4.17). Si vuole cioe una trasformazione
T , tale che
= TX
sia un rumore bianco (in senso debole) ovvero abbia una covarianza C = I o
uno spettro f (p) = 1.
Usando la (3.4.23) appare chiaro che
T (p) = f (p)];1=2
(3.4.26)
e una soluzione al nostro problema, in cui T (p) e una funzione reale simmetrica, continua e limitata proprio perche f (p) > 0. D'altro canto come
gia ricordato nel Corollario al Teorema 3.2.2, vale la relazione
+1
" = AX ("n = ak Xn;k )
(3.4.27)
X
k=0
dove ", l'innovazione di X , e un processo di rumore bianco con varianza 1
di nuovo applicando la (3.4.23) si vede che deve essere
f"(p) = 1 = f (p)jA(p)j2 :
144
Peraltro la A(p) cos denita e data da
+1
A(p) = ak ei2
kp
X
(3.4.28)
k=0
che, come appare chiaro, non e una funzione reale, ne e simmetrica rispetto
a p e quindi e una funzione certamente diversa dalla (3.4.26). Torneremo nel
prossimo paragrafo su questo problema.
3.5 La predizione ottimale calcolo di M ed A dallo
spettro
Il problema della predizione lineare ottimale denito come la ricerca della
variabile (Xn+k )n, proiezione di Xn+k su H(n) , e dell'errore quadratico medio
En2+kn =k Xn+k ; (Xn+k )n k2 e stato arontato e risolto nel x2.7 in termini
generali.
Riportiamo qui quei risultati tenendo conto che per un processo stazionario
X , tanto la matrice di covarianza C che M ed A sono matrici di Toeplitz. In
sostanza abbiamo
n
+1
(Xn+k )n =
mn+k;j "j = m`"n+k;` (3.5.1)
j =;1
`=k
n+k
k;1
Ek2 =
m2n+k;j = m2j (3.5.2)
b
b
b
"n+k;` =
X
X
X
X
j =n+1
j =0
Xaj Xn+k;`;j +1
j =0
(3.5.3)
notiamo che le (3.5.1) (3.5.3) possono essere unite per fornire la formula
n
+1
(Xn+k )n =
;kn;j Xj = ;kj Xn;j
(3.5.4)
j =;1
j =0
dove
n;j
(3.5.5)
;kn;j = mn;j;h+kah :
b
X
X
X
h=0
145
Come si vede il successo di tale formule dipende dalla conoscenza di M ed A
che a loro volta sono legate alla covarianza dalle relazioni
C = MM + A = M ;1 :
(3.5.6)
Poiche la funzione covarianza di un processo stazionario e stimabile anche
da una sola realizzazione, come vedremo nel prossimo paragrafo, occorre
trovare un modo per calcolare M ed A dalle (3.5.6). Un'idea e quella di
passare attraverso le rappresentazioni spettrali delle (3.5.6), ovvero
f (p) = jM (p)j2 (3.5.7)
A(p) = M1(p) (3.5.8)
dove
+1
X
M (p) = mk eik2
p
k=0
+1
X
A(p) = ak eik2
p :
k=0
(3.5.9)
(3.5.10)
La soluzione del problema posto e fornita dal seguente Teorema che ha
carattere costruttivo.
Teorema 3.5.1: le funzioni di trasferimento M (p) A(p) corrispondenti agli
operatori M ed A deniti in (3.5.6), sono le soluzioni uniche delle equazioni
(3.5.7), (3.5.8), (3.5.9), (3.5.10) con mk ak reali quando lo spettro f (p) sia
limitato sia sopra che sotto
0 < f (p) :
(3.5.11)
La linea della dimostrazione e la seguente: nella parte a) prendiamo le (3.5.7),
(3.5.8), (3.5.9), (3.5.10) come equazioni in M (p) ed A(p) e dimostriamo costruttivamente che esiste una soluzione corrispondente a successioni reali
fmk k 0g fak k 0g. Nella parte b) prendiamo la successione fak g
trovata e simostriamo che posto
+1
n = ak Xn;k ( = AX )
(3.5.12)
X
k=0
146
n coincide con l'innovazione "n ne segue che la matrice A cos trovata
coincide necessariamente con l'operatore autoregressivo che stiamo cercando
e quindi M = A;1 coincide con quello di media mobile.
a) Dato f (p) deniamo
u(p) = 21 log f (p) u e una funzione continua e limitata, per la (3.5.11), percio si puo porre
+1
X
u(p) =
anein2
p :
(3.5.13)
n=;1
Poiche u(p) e una funzione reale pari, al posto della (3.5.13) si puo scrivere
+1
u(p) = u0 + 2 un cos n2p :
(3.5.14)
X
n=1
P
Si osservi che se si suppone che f (p) abbia una derivata in L2, altrettanto
vale per u(p) e quindi si puo in questo caso ritenere che junj < +1.
Notiamo che se si pone # = 2p u(p) puo essere pensata come traccia sulla
circonferenza unitaria fr = 1g della funzione
+1
u(r #) = u0 + 2 unrn cos n# :
(3.5.15)
X
n=1
La (3.5.15) e notoriamente una funzione armonica in fr 1g e quindi
raggiunge i suoi valori massimi e minimi sul contorno cos che
1 log u(r #) 1 log :
(3.5.16)
2
2
Ora poniamo
+1
+1
n
in#
(z) = u0 + 2 unr e = u0 + 2 unzn
(3.5.17)
ove
X
X
n=1
n=1
z = rei# = rei2
p :
147
P
E chiaro che (z) e analitica in fr 1g se la serie (3.5.17) e convergente e
cio e vero se, come supponiamo, junj < 1. Notiamo che u(z) = Re(z).
Finalmente poniamo
M (z) = e(z) (3.5.18)
poiche (z) e una funzione analitica in fr 1g altrettanto e M (z) cos che
vale la rappresentazione di Taylor
+1
M (z) = mk zk
(3.5.19)
X
k=0
Inoltre da
e dalla (3.5.16) si vede che
jM (z)j = eu(z)
(3.5.20)
jM (z)j > p (3.5.21)
cos che M (z) non e mai nulla nel cerchio fr 1g. Inne risulta pure
jM (z)j2r=1 = e2u(p) = elog f (p) = f (p) cioe la funzione
M (p) =
+1
X
mk ein2
p
k=0
e proprio tale che
jM (p)j2 = f (p) :
(3.5.22)
Dunque la M (p) cos costruita e soluzione di (3.5.7), (3.5.9). Inoltre per la
(3.5.21) si puo anche porre
A(z) = M1(z)
(3.5.23)
148
ed aermare che pure A(z) e analitica regolare nel cerchio fr 1g, cos che
si avra
+1
A(z) = ak zk :
X
k=0
Ora preso z = ei2
p si trova
X
+1
1
A(p) = M (p) = ak eik2
p :
k=0
(3.5.24)
Si puo notare che mantenendo le ipotesi di regolarita n qui riportate, si puo
+1
anche aermare che jak j < +1, cioe A(p) 2 T1 X
k=0
b) notiamo che
+1
+1
X
X
jak j < +1 ) a2 < +1 cos che la serie (3.5.12) e
k=0
k=0
k
convergente, in quanto la condizione (3.5.11) garantisce che C I . Vogliamo
dimostrare che n = "n.
In primo luogo notiamo che
+1
n = ak Xn;k ) n 2 Hn :
X
k=0
Inoltre
f (p) = jA(p)j2f (p) = 1
il che ci dice che e un rumore bianco in senso debole, ovvero una successione
ortonormale, cos che e anche
k n k= 1 :
Inne osserviamo che
< n Xn;j > =
=
+1
X
ak Cj;k =
k=0
+1
+1 X
X
ak mimi+j;k =
k=0
149
i=0
=
D'altro canto dall'identita
A(p)M (p) =
=
discende
+1 X
+1
X
mi ak mi+j;k :
i=0
k=0
(3.5.25)
+1
X
ak mhei(k+h)2
p =
kh=0
X
!
+1
+1
X
n=0
ein2
p
k=0
ak mn;k 1
+1
n
X
X
ak mn;k = ak mn;k = n0 k=0
k=0
cos che la (3.5.25) da
+1
X
< n Xn;j >= m` `+j0 0 8j 1
`=0
perche ` + j 1 cos che `+j0 0.
Ma allora n e un vettore in Hn di norma 1 e ortogonale ad Hn;1 e percio
n "n 8n
ovvero la matrice A coincide con quella per cui
" = AX :
Tale matrice infatti e unica perche X e una base di Riesz.
Il risultato di questo paragrafo sta nell'aver dimostrato, anche in maniera
costruttiva, come calcolare la predizione lineare ottimale di un processo, noto
no al tempo n, quando se ne conoscano la covarianza C (k), ovvero lo spettro
f (p). Nel prossimo paragrafo ci occuperemo della stima di queste grandezze
a partire da una realizzazione di X .
150
3.6 Problemi di stima della funzione di covarianza e
dello spettro
Supponiamo che di un processo stazionario X sia nota una realizzazione, per
un numero limitato di tempi N , che chiameremo
(3.6.1)
x+N = fx1 x2 : : : xN g spesso ci verra comodo pensare a questo vettore prolungato con valori nulli
nel tempo in entrambe le direzioni, ponendo
x+0 f: : : 0 x1 : : : xN 0 : : :g (3.6.2)
ci poniamo il problema di stimare C (k) e/o f (p) a partire da xN , tenendo
presente che la proprieta per noi piu importante degli stimatori sara la consistenza, in quanto e noto che una stima di una covarianza da un campione
non numeroso puo contenere errori rilevanti.
a) Stima della funzione di covarianza
Uno stimatore ovviamente corretto di Ck e dato da
N ;k
1
Ck = N ; k Xj Xj+k (k < N ) j =1
b
X
(3.6.3)
questo stimatore sfrutta a fondo il concetto di stazionarieta utilizzando una
replica traslata di k tempi del vettore xN come una nuova realizzazione del
processo.
I valori empirici Ck ottenuti dalla (3.6.3) tuttavia in genere non possono essere
direttamente presi come se appartenessero ad una funzione di covarianza
come mostra il seguente controesempio.
b
Esempio 3.6.1: sia N = 3 x3 = f1 0 1g mediante la (3.6.3) si possono
stimare i tre valori
Cb0 = 23 Cb1 = 0 Cb2 = 1 che non possono appartenere ad una funzione di covarianza in quanto
C2 > C0.
b b
151
b
Tuttavia i valori empirici Ck , che costituiscono la cosiddetta funzione di covarianza empirica, possono essere interpolati con un qualche modello appartenente ad una delle famiglie parametriche illustrate nel x3.3 o ad una loro
combinazione.
Osservazione 3.6.1: i valori empirici Ck di solito non vengono stimati per
valori di k che vanno oltre il 20% di N poiche all'aumentare di k diminuisce
il numero di coppie disponibili per formare Ck e la stima diviene piu erratica inoltre ad un intervallo di 0 2N la funzione di covarianza deve gia aver
mostrato tutti i suoi caratteri salienti, se no vuol dire che il numero di dati
disponibili non e su!ciente per svolgere il tipo di stima richiesto.
Esempio 3.6.2: si prenda la funzione di covarianza empirica in Fig. 3.6.1.
Essa e stata generata da un campione di numerosita N = 100 di un processo
normale con covarianza
C (k)e;01jkj :
b
b
Come si vede la funzione empirica tende a zero senza mostrare oscillazioni
signicative e con un marcato approccio a cuspide nell'origine. Scelto percio
il modello Ck = C0e;jkj si sono stimati i parametri C0 ed ottenendo
l'interpolazione mostrata pure in Fig. 3.6.1
Fig. 3.6.1 Interpolazione della funzione di covarianza empirica con il
modello Ck = C0e;jkj C0 = 1 = 0:1.
In Fig. 3.6.2 e Fig. 3.6.3 mostriamo esperimenti analoghi per i modelli
C (k) = C0e;k2 (C0 = 1 = 0:1)
e
):
C (k) = C0e;jkj cos !k (C0 = 1 = 0:1 ! = 10
152
Fig. 3.6.2 Interpolazione della funzione
di covarianza empirica con il
2
;
k
modello Ck = C0 e C0 = 1 = 0:1.
Fig. 3.6.3 Interpolazione della funzione di covarianza empirica con il
modello Ck = C0e;jkj cos !k C0 = 1 = 0:1.
Nel primo caso la scelta della funzione interpolante della famiglia corretta e
suggerita dalla velocita di annullamento, dall'assenza di oscillazioni signicative e della forma sostanzialmente piatta nell'origine. Nel secondo caso la
scelta di una esponenziale coseno e dettata dalla cadenza di zeri, massimi e
minimi e del comportamento nell'origine.
Se anziche usare la procedura sopra descritta, si cercasse al posto di (3.6.3)
uno stimatore empirico Ck che possa essere usato direttamente come funzione
di covarianza, si potrebbe porre
N ;k
1
Ck = N Xj Xj+k :
(3.6.4)
j =1
e
e
X
Lemma 3.6.1: lo stimatore Cek dato della (3.6.4) da luogo ad una funzione
denita positiva.
In eetti sia x0 come in (3.6.2). Notiamo che
N Ce;`
=
x+0B `x0 =
XN xkxk;` =
k=`+1
N ;`
= x+0B ;`x0 =
153
Xxkxk;` = N Ce` k=1
pertanto, ricordando che B ;1 = B + = F ,
N
X
N ik Cei;k
=
ik=1
N
X
N ik x+0B i;k x0 =
ik=1
"XN #+ "XN #
= Nx+0
k=1
k B k
i=1
iB i x0 0 :
e
Si puo anche notare che Ck , benche non sia uno stimatore corretto di Ck , lo
e almeno asintoticamente in quanto
E fCk g = N N; k Ck (N;!
(3.6.5)
!1) Ck :
e
e
e
e
D'altro canto se Ck e uno stimatore consistente di Ck , altrettanto lo e Ck =
N ;k C pertanto C e uno stimatore accettabile di C , a condizione che sia
k
k
N k
consistente. A questa questione risponde un teorema dovuto a Bartlett.
Teorema 3.6.1: supponiamo che X sia un processo stazionario del tipo
(3.6.6)
X = A
b
con rumore bianco in senso forte (ovvero le componenti k j k 6= j sono
tra loro stocasticamente indipendenti) e con A 2 T1, ovvero
+1
+1
X
X
Xn =
an;k k jak j < +1 (3.6.7)
supponiamo inoltre che j abbia momento quarto nito
E fj4g < +1 (3.6.8)
k=;1
k=;1
allora vale la formula asintotica 10
+1
(C` C`+h) = 1
(Ck Ck+h + Ck+`+hCk;`)+
e e
N
X
(X
k=;1
X
In eetti se A 2 T1 anche C = AA+ 2 T1 , come si e visto nel Lemma 3.2.2 pertanto
jC` j < +1 ) C`2 < +1
cos che le serie in (3.6.9) sono convergenti.
10
154
1
+ (M4 ; 3)C`C`+hg + o N
:
(3.6.9)
Notiamo che la (3.6.9) per h = 0 ci dice che
(Ce`) = 0
questa unita al fatto che
1
(3.6.10)
lim E fC`g = C`
(3.6.11)
N !1
N
e
e
ci permette di aermare che C` ! C` in L2() e dunque anche in probabilita,
cos che C` e uno stimatore consistente di C`.
Ci limitiamo ad accennare la dimostrazione del Teorema solo nel caso
Xn = n (A = I ). In questo caso, quando ` 6= 0,
e
N
X
1
2
e
E fC` g = N 2 E fii+`k k+`g :
ik=1
Notiamo che se i 6= k il secondo termine e 0, mentre per i = k(` 6= 0)
risulta
E fii+`k i+`g = E fi2gE fi2+`g = 1 :
Pertanto, ricordando che C` = 0 perche Xn = n,
E fC`2g = 2 (C`) = NN;2 ` = N1 + o N1
e
e
come risulta anche nella (3.6.9) quando C` = `0.
Se ora invece prendiamo
XN
E fCe02g = N12 E fi2k2g =
ik=1
X
N
1
= 2 (M4 ; 1)ik + 1] = 1 + M4 ; 1 N ik01
N
155
ricordando che C0 = 1 (essendo Xn = n) si vede che tale relazione coincide
con la (3.6.9), essendo
2 (C0) = M4N; 1 :
e
b) Stima dello spettro
e
Naturalmente ogni stima di Ck che sia anche denita positiva, come Ck , da
luogo ad una stima della densita spettrale f (p) con la formula
N ;1
N ;1
f (p) = C0 + 2 Ck cos k2p Ck eik2
p
(3.6.12)
k=;1
k=;N +1
e
Xe
e
X e
Vale il seguente Lemma.
Lemma 3.6.2: risulta
fe(p) = IN (p) :
(3.6.13)
Il periodogramma IN (p) e denito in (3.4.4).
Questa identita e gia stata dimostrata nel Lemma 3.4.2.
Ricordando la proprieta (3.4.5) di IN (p) si vede che f (p) e uno stimatore
asintoticamente corretto. Tuttavia sfortunatamente f (p) non e uno stimatore consistente di f (p) puntualmente in p, come e dimostrato dal seguente
controesempio.
e
e
Esempio 3.6.3: sia fng un rumore bianco gaussiano. Posto
X
2
X
4
2
N
1
IN (p) = N
k eik2
p =
k=1
2
N
1
=
N k=1 k cos k2p +
! XN
!23
k sin k2p 5 notiamo che le due variabili
UN =
k=1
XN k cos k2p VN = XN k sin k2p
k=1
k=1
156
sono congiuntamente normali, con media nulla ed inoltre, preso p = Nn = rs
con k < s interi e successivamente N = Ms n = Mr in modo che p resti
costante 8M , si ha
n o XN
E UN2 Nn = cos2 k2Nn = N2
k=1
N
n
o
X
n
2
E VN N = sin2 k2Nn = N2 :
k=1
Ancora, vale
E fUN VN g =
XN cos k2n sin k2n = 0
k=1
di conseguenza si vede che
f rs = IN
= 1
2
N
N
r = 1 2 U2 + 2 V 2 =
sUN2 2 N VNN2 N 1N 2
e 2(UN ) + 2(VN ) = 2 2
e; rs non puo convergere ad
;
indipendentemente da N = Ms. Ne segue che f
una costante, f rs , per N = Ms.
e
Sebbene non valga una convergenza in probabilita di f (p) ad f (p) per ogni
p, tuttavia si puo dimostrare che si ha sempre una convergenza in media
quadratica di funzionali piu regolari di f (p) agli stessi funzionali di f (p). Piu
precisamente vale il seguente Lemma che enunciamo senza dimostrazione:
e
Lemma 3.6.3: 8'(p) misurabile limitata si ha
Z 1e
Z1
lim E f f (p)'(p)dpg = f (p)'(p)dp
N !1
0
0
Z
1
2
e
lim f
N !1
0
f (p)'(p)dpg = 0 :
157
(3.6.14)
(3.6.15)
e
Il Lemma 3.6.3 aerma essenzialmente che una versione lisciata di f (p) tende
in media quadratica ad un'analoga versione lisciata di f (p).
Sulla scorta del Lemma 3.6.3, si e costruita una teoria per gli stimatori
\lisciati" dello spettro.
Denizione 3.6.1: un lisciatore o nestra e una funzione w(p) che per
semplicita supponiamo pari, continua con tutte le derivate richieste, tale che
w(p) = 0
e tale che
Z 1=2
;1=2
jpj > w(p)dp = 1 :
158
(3.6.16)
(3.6.17)
Un esempio tipico e dato in Fig.
3.6.4
Dato w(p) si puo generare da questa una famiglia parametrica, traslando il
picco in p e cambiando l'ampiezza di w(p) pur mantenendo la condizione
(3.6.17)
w(p ; p) = w(p ; p)] :
(3.6.18)
Notiamo che ssato p e 8 sso w(p ; p) e una funzione continua e limitata,
cos che in base al Lemma 3.6.3 risulta che
f N(p) =
Z 1=2
w (p ; p)fe(p)dp
(3.6.19)
w(p ; p)f (p)dp :
(3.6.20)
;1=2
e uno stimatore consistente di
f (p) =
Z 1=2
;1=2
D'altro canto, essendo f (p) continua, appare chiaro che
lim f (p)
!1 =
Z 1=2
lim
w (p ; p)f (p)dp =
!1 1=2 Z +1 q = lim
!1 ;1 w(q)f p ; dq = f (p) cos che si e pensato che agendo contemporaneamente su e su N si potesse
ottenere una successione S NN che tenda in media quadratica ad f (p). In
eetti vale il seguente Lemma, che non dimostriamo.
159
Lemma 3.6.4: sia f (p) lo spettro corrispondente ad una covarianza C 2 T1
e sia N tale che
allora, 8p
N ! +1 NN ! 0 (3.6.21)
lim E ff NN g = f (p)
lim 2(f NN ) = 0 :
N !1
N !1
Osservazione 3.6.2: l'eetto dell'uso di w(p ; p) per costruire f N(p)
puo essere anche visto in termini di covarianza. In eetti ci si puo chiedere
quale sia la covarianza C (k) corrispondente a f N(p). Poiche w(p) e una
funzione pari si potra porre
+1
w(p) = wn cos 2np X
n=0
sostituendo questa relazione nella (3.6.19) vediamo che
N ;1
f N(p) = C0w0 + 2 Cnwn cos n2p :
e
Xe
n=1
Questa equazione ci dice che e semplicemente
C (k) = Ck wk :
(3.6.22)
Esempio 3.6.4: esempi di alcune tra le nestre piu usate per le stime spettrali sono associate ai coe!cienti di Fourier:
1
k
0kM
Finestra di Tuckey wk = w;k = 02 1 + cos M
k>M
2
k
k
1 ; 6 M + 6 M 3 0 k M2
M <kM
Finestra di Parzen wk = w;k =
2 1 ; Mk 3
2
0
k>M
1
k=0
Mk
sin N 2
Finestra di Daniell wk = w;k =
0<k N ;1
M sin Nk 2
e
;
8< ; ; ; :
8<
:
160
In tutti questi casi M prende il posto del parametro una regola empirica,
ma ben funzionante per la scelta di M e
p
M
=2 N :
In tutti i casi come si vede, per k sso
lim w (M ) = 1 :
M !1 k
3.7 Processi semplici
Deniamo semplici quei processi X la cui funzione di trasferimento tra innovazione " ed X ,
M (p) = M (z)jz=ei2p
(3.7.1)
ha la forma di una funzione trigonometrica razionale, ovvero
PL(z) M (z) = Q
h (z )
(3.7.2)
con PL Qh polinomi rispettivamente di grado L ed h.
Ricordando la discussione del x3.5, imponiamo ad M (z) di essere una funzione analitica in tutto il cerchio fjzj 1g ed anche ivi jM (z)j 6= 0 oltre a
soddisfare la (3.5.7), ovvero
jM (ei2
p )j = M (ei2
p )M (e;i2
p ) = f (p) :
(3.7.3)
Ne deduciamo in generale che PL Qh devono necessariamente soddisfare le
condizioni
PL(z) 6= 0 Qh(z) 6= 0 in fjzj 1g (3.7.4)
inoltre e logico usare per M (z) una rappresentazione irriducibile cos che
supporremo che PL e Qh non abbiano zeri in comune inne notando che PL
e Qh possono essere moltiplicati per una costante senza modicare M (z),
possiamo scegliere arbitrariamente un loro coe!ciente (purche 6= 0) ed in
specico assumeremo
(3.7.5)
q0 1 :
161
Osservazione 3.7.1: notiamo che se in M (z) si sostituisce z con B si ottiene
proprio l'operatore M matriciale per cui
X = M" = M (B )"
ovvero l'operatore in HX per cui
PL(B) " :
Xn = M"n = M (B)"n = Q
(B) n
h
(3.7.6)
La (3.7.6) moltiplicata per Qh(B) da
Qh(B)Xn = PL (B)"n
(3.7.7)
Xn + q1 Xn;1 + : : : qhXn;h = p0"n + pi"n;1 : : : + pL"n;L (3.7.8)
ovvero
un processo che segue una legge del tipo (3.7.8) viene anche detto autoregressivo e di media mobile (ARMA dall'inglese autoregressive-moving average).
La parte Qh(B ) e detta la parte autoregressiva dell'operatore mentre PL(B )
e detta la parte di media mobile.
I processi per cui Qh 1 sono detti di pura media mobile, o sinteticamente
MA, mentre quelli per cui PL p0 sono detti puramente autoregressivi,
ovvero AR. Per sfruttare meglio le loro specicita, dividiamo la trattazione
dei MA degli AR.
a) Processi a media mobile
In questo caso (cfr. (3.4.3), (3.2.25))
M (z) PL(z) = p0 + p1z : : : pLzL mk = pk
XL
2
L
X
i
2
kp
f (p) = mk e = C0 + 2 Ck cos 2kp k=0
k=1
L
X
Ck = m`m`;k (0 k L) :
k =`
162
(3.7.9)
(3.7.10)
(3.7.11)
Si noti che la caratteristica di questo processo e che
Ck 0 k > L
(3.7.12)
cioe il processo perde completamente memoria del passato dopo un intervallo
di tempo maggiore di L, cosa questa che aiuta anche ad identicare questi
processi partendo da una covarianza empirica.
L'equazione di evoluzione del processo e
Xn =
XL mk"n;k k=0
(3.7.13)
cioe appunto quella di una media mobile monolaterale (solo verso il passato).
Il problema della predizione ottimale per X , dati (X1 X2 : : : XN ) e invece
piu complesso di quanto sembri infatti se da un lato scrivendo la (3.7.13)
nella forma
j ;1
L
XN +j = mk "N +j;k + mk "N +j;k (j L)
(3.7.14)
X
X
k=0
k=j
si rende subito evidente che il termine
j ;1
mk "N +j;k ? HN X
k=j
cos che esso entrera per forza a far parte dell'errore di stima, non si deve commettere l'errore di credere che "N "N ;1 : : : 2 H1N = SpanfX1 X2 : : : XN g.
Infatti, ad esempio, l'innovazione "N dipende in generale anche da X0 X;1 : : :
cos che la sua proiezione ortogonale su H1N non e banale da ottenersi. Tuttavia, come mostreremo esplicitamente negli esempi, quando N e grande
rispetto ad L e possibile ottenere una soddisfacente approssimazione degli " necessari nella (3.7.14) in termini di X1 : : : XN . Notiamo anche che
chiaramente per j > L
P1N XN +j = 0 (j > L)
(3.7.15)
P1N = proiettore ortogonale su H1N
cos che
Ej21N = m20 + : : : + m2L (j > L)
(3.7.16)
163
Esempio 3.7.1: (MA1). In questo caso
M (z) = M0 + m1 z
e l'equazione di evoluzione e
Xn = m0 "n + m1 "n;1
Cos le (3.7.11) danno
8< C0 = m20 + m21
: CC1k == m0 0m1
(k > 1)
(3.7.17)
La condizione (3.7.4) limita le eventuali soluzioni della (3.7.17) a quelle che
soddisfano la condizione
jm1 j < jm0 j (3.7.18)
notiamo che in particolare si puo sempre assumere
m0 > 0 (3.7.19)
poiche tutt'al piu si puo cambiare segno ad m0 m1 e ad f"ng, il che naturalmente non cambia la natura di rumore bianco di tale successione.
Notiamo anche che della (3.7.17) si puo scrivere
C0 + 2C1 = (m0 + m1)2
C0 ; 2C1 = (m0 ; m1 )2
il che prova anche che deve essere
jC1j < 21 C0 questa condizione peraltro e anche necessaria perche lo spettro
f (p) = C0 + 2C1 cos 2p
164
(3.7.20)
sia strettamente positivo.
Dalle (3.7.20) possiamo ricavare m0 m1 in funzione della covarianza C0 C1
la sola soluzione che soddis le condizioni (3.7.18), (3.7.19) e
m0 = 1 ;pC0 + 2C1 + pC0 ; 2C1
2 ;p
p
m1 = 1 C0 + 2C1 ; C0 ; 2C1 :
2
(3.7.21)
b
Inne, osservato che dati X1 : : : XN la predizione di XN +2 e XN +2 = 0 con
e.q.m
E 2 = m20 + m21 = C0 :
b
Cerchiamo invece XN +1 poiche
XN +1 = m0"N +1 + m1"N
e chiaro che
XbN +1 = m1"bN
b
(3.7.22)
con "N la proiezione di "N su H1N .
Ora notiamo che
"N = A(B)XN
dove
A(z) = M1(z) = m (1 +1 m1 z) :
0
m0
Poiche, posto = mm01 , deve essere j j < 1, risulta anche
+1
1
A(z) = m (; )k zk 0 k=0
X
cioe
"N = m1
0
"NX;1
k=0
#
+1
X
(; )k XN ;k + (; )k XN ;k :
k=N
165
(3.7.23)
Consideriamo il secondo termine in parentesi quadra nella (3.7.23) si ha,
ricordando che k Xn k2 = C0,
+1
+1
N
k
(; ) XN ;k j jk k XN ;k k= C0 1j; j j j X
k=N
X
k=N
p
cos che se j j non e troppo vicino ad 1 ed N e abbastanza grande, tale
termine e trascurabile e possiamo porre
1 N ;1
(3.7.24)
"N = m (; )k XN ;k = "N 2 H1N :
0 k=0
X
b
b
La (3.7.24) usata nella (3.7.22) fornisce il predittore ricercato XN +1 il suo
e.q.m. di stima inoltre sara
E12 = m20 :
(3.7.25)
Osservazione 3.7.2: si noti che, partendo da un rumore bianco fng e
sempre possibile denire un processo fXng mediante un operatore di media
mobile
Xn = m0 n + m1 n;1 qualsiasi siano i valori di m0 m1 fXng risulta stazionario, con una covarianza
che soddisfa la (3.7.17). In particolare cio e vero anche quando jm1j > jm0j
cos che il polinomio caratteristico m0 + m1 ammette una radice interna al
cerchio unitario. Cio sembrerebbe in contraddizione con la teoria svolta nel
x3.5 in cui si garantiva l'esistenza e l'unicita di M (z), che per di piu non si
annullasse nel cerchio unitario. Tale contraddizione pero non esiste in quanto
eettivamente esiste un solo M (z) con quelle caratteristiche in specico se
C0 = m20 + m21 C1 = m0m1 , con jm1 j > jm0j e chiaro che m00 = m1 m01 = m0
sono soluzioni delle stesse equazioni e per di piu soddisfano correttamente la
condizione (3.7.18). Questa osservazione ha carattere generale per tutti i
processi stazionari di media mobile.
Esempio 3.7.2: (MA2). In questo caso
M (z) = m0 + m1z + m2 z2
166
e l'equazione di evoluzione del processo e
Xn = m0 "n + m1"n;1 + m2 "n;2 :
Per le (3.7.11) le relazioni tra m0 m1 m2 e C0 C1 C2 sono
8< C0 = m20 + m21 + m22
: CC12 == mm00mm12 + m1m2
(3.7.26)
mentre lo spettro e dato da
f (p) = C0 + 2C1 cos 2p + 2C2 cos 4p :
In primo luogo cerchiamo di risolvere la (3.7.26) conviene porre
cos # cos m0 p
m1 = C0 sin # cos # sin m2 cos che la prima delle (3.7.26) e automaticamente soddisfatta mentre dalle
altre due, posto R1 = C1=C0 R2 = C2 =C0, si ricava
cos # sin #(cos + sin ) = R1
cos2 # cos sin = R1
Quadrando la prima e sostituendo cos2 # della seconda, posto x = cos sin si riduce il sistema all'equazione
(R12 ; 2R2 )x2 ; R2 (1 ; 2R2 )x + R22 = 0 :
(3.7.27)
Notando che 2x = sin 2, l'equazione (3.7.27) va risolta col vincolo
jxj 1=2 sostituendo all'indietro si trova
cos2 # = Rx2
167
(3.7.28)
il che dimostra che deve anche essere
0 < R2 1 x
se tale condizione e soddisfatta possiamo ricavare # dalla (3.7.28). Ulteriori
condizioni sulle soluzioni (m0 m1 m2 ) sono imposte dalla richiesta che il
polinomio P2 (z) = m0 + m1 z + m2 z2 non abbia radici nel cerchio unitario,
cio che implica necessariamente (ma la condizione non e su!ciente) che
jm0 j > jm2j jm1 j > 2jm2j :
Quanto al problema della predizione, come gia nel caso del processo MA1,
notiamo che hanno senso solo (XN +1)1N (XN +2)1N in quanto
b
b
b
(XN +j )1N = 0 j > 2 :
In particolare si ha
( (Xb ) = m ("b ) + m ("b )
N +1 1N
1 N 1N
2 N ;1 1N
b
(XN +2 )1N = m2 ("bN )1N :
Vediamo che, come gia nel caso MA1, si puo spesso porre
("N ;1)1N = "N ;1 ("N )1N = "N
b
b
(3.7.29)
(3.7.30)
il che ci da come valore approssimato dell'e.q.m. di stima per le (3.7.29) le
espressioni
E12 = m20
E22 = m20 + m21 mentre 8j > 2 risulta
Ej2 = m20 + m21 + m22 = C0 :
Per vericare le (3.7.30) esprimiamo "N in funzione di fXn n N g. Osservando che
"N = M (B );1 XN = m1 (I ; 1B );1(I ; 2B );1XN 0
168
dove 1 2 sono gli inversi delle radici di M (z), cos che
j1j j2j < 1 (3.7.31)
usiamo la consueta serie di Neuman
+1
X
;
1
(I ; B ) = k B k
k=0
per ottenere
+1
X
"N = m1
1k 2hB k+hXN =
0 kh=0
!
+1 X̀
X
1
1k 2`;k XN ;` :
= m
0 `=0 k=0
Per la condizione (3.7.31) vale la maggiorazione
X̀ 1k2`;k `` k=0 cos che
X
! p N
+1 X̀
`=N k=0 1h2`;k XN ;` C0 (1 ; )2 N (1 ; ) + ] (3.7.32)
che e una quantita certamente piccola se non e troppo vicino ad 1 ed N e
abbastanza grande. Quando la (3.7.32) sia trascurabile, vale la (3.7.30) e si
potra porre
1 N ;2
("N ;1)1N "
1k 2`;k XN ;1;`
= N ;1 = m
0 `=0 k=0
N ;1
1
1k 2`;k XN ;` :
("N )1N = "N = m
0 `=0 k=0
b
b
X X̀ !
X X̀ !
169
b) Processi autoregressivi
In questo caso si ha per denizione
M (z) = Qp(0z) (q0 = 1)
h
2
f (p) = h p0 2 X i2
kp
qke (3.7.33)
(3.7.34)
k=0
la relazione tra mk e qk in questo non e aatto semplice e cos la relazione
tra mk e Ck .
Considerando invece che
A(z) = M ;1 (z) e elementare la relazione tra ak e qk , cioe
ak = pqk k = 0 1 : : : h :
0
Poiche il processo X soddisfa l'equazione
A(B )X = " si ha
a0Xn + a1Xn;1 : : : + ahXn;h = "n (3.7.35)
da cui il nome per X di processo autoregressivo di ordine h.
Cerchiamo la relazione generale che lega gli ak (ovvero p0 e i qk ) alla covarianza Ck . In primo luogo osserviamo che essendo
A
M =I con A e M entrambe triangolari basse, si deve avere pure
a0m0 = 1 m0 = a1 = p0 0
170
(3.7.36)
inoltre da C = MM + si ha anche
AC = M + (3.7.37)
con M + triangolare alta, che sulla diagonale principale ha p0 per la (3.7.36).
Rappresentando il prodotto (3.7.37) come in Fig. 3.7.1
k<j j
j
...
...
.
.
.. ..
...
... 0
... C C C C
. . . a 0 ...
0
1
2
3
0
.
. . C1 C0 C1 C2 . . .
... a a
A
C =
0
1
0
j : : : a2 a1 a0 0
j : : : C2 C1 C0 C1 . . .
a3 a2 a1 a0
C3 C2 C1 C0 . . .
... ... ... ...
... ... ... ...
k<j j
...
...
...
p0 * * *
0 p0 * *
= M+
j : : : 0 0 p0 *
0
0
0 p0
...
Fig. 3.7.1
si riconosce che deve essere
a0 C` + a1C`;1 + : : : + ahC`;h = p0`0 ` = 0 1 : : : h (a0 = p;0 1) :
(3.7.38)
Le (3.7.38) vanno sotto il nome di equazioni di Yule-Walker e si scrivono
esplicitamente come
a0C0 + a1C1 + : : : + ahCh = p0
a0C1 + a1C0 + : : : + ahCh;1 = 0
(3.7.39)
::::::::::::::::::::::::::::::
a0Ch + a1 Ch;1 + : : : + ahC0 = 0 :
8>
<
>:
171
Queste equazioni possono essere usate in duplice modo: o per ricavare la
funzione di covarianza fCk g, da a+ = a0 a1 : : : ah] o viceversa per ricavare a
da fCk g. Nel primo caso si risolve (3.7.39) rispetto a C0 C1 : : : Ch] e poi si
imbocca la relazione ricorsiva
Ck = ; aa1 Ck;1 : : : ; aah Ck;h (k > h) 0
0
che pure deriva dalla (3.7.37).
Nel secondo caso, chiamando ancora con Ch la matrice di Toeplitz e con e0
il vettore
1
C0 C1 : : : Ch
0
Ch = C1 . . . . . . C1 e0 = ..
.
Ch C1 . . . C0
0
poniamo
ea = Ch;1e0
da cui si vede che il vettore a soluzione della (3.7.39) e dato da
a = p0ea :
Ora notiamo che
(3.7.40)
ea0 = e+0ea = e+0Ch;1e0 > 0
poiche Ch e denita positiva, cos che dalla (3.7.40), ricordando la (3.7.38),
troviamo
a0 = e+0a = p0 a0
cioe
e
p
p
a0 = ea0 p0 = 1= ea0 :
Con cio dalla (3.7.40) si trova la soluzione completa.
Occupiamoci ora del problema della predizione che e conveniente risolvere a
passi.
172
A passo 1 avremo
XN +1 = ;p0 a1XN : : : ; p0ahXN +1;h + p0"N +1 se h N e chiaro che XN : : : XN +1;h 2 H1N mentre "N +1 ? H1N cos che
si ha banalmente
(XN +1 )1N = ;p0 a1XN : : : ; p0 ahXN +1;h
(3.7.41)
E12 = p20 b
che risolve il nostro problema.
Vediamo come agire a passo 2 in primo luogo abbiamo
XN +2 = ;p0 a1 XN +1 ; p0a2 XN : : : ; p0ahXN +2;h + p0 "N +2
da cui immediatamente ricaviamo
b
b
(XN +2 )1N = ;p0 a1(XN +1 )1N ; p0a2 XN : : : ; p0ahXN +2;h
b
(3.7.42)
dove (XN +1)1N e dato dalle (3.7.41).
In questo caso l'errore di predizione e
XN +2 ; (XN +2) = ;p0 a1XN +1 ; (XN +1)1N ] + p0 "N +2 =
= ;p0 a1p0 "N +1] + p0 "N +2
b
b
cos che l'e.q.m. di predizione a passo 2 e
E22 = p40 a21 + p20 :
(3.7.43)
Procedendo in modo analogo si ricavano iterativamente predizioni ed e.q.m.
di predizione per ogni passo.
Esempio 3.7.3: (AR1). In questo caso abbiamo
Q(z) = 1 + q1 z cos che l'equazione evolutiva del processo e
a0Xn + a1 Xn;1 = "n (a0 = p;0 1 a1 = p;0 1 q1) 173
ovvero
Xn = q1 Xn;1 + p0 "n
Notiamo che se deve essere jQ(z)j > 0 in fjzj 1g si deve avere
a1 jq1j = a < 1 :
0
Le (3.7.39) per un processo AR1 sono
a0C0 + a1C1 = p0
a0 C1 + a1 C0 = 0
(3.7.44)
a0Ck + a1 Ck;1 = 0 :
(3.7.45)
e, per k > 1,
Supposto di conoscere a0 a1 dalle (3.7.44) troviamo
8>
< C0 = 1 ;p20q12
>:
C1 = (;q1 )C0
e cos dalle (3.7.45) si ricava
Ck = (;q1 )k C0 (3.7.46)
che fornisce la forma generale della covarianza di un AR1.
Si puo notare che se q1 > 0 Ck e oscillante mentre se q1 < 0 Ck e monotona
in ogni caso essendo jCk j = jq1jk C0 si vede che la covarianza deve decadere
esponenzialmente a zero. Inoltre lo spettro del processo e dato da
f (p) = ja + a 1eo21pipj2 = 1 + q2 + 21q cos 2p 0
1
1
1
che come si vede e sempre positivo essendo jq1j < 1.
174
Viceversa le (3.7.44) possono essere risolte per a0 a1
a0 =
a1 =
s
C0
2
C0 ; C12
; CC1 a0 :
0
(p0 = a;0 1 ) Inne il procedimento di predizione visto alle (3.7.41), (3.7.42), (3.7.43), per
un AR1 da
(XbN +1)1N = ;q1XN
E12 = p20
(XbN +2)1N = q12XN
E22 = p20 + p40 a2 ; 1 = p20 (1 + q12 )
ed e facile vedere che piu in generale
8< (XbN +j )1N = (;q1)j XN
: Ej2 = p201 + q12 + : : : + q12(j;1)] :
Esempio 3.7.4: (AR2). In questo caso si ha
Q(z) = 1 + q1 z + q2z2
e l'equazione d'evoluzione del processo e
a0Xn + a1 Xn;1 + a2 Xn;2 = "n
ovvero
Xn = ;q1 Xn;1 ; q2Xn;2 + p0 "n :
Le equazioni di Yule-Walker sono
8< a0C0 + a1C1 + a2C2 = p0
: aa00CC12 ++ aa11CC01 ++ aa22CC10 == 00 175
a cui si puo aggiungere l'equazione ricorsiva
a0 Ck + a1 Ck;1 + a2Ck;2 = 0 (k > 2)
(3.7.47)
ovvero
Ck = ;q1 Ck;1 ; q2 Ck;2 (k > 2)
La soluzione delle equazioni di Yule-Walker rispetto a Ck e data da
+ a2
C0 = D1 aa0 ;
0 a2
C1 = ; D1 a a;1 a
0
2
8>
>>
>>
>><
>> 1 a21 ; a22 ; a0a2
>> C2 = D a0(a0 ; a2)
>>
>: (D = (a + a )2 ; a2) :
0
2
(3.7.48)
1
Si osservi che le (3.7.48) impongono dei limiti sui valori di C0 C1 C2, in
quanto deve necessariamente essre a0 6= a2 e ja0 + a2j 6= ja1j. La forma
generale della funzione di covarianza Ck va ricavata risolvendo la (3.7.47),
cio che richiede una certa discussione.
Intanto consideriamo la decomposizione del polinomio caratteristico
Q(z) = (1 ; 1z)(1 ; 2z) come si vede 1 2 sono gli inversi degli zeri del polinomio e quindi per ipotesi
devono soddisfare la diseguaglianza j1j j2j < 1.
Notiamo intanto che se 1 6= 2, le funzioni di k 1k 2k sono soluzioni particolari della (3.7.47) tra loro linearmente indipendenti pertanto la funzione
Ck = 11k + 2 2k (k > 1)
(3.7.49)
fornisce una soluzione generale della (3.7.47) dipendente da due costanti arbitrarie che possono a loro volta essere calcolate imponendo che la (3.7.49)
176
coincida con C0 C1 date dalla (3.7.48)
1 = 2C0;;C1
2
1
8>
><
>>: = 1C0 ; C1 :
2
1 ; 2
Si osservi che quando 1 2 sono complesse devono anche essere coniugate tra
loro 2 = 1 , cos che 2 ; 1 e immaginaria pura pertanto in tal caso risulta
pure 2 = 1 che garantisce la realta di Ck . Quando invece sia 1 2 = ,
che e quindi per forza un numero reale, tale che j j < 1, si ha
Ck = 1 k + 2kk (k > 1)
(3.7.50)
con 12 date da
<8 1 = C0 1
: 2 = C1 ; C0 :
Per completare la discussione notiamo inne che se 1 2 sono reali la (3.7.49)
da una combinazione di due esponenziali, possibilmente alternanti con k
quando 1 o 2 siano negativi,
1k = ()k e;1 k 2k = ()k e;2 k (1 2 > 0) :
Quando invece sia 2 = 1 = ei , si puo porre la (3.7.49) nella forma
Ck = Re;n cos(n + a) cioe di una esponenziale-coseno. Come sempre le equazioni di Yule-Walker
possono essere risolte rispetto ad a e ricordiamo che si puo porre (cfr. (3.7.40)
e seguenti)
a = p0 a p0 = p1 a0
nel nostro caso a puo essere esplicitamente scritto come
a0
2(C02 ; C12)
a1 = D C1(3C 2 ; C0) a2
2(C0C2 ; C12)
e e e e e
e
177
D = 2(C ; C )(C 21+ C C ; 2C 2) :
0
2 0
0 2
1
La densita spettrale del processo AR2 puo essere posta nella forma
2
2
p
p
0
f (P ) = jQ(ei2
p)j2 = (1 + a2 + a2 ) + 2(q + q0 ) cos 2p + 2q cos 2p :
1
2
2
1
2
Quanto alla predizione del processo, usando le (3.7.41), (3.7.42), (3.7.43) si
ha
(XN +1)1N = ;q1 XN ; q2XN ;1
E12 = p20 (XN +2)1N = (q12 ; q2)XN + q1q2 XN ;1
E22 = p20 (1 + q12 ) :
b
b
In modo analogo si ricavano le predizioni per i passi successivi.
c) I processi autoregressivi a media mobile
Anziche fare una trattazione generale dei processi ARMA ci limitiamo qui
a studiare il processo del tipo ARMA(1,1), corrispondente ad L = h = 1,
essendo peraltro tale esmpio facilmente generalizzabile.
Esempio 3.7.5: (ARMA (1,1). In questo caso si ha
M (z) = QP1((zz)) = p10 ++qp1zz :
1
(3.7.51)
Ricordiamo subito che dvoendo essere P1 (z) 6= 0 Q1 (z) 6= 0 nel cerchio jzj 1 si hanno le limitazioni
p0 > 0 jp0j > jp1j jq1 j < 1 :
Potendosi scrivere
ovvero
X = M (B )" = Q;1 1 (B )P1(B )"
Q1(B )X = P1 (B )" 178
(3.7.52)
l'equazione di evoluzione del processo risulta
Xn + q1Xn;1 = p0"n + p1"n;1 :
(3.7.53)
Le equazioni di Yule-Walker, che legano i tre parametri p0 p1 q1 alla funzione
di covarianza Ck , possono essere ricavate da
A(B )C = M +(B ) dove
A(B ) = M ;1 (B ) = P1;1(B )Q1 (B ) ovvero da
Q1 (B )C = P1(B )M + (B ) :
In eetti, notando che
M (z) = (p0 + p1z)(1 ; q1 z + q12z2 + 03 : : :) =
= p0 + (p1 ; p0q1 )z + 02
cos che
m0 = p0 m1 = p1 ; p0q1 si trova, ricordando che B fa scorre le colonne in giu di un posto,
m0 m1 ; ; 0 m0 m1 ; +
P (B )M (B ) = (p0 I + p1B ) 0 m00 mm10 =
j
...
...
p0 m0 + p1 m1
*
*
*
p0m0
p0 m0 + p1m1
*
*
j
::::::
p0m0
p0 m0 + p1m1
*
p0m0
p0 m0 + p1m1
.
...
..
0
analogamente
179
(3.7.54)
j
...
...
...
Q1 (B )C = j : : : C + q C C + q C C + q C
2
1 1
1
1 0
0
1 1
...
...
...
Da queste relazioni scrivendo la (3.7.54) per le componenti (k j ) con k j
si ha
C0 + q1 C1 = p0 m0 + p1m1 = p20 + p21 ; q1p1 p0
C1 + q1 C0 = p1 m0 = p0p1
(3.7.55)
Ck + q1 Ck;1 = 0 (k 2)
8<
:
Usando le (3.7.55) per ricavare Ck da p0 p1 q, si vede intanto che
Ck = (;q1 )(k;1) C1 (k 2)
cioe dal passo 2, Ck si comporta come la covarianza di un AR1 decadendo
esponenzialmente inoltre le prime due delle (3.7.55) danno
C0 = 1 p20 + p21 ; 2q1p0 p1
:
C1
1 ; q12 ;q1 (p20 + p21) ; (1 ; q12 )p0p1
Viceversa volendo usare le (3.7.55) per ricavare p0 p1 q1 da C0 C1 C2, si puo
intanto scrivere immediatamente
q1 = ; CC2 1
inoltre usando la seconda nella prima delle (3.7.55) queste equazioni si portano nella forma
p20 + p21 = (1 ; q12 )C0 + 2q1C1
p0p1 = C ; 1 + q1 C0 la cui unica soluzione soddisfacente (3.7.52) e
8> 1 hp
i
p
2
2
(1
+
2
q
;
q
)
C
+
2(1
+
q
)
C
+
(1
+
2
q
;
q
)
C
;
2(1
;
q
)
C
p
=
1
1 1
1
1 1
1 0
1 0
< 0 2
>: p1 = 1 hp(1 + 2q1 ; q12)C0 + 2(1 + q1)C1 ; p(1 + 2q1 ; q12)C0 ; 2(1 ; q1)C1 i :
2
180
La densita spettrale di un processo ARMA 1,1 e ricavata come al solito da
i2
p 2
2
2
1 cos 2p f (p) = jjQP1((eei2
p))jj2 = p01++pq12++22pq0pcos
2p
1
1
1
che, stanti le (3.7.52), e una funzione sempre positiva.
Inne occupiamoci del problema della predizione almeno per due passi a
partire da N .
Poiche si ha una parte di media mobile in M (B ), e chiaro che anche qui si
porra il problema di stimare ("N )1N . A questo scopo notiamo che posto
b
Yn = Xn + q1 Xn;1 risulta Yn 2 H1N n = 2 : : : N allora, riscritta la (3.7.53) come
"n = a0Yn ; "n;1
a0 = p;0 1 = pp1 (j j < 1) 0
si puo porre in via approssimata
N ;2
"N = a0 (; )k YN ;k = ("N )1N 2 H1N
X
b
b
k=0
considerando cos ("N )1N come nota con errore trascurabile.
Pertanto da
XN +1 = ;q1 XN + p0 "N +1 + p1"N
si vede immediatamente che, usando la (3.7.56),
(XbN +1)1N = ;q1XN + p1("bN )1N
E12 = p20 :
Inoltre da
XN +2 = ;q1 XN +1 + p0 "N +2 + p1"N +1 =
= ;q1 (XbN +1)1N + p0 "N +2 + (p1 ; q1 p0)"N +1 181
(3.7.56)
si vede che
(XbN +2)1N = ;q1(XbN +1)1N
2
2
2
E2 = p0 + (p1 ; q1p0 ) il procedimento puo poi essere continuato per le predizioni ai passi successivi.
182
Scaricare