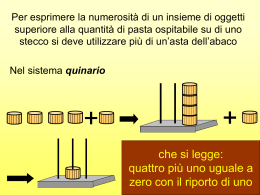
Introduzione alla teoria dell’informazione • misura dell’informazione • ridondanza • codifica di sorgente • robustezza • codifica di canale • decodifica dell’informazione biologica Francesco Piva Istituto di Biologia e Genetica Università Politecnica delle Marche [email protected] Struttura di comunicazione attraverso un canale trasmissivo Ci occupiamo della misura dell’informazione emessa da una sorgente la sorgente è tanto più efficiente quanto più risulta imprevedibile da parte del destinatario l’informazione che sarà emessa supponiamo che la sorgente di informazione sia un testo, se il destinatario già conosce quel testo, l’informazione emessa dalla sorgente è nulla se il destinatario non ha mai letto quel testo, la sorgente emette la massima informazione se il destinatario non conosce il testo ma conosce in modo generico l’informazione che si aspetta, allora l’informazione risulterà minore di quella massima con il termine linguaggio intendiamo una serie di regole su cui sorgenete e destinatario concordano per consentire il trasferimento di informazione dall’uno all’altro L’informazione contenuta in un messaggio ha l’effetto di cambiare lo stato di incertezza nei riguardi di una certa situazione. Dopo la ricezione del messaggio l’incertezza diminuisce o decade. Più il messaggio toglie incertezza più questo ha valore L’informazione è l’incertezza che si ha prima di ricevere il messaggio. Immaginiamo che io stia aspettando di sapere se una persona (Pippo) è o meno nel suo ufficio. Immaginiamo che ci sia il 70% delle probabilità di trovarlo nel suo ufficio e il 30% di trovarlo in altre stanze. Se mi informano che è nel suo ufficio, ho eliminato la mia incertezza, ma già la mia incertezza era bassa perché mi sarei aspettato di trovarlo in ufficio. Quindi questa informazione non ha un valore molto alto. Se mi informano che non è nel suo ufficio, ho risolto una maggiore incertezza perché c’erano meno probabilità che questo accadesse, cioè era una situazione più inaspettata, quindi avevo un’incertezza maggiore. Questa informazione ha più valore perché mi ha tolto una maggiore incertezza Se ho identiche probabilità di trovare Pippo nel suo ufficio, allora le due informazioni hanno lo stesso valore. Supponiamo che Pippo possa essere in 5 stanze diverse, e in ogni stanza con la stessa probabilità. Ho la probabilità del 20% che esso sia in una stanza. Un’informazione che mi risolve questo stato di incertezza ha molto valore perché molte erano le possibilità. Altro esempio: supponiamo di essere ad un esame e dover dare la risposta ad un quesito barrando una casella. Supponiamo di non conoscere la risposta alla domanda. Se le caselle, cioè le possibili risposte sono due, ho maggiori probabilità di barrare la risposta esatta. Se le caselle fossero 10 ho minore probabilità di barrare quella esatta. Da questo momento consideriamo l’equiprobabilità che si verifichi un certo stato tra N aspettati Consideriamo che l’informazione elementare viene portata da un simbolo che può assumere due soli stati: 0 e 1 N=2M Quindi la formula rappresenta il numero di stati che posso risolvere (discriminare) con una sequenza di M simboli di due stati Esempi di parole L’incertezza è tanto maggiore quanto è maggiore N All’arrivo del messaggio ho un’informazione tanto maggiore quanto più alta era l’incertezza, cioè quanto maggiore era N La quantità di informazione portata da un solo simbolo è i=log2N N=2 perché un simbolo a due stati mi permette di discriminare tra due eventi i=log22 = 1 bit La quantità di informazione portata da una sequenza di M simboli binari è i=log2(2M) = M log22 = log2N = M bit Se tutti gli N eventi che possono accadere (o gli N simboli che possono giungere) sono equiprobabili, poiché N = 1/P, possiamo scrivere la formula precedente in funzione della probabilità. La quantità di informazione portata da un simbolo è i = log2N = log2(1/P) = - log2(P) Se gli eventi o i simboli non si verificano con la stessa probabilità, ad esempio p(0) = 0.1 p(1) = 0.9 i0 = - log2(0.1) = 3.3 bit i1 = - log2(0.9) = 0.15 bit i simboli più rari portano più informazione Fin’ora abbiamo visto l’informazione portata da un preciso simbolo però in una conversazione, in una lettura, in una sequenza di dati di computer abbiamo a che fare con una lunga sequenza di simboli. Qual è l’informazione media per simbolo portata da una sequenza di simboli? imedio = P0 * i0 + P1 * i1 [bit per simbolo] Nel caso in cui 0 e 1 siano equiprobabili imedio = 0.5 * 1 + 0.5 * 1 = 1 bit Nel caso della non equiprobabilità precedente imedio = 0.1 * 3.3 + 0.9 * 0.15 = 0.46 bit Quindi una sorgente che emette simboli in modo equiprobabile ha la maggior efficienza informativa, cioè ciascun simbolo ha il massimo contenuto informativo o … a parità di informazione impiega meno simboli La quantità imedio = P0 * i0 + P1 * i1 è detta anche ENTROPIA (H) della sorgente di informazione Si nota che la massima entropia si ha per valori di P = 0.5 cioè per l’equiprobabilità degli stati 0 e 1. A questo punto si verifica il massimo trasferimento di informazione Estrazione di una sequenza consenso da dati sperimentali Frequenze delle singole lettere nella lingua italiana 0,15 0,12 0,09 0,06 0,03 0,00 a b c d e f g h i j k l m n o p q r s t u v w x y z _ Frequenze delle singole lettere nella lingua inglese 0,18 0,15 0,12 0,09 0,06 0,03 0,00 a b c d e f g h i j k l m n o p q r s t u v w x y z _ Frequenze delle singole lettere 0,18 italiano 0,15 inglese 0,12 0,09 0,06 0,03 0,00 a b c d e f g h i j k l m n o p q r s t u v w x y z _ RIDONDANZA Non equiprobabilità correlazione La ridondanza indica quanto diminuisce la capacità di una sorgente di inviare informazioni, a causa della non equiprobabilità e della correlazione tra i simboli. La correlazione è il legame tra i simboli che escono da una sorgente, è come dire che osservando la sequenza appena uscita, si possono trarre indicazioni sui simboli che stanno per uscire. Esempio: se stiamo leggendo un testo e in particolare una parola, di solito dalle prime lettere si intuisce già la parola intera. Questo perché c’è una correlazione tra le lettere di una parola. Le lettere più importanti alla comprensione sono le prime, queste portano anche più informazione. albergo albero alcool ali alimento allarme allegria allora alluvione alveolo alm… aln… alr als Parole proibite a causa delle regole di semantica che introducono correlazione E’ la tecnica usata dai software per scrivere messaggi sms sui telefonini aa ak au bd bn bx cg cq c_ dj dt ec em ew ff fp fz gi gs hb hl hv ie io iy jh jr ka kk ku ld ln lx mg mq m_ nj nt oc om ow pf pp pz qi qs rb rl rv se so sy th tr ua uk uu vd vn vx wg wq w_ xj xt yc ym yw zf zp zz _i _s frequenze di coppie di lettere in italiano 0,04 0,03 0,03 0,02 0,02 0,01 0,01 0,00 Vantaggi della correlazione tra caratteri: Irrobustiscono l’informazione quindi permettono di comprendere la parola anche se ci sfuggono alcuni caratteri, come nel caso di comunicazione disturbata da rumori di fondo Svantaggi Limitano il numero di parole diverse che possiamo comporre quindi abbiamo un linguaggio meno ricco di parole. Posso comporre la parola ‘almnqq’ ma questa non è una sequenza di simboli permessa dalle regole della semantica, cioè non c’è la giusta correlazione tra i caratteri. Altri esempi di correlazione sono l’articolo con il nome, il soggetto con il verbo. Codifica di sorgente Immaginiamo di dover trasmettere uno fra quattro possibili stati, possiamo utilizzare solo simboli binari A B C D 00 01 10 11 A B C D 00 01 10 11 Questa operazione che permette di associare dei simboli agli stati si chiama codifica che richiama l’idea di associare un codice Se i 4 stati sono equiprobabili la trasmissione ha già la massima efficienza P=0.25 P=0.125 P=0.5 P=0.125 Supponiamo ora che sia più probabile che dobbiamo trasmettere lo stato C e meno probabile di dover trasmettere B e D BCDACACCBACACCDC 01 10 11 00 10 00 10 10 01 00 10 00 10 10 11 10 i = 2 * 0.25 + 2 * 0.125 + 2 * 0,5 + 2 * 0.125 = 2 bit Per trasmettere uno stato uso in media due bit, per questa sequenza ne ho usati 32 A 01 P=0.25 Supponiamo ora di codificare in maniera diversa gli stati. B 001 P=0.125 Precisamente codifichiamo con sequenze più corte i C 1 P=0.5 simboli più probabili D 000 P=0.125 BCDACACCBACACCDC 001 1 000 01 1 01 1 1 001 01 1 01 1 1 000 1 i = 2 * 0.25 + 3 * 0.125 + 1 * 0,5 + 3 * 0.125 = 1.75 bit Per trasmettere uno stato uso in media 1.75 bit quindi trasmetto la stessa sequenza di prima ma con meno simboli, infatti ne ho usati 28. Ho attuato una compressione dell’informazione. Il primo ad usare questa tecnica fu Morse. I programmi di compressione tipo Winzip, Arj… analizzano la sequenza dei bit del file da comprimere, ricodificano il file associando sequenze di minor lunghezza a quelle più ricorrenti (codifica di Huffman) Se il file da comprimere ha molta ridondanza, cioè correlazione e non equiprobabilità dei simboli, allora questo si comprimerà molto. Questo tipo di compressione si basa sull’eliminazione delle ridondanze senza perdita di informazioni, vale a dire che il file compresso può essere riportato alla forma originale senza che il messaggio si sia degradato. Un altro tipo di compressione è quella con perdita di informazione. Questa oltre a sfruttare il principio precedente, elimina quelle informazioni ritenute poco importanti per la comprensione globale del messaggio. E’ il caso di compressioni di immagini in formato jpg o gif, queste comprimono molto ma provocano una certa perdita della qualità dell’immagine. La perdita è irreversibile perché si è scelto di memorizzare solo una certa parte delle informazioni. Uno svantaggio della compressione: un errore o un’incomprensione di un simbolo rischiano di compromettere la comprensione dell’intero messaggio. Esempio: se ci si perde qualche parola del discorso di una persona ridondante, quasi sicuramente si capirà il significato del messaggio. Il rumore Modello di un canale di trasmissione P00 0 P01 0 Simbolo ricevuto Simbolo trasmesso P10 1 P11 P01, P10: probabilità di errore 1 Distanza 0110100001010111011 0110100011010111011 Per determinare la distanza tra due sequenze si deve allinearle e colonna per colonna contare il numero di simboli differenti. In questo caso la distanza è 1 ovvero le due sequenze differiscono per un solo simbolo. 00 01 10 11 Le sequenze collegate dalle frecce distano fra loro 1 Le sequenze sulle diagonali distano 2 Concetto di distanza evoluzionistica e alberi filogenetici: posso dire che 00 e 01 sono imparentati direttamente, 11 è imparentato sia con 01 che con 10 ma non so da chi derivi. 000 001 010 011 100 101 110 111 011 001 010 000 111 110 101 Abbiamo disposto tutte le sequenze che si possono ottenere con tre bit, su un cubo in modo che le sequenze collegate direttamente avessero distanza 1. Si nota che per andare da 000 a 111 si devono verificare tre mutazioni ma si possono seguire molti percorsi diversi. 100 Distanza come robustezza: è più facile confondere 000 e 010 perché distano solo 1, una mutazione può far passare dall’uno all’altro, è più difficile confondere 000 e 111 perché ci vogliono tre mutazioni. Analogamente in un discorso è più probabile confondere ‘albero’ e ‘alberi’ piuttosto che ‘albero’ e ‘alluvione’. Ancora sulla robustezza Immaginiamo di dover trasmettere uno fra quattro possibili stati, possiamo utilizzare solo simboli binari A B C D 00 01 10 11 Questa operazione che permette di associare dei simboli agli stati si chiama codifica che richiama l’idea di associare un codice 01 11 sorgente destinatario disturbo Se avviene un errore durante la trasmissione, il destinatario riceve un messaggio sbagliato e non ha modo di accorgersi che c’è stato un errore A B C D 000 011 101 110 011 001 sorgente destinatario disturbo In questo caso il destinatario riceve una sequenza non permessa perché 001 non corrisponde a nulla di valido, quindi si accorge che c’è stato un errore di trasmissione. Ho ottenuto questo risultato codificando i 4 stati con sequenze a distanza 2 anziché 1, cioè ho distanziato gli stati in modo che un errore singolo non mi portasse direttamente a uno stato permesso 101 001 000 010 110 C non permesso A non permesso D A B C D 0000 1101 0111 1110 Fra gli stati A,C e A,D c’è distanza 3 Se trasmetto 0000 e al destinatario arriva 0001, quest’ultimo capisce che c’è stato un errore perché 0001è uno stato non permesso. Inoltre può anche ipotizzare che era stato trasmesso A perché è lo stato più vicino al simbolo ricevuto. Nel caso di canali non fortemente disturbati ovvero dove ogni 4 simboli si può avere al massimo un errore, il destinatario è in grado di correggere l’errore. 0111 1110 C D 0011 non permesso 0001 non permesso 0000 A 0010 0110 non permesso non permesso Altro modo di aumentare la robustezza di una codifica: Definire delle parole sinonime Codifico A con 000, ogni errore singolo produce delle parole a distanza 1 dala parola 000 Codifico A anche con 001, 010, 100. In questo modo tutte le parole a distanza 1 da 000 sono ancora dei sinonimi di A 100 A 101 001 000 010 011 C A A A D Questa tecnica si chiama codifica di canale Consiste nel codificare gli stati con più simboli del necessario così da poter distanziare le parole. In questo modo ho una trasmissione più robusta, cioè più immune agli errori. Pago questa robustezza con una diminuzione di efficienza perché trasmetto molti più simboli a parità di informazione. Dal punto di vista dei simboli impiegati per trasmettere (nello spazio) o memorizzare (nel tempo) un messaggio, la codifica di sorgente ha l’effetto contrario cella codifica di canale. La prima comprime, la seconda espande. Sequenze di DNA interpretate secondo la Teoria dell’Informazione il codice genetico è degenere, che cosa significa in termini numerici? . . . Ala Val Arg . . . GCA GTA CGA C C C G G G T T T AGA G 4 * 4 * 6 = 96 Combinazioni o parole sinonime GCAGTACGA GCAGTACGC GCAGTACGG GCAGTACGT GCAGTAAGA GCAGTAAGG GCAGTCCGA GCAGTCCGC GCAGTCCGG GCAGTCCGT GCAGTCAGA GCAGTCAGG GCAGTGCGA GCAGTGCGC GCAGTGCGG GCAGTGCGT GCAGTGAGA GCAGTGAGG GCAGTTCGA GCAGTTCGC GCAGTTCGG GCAGTTCGT GCAGTTAGA GCAGTTAGG GCCGTACGA GCCGTACGC GCCGTACGG GCCGTACGT GCCGTAAGA GCCGTAAGG GCCGTCCGA GCCGTCCGC GCCGTCCGG GCCGTCCGT GCCGTCAGA GCCGTCAGG GCCGTGCGA GCCGTGCGC GCCGTGCGG GCCGTGCGT GCCGTGAGA GCCGTGAGG GCCGTTCGA GCCGTTCGC GCCGTTCGG GCCGTTCGT GCCGTTAGA GCCGTTAGG GCGGTACGA GCGGTACGC GCGGTACGG GCGGTACGT GCGGTAAGA GCGGTAAGG GCGGTCCGA GCGGTCCGC GCGGTCCGG GCGGTCCGT GCGGTCAGA GCGGTCAGG GCGGTGCGA GCGGTGCGC GCGGTGCGG GCGGTGCGT GCGGTGAGA GCGGTGAGG GCGGTTCGA GCGGTTCGC GCGGTTCGG GCGGTTCGT GCGGTTAGA GCGGTTAGG GCTGTACGA GCTGTACGC GCTGTACGG GCTGTACGT GCTGTAAGA GCTGTAAGG GCTGTCCGA GCTGTCCGC GCTGTCCGG GCTGTCCGT GCTGTCAGA GCTGTCAGG GCTGTGCGA GCTGTGCGC GCTGTGCGG GCTGTGCGT GCTGTGAGA GCTGTGAGG GCTGTTCGA GCTGTTCGC GCTGTTCGG GCTGTTCGT GCTGTTAGA GCTGTTAGG Ma tutti questi sinonimi costituiscono veramente la robustezza? Si, dal punto di vista del codice genetico No, in assoluto, cioè per il fenotipo. Esistono altri linguaggi che specificano alcune tra le parole sinonime al fine di trasmettere informazioni per: • lo splicing • il ripiegamento dell’RNA • il tempo di vita dell’RNA • il trasporto dell’RNA • la stabilità del DNA (organizzazione in cromatina) • …? Messaggio: anche le mutazioni neutre vanno considerate come potenzialmente patogene
Scaricare