INGEGNERIA DEL SOFTWARE
Indice generale
1) Introduzione
2) Modelli di processo
3) Prject Management
4) Leggere scrivere requisiti
5) Casi d'uso
6) La progettazione del software
7) La progettazione orientata agli oggetti
8) UML e RUP
9) Design Patterns
10) La Progettazione di Architetture Software
11) La qualità del software
12) La manutenzione del software
Francesco Russo
1.
Intoduzione
Software: componente di un sistema di elaborazione (di larga diffusione -off the shelf- o commissionato da
un singolo committente); prodotto invisibile, intangibile, facilmente duplicabile ma costosissimo; macchina
astratta (ha un’architettura fatta di componenti e connettori); un servizio (ha un’interfaccia e si basa su una
infrastruttura). Categorie di sw: Middleware, Open source, Web Services, Software mobile (es. applet), Data
mining (es. motori di ricerca), Agenti, Social software (supporta la collaborazione di comunità di utenti), …
Garanzie sul software: verifica (garantisce l’aderenza ad una specifica), validazione (garantisce
l’accettazione da parte del cliente), certificazione (garantisce l’aderenza a specifiche definite dalla legge).
NB: il sw commerciale di solito viene venduto senza garanzie (“as is”).
1.1
Ingegneria del software
L’IdS (Software Engineering) è una disciplina metodologica, cioè studia i metodi di produzione, le teorie alla
base dei metodi, e gli strumenti efficaci di sviluppo e misura della qualità di sistemi software complessi. È
tuttavia anche una disciplina empirica, cioè basata sull’esperienza e sulla storia dei progetti passati.
I problemi principali che affronta l’IdS riguardano: metodi di analisi e progettazione dei prodotti sw; studio
del processo di sviluppo del sw; sviluppo degli strumenti di produzione del sw; aspetti economici dei
prodotti e dei processi; standardizzazione di processi e tecnologie.
IdS è influenzata da fattori di complessità: aspetti psicologici e organizzativi, scarsa formazione specifica
sulla produzione sw, innovazione tecnologica rapidissima, competizione internazionale. Possono esserci
diverse cause che portano al fallimento dell'IdS: project management inadeguato, requisiti sbagliati,
progettazione mediocre, parti interessate con interessi e punti di vista diversi, oppure molti progetti partono
assumendosi rischi alti e poco analizzati (66% percentuale fallimenti).
Stakeholder: soggetti "portatori di interessi" nei confronti di un'iniziativa economica (progettisti
professionisti, management, personale tecnico, decisori, utenti, finanziatori). Ad ogni stakeholder
corrisponde almeno un diverso punto di vista (view).
Processi di produzione a più livelli: – Ciclo di vita industriale – Analisi dei requisiti, progetto, testing –
Progettazione di un servizio sw – Progettazione di un modulo e del relativo test.
I costi software spesso dominano i costi di produzione di un sistema (sono spesso maggiori dei costi
dell’hardware sottostante). È più costoso mantenere il software che svilupparlo (manutenzione è circa il 67%
dei costi di ciclo); l’IdS si preoccupa di produrre software con costi “accettabili”.
Manutenzione a causa del cambiamento; tipi principali di manutenzione: perfettiva (65% - migliorare il
prodotto, agisce su funzionalità e efficienza), adattiva (18% - rispondere a modifiche ambientali), correttiva
(17% - correggere errori trovati dopo la consegna).
I prodotti software sono generici (OTS: off the shelf - sistemi prodotti da produttori di pacchetti software e
venduti sul mercato a qualsiasi cliente) o commissionati (“customizzati” - sistemi commissionati da un
cliente specifico e sviluppati apposta da un qualche fornitore).
Attributi dei prodotti software: esterni (visibili all’utente - costo e tipo di licenza, prestazioni, garanzia),
interni (visibili ai progettisti – dimensione, sforzo di produzione (effort), durata della produzione,
mantenibilità, modularità).
Tra gli attributi troviamo: correttezza (se fa la cosa giusta), manutenibilità, affidabilità (se si “rompe”, il sw
non dovrebbe causare danni), efficienza (il sw non dovrebbe sprecare le risorse di sistema), usabilità (il sw
dovrebbe avere interfaccia e documentazione appropriate).
L’importanza relativa degli attributi di prodotto dipende dal prodotto e dall’ambiente in cui verrà usato (es.
nei sistemi real time con requisiti di sicurezza, gli attributi chiave sono l’affidabilità e l’efficienza); se un
attributo dev’essere particolarmente curato e “spinto”, i costi di sviluppo tenderanno a crescere
esponenzialmente.
1.2
Il processo software
Processo software è l'insieme strutturato di ruoli (progettista, sviluppatore, tester, manutentore, ecc.), attività
e documenti (codice sorgente, codice eseguibile, specifica, commenti, risultati di test, ecc.) necessari per
creare un sistema software. Le attività differiscono in funzione dell’organizzazione che sviluppa e del sw da
produrre, ma di solito includono: specifica, progetto e sviluppo, verifica e validazione, evoluzione. Per
poterle gestire vanno esplicitamente modellate.
Attributi di processo: comprensibilità (processo è definito e comprensibile), visibilità (processo progredisce
in modo visibile), sostenibilità (processo è sostenuto da strumenti CASE – Computer-Aided Software
Engineering o ingegneria del software assistita dall'elaboratore), accettabilità (persone implicate nel
processo manifestano il loro consenso), affidabilità (errori di processo scoperti prima che diventino errori di
prodotto), robustezza (processo può continuare anche in presenza di errori), mantenibilità (processo può
evolvere per adattarsi ai cambiamenti nell’organizzazione che lo usa), rapidità (processo influenza la
velocità di produzione del prodotto).
Per far fronte alle problematiche che possono sorgere durante o dopo lo sviluppo del sw, vengono usati
principi, tecniche, metodi e strumenti.
Principi: anticipazione del cambiamento (considerare i probabili cambiamenti futuri come parte della
progettazione), rigore e formalizzazione (applicazione di metodi e tecniche ben definiti, assicurando
l’affidabilità del prodotto, permettendo il controllo dei costi, aumentando la fiducia dell’utente), separazione
dei problemi (nonostante molte decisioni di progetto siano correlate e interdipendenti, conviene concentrarsi
sui diversi aspetti del problema separatamente), modularità (scomposizione dei problemi), astrazione
(identificare gli aspetti importanti di un fenomeno, trascurandone i dettagli meno significativi), generalità
(favorisce la riusabilità), incrementalità (procedere passo passo).
1.3
Standard del software
Per migliorare qualità di prodotti sw e dei loro processi di produzione. Standard IEEE (principalmente di
metodo), Standard OMG (per UML e CORBA), Standard W3C (per tecnologie Web), Standard OASIS (per
Business Process).
Fig. Il “Body of Knowledge” (SWEBOK - IEEE)
MLOC: mega lines of code
SLOC: Source lines of code
2. Modelli di processo per lo sviluppo del software
Il processo edit – compile – test: molto veloce, feedback rapido,
disponibilità di molti strumenti, specializzato per la codifica, non
incoraggia la documentazione, il testing ha bisogno di un
processo specifico, non scala in-the-large in-the-many, ingestibile
durante la manutenzione.
Il processo del debugging: locate errors → design error repair → repair error → re-test program.
Il processo di testing: unit t. ↔ module t. ↔ sub-system t. ↔ system t. ↔ acceptance t.
Unit testing: controllo di componenti individuali. Module testing: controllo di collezioni di componenti
correlati. Sub-system testing: controllo di moduli integrati. System testing: controllo dell’intero sistema
(controllo di proprietà “emergenti”). Acceptance testing: testing con dati del cliente per controllare che il
comportamento sia accettabile.
Verifica e Validazione del sw: la prima dimostra che un sistema è conforme alla specifica, la seconda
assicura che un sistema soddisfi i bisogni del committente. Entrambe implicano controlli e processi di
revisione e testing di sistema (questo ultimo si basa sull’esecuzione su un insieme di casi di test derivati dalla
specifica dei dati reali che verranno elaborati durante l’attività del sistema stesso).
Programming in the small/large/many: small: un programmatore, un modulo = edit-compile-test; large:
costruire software decomposto in più moduli, su più versioni e più configurazioni; many: costruire grandi
sistemi sw richiede cooperazione e coordinamento di più programmatori, nell’ambito di un ciclo di vita.
Segmentare il ciclo di vita: suddividere il ciclo di vita in quattro fasi:
specifica → progetto → costruzione → manutenzione
Specifica: stesura requisiti e descrizione degli scenari d'usi. Progetto: determina un'architettura software
capace di soddisfare i requisiti specificati. Costruzione (o codifica): include il testing e termina col
deployment (consegna al cliente, con relativa installazione e messa in funzione, di una applicazione o di un
sistema software del sistema). Manutenzione: perfettiva, correttiva, adattiva.
Fig: Prosecco evolutivo
Il software è flessibile e può cambiare, evolversi per adattarsi a nuovi requisiti.
Modelli di processo (sw): rappresentazione di una famiglia di processi, presenta la descrizione di istanze di
processi sw viste da prospettive particolari.
A)a cascata: specifica e sviluppo sono separati e distinti. Molto dettagliato e rigido, orientato alla
documentazione e agli standard, adatto per organizzazioni gerarchizzate, rischioso.
system requirements analysis
## fase 1
software requirements analysis ##
preliminary design
## fase 2
detailed design
##
coding & unit testing ## fase 3
component integration & testing
integration testing
## fase 5
system testing
maintain
## fase 4
##
1. Analisi dei requisiti: utenti e sviluppatori. Successo se: il sw soddisfa i requisiti, i requisiti
soddisfano i bisogni percepiti dall'utente, i bisogni percepiti dall'utente riflettono i bisogni reali.
Prodotto di questa fase: documento su cosa il sistema deve fare.
2. Progetto: progettisti sw usano i requisiti per specificare e determinare l'architettura del sistema.
Diversi approcci e metodologie (strumenti, supporti linguistici). Prodotto di questa fase: documento
di progetto del sistema che identifica moduli e le loro interfacce.
3. Codifica: Prodotto di questa fase: moduli implementati e testati; implementati secondo le loro
specifiche, intervengono i linguaggi di programmazione, moduli testati rispetto la propria specifica.
4. Integrazione: moduli sono integrati fra loro, testing delle interazioni fra moduli. Prodotto di questa
fase: sistema completamente implementato e testato nelle sue componenti.
5. Test del sistema: il sistema è testato nella sua globalità. Prodotto di questa fase: sistema
completamente testato e pronto per essere deployed.
V MODEL (sviluppo VS verifica)
Modelli orientati alle qualità: i cicli di vita orientati alle qualità si basano su modelli almeno
idealmente quantitativi (si misurano i fattori di processo).
1. Cleanroom: teoria basata sulla squadra, orientata al processo di sviluppo e certificazione di alta
affidabilità dei sistemi software sotto il controllo di qualità. Un obiettivo principale è lo sviluppo
di software che espone zero fallimenti in uso. Combina matematicamente metodi basati sulla
specifica del software, la progettazione, la verifica e la correttezza con la statistica, l'utilizzo
basati su prove di certificare l'idoneità del software per l'uso.
2. ISO 9000: identifica una serie di norme e linee guida sviluppate dall’ISO (International
Organization for Standardization), che propongono un sistema di gestione per la qualità, pensato
per gestire i processi aziendali affinché siano indirizzati al miglioramento della efficacia e
dell'efficienza della organizzazione oltre che alla soddisfazione del cliente. Si suddivide in: ISO
9000 che descrive le terminologia e i principi essenziali dei sistemi di gestione qualità e della loro
organizzazione; ISO 9001 (per le fabbriche del sw) per la definizione dei requisiti dei sistemi
qualità; ISO 9002 e 9003, la cui certificazione non è riconosciuta in quanto sostituite
definitivamente dalla ISO 9001:2000 (prevede un approccio globale e completo di certificazione
per cui non è possibile escludere alcuni settori o processi aziendali, se presenti
nell'organizzazione o necessari a soddisfare i "clienti"). ISO 9004 è una linea guida per il
miglioramento delle prestazioni delle organizzazioni.
3. Capability Maturity Model (CMM): sviluppato dal 1987 al 1997, è un modello che indica
ventidue aree di processi aziendali (Process area) strutturate su cinque livelli, ognuna con i propri
obiettivi generici (Generic Goal) e specifici (Specific Goal). Gli obiettivi generici e specifici sono
implementati da una sequenza temporale di attività generiche (Generic practice) e specifiche
(specific practice), che hanno determinate tipologie di output (tipical work product).
Livello
Caratteristiche
Ottimizzante (Quantitativo) Processo misurato
Principali problemi
Identificare identificatori di processo
Gestito
(Qualitativo) Processo definito e Raccolta automatica di dati di processo per analizzarlo e
istituzionalizzato
modificarlo
Definito
(Qualitativo) Processo definito e Misurazione del processo; Analisi del processo; Piani di qualità
istituzionalizzato
quantitativi
Ripetibile
(Intuitivo) Processo dipendente Creare un Gruppo di Processo; Identificare un’architettura di
dagli individui
processo; Introdurre metodi e strumenti di Sw Eng
Iniziale
Ad hoc/ Caotico; No stima dei Project management; Pianificazione del progetto; Controllo di
costi, pianificazione, o gestione
qualità del software
4. Six Sigma: indica una programma di gestione della qualità basato sul controllo della varianza,
(indicata con Sigma) che ha lo scopo di portare la qualità di un prodotto o di un servizio ad un
determinato livello, particolarmente favorevole per il consumatore. Mira all’eliminazione dei
difetti e degli sprechi piuttosto che al semplice miglioramento della prestazione media.
ESEMPIO: Un impiegato esce di casa alle 8.00 e deve entrare al lavoro alle 8.30. Attraversando
la città impiega mediamente 25 minuti, mentre per il percorso in campagna (più lungo) occorrono
in media 28 minuti. Quale percorso gli conviene? La media non è un indicatore significativo. Si
deve analizzare l’intera distribuzione dei dati nei due casi: il percorso cittadino presenta una forte
variabilità dei dati, perché è molto influenzato (e poco prevedibilmente) dal traffico; il percorso
di campagna invece richiede un tempo praticamente costante. Visto l’alto numero di difetti nel
caso del percorso cittadino, quello di campagna è preferibile dal punto di vista dell’impiegato.
B) a spirale: rientra nei modelli a
processo evolutivo iterativi; specifica e
sviluppo sono sovrapposti; adatto se
requisiti installabili; non lineare;
flessibile; valuta il rischio; può
supportare diversi modelli generici.
Ad ogni spira è associata una fase del
processo. Nessuna sequenza fissa di
fasi: si decide via via quale fase
reiterare (go – not go; per decidere se
portare avanti il progetto). Il modello
si divide in quattro settori: definizione
dell’obiettivo (ogni fase identifica i
propri obiettivi), valutazione e
riduzione dei rischi (ogni rischio deve
essere
affrontato),
sviluppo
e
validazione (il modello di sviluppo
può essere generico, ogni fase include
sviluppo e validazione), pianificazione
(revisione del progetto e pianificazione
del suo futuro). I rischi sono valutati
continuamente ed esplicitamente. Si
basa, sul concetto di rischio,
(circostanza avversa che può pregiudicare il processo di sviluppo e la qualità del software). Il modello si
concentra sull’identificazione e l’eliminazione dei problemi ad alto rischio tralasciando quelli banali. La
caratteristica principale del modello è quella di essere ciclico, ogni ciclo di spirale si compone di quattro
fasi (come i settori), il raggio rappresenta il costo accumulato e la dimensione angolare il progresso nel
processo.
La prima fase identifica gli obiettivi e le alternative; le alternative si valutano nella seconda fase in cui
vengono evidenziate le potenziali aree di rischio. La terza consiste nello sviluppo e nella verifica del
prodotto, e nella quarta avviene la revisione dei risultati delle tre fasi precedenti (pianificazione).
Rational Unified Process (RUP) (estensione dello Unified Process) modello di processo
software iterativo. Una iterazione è un ciclo di sviluppo che porta al rilascio di una parte del prodotto
finale; ogni iterazione tocca tutti gli aspetti dello sviluppo sw; ogni rilascio iterativo è una parte
pienamente documentata del sistema finale. Questa scomposizione presenta numerosi vantaggi (in
particolare rispetto alla valutazione dell'avanzamento del progetto e alla gestione dei fattori di
rischio) ma implica un overhead specifico. Fu descritto in termini di un meta modello objectoriented, espresso in UML. Non definisce un singolo, specifico processo, bensì un framework
adattabile che può dar luogo a diversi processi in diversi contesti (per esempio in diverse
organizzazioni o nel contesto di progetti con diverse caratteristiche). È pensato soprattutto per
progetti di grandi dimensioni. Il ciclo di vita di un processo software è suddiviso in cicli di sviluppo,
a loro volta composti da fasi (o iterazioni):
● Inception Phase (fase iniziale/concezione)
● Elaboration Phase (fase di elaborazione)
● Construction Phase (fase di costruzione)
● Transition Phase (fase di transizione)
Iterazioni: sequenze di attività con un piano prestabilito e dei criteri di valutazione, che terminano
con un rilascio eseguibile. Il RUP definisce una "Project Management Discipline" (disciplina di
gestione dei progetti) a cui il project manager può affidarsi per amministrare le iterazioni.
L'Inception Phase: considerata come una particolare elaborazione e precisazione del concetto
generale di analisi di fattibilità. Lo scopo è quello di delineare il business case, cioè comprendere il
tipo di mercato al quale il progetto afferisce e identificare gli elementi importanti affinché esso
conduca a un successo commerciale (per un nuovo sistema o per l'aggiornamento di uno esistente).
Se il progetto non supera questa milestone, detta "Lifecycle Objective Milestone", esso dovrà essere
abbandonato o ridefinito. Prodotti: requisiti chiave per il progetto, valutazione iniziale del rischio
(opzionali: prototipo concettuale, modello del dominio).
Elaboration Phase: definisce la struttura complessiva del sistema. Comprende l'analisi di dominio e
un prima fase di progettazione dell'architettura. Questa fase deve concludersi con il superamento di
una milestone detta "Lifecycle Architecture Milestone". Perciò devono essere soddisfatti i seguenti
criteri. Deve essere:
● sviluppato un modello dei casi d'uso completo al 80%;
● fornita la descrizione dell'architettura del sistema;
● sviluppata un'"architettura eseguibile" che dimostra il completamento degli use case significativi;
● eseguita una revisione del business case e dei rischi;
● completata una pianificazione del progetto complessivo.
Se il progetto non passa questa milestone, viene abbandonato o rivisitato. Al termine di questa fase si
transita infatti in una situazione di rischio più elevato, in cui le modifiche all'impostazione del
progetto saranno più difficili e dannose.
Construction Phase: viene portato a termine il grosso degli sviluppi. Viene prodotta la prima release
del sistema. La milestone di questa fase si chiama "Initial Operational Capability" e rappresenta la
prima disponibilità delle funzionalità del sistema in termini di implementazione. Scopo: sviluppo
incrementale di un prodotto sw completo pronto per essere inserito nella comunità degli utenti.
Transition Phase: il sistema passa dall'ambiente dello sviluppo a quello del cliente finale. Vengono
condotte le attività di training degli utenti e il beta testing del sistema a scopo di verifica e
validazione. Si deve in particolare verificare che il prodotto sia conforme alle aspettative descritte
nella fase di Inception. Se così non è si procede a ripetere l'intero ciclo; altrimenti, si raggiunge la
milestone detta "Product Release" e lo sviluppo termina.
Processo Microsoft: si compone di
● Pianificazione: (Vision Statement - Product Managers) definisce gli obiettivi del nuovo prodotto
o delle nuove funzioni (“features”), le priorità delle funzioni da implementare in base ai bisogni
degli utenti. Pianificare con “buffer time”. Documenti: specifica; pianificazione e definizione dei
team di progetto di ciascuna “feature”. Partecipanti: 1 program manager, 3-8 developers, 3-8
testers (1:1 ratio with developers).(documento programmatico, specifica, team management).
● Sviluppo: lo sviluppo delle funzioni si divide in 3-4 sotto progetti, ciascuno dei quali esegue in
autonomia il ciclo completo di sviluppo, integrazione di feature, testing e debugging. I testers
vengono accoppiati agli sviluppatori. Il progetto si stabilizza alla fine del sottoprogetto. Gli utenti
vengono coinvolti durante lo sviluppo.
● Stabilizzazione (collaudo interno ed esterno, preparazione delle release). Usa Synch-and-Stab.
L'approccio Synch-and-Stabilize consiste nel sincronizzare di continuo gli sviluppi paralleli e
stabilizzare e incrementare periodicamente il prodotto (non tutto alla fine). Processo noto anche con i
nomi: milestone process, daily build process, nightly build process, zero-defect process. I principi
chiave di Synch&Stab (per definire i prodotti e modellare i processi):
1. Dividere i grandi progetti in più iterazioni con buffer time appropriato (20-50%);
2. Usare un “vision statement” e classificare le specifiche delle funzioni per guidare il progetto;
3. Selezione delle caratteristiche principali e ordinamento di priorità basato su dati d’uso;
4. Architettura modulare;
5. Gestione basata su piccoli compiti individuali e risorse di progetto prestabilite.
Il principio base seguito da MS è: “Eseguire ogni attività in parallelo, con frequenti
sincronizzazioni”. Prevede: dividere i grandi progetti in più cicli di traguardi interni, con buffer e
nessuna manutenzione separata del prodotto; utilizzare come guida un documento programmatico e
un documento di specifica delle funzionalità del prodotto; fondare la scelta delle funzionalità e la
scala delle priorità sui dati e le attività dell’utente; sviluppare un’architettura modulare e orizzontale,
in cui la struttura del prodotto sia rispecchiata nella struttura del progetto; controllare un progetto
impegnando i singoli in compiti di breve portata e “bloccando” le risorse del progetto.
Tra le metodologie agili (particolare metodo per lo sviluppo del software che coinvolge quanto più
possibile il committente) usate da MS c'è Extreme Programming, caratterizzato dalla
programmazione a più mani, la verifica continua del programma durante lo sviluppo per mezzo di
programmi di test e la frequente reingegnerizzazione del software, di solito in piccoli passi
incrementali, senza dover rispettare fasi di sviluppo particolari. XP si basa su cinque linee guida:
communication (tutti possono parlare con tutti, persino l'ultimo dei programmatori con il cliente),
simplicity (gli analisti mantengano la descrizione formale il più semplice e chiara possibile),
feedback (sin dal primo giorno si testa il codice), courage (si dà in uso il sistema il prima possibile e
si implementano i cambiamenti richiesti man mano), respect.
Planning game: è la pratica che trasforma la classica analisi dei requisiti in un “gioco”. Si basa sulle
user stories, descrizioni in linguaggio naturale di ciò che l’utente vuole che il software faccia. Ad
ogni user story gli utenti stessi assegnano una priorità, mentre gli sviluppatori un costo. Ovviamente
si tratta di una pianificazione informale. Le storie di più alto rischio e priorità sono affrontate per
prime, in incrementi “time boxed”. Il Planning Game si rigioca dopo ciascun incremento
Small release: si sviluppa i vari moduli del sistema software in modo incrementale, ad ogni ciclo si
fanno piccole release, minimali, ma comunque utili (mai ‘implementare il database’) in modo da
ottenere feedback dal cliente presto e spesso. Eseguire il “planning game” dopo ciascuna iterazione.
Whole team: tutto il team partecipa a ciascun aspetto dello sviluppo software in qualche modo.
Collettive ownership deriva dalla pratica precedente; la proprietà intellettuale del codice appartiene
al gruppo. Mentre i progettisti sviluppano il progetto possono osservare e modificare qualsiasi classe.
Coding Standard: usare convenzioni di codifica. A causa del Pair Programming, delle
rifattorizzazioni e della proprietà collettiva del codice, occorre avere sistemi per poter addentrarsi
velocemente nel codice altrui. Commentare i metodi (priorità al codice che “svela” il suo scopo, se
non puoi spiegare il codice con un commento, riscrivilo).
Soustainable Pace: lavorare fino a tarda notte danneggia le prestazioni: lo sviluppatore stanco fa più
errori. Se il progetto danneggia la vita privata dei partecipanti, alla lunga paga il progetto stesso.
Metaphore: per descrivere una funzionalità del sistema software nel gruppo si usa una metafora. Ad
esempio, per descrivere un gruppo di agenti software in azione “lo sciame di piccole api volano sui
fiori e rientrano all’alveare solo una volta terminato il loro compito”. Aiuta a far sì che il team usi un
sistema comune di nomi di entità, tale che sia immediato trovare, per uno sviluppatore, una certo
modulo in base al nome, o sia chiaro dove inserire le nuove funzionalità appena sviluppate.
Contiuos Integration: la coppia scrive i test ed il codice di un task ( = parte di una storia utente),
esegue un completo test di unità, esegue l’integrazione della nuova unità con le altre, esegue tutti i
test di unità, passa al task successivo a mente sgombra (una o due volte al giorno). L’obiettivo è
prevenire l’”IntegrationHell”.
Test-Driven Development: si scrive il codice sulla base dei test stessi. In poche parole si scrivono
prima i test, poi si sviluppa l’applicazione finché non supera positivamente il test. Questo processo è
sempre accompagnato da framework xUnit.
Refactoring del codice senza pietà!: Uno dei motti del XP è “se un metodo necessita di un
commento, riscrivilo!” (codice auto-esplicativo). Semplificare il codice; cercare opportunità di
astrazione; rimuovere il codice duplicato.
Simple design: No Big Design Up Front (BDUF) “Fare la cosa più semplice che possa funzionare”.
Includere la documentazione. Schede CRC cards (opzionali).
Pair programming: si programma in coppia, il driver (controlla tastiera e mouse e scrive
l’implementazione) scrive il codice mentre il navigatore (osserva l’implementazione cercando difetti
e partecipa al brainstorming su richiesta) controlla il lavoro del suo compagno in maniera attiva. I
ruoli di driver e navigatore vengono scambiati tra i due progettisti periodicamente. È risultato un
ottimo approccio, nonostante possa sembrare uno spreco di risorse umane.
Idealmente il cliente è sempre disponibile, in ogni fase del processo di sviluppo per chiarire le
storie e per prendere rapidamente decisioni critiche. Gli sviluppatori non devono fare ipotesi ne
devono attendere le decisioni del cliente. La comunicazione “faccia a faccia” minimizza la
possibilità di ambiguità ed equivoci.
Con l'approccio XP si ha che le coppie producono codice di migliore qualità e nella metà del tempo.
Rischi Cowboy Coders Ignore Team’s Process; Code Lacks Test Coverage; Stories Are Too
Complicated; Customer Doesn’t Help Test System; Team Produces Few Customer Tests; QA
Department Wants Requirements Specification; Team is Asked to Produce Way More Than it Can;
System Contains Many Defects; Team Encounters Risky Technical Challenges; Management Wants
System Documentation; Tests Not Run Before Integration; Tests Run Too Slowly.
Confronto tra i modelli: CMM (Stabilità, Ripetibilità) RUP (Adattabilità, Connettività) XP (Flessibilità,
Agilità). Perchè standardizzare CMM (Predicibilità, Efficienza) RUP (Componentistica, Integrazione)
XP (Velocità, Semplicità). La qualità come viene fuori CMM (Rimozione difetti, Prevenzione difetti,
Progetto per qualità) RUP (API predefinite, Integrazione semplice, Gestione dei rischi) XP (Fare la cosa
più semplice che possa funzionare)
C) formale: il modello matematico di un sistema viene trasformato in implementazione
D)orientato al riuso: assemblato con componenti preesistenti
Opensource può essere definito tramite i seguenti punti:
• Ridistribuzione libera
• No discriminazione contro campi applicativi
• Codice sorgente incluso nella distribuzione
• Distribuzione della licenza, che si applica a tutti
• Prodotti derivabili con licenza
• Licenza non specifica di prodotto
• Protezione dell’integrità del sorgente dell’autore
• Licenza che non vincola altri prodotti sw
• No discriminazione contro persone o gruppi
• Licenza tecnologicamente neutrale
Filosofia Ogni buon prodotto sw inizia da un problema personale; i bravi programmatori sanno cosa
scrivere, i migliori sanno cosa riscrivere; quando hai perso interesse in un programma che hai costruito, è tuo
dovere passare le consegne ad un successore competente; trattare gli utenti come sviluppatori è la strada
migliore per debugging efficace e rapidi miglioramenti del codice; distribuisci presto e spesso e presta
ascolto agli utenti; stabilita una base di betatester e co sviluppatori sufficientemente ampia, ogni problema
verrà presto individuato e qualcuno troverà la soluzione adeguata.
La Open Source Initiative pubblica una lista di licenze approvate (da un OSI board) e conformi alla Open
Source Definition. Esistono molte licenze certificate con caratteristiche diverse. Su richiesta, OSI board può
approvare nuove licenze se quelle esistenti non soddisfano le esigenze.
Il processo OpenSource è ”pubblico”; le implementazioni sono controllate da un board che revisiona e testa
il codice proposto; modifiche moderate; build frequenti; proprietà collettiva; no maintenance.
3. Project Management dei Progetti Software
Project Management: applicazione di conoscenze, abilità, tecniche e strumenti alle attività di progetto allo
scopo di soddisfarne i requisiti.
Il Project Manager (PM, o responsabile di progetto) controlla la pianificazione ed il budget di progetto.
Durante tutto il ciclo di vita il PM deve controllare costi e risorse di un progetto: inizialmente per verificare
la fattibilità del progetto; durante il progetto per controllare che le risorse non vengano sprecate ed i budget
vengano rispettati; alla fine per confrontare preventivo e consuntivo.
La valutazione dei costi procede in base alla durata (estensione temporale del progetto, dall'inizio alla fine;
dipende dalle dipendenze tra le attività di progetto; si misura di solito in mesi) o allo sforzo (somma dei
tempi di tutte le attività di progetto; si misura di solito in mesi/persona – mp).
I progetti informatici di solito vengono sottostimati sia in durata che in sforzo.
Costo di un progetto: il costo è una risorsa impiegata o ceduta per raggiungere un obiettivo o per ottenere
qualcosa in cambio; si misura in unità monetarie. Il Project Cost Management definisce i processi necessari
ad assicurare che il progetto si concluda con successo entro i termini di budget prestabiliti.
Tra i processi troviamo: Resource planning (determinare e pianificare le risorse da usare), Cost estimating
(stimare costi e risorse necessarie ad un progetto), Cost budgeting (allocare il costo complessivo su compiti
individuali per stabilire un riferimento per valutare le prestazioni), Cost control (controllare le modifiche al
budget durante il progetto).
Un prodotto importante del Project Cost Management è una stima dei costi. Esistono parecchi tipi di stima
dei costi, e di corrispondenti tecniche e strumenti per calcolarli. Occorre anche sviluppare un piano di cost
management che descriva come il progetto possa gestire variazioni dei costi. Stimare il costo di un progetto
(specie quando produce software) è un’arte. Ogni organizzazione che esegue progetti deve creare un
database dei costi per supportare le stime correnti e future.
Tre tecniche principali di stima dei costi:
● top-down (o analogica): uso del costo reale di un progetto analogo come base della stima del nuovo
progetto; sono dapprima valutati i costi complessivi del progetto, poi si procede alla loro suddivisione
nelle fasi di produzione;
● bottom-up: stima dei compiti individuali che compongono il progetto e loro somma per ottenere la stima
totale. Approccio basato sulla dimensione del codice: per ciascun componente elementare viene stimata la
dimensione in base ad una metrica prescelta. La stima delle dimensioni è calcolata sommando tutte le
stime calcolate in precedenza: il costo complessivo è quindi ottenuto applicando opportuni fattori di
costo. Per ogni componente sono date tre stime della dimensione: ottimistica, verosimile e pessimistica.
Approccio basato sulla stima dello sforzo: per ciascun componente è stimato lo sforzo necessario per
ciascuna fase del processo di sviluppo (sforzo in mesi/uomo). Uso di tabella in cui: ogni riga corrisponde
ad un componente; ogni colonna ad una fase dello sviluppo; le ultime tre righe contengono i valori per
calcolare i costi.
● parametrica: stima basata sull’uso di un modello matematico che usa parametri di progetto.
L’attività di stima durante un grosso progetto software richiede sforzo notevole ed è un compito complesso,
in più molte persone che effettuano stime hanno scarsa esperienza in tale attività: occorre formazione
specifica. Di solito si tende a sottostimare. Le revisioni di stima devono basarsi sulle domande “giuste”, per
evitare che le stime siano falsate. Ai dirigenti occorre un numero per fare un offerta, non una vera stima. Poi
è compito dei PM mediare con gli sponsor di un progetto per creare stime di costo realistiche.
I principali componenti di costo sw sono: costo dell’hardware di sviluppo; costo del software di sviluppo;
costo delle risorse umane (sforzo); durata complessiva.
Per stimare rapidamente alcuni parametri chiave di un progetto, esistono alcune regole euristiche (Boehm)
che aiutano a dare una stima “immediata” se è nota la misura dello sforzo in mesi-persona (mp):
● Durata media di un progetto = 2.5 * radice cubica di mp;
● Dimensione ottimale dello staff = radice quadrata di mp;
● Durata minima di un progetto = 0.75 * radice cubica di mp.
La curva di Rayleigh
La curva di distribuzione dello sforzo venne suggerita negli anni 50 per lo sviluppo hw,
e viene comunemente usata anche per il sw (t = mese, tD = mese del picco di sforzo
massimo). Osservando la curva (x = mesi, y = mp) si nota che duante la fase dei
requisiti e del design lo sforzo aumenta, sino a toccare il suo massimo durante la
codifica; dopo di che procede in lenta discesa durante i test e manutenzioni.
Strumenti Sw per il Cost Management: fogli elettronici, usati per resource planning, cost estimating, cost
budgeting, e cost control; alcune aziende usano applicazioni finanziarie centralizzate per gestire le
informazioni sui costi. Gli strumenti per Project Management offrono parecchie funzioni di analisi dei costi.
Tecniche di Stima dei Costi
● Il giudizio di esperti (metodo Delphi): vengono consultati esperti sulle tecniche di stima del software, i
quali stimano indipendentemente il costo del progetto e reiterano finché non si trovano in accordo.
● Stima per analogia: si applica quando sono già stati completati altri progetti con caratteristiche simili. Il
costo viene valutato in analogia al progetto già finito.
● Legge di Parkinson: la previsione di durata e sforzo aumenta fino a coprire il tempo e le persone
disponibili; il costo è quindi determinato dalle risorse disponibili piuttosto che dal bisogno oggettivo.
● Pricing to Win: il costo del software viene stimato in base alla spesa che il cliente è disposto a sostenere
per il progetto.
● Modelli parametrici (o algoritmici): il costo è stimato come una funzione matematica di attributi i cui
valori sono determinati dal manager di progetto. La funzione deriva da uno studio di precedenti progetti
(regressione). Attributi chiave: quelli che hanno un impatto significativo sul costo.
● Uso di strumenti di intelligenza artificiale e apprendimento automatica (reti neurali, Case Based
Reasoning, Fuzzy logic): il sistema impara a stimare usando un insieme di dati da progetti già finiti (detto
training set); la stima non è spiegata, e può essere inaccurata se il training set è piccolo.
In molti progetti alcune tecniche possono essere combinate. Se si predicono costi radicalmente differenti
allora bisogna cercare più informazioni e le stime vanno ripetute fino a quando non convergono.
L’accuratezza della stima deve crescere con il progredire del progetto.
3.1
Misurare le dimensioni del progetto
La dimensione di un progetto sw è il primo coefficiente di costo in molti modelli; esistono due misure
principali per stimare la dimensione del software da produrre:
● linee di codice sorgente (LOC). LOC può tener conto delle linee vuote o dei commenti (CLOC); in
generale si ha: LOC = NCLOC + CLOC, cioè i commenti si contano. KLOC = Migliaia di linee di codice
sorgente. Metriche: $ per KLOC, errori o difetti per KLOC, LOC per mese/persona, pagine di
documentazione per KLOC, errori per mese-persona, $/pagina di documentazione. Queste metriche
dipendono dal linguaggio di programmazione e penalizzano (sottovalutano la produttività) programmi
scritti bene e concisi. Potremmo trovare aspetti critici delle stime dimensionali: è difficile stimare la
dimensione in LOC di una nuova applicazione; la stima LOC non tiene conto della diversa complessità e
potenza delle istruzioni (di uno stesso linguaggio o di più linguaggi); è difficile definire precisamente il
criterio di conteggio (istruzioni spezzate su più righe, più istruzioni su una riga..); maggior produttività in
LOC potrebbe comportare più codice di cattiva qualità? Il codice non consegnato (es. test) va contato?
● punti funzione (Function Points [Albrecht]): metrica che misura funzionalità del sistema. Calcolo di FP:
Passo1: si descrive l’applicazione da realizzare partendo da una descrizione del sistema (specifica) di
natura funzionale.
Passo2: individuare nella descrizione i seguenti elementi funzionali: External Input (informazioni, dati
forniti dall’utente, es. nome di file, scelte di menù, campi di input), External Output (informazioni, dati
forniti all’utente dell’applicazione, es. report, messaggi d’errore), External Inquiry (sequenze interattive
di richieste – risposte), External Interface File (interfacce con altri sistemi informativi esterni), Internal
Logical File (file principali logici gestiti nel sistema).
Passo3: occorre classificare i singoli elementi funzionali per complessità
di progetto, usando la tabella di pesi raffigurata a fianco.
Passo4: censire gli elementi di ciascun tipo, moltiplicare per il lor “peso”
e sommare: UFC= Sum [i=1_5] ( Sum [j=1_3] ( elemento i,j * peso i,j)).
Dove, i=tipo elemento, j=complessità (semplice, media o complessa),
UFC=Unajdjusted Function Count.
Passo5: Moltiplicare UFC per il fattore di complessità tecnica dell’ applicazione (TFC). Calcolo di TFC:
TFC = 0.65+0.01* S [i =1-14] Fi. Ciascun Fi assume un valore tra 0 (irrilevante) e 5 (massimo).
PassoFinale: Nota: il valore complessivo di TFC varia nell’intervallo da 0.65 (applicazione facile) a 1.35
(applicazione difficile). Alla fine la formula risulta: FP = UFC * TFC (function point).
Il conteggio degli FP si basa su giudizi soggettivi, quindi persone diverse possono raggiungere risultati
diversi. Quando si introduce la FPA in una organizzazione, è necessaria una fase di calibrazione, usando
i progetti sviluppati in passato come base del sistema di conteggio.
Problemi: i “logical files” sono difficili da definire; riconoscimento esplicito dei dati da elaborare; pesi
insufficienti alla complessità interna; validità dei pesi e consistenza della loro applicazione; la
produttività in termini di FP sembra funzione della dimensione del progetto; gli FP sono stati
estensivamente usati con sistemi informativi (minore esperienza con sistemi client-server o embedded).
Entrambe queste misure hanno bisogno di dati storici per poter essere calibrate all’organizzazione che le usa.
Se occorre, è possibile usare la tecnica del backfiring, che permette di convertire LOC in FP e viceversa; si
basa sulla nozione di livello di astrazione dei linguaggi di programmazione. Misure derivate dai FP:
● Produttività: Ore per FP: misura il numero di ore necessarie in media per sviluppare un FP; calcolo:
Ore totali di progetto / # FP consegnati;
● Produttività generale: è la produttività complessiva di gruppo di produzione IT; calcolo: FP totali /
Sforzo totale del gruppo;
● Funzionalità consegnata & Funzionalità di sviluppo: funzionalità consegnate all’utente finale in
relazione al tasso di produttività raggiunto per tali funzionalità; Calcolo: Costo totale / # FP consegnati,
Sforzo totale / # FP sviluppati internamente.
3.2
Altre misure e stime
Misure di qualità:
● Dimensione dei requisiti funzionali: misura il numero totale di funzioni richieste in FP;
● Completezza: misura la funzionalità consegnata rispetto a quella richiesta inizialmente; calcolo: #FP
consegnati / #FP richiesti;
● Produttività di consegna: produttività necessaria alla consegna entro un certo periodo di durata del
progetto; calcolo: # FP totali / Durata dello sforzo;
● Efficienza nella rimozione di difetti: # difetti trovati prima della consegna / # difetti totali;
● Densità dei difetti: numero di difetti identificati in una o più fasi del ciclo di vita in rapporto alla
dimensione totale dell’applicazione; calcolo: # difetti / # FP totali;
● Copertura dei casi di test: numero dei casi di test necessari ad un controllo accurato del progetto; calcolo:
# casi di test totali / # FP totali;
● Volume della documentazione: misura o stima delle pagine prodotte o previste come effetto dello
sviluppo; calcolo: # pagine / # FP totali.
Misure finanziare:
● Costo per function point: il costo medio della realizzazione di ciascun FP; calc: Costo totale / # FP totali;
● Costo di una riparazione: costo di riparazione di applicazioni consegnate ed operative; è una metrica di
monitoraggio di nuove applicazioni; calcolo: (Ore totali di riparazione * Costo_orario) / # FP rilasciate:
Misure di manutenzione:
● Mantenibilità: misura del costo necessario per mantenere un’applicazione; calcolo: Costo di
manutenzione / # FP totali dell’applicazione:
● Affidabilità: numero dei fallimenti in rapporto alla dimensione dell’applicazione; calcolo: # fallimenti / #
FP totali dell’applicazione:
● Impegno di manutenzione: dimensione dell’applicazione rapportata al numero di risorse a tempo pieno
necessarie per il suo supporto; calcolo: # FP totali dell’applicazione / # persone a tempo pieno impiegate
per la manutenzione;
● Tasso di accrescimento: crescita delle funzionalità di un’applicazione in un certo periodo; calcolo:
# FP correnti / # FP originali;
● Dimensione del patrimonio: misura del patrimonio di FP di un’organizzazione; si usa per scopi di budget
in accordi di outsourcing;
● Valore di Backfire: numero di linee di codice moltiplicate per un fattore di complessità linguistica per
derivare il numero totale di FP;
● Tasso di stabilità: si usa per monitorare quanto effettivamente un’applicazione ha soddisfatto i suoi utenti
(in base al numero di modifiche richieste nei primi 2-3 mesi di produzione oppure operatività); calcolo:
# modifiche / # FP totali dell’applicazione.
Stima Basata Su Modelli di Costo
I modelli di costo permettono una stima rapida dello sforzo; questa stima è poi raffinata, più avanti nel ciclo
di vita, mediante dei fattori detti cost driver. Il calcolo si basa sull’equazione dello sforzo: E = A + B*(S^C),
dove E è lo sforzo (in mesi-persona), A, B, C sono parametri dipendenti dal progetto e dall’organizzazione
che lo esegue, S è la dimensione del prodotto stimata in KLOC o FP.
Problemi dei costi del software: mentre i costi hardware diminuiscono, i costi del software continuano ad
aumentare, almeno in percentuale dei costi totali dei sistemi informativi. I problemi di stima dei costi sw
sono causati da: incapacità di dimensionare accuratamente un progetto; incapacità di definire nel suo
complesso il processo e l’ambiente operativo di un progetto; valutazione inadeguata del personale, in
quantità e qualità; mancanza di requisiti di qualità per la stima di attività specifiche nell’ambito del progetto.
Sono esempi di modelli dei costi del software, modelli commerciali: COCOMO; COSTXPERT; SLIM;
SEER; Costar, REVIC, etc.
3.3
COCOMO
Il Constructive Cost Model (COCOMO) è uno dei modelli più diffusi per fare stime nei progetti software,
basato su regressione (cioè su un archivio storico) che considera vari parametri del prodotto e
dell’organizzazione che lo produce, pesati mediante una griglia di valutazione. Il principale calcolo di
COCOMO si basa sull’“Equazione dello Sforzo”, che stima il numero di mesi-persona necessari per un
progetto. La maggior parte delle altre grandezze da stimare (la durata del progetto, la dimensione dello staff
da impiegare, ecc.) vengono poi derivate da questa equazione. Es.: # mp * costo_lavoro = Costo_Stimato.
Boehm costruì la prima versione del modello di costo CoCoMo 1 nel 1981; è una collezione di tre modelli:
Basic (applicato all’inizio del ciclo di vita del progetto), Intermediate (applicato dopo la specifica dei
requisiti), Advance (applicato al termine della fase di design). I tre modelli hanno forma equazionale Effort =
a*(S^b)*EAF, dove: Effort è lo sforzo in mesi-persona; EAF il coefficiente di assestamento; S la dimensione
stimata del codice sorgente da consegnare, misurata in migliaia di linee di codice sorgente (KSLOC); a e b
sono coefficienti che dipendono dal tipo di progetto. I vari valori e coefficienti variano a seconda del tipo di
progetto: Organic mode (progetto semplice, sviluppato in un piccolo team), Semidetached mode (progetto
intermedio), Embedded (requisiti molto vincolanti e in campi non ben conosciuti).
Il modelloodello intermedio, più usato con COCOMO 1, aggiunge al risultato del modello base (in cui ci
sono solo coefficinti fissi) un fattore di aggiustamento che lo può accrescere o decrescere, identificando un
insieme di attributi che influenzano il costo (detti cost driver), ottenendo risultati con una buona precisione.
Tipi di cost drivers: del personale (capacità ed esperienza degli analisti e dei programmatori, conoscenza del
linguaggio di programmazione utilizzato), del prodotto (affidabilità richiesta, dimensione del DB,
complessità del prodotto), del computer (tempo di esecuzione del programma, limitazioni di memoria), del
progetto (tools software disponibili, tempo di sviluppo del programma).
CoCoMo 2 rinnova CoCoMo 1 supportando: sw orientati agli oggetti, sw creati con ciclo di vita a spirale o
con modelli di processo evolutivi, sw per e-commerce. Il metodo COCOMO2 come unità di misura della
dimensione del software (Size) può usare le KSLOC oppure i FP. Contiene 3 diversi modelli: Early Design
Model, per stime preliminari, basato su UFP; Post-Architecture Model, da usarsi dopo che è stata delineata
l'architettura (ha nuovi cost drivers e nuove equazioni); Application Composition Model, per GUI.
Vediamo COCOMO 2 (2000) nella versione “PostArchitecture”: il metodo presuppone una stima preliminare
della dimensione del codice da sviluppare; il risultato dell'applicazione del metodo è una stima dello sforzo
di sviluppo che una specifica organizzazione dovrà "spendere" per costruire un codice di tale dimensione;
buona precisione del metodo (circa ± 25%). L'applicazione del metodo si basa su: analisi dei componenti da
stimare; costituzione e analisi di uno storico; stima del Size (SLOC o FP); stima dei parametri (fattori di
scala + cost drivers); calcolo dello sforzo. Equazione dello sforzo = A * (Size^ES) * EM, dove A fattore di
calibrazione da storico, ES somma di fattori di scala relativi a prodotto, processo e organizzazione, EM
produttoria di cost drivers relativi a prodotto, processo e organizzazione, Storico insieme di dati di processo
su componenti costruite in passato, Size dimensione dei componenti da produrre.
Occorre “calibrare” quattro costanti chiamate A B C D che si ricavano da un archivio storico di progetti.
Calcolo di A (calibrazione): A rappresenta la precisione storica di stima. Il calcolo del coefficiente A è molto
sensibile alla scelta dei progetti da inserire nello storico. A(originale) = 2.94, ottenuto dalla calibrazione
COCOMO2.2000 fatta dal gruppo di Bohem su un centinaio di progetti industriali.
Calcolo di ES: ES rappresenta una scala (de)amplificatrice di sforzo direttamente basata su SIZE; è una
somma, ES = 0,91 + (PREC + FLEX + RESL + TEAM + PMAT)/100. ES è calcolato per ogni singolo
componente sulla base dello storico (diviso in 8 profili); spesso ES>1 (se il progetto permette economie di
scala allora ES<1).
Calcolo di EM: EM rappresenta il peso combinato di fattori (cost driver) di prodotto, di processo e
organizzativi; i cost driver si moltiplicano.
4. Scrivere e leggere requisiti
Per stesura dei requisiti si intende stabilire cosa richiede il cliente ad un prodotto software (non stabilire
come il prodotto verrà costruito). Ingegneria dei requisiti è il processo di definizione dei:
● servizi che un cliente richiede ad un sistema
● vincoli di sviluppo di un sistema
● scenari d’uso del sistema
● vincoli operativi di un sistema
Comprende: elicitazione, specifica, gestione, analisi e verifica dei requisiti.
Tecniche di elicitazione: interviste e questionari, riunioni (workshop) dei requisiti, brainstorming,
storyboards, casi d’uso, giochi di ruolo, prototipazione. Attività di elicitazione: identificare gli attori, i casi
d’uso e relazioni tra essi, gli scenari, requisiti non funzionali e gli oggetti partecipanti; raffinare i casi d’uso.
Un requisito può essere una descrizione astratta e vaga di un servizio o vincolo di sistema, oppure una
specifica dettagliata di una funzionalità del sistema. I requisiti hanno infatti una doppia funzione: base per
un’offerta di contratto (devono essere aperti a varie interpretazioni); base per un contratto (devono essere
dettagliati e non soggetti ad interpretazioni arbitrarie). Quindi possono essere definiti come proprietà di un
sistema o prodotto desiderate dai suoi acquirenti o come descrizione in linguaggio naturale dei servizi e dei
vincoli operativi di un sistema (si scrive per i clienti).
Lo standard IEEE definisce l'uso del Software Requirement Specification document (SRS) il cui punto di
partenza è costituito dalla definizione di sette attributi di qualità (unambigous, correct, complete, verifiable,
consistent, modifiable, traceable, ranked - for importance and/or stability). Il documento fornisce feedback
all’utente; decompone un problema in sottoproblemi in modo ordinato e orientato a componenti
indipendenti; serve come input per la fase di progettazione, verifica e validazione.
Un aspetto importante da evitare è l'inconsistenza dei requisiti: difficile anticipare l'effetto di un nuovo
servizio software sull'organizzazione che lo sviluppa; utenti diversi hanno priorità e requisiti diversi; gli
utenti finali hanno aspettative diverse da quelle di chi finanzia lo sviluppo; per chiarire i requisiti è spesso
utile l’uso di prototipi.
Classificazione dei requisiti (alcuni requisiti possono essere sia funzionali che non, es. di sicurezza):
● funzionali: descrivono le interazioni tra il sistema ed il suo ambiente, indipendentemente
dall’implementazione (es. questa procedura stampa un documento);
● non funzionali: proprietà del sistema visibili all’utente e non direttamente correlate al suo
comportamento funzionale (vincoli sui servizi offerti come affidabilità, robustezza, usabilità, vincoli
temporali, memoria, ecc., es. questo documento deve esser stampato su stampante a colori). Possono
essere più critici di quelli funzionali, se non rispettati possono rendere il sistema inutile. Questa famiglia
può esser ulteriormente classificata in: requisiti di prodotto (specificano il comportamento del prodotto al
momento del rilascio come velocità di esecuzione, attendibilità, ecc.); di processo (possono essere
demandati, delegati, ad un particolare sistema CASE o metodo di sviluppo); organizzativi (o aziendali,
dipendono dalle politiche e le procedure adottate dall'organizzazione, cioè standard di processi usati,
requisiti di implementazione, ecc.); esterni (sorgono da fattori esterni al sistema e al suo ambiente di
sviluppo, cioè requisiti di interoperabilità, legislativi, ecc.);
● vincoli (“Pseudo requisiti”): imposti dal cliente o dall’ambiente operativo in cui funzionerà il sistema (es:
il linguaggio di programmazione dev’essere Java).
Secondo l'ingegneria dei requisiti vengono fatte ulteriori distinzioni:
● requisiti utente: funzionali e non funzionali, definiti in linguaggio naturale e diagrammi informali
comprensibili dagli utenti (il documento è scritto per gli utilizzatori); descrivono i servizi offerti;
● requisiti di sistema: documento strutturato che descrive dettagliatamente il comportamento del sistema,
visto come entità unitaria (contratto tra cliente); possono essere requisiti emergenti, cioè non direttamente
derivabili o conseguenti da alcun sottoinsieme dei requisiti;
● requisiti architetturali: documento contenente una descrizione dettagliata dell’architettura sw che servirà
come base per la progettazione e implementazione (scritto per gli sviluppatori).
La scrittura dei requisiti può avvenire con:
● linguaggio naturale, va in contro a problemi di tipo: scrittori e lettori della specifica dovrebbero usare le
stesse parole per lo stesso concetto; una specifica è sempre soggetta a più interpretazioni; i requisiti non
vengono partizionati da strutture linguistiche specifiche. Più precisamente: mancanza di chiarezza (più il
documento è preciso, meno sarà leggibile), confusione (requisiti funzionali e non vengono facilmente
mescolati), amalgamazione (potranno essere espressi in singole fasi più requisiti insieme);
● linguaggio naturale strutturato, forma ristretta del precedente, rimuove parte dei problemi di ambiguità e
impone uniformità al documento di specifica; spesso si basa su una serie di documenti schematici (form);
● notazioni visuali (es. UML) e specifiche formali (es. Z).
Il processo di stesura dei requisiti è l'insieme di fasi che portano alla scrittura del documento dei requisiti
che contiene la definizione “ufficiale” di cosa viene richiesto agli sviluppatori, includendo sia la definizione
(descrizione in linguaggio naturale dei servizi e dei vincoli operativi di un sistema, scritto per i clienti) che la
specifica (documento strutturato che dettaglia i servizi attesi dal sistema, scritto per i contraenti e gli
sviluppatori, come contratto tra cliente e contraente) dei requisiti. Non è un documento di progettazione, dice
cosa il sistema deve fare, non come. Deve: specificare il comportamento del sistema (dal punto di vista
esterno) e i vincoli realizzativi; essere facilmente modificabile e servire da riferimento per la manutenzione;
predire possibili cambiamenti al sistema e definire le risposte del sistema ad eventi inaspettati
Il documento dei requisiti è strutturato in sei moduli: introduzione (definizione dei requisiti - descrive perché
si costruisce il sistema e come risponde ai bisogni dell’organizzazione), requisiti funzionali (descrive in
dettaglio i servizi da fornire), requisiti non-funzionali (definisce i vincoli sul sistema e sul suo processo di
sviluppo), evoluzione del sistema (definisce le assunzioni critiche su cui si basa il sistema ed anticipare i
possibili cambiamenti), glossario (definisce i termini tecnici usati, deve essere il più completo e sintetico
possibile), indici generale e analitico.
Dev’essere organizzato in modo che possa essere modificato senza bisogno di riscriverlo completamente,
dev’essere modulare e i riferimenti all’esterno del documento devono essere pochi, possibilmente nessuno (il
documento dev’essere autocontenuto).
La prima pagina del documento dei requisiti contiene informazioni generali sul prodotto o progetto (nome,
data, autori, vers.), esplica le responsabilità di ciascun autore e definisce i cambiamenti dall’ultima versione.
Non tutti i requisiti hanno la stessa importanza, perciò vengono divisi in tre classi di priorità: obbligatori,
desiderabili, opzionali. I requisiti correlati devono essere collegati e magari collegati anche alla fonte: questa
operazione prende il nome di tracciabilità dei requisiti (la tracciabilità è una proprietà della specifica dei
requisiti che permette di trovare facilmente i requisiti correlati). Sono disponibili tecniche per questa
operazione che costruire una lista dei riferimenti incrociati ai requisiti usando identificatori unici assegnati
precedentemente; possono essere usati link ipertestuali (es. HTML) per realizzare meccanismi di navigazione
della tracciabilità.
Verificabilità dei requisiti: i requisiti vanno scritti in modo che possano essere oggettivamente verificati nel
prodotto finale; occorre quantificare il tasso degli errori.
Validazione dei requisiti: è la dimostrazione che i requisiti definiscono il sistema davvero voluto dal cliente.
Il costo di un errore nei requisiti è molto alto, quindi la validazione è importante (la correzione di un errore
nei requisiti dopo la consegna può costare oltre 100 volte il costo di correzione di un errore implementativo).
La tecnica più importante di validazione dei requisiti è la prototipazione
Il controllo dei requisiti si basa sulle seguenti proprietà: validità (dimostrazione che i requisiti definiscono il
sistema davvero voluto dal cliente, es. di tecnica è la prototipazione), consistenza (se ci sono conflitti tra i
requisiti), completezza (se sono incluse tutte le funzioni richieste dal cliente), realisticità (se i requisiti sono
soddisfacibili dato il budget disponibile e la tecnologia corrente).
Revisioni dei requisiti: dovrebbero essere fatte regolarmente durante il periodo di definizione dei requisiti.
Servono ad affrontare problemi o errori di specifica nella fase iniziale del processo; possono essere formali
(strutturate) o informali. Alle revisioni partecipano sia persone del cliente, sia del contraente. Anche per
questa fase sono disponibili controlli che mirano a verificare le seguenti proprietà: verificabilità (se il
requisito è realisticamente controllabile), comprensibilità (se il requisito si capisce correttamente),
tracciabilità (se l'origine del requisito è definita correttamente), adattabilità (se il requisito può essere
modificato senza influenzare pesantemente gli altri requisiti).
Evoluzione dei requisiti, perché si capiscono meglio i bisogni dell’utente o gli obiettivi dell’organizzazione
cambiano; è importante perciò anticipare e pianificare il cambiamento dei requisiti mentre il sistema viene
sviluppato ed usato. Possiamo quindi fare un altra classificazione: requisiti duraturi (o stabili, tipici del
dominio dell'applicazione o dell'organizzazione che la userà, es. regole di privacy negli ospedali) e effimeri
(o volatili, che cambiano durante lo sviluppo o dopo che l'applicazione è divenuta operativa; dipendono
dall'ambiente, es. gestione di certe malattie negli ospedali).
5.
Casi d'uso
Un Caso d’Uso è una vista sul sistema che mostra il suo comportamento come apparirà agli utenti esterni.
Partiziona le funzionalità in transazioni (casi d’uso) significative per gli utenti (attori). Rappresenta un
requisito funzionale di un sistema che si costruisce dialogando con l’utente (elicitazione) e viene usato per
costruire i modelli sia strutturali che operazionali, e inoltre per predisporre casi di test.
“Il Caso d’Uso è una descrizione del comportamento di un sistema dal punto di vista di un utente”.
I casi d’uso possono essere descritti sotto forma di scenario (un dialogo, o sequenza di azioni che
rappresenta l’interazione di entità esterne al sistema -attori- con il sistema stesso o sue componenti) tra gli
utilizzatori e il sistema. Un caso d’uso è un insieme di scenari legati da un obiettivo comune. L’attenzione si
focalizza quindi sull’interazione, non sulle attività interne al sistema. Si distinguono due tipi di scenari:
● base: è di solito quello che prevede il successo del caso d’uso, ed uno svolgimento lineare;
● alternativi: possono essere di successo o fallimento, con complicazioni varie; non è necessario (e sarebbe
molto costoso) analizzare in dettaglio tutti i possibili scenari di un caso d’uso; è invece necessario
individuare le singole possibili varianti che possono portare al fallimento del caso d’uso, o che
comportano trattamenti particolari.
Un caso d'uso specifica cosa ci si aspetta da un sistema nascondendone il suo comportamento; è una
sequenza di azioni (con varianti) che producono un risultato osservabile da un attore. Si usa per descrivere
requisiti d’utente (analisi iniziale) e convalidare l’architettura /verificare il sistema.
Le sequenze di azioni, o flussi di eventi, possono essere: testuali (informale, formale, semi formale) in cui il
flusso è diviso in flusso principale (di base o primario) e uno o più flussi eccezione (alternativi); oppure
diagrammatici (diagrammi di interazione). Tale sequenza descrive solo gli eventi relativi al caso d’uso, e non
quel che avviene in altri casi d’uso; evita l’uso di termini vaghi (come "per esempio", "ecc." o
"informazione"). Il flusso degli eventi dovrebbe descrivere: come e quando il caso d’uso inizia e finisce,
quando interagisce con gli attori; quali informazioni sono scambiate tra un attore e il caso d’uso, tralasciando
i dettagli dell’interfaccia utente.
Attori: descrivono un ruolo che una persona o un dispositivo hardware o un sistema gioca rispetto al
sistema; eseguono casi d’uso (prima si cercano gli attori, poi i loro casi d’uso); possono non essere una
persona (ad es. un altro sistema o contenitore di informazioni); possono essere specializzati. Sono disponibili
istanze di attori che permettono ad un utente di agire come attori diversi, ad esempio come operatore e
cliente.
Gli attori vengono connessi ai casi d'uso mediante associazioni (relazioni di comunicazione, in cui entrambi
possono mandare o ricevere messaggi).
Nel definire gli attori si possono adottare due diversi punti di vista che corrispondono a diversi livelli di
astrazione: uno indipendente da particolari soluzioni organizzative e tecnologiche (modello dell’ambito
"business workflow") ed uno legato ad una particolare soluzione organizzativa e tecnologica (modello dei
servizi del sistema informatico). Possiamo quindi considerare due tipi di attori: buisness e di servizio.
Un caso d’uso consiste di: un unico nome; attori partecipanti; condizioni d’ingresso (precondizioni, ciò che
deve esser vero prima che il caso d'uso possa iniziare); flusso degli eventi; condizioni d’uscita
(postcondizioni, ciò che sarà vero al termine del caso d'uso). Rappresentano fonti di informazione per i casi
d’uso le specifiche del sistema, la bibliografia del dominio del sistema, interviste con gli esperti del dominio,
la conoscenza personale del dominio e l'osservazione di sistemi già esistenti. Sono documentati da:
● Una breve descrizione: descrizione generica e sequenziale del flusso di eventi di un caso d’uso che
consiste nel descrivere la precondizione (stato iniziale del sistema) ed elencare la sequenza di passi;
Include le interazioni con gli attori e descrive quali entità vengono scambiate; può contenere punti di
estensione ma dev’essere chiara, precisa e breve;
● Flusso dettagliato degli eventi: descrizione dei flussi primari ed alternativi (usati anche per gestire
situazioni erronee) degli eventi che seguono lo start-up dello use case.
La documentazione dovrebbe essere come un dialogo tra l’attore e lo use case perciò tutti i documenti sono
scritti in modo comprensibile per il cliente.
5.1
Organizzare i casi d'uso
Generalizzazione: Il caso figlio eredita comportamento e significato dal caso genitore; può aggiungere o
modificare comportamento del genitore; può essere sostituito in qualsiasi punto appaia il genitore.
Inclusione: Si usa per non descrivere più volte lo stesso flusso di eventi, inserendo il comportamento
comune in un caso d’uso a parte. Evita di copiare parti di descrizioni di casi d'uso. Quindi: fattorizza
comportamento comune, spesso nessun attore è associato al caso d’uso comune, sono possibili attori diversi
per i casi d’uso “chiamanti”.
Estensione: Permette di modellare la parte opzionale di un caso d’uso e i sottoflussi condizionali; permette
di inserire un sottoflusso in un punto specifico, regolato da un’interazione con un attore. Punti estensione
(nei flussi testuali). Quindi: distingue le varianti, gli attori associati eseguono il caso d’uso e tutte le
estensioni, l’attore è collegato al caso “base”.
Possono essere definite le seguenti proprietà per i casi d'uso: granularità (fine o grande); conseguire un
obiettivo preciso; i casi d’uso descrivono funzionalità osservabili dall’esterno del sistema; spesso catturano
funzioni visibili agli utenti; servono come base per il testing.
Andiamo ora ad analizzare la stesura dei casi d'uso che procede tramite l'adempimento di cinque punti:
identificare gli attori che interagiscono col sistema; organizzare gli attori; considerare l’interazione
principale; cercare le eccezioni agli scenari principali; organizzare i comportamenti come casi d’uso, usando
le relazioni di generalizzazione, inclusione ed estensione.
ESEMPIO: Gestione conto corrente
• Il sistema usa uno sportello Bancomat
• L’utente deve poter depositare assegni
• L’utente deve poter ritirare contante
• L’utente deve poter chiedere il saldo
• L’utente deve poter ottenere una ricevuta se
lo richiede. La ricevuta riporta il tipo di
transazione, la data, il numero di conto, la
somma, ed il nuovo saldo
• Dopo
ciascuna
transazione
viene
visualizzato il nuovo saldo
SOLUZIONE
A) Use case: withdraw
Precondition: User has selected withdraw option
Main flow:
• Include (Verify user)
• Check available funds of user
• Give money
• Prompt user for amount to
• Check available money of ATM • (print receipt)
withdraw
• Remove amount from account
• Print current balance
Exceptional flow
• If not sufficient funds or money available, prompt user for lower amount
B) Use case: deposit
Precondition: User has selected deposit option
Main flow:
• Include (Verify user)
• Open slot
• (print receipt)
• Prompt user for amount of deposit • Get check
• Print (balance+deposited amount)
C) Use case: check balance
Precondition: User has selected balance option
Main flow:
• Include (Verify user)
• Print balance
D) Use case: verify user
Precondition: none
Main flow:
• User enters ID card
• User enters PIN number
• System checks validity of card and number
Exceptional flow:
• If combination is not valid, reject user
E) Use case: withdraw with receip
Precondition: User has selected withdraw option and print receipt option
F) Use case: deposit with receipt
Precondition: User has selected deposit option and print receipt option
6.
La progettazione del software
La progettazione si apprende studiando i principali paradigmi evolutisi in relazione al progresso della
tecnologia e delle applicazioni. È importante distinguere metodologia dal paradigma. La prima è un insieme
di metodi, regole e postulati impiegati da una disciplina, che nasce da un analisi dei principi di conoscenza in
un dominio specifico e dallo studio dei metodi di analisi di tale dominio. Il secondo rappresenta un esempio,
un modello. Il paradigma oggi dominante è l’object-oriented.
Mentre l’analisi si occupa di definire la soluzione giusta per il problema giusto, la progettazione si occupa di
descrivere (anticipare) una soluzione al problema mediante un modello (rappresentazione semplificata della
realtà che contiene informazioni ottenute focalizzando l’attenzione su alcuni aspetti cruciali e ignorando
alcuni dettagli) che si ispiri ad un qualche paradigma.
Dopo l’analisi, distinguiamo almeno due fasi di progettazione: la progettazione architetturale, che
decompone il sistema in moduli e determina le relazioni tra i moduli, e la progettazione dettagliata, specifica
delle interfacce dei moduli che descrive funzionalmente i moduli stessi. Diversi meccanismi linguistici
vengono presi come elementi atomici (paradigmatici) della progettazione architetturale: procedure, funzioni,
coroutine, processi, moduli, oggetti, componenti, agenti.
L’architettura di un sistema software definisce una visione comune che tutte le parti interessate allo
sviluppo devono accettare e condividere. Un es. di tale architettura è la Micro-Kernel Architecture: è un
approccio che si basa sulla modularizzazione del kernel (il kernel è piccolo ed esegue solo le funzioni
essenziali, il resto sono programmi -moduli- a cui il microkernel accede per assolvere a tutte le altre
funzioni) il cui diagramma è diviso in tre parti: User Mode (in cui si distinguono i User Processes e i System
Processes), Kernel Mode (Micro Kernel), Hardware. Non esistono metodi universali per descrivere le
architetture sw; i più diffusi sono: disegni informali, diagrammi UML (vari), linguaggi architetturali.
Cosa NON è un’architettura: la maggior parte dei casi d’uso e delle classi con operazioni, interfacce e
attributi privati (nascosti); i casi di test e le procedure di test (di solito meno del 10% delle classi sono
rilevanti per l’architettura, l’altro 90% non è visibile).
I modelli del sw richiedono l'uso più viste; un buon modello ne include almeno quattro:
● vista Teleologica: descrive scopo e usi del sistema da progettare (eg. Documento di Marketing);
● vista Funzionale: descrive il comportamento di un sistema in relazione allo scopo (eg. Casi d’uso);
● vista Strutturale: descrive i componenti di un sistema e le loro relazioni (elementi e relazioni):
● vista Comportamentale: descrive il comportamento di un sistema in relazione ai cambiamenti del suo
ambiente (interazione dinamica tra Funzionale e Strutturale).
Le prime due viste sono “soggettive” (descrivono le intenzioni del progettista), le seconde “oggettive”
(descrivono proprietà future del sistema). Esempio in UML:
Use Cases
Interactions between a User & System
Process Description
Overview of process goals, participants
and collaboration.
Funzione
Interaction Diagrams
Behavior of core business elements in
process.
Class Diagrams
Basic business elements and their
relationships.
State Diagrams
Life cycle of core system elements in
process.
Deployment Diagrams
Actual structure of the final system
Comportamento
Fig. Visualizzare il software
Struttura
Livelli di astrazione
● Strutture dati e algoritmo;
● Classe (strutture dati e molti algoritmi);
● Package/Moduli (gruppi di classi correlate, magari interagenti via design pattern);
● Moduli/Sottosistemi (moduli interagenti contenenti ciascuno molte classi; solo le interfacce pubbliche
interagiscono con altri moduli/sottosistemi);
● Sistemi (sistemi interagenti con altri sistemi – hardware, software ed esseri umani).
La progettazione architetturale riguarda gli ultimi 2 livelli.
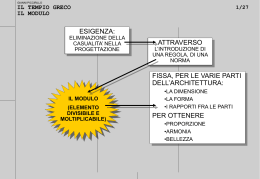
Modulo è un componente di un sistema che ha un’interfaccia ben definita verso gli altri componenti. Facilita
la composizione, il riuso e la riparazione del sistema, e rende flessibile la riconfigurazione. Un modulo
software è un contenitore di programmi e strutture dati. I moduli sono unità di incapsulamento quando
permettono di separare l’interfaccia dall’implementazione. L’interfaccia del modulo esprime ciò che il
modulo offre o richiede; gli elementi dell’interfaccia sono visibili agli altri moduli. L’ implementazione del
modulo contiene il codice corrispondente agli elementi dell’interfaccia e che realizza la semantica del
modulo. I moduli software possono essere compilati separatamente, facilitando così lo sviluppo parallelo, il
riuso e le riparazioni.
Gli obiettivi di progettazione sono: semplicità (spesso si coniuga con eleganza, il codice è più semplice da
capire e correggere, riduce gli errori), affidabilità e robustezza (gestire input inattesi, superare gli errori senza
crash, non far danni), efficacia (risolvere i problemi giusti, efficienza, integrazione e compatibilità con altro
software). Tra due progetti equivalenti è sempre da preferire quello strutturato in modo più semplice
possibile, che magari massimizzi la coesione (le relazioni intraclasse) e minimizzi l'accoppiamento (le
relazioni interclasse).
La coesione dei moduli misura della coerenza funzionale di un modulo software; ogni modulo dovrebbe
avere coesione alta. Un modulo ha coerenza funzionale se fa una cosa sola, e la fa bene. Le classi
componenti di grossi moduli dovrebbero essere funzionalmente correlate. Ci sono diversi tipi di coesione,
che vanno da un basso livello di coerenza (coincidentale) ad uno alto (funzionale):
● Coincidentale: molteplici azioni e componenti completamente scorrelati; l’oggetto non rappresenta una
singola nozione o racchiude codice scorrelato;
● Logica: serie di azioni o componenti correlate (e.g. libreria di funzioni di IO): il modulo contiene
funzioni correlate, se ne sceglie una mediante un parametro di invocazione (ad es. switch);
● Temporale: serie di azioni o componenti simultanee (e.g. moduli di inizializzazione); il modulo raccoglie
comandi che vengono elaborati in un certo breve periodo di tempo (es. tipico è il modulo di
inizializzazione);
● Procedurale: serie di azioni che condividono sequenze di passi;
● Comunicativa: coesione procedurale sugli stessi dati;
● Funzionale: una sola azione o funzione.
Per decidere il livello di coesione possiamo usare una serie di domande – passi:
Can the moduls be considered to be doing one problem-related function?
yes → 1. FUNCTIONAL
no → What relates the activies within the module?
Data → Is sequence important? → yes → 2. SEQUENTIAL
→ no → 3. COMMUNICATIONAL
Flow of control → Is sequence important? → yes → 4. PROCEDURAL
→ no → 5. TEMPORAL
Neither → Are the activitie in the same general categoty? → yes → 6. LOGICAL
→ no → 7. COINCIDENTAL
Se le attività in un modulo hanno diversi livelli di coesione, il modulo ha il grado di livello peggiore.
L' accoppiamento dei moduli misura del grado di indipendenza di un insieme di moduli software. I moduli
di un sistema dovrebbero riportare un accoppiamento basso (o lasco); questo si ottiene quando ci sono solo
poche dipendenze tra i moduli, tutte funzionalmente rilevanti e necessarie. In caso contrario, il software è
“fatto male” perché ad esempio risulta difficile da capire, mantenere, correggere, ecc… L’accoppiamento tra
i moduli può essere ridotto eliminando relazioni non necessarie, riducendo il numero o rilassando le relazioni
necessarie. Ci sono diversi tipi di accoppiamento, che vanno da un basso livello di indipendenza funzionale
di un insieme di moduli ad uno alto in modo crescente:
● Assenza di accoppiamento;
● Dati:
un modulo produce una struttura dati per un altro modulo che la consuma; output di un modulo è
input di un altro (es.: A passa X a B, dunque X e B sono accoppiati, perché una modifica all’interfaccia di
X richiede una modifica all’interfaccia di B);
● Stamp Couoling: un modulo fornisce parte di una struttura dati per un altro modulo;
● Controllo: un modulo passa un elemento di controllo ad un altro modulo;
● Esterno: dati comuni tra due moduli con accesso strutturato;
● Comune: i due moduli hanno accesso agli stessi dati globali;
● Contenuto: un modulo che referenzia il contenuto di un altro modulo.
Per ridurre le dipendenze vincolando la topologia delle relazioni fra i moduli, viene definita la gerarchia dei
moduli di un sistema sw. La struttura gerarchica dei moduli forma la base di progetto in quanto: decompone
il dominio del problema, facilita lo sviluppo parallelo, isola le ramificazioni di modifica e versionamento,
permette la prototipazione rapida.
Alcune relazioni gerarchiche tra moduli sono:
● X usa Y (dipendenza funzionale, es. call);
● X è_composto_da {Y,Z,W} (decomposizione architetturale: solo le foglie sono “vero” codice);
● X is_a Y (ereditarietà);
● X has_a Y (contenimento).
Lo standard IEEE 1016-1998 Software Design Description specifica la forma del documento dell'architettura
di sistema software.
7.
La progettazione orientata agli oggetti
I linguaggi ad oggetti includono un tipo di modulo chiamato classe, che è uno schema dichiarativo che
definisce tipi di oggetti, costituita da nome, attributi, operazioni/metodi. La dichiarazione di classe incapsula
la definizione dei campi e dei metodi degli oggetti creabili come istanza di classe.
Quattro concetti fondamentali: classe (nome collettivo -dichiarazione di tipo- di tutti gli oggetti che hanno gli
stessi metodi e variabili di istanza), oggetto (entità strutturata -codice, dati- e con stato la cui struttura e stato
è invisibile all’esterno dell’oggetto), stato (di un oggetto si accede e manipola mediante messaggi che
invocano metodi), variabili di istanza (contenute nell’oggetto, rappresentano il suo stato interno), messaggio
(richiesta ad un oggetto di invocazione di uno dei suoi metodi) metodo (azione che accede o manipola lo
stato interno del’oggetto). Con la programmazione OO si ha: decomposizione di un sistema mediante
astrazioni di oggetti; diversa dalla decomposizione funzionale/procedurale.
OOA: (analysis) Esaminare e decomporre il problema.
OOD: (design)Disegnare un modello del problema.
OOP: (programming)Realizzare il modello.
I processi OO hanno tutti la seguente struttura:
Elicitazione dei requisiti → Identificazione di scenari e casi d’uso → “Estrazione” delle classi
candidate → Identificazione di attributi e metodi → Definizione di una gerarchia di classi →
Costruzione di un modello a oggetti e relazioni → Costruzione di un modello di comportamento
degli oggetti → Revisione dell’analisi rispetto ai casi d’uso → Iterare se necessario.
Differenza tra approccio funzionale (non OO) e approccio OO:
● Componenti sono blocchi funzionali; in OO classi e oggetti.
● Astrazione e incapsulamento assenti o poveri; in OO sono meccanismi principali.
● Non modella il dominio del problema; in OO il sistema finale rispecchia il dominio del problema.
● Sequenziale (thread singolo); in OO c'è concorrenza (thread multipli).
Secondo Booch i principali elementi del paradigma OO sono:
● Astrazione Il progettista crea le classi e gli oggetti;
● Incapsulamento Information hiding (nascondere i dettagli inessenziali, accesso solo mediante operazioni
predefinite);
● Modularità Decomposizione in moduli ad accoppiamento lasco;
● Gerarchia ordinamento di astrazioni mediante ereditarietà (uso condiviso di attributi e codice in classi
diverse, utile per classificare entità, evitare ridondanze grazie al riuso del codice).
Sono da classificarsi elementi minori: Tipaggio (vincoli su classi e oggetti), Concorrenza (Thread multipli),
Persistenza (oggetti che sopravvivono nello spazio e nel tempo al programma che li crea).
OO garantisce l'information hiding (nascondere i dettagli inessenziali, accesso solo mediante operazioni
predefinite; es. invocazione getArea() restiruirà un valore senza mostrare l'implementazione).
Un linguaggio di modellazione permette di specificare, visualizzare e documentare un processo di sviluppo
OO; i linguaggi di modellazione più usati sono anche standardizzati. I modelli sono strumenti di
comunicazione tra cliente e sviluppatori.
UML(Unified Modeling Language) è lo standard utilizzato dalla Object Management Group. È un
linguaggio con una specifica semantica semiformale che include sintassi astratta, valide regole grammaticali
e semantica dinamica. Può essere espresso in diagrammi che abbracciano la gamma di costrutti di un tipico
sistema a oggetti. Tra questi diagrammi troviamo il diagramma delle classi (che presenta relazioni di
ereditarietà, associazione semantica, composizione e
aggregazione), di sequenza (vista temporale dello scambio
di messaggi tra classi) e di collaborazione (mostra le
interazioni tra gli oggetti), dei casi d'uso. Il diagramma di
sequenza e di collaborazione catturano in realtà lo stesso
significato, tanto che è facile convertire l'uno nell'altro. Il
primo ha un organizzazione molto rigida e pone l'accento
sulla sequenza temporale, mentre il secondo tende ad
Fig. Diagramma sequenza
essere utilizzato in modo più libero e flessibile.
La notazione UML, per i diagrammi di classe, offre tre importanti costrutti orientati agli oggetti (uses e
extends):
● eredità (generalizzazione): eredità singole e multiple;
● associazione generica :(0..*, 1..1, 1..n, ecc...);
l'associazione può essere promossa a classe
(graficamente la nuova classe NomeAssociazione è
collegata alla linea dell'associazione tramite linea
tratteggiata) per permettere di collegare ad essa attributi e
operazioni;
● associazione tutto/parte: prende il nome di composizione,
dove il tutto è il composto e il parte è il componente, o di
aggregazione, dove il tutto è l'aggregato e il parte è il
costituente. Il composto non esiste senza i suoi
componenti, l'aggregato sì; ciascun componente può
Fig. Diagramma di collaborazione
essere parte di un solo composto, invece, ciascun
costituente può esserlo per più di un aggregato; composizione tipicamente eterogenea, l'aggregazione
tende ad essere omogenea.
Responsibility-Driven Design Tecnica in cui le responsabilità di un oggetto (conoscere, fare, appòlicare)
guidano il suo design, che si concentra sul ruolo di un oggetto e su come il suo comportamento influenza gli
altri oggetti. Se si comincia dalle responsabilità di un oggetto risulta più semplice creare la sua interfaccia
pubblica, progettare il suo funzionamento interno e tener conto degli eventi da esso riconosciuti.
Le varie prospettive di modellazione possono portare a una vista strutturale (componenti), comportamentale
(attività), delle responsabilità (scopo entro un sistema).
Un approccio per capire quali sono le responsabilità dei vari oggetti prevede l'uso delle schede CRC, dopo
aver definito il problema e creato gli scenari d’uso (mediante interviste o concentrandosi sulle operazioni
principali). Le CRC card sono strutturate in campi: Classe, Supeclasse, Sottoclasse, responsabilità (compiti
da eseguire), collaborazioni (altri oggetti che cooperano con questo).
Le schede CRC definiscono le classi principali e le loro interazioni, per cui possono essere considrate uno
strumento di brainstorming. In seguito verrà usato UML per raffinare e documentare il progetto e per
descrivere il progetto ad altri.
8.
UML e RUP
UML è un sistema di notazioni principalmente grafiche (con sintassi, semantica e pragmatica predefinite) per
la modellazione OO di sistemi software. UML non è un processo, né è una notazione proprietaria. E' uno
standard OMG (Object Management Group), definito mediante un metamodello; è uno standard
internazionale, non è proprietà di una singola azienda. UML include: viste (mostrano diverse facce del
sistema: utente, strutturale, operazionale, ecc., anche in relazione al processo di sviluppo), diagrammi (grafi
che descrivono i contenuti di una vista), elementi di modellazione (costrutti usati nei diagrammi).
Aggiungo, rispetto a quando detto prima, un ulteriore diagramma, il diagrammi dei componenti. Illustra
l’organizzazione e le dipendenze tra i componenti software. Un componente può essere codice sorgente,
RunTime (libreria), eseguibile.
Fig. Diagramma dei componenti
Un componente software è “un’entità software non banale: un modulo, un package o un sottosistema che
abbia una funzione precisa ed un contorno ben delineato, e che possa essere integrato in un’architettura ben
definita”. Concetti chiave in questa definizione: non banale, funzione precisa, contorno ben delineato.
Le architetture modulari sono fatte di componenti ben formati. Occorre identificare, progettare, sviluppare e
testare i componenti; prima vengono testati da soli, poi integrati e testati nel sistema. I componenti
dovrebbero essere riusabili (specialmente se risolvono problemi ricorrenti, sono più che utilità di libreria).
Ogni organizzazione costruisce il proprio insieme di componenti riusabili. I componenti si possono comprare
già fatti (COTS: Components Off The Shelf): lo sviluppo di un sistema sw allora si riduce a trovare,
integrare e testare componenti.
Per quanto riguarda la configurazione del sistema, il diagramma di deployment mostra la configurazione a
run time degli elementi di calcolo e dei processi software che vivono in essi, inoltre visualizza la
distribuzione dei componenti all’interno dell’azienda.
UML, oltre a descrivere sw e servizi per utenti, sviluppatori, dirigenti e clienti, può descrivere l'uso del sw,
come funziona, come va costruito e l'accordo (contratto) tra il cliente e lo sviluppatore.
Per quanto possa essere essenziale, UML è solo una notazione standard; non specifica affatto il processo,
cioè il modo in cui dev’essere usata la notazione. È più efficace se viene esplicitamente combinato con un
processo di sviluppo; gli inventori di UML raccomandano la sua combinazione con RUP (Objectory = USDP
= RUP™ = UP).
Il processo RUP integra due diverse prospettive: una tecnica, che tratta gli aspetti qualitativi, ingegneristici e
di metodo di progettazione, l'altra gestionale, che tratta gli aspetti finanziari, strategici, commerciali e umani.
Le due prospettive sono rispettivamente articolate su sei e tre “core workflow”.
I workflow vengono suddivisi in (che possono essere estesi o ristretti):
● workflow di processo
Business modeling: attività che modellano l’ambito di risoluzione del problema, ovvero l’ambiente
esterno al sistema da produrre.
Requirements: attività che modellano i requisiti del sistema da produrre.
Analysis and design: attività di decomposizione del problema e progetto architetturale del sistema.
Implementation: attività di progetto dettagliato e codifica del sistema.
Test: controllo di qualità, sia a livello di moduli che di integrazione.
Deployment: attività di consegna e messa in opera.
● workflow di supporto
Configuration and change management: attività di manutenzione durante il progetto, ovvero richieste di
cambiamento e gestione della configurazione.
Project management: attività di pianificazione e governo del progetto.
Environment: attività che supportano il team di progetto, riguardo ai processi e strumenti utilizzati.
Potremmo dire, anche per quanto detto nel capitolo 2, che le qualità del RUP possono esser riassunte:
iterativo (ciclico), incrementale, OO, flessibile ed estendibile, gestito e controllato, altamente automatizzato.
Siccome non esiste un processo universalmente valido, RUP è stato progettato per essere flessibile,
estendibile, restringibile; permette di ridefinire la struttura del ciclo di vita, selezionare gli artefatti da
produrre, definire attività e ruoli dei worker, modellare nuovi aspetti di processo. È un vero e proprio
Framework di Processo.
Esistono innumerevoli strumenti di supporto alla progettazione con UML e RUP, tra i più famosi: Rational
Rose, Eclipse (open source da IBM) + Omondo, Microsoft Visual Studio, Together, Argo (open source) e
Poseidon (versione commerciale).
Un processo basato su RUP descrive chi fa cosa, come e quando, basandosi su 4 elementi principali:
● workers (chi): definisce comportamenti e responsabilità di un individuo o di un gruppo di individui che
lavorano in squadra (dunque un worker è un ruolo). Ad ogni worker viene associato un insieme di attività,
tali attività verranno logicamente eseguite dalla stessa persona. Il worker è responsabile di creare,
modificare e controllare certi artefatti. Un esempio di Worker è l'analista di sistema: individuo
responsabile di dirigere e coordinare l’elicitazione dei requisiti e la modellazione dei casi d’uso,
schematizzando le funzionalità del sistema e delimitandone i contorni.
● attività (come): definiscono il lavoro eseguito dai worker; ogni attività è assegnata ad un worker
specifico, per esempio un individuo responsabile della sua esecuzione. Un’attività è “una unità di lavoro
che un individuo in quel ruolo può dover eseguire e che produce un risultato significativo per il progetto”.
Le attività di solito hanno lo scopo preciso di creare un artefatto. La granularità temporale di un’attività
va da poche ore ad alcuni giorni. Le attività sono soggette a pianificazione e tracciamento. Le attività
sono articolate su tre tipi di passi:
- passi di riflessione (Thinking): comprendere la natura del compito, raccogliere ed esaminare gli artefatti
iniziali; riflettere sul risultato;
- passi esecutivi (Performing): creare o aggiornare artefatti;
- passi di revisione (Reviewing): ispezionare e valutare gli artefatti secondo qualche criterio.
Esempio di attività: Attività: Trovare Casi d’uso e attori.
Nel RUP si esprime così:
1. Trova attori
(Thinking)
2. Trova Casi d’Uso
(Thinking)
3. Descrivere interazione di attori e casi d’uso
(Performing)
4. Impacchettare attori e casi d’uso
(Performing)
5. Presentare modello dei casi d’uso in diagramma
(Performing)
6. Riassumere il modello dei casi d’uso
(Performing)
7. Valutare il risultato
(Reviewing)
● artefatti (cosa): in terminologia RUP, un artefatto è un documento prodotto, modificato o usato da una
attività, quindi è un prodotto “tangibile” del processo. Le attività hanno artefatti in input e output. Alcuni
di essi sono “deliverables”, cioè vengono consegnati e “congelati”. Un artefatto può includere altri
artefatti o esserne composto. Esempi di artefatti sono: un file sorgente, un file binario eseguibile, un
messaggio, un documento XML, un’immagine, uno script, un database (o anche una tabella di database),
un jar. Gli artefatti realizzano i componenti, o più in generale gli elementi del modello. Possono esserci
più artefatti associati a un componente, anche allocati su nodi distinti. Un componente può essere o
realizzato su nodi distinti. Solo gli artefatti risiedono (sono allocati) su nodi hardware, non i componenti.
La realizzazione di un modulo software è memorizzato in artefatti. Per esempio una classe (pensata come
modulo, e quindi come entità concettuale) è realizzata da un frammento di programma in un linguaggio di
programmazione, memorizzato in un artefatto, il file sorgente. Il risultato della compilazione del sorgente
è ancora un artefatto: un file che contiene la realizzazione (eseguibile) della classe. Gli artefatti spesso
hanno bisogno di controllo delle versioni. Gli artefatti RUP tipicamente NON sono documenti cartacei; di
solito sono documenti digitali on line, facili da modificare e dunque almeno in teoria sempre aggiornati.
Fig. Pianificazione artefatti RUP
●
workflows (quando): descrivono: quando i workers eseguono attività per produrre artefatti; le attività e
gli artefatti che dovrebbero produrre.
ES. Il Workflow dei Requisiti. Lo scopo del workflow dei Requisiti: costruire e conservare il consenso
degli stakeholder sull’obiettivo del sistema; migliorare la comprensione del sistema da parte degli
sviluppatori; delimitare i confini del sistema; fornire un punto di partenza per pianificare i contenuti
tecnici delle iterazioni; base di stima di costi e durata dello sviluppo del sistema; definire l’interfaccia
utente del sistema esplicitando gli obiettivi ed i bisogni degli utenti.
9.
Design patterns
“Ogni pattern descrive un problema che compare di continuo nel nostro ambito, e quindi descrive il nucleo
di una soluzione a tale problema, in modo da poterla usare più di volte, senza mai farlo allo stesso modo”.
I pattern permettono di sfruttare l’esperienza collettiva dei progettisti esperti, catturano esperienze reali e
ripetute di sviluppo di sistemi sw, e promuovono buone prassi progettuali. I pattern si possono combinare per
costruire architetture sw con proprietà specifiche.
Volendo cercare un pattern per diventare un Maestro progettista: prima si imparano le regole di progetto
(algoritmi, strutture dati e linguaggi); poi si imparano i principi di progetto (programmazione strutturata,
modulare e oo, concorrenza, ecc). Per diventare Maestro occorre comunque studiare i progetti di altri
Maestri, i progetti contengono pattern che vanno compresi, memorizzati e applicati ripetutamente. Esistono
centinaia di tali design pattern.
Un desig patter dunque è una descrizione di classi e oggetti comunicanti adatti a risolvere un problema
progettuale generale in un contesto particolare. Ogni pattern indirizza un particolare problema progettuale.
Proprietà:
● Sono un vocabolario comune per i progettisti;
● Sono una notazione abbreviata per comunicare efficacemente principi complessi;
● Aiutano a documentare l’architettura sw;
● Catturano parti critiche di un sistema in forma compatta;
● Mostrano più di una soluzione;
● Descrivono astrazioni software;
● Non costituiscono una soluzione precisa di problemi progettuali;
● Non risolvono tutti i problemi progettuali;
● Non si applicano solo alla progettazione OO, ma anche ad altri domini.
Tipi di pattern software:
● design patterns: architetturali (progetto di sistemi) [Buschmann-POSA]; progettuali (micro-architetture)
[Gamma-GoF]; idiomi (basso livello);
● pattern di analisi (modelli di analisi ricorrenti e riusabili [Flower]);
● pattern di organizzazione o di progetto;
● pattern di processo;
● pattern di dominio.
Secondo Alexander la forma canonica di un design pattern è schematizzata come segue:
•
Nome (nome significativo);
•
Problema (descrizione del problema di progettazione);
•
Contesto (una situazione dove ci si imbatte nel problema);
•
Forze (descrizione di forze e vincoli rilevanti);
•
Soluzione (soluzione comprovata al problema);
•
Esempi (applicazioni esemplificative del pattern);
•
Contesto risultante (risoluzione delle forze, stato del sistema dopo l’applicazione del pattern);
•
Rationale (spiegazione di passi o regole nel pattern);
•
Pattern correlati (relazioni statiche o dinamiche);
•
Uso noto (occorrenza del pattern e sua applicazione entro sistemi reali).
Mentre il formato GoF prevede:
•
Nome e classificazione del pattern;
•
Intento (cosa fa il pattern / quando funziona la soluzione);
•
Sinonimi (altri nomi noti del pattern, se ci sono);
•
Motivazione (il problema progettuale e come classi e oggetti lo risolvono);
•
Applicabilità (contesti in cui può applicare il pattern);
•
Struttura (rappresentazione grafica delle classi entro il pattern);
•
Partecipanti (classi e oggetti partecipanti e loro responsabilità);
•
Collaborazioni (tra i partecipanti per condividere le responsabilità);
•
Conseguenze (costi e benefici);
•
Implementazione (suggerimenti e tecniche);
•
Codice esemplificativo (frammento che mostra una possibile implementazione);
•
Usi noti (pattern trovati in sistemi reali);
•
Pattern correlati (pattern fortemente interrelati a questo).
Comunque gli elementi chiave dei design patterns sono principalmente quattro fra quelli proposti nelle due
forme precedenti: Nome del pattern, Problema, Soluzione, Conseguenze.
Schema:
[PATTERN-NAME]
Author
[YOUR-NAME] ([[email protected]]).
Last updated on [TODAY'S-DATE]
Context
[PARAG-1]
[PARAG-2]
Problem
[ONE-ASPECT]
[ANOTHER-ASPECT]
Examples
Forces
1.[FORCE-1]
2.[FORCE-2]
Design
[PARAG-1]
[PARAG-2]
An Implementation
[SOME-CODE]
Examples
Variants
[VARIANT]
[ANOTHER-VARIANT]
See Also
[ANOTHER-REF]
9.1
IF you find yourself in CONTEXT
for example EXAMPLES,
with PROBLEM,
entailing FORCES
THEN for some REASONS,
apply DESIGN FORM AND/OR RULE
to construct SOLUTION
leading to NEW CONTEXT and OTHER
PATTERNS
Design patter: MVC
Model, implementa algoritmi (business logic) indipendente dall’ambiente o interfaccia, View, comunica con
l’ambiente e l’utente e implementa l’interfaccia I/O del modello, Controller, controlla lo scambio di dati
(mediante notifica) tra model e view.
Se, ad esempio, decidessimo di apploicare MVC ad un videogioco, M sarà costituito da regole, strategie,
giocatori; V da bottoni, visualizzazioni; e C istallerà gli adattatori necessari per far comunicare model e view.
Relazioni di MVC con altri pattern
MVC disaccoppia le viste dai modelli:
● Disaccoppia gli oggetti, in modo che cambiare un oggetto che influenza molti altri oggetti non richiede
all’oggetto stesso di conoscere i dettagli degli altri;
● Il pattern Observer risolve il problema più in generale
MVC permette di annidare le views:
● Gli oggetti CompositeView agiscono come View
● Il pattern Composite descrive il problema più generale di raggruppare oggetti primitivi e compositi in
nuovi oggetti con interfacce identiche
MVC controlla la vista mediante il controller
● Esempio del pattern più generale Strategy
MVC usa inoltre i pattern Factory e Decorator
Sorgono però degli inconvenienti, ad es. che i cataloghi di pattern non bastano, inoltre, occorre spiegare non
solo il come, ma anche il perché dei pattern disponibili. Per far fronte a questi problemi vengono introdotti i
linguaggi per pattern che definiscono un vocabolario per i problemi di progettazione, forniscono un
processo per la soluzione sistematica di tali problemi e aiutano a costruire e riusare le architetture sw.
Quindi un linguaggio per pattern può esser definito come: collezione strutturata di pattern utile per
trasformare forze e vincoli in una architettura software; ma anche come collezione di pattern e regole per
comporli in uno stile architetturale (descrive framework o famiglie di sistemi correlati).
9.2
Il linguaggio di pattern di GoF
Scope
Class
Object
Purpose
Creational
Structural
Behavioral
Factory Method Adapter (class) Interpreter
Template Method
Abstract Factory Adapter (object) Chain of Responsibility
Bridge
Builder
Command
Composite
Prototype
Iterator
Decorator
Mediator
Singleton
Facade
Memento
Flyweight
Observer
Proxy
State
Strategy
Visitor
GoF, Pattern creativi: astrazioni dell’istanziazione (rendono un sistema indipendente da come gli oggetti
vengono creati, composti e rappresentati), incapsulano la conoscenza che ha un sistema sulle classi concrete
che usa, nascondono la creazione e la composizione delle istanze delle classi. Importante se il sistema evolve
e dipende più dalla composizione di oggetti che dall’ereditarietà; invece di codificare comportamenti
complessi prefissati si individua un insieme più piccolo di comportamenti fondamentali componibili.
GoF, Pattern strutturali: si usano per comporre classi e oggetti in strutture più grandi. I patter strutturali di
classe usano l’ereditarietà per comporre interfacce o implementazioni. Esempio: l’ereditarietà multipla il cui
risultato è una classe che combina le proprietà delle sue superclassi. Questo schema è utile soprattutto
quando occorre far lavorare insieme librerie di classi sviluppate indipendentemente.
GoF, Pattern comportamentali: basati su classi, di solito usano l’ereditarietà per descrivere algoritmi e flussi
di controllo, e su oggetti, di solito descrivono come collabora un gruppo di oggetti allo scopo di eseguire un
compito che non potrebbe essere portato a termine da un solo oggetto.
Ecco alcuni esempi di quando usare i pattern, e quali: è fondamentale leggere i requisiti, specie i non
funzionali; alcuni frasi idiomatiche potrebbero essere associate a qualche design pattern.
Testo: “indipendente dal costruttore hw o dal dispositivo”, “deve supportare una famiglia di prodotti” - AFP.
Testo: “deve interfacciare un oggetto pre-esistente” - Adapter Pattern.
Testo: “deve interfacciarsi con molti sistemi, alcuni dei quali verranno sviluppati in futuro”, “occorre esibire
un prototipo” - Bridge Pattern.
Testo: “struttura complessa”, “deve avere parametri variabili” - Composite Pattern.
Testo: “deve interfacciare un insieme di oggetti preesistenti” - Façade Pattern.
Testo: “must be location transparent” - Proxy Pattern.
Testo: “dev'essere estendibile”, “dev'essere scalabile” - Observer Pattern.
Testo: “deve fornire politiche indipendenti dai meccanismi” - Strategy Pattern.
Punti deboli nei pattern: non favoriscono il riuso di codice; alcuni di essi sono ingannevolmente semplici;
certe composizioni di pattern sono molto complesse; ci si può trovare travolti dai troppi pattern; i pattern
vengono convalidati dall’esperienza, non dal testing; integrare i pattern nel processo di sviluppo software è
costoso. Vediamo in dettaglio alcuni dei pattern maggiormente usati.
Factory Method definisce un interfaccia per creare un oggetto (ma sono le sottoclassi che decidono quale
classe istanziare) e permette ad una classe di differire l’istanziazione alle sue sottoclassi.
Un framework usa classi astratte per definire e gestire relazioni tra oggetti, deve anche creare oggetti: deve
istanziare le classi ma conosce solo le classi astratte, che non può istanziare. Il pattern Factory Method
incapsula la conoscenza di quali classi occorre creare, spostando tale conoscenza al di fuori del framework.
Il pattern Factory Method va usato quando: una classe non è in grado di anticipare quale classe di oggetti
deve creare; una classe desidera che le sue sottoclassi specifichino gli oggetti che crea; dato che le classi
delegano responsabilità ad una classe ancillare tra tante, e vogliamo localizzare la conoscenza di quale classe
ancella è la delegata.
Product: definisce l’interfaccia degli oggetti creati dal Factory Method.
ConcreteProduct: implementa l’interfaccia del prodotto Product.
Creator: dichiara il Factory Method che restituisce l’ogg di tipo Prodotto e si basa sulle sue sottoclassi per
definire il Factory Method in modo che restituisca un’istanza del ConcreteProduct appropriato. Può
contenere una implementazione di default del Factory Method.
ConcreteCreator: ridefinisce il Factory Method per restituire un’istanza di Concrete Product.
Fig. Struttura del Factory Method, mostra i vari partecipanti
Abstract Factory definisce una interfaccia per creare famiglie di oggetti correlati o dipendenti senza dover
specificare le loro classi concrete. Motivazione: una libreria di interfaccia utente che supporta molteplici
standard look and-feel (es. Motif, Presentation Manager); aspetti e comportamenti diversi per i widgets
d’interfaccia utente; le applicazioni non dovrebbero prefissare i loro widgets. Una soluzione prevederebbe i
seguenti “oggetti”: Abstract WidgetFactory class, interfacce per creare ciascun tipo base di widget, classe
astratta per ciascun tipo base di widget, le classi concrete implementano un look-and-feel specifico. Il pattern
Abstract Factory si usa quando; un sistema dev’essere indipendente da come i suoi prodotti vengono creati,
composti e rappresentati; un sistema dev’essere configurato per una specifica famiglia di prodotti, a partire
da molte; un insieme di oggetti correlati vengono progettati per essere usati insieme, ed occorre forzare
questo vincolo; si deve scrivere una libreria di classi di cui si espone solo l’interfaccia, non
l’implementazione.
Fig. Struttura dell'Abstract Factory, mostra i vari partecipanti
AbtractFactory: dichiara l’interfaccia per le operazioni che creano gli oggetti prodotto astratti.
ConcreteFactory: implementa le operazioni che creano gli oggetti prodotto astratti.
AbstractProduct: dichiara un interfaccia per un tipo di oggetto prodotto.
ConcreteProduct: definisce un oggetto prodotto che verrà creato da una factory concreta e implementa
l’interfaccia del prodotto astratto.
Client: usa solo le interfacce dichiarate dalle classi AbstractFactory e AbstractProduct.
Builder separa la costruzione di un oggetto complesso dalla sua rappresentazione in modo che lo stesso
processo di costruzione possa creare diverse rappresentazioni. Es. un lettore RTF dovrebbe poter convertire
RTF in molti formati. È utile usare questo pattern quando l’algoritmo per creare un oggetto complesso non
dipende dai componenti dell’oggetto stesso e da come vengono assemblati, e quando il processo di
costruzione deve permettere diverse rappresentazioni per l’oggetto da costruire. La struttura delle
collaborazioni può essere riassunta in quattro passi: Client crea Director (“newDirector(aConcreteBuilder)”)
e lo configura con il Builder appropriato; Director notifica a Builder quando dev’essere costruita una parte
del prodotto (“BuildPartA()” o “BuilPart B ()”); Builder gestisce le richieste di Director e aggiunge parti al
prodotto; Client ottiene il prodotto da Builder (“getResult()”).
Fig. Struttura del Builder
Prototype specifica i tipi di oggetti da creare usando un’istanza prototipale; crea i nuovi oggetti copiando il
prototipo. Usare il pattern Prototype quando: un sistema va reso indipendente (disaccoppiato) da come si
creano, compongono o rappresentano i suoi prodotti; quando le classi da istanziare sono specificate a tempo
di esecuzione, per esempio mediante caricamento dinamico; oppure per non costruire una gerachia di
“factory” analoga alla gerarchia delle classi dei prodotti; oppure quando le istanze di una classe possono
assumere uno stato scelto tra poche combinazioni diverse, può risultare conveniente istanziare un numero
corrispondente di prototipi e clonarli, invece di istanziare a mano la classe, ogni volta con lo stato
appropriato.
Prototype (Graphic) dichiara un’interfacca da clonare.
ConcretePrototype (Staff, WholeNote, HalfNote) implementa un’interfaccia da clonare.
Client (GraphicTool) crea un nuovo oggetto chiedendo ad un prototipo di clonarsi.
Fig. Struttura del Prototype
Singleton assicura che una classe ha una sola istanza, e fornisce un punto di accesso unico e globale. Questo
perché certe classi devono avere esattamente una istanza (es. print spooler, file system, window manager).
Una variabile globale rende un oggetto accessibile ma non proibisce l’istanziazione di oggetti multipli. La
classe sarà responsabile della sua unica interfaccia.
Usare il pattern Singleton quando deve esistere esattamente una istanza di una classe, che inoltre dev’essere
accessibile ai clienti da un unico punto di accesso predefinito; oppure quando l’unica istanza va estesa
mediante “subclassing”, e i clienti dovranno usare l’istanza estesa senza modificare il proprio codice.
Partecipante: Singleton definisce un’operazione Instance che permette ai clienti di accedere la sua unica
interfaccia; Instance è un’operazione della classe (static in Java); può essere responsabile di creare la sua
unica istanza.
Collaborazioni: i clienti accedono un’istanza di Singleton solo via l’operazione Instance.
Fig. Struttura del Singleton
10. La progettazione di architetture software
L'architettura è il progetto o la struttura complessiva di un sistema informatico, compresi hardware e
software di gestione; in particolare, la struttura interna di un microprocessore.
Per capire il concetto di progettazione architetturale usiamo tre definizioni:
“L’integrità concettuale è il principio più importante nella progettazione di sistemi. L’architettura del sistema
è la specifica completa e dettagliata dell’interfaccia utente.” [Brooks]
“Associa le funzioni di sistema identificate nella specifica dei requisiti ai componenti del sistema che le
implementeranno.” [Shaw & Garlan]
“L’obiettivo primario della progettazione architetturale è lo sviluppo di una struttura modulare del
programma e la rappresentazione delle relazioni di controllo tra i moduli.” [Pressman]
L’architettura sw riguarda la teoria alla base della progettazione del software; l’architetto sw propone
l’architettura sw come base per le specifiche di progetto. Per esistere, un’architettura sw dev’essere
documentata. Una descrizione architetturale precisa la struttura e il comportamento di un sistema.
Il disegno dell'architettura sw è il processo di progettazione dell'organizzazione globale del sistema, che
include: la decomposizione in sottosistemi e componenti; le decisioni sulle interazioni dei sottosistemi o
componenti; il disegno delle loro interfacce. Si rende utile perché tutti i partecipanti al progetto dovrebbero
conoscere l'architettura e le sue motivazioni. L'architettura spesso vincolerà l'efficienza, la riusabilità e la
manutenibilità del sistema.
La modellazione architetturale (architettura sw) permette di comprendere meglio il sistema e di lavorare a
ciascun componente separatamente, in più favorisce le estensioni al sistema e facilita riuso e manutenzione.
La struttura di un modello architetturale viene espressa mediante diverse viste: proiezione
dell’architettura secondo un criterio. Secondo questa definizione, una vista considera solo alcuni
sottosistemi, per esempio considera solo la strutturazione del sistema in componenti, o solo alcune relazioni
tra sottosistemi. Un tipo di vista caratterizza un insieme di viste. Le viste sono classificate in:
● viste di tipo strutturale: descrivono la struttura del software in termini di unità di realizzazione (che può
essere una classe, un package Java, un livello, etc.). Le viste di tipo strutturale sono utili per: costruzione
(la vista può fornire la struttura del codice che definisce la struttura di directory e file sorgente), analisi
(tracciabilità dei requisiti e analisi d’impatto, quest'ultima valuta le ripercussioni di una modifica nei
requisiti o nella realizzazione di un modulo sull’intero sistema), comunicazione (per es, permette di
descrivere la suddivisione delle responsabilità nel sistema agli sviluppatori coinvolti in un progetto già
avviato o in una fase di manutenzione.
● viste di tipo comportamentale (componenti e connettori): descrivono l’architettura in termini di unità di
esecuzione, con comportamenti e interazioni. Un componente è la parte fisica o rimpiazzabile di un
sistema che implementa una o più interfacce; può essere un oggetto, un processo, una collezione di
oggetti, etc.. (clienti, server, database, filtri, liv di astrazione); può essere semplice o composto. Un
connettore è un’entità architetturale che modella le interazioni tra i componenti e le regole che governano
tali interazioni; queste ultime possono essere semplici (chiamata di procedura, accesso a variabile
condivisa) o complesse (protocolli client-server, protocolli d’accesso a database, multicast di eventi
asincroni, flussi di dati, spazi di tuple). La vista comportamentale è utile per: analisi delle caratteristiche
di qualità a tempo d’esecuzione (funzionalità, prestazioni, affidabilità, disponibilità, sicurezza),
documentazione e comunicazione della struttura del sistema in esecuzione (flusso dei dati, dinamica,
parallelismo, replicazioni), descrivere stili architetturali noti, quali condotte e filtri, client–server, etc.
Condotte e filtri (pipe & filters): in questo stile i componenti sono di tipo filtro e i connettori di tipo
condotta. Caratteristica di un filtro è quella di ricevere una sequenza di dati in input e produrre una
sequenza di dati in output (trasformazioni stream-to-stream). Usa il contesto locale nell’elaborazione e
nessuno stato viene preservato tra due istanziazioni. Due o più filtri possono operare in parallelo: un filtro
a valle può operare sui primi dati della sequenza di output di un filtro a monte, mentre questo continua a
elaborare la sua sequenza di input. Casi particolari sono la pipeline in cui si restringe la topologia a una
sequenza lineare di filtri e i bounded pipes in cui si fissa una capienza massima per le condotte.
Dati condivisi (Shared data): stile focalizzato sull’accesso a dati condivisi tra vari componenti. Prevede
un componente che mantiene lo stato condiviso, per esempio una base di dati, e un insieme di componenti
indipendenti che operano sui dati. Lo stato condiviso, almeno in un sistema a dati condivisi “puro”, è
l’unico mezzo di comunicazione tra i componenti. Un connettore che colleghi la base di dati con i
componenti che operano sui dati può descrivere, ad esempio, un protocollo di interazione che inizia con
una fase di autenticazione.
Publish-subscribe: i componenti, caratterizzati da un’interfaccia che pubblica e/o sottoscrive eventi,
interagiscono annunciando eventi: ciascun componente si abbona a classi di eventi rilevanti per il suo
scopo. Un connettore di tipo publish–subscribe è un bus di eventi: i componenti, pubblicando gli eventi, li
consegnano al bus, il quale li consegna ai componenti (consumatori) appropriati. Un’architettura di
questo tipo disaccoppia produttori e consumatori di eventi: un produttore invia un evento senza conoscere
il numero né l’identità dei consumatori così da rendere possibili modifiche dinamiche del sistema, in cui,
ad esempio, varia l’insieme dei consumatori.
Cliente-servente (Client-server): i componenti sono di tipo cliente o di tipo servente. Le interfacce dei
serventi descrivono i servizi (o in generale le funzionalità) offerti; le interfacce dei clienti descrivono i
servizi usati. Le comunicazioni sono iniziate dai clienti e prevedono una risposta da parte dei serventi. I
clienti devono conoscere l’identità dei serventi, mentre il viceversa non importa. I connettori
rappresentano un protocollo di interazione che prevede nel caso base una domanda e una risposta. Può
però anche specificare, ad esempio, che i clienti inizino una sessione con il servizio, rispettino eventuali
vincoli sull’ordine delle richieste, chiudano la sessione.
Da pari a pari (peer to peer): i componenti sono sia clienti sia serventi e interagiscono alla pari, per
scambiarsi servizi. Le interazioni sono del tipo “richiesta–risposta”, ma non sono asimmetriche come nel
case cliente-servente: i connettori sono di tipo invokes–procedure e ammettono che l’interazione sia
iniziata da entrambi i lati. L’esempio classico di P2P sono le reti per la condivisione di file.
● viste di tipo logistico: considerano le relazioni tra un sistema software e il suo contesto (file system,
hardware e sviluppatori) .Sono caratterizzate da: elementi software di altre viste (moduli, componenti e
connettori), elementi dell’ambiente (hardware, struttura di sviluppo, file system) e relazioni. La relazione
allocato permette di mappare un elemento software su un elemento dell’ambiente. Altre relazioni sono
caratteristiche delle singole viste.
Mappando un’architettura sull’hardware è possibile analizzare le prestazioni del sistema, la sua resistenza
ai guasti (fault tolerance), le caratteristiche di sicurezza; la mappatura sul gruppo di sviluppatori permette
di pianificare e gestire il processo di sviluppo; infine, la mappatura sul file system permette di gestire
versioni e configurazioni.
Vista logistica di dislocazione (deployment): considera la mappatura degli artefatti, per esempio gli
eseguibili, su elementi (processori, dischi, canali di comunicazione, sistemi operativi, ambienti di
esecuzione, etc.) dell’hardware su cui viene eseguito il sistema (relazione allocato).
Vista logistica di realizzazione: considera la mappatura di moduli su file e directory. Un modulo
corrisponde a molti file: quelli che contengono i codice sorgente, file che contengono definizioni e che
devono essere inclusi, file che descrivono come costruire un eseguibile (tipo un makefile), file risultato
della compilazione. Gli elementi di questa vista sono quindi da un lato i moduli software, dall’altro gli
elementi di configurazione, tipo un file o una directory. Le relazioni sono allocato (tra un modulo e un
elemento di configurazione) e contiene (tra una directory e una sotto–directory o file contenuti).
Vista logistica di assegnamento del lavoro: considera la mappatura di moduli su persone o gruppi di
persone incaricate della loro realizzazione. Gli elementi sono da un lato i moduli, dall’altro le singole
persone, i gruppi, le divisioni, o ditte fornitrici esterne. La relazione è allocato, dai moduli alle persone.
Le viste sono modelli semplificati adattati al contesto. Non tutti i sistemi richiedono tutte le possibili viste;
ad es. con un solo processore la vista di deployment è inutile, con un solo processo la vista dei processi è
inutile. Per programmi piccoli la vista implementativa è inutile. In certi casi sono necessarie viste aggiuntive
come quella sui dati e quella di sicurezza.
Tutti i diagrammi UML possono essere utili per specificare aspetti del modello architetturale. Alcuni tipi di
diagrammi sono particolarmente utili: Package, Sottosistema, Component, Deployment.
Possiamo ora dare una definizione più accurata di architettura software: un’architettura è l’insieme delle
decisioni significative riguardo l’organizzazione di un sistema software, la scelta degli elementi strutturali (e
delle loro interfacce) da cui il sistema è composto, insieme con il comportamento specificato nelle
collaborazioni tra tali elementi, la composizione degli elementi strutturali e comportamentali in sottosistemi
progressivamente più grandi, e lo stile che guida questa organizzazione - gli elementi e le loro interfacce, le
loro collaborazioni e la loro composizione.
Sono importanti una serie di definizioni che fanno parte della terminologia architetturale:
● toolkit: insieme di classi correlate e riusabili progettato per offrire funzionalità utile e generica (es. C++
I/O stream library, Libreria di contenitori/iteratori/algoritmi); un toolkit non prevede un progetto specifico
per le applicazioni; fornisce di solito funzionalità ausiliarie.
● framework: generalizzazione di un sistema software; microarchitettura specializzata per un dominio
particolare che fornisce le interfacce che permettono ai clienti di adattarsi ad applicazioni specifiche entro
un certo spettro di comportamenti. Di solito ha due componenti: un insieme di classi che catturano il
vocabolario un certo dominio, una politica di controllo che orchestra le istanze di tali classi. Un
framework realizza un’architettura; di solito i grossi sistemi OO si costruiscono a partire da un insieme di
framework cooperanti (Esempi: .NET, Java Media Framework).
● design pattern: descrizione astratta di oggetti e classi cooperanti, che quando viene istanziata risolve un
problema di progettazione generale in un contesto particolare. È più astratto di un framework perché
quest'ultimo può essere incorporato nel codice, mentre il primo può solo avere esempi incorporati in
codice. I design pattern sono unità architetturali “più piccole” e meno specializzate dei framework.
● architettura: insieme di decisioni significative riguardo l’organizzazione di un sistema software
selezione degli elementi strutturali e delle loro interfacce che compongono un sistema; le modalità di
collaborazione tra gli elementi strutturali; composizione degli elementi strutturali e comportamentali in
sottosistemi via via più grandi; lo stile architetturale che guida tale organizzazione. L’architettura
software riguarda anche la funzionalità, le prestazioni, il riuso, la comprensibilità, la flessibilità, i vincoli
economici e tecnologici, ed anche certi aspetti estetici. Si cerca di avere architetture robuste, semplici e
comprensibili, con chiara separazione delle responsabilità, distribuzione bilanciata delle responsabilità ed
equilibrio dei vincoli economici e tecnologici.
L’architettura sw è importante per: registrare le decisioni iniziali di progettazione; capire il sistema;
organizzare il processo di sviluppo (è un documento di riferimento durante il ciclo di vita); promuovere il
riuso di componenti; facilitare l’evoluzione del sistema. Se non viene definita l’architettura del sistema,
incluse le sue spiegazioni, il progetto non dovrebbe avanzare nello sviluppo. Il documento di specifica
dell’architettura è usato durante tutto il processo di sviluppo e manutenzione successiva. Es. di architetture:
● Pipeline
● Master-Worker
● Sistema transazionale
● Livelli d’astrazione
● Interprete
● Sistema per-to-peer
● Repository
● Blackboard
● Modello a tre livelli
● Cliente-servente
● Sistema monolitico
● Controllo processi industriali
Una configurazione architetturale è un grafo connesso di componenti e connettori che descrivono una
struttura architetturale, basandosi su proprietà di connettività, proprietà concorrenti e distribuite, aderenza
alle regole stilistiche ed alle euristiche di progetto. I componenti compositi sono configurazioni.
Uno stile architetturale definisce una famiglia di sistemi in termini di un vocabolario di componenti e tipi di
connettori; un insieme di vincoli su come componenti e connettori possono essere combinati; uno o più
modelli (rappresentazioni di un sistema, già costruito o da costruire) semantici che specificano come le
proprietà complessive di un sistema possono essere determinate dalle proprietà delle sue parti componenti.
I modelli sono strumenti di comunicazione tra le parti interessate (stakeholders) al sistema. Spesso sono
grafici, hanno una scala e proprietà visuali. In molte discipline i modelli sono il linguaggio dei progettisti.
Una vista architetturale è una descrizione (un’astrazione) di un sistema da un particolare punto di vista;
riguarda aspetti particolari, ed omette entità che non sono rilevanti dal punto di vista prescelto. Sono viste
architetturali: Vista logico/funzionale, Vista del codice, Vista di sviluppo/strutturale, Vista della concorrenza
(processi e thread), Vista fisica o di deployment, Vista azioni d’utente (feedback).
Caratteristiche desiderabili: architetture robuste, semplici, comprensibili, chiara separazione delle
responsabilità, distribuzione bilanciata delle responsabilità, equilibrio dei vincoli economici e tecnologici.
La progettazione architetturale si basa su circa 14 fasi: Identificare i moduli (o sottosistemi) principali ed i
sottomoduli, le interazioni con gli attori ed i sistemi esterni, le dipendenze tra i moduli; determinare per
ciascun modulo le classi e le funzioni pubbliche; identificare quali classi pubbliche di ciascun modulo
interagiranno l’una con l’altra; determinare l’ordine di interazione tra i moduli e come interagiranno due
moduli usando esperienza e design pattern; identificare i metodi e funzioni che interagiranno con metodi e
funzioni di altri moduli; determinare le interazioni dinamiche (run-time); prototipare l’architettura;
documentarla; rivederla per cercare errori; ripetere il ciclo almeno un paio di volte assicurando la modularità,
l’estensibilità, la soddisfazione dei requisiti (specie le prestazioni); compilarla…
11. La qualità del software
Il prodotto deve soddisfare la sua specifica (i requisiti sono il fondamento su cui misurare la qualità), non
deve contenere difetti (ma è molto difficile produrre sw privo di errori), deve essere conforme a standard di
sviluppo, deve presentare le caratteristiche che ci si aspetta da una realizzazione professionale (es. si può
stimare il costo probabile di manutenzione del sw a partire da certe analisi?).
Come detto prima è difficile produrre sw non contenente errori. Gli esseri umani commettono errori, specie
quando eseguono compiti complessi; i programmatori esperti commettono circa un errore ogni 10 righe.
Circa il 50% degli errori di codifica vengono catturati a tempo di compilazione. Altri vengono catturati col
testing. Circa il 15% sono ancora nel sistema quando viene consegnato.
Tipi di errori nel software: Error (errore umano d'interpretazione della specifica o nell'uso di un metodo),
Failure (malfunzionamento, comportamento del sw non previsto dalla sua specifica), Fault (difetto del
sorgente, detto anche bug).
Esistono almeno tre classi di metodi che promuovono la qualità del sw:
● metodi convenzionali, orientati al prodotto, cercano di riparare gli errori dopo che sono stati fatti e
trovati;
● metodi orientati a standard di qualità totale, come ISO 9000 (orientato alla qualità di processo) e CMM,
orientati al processo;
● metodi “estremi”, come Cleanroom (orientato alla qualità di prodotto) e PSP, in cui le fasi del ciclo di vita
sono ridefinite una per una orientandole alla qualità.
Valutare la qualità del sw o garantirla è particolarmente complesso. Esistono attività legate alla qualità del sw
(es. testing), metodi, metamodelli di processo orientati alla qualità (es. GQM). In un qualsiasi ciclo di vita
del software le entità visibili e misurabili sono: processi (le attività), prodotti e risorse impiegate. La qualità
di un prodotto sw è la misura in cui il prodotto soddisfa la sua specifica. Gli attributi di qualità possono
essere esterni (visibili all’utente e includono correttezza, affidabilità, robustezza, efficienza, usabilità) o
interni (visibili ai costruttori/sviluppatori e includono complessità, verificabilità, manutenibilità, riparabilità,
evolvibilità, riusabilità, portabilità, leggibilità, modularità).
11.1
GQM
Goal Question Metric (GQM) è un approccio top-down per effettuare misure e controllare la complessità del
piano di misurazione. Inizialmente sviluppato per valutare gli errori in progetti NASA; metodo orientato alla
pratica. Permette di esplicitare la relazione tra gli attributi da misurare e gli obiettivi di qualità che si
intendono raggiungere aiutando a comprendere la dipendenza tra osservabili ed i relativi attributi dalla
qualità che si vuole misurare. Specializza gli obiettivi della misura sulla base di: specifiche esigenze del
progetto o dell’organizzazione, modello di processo o di prodotto, aspetti d’interesse della qualità. Passi:
Comprendere e analizzare gli obiettivi del progetto o organizzazione; per ciascun Goal ricavare un insieme
di domande od ipotesi che servono a quantificare gli obiettivi; stabilire quali attributi occorre misurare per
poter rispondere alle domande. GQM si usa per definire misure di progetto, processo e prodotto sw in modo
che: i dati di misurazione possano essere usati in modo utile e costruttivo, e le metriche e la loro
interpretazione riflettano i valori ed i punti di vista delle diverse parti interessate. GQM si basa su tre livelli:
● Livello concettuale (goal): un obiettivo (goal) per un oggetto di studio viene definito rispetto a vari
modelli di qualità e da vari punti di vista,
relativamente ad un ambiente particolare;
● Livello operativo (question): si usa un insieme di
domande per definire modelli dell’oggetto di studio
atti a valutare l’obiettivo richiesto;
● Livello quantitativo (metric): un insieme di metriche
base sui modelli viene associato ad ogni domanda in
modo da caratterizzare le risposte in modo misurabile.
GQM si può usare in tutte le le fasi di produzione sw; si può applicare ai progetti, ai processi ed ai prodotti.
11.2
ISO 9126
ISO 9126 è uno standard internazionale per la valutazione della qualità del software. Lo standard è diviso in
quattro parti: modello di qualità, parametri esterni, metriche interne, qualità in uso metriche.
Il modello di qualità stabilito nella prima parte della norma ISO 9126-1, classifica la qualità del software in
un insieme strutturato di caratteristiche e sotto-caratteristiche come segue:
Functionality (Funzionalità): serie di attributi che recano l'esistenza di una serie di funzioni e loro
proprietà specificate. Le funzioni soddisfano dichiarate o implicite esigenze. Include: suitability
(idoneità), accuracy (precisione), interoprability (interoperabilità), compliance (conformità), security.
● Reliability (Affidabilità): serie di attributi che riguardano la capacità del software di mantenere il suo
livello di prestazioni come indicato dalle condizioni per un determinato periodo di tempo. Include
maturity (maturità), recoverability (recuperabilità), fault tollerance (tolleranza ai guasti).
● Usability (Usabilità): serie di attributi che riguardano lo sforzo necessario per l'uso e la valutazione
individuale di tale uso. Includono learnability, understandability (comprensibilità), operability.
● Efficiency (Efficienza): serie di attributi che recano sul rapporto tra il livello di prestazioni del software e
la quantità di risorse utilizzate, ha dichiarato sotto condizioni. Include: time behaviour (tempo di
comportamento), resource behaviour (comportamento delle risorse).
● Maintainability (Manutenibilità): serie di attributi che recano sul sforzo necessario per fare le modifiche
indicate. Include: stability (stabilità), analyzability, changeability (mutevolezza), testability.
● Portability (Portabilità): serie di attributi che recano sulla capacità del software di essere trasferito da un
ambiente all'altro. Include: installability, replaceability, adaptability (adattabilità), co-existence.
La sotto-caratteristica di conformità non è elencato in precedenza e si applica a tutte le caratteristiche (ne
sono esempi la conformità alla legislazione in materia di usabilità e affidabilità).
●
11.3
Cleanroom
La filosofia alle spalle della cleanroom software engineering consiste nell'evitare la dipendenza da costosi
processi di rimozione degli errori scrivendo porzioni di codice corrette per principio e verificandone la
correttezza prima del collaudo. Il modello di processo corrispondente incorpora la certificazione statistica di
qualità delle porzioni di codice a mano a mano che vengono prodotte. Invece di creare un prodotto e poi
impegnarsi a eliminare i difetti, la soluzione a camera sterile impone una disciplina tesa a eliminare gli errori
nella specifica e nella progettazione e svolge la fabbricazione in un ambiente sterilizzato.
Adotta una versione specializzata del modello incrementale del processo software. Un gruppo di team piccoli
e indipendenti sviluppa un condotto di porzioni; quando queste verranno certificate, entreranno a far parte
del sistema. I compiti da svolgere per ogni porzione sono descritti in seguito:
● Pianificazione degli incrementi: di ogni incremento si stabiliscono la funzionalità, la dimensione stimata
e un calendario di sviluppo;
● Raccolta dei requisiti;
● Specifica della struttura a scatole: per descrivere le specifiche funzionali;
● Progettazione formale: le specifiche (scatole nere) vengono progressivamente raffinate (nell'ambito di
una porzione) fino a diventare analoghe a modelli dell'architettura e procedurali (scatole di stato o
chiare);
● Verifiche di correttezza: comincia dalla scatola a livello più alto (la specifica) procedendo verso la
progettazione dettagliata del codice;
● Generazione, ispezione e verifica del codice: per verificare la conformità semantica del codice e le
scatole, e la correttezza sintattica del codice;
● Pianificazione statica del collaudo: sianalizza l'uso previsto del sw; si pianificano e progettano i casi di
prova;
● Collaudo statistico d'uso: poiché il collaudo esaustivo è impossibile;
● Certificazione: si certifica la porzione, dichiarandola pronta per l'integrazione.
L'IS in cleanroom differisce dalle soluzioni tradizionali e da quelle OO per tre motivi: fa uso esplicito del
controllo statistico di qualità; verifica le specifiche progettuali mediante dimostrazioni di correttezza di tipo
matematico; si fonda sul collaudo statistico d'uso per scoprire gli errori più gravidi di conseguenze.
L'IS in cleanroom rispetta i principi operativi di analisi mediante la specifica a scatole.
Scatola nera: specifica il comportamento del sistema o di una parte di esso; quest'ultimo reagisce a stimoli
specifici (eventi) secondo opportune regole di transizione.
Scatola di stato: Racchiude i dati di stato e i servizi (operazioni), in modo simile agli oggetti; sono qui
rappresentati i simboli in ingresso (stimoli) e quelli in uscita (reazioni). Una scatola di stato rappresenta
anche la storia degli stimoli di una scatola nera, cioè i dati della scatola di stato che devono essere conservati
fra le relative transizioni.
Scatola chiara: definisce le funzioni di transizione relative a una scatola di stato; cioè contiene lo schema
procedurale per una scatola di stato.
Progettazione in camera sterile: le funzioni elaborative di base (descritte nelle prime fasi di raffinamento
delle specifiche) vengono raffinate tramite l'espansione a passi delle funzioni matematiche in strutture di
connettivi logici (come if-then-else) e sottofunzioni, condotta fino al punto in cui le sottofunzioni possono
essere direttamente espresse nel linguaggio di implementazione.
11.4
CMM
CMM (Capability Maturity Model) definisce alcuni livelli di qualità delle pratiche di produzione del
software in organizzazioni industriali:
● Iniziale: il processo è ad hoc (definito per singolo progetto) o addirittura caotico; il successo dipende
dalla qualità delle persone coinvolte;
● Ripetibile: vengono stabilite pratiche di registrazione dei costi, di pianificazione, di progettazione
funzionale; si tenta di riottenere successi conseguiti in progetti precedenti con pratiche analoghe;
● Definito: il processo è documentato sia per la parte manageriale che per quella tecnica, è standardizzato
ed integrato in una organizzazione disegnata appositamente; tutti i progetti usano una versione approvata
del processo standard locale sia nello sviluppo che nella manutenzione;
● Gestito: vengono raccolte misure dettagliate della qualità del prodotto e del suo processo di sviluppo; sia i
processi che i prodotti sono analizzati e controllati quantitativamente;
● Ottimizzante: il processo viene continuamente misurato e conseguentemente migliorato, anche mediante
introduzione di idee e tecnologie innovative.
Ai diversi livelli di qualità sono associate diverse tipologie di strumenti da usare nel processo:
● Iniziale: approccio individuale e artigianale; nessuno standard sugli strumenti; nessuna metrica di qualità;
nessun supporto per il riuso; produzione limitata a gruppi numericamente piccoli.
● Definito: specifica e standard di progetto sugli strumenti ed educazione all’uso di essi; meccanismi di
integrazione di strumenti; analisi quantitativa mediante metriche locali; riuso limitato di progetti e codice.
● Ripetibile: specifica e standard di organizzazione sugli strumenti; database di organizzazione; database
centrale di riuso; metriche standard di organizzazione, registrate e analizzate; educazione all’uso degli
strumenti basata su standard di organizzazione.
● Gestito: il miglioramento del processo di sviluppo è guidato da analisi quantitativa di dati metrici.
● Ottimizzante: l’organizzazione usa le metriche per valutare, confrontare ed eventualmente adottare
strumenti e tecnologie innovativi.
Con l'utilizzo del CMM è stato stimato il risparmio ottenibile ai vari livelli nella produzione di
un’applicazione di 200 KLOC, usando dati tratti da circa 1300 progetti. Nonostante ciò manca definizione
formale (la certificazione è data da esperti) e di supporto empirico consolidato; ignora l'importanza dei
singoli; istituzionalizza il processo ma non ne prescrive uno; migliora la maturità di produzione, non
necessariamente la qualità dei prodotti.
11.5
ISO 9000 e Spice
ISO 9000: ISO è un’agenzia che sviluppa e pubblica standard internazionali nell’area della gestione e
valuazione della qualità. Nel campo della qualità dei processi aziendali ISO ha pubblicato 5 documenti
principali: ISO 9000–9004 (già descritti in precedenza). Un’azienda può essere certificata ISO 9001, 9002, o
9003, ma la certificazione al momento ha solo valore nazionale. ISO 9003 è lo standard ISO 9001 specifico
per le aziende che producono sw. Nota: ISO 9001 è un sovrainsieme di ISO 9002, che a sua volta è un
sovrainsieme di ISO 9003.
SPICE (ISO/IEC-TR15504) & CMMI 1.1: si basa su sei livelli: incompleto, eseguito (esistenza di una
prassi di processo), gestito (pianificazione e gestione delle attività, qualità e integrità di prodotto),
prestabilito (esistenza di standard di processo e regole di adattamento, corretta utilizzazione delle risorse),
predicibile/gestito quantitativamente (uso effettivo di misurazioni di prodotto e di processo, controllo
quantitativo dei processi), ottimizzante (gestione e adattamento continui dei processi, prassi di continua
ottimizzazione).
Gli obiettivi dello standard SPICE sono: incoraggiare le organizzazioni a valutare i propri processi usando
metodi comprovati, consistenti ed affidabili; usare il risultato della valutazione come parte di un programma
completo di miglioramento organizzativo.
L’ambito è la valutazione, il miglioramento e la definizione delle capacità di processo. I domini da valutare
sono: acquisition, supply, development, operation, maintenance, supporting, processes e service support.
11.6
Attività legate alla qualità
Sono esempio di tali attività: testing, misurazione di attributi, verifica (confronto di un prodotto con la sua
specifica), validazione (accettazione del prodotto da parte del committente, ovvero, confronto di un prodotto
con i suoi requisiti), certificazione.
L’attività di verifica, così come quella di documentazione, non dovrebbe essere una fase separata del
processo. Ogni documento prodotto dovrebbe essere controllato (possibilmente da persone diverse dagli
autori) e sistematicamente documentato. Esistono due tipi di verifica: quello basato sull’analisi (ispezione) e
quello basato sull’esecuzione (testing).
Il testing si può usare per provare la presenza di errori in un programma, mai per dimostrarne l’assenza. È un
operazione difficile: molti sviluppatori non conoscono le principali tecniche il testing, il quale viene ritenuto
“noioso”; non sempre i requisiti sono chiari; occorre testare tutto, e spesso non c’è tempo; il testing
sistematico ed esaustivo è intrattabile.
Dopo aver testato la specifica di progetto (il testing inizia prima della codifica), è importante definire un
piano di test che sia completo (ma non eccessivo) usando una matrice di test o includendo test positivi e
negativi; bisogna trovare i casi di test interessanti e eseguire ogni test almeno due volte. Il piano deve essere
aggiornato durante lo sviluppo aggiungendo test di regressione e sfruttando il feedback degli utenti.
Metodi di test:
● diretti: di solito automatico, di basso livello, solo funzionalità base, sfrutta le specifiche (struttura
sequenziale);
● indiretti: di solito manuale, di alto livello, con scenari “realistici”, scopre molti errori imprevisti (struttura
a grafo).
Per cercare e colpire i punti vulnerabili vengono usate Black box e White box.
Testing di un modulo (eseguire esaustivamente il testing è impossibile):
● Black-box testing (funzionale, data-driven, I/O-driven): i casi di test sono definiti nel documento di
specifica; il codice del prodotto viene ignorato durante il testing. Sfrutta la semplicità apparente del
software facendo assunzioni sull’implementazione, grazie alla definizione del comportamento ingressouscita dei programmi per ricavare i casi di prova; adatto per testare le interazioni tra componenti, le
interfacce ed il comportamento. L’arte del black-box testing (che non prevede l’accesso al sorgente)
consiste nell’usare la specifica per predisporre un piccolo insieme di casi di test che massimizzi la
probabilità di trovare un errore e minimizzi quella che due test diversi trovino lo stesso errore. Viene
tipicamente svolto dopo il test a scatola bianca (non è alternativo, ma complementare ad esso).
Equivalence testing with boundary value analysis: i possibili dati di input e/o di output (definiti dalla
specifica) possono talvolta essere partizionati in classi di equivalenza; così si diminuiscono i casi di test
necessari e si possono usare i “boundary values” (valori di confine di partizione) per guidare il test.
Functional testing: dopo aver identificato nella specifica tutte le funzioni di un modulo, si definiscono i
dati di test necessari per controllare ciascuna funzione separatamente.
● White-box testing (strutturale, glass-box, logic-driven, path-oriented): sfrutta la struttura del controllo
(ovvero il grafo di controllo o di flusso) dei programmi per ricavare i casi di prova: viene tipicamente
svolto durante la fase di codifica. I casi di test sono definiti sul codice sorgente; adatta a testare funzioni
singole; sfrutta la complessità interna del software; occorre completa conoscenza dell’implementazione.
Testa l’implementazione ed il progetto; permette il test di parti del programma (a differenza del test a
scatola nera) e di coprire sistematicamente ogni parte dello stesso (spesso gli errori sono presenti nei
“casi particolari”). Esistono strumenti automatici che consentono di valutare la copertura del codice in
run-time.
Statement coverage: ogni comando viene eseguito almeno una volta (ma non c’è garanzia che ogni
condizione venga testata).
Branch coverage: ogni comando viene eseguito almeno una volta ed ogni condizione viene testata.
Path coverage: ogni cammino possibile viene testato almeno una volta.
Esempio (I/O-driven testing): se l’applicazione da testare ha 10 parametri di ingresso, e ciascuno può
assumere 5 valori, occorre testare 10^5 casi di input.
Sono inoltre necessarie metriche di complessità del sorgente per predire la quantità di errori probabilmente
presenti in un modulo, allo scopo di valutare quanta manutenzione si renderà necessaria. Esempi (cap
Manutenzione del sw): KLOC, num ciclomatico di McCabe, Software Science, Fan IN, Fan OUT.
Un altra tecnica da prendere in considerazione è quella che non utilizza il calcolatore, definita anche test
umano o analisi statica: si basa su tecniche non sono sostitutive del test al calcolatore che vanno utilizzate nel
lasso di tempo che intercorre fra la fine della codifica e l’inizio del test al calcolatore;
● Walkthrough e ispezione non si basano sull’esecuzione del programma e richiedono gruppi di almeno
quattro persone esperte e con competenze diverse (es. specificatore, progettista, programmatore,
controllore della qualità). Possono essere orientati alle persone partecipanti (che debbono prepararsi in
anticipo ad esporre dubbi e perplessità) oppure ai documenti di progetto (occorre un mentore che guidi la
lettura collettiva). Walktrough si basa su due fasi: preparazione (si forma il gruppo scegliendone
opportunamente i membri, che leggeranno in modo indipendente il codice da testare; ciascuno crea: una
lista delle cose che non capisce e una lista di errori), e analisi di gruppo (il controllore della qualità guida
gli altri alla scoperta ed alla registrazione degli errori, che non vengono corretti dal gruppo). Ispezione si
basa su: overview (il documento da testare viene illustrato dall’autore, quindi viene distribuito agli
ispettori), preparation (ogni ispettore legge il documento in modo indipendente dagli altri, e lo valuta
usando i risultati delle ispezioni precedenti), inspection (in una riunione presieduta dal responsabile di
progetto si usano checklist di errori potenziali e si “percorre” il documento), rework (l’autore del
documento lo riscrive per eliminare gli errori trovati), follow-up (il controllore della qualità controlla che
le correzioni non abbiano introdotto altri errori; se più del 5% del documento originale è stato modificato
si indice un’altra ispezione).
● Errori comuni: durante il processo di ispezione viene tipicamente usata una lista di errori più comuni che
non deve comprendere aspetti dello stile di programmazione. Presentiamo una classificazione di errori
indipendente dal linguaggio di programmazione (alcuni tipi di errori potrebbero non essere significativi in
Java, ma esserlo in C): errori di riferimento ai dati, di calcoli, di confronto, di controllo, di interfaccia, di
I/O.
Certificazione: attestazione, rilasciata da un organismo accreditato, atta ad assicurare, con un livello di
confidenza precisamente definito, la conformità a requisiti prefissati di un determinato prodotto, servizio,
processo, sistema di qualità o personale. Può essere di prodotto, di processo, professionale e può essere
ulteriormente classificate in:
● obbligatoria: Conformità alle Regole Tecniche cioè aderenza a quelle specifiche tecniche la cui
osservanza è obbligatoria per la commercializzazione o l’utilizzazione di un prodotto in uno Stato (art.
1.5 Dir. 83/189 CEE); garantisce solo il rispetto dei requisiti essenziali e quindi un livello basico di
qualità;
● volontaria: Conformità alle Norme Tecniche cioè aderenza a regole la cui osservanza avviene per scelta
del produttore; nonostante rientri solo nell’ambito della volontarietà, ciò non fa venir meno l’obbligo di
rispettare le norme stabilite una volta deciso di aderirvi (es. fornitori NATO).
La certificazione di processo si basa su modelli di maturità, i quali definiscono il processo attraverso i
requisiti che deve soddisfare (es. ISO 9000, MBA, CMM), e metodi di miglioramento, che definiscono la
strategia secondo cui il processo deve essere gestito e condotto (TQM, Six Sigma, BPR, SPICE).
12. La manutenzione del software
Modificare il sw dopo la consegna è inevitabile in quanto durante il suo uso emergono nuovi requisiti, o
l’ambiente operativo del sw cambia, o gli errori emersi durante l’uso vanno riparati, o viene aggiunto nuovo
hardware, o serve migliorare prestazioni e affidabilità. Quando parliamo di reingegnerizzazione, evoluzione,
trasformazione architetturale, aggiornamento o adattamento stiamo parlando di manutenzione del sw.
Tutte le organizzazioni hanno il problema di gestire i propri sistemi legacy. La gestione di famiglie di
versioni sw anch’essa necessita di tecniche di manutenzione efficaci.
Sistemi legacy
I sistemi sw sviluppati su commessa per un’organizzazione spesso hanno una vita operativa lunga; molti
sistemi sw in uso vennero sviluppati molto tempo fa usando tecnologie oggi obsolete. Tali sistemi sono
spesso critici, ovvero essenziali per il funzionamento normale dell’organizzazione che li usa; tali sistemi
vengono detti “legacy systems” (ereditati).
Def. Sistema Legacy: un sistema informatico o programma applicativo che continua ad essere usato a causa
del costo proibitivo di rimpiazzarlo o riprogettarlo, malgrado la sua scarsa competitività e compatibilità con
altri sistemi moderni. Questi sistemi sono di solito grandi, monolitici e difficili da modificare.
Chi rimpiazza un sistema legacy con un sistema sviluppato con tecnologie moderne si assume vari rischi
significativi: i sistemi legacy spesso non hanno una specifica completa e durante la loro vita hanno subito
modifiche anche importanti, di solito non documentate; i processi aziendali si basano sul sistema legacy, che
può seguire regole aziendali non documentate altrove; lo sviluppo di nuovo sw è rischioso di per sé.
Leggi di Lehman:
Law of continuing change: un sistema deve necessariamente cambiare ed evolvere per mantenere la sua
utilità, perché cambia l’ambiente in cui opera.
Law of increasing complexity: la struttura di un sistema che evolve si deteriora man mano che cambia, e
devono essere impegnate risorse aggiuntive per preservarne la semantica e semplificarne la struttura.
Law of large program evolution: l’evoluzione di un programma è un processo “autoregolante”. Sono
all’incirca invarianti per ciascuna versione attributi critici quali la dimensione, il periodo di tempo necessario
per la versione successiva, il numero di errori rilevati.
Law of organizational stability: durante il ciclo di vita di un programma la sua velocità di sviluppo è
all’incirca costante e indipendente dalle risorse dedicate allo sviluppo del sistema stesso.
Law of conservation of familiarity: durante il ciclo di vita di un sistema il tasso di cambiamento di ciascuna
versione è approssimativamente costante.
La manutenzione del sw viene distinta in manutenzione che corregge gli errori e di sviluppo. La prima
comprende: manutenzione preventiva (identifica e rimuove errori latenti, prima che vengano riscontrati;
adatta a sistemi con problemi di sicurezza), manutenzione correttiva (identifica e rimuove i difetti riscontrati
durante l’uso e corregge gli errori residui dopo il testing pre-delivery) e manutenzione d’emergenza (non
prevista, rischiosa perché prevede testing ridotto). La seconda comprende: manutenzione perfettiva (migliora
le prestazioni, l’affidabilità, la manutenibilità e aggiunge nuove funzionalità su richiesta del cliente) e
manutenzione adattiva (sviluppo o migrazione, adatta ad un nuovo ambiente).
L’incidenza della manutenzione sul costo complessivo di sviluppo di un sistema è crescente nel tempo
(seconda Legge di Lehman) e può giungere sino all’80%, di cui la manutenzione correttiva prende il 20%,
quella adattativa il 25% e quella perfettiva il 55%. Dunque la maggiorparte dei costi è attribuibile ai
mutamenti imposti dall’ambiente (prima Legge di Lehman).
ISO/IEC 15288
Lo scopo di questo processo di manutenzione è di sostenere la capacità del sistema di fornire un servizio.
Osserva la capacità di un sistema di erogare servizi, registra i problemi per poi analizzarli, intraprende azioni
correttive, adattive, perfettive e preventive, e conferma la riacquisizione della capacità di erogare il servizio.
Risultati del processo di manutenzione: sviluppo di una strategia di manutenzione; vincoli di manutenzione
come input ai requisiti; vengono resi disponibili elementi sistemici di rimpiazzo; vengono supportati servizi
che soddisfano i requisiti delle parti interessate, vengono registrate le necessità di modifiche correttive al
progetto; vengono registrati i fallimenti e i dati di vita operativa.
Lo standard IEEE 1219 (1993)
Definisce un modello di manutenzione di tipo iterativo su sette fasi: identificazione e classificazione; analisi;
disegno; implementazione; testing di sistema; test di accettazione; rilascio.
Lo standard ISO/IEC 12207 (1995)
Fornisce un quadro di riferimento ed una terminologia comune per tutti i processi del ciclo di vita del sw.
Individua processi, attività e task da sviluppare durante l’acquisizione di un sistema e dei relativi servizi, e
durante la forinitura, sviluppo, esercizio e manutenzione di prodotti sw. È molto più ampio di IEEE 1219.
IEEE/EIA 12207
Questo processo si attiva quando il prodotto sw viene modificato nel codice e nella documentazione correlata
a causa di un problema o per necessità di miglioramento o adattamento. L’obiettivo del processo è di
modificare il prodotto sw esistente preservando la sua integrità. Questo processo include la migrazione o il
ritiro del prodotto. Il processo di manutenzione termina col ritiro del prodotto.
L’uso del processo di manutenzione dovrebbe conseguire i seguenti obiettivi :
● definire l’impatto dell’organizzazione, delle operazioni e delle interfacce sul sistema esistente durante la
sua operatività;
● identificare e aggiornare i dati di ciclo di vita;
● sviluppare la modifica di componenti di sistema e la relativa documentazione, e controllare che i requisiti
del sistema non siano stati compromessi;
● far migrare gli aggiornamenti di sistema e di prodotto nell’ambiente dell’utente;
● assicurare che la messa in opera di nuovi sistemi o versioni non influenzi negativamente le operazioni
correnti;
● mantenere la possibilità di riassumere l’elaborazione mediante vesioni precedenti.
Fattori che influenzano il costo della manutenzione sono:
● Instabilità del personale: i costi di manutenzione aumentano se il personale addetto cambia spesso;
● Irresponsabilità dei progettisti: se gli sviluppatori del sistema non hanno responsabilità di manutenzione
non c’è incentivo per “design for change”;
● Inesperienza del personale: il personale addetto alla manutenzione è spesso poco esperto e con scarsa
conoscenza del dominio applicativo;
● Età e struttura del software: quando il programma invecchia la sua struttura si degrada e diventa più
difficile da capire e modificare.
La predizione o stima dei costi di manutenzione si basa sulla valutazione di complessità dei componenti del
sistema. Esiste evidenza empirica che gran parte dello sforzo di manutenzione di solito si spende su un
piccolo numero di componenti. La complessità di un prodotto sw dipende dalle strutture di controllo,
strutture dati e dimensioni di procedure e moduli.
Alcune misure di processo (metriche di processo) permettono di stimare i costi di manutenzione:# richieste
di manutenzione correttiva, il tempo medio necessario per analisi d’impatto, il tempo medio necessario per
soddisfare una richiesta di modifica, # richieste di modifica principale.
Se i valori di queste misure aumentano, abbiamo un’indicazione di manutenibilità decrescente e conseguente
aumento dei costi relativi
Per quanto riguarda le metriche di prodotto, tra esse compaiono: dimensione (LOC-, o Kilo LOC -KLOC),
complessità ciclomatica di McCabe (misura il numero di cammini esecutivi indipendenti, o il numero di
condizioni binarie), complessità di Halstead (o Software Science, misura il numero di operatori e operandi
nel programma), metriche strutturali: misure di accoppiamento basate su Fan in e Fan out dei moduli).
La dimensione del programma in KLOC influenza il costo di manutenzione: programmi più grandi
richiedono un maggiore sforzo di manutenzione. Il numero di difetti per KLOC (tasso di difettosità, o defect
rate) ha una relazione curvilineare con la dimensione dei moduli: ciò suggerisce che esista una dimensione
ottima dei moduli che induce il minimo tasso di difettosità; tale dimensione però dipende da prodotto,
linguaggio e ambiente operativo.
La complessità ciclomatica di McCabe è una delle più note metriche di manutenzione [McCabe 76]; stima
la manutenibilità del programma (testabilità e comprensibilità) misurando il numero di cammini esecutivi
indipendenti; tale numero è un indicatore dello sforzo necessario per testare un programma. Questo tipo di
complessità cerca di valutare quanta “fiducia” possiamo avere che un programma sia privo di errori; è
indipendente dal linguaggio di programmazione ed è usata spesso in combinazione con altre metriche. È
stata estesa per comprendere la complessità progettuale di un sistema [McCabe 89].
Calcolo complessità ciclomatica: la misura M si calcola sul diagramma di flusso del programma M = e - n +
2p, dove e = numero di archi, n = numero di nodi, p = numero di sottografi sconnessi.
Esempio: programma con due comandi condizionali (if-then-else); 8 archi, 7 nodi, 1 solo sottografo. Quindi
M = 8 - 7 + 2 * 1 = 3, M = Numero di condizionali + 1. Un condizionale a n vie (case select) viene contato
come n-1 condizionali binari.
McCabe misurò parecchi programmi, stabilendo intervalli di complessità che aiutano il progettista a
determinare il rischio e la stabilità del suo programma. Questa misura si può usare durante lo sviluppo, la
manutenzione e la reingegnerizzazione per ottenere stime di rischio, costo o stabilità del programma. Studi
empirici mostrano una buona correlazione tra la complessità ciclomatica di un programma e la frequenza di
errori. Una bassa complessità ciclomatica è indicatrice di buona comprensibilità del programma e sua
modificabilità a basso rischio.
La complessitò ciclomatica di un modulo è un' ottimo indicatore della sua testabilità; un'applicazione tipica
della complessità ciclomatica di un modulo è di valutarla mediante la seguente scala di valori:
Complessità ciclomatica
Valutazione del rischio
1-10
programma semplice, rischio minimo
11-20
rischio moderato
21-50
programma complesso, rischio alto
maggiore di 50
programma non testabile, rischio altissimo
La complessità ciclomatica si può usare per:
● Analisi del rischio durante la stesura del codice;
● Analisi del rischio di cambiamento durante la manutenzione: la complessità del codice aumenta nel
tempo a causa delle manutenzioni; misurando la complessità ciclomatica prima e dopo un cambiamento
si può monitorare la configurazione del sistema e decidere come mimizzare il rischio di ulteriori
cambiamenti;
● Reingegnerizzazione: l'analisi della complessità ciclomatica valuta la struttura di un sistema; dunque il
rischio di reingegnerizzazione di una parte del codice è correlato alla sua complessità.
La complessità ciclomatica si può usare durante il testing per definire il numero di cammini indipendenti da
testare, per calcolare il path coverage set (insieme dei cammini che eseguiranno tutti i comandi e valuteranno
tutte le condizioni logiche almeno una volta; non è unico), definire un insieme minimale di casi di test.
La complessità di Halstead si applica direttamente al sorgente del programma; si può usare direttamente
come metrica di manutenzione, tuttavia il suo uso non gode di consenso unanime: le opinioni in merito
variano da “oscura e inaffidabile” [Jones 94] a “una delle migliori metriche di manutenibilità” [Oman 91].
Un programma si compone di un numero finito di token, classificati in operatori (ogni simbolo o parola
chiave che specifica un'azione) e operandi (ogni simbolo che rappresenta dati). La complessità di un
programma, ed il suo tempo di sviluppo, è proporzionale al tipo e numero di operatori e operandi che
contiene. Grazie alle seguenti variabili definiamo le misure di Halstead:
n1 = # di operatori distinti in un programma
N1 = # di occorrenze di operatori
n2 = # di operandi distinti in un programma
N2 = # di occorenze di operandi
Lunghezza del programma N = N1 + N2
Vocabolario del programma n = n1 + n2
Volume V = N * (log2 n)
Difficoltà D = (n1 /2) * (N2/n2)
Sforzo E = D * V
Una critica alla complessità di Halstead riguarda l'ambiguità della definizione di operatore e operando, in
quanto può essere difficile decidere cos'è operatore e cos'è operando; inoltre queste metriche misurano la
complessità lessicale e testuale più che la complessità strutturale o logica.
Metriche di struttura modulare
Stimano l'accoppiamento tra moduli, invece le metriche LOC, Complessità Ciclomatica, Complessità di
Halstead misurano la complessità dei singoli moduli come se fossero entità separate. Vengono usate le
variabili Fan-in (# di moduli che chiamano un certo modulo) e Fan-out (# di moduli chiamati da un certo
modulo). I moduli con grande fan-in di solito sono piccoli e appartengono ai livelli inferiori di un'architettura
sw a livelli. I moduli grossi e complessi hanno di solito fan-in piccolo. I moduli con grande fan-out
dipendono da parecchi moduli e alzano il livello di accoppiamento. Dunque se ci sono moduli con fan-in
piccolo e fan-out grande abbiamo un'indicazione di cattiva qualità di progettazione.
Metriche di manutenibilità
La manutenibilità è la misura in cui un sistema sw ammette modifiche per estendere il suo tempo di uso. Si
hanno due prospettive sulla manutenibilità: una interna (dipende solo dalle caratteristiche del sistema) ed una
esterna (dipende anche dal personale di manutenzione, dall'ambiente di supporto, dalla documentazione e
dagli strumenti disponibili).
Per quanto riguarda queste metriche si cerca di avere valori bassi in: quantità di risorse necessarie, # persone
necessarie (manutentori) / dimensione del codice, tempo per costruire eseguire e testare, complessità del
codice, numero di versioni da gestire, tempo medio per fare una modifica, costo medio per correggere un
difetto dopo il rilascio, # di file oggetto ricompilati dopo una modifica ad un file sorgente, quantità di codice
morto, grado di accoppiamento tra i moduli. Si cerca invece di avere valori alti in: numero di design pattern
usati, livello del linguaggio di programmazione, rapporto tra linee commento e linee codice, numero di test
di regressione, percentuale dei manutentori che dicono che il codice è facilmente modificabile, rapporto tra
numero di moduli e dimensione del codice, numero di moduli ad alta coesione sul totale dei moduli.
Nel 1991 Oman e Hagemeister introdussero una metrica composita per quantificare la manutenibilità del
software. Questo Indice di Manutenibilità (Maintainability Index o MI) ha oggi molte varianti ed è stato
applicato con successo a molti sistemi sw industriali. MI incorpora le metriche di Halstead (sforzo o
volume), la complessità ciclomatica di McCabe, la dimensione in LOC, ed il conteggio dei commenti.
MI = 171 - 5.2 * ln(aveV) - 0.23 * aveV(g') - 16.2 * ln (aveLOC) + 50 * sin (sqrt(2.4 * perCM))
I coefficienti ponderali sono stati derivati empiricamente; i termini dell'equazione sono: aveV (Volume di
Halstead medio V per modulo), aveV(g') (complessità ciclomatica estesa media per modulo), aveLOC
(media LOC per modulo), perCM (percentuale media di righe commento per modulo).
Un'altra versione omette il termine "perCM":
MI = 171 - 5.2 * ln(aveV) - 0.23 * aveV(g') - 16.2 * ln (aveLOC)
Questa composizione di metriche spiega perché si voleva incorporare nell'indice complessivo: la densitò di
operatori e operandi (quante variabili ci sono e come vengono usate), la complessità logica (da quanti
cammini esecutivi è composto il codice), la dimensione (quanto codice c'è), L'apporto dell'intuizione umana
(commenti nel codice).
La complessità ciclomatica estesa tiene conto della complessità aggiuntiva derivante dalle espressioni
condizionali complesse; un'espressione condizionale complessa contiene condizioni multiple separate da OR
o AND. Quando un costrutto di controllo contiene un'espressione logica con OR e/o AND, la misura di
Complessità Ciclomatica Estesa aumenta di uno per ciascun operatore logico impiegato nel costrutto.
Esistono parecchi strumenti in grado di supportare la manutenzione del software molti dei quali registrano
misure utili per valutare l’indice di manutenibilità.
Scarica