UNIVERSITÀ DEGLI STUDI DI SIENA
FACOLTÀ DI INGEGNERIA
CORSO DI LAUREA IN INGEGNERIA INFORMATICA
MODULO PROFESSIONALIZZANTE
"TECNOLOGIE PER IL KNOWLEDGE MANAGEMENT"
A.A. 2005/2006
DISPENSE DI
CALCOLATORI ELETTRONICI 1
Hanno collaborato alla stesura delle dispense:
Sara Belloni
Paolo Bennati
Riccardo Brogi
Elena Caini
Saverio Carito
Matteo Carletti
Ilaria Castelli
Ludovico Ciacci
Paolo Cini
Manuela Cippitelli
Elena Clementi
Matteo Collini
Andrea Corsi
Andrea Corsoni
Luca Daveri
Mauro De Biasi
Lucia Di Noi
Alessandra Di Tella
Pierluigi Failla
Valentina Fambrini
Samuele Forconi
Lucia Gentili
Roberto Giorgi
Annamaria Giovannoni
Francesco Gnarra
Ciro Guariglia
Mirko Leommanni
Michele Moramarco
Riccardo Nieto
Giacomo Novembri
Davide Pallassini
Carlo Alberto Pascucci
Erik Peruzzi
Gabriele Petri
Marcello Piliego
Nicola Pisu
Claudio Rocchi
Laura Romano
Francesco Russo
Fabrizio Simi
Carlo Snickars
Martina Tiribocchi
Andrea Tommasi
Francesco Vivi
Matilda Xheladini
Matteo Zampi
La dispensa e' rilasciata per uso dei soli studenti
del Corso di Calcolatori Elettronici 1
del Corso di Laurea di Ingegneria Informatica
della Facoltà di Ingegneria
Università degli Studi di Siena
Copyright notice
All figures from Computer Organization and Design: The Hardware/Software Approach, Second Edition, by David Patterson and
John Hennessy, are copyrighted material. (COPYRIGHT 1998 MORGAN KAUFMANN PUBLISHERS, INC. ALL RIGHTS
RESERVED.)
Figures may be reproduced only for classroom or personal educational use in conjunction with the book and only when the above
copyright line is included. They may not be otherwise reproduced, distributed, or incorporated into other works without the
prior written consent of the publisher.
INDICE
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
Lezione
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
Introduzione
Assembly MIPS (parte prima)
Assembly MIPS (parte seconda)
Valutazione delle prestazioni (parte prima)
Valutazione delle prestazioni (parte seconda)
Valutazione delle prestazioni (parte terza)
Standard IEEE-754 per le operazioni floating point
Assembly MIPS
Interrupt
Implementazione di semplice CPU MIPS
BUS
BUS PCI, SCSI e USB
Tecniche di pilotaggio dei dispositivi I/O
Esempi di dispositivi di I/O: il timer e la porta seriale
Hard disk
Introduzione al sottosistema di memoria
Introduzione alla memoria cache (parte prima)
Introduzione alla memoria cache (parte seconda)
Memoria virtuale
Pipeline
LEZIONE 1
Introduzione
1.1 INTRODUZIONE
Queste dispense sono state raccolte con lo scopo di fornire un riferimento sintetico alla
materia trattata nel Corso di Calcolatori Elettronici 1 presso la Facolta’ di Ingegneria
dell’Universita’ di Siena. Per gli approfondimenti (molti!) alla materia si rimanda ai Testi di
Riferimento del corso [1], [2], [3], [4], [5], [6], [7] e ai Riferimenti Bibliografici posti al
termine di ognuna delle venti lezioni. Gli argomenti di una lezione vengono tipicamente trattati
in circa due ore. Accompagnano il materiale didattico del corso, gli esercizi proposti nelle
prove di esame e i simulatori architetturali (disponibili sul sito web del corso [8]).
1.1.1 Prerequisiti del Corso
Per affrontare il corso di Calcolatori Elettronici 1 è opportuno aver acquisito alcune
conoscenze di base dai corsi precedenti, con particolare riferimento a:
• struttura base della macchina (macchina di Von Neumann, ciclo fetch-execute);
• lettura e scrittura di programmi C;
• passi per eseguire il programma (compilazione, collegamento, caricamento, esecuzione);
• progetto logico di un circuito (componenti logici, macchine a stati finiti,).
1.2 STRUTTURA DEL CORSO
I tre
•
•
•
principali obiettivi che il corso si propone di raggiungere sono:
imparare a misurare e analizzare le prestazioni di un Calcolatore;
capire l’architettura di un Calcolatore;
individuare possibili ottimizzazioni per migliorare le potenzialità di un Calcolatore.
1.2.1 Analisi delle prestazioni
Per poter valutare la bontà di un Calcolatore è necessario innanzitutto mettersi d’ accordo su
come misurarne le prestazioni relativamente allo scopo che si vuole adibire a quella macchina.
L’obiettivo della prima parte del corso è quindi quello di analizzare i fattori che influenzano le
prestazioni, capire come effettuare un’analisi quantitativa di essi e discutere di come questi
siano influenzati dall’architettura scelta. Gli argomenti affrontati in questa prima parte sono:
• definizione “software” della macchina (lezioni 2,3);
• metriche e benchmark per la valutazione delle prestazioni (lezioni 4,5,6);
• influenza dei criteri prestazionali sulla definizione “software” (lezioni 7,8,9).
1.2.2 Analisi dell’architettura
Per comprendere l’architettura dei moderni Calcolatori si analizzera’ l’organizzazione interna
dei principali elementi della macchina cosi’ come sono oggi realizzati: processore, memoria,
sottosistema di input/output (I/O). I principali argomenti trattati in questa parte sono:
• struttura del processore: parte di controllo e datapath (lezione 10);
• reti di interconnessione e interfacciamento (lezioni 11,12);
• sottosistema di Input/Output (lezioni 13,14,15);
• memoria (lezione 16).
1.2.3 Meccanismi architetturali per il miglioramento delle performance
Parti “accessorie” del Calcolatore ma ormai quasi universlamente utilizzate sono:
• memoria cache (lezioni 17,18);
• memoria virtuale (lezione 19);
• pipeline (lezione 20).
1.1
1.3 EVOLUZIONE DEI CALCOLATORI
1.3.1 La legge di Moore
Il forte sviluppo dei Calcolatori Elettronici dipende in gran parte dai progressi della
Tecnologia Elettronica e in particolare dei Circuiti Integrati la cui capacita’, in termini di
numero di transistor e quindi di funzionalita’ ha seguito per oltre 40 anni la Legge di Moore:
“Il numero di transistor su singolo chip raddoppia ogni 18 mesi”
Nel 1965, Gordon Moore (che successivamente nel 1968 fondo’ con R. Noyce la ditta Intel)
osservo’ l’evoluzione dell’industria elettronica nei 6 anni precedenti (1959-1965) e gli sembro’
ragionevole una proiezione [9] secondo cui il numero di “componenti a minimo costo” in un
circuito integrato sarebbe raddoppiato ogni 12 mesi; questa supposizione si rivelò corretta “al
90%” fino al 1975. Osservando invece, il numero di transistor nei processori Intel da meta’ del
1971 (anno di introduzione del processore 4004, con 2300 transistor) a fine del 2000 (anno di
introduzione del processore Pentium-4, con 43 milioni di transistor) si puo’ osservare un
raddoppio dei transistor solo ogni 24 mesi (in parte questo è contemplato in [9]). Altri (non
Moore) hanno fatto si’ che quella formulata sopra sia la versione “popolarmente acclamata
della Legge di Moore”.
Pent 4
Pent III
Pent II
Pent Pro
Pent.
Migliaia di Transistor
10000
486SL
486
286
100
8086
8080
4004
1
1972
1976
1980
1984
1988
1992
1996
2000
Figura 1.1: La legge di Moore.
A prescindere dalle diverse interpretazioni, resta comunque il dato di fatto di uno
stupefacente incremento, che non ha eguali in nessun altro settore industriale. Simili
incrementi si possono altresi’ registare per altri componenti dell’Architettura del Calcolatore:
• Processore: Porte logiche:
+30%/anno
Velocità clock:
+20%/anno
• Memoria:
Dimensione:
+60%/anno
Velocità:
+9%/anno
Costo per bit:
+25%/anno
• I/O (Disco): Dimensione:
+60%/anno
1.3.2 I tipi di Calcolatori Elettronici
Si puo’ dire che agli inizi del terzo millennio le tipologie di Calcolatori esistenti sono
sostanzialmente tre (v. anche figura 1.2):
• Sistemi Desktop (principalmente analizzati in questo corso);
• Sistemi Server (Network of Workstation, Supercomputer, Parallel Computers);
• Sistemi Embedded (dai telefonini ai palmari e ai sistemi di controllo industriale).
1.2
Mainframe
Massively
Parallel Processors
Vector
Supercomputer
Minicomputer
Portable
Computers
Networks of Workstations/PCs
Figura 1.2: Computer Food Chain.
Altre tipologie introdotte agli albori dell’introduzione dei “Calcolatori a programma
memorizzato” sono ormai scomparse (Mainframe, MiniComputer) o prevalentemente confluite
(Vector Supercomputer, Massively Parallel Processor) in altre tipologie.
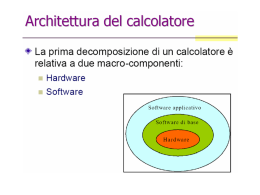
1.4 ARCHITETTURA DI UN CALCOLATORE DESKTOP
Un Calcolatore di tipo desktop può essere visto come un elettrodomestico componibile. Al suo
interno sono presenti infatti molti componenti che consentono di mettere in piedi l’intera
macchina in maniera abbastanza semplice e modulare. Una tipica organizzazione di un
Calcolatore Desktop e’ riportata in Figura 1.3. Tale organizzazione si discosta pochissimo
dall’originaria impostazione presentata da Von Neumann [10] nel 1946.
CPU
Cache
Bus
Memoria
Adattatore
(bridge)
Disco
Dispostivi di I/O: Display
Tastiera
Controller
Scheda di rete
INTERNET
Figura 1.3: Organizzazione a blocchi.
1.3
1.4.1 Limiti dovuti alla dimensione del chip
Sabbene sia teoricamente conveniente avere chip “grossi” per ottenere un numero elevato di
transistor (e quindi di funzionalita’) sullo stesso, cio’ non viene attuato nella realta’ perche’
“il costo di un chip è proporzionale a circa il cubo della sua area. “
E’ infatti possibile calcolare il costo del chip (o ‘die’) con la seguente formula:
C DIE =
CWAFER
N DIE ⋅ YWAFER
dove: CDIE = Costo del die
CWAFER = Costo del wafer
NDIE = Numero di die in un wafer
YWAFER = ‘Yield’ o Resa del wafer (numero ‘die’ per unita’ di sup.)
Il numero di die all’interno di un wafer e la resa del wafer stesso dipendono dall’area del die,
come si vede dalle seguenti formule:
2
N DIE
π ⋅ ⎛⎜ DWAFER 2 ⎞⎟
AWAFER
⎠ − π ⋅ DWAFER − N
= ⎝
TEST ≅
ADIE
ADIE
2 ⋅ ADIE
YWAFER =
1
2
1 + (F ⋅ ADIE 2)
dove: DWAFER = Diametro del wafer
ADIE = Area del ‘die’=⋅π(DWAFER/2)2
AWAFER = Area del wafer
NTEST = Numero di ‘die’ usati per test
F
= Difetti per unita’ di superfice
1.4.2 Limiti dovuti al consumo di potenza
Il consumo di potenza di un calcolatore elettronico è un altro degli aspetti fondamentali che
limita il numero di componenti che e’ possibile integrare sul chip. Inolre, questo problema
risulta essere maggiormente pressante con l’avvento di CPU sempre più complesse.
Il consumo di potenza è influenzato dalla densità con cui sono costruiti i chip; chip più densi,
che significano quindi sistemi più complessi, richiedono un maggiore consumo di potenza per
unità di superficie. Per un Calcolatore Desktop il limite “a braccio” che viene utilizzato per la
potenza totale dissipata (Total Dissipated Power o TDP) e’ intorno ai 100W.
1.5 DEFINIZIONE DI “ARCHITETTURA DI UN CALCOLATORE”
L’Architettura di un Calcolatore e’ “...l’insieme dell’insieme degli attributi visibili al
programmatore, ovvero la struttura concettuale e il comportamento funzionale, distinti
dall’organizzazione del flusso dei dati e del controllo, dagli elementi logici e
dall’implementazione fisica” (tradotto dalla definizione originale che compare in [12]).
Per definire un’architettura si dovrà specificare come organizzare i dispositivi di
memorizzazione, definire quali siano i tipi di dato e le strutture dati, stabilire l’insieme delle
istruzioni ed il loro formato, fissare un metodo di indirizzamento della memoria e di accesso
ai dati e alle istruzioni ed, infine, essere in grado di gestire le eccezioni.
In altri termini, l’Architettura del Calcolatore e’ l’interfaccia tra cio’ che viene fornito
dall’Hardware e cio’ che viene richiesto dal Software.
1.4
Un termine vicino ma distinto e’ Microarchitettura, che viene usato per definire le risorse ed i
metodi per implementare una data Architettura [13] di un Calcolatore ovvero la
Microarchitettrura e’ l’implementazione di una Architettura e fornisce a sua volta la specifica
da utilizzare per il progetto logico (e successivamente elettrico e fisico).
1.6 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] G. Bucci, "Architettura dei Calcolatori Elettronici", McGraw-Hill, 2001, ISBN 88-386-0889-X.
[3] P. Corsini, G. Frosini, "Architettura dei calcolatori", McGraw Hill, 1997, ISBN 88-386-0735-4.
[4] A. S. Tanenbaum, "Structured computer organization", 4th ed., Prentice-Hall International, 1999,
ISBN 0130959901.
[5] V.P. Heuring, "Computer Systems Design and Architecture" 2ed, Pearson/Prentice Hall, 2004,
ISBN 0-13-191156-2.
[6] S. Furber, "ARM System-on-chip architecture", 2ed, Pearson/Addison Wesley, 2000, ISBN 0-20167519-6.
[7] W. Stallings, "Architettura e organizzazione dei calcolatori", Jackson Libri, 2000, ISBN 88-2561836-0.
[8] Sito Web del Corso.
http://www.dii.unisi.it/~giorgi/didattica/calel
[9] G. E. Moore, “Cramming more components onto integrated circuits”, Electronics Magazine (1965)
(ftp://download.intel.com/museum/Moores_Law/Articles-Press_Releases/Gordon_Moore_1965_Article.pdf).
[10] J. von Neumann, “First Draft of a Report on the EDVAC” (anche disponibile al sito:
http://www.virtualtravelog.net/entries/2003-08-TheFirstDraft.pdf).
[11] Intel, Microprocessor Quick Reference Guide,
http://www.intel.com/pressroom/kits/quickrefyr.htm
[12] G. M. Amdahl, G.A. Blaauw, F.P. Brooks, (1964), “Architecture of the IBM System/360”, IBM J.
Research and Development 8. Reprinted (2000) loc.cit. 44 21-37.
(http://www.research.ibm.com/journal/rd/441/amdahl.pdf)
[13] B. Shriver and B. Smith. The Anatomy of a High-Performance Microprocessor, A Systems
Perspective. IEEE Computer Society Press, July 1998.
1.5
LEZIONE 2
Assembly MIPS (parte prima)
.
2.1 INTRODUZIONE
I calcolatori, per loro natura, comprendono segnali composti da due soli elementi, che
rappresentano lo stato di on e off, identificati nei numeri 0 e 1 e il linguaggio formato da
questo alfabeto è detto linguaggio macchina. I programmatori anziché il linguaggio macchina
utilizzano il linguaggio assembly che associa alle sequenze binarie del linguaggio macchina una
rappresentazione simbolica più comprensibile. Tutti i comandi che vengono impartiti ai
calcolatori sono detti “istruzioni”, ossia sequenze di 0 e 1 che il calcolatore è in grado di
comprendere. Un programma assemblatore traduce la notazione simbolica, quindi in linguaggio
assembly, di un’istruzione, nella corrispondente notazione binaria, ovvero in linguaggio
macchina.
Ad esempio:
add $so, $s1, $s2
000000 10010 10011 10001 00000 100000
(linguaggio assembly MIPS)
(linguaggio macchina MIPS)
L’ istruzione nell’esempio dice al calcolatore di sommare due numeri.
Il linguaggio macchina ha una diretta implementazione in termini circuitali. Sopra al linguaggio
assembly si costruiscono dei linguaggi ad alto livello che includono delle istruzioni più vicine al
linguaggio naturale in quanto permettono la programmatore di non specificare certi tipi di
dettagli implementativi della macchina ed inoltre sono più flessibili rispetto all’assembly.
Alcuni dei più famosi linguaggi ad alto livello sono il Java, il C++, il C e il Pascal. I programmi
che utilizzano tali linguaggi si chiamano compilatori e consentono al programmatore di scrivere
espressioni del tipo:
C = A + B;
che il compilatore tradurrà in istruzione assembly
(linguaggio ad alto livello C)
add $so, $s1, $s2.
Dove la variabile A è associata al contenuto del registro $s1, la variabile B a quello del
registro $s2 e la variabile C al registro $s0.
2.2 ISTRUZIONI ASSEMBLY
Per poter gestire l’hardware di un calcolatore bisogna saper parlare il suo linguaggio; le parole
del linguaggio del calcolatore si chiamano istruzioni e il vocabolario è il set di istruzioni. Il set
di istruzioni prescelto proviene dal processore MIPS, usato fra gli altri da NEC, Nintendo,
Sylicon Graphics e Sony. L’architettura dei processori MIPS appartiene alla famiglia delle
architetture RISC (Reduced Instruction Set Computer) sviluppate dal 1980 in poi. I
principali obiettivi delle architetture RISC sono la semplificazione della progettazione
dell'hardware e del compilatore, la massimizzazione delle prestazioni e la minimizzazione dei
costi. Gli operandi delle istruzioni non possono essere variabili in memoria ma devono essere
scelti fra i registri interni al microprocessore. Fanno eccezione solo le istruzioni load e store
che fanno riferimento a variabili in memoria. Un processore possiede un numero limitato di
registri ad esempio il processore MIPS possiede 32 registri composti da 32-bit (word). In
tutti i casi in cui è possibile i registri sono associati alle variabili di un programma dal
compilatore. Inoltre se i registri non fossero sufficienti per rappresentare le variabili che
vogliamo, possiamo ricorrere alla memoria, ma questo metodo non si usa sempre dato che
2.1
l’accesso alla memoria è più lento di quello ai registri, argomento che sarà affrontato in
dettaglio nella lezione 16. Per identificare i registri si usano nomi simbolici preceduti da $, ad
esempio: $s0, $s1 oppure possono essere anche indicati direttamente mediante il loro
numero (0, …, 31) preceduto sempre da $. I nomi simbolici e i numeri per i registri vengono
assegnati attraverso questa convenzione:
Tabella 2.1: Convenzione per i registri MIPS
Numero registro
0
2-3
4-7
8-15
16-23
24-25
26-27
28
29
30
31
Uso
Valore costante 0
Valore dei risultati e valutazione di espressione
Parametri
Variabili temporanee
Variabili salvate
Altre variabili temporanee
Riservato al kernel
Global pointer
Stack pointer
Frame pointer
Indirizzo di ritorno
Nome
$zero
$v0-$v1
$a0-$a3
$to-$t7
$s0-$s7
$t8-$t9
$k0-$k1
$gp
$sp
$fp
$ra
Le istruzioni del linguaggio assembly MIPS possono essere divise nelle seguenti categorie:
• Istruzioni ARITMETICO-LOGICHE
• Istruzioni LOAD and STORE (trasferimento da/verso memoria)
• Istruzioni di salto condizionato e non condizionato per il controllo del flusso di
programma
Il linguaggio assembly fornisce anche delle pseudoistruzioni che costituiscono un modo più
“comodo” per scrivere istruzioni assembly o brevi sequenze di istruzioni assembly. Queste
sono istruzioni fornite dall’assembler ma non implementate in hardware.
Ad esempio:
move $t0, $t1
esiste solo in assembly in quanto l’assemblatore traduce usando
add $t0, $t1, $zero
Nel registro t0 viene messo il risultato della somma del contenuto di t1 e di zero, ovvero
viene spostato il contenuto di t1 in t0.
2.2.1 Istruzioni aritmetiche
In MIPS, un’istruzione aritmetico-logica possiede tre operandi che sono sempre e solo
registri: i due registri contenenti i valori da elaborare (registri sorgente) e il registro
contenente il risultato (registro destinazione). L’ordine degli operandi è fisso: prima il
registro contenente il risultato dell’operazione e poi i due operandi.
Istruzione add
L’istruzione add serve per sommare il contenuto di due registri sorgente s1 e s2 e mettere il
risultato in s0.
2.2
Esempio:
Codice C: R = A + B
Codice MIPS: add $s0, $s1, $s2
Dove la variabile R è associata al registro $s0, la variabile A al registro $s1 e la variabile
B a $s2.
Nella traduzione da linguaggio ad alto livello a linguaggio assembly, le variabili sono associate
ai registri dal compilatore Quando dobbiamo svolgere operazioni con un numero di operandi
maggiore di tre queste possono essere effettuate scomponendole in operazioni più semplici, in
quanto ciascuna delle istruzioni MIPS può eseguire una sola operazione.
Ad esempio, per eseguire la somma delle variabili B, C , D ed E nella variabile A servono tre
istruzioni:
Codice C:
A=B+C+D+E
Codice MIPS: add $t0, $s1, $s2
add $t0, $t0, $s3
add $s0, $t0, $s4
# il registro $t0 contiene B+C
# il registro $t0 contiene B+C+D
# il registro $s0 contiene B+C+D+E
Dove la variabile A è associata al registro $s0, la variabile B al registro $s1, la
variabile C a $s2, la variabile D a $s3 e la variabile E a $s4. Il registro $t0 è utilizzato
per memorizzare temporaneamente il risultato.
Istruzione sub
L’istruzione sub serve per sottrarre il contenuto di due registri sorgente s1 e s2 e mette il
risultato in s0.
Esempio:
Codice C:
R=A-B
Codice MIPS: sub $s0 ,$s1, $s2
Dove la variabile R è associata al registro $s0, la variabile A al registro $s1 e la variabile
B a $s2.
2.2.2 Istruzioni di trasferimento
Gli operandi delle istruzioni aritmetiche devono risiedere nei registri che, come abbiamo già
detto, nel nostro processore MIPS sono 32. Se abbiamo programmi i cui dati richiedono più di
32 registri, ovvero hanno moltissime variabili, alcuni di questi risiedono nella memoria.
L’allocazione in memoria di alcune variabili è detto spilling (riversamento). A questo proposito
servono specifiche istruzioni atte a trasferire i dati dalla memoria ai registri e viceversa;
queste possono solo leggere o scrivere un operando ma non possono eseguire nessuna
operazione su di esso. Le operazioni base di questo tipo sono due la load e la store
rispettivamente.
Breve richiamo sulla struttura della memoria
La memoria può essere vista come un unico grande array uni-dimensionale con gli indirizzi che
rappresentano l’indice del vettore a partire da 0. Dato che i byte, composti da 8 bit, sono
utilizzati da molti programmi, la maggior parte delle architetture indirizza il singolo byte ma
per ragioni di efficienza i microprocessori trasferiscono più byte in un colpo solo (come ad
2.3
esempio un microprocessore a 32 bit). Quindi dato che i programmi utilizzano l’indirizzamento
al byte e le istruzioni sono a 32 bit (quindi comprendono 4 byte) il loro indirizzo è sempre a
multipli di quattro, così parole adiacenti hanno indirizzi che differiscono di un fattore di
quattro. All’interno di una parola i byte possono essere ordinati facendo corrispondere
all’indirizzo al byte (es. 0x00000000) il byte più significativo di una parola a 4 byte; si parla in
questo caso di disposizione big-endian (v. figura 2.1). Se invece si fa corrispondere
all’indirizzo al byte (es. 0x00000000) il byte meno significativo si parla di disposizione littleendian (v. figura 2.1).
Vogliamo andare alla parola 0 con questa sequenza di byte numerati da 0 a 3 le due
disposizioni sono:
Disposizione big-endian
0
1
2
3
Disposizione little-endian
3
2
1
0
Fgura 2.1: Disposizione dei bit per big-endian e little-endian. Nel caso big-endian la memorizzazione inizia
dal byte più significativo per finire col meno significativo; nel caso little-endian la memorizzazione inizia dal
byte meno significativo per finire col più significativo.
Istruzione load
L’istruzione LOAD serve per trasferire un dato dalla memoria in un registro. Il nome
convenzionale di questa istruzione nel linguaggio MIPS è lw, che significa load word (carica
una parola). L’istruzione lw ha tre argomenti: il registro di destinazione in cui caricare la
parola letta dalla memoria, una costante che rappresenta l’offset (o spiazzamento) e un
registro sorgente che contiene il valore dell’indirizzo base da sommare alla costante. Quindi
l’indirizzo effettivo della parola di memoria da caricare nel registro di destinazione viene
calcolato sommando un valore base, contenuto nel registro sorgente e un offset direttamente
specificato all’interno dell’istruzione.
$s 3
(BASE)
4*k
(OFFSET)
Figura 2.2: Schema di funzionamento dell’istruzione di LOAD.
Esempio:
Codice C: g = h + A[8]
Codice MIPS: lw $t0, 32($s3)
add $s1, $s2, $t0
# il registro $t0 assume il valore A[8]
# g = h + A[8]
2.4
In cui la variabile g è associata al registro $s1, la variabile h al registro $s2, A a $s3
(registro base), 8 rappresenta il nono elemento del vettore di indirizzamento a 32 bit,
ossia l’offset 8 × 4=32.
Istruzione store
L’istruzione STORE è la complementare della load, infatti serve per trasferire il contenuto di
un registro verso la memoria. Il nome convenzionale in linguaggio MIPS è sw, che significa
store word (memorizza una parola). Il suo formato è analogo a quello della load: per primo
viene messo il nome del registro che contiene il dato da trasferire in memoria, poi l’offset e in
fine il registro base. Nell’istruzione store il registro destinazione è l’ultimo operando.
Esempio:
Codice C:
A[12] = h + A[8]
Codice MIPS: lw $t0, 32($s3)
add $t0, $s2, $t0
sw $t0, 48($s3)
# il registro t0 assume il valore A[8]
# il registro $t0 assume il valore h + A[8]
# memorizza h + A[8] in A[12]
In cui la variabile h è associata al registro $s2, A a $s3 (registro base), 8 rappresenta il
nono elemento del vettore di indirizzamento a 32 bit, ossia l’offset 8 × 4=32, ugualmente
12 che ha un offset di 12 × 4=48.
2.2.3 Istruzioni di salto condizionato e non condizionato
Le istruzioni di salto condizionato e non condizionato sono rese necessarie dalla struttura del
calcolatore. L'unità di controllo fa funzionare l’elaboratore che da quando viene acceso a
quando viene spento esegue di continuo il ciclo di prelievo / decodifica / esecuzione (fetch /
decode / execute ), la cui struttura è schematizzata nella seguente tabella.
Tabella 2.2: Il ciclo Fecth-Decode-Execute.
Passo 1.
Carica un'istruzione dalla memoria puntata da un registro speciale chiamato “program counter” (PC), e la
assegna a un registro interno chiamato IR.
Passo 2.
Cambia PC con l'indirizzo successivo in memoria (PC=PC+4).
Passo 3.
Determina il tipo di istruzione appena caricata nel registro delle istruzioni in base al suo opcode (Codice
Operativo).
Passo 4.
Si chiede se l'istruzione utilizza una parola in memoria. In tal caso determina l’effettivo indirizzo
dell’operando in memoria (base + offset).
Passo 5.
Se necessario, carica la parola residente in memoria in un registro della cpu.
Passo 6.
Esegue l'istruzione.
Passo 7.
Torna all'inizio, al 1 passo, ed esegue la prossima istruzione.
Il ciclo descritto in tabella può essere così sintetizzato:
• Operazione di FETCH
2.5
Passi 1 2
• Operazione di DECODE
Passo 3
• Operazione di EXECUTE
Passo 4, 5, 6.
Istruzioni particolari possono alterare il prelievo delle istruzioni da celle consecutive come ad
esempio le istruzioni di salto.
Le istruzioni di salto condizionato e non condizionato prendono il nome anche di istruzioni di
decisione in quanto alterano il flusso principale del programma, ovvero cambiano la “prossima”
istruzione da eseguire. Le istruzioni di salto condizionato utilizzano un campo offset di 16 bit
(con segno); possono quindi saltare a una locazione posta nell’intervallo [-215-1; 215].
Le istruzioni di salto incondizionato contengono invece un campo di 26 bit per specificare
l’indirizzo, anche se il calcolo dell’indirizzo effettivo è diverso a seconda del tipo di istruzione,
come vedremo nel capitolo 2. I salti condizionati si dividono in beq (branch if equal), bne
(branch if not equal) e slt (set on less than) mentre quelli incondizionati vengono effettuati
con l’istruzione j (jump) e jal (jump and link).
Istruzioni di salto condizionato
Le istruzioni di salto sono effettuate attraverso le operazioni di branch che cambiano il
flusso del programma creando diramazioni. L’istruzione beq trasferisce il flusso di controllo
(PC) all’istruzione etichettata con Label se e, solo se, il valore contenuto nel registro t0 è
uguale al valore del registro t1:
beq $t0, $t1, Label
Esempio:
Codice C:
if (i= =j)
f = g + h;
f =f –i;
Codice MIPS:
beq $s3, $s4, L1
add $s0, $s1, $s2
L1: sub $s0, $s0, $s3
# va a L1 se i = j
# f = g + h ( si salta se i = j )
# f = f – i ( eseguita sempre)
Dove la variabile i è associata al registro $s3, la variabile j al registro $s4, la variabile f
a $s0, la variabile g a $s1 e la variabile h a $s2.
L’istruzione bne indirizza all’istruzione etichettata con Label se e, solo se, il valore contenuto
nel registro t0 non è uguale al valore del registro t1.
bne $t0, $t1, Label
E’ opportuno chiedersi a questo punto quale istruzione utilizzare nel caso vogliamo fare
confronti di disuguaglianza ( <, ≤ , >, ≥ ) fra due variabili. A questo proposito viene utilizzata
l’istruzione slt che serve per verificare se la variabile corrispondente al registro s0 è minore
della variabile corrispondente al registro s1. Il registro t0 diventa uguale a 1 se s0 < s1 0
altrimenti.
Quindi il test finale è realizzato da un’istruzione bne che confronta i registri t0 e zero,
oppure da un’istruzione beq che confronta i registri t0 e la costante 1.
2.6
slt $t0, $s0, $s1
Esempio:
Codice C:
if A<B;
then C=1;
else C=0;
Codice MIPS: slt $t0, $s1, $s2
La variabile A è associata al registro $s1, la variabile B a $s2, e la variabile C a $t0.
Istruzioni di salto non condizionato
L’istruzione di salto non condizionato è j ed indica all’elaboratore di eseguire sempre il salto;
l’indirizzo di destinazione del salto è un indirizzo assoluto di memoria.
Esempio:
Codice C:
if (i = = j) f = g + h;
else f = g – h;
Codice MIPS: beq $s3, $s4, L1
L1:add $s0, $s1, $s2
bne $s3, $s4, L2
L2: sub $s0, $s1, $s2
j esci
# va a L1 se i = j
# f = g + h ( si salta se i = j )
# va a L2 se i ≠ j
# f = g -h
# vai a esci
La variabile i è associata al registro $s3, la variabile j al registro $s4, la variabile f al
registro $s0, e le variabili g e h rispettivamente a $s1 e $s2.
L’istruzione di salto non condizionato jal richiede un’analisi più approfondita che sarà
affrontata nella lezione 3.
2.2.4 Esempi di programmi assembly
Implementazione ciclo “while”
Codice C: while (A[i]==k)
i=i+j;
Codice MIPS:
Ciclo: add $t1, $s3, $s3
add $t1, $t1, $t1
add $t1, St1, $s6
lw $t0, 0($t1)
bne $t0, $s5, esci
add $s3, $s3, $s4
j ciclo
Esci:
# il registro temporaneo $t1 è uguale a 2 × i
# il registro temporaneo $t1 è uguale a 4 × i
# $t1 è uguale all’indirizzo di A[i]
#il registro temporaneo $t0 è uguale a A[i]
# vai ad esci se A[i]=k
# i=i+j
# vai a ciclo
Si assuma che le variabili i, j e k corrispondano ai registri $s3, $s4 e $s5 rispettivamente e
che $s6 contenga l’indirizzo di base del vettore A.
Implementazione ciclo “do while”
Codice C: do
2.7
g = g+A[i];
i=i+j;
while (i!=h)
Codice MIPS:
Ciclo: add $t1, $s3, $s3
add $t1, $t1, $t1
add $t1, St1, $s5
lw $t0, 0($t1)
add $s1, $s1, $t0
add $s3, $s3, $s4
bne $s3, $s2, ciclo
# il registro temporaneo $t1 è uguale a 2 × i
# il registro temporaneo $t1 è uguale a 4 × i
# $t1 è uguale all’indirizzo di A[i]
# il registro temporaneo $t0 è uguale a A[i]
# g=g+A[i]
# i=i+j
# se i ≠ h vai a ciclo
Si suppone che le variabili g e h siano associate a $s1 e $s2, i e j associate a $s3, $s4 e che
$s5 contenga l’indirizzo di base di A.
2.3 LINGUAGGIO MACCHINA
Tutte le istruzioni MIPS hanno la stessa dimensione (32 bit). I 32 bit hanno un significato
diverso a seconda del formato (o tipo) di istruzione. Tutte le istruzioni scritte dal
programmatore in linguaggio assembly vengono passate al calcolatore come una sequenza finita
di bit scritta in base 2. Il tipo di istruzione è riconosciuto in base al valore dei 6 bit più
significativi che compongono il codice operativo (OPCODE, OP) mentre i rimanenti 26 bit sono
suddivisi diversamente in base al formato in cui l’istruzione è scritta. Esistono tre tipi di
formati:
• Tipo R (register)
• Tipo I (immediate)
• Tipo J (jump)
2.3.1 Formato di tipo R
Con il formato di tipo R vengono descritte le funzioni aritmetico-logiche. A ciascuno dei campi
delle istruzioni MIPS viene associato un nome, per poter fare più agevolmente gli opportuni
riferimenti.
opcode
6 bit
rs
5 bit
rt
5 bit
rd
5 bit
shamt
5 bit
funct
6 bit
Ogni campo in cui è suddivisa l’istruzione ha un preciso significato:
• Op (opcode) identifica il tipo di operazione è chiamato anche codice operativo
• Rs primo operando sorgente
• Rt secondo operando sorgente
• Rd registro di destinazione che contiene il risultato dell’operazione
• Shamt questo termine contiene il valore dello scorrimento (shift amount che verrà
discussa successivamente)
• Funct funzione. Seleziona una variante specifica dell’operazione base descritta nel
campo op, è chiamato “codice funzione”.
Esempio:
2.8
Add $t0, $s1, $s2
0
17
18
8
0
32
000000
10001
10010
01000
00000
100000
Esempio istruzione formato R:
Nome campo
Dimensione
Add $s1,$s2,$s3
Op
6 bit
000000
Rs
5 bit
10010
Rt
5 bit
10011
Rd
5 bit
10001
Shamt
5 bit
00000
Funct
6 bit
100000
2.3.2 Formato di tipo I
Il formato di tipo I nasce dall’esigenza di specificare operandi immediati (costanti)
direttamente nelle istruzioni. In generale servirebbero 32 bit ma fortunatamente nella
maggioranza dei software le costanti utilizzate sono piccole, quindi con 16 bit si risolve già la
stragrande maggioranza dei casi. Infatti quando si vuole rappresentare un’istruzione di
trasferimento con il formato R possono nascere dei problemi in quanto questa necessita di
campi di dimensioni maggiori rispetto a quelli sopra specificati. Ad esempio l’istruzione load
deve specificare due registri e una costante; se la costante dovesse essere specificata in uno
dei campi da cinque bit, sarebbe limitata al valore di 25, cioè 32, ma poiché questa serve per
indirizzare all’interno di vettori di grandi dimensioni spesso assume valori maggiori. Per far
rimanere la lunghezza delle istruzioni sempre di 32 bit il compromesso è quello di creare
formati diversi per le diverse istruzioni.
Per le istruzioni di trasferimento utilizziamo il tipo I che ha la seguente struttura:
opcode
6 bits
rs
5 bits
rt
5bits
In questo caso i campi hanno il seguente significato:
• opcode identifica il tipo di istruzione
• rs indica il registro base
• rt indica il registro destinazione dell’istruzione di caricamento
• address riporta lo costante (in alcuni casi offset)
2.9
address
16 bits
Esempio:
lw $t0, 32($s3)
35
19
8
32
100011
10011
01000
0000000000100000
Esempio istruzione formato I:
Nome campo
Dimensione
Lw $t0, 32($s3)
Op
6 bit
100011
Rs
5 bit
10011
Rt
5 bit
01000
Address
16 bit
0000 0000 0010 0000
Con il formato I oltre che alle istruzioni di trasferimento vengono descritte anche tutte le
istruzioni con operandi immediati e operazioni di salto condizionato. Quest’ultime possono
avere un offset maggiore dei 16 bit, che consente il formato I, quindi una valida alternativa
consiste nello specificare un registro il cui valore deve essere sommato all’indirizzo di salto
permettendo così di raggiungere 32 bit. Il registro da usare è il program counter che
contiene l’indirizzo dell’istruzione corrente e quindi può saltare fino a una distanza di ± 215
istruzioni rispetto alle istruzioni in esecuzione. Siccome in quasi tutti i cicli e i costrutti di if,
in cui i salti condizionati vengono usati, l’etichetta a cui salto è tipicamente un numero di
istruzioni minore di 216 parole, il program counter è la scelta ideale.
2.2 3 Formato di tipo J
Il terzo tipo di formato di istruzioni (formato J) è il formato usato per le istruzioni di salto
incondizionato.
Op
6 bit
Address
26 bit
In questo caso i campi hanno il seguente significato:
• Op indica il tipo di operazione
• Address riporta una parte (26 bit su 32) dell’indirizzo assoluto di destinazione del
salto
L’assemblatore sostituisce l’etichetta con i 28 bit meno significativi traslati a destra di 2
(divisione per 4 per calcolare l’indirizzo di parola) per ottenere 26 bit; in pratica elimina i due
zero finali e si amplia lo spazio di salto tra zero e 228 byte (ossia 226 word). I 26 bit del campo
indirizzo rappresentano un indirizzo di parola. Quindi corrispondono a un indirizzo di byte
composto da 28 bit; poiché il registro PC è composto da 32 bit si verifica che l’istruzione jump
rimpiazza solo i 28 bit meno significati del PC lasciando inalterati i rimanenti quattro bit più
significativi.
2.10
Nome campo
Dimensione
j 32
Op
6 bit
000010
Address
26 bit
00 0000 0000 0000 0000 0000 1000
2.11
LEZIONE 3
Assembly MIPS (parte seconda)
3.1 LA MOLTIPLICAZIONE
Come è noto effettuando l’operazione di moltiplicazione tra due numeri binari rappresentati
su n bit, in generale sono necessari 2n bit per rappresentare il risultato [1].
Nel MIPS tutti i registri utilizzati hanno una dimensione di 32 bit; moltiplicando il contenuto
di due registri da 32 bit per rappresentare correttamente il risultato sono quindi necessari
64 bit.
Il risultato della moltiplicazione viene posto sempre in due registri dedicati (special porpouse)
da 32 bit ciascuno, denominati Hi e Lo in grado di contenere il prodotto su 64 bit.
L’istruzione MIPS per effettuare la moltiplicazione è mult (multiply).
Esempio:
mult $2, $3
#calcola il prodotto tra il contenuto dei registri $2 e $3 e il risultato si
trova nei registri Hi e Lo.
In particolare il registro Hi contiene i 32 bit più significativi del prodotto, Lo i 32 bit
meno significativi (Figura 3.1).
$2
HI
LO
mult
$3
64 bit
32 bit
Figura 3.1. L’istruzione mult.
Per eseguire la moltiplicazione tra numeri senza segno possiamo utilizzare multu (multiply
unsigned).
Il prodotto inserito nei registri Hi e Lo può essere recuperato con le istruzioni mfhi (move
from hi) e mflo (move from lo).
Esempio:
mfhi $4
mfhi $5
#trasferisce nel registro $4 il contenuto di Hi.
#trasferisce nel registro $5 il contenuto di Lo (Figura 3.2).
HI
LO
$4
$5
Figura 3.2. Le istruzioni mfhi e mflo.
3.1
3.2 LA DIVISIONE
LA DIVISIONE TRA DUE NUMERI PUÒ ESSERE EFFETTUATA IN MIPS UTILIZZANDO
L’ISTRUZIONE DIV (DIVIDE) .
Dividendo e divisore sono contenuti in registri da 32 bit e, analogamente a quanto accade per
la moltiplicazione, dopo l’esecuzione dell’istruzione div il risultato della divisione si trova in due
registri Hi e Lo che contengono rispettivamente il resto e il quoziente.
Esempio:
div $2,$3
#effettua la divisione tra il contenuto del registro $2 e il contenuto del
registro $3; il quoziente si trova nel registro Lo, il resto nel registro Hi
(Figura 3.3).
$2
%
$4
/
32 bit
HI
LO
32 bit
Figura 3.3. L’istruzione div.
Il contenuto dei registri Hi e Lo può essere recuperato in modo analogo a quanto abbiamo
visto per la moltiplicazione.
3.3 LE COSTANTI
L’utilizzo delle costanti ricorre spesso nelle operazioni usate comunemente in MIPS [1].
Utilizzando le sole istruzioni che abbiamo incontrato fino ad adesso tutte le volte che
abbiamo bisogno di una piccola costante dovremmo fare un ulteriore accesso alla memoria.
La costante zero viene utilizzata molto frequentemente, quindi ad essa è addirittura riservato
un registro indicato con $zero.
Per evitare ulteriori accessi alla memoria possiamo inserire le costanti direttamente nelle
istruzioni e velocizzare così la loro esecuzione.
Per inserire le costanti all’interno dell’istruzione è necessario utilizzare il formato-I (vedi
capitolo 2); come abbiamo già visto in questo tipo di formato sono disponibili 16 bit per
memorizzare la costante.
Istruzioni che contengono costanti al loro interno vengono dette immediate.
Esempio:
addi $t1, $t1, 5
#addizione immediata tra in contenuto di $t1 e la costante 5.
3.2
A questa istruzione corrisponde il seguente codice macchina:
op
rs
rt
immediate
8
9
9
5
6 bit
5 bit
5 bit
16 bit
001000
01001
01001 0000 0000 0000 0101
Figura 3.4. Esempio di istruzione addi.
Altri esempi di istruzioni immediate sono:
slti $t0, $s0, 3
andi $s0, $s1, 10
ori $s0, $s1, 4
#confronto tra il contenuto di $s0 e la costante 3;
#and logico tra $s1 e 10;
#or logico tra $s1 e 4.
Se le costanti assumono valori elevati e non possono essere rappresentate su 16 bit possiamo
caricare costanti di 32 bit nei registri utilizzando la combinazione di due diverse istruzioni.
Esempio:
Vogliamo caricare la costante 521.499 corrispondente al
00000000000001111111010100011011. Usiamo le istruzioni lui e ori:
codice
lui $t0, 0000 0000 0000 0111
binario
#load upper immediate carica i 16 bit più significativi
della costante nel registro $t0 e mette a zero i 16
bit meno significativi;
ori $t0, 1111 0101 0001 1011 #or immediate permette di caricare i 16 bit meno
significativi della costante nel registro lasciando
inalterati i 16 bit più significativi.
$t0 0000 0000 0000 0111 0000 0000 0000 0000 lui
0000 0000 0000 0111 1111 0101 0001 1011
$t0 0000 0000 0000 0111 1111 0101 0001 1011 ori
Figura 3.5. Le istruzioni lui e ori.
3.3
3.4 ISTRUZIONI PER LA MANIPOLAZIONE DI STRINGHE
Nella maggior parte dei calcolatori i caratteri vengono rappresentati su 8 bit (1 byte)
attraverso la codifica ASCII [1]. Poiché l’elaborazione dei caratteri è un’operazione
ricorrente, il MIPS prevede due istruzioni per trattare i byte: lb (load byte) che preleva dalla
memoria un byte e lo salva negli 8 bit meno significativi di un registro, e sb (store byte) che
prende gli 8 bit meno significativi di un registro e li mette in memoria.
Esempio:
Supponiamo di avere in memoria una word di 32 bit memorizzata a partire dall’indirizzo
che si trova in $4; ricordando che una variabile di tipo char occupa 1byte, utilizzando lb
e sb otteniamo:
0
$
1
an
a n-1
a n-2
a n-3
………
…
a1
a0
Figura 3.6. Le istruzioni lb e sb.
Solitamente i caratteri sono raggruppati in stringhe. Una stringa può essere rappresentata in
vari modi:
1) la lunghezza della stringa può essere indicata dal primo elemento;
N
Stringa
2) alla stringa possono essere associate due variabili: una che contiene la stringa stessa, e
una variabile di appoggio che ne contiene la lunghezza;
Stringa
N
3) l’ultimo elemento della stringa può essere un carattere particolare che ne indica la
fine.
Stringa
0
Il linguaggio C utilizza quest’ultimo metodo utilizzando come carattere di fine stringa un byte
di valore 0.
3.4
3.5 ISTRUZIONI LOGICHE
Tabella 3.1. Le istruzioni logiche.
Istruzione
Esempio
Significato
Commento
Formato
and
and $1, $2, $3
$1 = $2 & $3
AND logico
R
or
or $1, $2, $3
$1 = $2 | $3
OR logico
R
xor
xor $1, $2, $3
$1 = $2 ⊕ $3
XOR logico
R
nor
nor $1, $2, $3
$1 = ~($2 | $3) NOR logico
R
and immediate
andi $1, $2, 10
$1 = $2 & 10
AND logico con costante
I
or immediate
ori $1, $2, 10
$1 = $2 | 10
Or logico con constante
I
xor immediate
xori $1, $2, 10
$1 = ~$2 & ~10
XOR logico con costante
I
$1 = $2 << 10
Shift logico sx di una quantità costante
I
$1 = $2 >> 10
Shift logico dx di una quantità costante
Shift aritmetico dx di una quantità
costante
I
Shift logico sx di una quantità variabile
R
Shift logico dx di una quantità variabile
Shiftr aritmetico dx di una quantità
variabile
R
shift left logical sll $1, $2, 10
shift
right
logical
srl $1, $2, 10
shift
right
arithm.
sra $1, $2, 10
$1 = $2 >> 10
shift left logical sllv $1, $2, $3 $1 = $2 << $3
shift
right
logical
srlv $1, $2, $3 $1 = $2 >> $3
shift
right
arithm.
srav $1, $2, $3 $1 = $2 >> $3
I
R
Lo shift logico (destro/sinistro) coinvolge tutti i bit, mentre lo shift aritmetico lascia
inalterato il bit più significativo.
Esempio:
srl $1, $1, 1
0
$
1
an
#effettua lo shift logico a destra (1 posizione) del contenuto del
registro $1; il bit meno significativo si perde.
a n-1
a n-2
a n-3
………
…
a1
a0
Figura 3.7. Funzionamento dello shift logico a destra.
In generale shiftando verso destra di n posizioni, vengono persi gli n bit meno significativi.
Esempio:
sll $1,$1,1
#effettua lo shift logico a sinistra (1posizione) del contenuto del
registro $1; il bit più significativo viene perso.
3.5
$
1
an
a n-1
a n-2
a n-3
………
…
a1
0
a0
Figura 3.8. Funzionamento dello shift logico a sinistra.
Effettuando lo shift logico a sinistra di n posizioni, gli n meno significativi vengono posti a
zero, mentre gli n bit più significativi si perdono.
Esempio:
sra $1,$1,1
$
1
an
#effettua lo shift aritmetico a destra (1 posizione) del contenuto del
registro $1, lasciando inalterato il bit più significativo; anche in questo
caso il bit meno significativo si perde.
a n-1
a n-2
a n-3
………
…
a1
a0
Figura 3.9. Funzionamento dello shift aritmetico a destra.
Lo shift aritmetico a sinistra non viene utilizzato, perchè coincide con lo shift logico (sll).
3.6 ISTRUZIONI CHE TRADUCONO I PUNTATORI DEL C
Analizziamo un semplice programma C che fa uso di puntatori e il codice MIPS corrispondente.
Supponiamo che alle variabili siano associati i seguenti registri: zÆ$7, pÆ$8, cÆ$9.
typedef struct tabletag {
int i;
char *cp, c;
}table;
table z[20] ;
table *p ;
char c ;
p= &z[4]
..............
..............
c= p->c ;
..............
Il programma C definisce la struttura " table" i cui
campi
sono: un intero (32 bit), un puntatore a char (32 bit) e
un char (8 bit).
Un elemento di tipo table occupa quindi in totale 9
byte.
addi $1, $7, 36 #calcola l’indirizzo di z[4] (base + offset)
sw $1, 0($8) #salva l’indirizzo calcolato
lb $2, 8($8) #preleva il campo c (1 byte) dalla struttura puntata da p
sb $2, 0($9) #salva il campo prelevato nel registro corrispondente a c
3.6
3.7 MODI DI INDIRIZZAMENTO MIPS
I diversi modi con cui si può esprimere un indirizzo di memoria vengono chiamati modi di
indirizzamento [1][7]. Elenchiamo di seguito i modi di indirizzamento utilizzati in MIPS.
Nel seguito indicheremo con A l’indirizzo effettivo di memoria a cui ci riferiamo poiché, come
vedremo, questo può essere diverso dall’indirizzo che troviamo nell’istruzione.
Il modo in cui A viene calcolato differenzia un modo di indirizzamento dall’altro.
3.7.1 Register Addressing
Nel Register Addressing (indirizzamento tramite registro) gli operandi si trovano nei
registri; questo modo di indirizzamento è usato dalle istruzioni in formato-R.
L’indirizzo effettivo è dato da:
A = $(rs)
dove rs indica il numero del registro all’interno del set di registri.
op
rs
rt
rd
shamt
funct
Registro
Figura 3.10. Register addressing.
Istruzioni:
add, addu, sub, subu, mult, multu, div, divu, and, or, sll, slt, sltu, mfhi, mflo, jr.
3.7.2 Immediate Addressing
Nel modo di indirizzamento immediato l’operando è una costante specificata nell’istruzione,
come abbiamo già visto nel paragrafo dedicato alle costanti.
Il modo di indirizzamento immediato è utilizzato nelle istruzioni in formato-I.
In questo caso l’indirizzo effettivo sarà quindi uguale a quello scritto nel campo address
dell’istruzione in formato-I:
A = I (dove I è il contenuto del campo address)
op
rs
rt
immediate
Figura 3.11. Immediate addressing.
Istruzioni:
addi, addiu, andi, ori, slti, sltiu, lui.
3.7.3 Base Addressing
Nell’indirizzamento tramite base, l’operando si trova in una locazione di memoria individuata
dalla somma del contenuto di un registro e di una costante specificata nell’istruzione.
L’indirizzo effettivo è:
3.7
A = I + <contenuto del registro indicato in rs>
Il registro da utilizzare viene indicato nell’istruzione stessa.
Questo modo di indirizzamento è usato per esempio nelle istruzioni lw e sw, in cui l’indirizzo
degli operandi è dato dalla somma tra l’indirizzo di base e l’offset; per esempio lw $t0
32($s2) indica che l’indirizzo di base è contenuto nel registro $s2 e l’offset da sommare è 32
(contenuto nel campo address). L’offset è rappresentato in complemento a due (e varia tra –
32.768 e 32767).
op
rs
rt
Memoria
address
+
Registro
byte
halfword
word
Figura 3.12. Base addressing.
Istruzioni:
lw, lh, lb, lbu, sw, sh, sb.
3.7.4 PC-relative Addressing (base + index)
Il modo di indirizzamento relativo al program counter è stato introdotto per ovviare ad un
problema relativo all’ istruzione di salto condizionato (Branch).
L’istruzione Branch fa uso del formato-I, riservando quindi 16 bit al campo indirizzo.
In base a questa considerazione nessun programma potrebbe avere una lunghezza superiore a
216 poiché in caso contrario l’indirizzo a cui si deve “saltare” nella Branch non potrebbe essere
contenuto nel campo di 16 bit.
Poiché questa condizione è molto restrittiva possiamo usare un’alternativa che consiste
nell’utilizzo di un registro il cui valore deve essere sommato all’indirizzo specificato
nell’istruzione di salto.
A questo scopo viene utilizzato il registro PC (program counter) che contiene l’indirizzo
dell’istruzione corrente. Solitamente nei salti condizionati ci si sposta ad istruzioni vicine;
utilizzando il PC siamo in grado di spostarci fino ad una distanza di ±215 istruzioni rispetto
all’istruzione corrente.
Solitamente si fa in modo che il PC punti all’istruzione successiva a quella in esecuzione;
ricordando che le istruzioni sono tutte a 32 bit e quindi si trovano in memoria ad indirizzi
sempre multipli di 4, l’istruzione successiva a quella in esecuzione si trova all’indirizzo PC+4.
Quindi l’indirizzo effettivo di salto sarà dato da:
A = PC + 4 + I’ = PC + 4 + 4*I
dove I è il contenuto del campo address dell’istruzione (che può essere positivo o negativo) e
rappresenta la distanza dell’indirizzo a cui si deve saltare in termini di word. L’indirizzo PCrelative indica cioè il numero di parole che separano l’istruzione successiva a quella corrente
3.8
dall’istruzione a cui si salta. Nell’espressione I’ rappresenta questa stessa distanza in termini
di byte.
Poiché I è rappresentato su 16 bit, I’ sarà rappresentato su 18 bit, quindi il campo effettivo in
cui possiamo spostarci sarà 218.
op
rs
rt
Memoria
address
x4
+
PC + 4
Word
Figura 3.13. PC-relative addressing.
Istruzioni:
beq, bne.
3.7.5 Pseudodirect Addressing
Se dobbiamo effettuare salti su un campo più ampio di 218 possiamo utilizzare l’istruzione
Jump.
Consideriamo quindi l’istruzione di salto non condizionato Jump: essa utilizza il formato-J in
cui 6 bit vengono impiegati per il codice operativo e i restanti 26 per il campo indirizzo.
Il modo di indirizzamento pseudo-diretto viene utilizzato per impiegare al meglio i 26 bit
riservati all’indirizzo.
In questo caso l’indirizzo effettivo di salto è dato da:
A = (PC<31…28> , 0<27...0>) + I’ = (PC<31…28> , 0<27...0>) + 4*I
Anche in questo caso il campo address viene in pratica esteso di 2 bit, poiché I’ è
rappresentato su 28 bit. L’ampiezza massima del salto sarà quindi 228.
L’indirizzo effettivo viene ottenuto concatenando I’ con i 4 bit più significativi del program
counter.
op
00
address
Memoria
28 bit
31…2
8
32 bit
Memoria
Word
PC
4 bit
Figura 3.14. Pseudodirect addressing.
Istruzioni:
j,jal.
3.9
3.8 LINGUAGGIO ASSEMBLY E LINGUAGGIO MACCHINA
Il linguaggio Assembly fornisce una rappresentazione simbolica della codifica binaria usata dal
calcolatore, detta linguaggio macchina; l’Assembly è più semplice da leggere e da scrivere
rispetto al linguaggio macchina poiché utilizza simboli invece di bit [reference 1].
Inoltre l’Assembly permette di utilizzare pseudoistruzioni, ovvero istruzioni che non fanno
propriamente parte del linguaggio simbolico, ma che facilitano la scrittura dei programmi.
Come abbiamo visto nel corso della trattazione, vi sono differenze tra le istruzioni scritte in
Assembly e le corrispondenti stringhe di bit in linguaggio macchina.
Esempio:
Analizziamo l’istruzione add e il relativo codice macchina.
add $t2, $t0, $t1
op
rs
rt
rd
shamt
funct
000000
01000
01001
01010
00000
100000
0
8
9
10
0
32
Figura 3.15. Codice macchina relativo all’istruzione add.
In Assembly la destinazione è il primo operando, mentre in linguaggio macchina si trova
nel quarto campo; a livello di linguaggio macchina l’istruzione add viene rappresentata con
il codice operativo 0 e il codice funzione 32.
Un vantaggio che l’Assembly offre rispetto ai linguaggi di alto livello è la possibilità di
velocizzare l’esecuzione e minimizzare l’occupazione di memoria dei programmi. In quest’ottica
di ottimizzazione delle prestazioni è quindi importante sapere quali sono le istruzioni “reali”
che si nascondono dietro al linguaggio simbolico Assembly.
3.9 CONVENZIONI PER I REGISTRI MIPS
Tabella 3.2. I registri MIPS.
0
1
zero
at
costante 0
riservata all'assemblatore
2
3
v0
v1
valori dei risultati e
valutazione di espressioni
4
5
a0
a1
parametri utilizzati nella
chiamata delle procedure
6
7
a2
a3
8
t0
variabili temporanee
…
15
t7
3.10
16
s0
variabili salvate quando
…
23
s7
24
25
t8
t9
altre variabili temporanee
26
27
k0
k1
riservati al sistema operativo
28
29
30
gp
sp
global pointer
stack pointer
fp
frame pointer
31
ra
indirizzo di ritorno
si richiamano procedure
3.10 INTRODUZIONE ALLA CHIAMATA A FUNZIONE
Una procedura è una parte del programma dedicata alla risoluzione di un problema specifico,
uno strumento utilizzato per strutturare i programmi e renderli più facili da comprendere.
Nei successivi paragrafi verrà indicato il protocollo da seguire per implementare la chiamata
ed esecuzione di una funzione.
3.11 STRUTTURA DELLA CHIAMATA E DELL’ESUCUZIONE DI
UNA FUNZIONE
In questo paragrafo sono enunciate le varie fasi di una chiamata a funzione con le
convenzioni e le regole che le contraddistinguono; per ogni fase è riportato a fianco al nome
se questa avviene dal lato chiamante (programma che chiama la procedura) o dal lato chiamato
(procedura chiamata).
3.11.1 Prechiamata (lato chiamante)
Questa prima fase consiste nel preparare i parametri d’ingresso, quelli che servono alla
funzione che verrà successivamente chiamata per poter svolgere le operazioni per cui è stata
progettata.
Per questa operazione il MIPS rende disponibili 4 registri: $a0 - $a3.
In questi 4 registri vengono posti i primi quattro parametri necessari alla funzione; se vi è la
necessità di fornire più di quattro argomenti sarà richiesto l’impiego di uno stack (una coda
del tipo “last in first out”); in particolare per ogni funzione chiamata può essere necessario
allocare una porzione dello stack detto frame, di cui daremo una spiegazione più dettagliata in
seguito nel paragrafo 3.13 “gestione dello stack nell’assembler MIPS”.[1]
3.11.2 Chiamata a funzione (lato chiamante)
Il linguaggio assembly MIPS include un’istruzione apposita per le procedure, che salta ad un
indirizzo e contemporaneamente salva l’indirizzo dell’istruzione successiva nel registro $ra.
L’istruzione in questione è jal (jump and link) che si scrive semplicemente:
jal <etichetta della procedura>
La parte link del nome si riferisce al fatto che viene creato un collegamento (link), che
permette alla procedura di ritornare all’indirizzo corretto nel momento in cui termina; questo
“link” viene memorizzato nell’indirizzo $ra ed è detto indirizzo di ritorno. L’ indirizzo di
ritorno è fondamentale perché la stessa procedura può essere richiamata in più parti del
programma. [1]
Come già descritto nei capitoli precedenti l’indirizzo della prossima istruzione da prelevare è
contenuto in un particolare registro denominato PC (program counter); supponiamo che
l’istruzione puntata da PC sia la jal di Figura 3.16, il valore da salvare in $ra è PC+4 (il valore 4
deriva dal fatto che le istruzioni sono tutte a 32 bit e quindi si trovano in memoria ad indirizzi
sempre multipli di 4).
3.11
Prima dell’esecuzione della jal
Dopo l’esecuzione della jal
indirizzi
indirizzi
“∞”
PC
“∞”
jal proc
jal proc
ra
ra
PC
0
0
Figura 3.16. Meccanismo innescato dall’istruzione jal nella memoria.
3.11.3 Prologo (lato chiamato)
In questa fase si provvede all’allocazione di una parte di memoria che contiene i registri
salvati da una procedura e le variabili locali, questa parte dello stack prende il nome di
activation frame ( o activation record); il software MIPS utilizza un frame pointer per
indirizzare la prima parola del frame di una procedura.(vedere paragrafo 3.13 “gestione dello
stack nell’assembler MIPS”).
Nell’activation frame vanno salvati i registri che il chiamato intende sovrascrivere:
¾ Salvataggio degli argomenti della funzione oltre il quarto; i primi quattro possono
essere memorizzati nei registri $a0 - $a3.
¾ Salvataggio del precedente $ra se la funzione chiama altre funzioni; (vedi
paragrafo 3.14 “procedure annidate”)
¾ Salvataggio dei registri $s0 - $s7 se intendo sovrascriverli perché il chiamante si
aspetta di trovarli intatti.
3.11.4 Corpo (lato chiamato)
Questa fase coinvolge l’esecuzione delle istruzioni che realizzano le funzionalità previste dalla
procedura.
3.11.5 Epilogo (lato chiamato)
Nell’epilogo della funzione vi sono due operazioni fondamentali che devono essere svolte:
¾ Ripristino dei registri di interesse dallo stack: $s0 - $s7, $ra, $fp, $sp.
¾ Se devono essere restituiti dei valori questi devono essere posti nei registri $v0 e
$v1.
3.12
3.11.6 Ritorno al chiamante (lato chiamato)
Il linguaggio assembler MIPS include un’istruzione apposita jr (salto tramite registro) che
permette di ritornare all’indirizzo memorizzato nel registro $ra, cioè permette di tornare
nella procedura chiamante all’indirizzo dell’istruzione successiva a quella di chiamata a
funzione.
Al termine della procedura basterà quindi scrivere:
jr $ra .
Con questa istruzione si restituisce il controllo al chiamante.
Prima dell’esecuzione della jr
Dopo l’esecuzione della jr
indirizzi
indirizzi
“∞”
“∞”
jal proc
ra
jal proc
•••••
(
•••••
PC
•••••
PC
ra
)
•••••
•••••
•••••
Jr $ra
Jr $ra
0
0
Figura 3.17. Meccanismo innescato dall’istruzione jr nella memoria.
3.11.7 Post chiamata (lato chiamante)
Una volta ritornati nella funzione chiamante è possibile utilizzare i risultati forniti dalla
procedura chiamata tramite i registri $v0 e $v1.
3.12 MOTIVI PRINCIPALI DI UTILIZZO DELLO STACK
Come abbiamo visto analizzando le varie fasi di una chiamata a funzione esistono una serie di
situazioni in cui è necessario salvare dei dati in una zona della memoria per evitare che questi
vengano sovrascritti e quindi perduti. Quest’ area della memoria è chiamata stack.
Riassumendo i punti visti fin’ora lo stack deve essere utilizzato nei seguenti casi:
¾ Quando una procedura richiede più registri rispetto ai 4 riservati per il passaggio dei
parametri e ai 2 per la restituzione di valori.
¾ Quando si devono salvare dei registri che una procedura potrebbe modificare, ma che
il programma chiamante ha bisogno di mantenere inalterati.
3.13
¾ Quando si devono salvare delle variabili locali relative ad una procedura.
¾ Quando si devono gestire procedure annidate (procedure che richiamano al loro interno
altre procedure) e procedure ricorsive (procedure che invocano dei cloni di se stesse).
3.13 GESTIONE DELLO STACK NELL’ASSEMBLER MIPS
3.13.1 Descrizione generale dello stack
Lo stack è una coda del tipo “last in first out” e ha bisogno di un puntatore all’indirizzo del
dato introdotto più recentemente, per indicare dove la prossima procedura può memorizzare i
registri da riversare e dove può recuperare i vecchi valori dei registri. Il puntatore dello
stack è aggiornato ogni volta che viene inserito o estratto un valore di un registro; per questo
motivo il software MIPS alloca un altro registro appositamente per lo stack: lo stack pointer,
usato per salvare i registri che servono al programma chiamato. [1]
Lo stack può crescere verso l’alto (grow up) cioè da indirizzi di memoria più bassi a indirizzi di
memoria più alti, oppure verso il basso (grow down) cioè da indirizzi più alti a indirizzi più
bassi, come illustrato in figura 3.18.
Convenzione indirizzi
Grow down
Convenzione
Grow up
indirizzi
“∞”
“∞”
0
0
Figura 3.18. Convenzioni sul verso di crescita degli stack.
Inoltre lo stack si può suddividere in base a cosa punta lo stack pointer: può puntare al
successivo elemento dello stack vuoto (convenzione next empity), oppure può puntare
all’ultimo elemento dello stack pieno (convenzione last full).
3.13.2 Gestione dello stack nel MIPS
Per ragioni storiche nel caso dell’assembler MIPS lo stack adotta la convenzione grow down –
last full, e il registro riservato allo stack pointer è $sp.
Quindi l’inserimento di un dato nello stack avviene decrementando $sp per allocare lo spazio
necessario ed eseguendo l’operazione sw (store word) per inserire il dato; il prelevamento di
un dato dallo stack avviene incrementando $sp per eliminare il dato e riducendo quindi la
dimensione dello stack.
3.14
Esempio:
sw $t0, offset($sp)
lw $t0, offset($sp)
# salvataggio di $t0
# ripristino di $t0
Il segmento dello stack che contiene i registri salvati da una procedura e le variabili locali
prende il nome di activation frame . Il software MIPS utilizza un frame pointer ($fp) per
indirizzare la prima parola del frame di una procedura.
Tutto lo spazio in stack di cui ha bisogno una procedura (activation frame) viene
esplicitamente allocato dal programmatore in una sola volta.
Alla chiamata di una procedura lo spazio nello stack viene allocato sottraendo a $sp il numero
di byte necessari:
Esempio:
sub $sp , $sp, 12
# allocazione di 12 byte nello stack.
Al rientro da una procedura il frame viene rimosso dalla procedura incrementando $sp della
stessa quantità di cui lo si era decrementato alla chiamata:
Esempio:
addi $sp, $sp, 12
# dealloca 12 byte nello stack.
Di seguito è riportato uno schema che illustra la situazione in memoria dopo l’allocazione dello
stack (figura 3.19a) in cui si nota come cresca verso il basso. Nella figura 3.19b si può
osservare come viene utilizzato l’activation frame: il frame pointer ($fp) verrà usato per
l’accesso ai dati contenuti nel frame, lo stack pointer ($sp) è libero di variare e viene
tipicamente usato per inserire nello stack i risultati parziali nel calcolo delle espressioni(se
necessario). Nella figura 3.19c è schematizzata la situazione della memoria dopo che lo stack
è stato deallocato.
3.15
Situazione dopo
l’allocazione
dello stack
indirizzi
MEMORIA
Uso dello spazio
allocato per
l’activation frame
indirizzi
MEMORIA
“∞”
“∞”
fp
Argomento 5
Argomento 6
•••••
Registri
Salvati
Variabili
Salvate
sp
a)
Situazione dopo
la deallocazione
dello stack
indirizzi
MEMORIA
f
r
a
m
e
“∞”
sp
( fp )
Zona utilizzata
per il calcolo di
espressioni
0
b)
0
c)
0
Figura 3.19. Allocazione dello stack e del frame.
3.14 ESEMPIO 1: SOMMA ALGEBRICA
L’esempio in questione si propone di creare una procedura che svolga una somma algebrica; per
comprendere al meglio l’esempio di seguito è riportato il listato in linguaggio C.[1]
Procedura Somma_algebrica
int somma_algebrica (int g, int h, int i, int j)
{
int f;
f = (g + h) - (i + j);
return f;
}
ed ecco il listato MIPS:
#
#
#
#
g,h,i e j associati a $a0, …, $a3;
f associata a $v0
Supponiamo di utilizzare i 3 registi: $s0, $s1, $s2 nel calcolo quindi è necessario salvarne il
contenuto (in stack)
3.16
Somma_algebrica:
addi $sp,$sp,-12
sw $s0, 8($sp)
sw $s1, 4($sp)
sw $s2, 0($sp)
# alloca nello stack lo spazio per i 3 registri
# salvataggio di $s0
# salvataggio di $s1
# salvataggio di $s2
add $s0, $a0, $a1
add $s1, $a2, $a3
sub $s2, $t0, $t1
# $t0 Åg + h
# $t1 Å i + j
# f Å $t0 - $t1
add $v0, $s2, $zero
# restituisce f copiandolo nel reg. di ritorno $v0
# ripristino del vecchio contenuto dei registri estraendolo dallo stack
lw $s2, 0($sp)
# ripristino di $s0
lw $s1, 4($sp)
# ripristino di $t0
lw $s0, 8($sp)
# ripristino di $t1
addi $sp, $sp, 12
# aggiornamento dello stack per eliminare 3 registri
jr $ra
#ritorno al programma chiamante
3.15 PROCEDURE ANNIDATE
All’interno di una procedura ci possono essere delle ulteriori chiamate ad altre procedure o vi
possono essere procedure ricorsive che invocano “cloni di se stesse”; quando queste situazioni
hanno luogo è necessario fare molta attenzione all’uso dei registri. [1]
Si supponga ad esempio che il programma principale chiami la procedura “A” con un parametro
uguale a 3, mettendo il valore 3 nel registro $a0 ed usando l’istruzione jal A. Si supponga poi
che la procedura A chiami la procedura B con l’istruzione jal B passandole il valore 7, anch’esso
posto in $a0; dato che A non ha ancora terminato il proprio compito si verifica un conflitto
nell’uso del registro $a0. In modo analogo c’è un conflitto sull’indirizzo di ritorno dalla
procedura, memorizzato in $ra, perché dopo la chiamata a B esso contiene l’indirizzo di
ritorno a B; se non si adottano misure per prevenire il problema, la procedura A non sarà più in
grado di restituire il controllo al proprio chiamante.
Una soluzione consiste nel salvare nello stack tutti i registri che devono essere preservati. Il
programma chiamante memorizza nello stack i registri argomento ($a0-$a3) o i registri
temporanei ($t0-$t9) di cui ha ancora bisogno dopo la chiamata; il chiamato salva nello stack
il registro di ritorno $ra e gli altri registri ($s0-$s7) che utilizza.
Lo stack pointer $sp è aggiornato per tener conto del numero di registri memorizzati nello
stack; alla fine i registri vengono ripristinati e lo stack riaggiornato.
3.16 ESEMPIO 2: PROCEDURA RICORSIVA PER IL CALCOLO DEL
FATTORIALE
Nell’esempio che segue si mostra una procedura ricorsiva che calcola il fattoriale.[1]
Il segmento di programma può essere descritto attraverso il linguaggio c nel seguente modo:
3.17
int fact (int n)
{
if (n < 1) return (1);
else return(n * fatt (n-1));
}
Il parametro n corrisponde al registro argomento $a0. Il programma inizia con l’etichetta
della procedura, quindi salva nello stack due registri, l’indirizzo di ritorno e $a0:
fatt:
sub
sw
sw
$sp, $sp, 8
$ra, 4($sp)
$a0, 0($sp)
#aggiornamento dello stack per fare spazio a due elementi
#salvataggio del registro di ritorno
#salvataggio del parametro n
La prima volta che la procedura fatt viene chiamata, sw salva un indirizzo interno al
programma chiamante.
Le due istruzioni successive verificano se n è minore di 1, saltando a L1 se n<=1:
slt
beq
$t0, $a0, 1
$t0, $zero, L1
# test per n<1
# se n >=1 salta a L1
se n è minore di 1, fatt restituisce 1 mettendolo in un registro valore: somma 1 a 0 e lo
memorizza in $v0. Quindi ripristina dallo stack i due valori salvati e salta all’indirizzo di
ritorno:
addi
addi
jr
$v0, $zero, 1
$sp, $sp, 8
$ra
# restituisce 1
#aggiornamento dello stack per eliminare due elementi
#ritorno all’istruzione successiva a jal
prima dell’aggiornamento dello stack pointersi sarebbero dovuti ripristinare $a0 e $ra, ma
dato che non cambiano quando n è minore di 1 è possibile saltare queste istruzioni.
Se n non è minore di 1, il parametro n viene decrementato e viene nuovamente chiamata la
procedura fatt passandole tale valore:
L1:
sub
Jal
$a0, $a0, 1
fatt
# n > 1: l’argomento diventa (n-1)
# chiamata a fatt con (n-1)
L’istruzione successiva è quella a cui ritorna la procedura fatt; il vecchio indirizzo di ritorno
ed il vecchio valore del parametro sono ripristinati, oltre ad eseguire l’aggiornamento dello
stack pointer:
lw
lw
addi
$a0, 0($sp) #ritorno da jal: ripristino di n
$ra, 4($sp) #ripristino dell’indirizzo di ritorno
$sp, $sp, 8 #aggiornamento dello stack per eliminare due elementi
3.18
quindi nel registro $v0 viene memorizzato il valore del prodotto del valore corrente per il
vecchio parametro $a0:
mult
$v0, $a0, $v0
# restituzione di n*fatt(n-1)
infine la procedura fatt salta nuovamente all’indirizzo di ritorno:
jr
$ra
#ritorno al programma chiamante
3.17 DIRETTIVE DELL’ ASSEMBLATORE.
I nomi che iniziano con un punto specificano all’assemblatore come tradurre un programma ma
non generano istruzioni macchina. [1][12]
Tabella 3.3. Le direttive dell’assemblatore.
.data [<address>]
.text [<address>]
.globl <symb>
.asciiz <str>
.ascii <str>
.byte <b1>,…,<bn>
.word <w1>,…,<wn>
.float <f1>,…,<fn>
.double <d1>,…,<dn>
.half <h1>,…,<hn>
.space <n>
.align <n>
.extern <sym> [size]
.kdata [<addr>]
.ktext [<addr>]
marca l’inizio di una zona dati; se <address> viene specificato i dati
sono memorizzati a partire da tale indirizzo.
marca l’inizio del codice assembly; se <address> viene specificato i
dati sono memorizzati a partire da tale indirizzo.
dichiara un simbolo <symb> visibile dall’esterno (gli altri sono locali per
default) in modo che possa essere usato da altri file.
mette in memoria la stringa<str>, seguita da un byte ‘0’.
mette in memoria la stringa<str> e non inserisce lo ‘0’ finale.
mette in memoria gli n byte che sono specificati da <b1>,…,<bn>
mette in memoria le n word a 32 bit che sono specificate da
<w1>,..,<wn>
mette in memoria gli n numeri floating point a singola precisione (in
locazioni di memoria contigue).
mette in memoria gli n numeri floating point a doppia precisione (in
locazioni di memoria contigue).
mette in memoria le n quantità a 16 bit (in locazioni di memoria
contigue).
mette in memoria n spazi.
allinea il dato successivo ad un indirizzo multiplo di 2^n.
dichiara che il dato memorizzato all’indirizzo <sym> è un simbolo
globale ed occupa <size> byte di memoria.Questo consente
all’assemblatore di memorizzare il dato in una porzione del segmento
dati a cui si ha accesso tramite il registro $gp.
Marca l’inizio di una zona dati pertinente al kernel. Se è presente il
parametro opzionale <addr>, tali dati sono memorizzati a partire da
tale indirizzo.
Marca l’inizio di una zona contenente il codice del kernel. Se è
presente il parametro opzionale <addr>, tali dati sono memorizzati a
partire da tale indirizzo.
3.19
Esempio di utilizzo di direttive:
# Somma valori in un array
.data
array: .word 1,2,3,4,5,6,7,8,9,10
# dichiarazione array
# (array rappresenta l’indirizzo del primo elemento)
.text
.globl main
main:
li $s0,10
la $s1, array
add $s2, $zero, $zero
add $t2, $zero, $zero
loop: lw $t1, 0($s1)
add $t2, $t1, $t2
addi $s1, $s1, 4
addi $s2, $s2, 1
bne $s2, $s0, loop
# $s0 = 10 (li è una pseudoistruzione)
# load address (la è una pseudoistruzione)
# azzero $s2 contatore ciclo
# azzero $t2 per somma
# accesso all’array
# calcolo somma
# $s1: indice del prossimo elemento dell’array
# incremento $s2 contatore ciclo
# test termine ciclo
3.18 SYSCALL: CHIAMATE A SISTEMA.
Il mips mette a disposizione delle chiamate di sistema (system call) predefinite che
implementano particolari servizi (ad esempio: stampa a video). [1][12]
Ogni system call ha un codice (da caricare in $v0),degli argomenti (opzionali, da caricare in
$a0-$a3)e dei valori di ritorno (opzionali, in $v0).
Per richiedere un servizio ad una syscall occorre:
¾
¾
¾
¾
Caricare il codice della syscall nel registro $v0.
Caricare gli argomenti nei registri $a0-$a3 (quando necessario).
Eseguire syscall.
L’eventuale valore di ritorno è caricato nel registro $v0.
Nella pagina seguente è riportata una tabella che elenca le varie chiamate di sistema con i
rispettivi codici,eventuali argomenti ed eventuali valori di ritorno.
3.20
Tabella 3.4. Elenco delle chiamate a sistema.
Chiamata
Print_int
Cod
1
Argomento
$a0 = intero
Risultato
Print_float
2
$f12= virgola mobile
Print_double
3
$f12= doppia
precisione
Print_string
4
$a0 = stringa
Read_int
5
Intero in $v0
Read_float
6
Virgola mobile in $f0
Read_double
7
Doppia precisione in
$f0
Read_string
8
$a0 = buffer
$a1 = lunghezza
Sbrk
9
$a0 = quantità
Exit
10
Indirizzo in $v0
Esempio:
Operazione svolta dalla chiamata
stampa sulla console il numero intero
che le viene passato come
argomento.
stampa sulla console il numero intero
che le viene passato come
argomento.
stampa sulla console il numero
virgola mobile a doppia precisione
che le viene passato come
argomento.
stampa sulla console la stringa che le
viene passata come argomento
terminandola con il carattere Null.
legge una linea d’ingresso fino al
carattere a capo incluso;i caratteri
che seguono il numero sono ignorati
legge una linea d’ingresso fino al
carattere a capo incluso;i caratteri
che seguono il numero sono ignorati
legge una linea d’ingresso fino al
carattere a capo incluso;i caratteri
che seguono il numero sono ignorati
legge una stringa di caratteri di
lunghezza $a1 da una linea di
ingresso scrivendoli in un buffer
($a0),terminando la stringa con il
carattere Null
restituisce il puntatore (indirizzo)
ad un blocco di memoria
interrompe l’esecuzione del prog.
# Programma che stampa: la risposta è 5
.data
str: .asciiz “la risposta è”
.text
li $v0, 4
# $v0 caricato con codice di print_string
la $a0, str
# $a0 caricato con indirizzo della stringa
syscall
# stampa della stringa
li $v0, 1
# $v0 caricato con codice di print_int
li $a0, 5
# $a0 caricato con intero da stampare
syscall
li $v0, 10
# $v0 caricato con codice della exit
syscall
3.21
3.19 HIGH-LEVEL LANGUAGES
I linguaggi di programmazione possono essere suddivisi in 3 categorie:
• M-Code
• Low-Level
• High-Level
La prima categoria è quella del linguaggio macchina (M-Code sta per Machine Code). Questa
categoria comprende tutti linguaggi direttamente eseguibili dal calcolatore. I codici di questo
genere sono tipicamente costituiti da sequenze numeriche esadecimali o binarie.
La seconda categoria è costituita dai linguaggi di basso livello, di cui fa parte l'Assembly.
Questa categoria di linguaggi fornisce un livello di astrazione più alto rispetto all' M-Code, ma
richiede comunque che il programmatore conosca dettagliatamente l'architettura del
calcolatore.I linguaggi di questo tipo generano applicazioni non-portabili perchè il codice
sorgente è tipicamente molto legato al tipo di elaboratore per il quale viene progettato.
La terza categoria di linguaggi è costituita dai linguaggi di alto livello e comprende gli odierni
linguaggi di programmazione come C/C++/Java e altri. Questi tipi di linguaggi, hanno un livello
di astrazione molto elevato, per cui non richiedono la conoscenza specifica dell'architettura
dell'elaboratore e consentono di interagire con la macchina utilizzando un linguaggio "quasienglish". Naturalmente questo tipo di linguaggio non è direttamente eseguibile dal calcolatore,
per cui è necessario che vi sia un altro programma che esegua la conversione del codice di alto
livello in codice macchina, questa classe di programmi sono i compilatori.
3.20 COMPILATORI E SISTEMI DI COMPILAZIONE
Il processo di conversione di un codice sorgente in un file binario è composto da diverse fasi.
In questa immagine viene illustrata l'organizzazione di un sistema di compilazione:
Compiler
Source Code
Source Code with # substitutions
Preprocessor
Parser
Parse
Tree
Translator
AssemblyCode
MemoryImage
Loader
ExecutableFile
Linker
Object
File
Assembler
Figura 3.20. Struttura di un sistema di compilazione.
Come si può vedere la trasformazione del codice avviene in maniera graduale e comporta
l'impiego di di altri strumenti oltre il compilatore.
Analizziamo più in dettaglio il funzionamento degli strumenti che fanno parte del sistema di
compilazione [1] [2] .
3.20.1
Preprocessor
In C/C++ il preprocessore è lo strumento che gestisce le direttive #. Il preprocessore riceve
in input il codice sorgente e si preoccupa di rimuoverne i commenti e interpretare le direttive
speciali denotate dal carattere #. L'output del preprocessore è costituito dal nostro codice
sorgente opportunamente modificato, in cui ogni direttiva è stata sostituita dal risultato della
sua interpretazione [2]. Questo codice risultante viene poi fornito al compilatore per la vera e
3.22
propria generazione del codice oggetto. Sfruttando le possibilità offerte dal preprocessore, è
possibile rendere dinamico il sorgente di un software, facendo in modo che la compilazione
percorra una strada piuttosto che un'altra.
In C/C++ alcune tra le direttive del preprocessore sono:
#include, #define, #ifndef, #undef, #endif, #else, #elif, #if, #error, #line...
Facciamo qualche esempio:
La direttiva di inclusione #include comunica al preprocessore di includere nel
programma il contenuto di una libreria o di un file header.
La direttiva #define comunica al preprocessore una macro-sostituzione di un nome
simbolico o di una costante.
3.20.2
Compiler
Il compilatore è lo strumento che si occupa della conversione del codice sorgente in codice
Assembly. Per eseguire questa conversione è necessario che il codice sorgente non contenga
errori e quindi il compilatore si occupa anche dell'analisi del codice sorgente [2].
Riportiamo di seguito uno schema della struttura di un compilatore:
Parser
Source Code
Lexical
Analyzer
Translator
Assembly Code
Object Code
Generator
Semantic
Analyzer
Syntax
Analyzer
Code
Optimizer
Parse Tree
Intermediate Code
Generator
Figura 3.21. Struttura interna di un compilatore.
L'Analizzatore Lessicale individua le componenti elementari (token) come gli identificatori, le
stringhe, costanti numeriche, le keywords, gli operatori matematici e così via, e inizializza la
Tabella dei Simboli (Symbol Table).
L'Analizzatore Sintattico raggruppa i token in strutture sintattiche e insieme
all'Analizzatore Semantico controlla che le componenti delle strutture sintattiche soddisfino
le regole all'interno del contesto in cui sono inserite. Al termine dell'analisi verrà generato il
Parse Tree o Albero Sintattico. Il Parse Tree verrà interpretato dal Generatore di Codice
Intermedio, il cui codice a sua volta verrà interpretato dall'ottimizzatore che provvederà a
rimuovere eventuali inefficenze. A questo punto il codice è pronto per essere convertito in
Assembly dall'Object Code Generator. Il codice Assembly prodotto è legato alla architettura
del calcolatore.
Ad esempio proviamo ad esaminare il programma helloworld.c:
3.23
/* Created by Anjuta version 1.2.2 */
/*
This file will not be overwritten */
#include <stdio.h>
int main()
{
printf("Hello world\n");
return (0);
}
In sistemi Unix-like possiamo creare il corrispondente file Assembly con il comando:
cc -S main.c
che produce in output il file main.s:
.global
.global
.global
.global
.global
.global
_exit
_open
_close
_read
_write
_printf
LC0:
.ascii "Hello world\12\0"
.align 4
.global _main
_main:
;; Initialize Stack Pointer
add r14,r0,r0
lhi r14, ((memSize-4)>>16)&0xffff
addui r14, r14, ((memSize-4)&0xffff)
;; Save the old frame pointer
sw -4(r14),r30
;; Save the return address
sw -8(r14),r31
;; Establish new frame pointer
add r30,r0,r14
;; Adjust Stack Pointer
add r14,r14,#-16
;; Save Registers
sw 0(r14),r3
sub r14,r14,#8
lhi r3,(LC0>>16)&0xffff
addui r3,r3,(LC0&0xffff)
sw 0(r14),r3
jal _printf
nop
addi r1,r0,#0
add r14,r14,#8
j L1
nop
L1:
;; Restore the saved registers
lw r3,-16(r30)
nop
;; Restore return address
lw r31,-8(r30)
nop
;; Restore stack pointer
add r14,r0,r30
;; Restore frame pointer
lw r30,-4(r30)
3.24
nop
;; HALT
jal _exit
nop
_exit:
trap #0
jr r31
nop
_open:
trap #1
jr r31
nop
_close:
trap #2
jr r31
nop
_read:
trap #3
jr r31
nop
_write:
trap #4
jr r31
nop
_printf:
trap #5
jr r31
nop
.global ___gnuc_va_list
___gnuc_va_list: .space 8
Questo file sarà poi inviato all'assemblatore che si incaricherà di produrre il corrispondente
object file.
3.20.3
Assembler
Il codice Assembly prodotto in output dal compilatore viene inviato all'assemblatore, che
provvederà a tradurlo in codice macchina (object code).
Un assemblatore è un programma che processa un file sorgente in codice Assembly mappando
direttamente ogni istruzione in codice macchina (ovvero ogni istruzione Assembly viene
trasformata in una istruzione in codice macchina eseguibile dal calcolatore). Per effettuare la
mappatura del codice Assembly in codice macchina l'assemblatore effettua due passate [3] .
Durante la prima passata l'assemblatore esegue le seguenti operazioni:
• Controlla che le espressioni Assembly siano corrette.
• Alloca spazio per le istruzioni e per il salvataggio in memoria che il codice richiede.
• Assegna i valori alle costanti (se definite).
• Costruisce una Symbol Table (o Cross Reference Table).
La Symbol Table identifica i simboli che il compilatore non è riuscito a ‘risolvere’, cioè quelli
di cui non sa ancora il valore perché tale valore dipende dal resto dell’eseguibile finale.
Ci sono due tipi di simboli:
• Definiti nel file ma utilizzati altrove (esportati).
3.25
Ad esempio le funzioni che definiamo all'interno di un file ma che utilizziamo in altri moduli
del programma.
Per i simboli esportati la Symbol Table contiene: nome e indirizzo locale.
Tabella 3.5. Simboli esportati.
Simboli esportati
Nome
•
Indirizzo locale
Definiti altrove ma utilizzati nel file (esterni).
Ad esempio le funzioni importate come printf, scanf (e tutte quelle delle librerie che
utilizziamo all'interno del nostro programma).
Per i simboli esterni la Symbol Table contiene: nome e indirizzo delle istruzioni che vi fanno
riferimento.
Tabella 3.6. Simboli esterni.
Nome
Simboli esterni
Indirizzo delle istruzioni
che vi fanno riferimento
Come viene costruita la Symbol Table.
L'assemblatore legge il file sorgente una riga alla volta (ogni riga corrisponde ad una
istruzione), ed esamina se la label-field contiene un simbolo valido per una label.
Se il simbolo trovato viene ritenuto valido ed è la prima volta che si utilizza il simbolo come
label, l'assemblatore lo aggiungerà nella tabella dei simboli e gli assegnerà il valore corrente
del contatore di locazione. Se invece si verifica che il simbolo era già stato usato come label,
allora l'assemblatore riporterà il messaggio di errore Redefinition of symbol e sovrascriverà
il valore del simbolo con il valore corrente del contatore di locazione [3].
Durante la seconda passata vengono eseguite le seguenti operazioni:
• Gli op-code vengono tradotti in sequenze binarie usando una apposita Op-code Table.
• Gli indirizzi simbolici vengono tradotti in sequenze binarie usando la Symbol Table.
• Si predispone la Tabella di Rilocazione (Relocation Table).
La tabella di rilocazione identifica le parti del testo che si riferiscono ad indirizzi assoluti di
memoria (ad esempio dei jump assoluti o dei riferimenti assoluti all'area dei dati globali).
Questi indirizzi devono essere rilocati nell'eseguibile finale a seconda della posizione della
prima istruzione del testo (offset), l'offset verrà sommato ad ogni indirizzo rilocabile.
Struttura di un object file:
3.26
Header:
dimensione e posizione del file e
dei suoi moduli
Text Segment:
contiene il codice macchina
Data Segment:
dati statici generati con il
programma
Relocation Info:
identifica dati e istruzioni che
dipendono da indirizzi assoluti
quando il programma è caricato in
memoria
Symbol Table:
tabella dei simboli locali ed
etichette visibili all'esterno
Debugging Info:
parte opzionale per il debugging
del programma
Figura 3.22. Struttura di un object file.
In sistemi Unix-like possiamo avere informazioni sull'object file utilizzando il comando:
nm file.o
Ad esempio, per il programma helloworld.c:
nm main.o
Symbol Value
00000000
Symbol Type
Symbol Name
T
main
U
printf
"T" The symbol is in the text (code) section.
"U" The symbol is undefined.
3.20.4
Linker
Le librerie o i file esterni a cui un programma fa riferimento vengono compilati a parte come
moduli separati e solo successivamente vengono collegati al programma principale in maniera
da risolverne le dipendenze. Quindi, se il file sorgente contiene riferimenti a funzioni definite
in librerie o in file esterni, queste librerie e questi file esterni dovranno essere collegati al
file che le utilizza [4] [5] [6]. Il linker permette di collegare più moduli oggetto assemblati
separatemente in modo da costituire un unico modulo esegibile finale.
3.27
Figura 3.23. Schema del linking di un programma.
Ogni modulo oggetto generato dall'assemblatore contiene tutte le informazioni necessarie al
linker per operare il collegamento. In particolare vengono forniti i simboli pubblici (ad esempio
le procedure esportate nel modulo), ed i riferimenti esterni (ad esempio le chiamate a
procedure definite in altri moduli).
Il linker deve risolvere tre problemi:
1. Cercare nelle librerie le funzioni utilizzate dal programma.
2. Determinare le locazioni di memoria che ciascun modulo occuperà e rilocare le
istruzioni aggiornando i riferimenti assoluti.
3. Risolvere i riferimenti tra i file che compongono il programma.
Passi compiuti dal linker:
1. Costruisce una tabella contenente la lunghezza dei moduli oggetto.
2. In base alla tabella assegna un indirizzo di caricamento ad ogni modulo oggetto.
3. Aggiorna tutti gli indirizzi rilocabili.
4. Aggiorna tutti i riferimenti a procedure esterne.
Per realizzare le operazioni 3 e 4 il linker sfrutta le informazioni prodotte dall'assemblatore
e contenute nei moduli oggetto. Vengono costruite due tabelle generali che raccolgono i
simboli pubblici ed i riferimenti esterni di tutti i moduli [5].
Il linker produce un file eseguibile dello stesso formato dell'object file, ma con la differenza
che non contiene informazioni per la rilocazione degli indirizzi, visto che gli indirizzi sono già
stati tutti risolti, cioè sono già stati assegnati indirizzi definitivi [5].
3.28
Startup
Object file
Object files
(*.o)
Library
(*.a)
Symbol
Table
Linker
Relocation
Infos
Binary File
(executable)
Figura 3.24. Schema di funzionamento del linker.
3.20.5
Loader
Ogni volta che viene eseguito un programma il loader compie le seguenti operazioni [1]:
1. Legge l'header del file eseguibile per determinare la dimensione del Data Segment e del
Text Segment.
2. Alloca uno spazio di indirizzamento in memoria.
3. Copia le istruzioni e i dati del file eseguibile nel nuovo spazio di indirizzamento.
4. Copia i parametri passati al programma principale nello stack.
5. Inizializza i registri e assegna allo stack pointer l'indirizzo della prima cella libera.
6. Copia gli argomenti del programma principale nei registri e chiama il main.
3.21 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Sito web: http://ou800doc.caldera.com/en/SDK_cprog/CCCS_CompCCompilationSys.html
[3] Sito web: http://www.nersc.gov/vendor_docs/ibm/asm/alangref02.htm
[4] Sito web: http://acm.uiuc.edu/sigmil/RevEng/index.html
[5] F. Tortorella, "Corso di Calcolatori Elettronici", Università degli studi di Cassino,
Link: webuser.unicas.it/tortorella/
[6] S. Salza, G. Santucci, "Calcolatori Elettronici", Università di Roma "La Sapienza",
Sito web: http://www.dis.uniroma1.it/~salza/teaching.htm
[7] Riccardo Solmi, “Assembly1”, Link: http://www.cs.unibo.it/~solmi/
3.29
LEZIONE 4
Valutazione delle prestazioni (parte prima)
4.1 INTRODUZIONE
4.1.1 Definizione di prestazione
Ci preoccupiamo, per prima cosa, di capire cosa s’intende quando si afferma che “un dato
calcolatore è più veloce di un altro”. Si potrebbe pensare a due significati diversi:
- ad esempio, un generico utente potrebbe dire che un calcolatore è più veloce di un
altro quando esegue un programma in minor tempo rispetto ad un altro;
- al contrario, il gestore di un centro informatico potrebbe dire che il calcolatore più
veloce è quello che, a parità d’intervallo di tempo a disposizione (ad esempio un’ora),
completa il maggior numero di lavori (jobs).
La differenza tra i due “significati” è dunque riscontrabile nel parametro usato per giudicare
la velocità di un calcolatore.
Prendiamo in considerazione un esempio per chiarire la situazione.
Velivolo
DC to Paris
Velocità
Passeggeri
Boeing 747
Concorde
6.5 hours
3 hours
610 mph
1350 mph
470
132
Throughput
(pmph)
286.000
178.200
Considerando la tabella sovrastante, quale dei due velivoli ha migliori prestazioni?
Prendendo in esame la velocità, potremmo dire che il Concorde ha migliori prestazioni del
Boeing 747, ma non sarebbe errato affermare che, per quanto riguarda la portata, il Boeing
747 ha migliori prestazioni del Concorde.
Com’è ormai chiaro, risulta indispensabile chiarire la tipologia d’utente ed i relativi parametri
da essi utilizzati per giudicare le suddette prestazioni:
- l’utente generico è soprattutto interessato a minimizzare il response time (tempo di
risposta), ossia il tempo che intercorre tra l’inizio e il completamento di un evento. Si
parla anche di tempo di esecuzione (execution time) oppure di latenza (latency);
Esempi di tempo di risposta:
- Durata dell’esecuzione del mio programma.
- Attesa per l’accesso ad un sito web.
-
al contrario, il gestore del centro informatico è interessato essenzialmente a
massimizzare il throughput del calcolatore, ossia la quantità complessiva di lavoro
svolto in un dato intervallo di tempo. Si parla anche di banda passante (bandwidth) del
calcolatore (da non confondere con l’ampiezza di banda dei mezzi trasmissivi).
Esempi di throughput:
- Numero di programmi eseguiti nell’unità di tempo.
- Numero di lavori (job, transizioni, interrogazioni a basi di dati) effettuati
nell’unità di tempo.
- Numero di programmi eseguibili da una macchina contemporaneamente.
Si può del resto intuire che, almeno in condizioni normali, un tempo di risposta più basso
equivale ad un aumento del throughput: quanto più il sistema è rapido nell’eseguire i singoli
compiti, tanti più compiti potrà portare a termine in un dato intervallo di tempo.
4.1
Per comprendere meglio i concetti appena citati, possiamo fare un semplice esempio. Esistono
diversi modi per migliorare le prestazioni di un calcolatore; ad esempio tre di questi sono i
seguenti:
1. periodo di clock più breve (cioè clock più veloce);
2. processori multipli per compiti diversi;
3. elaborazione parallela per problemi scientifici.
Il primo ed il terzo metodo sicuramente garantiscono tempi di risposta più brevi: ad esempio,
se l’esecuzione di un dato programma richiede N cicli di clock e ogni ciclo dura τ secondi, il
tempo totale di esecuzione è N·τ, che sarà tanto più piccolo quanto più è piccolo τ. Quindi, il
primo ed il terzo metodo contribuiscono anche ad aumentare il throughput complessivo. Il
secondo metodo, invece, non comporta alcun miglioramento sulla velocità con cui viene eseguito
il singolo compito, ma consente di svolgere più compiti contemporaneamente, per cui serve ad
incrementare solo il throughput.
Esempio 1:
I seguenti cambiamenti apportati ad un sistema di calcolo aumentano il throughput,
diminuiscono il tempo di risposta o entrambe le cose?
1. Sostituire il processore all’interno del calcolatore con una versione più veloce.
2. Aggiungere processori addizionali ad un sistema che usa processori multipli per
compiti separati, ad esempio per gestire il sistema di prenotazioni di una linea aerea.
Soluzione
Diminuire il tempo di risposta aumenta quasi sempre il throughput. Quindi nel caso 1
migliorano sia il tempo di risposta che il throughput. Nel caso 2 nessun compito viene
eseguito più velocemente e di conseguenza aumenta soltanto il throughput. Se però nel
secondo caso il numero di elaborazioni richieste fosse quasi elevato come il throughput,
il sistema potrebbe essere costretto a mettere in coda le richieste. In questo caso
aumentare il throughput può anche diminuire il tempo di risposta, dal momento che si
riduce il tempo di attesa nella coda. Così, in molti sistemi di calcolo reale modificare il
tempo di esecuzione influenza il throughput e viceversa.
4.2 MISURE STATISTICHE
Talvolta, le misure delle prestazioni di un calcolatore sono descritte meglio da distribuzioni
di probabilità che non da valori deterministici. Ad esempio, consideriamo il tempo di risposta
necessario per completare una data operazione di I/O sul disco rigido del calcolatore: tale
tempo di risposta dipende sia da fattori deterministici (ad esempio dalla quantità di dati da
leggere e da scrivere su disco) sia da fattori non deterministici (ad esempio da ciò che il disco
sta eventualmente già facendo quando viene richiesto l’I/O oppure dalla quantità di altri
processi in attesa di accedere allo stesso disco). Data la presenza di tali fattori non
deterministici, ha più senso parlare di tempo medio di risposta per un I/O da disco. In modo
analogo, anche l’effettivo throughput di disco (cioè il numero di dati che transitano realmente
da o verso il disco nell’unità di tempo) non risulta essere un valore costante. Nel seguito,
comunque, tratteremo il tempo di risposta ed il throughput come valori deterministici.
4.3 LE PRESTAZIONI
Per i progettisti di calcolatori, così come ad esempio per quelli di automobili, non esiste un
unico obiettivo da raggiungere:
4.2
-
-
ad un estremo, troviamo i progetti ad elevate prestazioni, che non badano a spese
pur di raggiungere il proprio obiettivo (lo stesso accade, ad esempio, per la
Ferrari);
all’estremo opposto troviamo invece i progetti a basso costo, dove le prestazioni
vengono sacrificate per raggiungere costi contenuti;
una via di mezzo è costituita dai cosiddetti progetti costo/prestazioni, nei quali il
progettista effettua un bilancio appunto tra costi e prestazioni.
4.3.1 Concetti generali
Il tempo è la misura delle prestazioni di un calcolatore: questo significa, in parole povere, che
il calcolatore che svolge la stessa quantità di lavoro impiegando il minor tempo è il più veloce.
Due esempi banali sono i seguenti:
-
il tempo di esecuzione di un programma si misura in secondi per programma;
la prestazione viene spesso misurata come il tasso di un certo numero di eventi per
secondo, in modo tale che bassi tempi significano prestazioni più elevate.
Il tempo può del resto essere definito in vari modi, a seconda di come lo si conteggia; volendo
usare la sua definizione più semplice, parliamo di tempo assoluto o tempo di risposta (elapsed
time):
esso rappresenta la latenza per il completamento di un dato lavoro, includendo
tutti i fattori necessari per svolgere tale lavoro,
come ad esempio gli accessi al disco, gli accessi alla memoria, le attività di I/O, il sovraccarico
dovuto al sistema operativo e altro. Tuttavia, quando ci riferiamo ad un ambiente di
multiprogrammazione, è noto che la CPU si dedica contemporaneamente a più programmi, che
quindi si alternano al suo utilizzo: ad esempio, mentre la CPU attende le operazioni di I/O per
un dato programma, si dedica all’esecuzione di un altro programma; di conseguenza, il tempo
trascorso non necessariamente risulta minimizzato, il che ci costringe a trovare altri termini
più efficaci. Ci viene incontro, allora, il cosiddetto tempo di CPU, il quale coglie la
“distinzione” citata poco fa, non includendo il tempo di attesa per l’I/O ed il tempo per
l’esecuzione di altri programmi. Ovviamente, dal punto di vista dell’utente, il tempo che conta
è il tempo di risposta del programma e non certo il tempo di CPU; quest’ultimo è invece una
buona misura di prestazione per il progettista.
Il tempo di CPU può essere ulteriormente suddiviso in due componenti:
- tempo utente di CPU: è il tempo di CPU dedicato al programma (TU);
- tempo CPU di sistema: è il tempo speso dal sistema operativo per effettuare i
compiti richiesti dal programma (TK).
Quest’ultima distinzione si può apprezzare sperimentalmente tramite un apposito comando
previsto dal sistema operativo Unix: si tratta del comando “time”, il quale restituisce una
sequenza di valori del tipo seguente:
90.7u 12.9s 2:39 65%
Questa sequenza dice che il tempo utente di CPU, per il programma desiderato, è
complessivamente di 90.7 secondi, mentre 12.9 secondi costituiscono il tempo CPU di sistema;
4.3
il tempo impiegato dal programma è di 2 minuti e 39 secondi (cioè 159 secondi), mentre invece
la percentuale di tale tempo rappresentativa del tempo di CPU vale:
90.7 +12.9
×100 = 65%
159
Quindi, poco meno dei 2/3 del tempo totale sono spesi per l’esecuzione del programma in
questione, mentre poco più di 1/3 del tempo è usato per attese legate sia all’I/O sia
all’esecuzione di altri programmi. Segnaliamo, comunque, che molte misure ignorano il tempo di
CPU del sistema, sostanzialmente per due motivi:
1. si è verificato che l’accuratezza con cui il sistema operativo effettua rilievi su se
stesso è generalmente molto bassa;
2. dato che il tempo di CPU di sistema cambia da macchina a macchina (poiché cambia il
codice di sistema), questa misura non è assolutamente valida per confrontare le
prestazioni tra due macchine diverse.
4.3.2 Le prestazioni della CPU
È noto che la maggior parte dei calcolatori viene realizzata usando un clock di frequenza
fissa. Tale clock fornisce dunque degli “eventi” che discretizzano il tempo, questi vengono
chiamati cicli di clock. Si può far riferimento alla durata dei cicli di clock sia mediante la loro
lunghezza, detta periodo di clock (ad esempio 10 ns), sia mediante il suo inverso, ossia la
frequenza di clock (ad esempio 100 MHz). In base a questa distinzione, è possibile esprimere
il tempo di CPU per un programma in due modi perfettamente equivalenti:
CCPU = cicli di clock della CPU
TC = periodo di clock
fC = frequenza di clock
C CPU
TCPU = CCPU·TC =
fC
Oltre al numero dei cicli di clock necessari per eseguire un programma, si può anche contare il
numero di istruzioni eseguite o istruzioni dinamiche, indicato con NCPU. Esso dipende dal set
di istruzioni e dalla qualità dei compilatori (per qualità di un compilatore s’intende la sua
capacità di ottimizzare il programma, ad es. eliminando le istruzioni non necessarie). Se il set
di istruzioni contiene istruzioni di tipi semplici avremo un NCPU alto; istruzioni di tipo più
complesso permetteranno invece di abbassare NCPU (con un set di istruzioni di tipo semplice ne
occorrono infatti di più per svolgere le stesse funzioni). Questo numero, unito al numero di
cicli di clock necessari per l’esecuzione, permette a sua volta di calcolare il numero medio di
cicli di clock per istruzione (indicato con CPI ):
CPI =
CCPU
N CPU
Il CPI andrebbe sempre misurato in quanto i costruttori lo forniscono spesso nella
documentazione per tutti i tipi di istruzioni per le quali il tempo di esecuzione varia, per
esempio, in funzione degli operandi, può essere definito il valore minimo o un intervallo di
valori. Se le istruzioni sono di tipo semplice, si avrà un CPI basso, se invece si eseguono
operazioni più complesse si avrà un CPI elevato).
4.4
Esempio 2:
Un progettista di compilatori sta cercando di scegliere tra due sequenze di codici per un
determinato calcolatore. I progettisti hardware hanno fornito le seguenti informazioni:
CPI A =1; CPI B=2; CPI C =3.
Una particolare istruzione di un linguaggio ad alto livello può essere compilata ricorrendo
a due diverse sequenze di codici, le quali richiedono le seguenti combinazioni di
istruzioni:
Compilatore
CC1
CC2
1.
2.
3.
Istr. tipo A
Istr. tipo B
2
4
1
1
Istr. tipo C
2
1
Quale sequenza di codici causa l’esecuzione del maggior numero di istruzioni?
Quale viene eseguita più velocemente?
Qual è il CPI per ciascuna delle sequenze?
Soluzione
NCPU(2)= 4+1+1= 6
1.
NCPU(1)= 2+1+2=5
Il compilatore 1 produce il codice più corto.
2. CCPU(1)=(2*1)+(1*2)+(2*3)=10 cicli
CCPU(2)=(4*1)+(1*2)+(1*3)= 9 cicli
Il compilatore 2 produce il codice più veloce!
C (1) 10
=
=2
CPI (1) = CPU
3.
N CPU (1) 5
CPI (2) =
CCPU (2) 9
= = 1.5
N CPU (2) 6
Il compilatore 2 produce il codice con il miglior CPI .
Dalla formula della CPI , vista in precedenza, possiamo ricavare due espressioni alternative
per il tempo di CPU: portando infatti a numeratore il numero di istruzioni eseguite e
riprendendo le precedenti formule per il calcolo del tempo di CPU, otteniamo che:
TCPU = N CPU × CPI× TC =
N CPU × CPI
fC
Dalla precedente serie di equazioni possiamo dunque affermare che le componenti principali
per la valutazione delle prestazioni, con le relative unità di misura, sono:
Componenti delle prestazioni
NCPU
Numero istruzioni
CPI
Cicli di clock per istruzione
TC
Durata del ciclo di clock
Unità di misura
Istruzioni eseguite
Numero medio di
cicli di clock per istruzione
Secondi per ciclo di clock
Osserviamo dunque che la prestazione della CPU dipende da tre caratteristiche:
- il periodo di clock (o la frequenza di clock);
4.5
i cicli di clock per istruzione ( CPI );
il numero di istruzioni (NCPU).
Non è possibile modificare separatamente una di queste tre caratteristiche, poiché le
tecnologie di base che le riguardano singolarmente sono interdipendenti tra loro:
- il periodo di clock dipende sia dalla tecnologia dell’hardware sia dall’organizzazione;
-
il CPI dipende a sua volta dall’organizzazione ed anche dall’architettura dell’insieme
di istruzioni;
- il NCPU dipende infine dall’architettura dell’insieme di istruzioni nonché dalla
tecnologia dei compilatori.
Talvolta, risulta anche utile calcolare il numero totale dei cicli di clock della CPU ripartendo il
numero medio di cicli di clock per ciascuna istruzione di programma:
-
N
(
CCPU = Σ CPIi × Ii
i=1
)
In questa formula, il pedice i indica l’i-esima istruzione dinamicamente eseguita dal
programma in questione, Ii indica il numero di volte che tale istruzione viene eseguita in un
programma, mentre CPIi indica il numero medio di cicli di clock per eseguire l’istruzione i.
Moltiplicando questa formula per il periodo di clock, si ottiene evidentemente ancora una volta
il tempo di CPU:
N
(
)
TCPU = Σ CPIi × Ii × TC
i=1
Se invece dividiamo per il numero di istruzioni, otteniamo il CPI :
N
CPI =
CCPU
=
N CPU
Σ (CPI × I )
i
i=1
i
N CPU
In generale, si ricordi, che la misura reale delle prestazioni è sempre il tempo, anche perché si
tratta dell’unica grandezza facilmente misurabile.
Esempio 3:
Un dato programma viene eseguito in 10 secondi dal calcolatore A, dotato di un clock a
400 MHz. Un progettista deve costruire un calcolatore B in grado di eseguire lo stesso
programma in 6 secondi ed ha concluso che è possibile aumentare in modo significativo la
frequenza di clock; questa modifica avrà però influenza su tutto il progetto della CPU,
facendo sì che il calcolatore B richieda un numero di cicli maggiore di un fattore 1.2
rispetto al calcolatore A. Dovendo dare un consiglio al progettista quale sarà la
frequenza di clock a cui puntare come obiettivo?
Soluzione
Il numero di cicli di clock necessari all’esecuzione del programma su A sono:
CCPU(A)=fC(A)·TCPU(A)=4·109
Da cui la frequenza di clock del calcolatore B:
fC = (CCPU(B) / TCPU(B)) = (1.2 · 4 ·109) / 6 = 800 MHz
4.6
Per ottenere una diminuzione del 40% del tempo di esecuzione è necessario raddoppiare
la frequenza di clock.
Esempio 4:
Siano dati due calcolatori A e B, il primo è dotato di un clock a 1GHz e di un numero
medio di cicli di istruzione pari a 2.5. Il secondo ha una frequenza di clock pari a 500
MHz e un numero medio di cicli di istruzione di 1.2. Tenendo presente che il set di
istruzioni non cambia per entrambi i calcolatori (NCPU(A)=NCPU(B)), qual è il calcolatore
più veloce?
Soluzione
Calcoliamo lo speed up:
SAB =
TCPU (B ) N CPU (B) CPI (B)
=
TCPU ( A) N CPU ( A) CPI ( A)
f C ( A) 1.2 1000
=
= 0.96
f C (B ) 2.5 500
Il rapporto tra le velocità di A e B è di 0.96, facendo il reciproco però, si può capire
meglio che B è più veloce di A del 4%, avendo un SBA (reciproco del rapporto SAB ) di 1.04.
4.4 CONFRONTO DI PRESTAZIONI
Quando si deve scegliere tra diverse alternative di progetto di un calcolatore, è necessario
confrontare le rispettive prestazioni in modo da individuare l’alternativa più adeguata alle
proprie esigenze. Indichiamo allora due macchine prese ad esempio con X ed Y. Diremo
sempre che “X è più veloce di Y” per dire che il tempo di esecuzione, per uno stesso lavoro, è
più basso in X che in Y:
Y
tempo di esecuzione su Y
X
tempo di esecuzione su X
0
50
100
150
200
250
Figura 4.1 Confronto delle Prestazioni.
Da un punto di vista quantitativo, possiamo quantificare la differenza di velocità nel modo
seguente: indicati con EX ed EY i tempi di esecuzione, rispettivamente, di X e di Y, possiamo
scrivere che
EY EX + Δ
Δ
=
= 1+
EX
EX
EX
In questa espressione, Δ rappresenta evidentemente l’incremento del tempo di risposta di Y
rispetto ad X. Se vogliamo adottare invece una misura percentuale allora ci basta scrivere che
EY
n
= 1+
EX
100
4.7
In base a quest’espressione potremmo dire che “X è n% volte più veloce di Y”. Ad esempio, se
n=50, diremo che X è il 50% più veloce di Y, il che significa:
EY
50
= 1+
= 1.5
EX
100
ossia che il tempo di esecuzione di X è 2/3 rispetto a quello di Y, con riferimento, ovviamente,
ad un lavoro specificato.
E’ facile capire che il tempo di esecuzione è il reciproco della prestazione, per cui possiamo
anche scrivere che
1
E
P
P
n
1+
= Y = Y = X
1
100 E X
PY
PX
dove P sta appunto per “prestazione”. In base a quest’espressione, “la prestazione di X è n%
migliore di quella di Y”.
Esiste anche un ulteriore modo di vedere la cosa. Generalmente, confrontando due quantità
diverse tra loro, si considera la differenza tra la quantità maggiore e la quantità minore e la si
divide per la quantità minore (si può anche moltiplicare per 100 per ottener una misura
percentuale). Lo stesso discorso possiamo fare nel nostro caso, ossia possiamo affermare che
l’aumento percentuale n di prestazione di X rispetto a Y equivale alla differenza tra la
prestazione di X e la prestazione di Y, divisa per la prestazione di Y:
n=
PX - P Y
×100
PY
Riarrangiando questa espressione, è facile trovare esattamente la formula precedente
1+
n
P
= X , il che ci dice che i vari modi di esprimersi, sia in termini qualitativi (cioè di
100 PY
definizioni) sia in termini quantitativi (cioè di formule), sono perfettamente equivalenti tra
loro.
Esempio 5:
Supponiamo che una data macchina A esegua un programma in 10 secondi, mentre lo
stesso programma viene eseguito da una macchina B in 15 secondi. E’ evidente che la
macchina A è più veloce della macchina B, dato il tempo di esecuzione più basso.
Soluzione
Per quantificare numericamente l’incremento n di velocità ci basta applicare le formule
citate poco fa:
1+
n
E
15
= Y =
= 1.5
100 E X 10
n=50
Quindi A è più veloce di B del 50%.
4.8
4.5 MIPS (MILIONE DI ISTRUZIONI AL SECONDO)
Una ferma convinzione di molti esperti del settore è quella per cui la sola misura uniforme ed
affidabile delle prestazioni di un calcolatore è il tempo di esecuzione di programmi reali,
ossia programmi di utilizzo comune presso gli utenti. Qualunque proposta alternativa, sia al
parametro temporale sia all’uso di programmi reali come elementi di misura, è ritenuta poco
consona alle esigenze della progettazione dei calcolatori o addirittura foriera di errori nella
progettazione stessa.
Di seguito vogliamo allora esaminare le proposte alternative più diffuse ed i pericoli insiti in
esse.
Una prima importante alternativa all’uso del tempo come metro di prestazione è il cosiddetto
MIPS, che sta per milioni di istruzioni al secondo. Per un dato programma, il MIPS è
semplicemente definito nel modo seguente:
MIPS =
N CPU
fC
6 =
TCPU ×10
CPI×106
Le macchine più veloci sono evidentemente quelle con il MIPS più alto. È subito importante
sottolineare che il MIPS dipende strettamente dal programma usato: infatti, esistono
programmi che sfruttano le parti più complicate di un processore ed altri che invece
sfruttano solo le funzioni più semplici, perciò il CPI è legato a tali programmi e quindi varia da
uno all’altro.
Tra le due forme alternative del MIPS proposte, la seconda è quella più apprezzata, dato che
la frequenza di clock è fissa per una data macchina e il CPI è normalmente un numero piccolo,
a differenza di quanto accade invece per il numero di istruzioni e il tempo di esecuzione.
Portando il tempo di esecuzione al primo membro ed il MIPS a secondo membro, si ottiene:
TCPU =
N CPU
MIPS×106
Questa espressione è utile poiché, essendo il MIPS nient’altro che la frequenza delle
operazioni per unità temporale, le prestazioni delle macchine più veloci (cioè con MIPS più
alto) sono evidenziabili tramite i tempi di esecuzione più bassi.
Il pregio fondamentale del MIPS è che si tratta di una figura di merito facilmente
comprensibile per l’acquirente: quest’ultimo sarà infatti tentato ad acquistare la macchina con
il MIPS più alto. A fronte di questo, però, ci sono da considerare tre problemi fondamentali:
1. il MIPS dipende dall’insieme di istruzioni della macchina, il che rende difficile
confrontare, tramite il MIPS appunto, calcolatori con diversi insiemi di istruzioni;
2. il MIPS può variare, sullo stesso calcolatore, al variare del programma considerato
(perché varia il NCPU e il CPI ): si può perciò avere un MIPS molto alto per un dato
programma ed un MIPS molto più basso per un altro programma;
3. infine, il MIPS può variare in modo inversamente proporzionale alle prestazioni, il che
rappresenta il principale difetto di questo indice di prestazione. Un classico esempio
per evidenziare questo concetto è quello di una macchina che possiede hardware
opzionale per le operazioni in virgola mobile: in condizioni normali, le operazioni in
4.9
virgola mobile hanno bisogno di più cicli di clock rispetto a quelle che lavorano con
numeri interi; di conseguenza i programmi usano, per la virgola mobile, non le apposite
routine software, ma l’hardware opzionale, il che garantisce tempi minori di esecuzione
ma anche un MIPS più basso (vengono eseguite meno istruzioni); al contrario, se le
operazioni in virgola mobile vengono effettuate via software (tramite l’uso di istruzioni
semplici), il MIPS sale ma sale anche il numero di istruzioni da eseguire e anche il
tempo di esecuzione.
In base a questi discorsi si comprende come il MIPS possa non dare un’immagine veritiera
delle prestazioni, proprio perché non considera il tempo di esecuzione. Per compensare questa
“debolezza”, si può pensare di introdurre un MIPS di riferimento, ossia un MIPS calcolato
per una particolare macchina di riferimento, rispetto al quale esprimere il MIPS originario,
ossia quello definito prima: si ottiene così il cosiddetto MIPS relativo, dato da
MIPS relativo =
Tempo riferimento
× MIPSriferimento
Tempo non rapportato
In quest’espressione, la quantità Temporiferimento rappresenta il tempo di esecuzione di un
programma sulla macchina di riferimento, mentre invece Temponon rapportato è il tempo
necessario ad eseguire lo stesso programma sulla macchina da rapportare. La quantità
MIPSriferimento è invece il MIPS accertato della macchina di riferimento. Naturalmente il MIPS
relativo considera solo il tempo di esecuzione per un programma specifico e per un ingresso
specifico a tale programma.
Ci sono per lo meno due problemi da considerare a proposito del MIPS relativo:
1. risulta in ogni modo difficile trovare una macchina di riferimento della stessa età di
quella da testare (negli anni ’80, la principale macchina di riferimento fu il VAX 11/780,
che fu detta anche macchina da 1 MIPS);
2. bisogna decidere se la macchina più vecchia debba funzionare con la versione più
recente del compilatore e del sistema operativo oppure se il software debba in ogni
caso essere fissato in modo che la macchina di riferimento non diventi più veloce con il
passare del tempo.
Facendo dunque una sintesi di quanto detto, anche il MIPS relativo appare scarso, in quanto il
tempo di esecuzione, il programma ed il suo ingresso devono comunque essere noti per poter
ricavare delle informazioni significative.
4.6 MFLOPS (MILIONI DI OPERAZIONI IN VIRGOLA MOBILE AL
SECONDO)
Una diffusa alternativa al tempo di esecuzione, per la misura delle prestazioni, è il cosiddetto
MFLOPS (si legge “megaflops”), che sta per “milioni di operazioni in virgola mobile al secondo”.
La formula con cui si calcola questo indice di prestazione non è altro che la definizione
dell’acronimo:
MFLOPS =
Numero di operazioniin virgola mobiledi un programma
Tempo di e sec uzione×106
4.10
E’ subito evidente che il MFLOPS dipende sia dalla macchina sia dal programma che si sta
usando. Naturalmente, dato che il MFLOPS fa riferimento alle sole operazioni in virgola
mobile, non è applicabile altrove. A titolo di esempio estremo, citiamo il fatto che ci sono
alcuni compilatori che, a prescindere dalla velocità della macchina su cui vengono eseguiti,
hanno un MFLOPS quasi nullo, poiché usano molto poco le operazioni in virgola mobile.
Il MFLOPS appare più rappresentativo del MIPS: infatti, essendo basato sulle singole
operazioni e non sulle istruzioni, esso può essere teoricamente usato per confrontare tra loro
due o più macchine, partendo dal presupposto che un programma, funzionando su diverse
macchine, può eseguire un diverso numero di istruzioni, ma compirà sempre lo stesso numero
di operazioni in virgola mobile.
Nonostante questo pregio, si manifesta comunque anche un problema: l’insieme delle
operazioni in virgola mobile non è lo stesso in tutte le macchine. Ad esempio, il calcolatore
CRAY-2 non possiede istruzioni di divisione, mentre invece il Motorola 68882 possiede la
divisione, la radice quadrata, il seno ed il coseno. A questo si aggiunge anche il problema per
cui il MFLOPS cambia non solo al variare della mescolanza tra le operazioni intere ed
operazioni in virgola mobile, ma anche al variare della mescolanza tra operazioni in virgola
mobile “lente” e “veloci”: ad esempio, un programma con il 100% di addizioni in virgola mobile
darà origine ad un MFLOPS più alto (e quindi migliore) rispetto ad un programma che invece ha
il 100% di divisioni in virgola mobile.
Una possibile soluzione ad entrambi questi problemi consiste nel definire un numero canonico
di istruzioni in virgola mobile a livello di programma sorgente ed usare tale numero per
calcolare il MFLOPS, dividendo in pratica per il tempo di esecuzione. Si ottiene in questo caso
il cosiddetto MFLOPS normalizzato, che differisce quindi dal MFLOPS originario (cioè quello
definito all’inizio del paragrafo). Ricordiamo che il MFLOPS, come ogni altra misura di
prestazione, è legato al programma che si sceglie di usare (per cui ha senso parlare solo di
MFLOPS per un dato programma su una data macchina) e quindi non può essere generalizzato
al fine di stabilire una singola misura di prestazione per un calcolatore.
4.7 SCELTA DI PROGRAMMI PER VALUTARE LE PRESTAZIONI
Un utente di calcolatori che usa gli stessi programmi ogni giorno potrebbe essere il candidato
perfetto per valutare un nuovo calcolatore: infatti, per valutare un nuovo sistema, egli
dovrebbe semplicemente confrontare il tempo di esecuzione del suo abituale carico di lavoro
(workload), ossia appunto dell’insieme di programmi e di comandi sul sistema operativo che usa
abitualmente. Il problema è che difficilmente si trovano utenti con una tale caratteristica di
regolarità per quanto riguarda i programmi utilizzati, per cui bisogna necessariamente far
riferimento ad altri metodi per valutare le macchine.
Esistono allora quattro “livelli” di programmi da poter usare per confrontare le prestazioni di
macchine diverse; gli elenchiamo in ordine decrescente dal punto di vista dell’accuratezza
delle predizioni che consentono di ottenere:
-
programmi reali: pur non sapendo quale frazione del tempo sarà dedicata a questi
programmi, il venditore sa comunque che alcuni utenti li useranno per risolvere i
propri problemi reali; tipici esempi di programmi reali sono i compilatori per il C, i
programmi di composizione testi oppure alcuni strumenti CAD come Spice. Una delle
caratteristiche dei programmi reali è quella di avere degli ingressi, delle uscite, e
delle opzioni che l’utente può selezionare quando tali programmi sono in funzione;
4.11
Esempi:
-
Programmi scientifici
Compilatori
Programmi per word processing (MS-WORD)
Strumenti CAD (SPICE)
Nuclei o benchmark ridotti (kernel): sono stati fatti numerosi tentativi per
circoscrivere piccoli pezzi chiave (detti appunto kernel) dei programmi reali per
valutare le prestazioni dei calcolatori (gli esempi più noti sono il Livermore Loops ed
il Linpack). Chiaramente, gli utenti generalmente non fanno girare programmi kernel
sulle proprie macchine, proprio perché questi, a differenza dei programmi reali da
cui provengono, sono pensati solo per valutare le prestazioni e non per risolvere
problemi reali. I kernel vengono utilizzati al meglio quando si vogliono isolare le
prestazioni di alcune caratteristiche specifiche di una macchina, al fine di
evidenziare le ragioni delle differenze tra le prestazioni con programmi reali;
Esempi:
-
Linpack
Livermore loops
Programmi giocattolo (Toy Benchmark): questi particolari programmi sono
tipicamente lunghi dalle 10 alle 100 linee di codice e producono un risultato che
l’utente conosce in partenza;
Esempi:
-
Quicksort
Puzzle
Algoritmi di sort
Benchmark sintetici: questi programmi sono “filosoficamente” simili ai kernel, ma
hanno la differenza di sforzarsi di accordare la frequenza media degli operandi e
delle operazioni di un vasto insieme di programmi (i più popolari benchmark sintetici
sono il Whetstone ed il Dhrystone). Così come i kernel, i benchmark sintetici non
sono usati dagli utenti proprio perché non calcolano nulla di utile per i loro problemi
reali. Tra l’altro, i benchmark sintetici sono ancora più astratti rispetto ai kernel,
dato che, mentre i kernel hanno un codice comunque estratto dai programmi reali, il
codice sintetico viene creato artificialmente per soddisfare il profilo medio di
esecuzione di cui si diceva prima.
Esempi:
Whetstone
Dhrystone
Quando sia ha disposizione un programma per la valutazione delle prestazioni di un calcolatore
e non si è sicuri del modo con cui classificarlo, il primo controllo da effettuare consiste nel
vedere se esiste un qualche ingresso al programma e/o se sono previsti dei risultati in uscita.
Ad esempio, un programma senza ingresso calcola lo stesso risultato ogni volta che viene
4.12
invocato, mentre invece alcuni programmi (tipicamente le applicazioni per l’analisi numerica e la
simulazione) usano quantità trascurabili di dati d’ingresso. In generale, ogni programma reale
ha almeno un ingresso.
Dato che i produttori di calcolatori hanno maggiore o minore successo a seconda del rapporto
prezzo/prestazioni dei loro prodotti in relazione a quello degli altri concorrenti presenti sul
mercato, sono disponibili enormi risorse per migliorare le prestazioni dei programmi più
diffusi per la valutazione. Abbiamo osservato più volte che i programmi reali possono essere
teoricamente usati per valutare le prestazioni dei calcolatori. Tra l’altro, se l’industria usasse
tali programmi, quanto meno spenderebbe le proprie risorse per migliorare le prestazioni di
ciò che realmente serve agli utenti. Viene allora da chiedersi come mai non tutti usano i
programmi reali per misurare le prestazioni. Possiamo citare le seguenti motivazioni:
-
-
i kernel ed i toy benchmark appaiono molto utili nelle fasi iniziali di un progetto, in
quanto sono abbastanza piccoli da essere simulati facilmente, al limite anche a
mano. Essi risultano particolarmente invitanti quando si inventa una nuova macchina,
dato che i compilatori potrebbero non essere subito disponibili. Inoltre, i piccoli
benchmark, a differenza dei grandi programmi, possono essere standardizzati con
maggiore facilità ed infatti si trovano in letteratura molti più risultati pubblicati
per i piccoli benchmark che non per quelli grandi;
a fronte di questi pregi, almeno al giorno d’oggi non esiste più una valida motivazione
razionale che giustifichi l’uso dei benchmark e dei kernel per valutare come
lavorano i sistemi di calcolo: in passato, i linguaggi di programmazione non erano
uniformi in macchine diverse e ogni macchina aveva il suo sistema operativo, per cui
il trasporto dei programmi reali appariva particolarmente scomodo e quindi venivano
preferiti i benchmark e/o i kernel; al giorno d’oggi, invece, la diffusione di sistemi
operativi standard, la presenza di software liberamente distribuito dalle università
e da altri enti, oltre alla disponibilità di calcolatori moderni e veloci, hanno rimosso
molti dei vecchi ostacoli, per cui l’uso di programmi reali è diventato, oltre che
opportuno al fine di ottenere risultati corretti, anche molto semplice.
4.7.1 SPEC benchmarks
Un progresso notevole nella valutazione delle prestazioni si ebbe con la formazione del gruppo
SPEC (System Performance Evaluation Cooperative) nel 1988. SPEC comprende rappresentanti
di diverse industrie informatiche che si sono accordati su un insieme di programmi reali e di
valori d’ingresso.
La versione iniziale, chiamata SPEC89, conteneva in totale 10 benchmark: sei per l’analisi in
virgola mobile e i restanti quattro per elaborazioni intere, ed il valore complessivo veniva
calcolato come media geometrica dei tempi di esecuzione normalizzati rispetto al VAX11/780, che favoriva calcolatori con migliori prestazioni sui numeri in virgola mobile.
Nella seconda versione, chiamata SPEC92, tra i benchmark utilizzati venne escluso il
matrix300, il motivo è chiaro dal seguente grafico che riporta le prestazioni relative allo
SPEC89 riportate per la IBM Powerstation 550, utilizzando due diversi compilatori.
4.13
800
700
600
500
Compilatore
400
Compilatore avanzato
300
200
100
li
eq
n
m tot
t
at
rix
30
0
fp
pp
to p
m
ca
tv
g
es cc
pr
es
so
sp
ic
e
do
du
c
na
sa
7
0
Figura 4.2 Confronto delle Prestazioni.
Sempre nella seconda versione, venne introdotto un nuovo insieme di benchmark che
comprendeva programmi nuovi e forniva valori medi separati: SPECint, che comprendeva 6
programmi, SPECfp, che ne comprendeva 14, rispettivamente per programmi interi e in virgola
mobile. Inoltre fu aggiunta la misura SPECbase, in cui si vietano versioni di ottimizzazione
adattate ai benchmark, per permettere di ottenere delle cifre più vicine alle prestazioni dei
programmi reali.
Un ulteriore modifica fu apportata con lo SPEC95, dal quale vennero eliminati alcuni
benchmark, rivelatisi errati, ed aggiunti altri. Anche il calcolatore di riferimento per la
normalizzazione venne cambiato, adottando una Sun SPARCstation 10/40, poiché iniziava ad
essere difficile reperire esemplari funzionanti di VAX 11/780. Questa versione comprendeva
18 benchmark: otto con prevalenti operazioni su interi (go, m88ksim, gcc, compress, li, ijpeg,
perl, vortex) e i restanti dieci con prevalenti operazioni in virgola mobile (tomcatv, swim,
su2cor, hydro2d, mgrid, applu, turb3d, apsi, fpppp, wave5).
I benchmark più recenti di SPEC2000 mirano a valutare le prestazioni con carichi di lavoro
che si avvicinano ad elaborazioni scientifiche di alto livello, come ad esempio i server web.
4.8 COME PORRE IN RELAZIONE LE PRESTAZIONI
Il principio fondamentale da applicare nella presentazione delle misure di prestazioni
dovrebbe essere la riproducibilità: si dovrebbero cioè annotare e fornire tutte le
informazioni che potrebbero essere utili ad un altro sperimentatore per duplicare i risultati.
Al contrario, tale principio non sempre viene applicato; per rendersene conto, basterebbe
confrontare il modo con cui vengono descritte in letteratura le prestazioni dei calcolatori ed il
modo, ad esempio, con cui vengono presentate le prestazioni automobilistiche delle riviste del
settore: tali riviste, oltre a fornire un numero elevato di misure di prestazioni (almeno 20),
elencano tutti gli accessori montati sulla macchina in prova, il tipo di pneumatici usati durante
il test, la data di tale test e molto altro; al contrario, le pubblicazioni scientifiche possono
avere solo i secondi di esecuzione, etichettati semplicemente con il nome del programma e
quello della macchina: ad esempio, si trova scritto che Spice richiede 94 sec. su una macchina
DECstation 3100. In casi come questo, si lasciano all’immaginazione del lettore gli ingressi e la
versione del programma, quella del compilatore, il livello di ottimizzazione del codice
4.14
compilato, la versione del sistema operativo, le caratteristiche hardware della macchina (ad
esempio quantità di memoria centrale, numero e tipo di dischi, versione della CPU); si nasconde
cioè tutta una serie di informazioni che invece influiscono pesantemente sull’esito delle prove.
I periodici automobilistici hanno abbastanza informazioni, circa le misurazioni, da permettere
allo stesso lettore di ripetere i risultati oppure semplicemente di mettere in relazione le
opzioni selezionate per i rilievi; al contrario, sulle riviste di calcolatori questo spesso non
avviene.
4.9 LOCALITÀ DEL RIFERIMENTO
La proprietà principale di un programma è la cosiddetta località del riferimento: essa
corrisponde al fatto che i programmi tendono a riutilizzare i dati e le istruzioni che hanno
usato di recente. Ad esempio, una regola pratica ormai ampiamente accettata e la cosiddetta
regola 90/10: essa afferma che un programma spende il 90% del suo tempo di esecuzione
solo per il 10% del suo codice. Una immediata applicazione di questo principio è che,
basandosi sul passato recente del programma, è possibile predire, con ragionevole
accuratezza, quali dati ed istruzioni il programma userà nel prossimo futuro.
La località dei riferimenti può essere applicata anche all’accesso ai dati, anche se in modo
decisamente meno regolare rispetto all’accesso alle istruzioni. Vanno distinti, in particolare,
due differenti tipi di località:
-
una località temporale afferma che gli elementi quali si è fatto riferimento di
recente saranno usati ancora nel prossimo futuro;
una località spaziale afferma invece gli elementi i cui indirizzi sono vicini ad un
dato indirizzo di riferimento tendono ad essere referenziati in tempi molto
ravvicinati.
Questi concetti sono alla base dell’uso di particolari unità di memoria ad accesso rapido
(memorie cache) (vedi capitolo 7), che consentono di migliorare le prestazioni di una macchina
rendendo più velocemente disponibili quei dati che essa vorrà utilizzare con maggiore
probabilità.
4.10 IL LAVORO DI UN PROGETTISTA DI CALCOLATORI
Il progettista di architetture di calcolatori è colui che progetta macchine per eseguire
programmi.
La realizzazione di una macchina ha, in generale, due componenti:
-
organizzazione: comprende gli aspetti di progetto di più alto livello, come il sistema
di memoria, la struttura del bus ed il progetto interno della CPU;
hardware: con questo termine ci si riferisce generalmente al progetto logico
dettagliato della macchina ed alla tecnologia con cui è stato realmente realizzato.
4.10.1 Requisiti funzionali
Un progettista di architetture di calcolatori deve effettuare il suo progetto in modo da
soddisfare gli obiettivi prefissi su tre diversi aspetti:
4.15
- requisiti funzionali;
- prezzo;
- prestazioni.
Per quanto riguarda i requisiti funzionali, può trattarsi semplicemente di caratteristiche
specifiche imposte dal mercato: ad esempio, le applicazioni software determinano come la
macchina sarà usata e quindi spesso guidano la scelta di determinati requisiti funzionali; se
una gran parte del software viene concepita per una certa architettura dell’insieme di
istruzioni, sarà tale architettura ad essere considerata quasi come predefinita dal
progettista. Una semplice considerazione, in quest’ottica, è la seguente: il fatto che la
maggior parte dei moderni sistemi operativi usino memoria virtuale e meccanismi di protezione
costituisce un requisito funzionale che il progettista dovrà garantire, fornendo un supporto
minimo a tali funzionalità, senza il quale la macchina non sarebbe nemmeno avviabile:
successivamente, ogni hardware aggiuntivo a tale soglia può essere valutato da un punto di
vista costo/prestazioni.
4.10.2 Bilancio software e hardware
Una volta stabilito un insieme di requisiti funzionali, il progettista deve cercare di ottimizzare
il progetto complessivo della macchina, sulla base di opportuni parametri. I parametri più
comuni sono senz’altro il costo e le prestazioni. Altri parametri, più specifici dei vari ambienti
di lavoro, sono ad esempio l’affidabilità e la tolleranza ai guasti.
Subentra a questo punto la questione generale della scelta se realizzare una data
caratteristica tramite l’hardware o tramite il software:
-
la realizzazione via software è facile da progettare, semplice da aggiornare e con
minore costo degli errori;
la realizzazione via hardware ha invece il grosso vantaggio di garantire migliori
prestazioni, anche se non sempre (infatti, un algoritmo realizzato via software può
essere migliore di un algoritmo mediocre realizzato in hardware), mentre invece il
costo degli errori è decisamente più alto (una cosa è modificare la riga di un
programma e ben altra cosa è riparare o sostituire integralmente un intero
circuito).
Possiamo perciò affermare che un giusto bilancio tra hardware e software conduce
sicuramente ad ottenere la macchina migliore per l’applicazione di interesse.
A questo possiamo aggiungere che, talvolta, un requisito specifico può rendere necessaria
l’introduzione di un supporto hardware. Dovendo scegliere tra due progetti, un fattore di
giudizio importante è anche la complessità di progetto. Infatti, i progetti complessi
richiedono tempo per essere completati e immessi sul mercato, il che implica che essi, per
poter essere competitivi ed attrarre gli utenti, debbano avere alte prestazioni.
In generale, risulta più semplice controllare la complessità del software che non
dell’hardware, dato che il software è più facilmente leggibile e quindi modificabile, per cui un
progettista potrebbe esplicitamente trasferire talune funzionalità dell’hardware al software.
A fronte di questo, d’altra parte, la scelta dell’architettura dell’insieme di istruzioni e la
scelta dell’organizzazione influenzano la complessità non solo dei sistemi operativi e dei
compilatori, ma anche della realizzazione della macchina.
4.16
4.10.3 Ulteriori fattori che influiscono sul progetto
Affinché una data architettura abbia successo, deve essere progettata per sopravvivere ai
mutamenti della tecnologia hardware, della tecnologia software e delle caratteristiche delle
applicazioni. Di conseguenza, il progettista deve essere sempre informato sulle tendenze
prevalenti nella tecnologia dei calcolatori e sul loro impiego, nonché sulle tecnologie
realizzative. Il progettista deve anche essere informato sulle tendenze di mercato nel
software e sul modo in cui i programmi utilizzeranno la macchina. L’ultima importante
questione che un progettista deve affrontare, una volta compresa l’influenza che le tendenze
hardware e software hanno sul progetto della macchina, riguarda il modo con cui bilanciare la
macchina. Ad esempio, bisogna decidere quanta memoria è necessario prevedere per la
velocità di CPU stabilita oppure quando I/O verrà richiesto e simili. Per rispondere a questo
tipo di domande, i progettisti Case e Amdahl hanno creato due regole approssimative, che
sono state poi riunite nella seguente regola unificata:
una macchina da 1 MIPS (milioni di istruzioni al secondo) è bilanciata quando ha 1
megabyte di memoria ed 1 megabyte al secondo come prestazione di I/O.
Questa regola è solo un punto di partenza per la progettazione di sistemi bilanciati, da
perfezionare poi tramite misure delle prestazioni della macchina quando vengono eseguite le
applicazioni previste.
4.11 LA SCELTA DEL SOFTWARE BENCHMARK PER LE NOSTRE
VALUTAZIONI
SiSoft SANDRA (System Analyzer/Diagnostic and Reporting Assistant) è un analizzatore di
sistema per Windows, in grado di eseguire diagnosi e che consente anche di valutare le
prestazioni del pc, grazie ad una nutrita serie di moduli di testing. Ci sono diversi software
che sono in grado di svolgere queste analisi, ma abbiamo scelto SANDRA per effettuare i
nostri test perché ha il vantaggio di essere gratuito e di offrire ben 50 moduli. L’unica pecca
che può essere attribuita al programma è la non compatibilità con il sistema operativo LINUX,
quindi effettueremo i nostri test solo su macchine che montano sistema operativo Windows.
Il software si presenta sotto forma di una finestra, molto simile a quella familiare di “Esplora
Risorse” di Windows, in cui sono elencati gli “Active Modules”, ossia i moduli in grado di
eseguire analisi, test e report. La difficoltà non risiede quindi tanto nell’uso (come del resto
tutti i software di questo genere), ma piuttosto nell’interpretazione dei risultati, giacché
questi programmi recuperano informazioni dettagliate su Processore e Chipset, RAM e disco
fisso, scheda grafica e audio, porte e driver di periferiche o determinano le prestazioni del
sistema, tutti dati che richiedono un’analisi curata e approfondita in modo che una volta
interpretati si possa arrivare a trovare delle soluzioni per migliorare le prestazioni della
macchina, operando non solo a livello di aggiornamento ma anche nella configurazione ottimale
di tutte le risorse disponibili.
4.17
4.11.1 Caretteristiche del Software SiSoft Sandra
Versione: SANDRA Standard 2004.SP2 9.131
Produttore: SiSoft
PRO
CONTRO
1. Gratuito per uso privato/didattico (Freeware)
2. Disponibili 50 moduli per effettuare altrettanti
test ed analisi.
1. Non compatibile con il sistema operativo
LINUX, ma soltanto per Windows.
2. Difficoltà nell’interpretazione dei dati
forniti nei risultati dei test
3. Supporto di un vasto numero di periferiche,
chipset e processori , compresa la modalità a 64 bit
dei nuovi processori AMD Athlon.
3. Nell’esecuzione di particolari test i
componenti Hardware sono molto sollecitati
e “stressati”.
SiSoftware Sandra è uno strumento di analisi per sistemi Windows 32/64 con moduli di
testing e benchmarking integrati. Il suo funzionamento è del tutto simile a quello di altre
utilità di Windows ma Sandra si prefigge di andare oltre, mostrando cosa realmente stia
accadendo ed offrendo all’utente la possibilità di creare confronti sia ad alto che basso livello.
E’ possibile ottenere informazioni su CPU, chipset, adattatori video, porte, stampanti, schede
sonore, memoria, rete, risorse di Windows, AGP (Accelerated Graphics Port=Porta di
Accelerazione Grafica: slot di espansione ad alta velocità sviluppato da Intel per permettere
ad una scheda ad alte performance grafiche di essere adattata su un PC. La porta fornisce un
bus dedicato per trasferire dati grafici tra il processore del PC e la sua memoria principale; la
porta AGP trasferisce informazioni a 528Mbytes per secondo, così è molto più veloce del
generico bus di espansione PCI che trasferisce dati a 132 Mbytes per secondo), Connettività
ODBC (Open DataBase Connectivty: software che concede ad un'applicazione di accedere a
tutta la fonte di dati compatibile; lo standard è stato sviluppato da Microsoft ma viene anche
usato da molti differenti sviluppatori come un metodo standard di fornire acceso ad una vasta
gamma di database), USB2 (Universal Serial Bus: standard che definisce un interfaccia
seriale ad ala velocità che trasferisce dati fino a 12Mbps e permette che fino a 127 unità
periferiche compatibili siano collegate ad un calcolatore; questo bus oggi è disponibile su tutti
i nuovi computer e la porta USB probabilmente sostituirà i connettori separati richiesti per
una tastiera, mouse, modem 56k e stampanti), Firewire (Interfaccia seriale ad alta velocità
sviluppata dalla Apple Computers e usata per collegare dispositivi come le fotocamere o
telecamere digitali con il computer).
I benchmark sono ottimizzati per SMP (Sistema Multi Processore: alcuni di questi sistemi
sono per esempio gli Athlon MP)/SMT (Surface Mount Technology: metodo di costruzione dei
circuiti che permette la modalità di esecuzione parallela, cioè una modalità che è stata
sviluppata per poter ottenere maggiori prestazioni dai sistemi Hyper-Threading. Tale
implementazione hardware permette l'esecuzione di più processi contemporanei migliorando
l'utilizzazione delle risorse disponibili, e ottenendo dei sistemi più veloci), nonchè per
supportare fino ad un massimo di 32/64 CPU, a seconda della piattaforma.
I resoconti di sistema creati potranno essere salvati/stampati/inviati via fax/spediti per email/posta/trasferiti su Web o inseriti all’interno di database ADO/ODBC in formato testo,
HTML (HyperText Markup Language: una serie di codici speciali di testo che vengono
normalmente usati per creare pagine web, infatti è lo standard impiegato in internet e
tradotto da tutti i browser in circolazione ), XML (Extensible Markup Language: altro tipo di
linguaggio usato per la creazione di pagine web, ma più flessibile dell’HTML), SMS/DMI o RPT.
4.18
Sistemi operativi supportati in questa versione:
Win32 x86/IA32 Version (Windows 98/Me/2000/XP/2003); Win64 AMD64/EM64T Version
(Windows x64 Edition); Win64 IA64 Version (Windows 64-bit Edition); WinCE 3.00 Arm
Pocket PC / Smart Phone 2002; WinCE 4.20 Arm Pocket PC / Smart Phone / Windows Mobile
2003; WinCE 4.21 Arm Pocket PC / Smart Phone / Windows Mobile 2003SE
I Moduli disponibili in SANDRA sono suddivisi in quattro categorie:
1. INFORMATION MODULES: forniscono preziose informazioni sui vari elementi del
sistema operativo.
2. BENCHMARKING MODULES: offrono un rapporto dettagliato sulle prestazioni
(saranno i moduli da noi maggiormente usati per i nostri test).
3. LISTING MODULES: consentono di controllare i file di sistema come “Autoexec.bat”,
“Config.sys” o il “System.ini”
4. TESTING/DIAGNOSTIC MODULES: vengono in aiuto per risalire all’origine di un
problema nel funzionamento di un componente del sistema, per verificare lo stato del
CMOS (MOS a simmetria Complementare: è un dispositivo formato dalla combinazione
di un PMOS con un NMOS che viene montato sulla scheda madre del computer),
dell’IRQ (Interrupt ReQuest: è un segnale trasmesso all'unità centrale
dell’elaboratore [CPU] temporaneamente per sospendere l'elaborazione normale e
trasferire il controllo ad una interruzione [interrupt] che sta usando la
procedura[routine])e degli handler.
4.11.2 Informazioni sul calcolatore impiegato per i test
Iniziamo i nostri test dal modulo SYSTEM SUMMARY (Informazioni sul Sistema), disponibile
nella prima categoria dei moduli (INFORMATION MODULES), in quanto dobbiamo dare una
panoramica dettagliata in modo rapido sulle principali caratteristiche del sistema in uso:
processore, frequenza, ma anche versione del BIOS, chipset (chip base della scheda madre) e
RAM (Random Access Memory: memoria ad accesso casuale, infatti permette di accedere a
qualsiasi locazione in qualsiasi ordine ) disponibile. Qui di seguito sono riportate i risultati del
test sulla macchina che abbiamo usato. Nel campo “Voce” sono elencati gli elementi analizzati,
mentre nel campo “Valore” sono riportate le relative informazioni.
4.19
VOCE
VALORE
Processore
Modello
Intel(R) Pentium(R) 4 CPU 2.00GHz
Velocità:
2.01GHz
Performance Rating (PR):
PR2206 (stimato)
Tipo:
Standard
Cache L2 On-board:
512kB ECC Sincrono ATC (8-way a settore, 64 byte dim. linea)
Mainboard
Bus:
AGP PCI IMB USB
BIOS Sistema:
Award Software, Inc. ASUS P4PE ACPI BIOS Revision 1001
Sistema:
System Manufacturer System Name
Mainboard:
ASUSTeK Computer INC. P4PE
Memoria Totale:
512MB DDR-SDRAM
Chipset 1
Modello:
ASUSTeK Computer Inc 82845PE Brookdale Host-Hub Interface
Bridge (B0-step)
Velocità Front Side Bus (FSB)
4x 100MHz (400MHz vel. dati)
Memoria Totale:
512MB DDR-SDRAM
Velocità Bus di Memoria:
2x 133MHz (266MHz vel. dati)
Sistema Video
Monitor/Pannello:
Monitor Plug and Play
Adattatore:
NVIDIA RIVA TNT2 Model 64
Unità di Memorizzazione Fisiche
Unità Rimovibile:
Unità disco floppy
Disco Rigido:
Maxtor 6Y080P0
CD-ROM/DVD:
HL-DT-ST DVD-ROM GDR8161B (CD 48X Rd) (DVD 6X Rd)
CD-ROM/DVD:
PLEXTOR CD-R PX-W2410A (CD 40X Rd, 24X Wr)
Unità di Memorizzazione Logiche
Disco Rigido (C:):
29.3GB (15.1GB, 52% Liberi) (NTFS)
Disco Rigido (D:):
47.0GB (30.3GB, 64% Liberi) (NTFS)
Sistema Operativo
Sistema Windows:
File System:
Microsoft Windows XP (Build 2600) Professional (Win32
x86/IA32) 5.01.2600
NTFS
Le informazioni che abbiamo raccolto sono di carattere generale e possono essere
successivamente approfondite tramite l’apposito modulo per ogni periferica o componente del
PC, infatti abbiamo sempre nella categoria “INFORMATION MODULES” quelli relativi ai Bus
4.20
PCI(tipo di bus locale veloce sviluppato da Intel che permettere di trasferire dati ad alta
velocità tra il processore del PC e una periferica o una scheda di espansione) e AGP
(Accelerated Graphics Port), al sottosistema Video e alla Memoria del Sistema, alle varie
unità e alle porte, alla tastiera e al mouse, alla scheda video e audio, alle stampanti, a
Windows, ai processi in corso e ai tipi di caratteri (Font) e, in ultima analisi anche alle varie
librerie (Direct X e Open GL).
4.11.3 Risultati dei Bencmark SiSoft Sandra “Aritmetica CPU” e SPEC CPU2000
I moduli messi a disposizione nella categoria “BENCHMARKING MODULES” sono i seguenti:
• Aritmetica CPU
• Multi-Media CPU
• Unità Rimovibili/Flash
• File System
• CD-ROM/DVD
• Bandwidth Memoria
• Cache & Memoria
• Bandwidth Network/LAN
• Connessione ad Internet
• Ping Internet
Qui di seguito sono riportati i risultati del Benchmark “Aritmetica CPU” ottenuti sul
calcolatore che abbiamo usato, mentre nella seconda tabella sono riportati i risultati del test
SPEC CPU2000 effettuato sempre sullo stesso tipo di calcolatore da noi impiegato.
Risultati prodotti dal Benchmark “Aritmetica CPU” di SisSoft SANDRA:
CPU
Intel Pentium 4 2.0GHz 256L2
(Win32 x86/IA32)
Drystone ALU
Whestone FPU
Whestone SSE2
5289 MIPS
1466 MFLOPS
2701 MFLOPS
Significato del valore Dhrystone ALU:
Il valore del Benchmark Dhrystone è utilizzato per misurare le "performance" della CPU nelle
operazioni ALU (con numeri interi). Nel test vengono utilizzate numerosi tipi di operazioni
usate nelle applicazioni più comuni. Purtroppo, il valore non rappresenta le prestazioni reali
della CPU, ma è indice di velocità del processore in funzione di una comparazione con altre
CPU. Comunque l'indice MIPS (Milioni di istruzioni per secondo) dovrebbe essere identico per
lo stesso sistema con variazioni del 5-10%.
Significato del valore Whetstone FPU:
Il valore del Benchmark Whetstone è utilizzato per misurare le prestazioni del calcolo in
virgola mobile impiegando l'unità FPU o il coprocessore matematico del sistema. Molti
programmi sfruttano ampiamente l'unità FPU della CPU, e la misurazione di tale quantità è
d'obbligo per un valido programma di test. Il risultato del test non è comparabile con altri
software che verificano tale quantità. Nonostante ciò, il valore in MFLOPS (Milioni di
operazioni in virgola mobile per secondo) potrebbe differenziarsi del 5-10%.
Significato del valore Whestone SSE2:
Il valore del Benchmark Whetstone è utilizzato per misurare le prestazioni del calcolo in
virgola mobile impiegando le istruzioni SSE2. Con l'introduzione di queste istruzioni è ora
possibile quantificare un valore di prestazione del sistema utilizzando tali quantità. SiSoft
4.21
Sandra 2004 sfrutta le istruzioni delle SSE2 e determina un valore di prestazione
complessivo. Il valore in MFLOPS (Milioni di operazioni in virgola mobile per secondo)
potrebbe differenziarsi del 5-10% sullo stesso sistema.
Nota sul perché si verificano variazioni nei risultati: normalmente la variazione dei risultati
dei test condotti sullo stesso PC è del +/-5%. Nei sistemi con poca memoria tale valore
potrebbe salire al +/-10%; ciò è dovuto all'operazione di "Swapping" (in pratica il sistema
operativo utilizza il disco rigido per memorizzare dei dati poichè la memoria disponibile è
insufficiente), che rallenta non di poco l'esecuzione del Benchmark.
Risultati prodotti dal Benchmark CPU2000 di SPEC:
Risultato
Baseline
755
749
Processore
Intel Pentium 4
Processor (2.0A
GHz,400 MHz bus)
Processore
2000 MHz
Memoria RAM
512 MB (2 256 MB
PC1066-32 RDRAM
non-ECC modules)
Sist. Operativo
Windows XP
Professional
(Build 2600)
CINT2000 Result
Copyright © 1999-2002 Standard Performance Evaluation Corporation
Intel Corporation
Intel Pentium 2.0A GHz
Benchmark
SPECint2000 =
755
SPECint_base2000 =749
Base
Reference Base
Time Runtime Ratio Runtime Ratio
164.gzip
1400
177
790
177
793
175.vpr
1400
286
489
306
458
176.gcc
1100
125
878
125
877
181.mcf
1800
314
573
314
573
186.crafty
1000
134
747
132
755
197.parser
1800
251
718
251
718
252.eon
1300
147
882
127
1023
253.perlbmk 1800
208
867
208
866
1100
114
963
113
972
255.vortex 1900
155
1224
155
1224
256.bzip2
1500
252
595
253
594
300.twolf
3000
540
556
539
556
254.gap
SPECint_base2000
749
SPECint2000
755
4.22
4.12 Descrizione di SPEC CPU2000
Spec. CPU2000 è la suite benchmark industria-standardizzato next-generation di CPUintensive. In generale, spec. ha progettato spec. CPU2000 per fornire una misura comparativa
delle prestazioni intense di calcolo attraverso la più larga gamma di hardware. Perciò Spec ha
corredato i benchmarks di codice sorgente sviluppato dalle applicazioni reali dell'utente.
Questi benchmarks dipendono dal processore dalla memoria e dal compilatore sul sistema
esaminato.
4.12.1 Che cosa è “SPEC”
Spec. è una sigla che significa Standard Performance Evaluation Corporation. Spec. è
un'organizzazione senza scopo di lucro composta da fornitori di calcolatori, da integratori dei
sistemi, da università, da organismi di ricerca, da editori e da consulenti il cui obiettivo è
quello di stabilire, effettuare e firmare un insieme standardizzato dei benchmarks relativi ai
sistemi di elaborazione. Anche se nessun insieme delle prove può completamente
caratterizzare le prestazioni del sistema generale, spec. crede che l'associazione di utenti
tragga beneficio da una serie obiettiva di prove che possono servire come punto di
riferimento comune.
Che cosa misura spec. CPU2000
Spec. CPU2000 si focalizza sulle prestazioni intense di calcolo, ciò significa che questi
benchmarks danno risalto alle prestazioni di:
• il processore del calcolatore (CPU)
• l'architettura di memoria
• i compilatori.
È importante ricordarsi del contributo dei due componenti posteriori anche se le prestazioni
dipendono appena un pò più dal processore.
Spec. CPU2000 si compone di due subcomponenti che si concentrano su due tipi differenti di
prestazioni intense di calcolo:
• CINT2000 per la misurazione e il confronto delle prestazioni comput-intense di
numero intero
• CFP2000 per la misurazione e il confronto delle prestazioni comput-intense della
virgola mobile.
Si noti che spec. CPU2000 non sollecita altri componenti del calcolatore quali I/O (driver del
disco), rete, il sistema operativo o i grafici. Potrebbe essere possibile configurare un sistema
in modo tale che uno o più di questi componenti ha effetto sulle prestazioni di CINT2000 e di
CFP2000, ma questo non è intenzione della suites CPU 2000
A che cosa corrisponde la “C" in CINT2000 ed in CFP2000?
La “C" denota che questi sono benchmark del componente-livello in contrasto con i benchmark
interi del sistema.
Perchè si usa spec. CPU2000
Come detto precedentemente, spec. CPU2000 fornisce una misura comparativa delle
prestazioni intense di calcolo della virgola mobile e/o di numero intero. Se questo è combinato
con il tipo di quote di lavoro a cui siamo interessati, spec. CPU2000 fornisce un buon punto di
riferimento. Altri vantaggi nell’usare spec. CPU2000 sono:
4.23
•
•
•
•
•
I programmi di benchmark sono sviluppati dalle applicazioni reali dell'utilizzatore
finale in contrasto con l’essere benchmarks sintetici.
I fornitori multipli usano la suite SPEC e la sostengono.
Spec. CPU2000 è altamente portatile.
Una vasta gamma dei risultati è disponibile all’indirizzo web http://www.spec.org
I benchmarks sono richiesti per essere fatti funzionare e secondo per segnalare un
insieme di regole per accertare la comparabilità e la ripetibilità.
Quali sono le limitazioni di spec. CPU2000
Il benchmark ideale per la selezione del prodotto o del fornitore sarebbe la vostra propria
quota di lavoro sulla vostra propria applicazione. Quindi bisogna considerare che nessun
benchmark standardizzato può fornire un modello perfetto delle realtà dei vostri sistemi ed
associazione di utenti particolari.
Che cosa è incluso nel pacchetto di spec. CPU2000
Spec. fornisce quanto segue sulla suite di spec. CPU2000:
•
•
•
•
•
•
Codice sorgente per i benchmarks CINT2000
Codice sorgente per i benchmarks CFP2000
Un tool per la compilazione, il funzionamento, la convalidazione e la segnalazione sui
benchmarks
Tools Pre-compilati per una varietà di sistemi operativi.
Codice sorgente per i tools di spec. CPU2000, per i sistemi non coperti dai tools precompilati
Documentazione varia, tra cui dettagli sulle funzioni e le regole che definiscono come i
benchmarks dovrebbero essere usati per fornire i risultati di spec. CPU2000.
Che cosa l'utente della suite di spec. CPU2000 deve avere (Requisiti di Sistema)
Brevemente, avete bisogno di un sistema NT o UNIX con 256MB di memoria, almeno 1GB di
disco e un insieme di compilatori poiché spec. fornisce soltanto il codice sorgente per i
benchmarcks, quindi avrete bisogno di un insieme di compilatori per il risultato che intendete
misurare:
1. Per SPECint2000: sia compilatore C e C++
2. For SPECfp2000: sia compilatore C e Fortran-90
Quale codice sorgente viene fornito? Quali sono esattamente i componenti di questa
suites?
CINT2000 e CFP2000 sono basati sulle applicazioni comput-intense fornite come codice
sorgente. CINT2000 contiene undici applicazioni scritte in C ed in 1 in C++ (252.eon) che sono
usati come benchmarks:
4.24
Nome
164.gzip
175.vpr
176.gcc
181.mcf
186.crafty
197.parser
252.eon
253.perlbmk
254.gap
255.vortex
256.bzip2
300.twolf
Ref Time
1400
1400
1100
1800
1000
1800
1300
1800
1100
1900
1500
3000
Descrizione
Programma di utilità di compressione di dati
Disposizione e percorso del circuito di FPGA
Compilatore di C
Solver minimo di flusso della rete di costo
Programma di scacchi
Elaborazione di linguaggio naturale
Tracciato del raggio
Perl
Teoria di calcolo del gruppo
Base di dati orientata oggettivamente
Programma di utilità di compressione di dati
Dispone e dirige il simulatore
CFP2000 contiene 14 applicazioni (6 Fortran-77, 4 Fortran-90 e 4 C) che sono usati come
benchmarks:
Nome
168.wupwise
171.swim
172.mgrid
173.applu
177.mesa
178.galgel
179.art
183.equake
187.facerec
188.ammp
189.lucas
191.fma3d
200.sixtrack
Ref Time
1600
3100
1800
2100
1400
2900
2600
1300
1900
2200
2000
2100
1100
Descrizione
Chromodynamics di Quantum
Modellistica poco profonda dell'acqua
Solver multi-grid nel campo di potenziale 3D
Equazioni differenziali parziali di Parabolic/elliptic
Biblioteca dei grafici 3D
Dynamics fluido: analisi di instabilità oscillatoria
Simulazione della rete neurale: teoria adattabile di risonanza
Simulazione limitata dell'elemento: modellistica di terremoto
Dispositivo ottico del computer: riconosce le facce
Chimica di calcolo
Teoria di numero: prova di primality
Simulazione di arresto del Limitato-elemento
Modello dell'acceleratore della particella
301.apsi
2600
Solves problems regarding temperature, wind, etc.
Sia i numeri usati come componente dei benchmarks che i nomi forniscono un contrassegno
come aiuto per distinguere i programmi l'uno dall'altro. Per esempio, alcuni programmi erano
aggiornati da spec. CPU95 e devono essere distinti dalla loro versione precedente.
Quale metrica può essere misurata
La suites CINT2000 e CFP2000 possono essere usati per misurare e calcolare la seguente
metrica:
CINT2000 (per i confronti di prestazioni intense di calcolo di numero intero):
• SPECint2000: La media geometrica di dodici ha normalizzato i rapporti (uno per ogni
benchmark di numero intero) una volta compilata con ottimizzazione aggressiva per
ogni benchmark.
• SPECint_base2000: La media geometrica di dodici ha normalizzato i rapporti una volta
compilata con ottimizzazione conservatrice per ogni benchmark.
• SPECint_rate2000: La media geometrica di dodici ha normalizzato i rapporti di
rendimento una volta compilata con ottimizzazione aggressiva per ogni benchmark.
4.25
SPECint_rate_base2000: La media geometrica di dodici ha normalizzato i rapporti di
rendimento una volta compilata con ottimizzazione conservatrice per ogni benchmark.
CFP2000 (per i confronti di prestazioni intense di calcolo della virgola mobile):
• SPECfp2000: La media geometrica di quattordici ha normalizzato i rapporti (uno per
ogni benchmark della virgola mobile) una volta compilata con ottimizzazione aggressiva
per ogni benchmark.
• SPECfp_base2000: La media geometrica di quattordici ha normalizzato i rapporti una
volta compilata con ottimizzazione conservatrice per ogni benchmark.
• SPECfp_rate2000: La media geometrica di quattordici ha normalizzato i rapporti di
rendimento una volta compilata con ottimizzazione aggressiva per ogni benchmark.
• SPECfp_rate_base2000: La media geometrica di quattordici ha normalizzato i
rapporti di rendimento una volta compilata con ottimizzazione conservatrice per ogni
benchmark.
Il rapporto per ciascuno dei benchmarks è calcolato usando un tempo di riferimento
determinato spec. ed il tempo di esecuzione del benchmark.
Un più alto segno significa "le prestazioni migliori" sulla data quota di lavoro.
•
Quale è la differenza fra metrica "base" e metrica “peak”
Per fornire i confronti attraverso hardware di calcolatori differenti, spec. fornisce i
benchmarks come codice sorgente. Quindi, per fare funzionare i benchmarks, devono essere
compilati. Ci è accordo che i benchmarks dovrebbero essere compilati in senso che gli utenti
compilano
i
programmi.
Ma
come
compilano
i
programmi
gli
utenti?
Da un lato, la gente potrebbe compilare appena con le opzioni ad alto rendimento generali
suggerite dal fornitore del compilatore. Dall'altro lato, la gente potrebbe sperimentare con
molti compilatori e flags (bandierine) differenti del compilatore per realizzare le prestazioni
migliori. Così, mentre spec. non può sapere esattamente come tutti usano i compilatori, può
però fornire la metrica che rappresenta le caratteristiche generali di questi due gruppi.,
quindi sono possibili due punti di riferimento:
• La metrica “base”[bassa] (per esempio SPECint_base2000).
• La metrica “peak”[picco](per esempio SPECint2000) è facoltativa ed ha requisiti meno
rigorosi.
Quale è la differenza fra metrica "rate" e "speed"?
Ci sono vari differenti modi di misurare le prestazioni dell'elaboratore. Il “one-way” deve
misurare quanto velocemente il calcolatore completa una singola operazione; ciò è una misura
di velocità. Un altro metodo è quello che deve misurare quante mansioni un calcolatore può
compire in un determinato tempo; ciò è denominata una misura di rendimento, di capienza o di
tasso.
• La metrica di velocità di spec. (per esempio, SPECint2000) è usata per confrontare
l'abilità di un calcolatore per completare le singole mansioni.
• La metrica di tasso di spec. (per esempio, SPECint_rate2000) misura il rendimento o il
tasso di una macchina che effettua un certo numero di mansioni. Tradizionalmente, la
metrica di tasso è stata usata per dimostrare le prestazioni dei sistemi del
multiprocessore.
Per la metrica di tasso, le copie multiple dei benchmarks sono fatte funzionare
simultaneamente. Tipicamente, il numero di copie è lo stesso del numero di CPU sulla macchina,
ma questo non è un requisito. Per esempio, sarebbe perfettamente accettabile fare
4.26
funzionare 63 copie dei benchmarks su una macchina 64-CPU (quindi che lascia una CPU libera
di gestire le spese generali del sistema).
Quale metrica dovrebbe essere usata per confrontare le prestazioni in spec. CPU2000
Dipende dai vostri bisogni. Spec. fornisce i benchmarks ed i risultati come tools per il vostro
uso. Dovete determinare come utilizzate un calcolatore o quali sono i vostri requisiti di
prestazioni ed allora scegliere il benchmark adatto o la metrica di spec..
Un monoutente che fa funzionare un programma comput-intenso di numero intero, per
esempio, potrebbe soltanto essere interessato in SPECint2000 o in SPECint_base2000.
D'altra parte, una persona che gestisce una macchina usata da un certo numero di scienziati
che fanno funzionare le simulazioni della virgola mobile potrebbe di più preoccuparsi di
SPECfp_rate2000 o di SPECfp_rate_base2000.
Perchè si è sviluppato spec. CPU2000 e quali sono le differenze da spec. CPU95
La tecnologia sta migliorando sempre. Mentre la tecnologia migliora, anche i benchmark
dovrebbero migliorare. Spec. ha dovuto migliorare le seguenti caratteristiche rispetto a
CPU95:
• Tempo di esecuzione: vari dei benchmarks CPU95 stavano rifinendo in meno che un
minuto su processors/systems marginale. Dato che gli attrezzi di misura di spec., i
piccoli cambiamenti o fluttuazioni nelle misure stavano avendo effetti significativi sulla
percentuale dei miglioramenti che si sono visti. Spec. ha scelto di rendere i tempi di
esecuzione per i benchmarks CPU2000 più lunghi per considerare le prestazioni future
e per impedire che questo possa essere un errore per il corso della vita della suites.
• Formato di applicazione:molte osservazioni ricevute da SPEC hanno indicato che le
applicazioni si erano sviluppate nella complessità e nel formato e che CPU95 stava
diventando meno rappresentativo di ciò che funziona sui sistemi correnti. Per
CPU2000, spec. ha selezionato i programmi con i più grandi requisiti di risorse per
fornire una miscela ad alcuni dei più piccoli programmi.
• Tipo di applicazione:spec. ha ritenuto che cerano campi di applicazione supplementari
che dovrebbero essere inclusi in CPU2000 per aumentare la varietà e la
rappresentazione all'interno della suites. Le zone quali 3D e il riconoscimento di
immagine sono state aggiunte e la compressione di dati è stata espansa.
Ha un senso tradurre i risultati di spec. CPU95 ai risultati di spec. CPU2000 o
viceversa?
Non c’è formula per convertire i risultati CPU95 ai risultati CPU2000 e viceversa; sono
prodotti differenti. Ci sarà probabilmente una certa correlazione dei risultati fra CPU95 e
CPU2000 (cioè, le macchine con i risultati più elevati CPU95 avranno spesso risultati più
elevati CPU2000), ma non c’è formula universale per tutti i sistemi.
4.13 OSSERVAZIONE SUI RISULTATI OTTENUTI DAI TEST SPEC
CPU2000 E SISOFT SANDRA “ARITMETICA CPU”
Molti dei benchmarks di spec. sono stati derivati da programmi di applicazioni pubblicamente
disponibili e tutti sono stati sviluppati per essere portatili su piattaforme hardware attuali e
future. Le dipendenze hardware sono state minimizzate per evitare di favorire una
piattaforma hardware rispetto ad un altra. Per questo motivo, i programmi di applicazione in
4.27
questa distribuzione non dovrebbero essere usati per valutare le prestazioni probabili delle
versioni disponibili in commercio. I diversi benchmarks della suite Spec CPU2000 possono
essere simili, ma non identici ai benchmarks o ai programmi con lo stesso nome che sono
disponibili da altre fonti come il benchmark “Aritmetica CPU” di SiSoft Sandra ; quindi, è non
valido paragonare i risultati del benchmark di spec. CPU2000 a qualche cosa tranne ad altri
risultati del benchmark di spec. CPU2000. (Nota: ciò inoltre significa che non è valido
confrontare i risultati di spec. CPU2000 ai più vecchi benchmarks del CPU di spec.; questi
benchmarks sono stati cambiati e dovrebbero essere considerati differente e non
paragonabile.)
Riferimenti bibliografici
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Sito www.spec.org;
[3] F. Tortorella, "Corso di Calcolatori Elettronici", Università degli studi di Cassino,
Link: webuser.unicas.it/tortorella/
4.28
LEZIONE 5
Valutazione delle prestazioni (parte seconda)
5.1 INTRODUZIONE
Le prestazioni di un sistema di elaborazione sono uno dei parametri fondamentali nella scelta
di una macchina. Per questo motivo, non basta misurare la velocità con cui un’applicazione viene
svolta su di essa, ma bisogna scegliere fra varie metriche di misura quelle più significative a
seconda del lavoro che vogliamo compiere.
A tale fine è utile stimare il carico di lavoro (workload ossia l’insieme dei programmi eseguiti),
svolto sulla nostra macchina e compararne il tempo di esecuzione su più calcolatori. Non
sempre questa operazione è possibile, si ricorre perciò a dei programmi campione (benchmark)
che rappresentino bene i diversi possibili usi del computer. I benchmark differiscono a
seconda delle particolari esigenze dell’utente: ad esempio, possono riguardare applicazioni
tipiche del campo ingegneristico o scientifico oppure database, e-commerce o altri domini
applicativi. I risultati forniti dal benchmark possono essere di natura diversa: si tratta di
valori assoluti (come, ad esempio, il numero di fotogrammi al secondo per un programma di
visualizzazione filmati oppure le milioni di operazioni eseguite in un secondo) oppure relativi
(dato ad un sistema di riferimento il valore pari a 1, il benchmark indica valori a quest’ultimo
riferiti: una performance di 2, ad esempio, indica prestazioni doppie rispetto alla macchina di
riferimento).
I benchmark possono essere suddivisi in due grandi categorie:
• benchmark applicativi: si tratta di applicazioni che riproducono reali situazioni di
utilizzo del computer. Il venditore, pur non sapendo quale frazione del tempo verrà
dedicato a questi programmi, sa però che alcuni utenti li useranno per risolvere
problemi reali. Spesso sono raggruppati in suite, per esempio SPEC95.
• benchmark sintetici: sono dei particolari software, che tentano di modellare
programmi reali, e permettono, con i propri test, di meglio analizzare specifiche
caratteristiche di un prodotto, mettendo "sotto stress" tutte le varie componenti
del calcolatore, e, quindi, di studiarne l'architettura e l'efficacia.
5.2 BENCHMARK SINTETICI: VANTAGGI E SVANTAGGI
Sono stati ideati come modelli di applicazioni reali e possono essere mediamente vicini al
contenuto statistico dei programmi modellati in termini di istruzioni, in quanto cercano di
simulare la frequenza media degli operandi e delle operazioni utilizzati in essi. Come indica il
loro nome, il loro pregio principale è la sinteticità che comporta una semplicità di
computazione. Nella figura 5.2 e 5.3 sono mostrati due esempi di benchmark sintetici.
Un limite dei benchmark sintetici è dato dal fatto che, non conoscendo il codice sorgente dei
programmi reali, non conosciamo neanche la effettiva sequenza con la quale le istruzioni
vengono eseguite. Ciò comporta che gli accessi alla memoria del benchmark non rispecchiano
quelli del software modellato. Nell’esempio, rappresentato in figura 5.1, è evidenziato che:
• in termini statistici il contenuto del benchmark modella correttamente il software (le
istruzioni ADD e LW sono utilizzate nelle medesime proporzioni in B e in S;
• in B ad ogni LW (load word – caricamento) la memoria ha un tempo di risposta
sufficiente per rendersi disponibile alla successiva operazione ADD;
• in S, invece, le modalità di accesso alla memoria sono diverse.
5.1
BENCHMARK B
SOFTWARE S
ADD
LW
ADD
LW
ADD
ADD
MEM
………
Tempo di
Risposta
ADD
MEM
LW
MEM
LW
Tempo di
Risposta
…….
LW
Tempo di
Risposta
Figura 5.1: Modellazione del software in un benchmark.
X=1.0
Y=1.0
Z=1.0
DO 88 I=1,N,1
CALL P3(X,Y,Z)
88 CONTINUE
SUBROUTINE P3(X,Y,Z)
COMMON T,TT1,T2
X1=X
Y1=Y
X1=T*(X1-Y1)
Y1=T*(X1+Y1)
Z=(X1+Y1)/T2
RETURN
Figura 5.2: Esempio di benchmark sintetico:il benchmark whetstone.
Fu sviluppato nel 1976 da CURNOW e WICHMANN del National Physical Laboratory in Inghilterra. Questo
benchmark cerca di misurare la velocità e l’efficienza con cui un calcolatore esegue le operazioni in virgola
mobile. Il risultato di tale prova viene dato in whetstone, definita come l’istruzione “media” su virgola
mobile (dove l’attributo media è da considerarsi in termini statistici).
5.2
LOAD/STORE
BRANCHES
FIXED ADD/SUB
COMPARE
FLT ADD/SUB
FLT MUL
31.2%
16.6%
6.1%
3.8%
6.9%
3.8%
FLT DIV
FIXED MULT
FIXED DIV
SHIFTS
LOGICAL
1.5%
0.6%
0.2%
4.4%
1.6%
Figura 5.3 Instruction-mix benchmark: gibson mix.
Per Instruction-Mix si intende la misura della frequenza relative delle istruzioni in un calcolatore all’interno
di diversi programmi. Qui sopra è riportato l’esempio del Gibson Mix, sviluppato da Jack C.Gibson nel 1959
per i sistemi 1BM 704. Nonostante tali valori risalgano a quasi 50 anni fa, possono essere considerati
ancora validi.
I benchmark, quindi, in quanto programmi campione, non rispecchiano fedelmente il
comportamento dei programmi reali e, poiché sono costituiti da un insieme particolare di
istruzioni, sono programmi molto scarsamente utilizzati dall’utente ai fini pratici. Spesso i
programmatori studiano delle cosiddette ottimizzazioni ‘ad hoc’, relative ad un solo specifico
software, e può accadere che tali tecniche di miglioramento non siano applicabili anche ad
altri programmi se pur simili. I benchmark, in quanto non programmi reali, risulterebbero
essere immuni da tali ‘trucchi’, ma solo ‘in teoria’. Infatti per migliorare le prestazioni di un
benchmark, è comunque possibile effettuare ottimizzazioni del compilatore e dell’hardware
che naturalmente non garantiscono i medesimi risultati su programmi reali. Per evitare questo
problema ed avere una visione più chiara delle potenzialità della macchina che stiamo
analizzando, ad esempio, gli autori del benchmark Dhrystone (insieme a Whetstone, uno dei
più popolari benchmark sintetici) richiedono che siano riportati i risultati ottenuti sul codice
ottimizzato e su quello non ottimizzato.
5.3 SPEC
L’insieme di benchmark più popolare è le serie SPEC (System Performance Evaluation
Cooperative) nato nel 1989 per volontà di Apollo/Hewlett-Packard, DEC, MIPS e Sun, col fine
di migliorare la misurazione delle prestazioni utilizzando processi di misure più controllate e
benchmark più realistici. Consideriamo lo SPEC95; esso consta di 18 programmi: 8 relativi
all’elaborazione su interi, scritti in linguaggio C, ed i restanti 10 dedicati all’elaborazione su
virgola mobile, scritti in FORTRAN (vedi tabella 5.1)
5.3
BENCHMARK
go
m88skim
gcc
compress
li
jpeg
perl
vortex
tomcatv
swim
su2cor
hydor2
mgrid
applu
turb3d
aspi
fpppp
wave5
SPEC95 – ELABORAZIONE SU INTERI
DESCRIZIONE
Intelligenza artificiale: gioco del Go
Simulatore del chip Motorola 88k; esecuzione di un programma
Compilatore GNU C che genera codice SPARC
Compressione e decompressione di un file in memoria
Interprete LISP
Compressione e decompressione di immagini grafiche
Interprete del linguaggio PERL
Programma di gestione di una base di dati
SPEC95 – ELABORAZIONE SU VIRGOLA MOBILE
Programma per la generazione di griglie
Modello per acqua poco profonda con una griglia 513x513
Fisica quantistica: simulazione Monte Carlo
Astrofisica: equazioni idrodinamiche di Naiver Stokes
Risolutore multi-griglia in campo di potenziale 3D
Equazioni alle differenze parziali paraboliche/ellittiche
Simulazione di turbolenza isotropica e omogenea in un cubo
Risoluzione di problemi di temperatura, velocità del vento
Chimica quantistica
Fisica dei plasmi: simulazione di particelle elettromagnetiche
Tabella 5.1 I benchmark di CPU SPEC95
Come analisi delle prestazioni viene utilizzato l’indice SPEC (SPEC RATIO)
⎛ n Tref , k
⎜
INDICE SPEC = ⎜ ∏ T
⎝ k =1 new , k
⎞
⎟
⎟
⎠
1
n
dove:
n è il numero di SPEC benchmark eseguiti,
Tref , k è il tempo di esecuzione del k-esimo SPEC benchmark misurato sulla macchina di
riferimento, una Sun SPARCstation 10/40,
Tnew, k è il tempo di esecuzione del k-esimo SPEC benchmark sulla macchina in valutazione.
Tale normalizzazione fa sì che a valori maggiori dell’indice corrispondano prestazioni migliori.
Le misure si distinguono in SPECint95 e SPECfp95 a seconda che si considerino nel calcolo
benchmark su interi o benchmark su virgola mobile.
L’ultima versione della serie SPEC è la suite SPEC CPU2000 che è composta da 12 programmi
per l’elaborazione su interi e 14 per l’elaborazione su virgola mobile (vedi tabella 5.2).
5.4
SPEC2000 – ELABORAZIONE SU INTERI
NOME
gzip
DESCRIZIONE
Compressione
SPEC2000- ELABORAZIONE IN FP
NOME
wupwise
DESCRIZIONE
Quantum chromodynamics
vpr
FPGA circuit placement and routing
swim
gcc
Compilatore GNU C
mgrid
mcf
Ottimizzazione combinatoria
applu
crafty
Gioco degli scacchi
mesa
Risolutore multi-griglia in campo di potenziale
3D
Equazioni alle differenze parziali
paraboliche/ellittiche
Three-dimensional graphics library
parser
Word processing program
galgel
Dinamica dei fluidi
eon
Computer visualization
art
Modello per acqua poco profonda
Image recognition usando reti neurali
gap
Group theory, interpreter
facerec
Simulazione della propagazione delle onde
sismiche
Image recognition of faces
vortex
Object-oriented database
ammp
Chimica computazionale
bzip2
Compressione
lucas
perlbmk
twolf
Applicazione del linguaggio Perl
equake
Place and rote simulator
fma3d
sixtrack
apsi
Test di primalità
Simulazione di crash usandoil metodo degli
elementi finiti
High-energy nuclear physics accelerator design
Meteorologia: pollutant distribution
Tabella 5.2 I benchmark di SPEC CPU2000
Per l’analisi delle prestazioni utilizziamo, anche in questo caso, l’indice SPEC RATIO in cui il
tempo di esecuzione misurato sulla macchina in considerazione è normalizzato dal tempo di
esecuzione su una Sun Ultra 5_10 con un processore di 300 MHz. Gli analoghi degli indici
SPECint95 e SPECfp95 sono rispettivamente CINT2000 e CFP2000. Per mostrare i
miglioramenti delle performance consideriamo la figura 5.4 dove vengono analizzate le misure
relative agli SPEC CINT2000 e SPEC CFP2000 dei processori Intel Pentium 4 e Intel Pentium
III utilizzando un computer Dell Precision.
Figura 5.4: Influenza dei fattori dell’equazione delle prestazioni su CINT2000 E CFP2000.
Notiamo che per entrambi i processori le performance crescono linearmente con la frequenza di clock. In
generale le prestazioni del Pentium 4 sono migliori di quelle del Pentium III però nel primo i CFP2000 hanno
prestazioni superiori del CINT2000, viceversa nel secondo. Ciò è dovuto ad una tecnologia di costruzione
superiore usata per il Pentium 4 per il floating point.
5.5
5.4 ESPRESSIVITÀ DELLE METRICHE
Al fine di confrontare più sistemi è utile avvalersi di un unico valore che ne esprima in modo
sintetico le prestazioni. Ci sono più modi per fare ciò. Una prima idea fa riferimento al tempo
totale di esecuzione di due o più programmi su due diverse macchine (chiamiamole A e B).
PA =
1
TA
PB =
1
TB
dove:
PA indica le prestazioni della macchina A,
PB indica le prestazioni della macchina B,
TA è il tempo totale di esecuzione sulla macchina A,
TB è il tempo totale di esecuzione sulla macchina B.
Se TB p TA Î
PA p P B
quindi B è migliore di A in termini di prestazioni.
Adesso confrontiamo le due prestazioni relative calcolando lo speed-up di B rispetto ad A
( S AB ).
S AB =
PB
PA
che ci dice di quanto B è più veloce rispetto ad A.
5.4.1 IDEA 1 – AMT
Un metodo alternativo consiste nel calcolare la media aritmetica dei tempi (AMT –
Arithmetic Mean Time) cosi’ definita
n
AMTCPU = ⋅ ∑TCPU , K
1
n
K =1
dove:
n è il numero dei programmi benchmark,
TCPU , K è il tempo di esecuzione del K-esimo programma.
Questo tipo di approccio è utile in quanto l’AMT è direttamente proporzionale al tempo di
esecuzione ed in oltre definendo
P=
1
AMTCPU
otteniamo una misura immediata delle prestazioni. Valori piu’ bassi di AMT comportano valori
maggiori di P, quindi prestazioni migliori.
5.6
5.4.2 IDEA 2 – WMT
Il precedente metodo (AMT) è attuabile solo quando gli n programmi hanno tempi di
esecuzione confrontabili. Se ciò non avviene si allungano artificialmente i tempi di esecuzione
(cioè ripetendo wK volte il K-esimo programma) fin quando non sono paragonabili. In questo
caso si può ricorrere alla media pesata dei tempi (WMT – Weighted Mean Time)
WMT CPU
1 n
= ⋅ ∑ (w K ⋅ TCPU , K )
n K =1
dove:
n è il numero dei programmi benchmark,
TCPU , K è il tempo di esecuzione del K-esimo programma,
wK
è il peso dato al K-esimo programma ed indica la frequenza relativa di esso entro il
workload (cioè il numero di volte che è eseguito).
5.4.3 IDEA 3 - HMT
Nel caso in cui le prestazioni siano espresse come un rapporto, il tempo totale di esecuzione è
definito tramite la media armonica dei tempi (HMT – Harmonic Mean Time).
HMT CPU
⎛1 n
1
= ⎜ ⋅∑
⎜ n K =1 T
CPU , K
⎝
⎞
⎟
⎟
⎠
−1
dove:
n è il numero dei programmi benchmark,
TCPU , K è il tempo di esecuzione del K-esimo programma.
Utilizzando opportuni sistemi di pesi è possibile definire la media armonica pesata dei tempi
WHMT CPU
⎛ 1 n wK
= ⎜⎜ ⋅ ∑
⎝ n K =1 TCPU , K
⎞
⎟
⎟
⎠
−1
Per quanto riguarda le medie armoniche, esse hanno la caratteristica di enfatizzare i
programmi con minor tempo di esecuzione.
5.4.4 IDEA 4 – GMT
Se le metriche fin qui esposte non soddisfano le nostre necessità, un ulteriore metodo è la
media geometrica dei tempi (GMT – Geometric Mean Time)
5.7
⎛
⎞
GMTCPU = ⎜⎜ ∏ TCPU , K ⎟⎟
⎝ K =1
⎠
n
1
n
Questa metrica enfatizza i programmi con grosse variazioni di prestazioni.
La media geometrica gode della proprietà di essere indipendente dalla serie di dati usata per
la normalizzazione, in quanto
GMT ( X )
⎛X⎞
= GMT ⎜ ⎟
GMT (Y )
⎝Y ⎠
LA MEDIA GEOMETRICA DEI RAPPORTI È UGUALE AL RAPPORTO DELLE MEDIE GEOMETRICHE
5.4.5 IDEA 5 - GMTR
Se vogliamo esporre le prestazioni di una macchina, è significativo normalizzare il tempo di
esecuzione rispetto ad una macchina di riferimento (come abbiamo visto per l’indice SPEC) e
quindi calcolare la media geometrica dei tempi normalizzati (GMTR – Geometric Mean Time
Ratio).
1 n
GMTRCPU
⎛ n T
= ⎜ ∏ CPU , K
⎜ K =1 T
CPU , REF , K
⎝
⎛ n
⎞
⎜⎜ ∏ TCPU , K ⎟⎟
⎝ K =1
⎠
1 n
⎞
⎟
⎟
⎠
=
1 n
⎛
⎞
⎜⎜ ∏ TCPU , REF , K ⎟⎟
⎝ K =1
⎠
n
=
GMTCPU
GMTCPU , REF
dove:
n è il numero dei programmi benchmark,
TCPU , K è il tempo di esecuzione del K-esimo programma,
TCPU , REF , K
è il tempo di esecuzione del K-esimo programma sulla macchina di riferimento
rispetto alla quale si aspetta la normalizzazione,
GMTCPU è la media geometrica dei tempi di esecuzione,
GMTCPU , REF è la media geometrica dei tempi di esecuzione sulla macchina di riferimento.
I vantaggi e gli svantaggi di queste metriche saranno trattati in modo più approfondito nella
successiva lezione 6.
5.8
5.5 SCALABILITÀ
Consideriamo l’equazione delle prestazioni:
TCPU = C CPU ⋅ TC =
C CPU
= N CPU ⋅ CPI ⋅ TC
fC
dove:
TC è il periodo di clock,
CCPU è il numero dei cicli di clock,
N CPU è il numero di istruzioni eseguite dinamicamente,
CPI è il numero medio di cicli di clock per istruzione.
Come abbiamo già visto le prestazioni di un sistema sono inversamente proporzionali al tempo
di esecuzione del carico di lavoro.
P∝
Se
1
TCPU
=
1
⋅ fC
N CPU ⋅ CPI
f C raddoppia ci aspetteremmo che anche le prestazioni raddoppino, ma in realtà ciò non
avviene. Osservando la figura 5.4 possiamo riscontrare che l’incremento delle prestazioni è
sempre minore al corrispondente aumento della frequenza di clock, ciò è dovuto al fatto che la
memoria principale non riesce a tenere il passo del processore.
Si definisce scalabilità rispetto ad un parametro la “capacità di fornire maggiori prestazioni
al variare di un parametro”.
Consideriamo, ad esempio, due grandezze y1 e y2 e supponiamo di voler confrontare la loro
scalabilità rispetto al parametro x (vedi figura 5.5). Ad una medesima variazione Δx del
parametro x, le grandezze y1 e y2 si comportano in modo differente: y1 subisce una variazione
Δy1 mentre y2 subisce una variazione Δy2. Poiché Δy1 > Δy2, la grandezza y1 è più
scalabile rispetto al parametro x della grandezza y2.
Tabella 5.3: Confronto fra Pentium III e Pentium 4.
RAPPORTO
CINT2000 / FREQUENZA DI CLOCK
CFP2000 / FREQUENZA DI CLOCK
PENTIUM III
0.47
0.34
PENTIUM 4
0.36
0.39
Adesso riprendiamo la figura 5.4. Nella tabella 5.3 è riportato il valor medio dei rapporti
INDICE SPEC / f C per gli indici CINT2000 e CFP2000, calcolato relativamente all’intervallo
delle frequenze di clock, in cui lavorano i due processori (PENTIUM III e PENTIUM 4). Da
questi dati deduciamo che, per quanto riguarda il CINT2000, il Pentium III è più scalabile
rispetto alla frequenza del Pentium 4; mentre nel caso del CFP2000, la situazione è invertita:
il Pentium 4 è più scalabile rispetto alla frequenza del Pentium III. Ricordiamo comunque che
tale analisi è condotta basandosi su valori medi dei rapporti e quindi possiamo fare solo
considerazioni approssimative.
5.9
< SCALABILITÀ
> SCALABILITÀ
∆y2
∆y1
∆x
∆x
(a)
Figura 5.5: Sistemi a diversa scalabilità.
(b)
5.6 LEGGE DI AMDAHL
É intelligente, al fine di migliorare le prestazioni di una macchina, concentrare i nostri sforzi
nell’ottimizzazione delle operazioni più utilizzate in quanto rendere più veloce un evento più
frequente è certamente più utile che ottimizzare un evento raro e spesso è anche più facile.
Tale principio prende il nome di legge di Amdahl o legge dei rendimenti decrescenti.
Legge di Amdahl: Il miglioramento di prestazioni che può essere ottenuto usando alcune
modalità di esecuzione più veloci è limitato dalla frazione di tempo nella
quale tali modalità possono venire impegnate.
Se ad esempio consideriamo un certo intervallo di tempo nel quale è eseguito un programma e
notiamo che in esso una porzione consistente è occupato dall’esecuzione di un unico tipo di
operazioni, possiamo chiederci di quanto devo velocizzare queste operazioni per far sì che il
programma sia eseguito x volte più rapidamente. Possiamo utilizzare la seguente relazione:
Tdopo =
Tmigliorabile
a
+ Tnon − migliorabile
dove:
Tdopo è il tempo di esecuzione dopo il miglioramento,
a è lo speed-up della parte di sistema migliorabile,
Tnon − migliorabi le è il tempo di esecuzione non influenzato dal miglioramento.
La legge di Amdahl può essere espressa in maniera diversa introducendo il fattore di speedup, il quale ci informa su quanto più velocemente un lavoro verrà effettuato usando la
macchina migliorata rispetto alla macchina originale (quindi fornisce un’informazione
sull’incremento delle prestazioni).
S=
Pdopo
Pprima
=
Tprima
Tdopo
=
Tprima
Tmigliorabile
a
+ Tnon − migliorabile
5.10
=
1
p
+ (1 − p )
a
dove p = Tmigliorabile Tprima è la percentuale di tempo migliorabile nella macchina originale
TEMPO DI ESECUZIONE PRIMA
Å---------------------------------------------------------------------------------------------Æ
Tmigliorabile
Tnon - migliorabile
p
1-p
Tmigliorabile /a
Tnon - migliorabile
p/a
1-p
Å------------------------------------------------------------------------Æ
TEMPO DI ESECUZIONE DOPO
Nel disegno sopra è evidenziato come la riduzione del tempo migliorabile tramite il fattore a
riduce il tempo di esecuzione complessivo.
100
90
80
Speed up (S)
70
60
50
40
30
20
10
0
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Frazione Migliorabile del Sistema (p)
Figura 5.5: Legame tra speed-up e la frazione migliorabile del sistema.
La figura 5.5 (sopra) ci mostra il legame esistente tra lo speed-up e la frazione migliorabile
del sistema (p). Come si può notare è importante, al fine di avere un significativo aumento
delle prestazioni, che p sia maggiore di 0.8 cioè che il tempo migliorabile sia almeno l’80% del
tempo di esecuzione totale del programma prima dei miglioramenti.
5.11
Una volta applicati i miglioramenti sulla parte più utilizzata è opportuno concentrarsi anche
sulla parte meno utilizzata del sistema, infatti, come possiamo notare dal prossimo esempio, è
facile raggiungere dei livelli di ottimizzazione oltre i quali non solo non si può andare, ma che
sono anche difficili da raggiungere.
Esempio 5.1
Consideriamo un generico programma e supponiamo che il 90% di esso possa essere eseguito in
parallelo ( cioè è migliorabile facendo lavorare più processori) Æ p = 0.9
S=
1
p
+ (1 − p )
a
A
1
2
10
100
1000
10000
S
1.0
1.8
5.3
9.2
9.9
9.99
Possiamo notare che con a → ∞ S = 10 ( valore massimo dello speed-up ).
Per a = 1000 si è quasi raggiunto il livello massimo di miglioramento (S=9.9) e possiamo
osservare che anche aumentando di 9000 unità il valore di a (in pratica, aggiungendo 9000
processori) otteniamo un aumento di S minore del 1%. Ciò dimostra che ad alte prestazioni per
avere piccoli miglioramenti di S bisogna fare grandi sforzi senza comunque ottenere risultati
proporzionali ad essi.
5.7 METRICHE INDIPENDENTI DALL’HARDWARE
Un errore comune è credere che le metriche indipendenti dall’hardware forniscano una
valutazione corretta delle prestazioni. Molti progettisti hanno studiato metodi che non fanno
riferimento alla misura del tempo di esecuzione. In passato esisteva un metodo che si basava
sull’utilizzo della dimensione del codice (NPROG) come misura della velocità, considerando il
programma più snello il più veloce.
5.12
PROGR:
______________
______________
___
___ CICLO(i)
___
______________
______________
CPU:
NPROG
______________
______________
___
___ CICLO(i,1)
___
___
___
___
….
….
___
___
___
N PROG ≤ NCPU
CICLO(i,2)
NCPU
CICLO(i,N)
______________
______________
Figura 5.6: Distinzione fra NPROG E NCPU.
NPROG indica il numero statico di istruzioni che costituisce il programma mentre NCPU è il numero di istruzioni
eseguite dinamicamente. Nella figura è mostrato l’esempio di un programma in cui è inserito un ciclo di i istruzioni
che deve essere svolto dalla CPU N volte (NPROG = i e NCPU = N * i ).
Ciò era importante qualche tempo fa (questo metodo fu pensato agli inizi degli anni 70),
quando la disponibilità di spazio in memoria era una risorsa critica ed era preferibile avere
programmi di dimensioni minori. Per le prestazioni tale considerazione non è valida. Prendiamo
l’esempio del calcolatore CDC 6600, i cui programmi sono in termini di N PROG 3 volte più
grandi di quelli del Burroughs B5500. Per quanto detto sopra la seconda macchina dovrebbe
essere assai più veloce della prima, ed invece la CDC 6600 esegue i programmi Algol 60 6 volte
più velocemente del Burroughs B5500.
Non è quindi opportuno usare il numero statico di istruzioni (NPROG) come parametro di
confronto fra architetture diverse. Ci dobbiamo limitare ad utilizzarlo per comparare codice
per lo stesso Instruction Set.
MIPS
Fra le metriche proposte per indicare le prestazioni di una macchina, vi sono i MIPS (milioni di
istruzioni per secondo).
MIPS
=
N CPU
10 6 ⋅ T CPU
La caratteristica positiva del MIPS è che risulta semplice da comprendere: a valori di MIPS
levati corrispondono macchine più veloci. Tuttavia questa metrica è affetta da 3 problemi:
5.13
•
per prima cosa dipende dall’insieme di istruzioni e non tiene conto delle loro
caratteristiche. Per questo non si possono utilizzare i MIPS per confrontare computer
con diversi Instruction Set (il conteggio delle istruzioni sarebbe senz’altro diverso);
•
un secondo aspetto è che i MIPS variano in base al programma considerato, quindi per
una data macchina non esiste un MIPS unico che sia valido per tutti i programmi;
•
infine, paradossalmente, l’indice MIPS può variare in modo inversamente proporzionale
alle prestazioni.
Esempio 5.2
Numero di Istruzioni (NCPU)
(espresse in miliardi)
A
B
C
COMPILATORE #1
5
1
1
COMPILATORE #2
10
1
1
A
1
___
CPI
B
2
C
3
Si consideri 2 diversi compilatori e 3 classi di istruzioni da eseguire A, B e C (vedi tabella
sopra). Supposto che la frequenza di clock fc sia 500 MHz, vogliamo sapere quale sequenza di
codice è eseguita più velocemente, confrontando tempo di esecuzione TCPU e MIPS.
TCPU
C CPU
1 3
=
=
⋅ ∑ N CPU , K ⋅ CPI K
fC
f C K =1
1
⋅ (5 ⋅1 + 1 ⋅ 2 + 1 ⋅ 3) ⋅10 9 = 20 sec
6
500 ⋅10
1
=
⋅ (10 ⋅1 + 1 ⋅ 2 + 1 ⋅ 3) ⋅10 9 = 30 sec
6
500 ⋅10
TCPU 1 =
(
)
TCPU 2
(
)
Quindi, secondo il tempo di esecuzione, il compilatore #1 risulta essere più veloce del
compilatore #2. Calcoliamo adesso i valori di MIPS nei due compilatori.
5.14
MIPS 1 =
MIPS
2
=
N CPU
TCPU ⋅ 10 6
N CPU
TCPU ⋅ 10 6
=
(5 + 1 + 1) ⋅ 10 9
20 ⋅ 10 6
1
=
= 350 MIPS
(10 + 1 + 1) ⋅ 10 9
30 ⋅ 10 6
2
= 400 MIPS
Come possiamo notare il compilatore #2 ha MIPS più elevato: da questo potremmo supporre
che il compilatore #2 sia migliore del compilatore #1, informazione smentita dai risultati
precedenti ( il compilatore #1 è più veloce Æ prestazioni di #1 maggiori di #2 ma MIPS di #1
inferiore di #2 Æ CONTRADDIZIONE! ).
IPC
Un’altra metrica proposta sono gli IPC ( numero medio di istruzioni per ciclo di clock).
IPC =
IPC =
1
CPI
1
N
N CPU
106
= CPU =
=
⋅ MIPS
fC
CPI CCPU TCPU ⋅ f C
Dall’ultima relazione si deduce che gli IPC sono caratterizzati dagli stessi problemi dei MIPS,
in quanto le due metriche sono direttamente proporzionali. A riprova riprendiamo l’esempio
precedente 5.2 e calcoliamo i valori di IPC per i due calcolatori.
IPC 1 =
IPC 2
N CPU 1
7 ⋅ 10 9
=
= 0 .7
10 ⋅ 10 9
C CPU 1
N CPU 2 12 ⋅ 10 9
=
=
= 0 .8
C CPU 2
15 ⋅ 10 9
IPC (#1) < IPC (#2)
Æ CALCOLATORE #2 MIGLIORE DEL CALCOLATORE #1 Æ SBAGLIATO!!!
Come dimostrano i MIPS e gli IPC, proposte alternative di misure delle prestazioni portano a
risultati parzialmente errati e in generale scorretti.
5.8 ALTRI INDICI USATI
Forniamo adesso altri indici per le prestazioni usati in diversi ambiti.
-ICOMP (Intel Comparative Microprocessor Performance Index)
Si tratta di un indice usato in ambito industriale, creato da Intel per stabilire la differenza di
velocità tra una CPU Intel ed un’altra. É utile soprattutto nell’ambiente del marketing per
5.15
promuovere il prodotto agli acquirenti. La prima versione ICOMP 1.0 fu introdotto il 16
ottobre 1985 quando uscì sul mercato il processore Intel 80386DX, mentre la seconda
ICOMP 2.0 nacque otto anni dopo, il 22 marzo 1993, in occasione del lancio dell’Intel Pentium
(P5). L’ultima versione ICOMP è la 3.0 utilizzata dal Gennaio 1998 quando comparve il Pentium
II (Deschutes).
- GSP (Global System Power)
GSP =
n
∑U
K =1
K
dove:
n è il numero di processori,
(T − Tstallo, K ) è il fattore di utilizzazione,
U K = CPU , K
TCPU , K
TCPU , K è il tempo di esecuzione di un programma sul processore K,
Tstallo , K è il tempo in cui non avvengono operazioni, ma in cui lavora solo la memoria relativa al
processore K ed il resto del sistema attende la sua risposta (vedi lezione 17-18 per ulteriori
approfondimenti).
Si tratta di una metrica composita perché tratta il lavoro di piu’ processori. Esso è utilizzato
soprattutto in campo accademico.
- CPKI (Cycles per Thousands Instructions)
Questo indice può essere considerato l’evoluzione del parametro CPI ed indica il numero di
cicli di clock per migliaia di istruzioni. Il CPKI viene prevalentemente nell’ambiente dei
progettisti.
5.9 ALTRI ERRORI COMUNI
Affinché i benchmark siano un utile strumento di confronto tra più macchine è necessario che
essi siano eseguiti in modo corretto. Un errore comune è lo scalare senza cura un benchmark,
eseguendone solo una parte o riducendo i dati in ingresso. Ad esempio se il nostro benchmark
prevede come input una matrice 1000*1000 sarà scorretto adoperarne una più piccola in
quanto nel secondo caso il sistema sarà stressato in modo minore ed in generale i risultati
prodotti nei due casi saranno diversi. Altra regola da seguire è quella di non includere nel
nostro pacchetto di valutazione troppi benchmark semplici, in quanto possono non evidenziare
alcune caratteristiche importanti. Allo stesso modo non dobbiamo fare uso di troppi pochi
benchmark semplici perché ciò potrebbe mettere eccessivamente in risalto una
caratteristica. In oltre bisogna ricordarsi che a seconda delle proprietà del sistema che si
intende studiare, bisogna scegliere il benchmark più opportuno.
5.16
LEZIONE 6
Valutazione delle Prestazioni (parte terza)
6.1 METRICHE BASATE SUL TEMPO
Come visto dai capitoli precedenti, il miglior modo di misurare le prestazioni, è fare
riferimento a metriche basate sul tempo, poiché sono maggiormente rappresentative: meno
tempo impiego per eseguire i miei programmi, più veloce è la mia macchina.
A questo proposito possiamo utilizzare una delle seguenti medie:
Dove TCPU è il tempo
AMTCPU
necessario a svolgere un
dato programma K escluso
il tempo di I/O e quello
impiegato per eseguire
altri programmi
1 n
= ⋅ ∑ TCPU , K
n K =1
Questa è la media aritmetica (Arithmetic Mean Time).
E’ facile da usare, ma viene troppo influenzata dai valori estremi (molto alti e/o molto bassi).
Inoltre, in questo modo stiamo supponendo che tutti i programmi vengano eseguiti lo stesso
numero di volte, ignorando così la composizione del workload reale .
Un modo per ovviare a questo inconveniente, può essere quello di “pesare” i vari tempi con un
coefficiente WK , che indica quante volte viene ripetuto il programma K. Così un programma
usato più volte, può pesare di più rispetto ad un altro che viene eseguito di rado.
Ciò di cui stiamo parlando è la media aritmetica pesata (Wheighted Mean Time) di cui sotto è
riportata la formula:
WMTCPU
1 n
= ⋅ ∑ W K ⋅ TCPU , K
n K =1
Un' altra media potrebbe essere quella armonica (Harmonic Mean Time)
HMTCPU = (
1 n 1
⋅∑
n K =1 TCPU ,K
)−1
la quale da maggior peso ai programmi più corti, in quanto al suo interno compare l’inverso del
Tempo di CPU.
Infine abbiamo la media geometrica (Geometric Mean Time)
GMTCPU = (
n
∏T
CPU , K
)1 n
K =1
che da risalto ai programmi con grandi variazioni di prestazioni.
6.1
Una proprietà importante è che il rapporto delle medie geometriche è uguale alla media
geometrica del rapporto. Quindi se stiamo valutando le prestazioni di due macchine, ad
esempio A e B, si può ottenere lo stesso valore relativo, sia che si normalizzi rispetto ad A,
sia che lo si faccia rispetto a B.
6.1.1 Medie normalizzate
Esiste anche una versione normalizzata delle precedenti medie, che consiste nell’allineare i
valori ottenuti, rispetto ad una macchina di riferimento. Questo effetto si ottiene dividendo
gli argomenti delle sommatorie delle medie aritmetica ed aritmetica pesata e della
T
produttoria della media geometrica, per un valore CPU , REF , K che sta ad
indicare il tempo di CPU (per come l’abbiamo definito all’ inizio del capitolo) del calcolatore di
riferimento. Nella media armonica invece, questo valore viene moltiplicato per il reciproco del
TCPU , K
:
AMTRCPU
1 n TCPU , K
= ⋅∑
n K =1 TCPU , REF , K
WMTRCPU
T
1 n
= ⋅ ∑ WK ⋅ CPU ,K
n K =1
TCPU ,REF ,K
HMTRCPU = (
GMTRCPU = (
1 n TCPU ,REF ,K
⋅∑
n K =1 TCPU ,K
n
∏T
K =1
TCPU ,K
Dove la R nelle
formule sta per
rapporto (ratio)
)−1
)1 n
Questa è la media usata
per valutare le
prestazioni nello
SPEC95
CPU , REF , K
6.2 L’INDICE DI PRESTAZIONI
Queste medie possono essere utilizzate nelle versioni normalizzate e non, per definire un
indice di prestazioni P, dato dal loro reciproco rispetto al tempo.
6.2
Secondi
P≡
1
XMTCPU
La X indica una
qualsiasi delle
medie
Oppure nel caso normalizzato
P≡
1
XMTRCPU
Come accennato prima, per lo SPEC95
P≡
1
GMTRCPU
6.3 DATI FUORVIANTI
Andiamo adesso, con l’ ausilio di alcuni esempi, ad evidenziare quali sono però i problemi nell’
uso di queste medie temporali.
6.3.1 Ambiguità con media aritmetica.
Prendiamo due calcolatori (A e B); facciamo eseguire loro due programmi (prog. 1, prog. 2).
Come si vede dai dati riportati in tabella, il programma 1 viene eseguito da A, 10 volte più
velocemente rispetto a B.
Invece per il programma 2 è il calcolatore B ad essere più veloce, in quanto esegue il suo
lavoro in 100 secondi contro i 1000 di A.
Ora, effettuando le medie, emerge un dato interessante: con AMT, B sembra essere 9.1 volte
più veloce di A; però con GMT le prestazioni risultano identiche! Quindi in questo modo non
possiamo dire quale sia la macchina più veloce.
6.3
Tabella 6.1 Esperimento con AMT e GMT.
Macchina A
Macchina B
TCPU (prog.1)
1s
10s
TCPU (prog.2)
1000s
100s
500.5s
55s
B è 9.1 volte più veloce di A
31.6
31.6
A è veloce come B
AMTCPU
(prog.1, prog.2)
GMTCPU
(prog.1, prog.2)
Che succede se usiamo la media aritmetica normalizzata?
Ripetiamo adesso lo stesso esperimento di prima, ma normalizziamo i risultati rispetto ad A.
Anche ora per il programma 1, B è 10 volte più lenta, mentre per il secondo programma è 10
volte più veloce. Dalle due medie però abbiamo ancora dati in conflitto tra loro. Infatti, se con
la media aritmetica normalizzata dovrebbe essere ancora B la macchina più potente, secondo
la media geometrica normalizzata i due calcolatori sono equivalenti. In sostanza, per come
abbiamo effettuato le prove, non possiamo dire nulla su quale sia il sistema più performante.
Tabella 6.2 Esperimento con le medie normalizzate rispetto ad A.
Macchina A
Macchina B
TCPU (prog.1)
1
10
TCPU (prog.2)
1
0.1
1
5.05
A è 5.05 volte più veloce di B
1
1
A è veloce come B
AMTRCPU
(prog.1, prog.2)
GMTRCPU
(prog.1, prog.2)
Normalizzando rispetto a B, con AMTR, sembra essere questa la macchina migliore,
nonostante non sia stato cambiato nulla rispetto all’ esperimento iniziale: i programmi ed i
calcolatori sono sempre gli stessi! GMTR continua invece a dirci che i due calcolatori hanno le
stesse prestazioni in media. Quindi si vede che è facile costruire dei risultati, combinando ad
hoc i dati e le medie.
Tabella 6.3 Esperimento con le medie normalizzate rispetto a B.
Macchina A
Macchina B
TCPU (prog.1)
0.1
1
TCPU (prog.2)
10
1
5.05
1
B è 5.05 volte più veloce di A
1
1
A è veloce come B
AMTRCPU
(prog.1, prog.2)
GMTRCPU
(prog.1, prog.2)
6.4
I problemi principali sono quindi che, usando la media aritmetica in un rapporto, i risultati sono
dipendenti dalla macchina di riferimento. Per la media geometrica questo non è vero in quanto,
come dicevamo all’inizio, la media geometrica del rapporto è uguale al rapporto delle medie
geometriche, quindi questa metrica è indipendente dai dati usati per la normalizzazione.
6.3.2 Ambiguità della media geometrica
A questo punto la media geometrica (normalizzata e non), sembrerebbe essere la miglior
metrica per valutare le prestazioni dei calcolatori. Purtroppo non è così, infatti:
1. Al contrario della media aritmetica, non è proporzionale al tempo totale d’ esecuzione,
quindi è anche meno intuitiva.
2. Non rispetta il principio fondamentale della misurazione delle prestazioni!
Non è infatti possibile predire attraverso essa il tempo d’esecuzione poiché non tiene traccia
del tempo totale d’esecuzione.
Cerchiamo di chiarire con un esempio:
I programmi ed i calcolatori sono sempre gli stessi dell’ esperimento sintetizzato nella Tab. 1.
Questa volta però, il programma 1 è stato fatto girare 100 volte. Per cui è come se avessimo
usato una WMT con pesi W1 = 100 e W2 = 1. Quindi considerando il tempo complessivo, A e B
avrebbero le stesse prestazioni, solo se il programma 1 venisse eseguito 100 volte più
frequentemente del programma 2. C’ è sempre la differenza di un ordine di grandezza tra i
tempi, relativi a ciascun programma, di A e di B, ma ora i tempi totali spesi dalle due macchine
per eseguire entrambi i programmi sono gli stessi: 1100 secondi.
Infatti adesso si vede che, anche con la media aritmetica, A e B hanno la stessa velocità.
Tabella 6.4 Esperimento con ripetizione del prog. 1.
TCPU
(prog.1 * 100)
TCPU (prog.2)
AMTCPU
(prog.1, prog.2)
GMTCPU
(prog.1, prog.2)
Macchina A
Macchina B
100s
1000s
1000s
100s
550s
550s
A e B hanno la stessa velocità
316s
316s
A e B hanno la stessa velocità
Il problema sopra enunciato riguardo alla GMT diventa quindi evidente considerando che,
nonostante pure GMT sia pesata, se W1 fosse uguale a 200, la GMT, al contrario della media
aritmetica, darebbe ancora risultati uguali, ignorando così la proporzionalità con il tempo
totale d‘esecuzione.
Svolgendo i conti:
6.5
AMTCPU
1 n
1
= ⋅ ∑ TCPU , K = ⋅ (200 + 1000 ) = 600
n K =1
2
AMTCPU
1 n
1
= ⋅ ∑ TCPU , K = ⋅ (2000 + 100 ) = 1050 macchina B
n K =1
2
GMTCPU = (
n
∏ TCPU ,K
K =1
GMTCPU = (
n
∏ TCPU ,K
K =1
macchina A
)1 n = (200 ⋅1000 )1 / 2 = 447.2 macchina A
)1 n = (2000 ⋅100 )1 / 2 = 447.2 macchina B
6.4 CONCLUSIONI SULLE METRICHE
In ogni caso, non si può definire un carico di lavoro (Workload), per fare previsioni, con GMTR
per 3 o più macchine. La soluzione consiste quindi, nel misurare prima uno Workload reale;
attribuire poi dei pesi secondo la reale frequenza d’ utilizzo dei programmi, oppure se non è
possibile, normalizzare, facendo sì che venga speso lo stesso tempo sullo stesso programma in
più macchine, rendendo espliciti i pesi e rendendo così possibile predire il tempo d’ esecuzione
di un carico analogo. Infine se abbiamo bisogno di normalizzare rispetto ad una macchina
specifica, questa deve essere l’ultima operazione, dopo aver sintetizzato le prestazioni con i
pesi adeguati.
In figura 6.1 è riassunta la procedura sopra descritta
6.6
Definisco lo workload
w1
t1
w2
w3
w4
w5
t2
t3
t4
t5
Estraggo i benchmark
w1’
w2’
w3’
w4’
t1’
t2’
t3’
t4’
w5’
t5’
Uso i benchmark
w1’’
w2’’
w3’’
w4’’
t1’’
t2’’
t3’’
t4’’
w5’’
t5’’
Estrapolo prestazioni
^
w1
^
t1
^
w2
^
w3
^
w4
^
w5
^
t2
^
t3
^
t4
^
t5
Figura 6.1 diagramma riassuntivo.
Dovrebbe essere ormai chiaro, che per avere un’ idea concreta di quali possano essere le
prestazioni di una macchina, si debba fare riferimento al tempo d’ esecuzione dei programmi.
Gli altri metodi utilizzati, sono fallaci sotto molti punti di vista, oppure sono stati usati in
maniera non corretta, ad esempio comparando senza le adeguate considerazioni i risultati
ottenuti su piattaforme differenti. Quindi anche quando vogliamo sintetizzare i risultati,
dobbiamo fare riferimento al tempo. Rivestono allora particolare interesse la AMT,che tiene
traccia i tempi d’ esecuzione e la WMT, che grazie ai pesi permette di bilanciare i benchmark
in un quadro di valutazione complessiva.
6.5 UN PO’ DI STORIA…
E interessante notare che non è stato così immediato arrivare a queste conclusioni. La ricerca
di un numero facile da calcolare (per i produttori) e da capire (per gli utenti), che
identificasse la qualità del sistema, ha portato spesso, anche a causa dell’evoluzione dei
computer, ad usare metriche diverse da quelle temporali ed a volte anche indipendenti
dall’hardware (dimensione del codice).
La prima in assoluto fu il tempo necessario ad effettuare una ADD, dato che la durata per
eseguire le istruzioni era più o meno la stessa per tutte. Quando questo incominciò a non
essere più vero, si pensò di rimediare misurando, invece che una sola istruzione, un mix di
6.7
queste, tenendo conto delle frequenze relative, che se misurate in cicli di clock dà il CPI: cicli
di clock per istruzione.
6.5.1 I MIPS e le loro varianti.
Scorrendo avanti nel tempo, troviamo i MIPS (milioni di istruzioni al secondo), il loro pregio è
che a valori più alti, corrispondono prestazioni superiori, solo che non tengono conto della
struttura delle istruzioni; non possono essere confrontati risultati di macchine differenti,
perché si sa a priori che il risultato sarà diverso. Addirittura, anche all’interno della stessa
macchina, i MIPS variano a seconda dei programmi eseguiti. Praticamente i MIPS sono utili
solo per confrontare due diverse implementazioni dello stesso programma sulla stessa
macchina.
Nonostante ciò, grazie alla loro intuitività, ebbero ampia diffusione. Ad “aggravare” la
situazione vennero poi i MIPS di picco, così detti perché venivano calcolati facendo eseguire
una combinazione di istruzioni che minimizzava il CPI. Senza considerare però che tale
combinazione poteva anche essere del tutto inutile ai fini pratici.
Per esempio se ho il set di istruzioni di Tab. 5
Tabella 6.5 set di istruzioni
Tipo
CPI
A
1
B
2
C
3
e voglio ottenere un valore di MIPS di picco uguale a 500, con un processore con frequenza di
clock ( f c ) di 500MHz, potrò utilizzare solo istruzioni di tipo A visto che
CPI =
fc
(10
6
⋅ MIPS
)=1
E’ importante sottolineare, che risulta piuttosto difficile immaginare che, un programma
costituito di sole istruzioni di tipo A abbia una qualche valenza pratica o sia addirittura
rappresentativo per la velocità dell’ intero sistema!
Un caso celebre fu il processore Intel i860 venne pubblicizzato come capace di eseguire due
istruzioni in virgola mobile ed una intera in un ciclo di clock a 50MHz. Gli furono attribuiti 100
MFLOPS (milioni di istruzioni in virgola mobile al secondo) e 150 MOPS (milioni di operazioni al
secondo). Quando fu commercializzato, nel ’91 (2 anni dopo il suo annuncio) però, lavorava alla
frequenza di 40MHz, ma il processore concorrente MIPS R3000, che aveva valori come 16
MFLOPS e 33 MOPS di picco, con i benchmark SPEC risultò essere il 15% più veloce dell’
Intel, quando invece sarebbe dovuto essere circa 5 volte più lento.
6.8
Allo scopo di rendere significativi i MIPS, anche con ISA (set di istruzioni) differenti, sono
stati poi “relativizzati” rispetto ad un calcolatore di riferimento (come avvenne anche per lo
SPEC).
Per cui adesso:
Dove TREF è in tempo d’esecuzione sulla
MIPSR =
TREF
⋅ MIPS REF
TNEW
macchina di riferimento;
TNEW è il tempo sul calcolatore che
stiamo testando;
MIPSREF sono i MIPS corrispondenti al
calcolatore di riferimento
Purtroppo anche questo sistema di valutazione è affetto da svariati problemi!
Innanzitutto i MIPS sono proporzionali al tempo d’esecuzione, soltanto per una determinata
combinazione dell’ input, per un determinato programma.
In più ci sono delle difficoltà legate anche alla macchina di riferimento. Poiché se negli anni
’80 il calcolatore di riferimento era il VAX-11/780, nel futuro sarebbe stato sempre più
difficile reperirlo e far girare i nuovi programmi su di esso. E le versioni dei software?
Aggiornarle avrebbe potuto far variare le prestazioni del VAX… quindi cambiare la macchina
di riferimento, avrebbe reso, anche nella migliore delle ipotesi, molto difficilmente
comparabili i risultati ottenuti successivamente.
6.5.2 Benchmark sintetici e Kernel - benchmark
Vista l’impossibilità di avere un riferimento fisso ed anche a causa dell’ evoluzione tecnologica
che vedeva CPU sempre più sofisticate e dipendenti da tanti altri fattori, come le pipeline e le
memorie, ogni speranza sulla validità dei vari MIPS, MOPS e MFLOPS venne meno, dato che,
anche conoscendo l’ ISA e le istruzioni da eseguire, non era più possibile risalire al tempo
d’esecuzione, nonché ai MIPS.
Così vennero introdotti i benchmark sintetici. Come il Whitestone e la sua versione successiva
Dhrystone, che consistevano in un “programma esempio”. La misura delle prestazioni era data
dal numero di iterazioni del benchmark stesso.
Ed ancora i kernel-benchmark (Linpack e Loop Livemoore) , ossia un frammento particolare di
un programma, che in base al suo tempo d’esecuzione, dovrebbe dare un’ idea della potenza
della CPU. Il problema è che è stato dimostrato che in questo modo le prestazioni vengono
sovrastimate.
6.5.3 I programmi giocattolo
Un altro passo (falso) in avanti fu fatto tentando di predire e misurare le prestazioni
attraverso programmi che riproducevano semplici giochi, il cui risultato era noto a priori, come
il setaccio di Eratostene, il gioco dei 15 o l’esecuzione di una Qucksort. La diffusione di questo
tipo di benchmmark fu dovuta alla facilità di implementazione di questi “programmini” sulle
varie macchine, inoltre le piccole dimensioni ne rendevano facile l’utilizzo in simulatori
software, ad esempio per i test delle cpu RISC che iniziarono a comparire nei primi anni ’80.
6.9
6.6 SCELTE PROGETTUALI
Come si è visto, sin dall’ inizio c’è stato sempre un grande sforzo per definire un sistema
valido per la valutazione delle prestazioni, perché questo è uno parametri fondamentali,
insieme al costo ed al consumo
d’ energia, sia nella fase di progetto che, da parte dell’ utente, nella fase d’acquisto di un
computer.
Questi tre fattori però sono in contrasto tra loro. Ad esempio abbassare il tempo
d’esecuzione (prestazioni migliori), comporta uno sforzo progettuale e di ricerca notevole, che
ha come conseguenza quella di aumentare i costi ed il consumo d’energia. Oppure se volessimo
progettare una CPU a basso consumo dovremmo probabilmente cedere qualcosa in termini di
prestazioni; in più anche qui il lavoro dei ricercatori e l’implementazione di nuove tecnologie
comporterebbe un aumento dei costi… Allora visto che il computer ideale (alte prestazioni,
basso consumo, basso costo), sarebbe veramente difficile (se non impossibile) da realizzare, si
preferisce fare delle scelte a priori, in base al campo d’applicazione previsto.
Per un progetto per alte prestazioni, come un server o una workstation, il costo ed il consumo
passano in secondo piano rispetto alla velocità. Per un sistema embedded, come un telefonino o
un PDA invece, la velocità non è più così vincolante, piuttosto si deve fare molta attenzione all’
assorbimento d’ energia ed al costo, poiché essendo oggetti di largo consumo, pensati per
essere sempre a portata di mano, dovranno innanzi tutto essere relativamente economici ed
avere una lunga autonomia. Per i computer da casa – ufficio infine, si richiede un compromesso
tra le due categorie precedenti, infatti siamo disposti a spendere di più, rispetto ad un
cellulare, ma sicuramente molto meno rispetto ad un server ed avendo la possibilità di
utilizzare la rete elettrica non siamo più vincolati alla scarsa autonomia delle batterie.
6.6.1 Il prezzo
Per ultimo (ma non meno importante) c’è da determinare il costo del calcolatore.
Come accennato prima c’e il costo di ricerca e sviluppo, ed il costo dei componenti, legato
anche alla tecnologia con la quale sono stati sviluppati. Comunque questi non sono gli unici
fattori, infatti c’è da tener conto del lavoro di assemblaggio e di tutta l’area relativa all’
aspetto commerciale (il marketing), nonché al margine di guadagno desiderato dal venditore
del sistema. Come se non bastasse c’è poi da tener conto che ogni sei mesi, un anno al massimo,
i componenti scelti diventano obsoleti, per cui il prezzo andrà ritoccato e le nostre scelte non
saranno più ottimali. Quindi la cosa importante è avere ben presente gli obiettivi che si
vogliono raggiungere, cercando di individuare il miglior compromesso.
6.7 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
6.10
LEZIONE 7
Standard IEEE-754 per le operazioni floating point
7.1 INTRODUZIONE
Lo sviluppo dei calcolatori elettronici è stato caratterizzato negli anni 80 e 90 da un
inarrestabile aumento della potenza di calcolo e dal costante miglioramento delle funzionalità
supportate. In particolare, i processori supportano tipicamente due tipi di rappresentazione
dei numeri: la rappresentazione dei numeri interi e la rappresentazione in virgola mobile
(floating point). Il motivo principale per l’introduzione dei numeri in floating point sta nella
possibilità di utilizzare un intervallo di numeri più ampio per effettuare i calcoli riducendo il
numero di cifre disponibili a parità di bit utilizzati per la codifica.
7.2 RAPPRESENTAZIONE FLOATING POINT
I numeri in floating point corrispondono ai numeri frazionari, rappresentabili su un numero
finito di cifre, nella forma:
(-1)S × A,B × 2 C
S è il segno del numero, la sua mantissa è A,B e il suo esponente è C. In questo caso la base di
rappresentazione e’ la base 2. Un’altra base che viene utilizzata e’ la base 10 (tramite codifica
BCD o Binary Coded Decimal). La base 2 e’ piu’ comoda da usare per ragioni di efficienza
implementativa. Nel seguito si fara’ riferimento a questa base di rappresentazione.
Nella aritmetica in floating point la prima decisione da prendere è quanti bit devono essere
assegnati ad ognuno di questi valori numerici. Una volta fissato il numero totale di bit
disponibili, resta da scegliere quanti bit assegnare a esponente e mantissa. Risulta chiaro,
quindi, che non tutti i numeri possono essere rappresentati, ma solo un sottoinsieme limitato.
Ad esempio, un comune schema per rappresentare un numero in floating point usando 32 bit è
mostrato in Figura 7.1.
1 bit
segno
8 bit
23 bit
esponente
mantissa
Figura 7.1. Rappresentazione floating point.
7.2.1 Numeri floating point normalizzati
La notazione scientifica adotta una forma standard che elimina gli zeri iniziali per avere
esattamente una cifra diversa da zero a sinistra della virgola decimale. Così –8,53 × 10-2 è in
notazione scientifica. Analogamente, un numero floating point normalizzato ha una mantissa la
cui cifra più a sinistra è diversa da zero; per i numeri floating point normalizzati in base due,
la sola cifra diversa da zero possibile è 1. Poiché il bit più a sinistra di una mantissa
normalizzata è sempre lo stesso, non è necessario codificarlo con un bit della
rappresentazione (così si risparmia un bit); perciò il bit iniziale diventa un bit nascosto
(hidden bit). La rappresentazione di un numero floating point normalizzato sarà:
(-1) S × 1, M × 2 E
dove S indica il segno, M è la mantissa ed E è l’esponente.
7.3 STANDARD IEEE-754
Nei primi anni ‘80 i principali costruttori di elaboratori elettronici producevano calcolatori che
utilizzavano i numeri floating point con proprie convenzioni e un proprio formato numerico. La
necessità di scambiare dati tra elaboratori diversi portò alla definizione di uno standard per il
floating point da parte di una commissione che trovasse un punto di riferimento comune.
7.1
Nel 1985 l’ IEEE Computer Society (Institute of Electrical and Electronics Engineers) definì
lo standard IEEE-754 per i numeri floating point e nel 1989 diventò uno standard
internazionale (IEC 559) adottato dai maggiori costruttori di calcolatori tra i quali Motorola,
Intel, SPARC e MIPS. Tale standard ha aumentato la qualità dell’ aritmetica dei calcolatori e
la facilità di trasferimento di programmi che fanno uso di operazioni in floating point. Lo
standard IEEE-754 definisce quattro formati numerici float: single precision, double
precision, single extended precision e double extended precision. Nel seguito ci
concentreremo a considerare solo i primi due formati nei paragrafi 7.3.1 e 7.3.4 .
7.3.1 Single precision (32 bit)
Dato un numero floating point nella forma (-1) S × 1, M × 2 E , con M intero rappresentabile su
23 bit ed E compreso tra –127 e 128, il formato standard single precision si rappresenta
seguendo lo schema mostrato in figura 7.2.
1 bit
Segno
8 bit
23 bit
esponente polarizzato
mantissa
Figura 7.2. Standard single precision.
Il segno della mantissa è indicato dal primo bit, seguito dalla rappresentazione dell’esponente.
Le ultime 23 cifre rappresentano la parte frazionaria della mantissa, cioè i bit che si trovano
alla destra della virgola binaria. Invece di utilizzare un esponente E con segno rappresentato
sepratamente, il valore che viene memorizzato nel campo dell’esponente (Ê) è un intero senza
segno Ê = E + 127, che assume un valore compreso tra 0 e 255. Questo formato viene
chiamato rappresentazione polarizzata (127 è il fattore di polarizzazione).
Esempio:
Rappresentare il numero –9,75 10 in single precision.
Trasformare la parte frazionaria in complemento a due:
- 1001,11 × 2 0
Normalizzare il numero:
- 1,00111 × 2 3
La rappresentazione di un numero in single precision è data da:
(-1) S × 1, M × 2Ê - 127
In questo caso:
S = 1 = segno negativo
Ê = 3 + 127 = 130 che in binario su 8 bit risulta 1 0 0 0 0 0 1 0
M = 0011 1000 0000 0000 0000 000
cioè:
10000010 0011 1000 0000 0000 0000 000 .
7.3.2 Casi particolari
Esistono casi speciali di operazioni aritmetiche in floating point che riguardano l’utilizzo di
zero e infinito. Nella tabella 1 sono schematizzati tali casi speciali.
Quando il risultato di un’operazione aritmetica è indeterminato, cioè nei casi
7.2
0
, ±∞ × 0 ,
0
(+ ∞ ) – (- ∞ ), ad essa viene associato il valore Not a Number (NaN). Il NaN è rappresentato
da una mantissa non nulla ed esponente di tutti uno.
Se in un numero floating point l’esponente è uguale a zero e la mantissa non nulla si
rappresenta un numero denormalizzato. La rappresentazione di un numero denormalizzato in
single precision è data da (-1) S × 0, M × 2- 126 , mentre in double precision avremo
(-1) S × 0, M × 2- 1022 , dove S indica il segno ed M la mantissa del numero denormalizzato; 2- 126
e 2- 1022 sono valori convenzionali. I numeri denormalizzati sono caratterizzati da una
crescente perdita di precisione (diminuzione delle cifre significative) man mano che ci si
avvicina allo zero. Il vantaggio e’ che in questo modo si riesce ad avere qualche valore
rappresentabile anche per i numeri compresi fra 0 e il numero minimo normalizzato (sia
nell’intervallo positivo che in quello negativo) (figura 7.3).
0
2-4 2-3
2-2
2-1
0
2-4 2-3
2-2
2-1
Figura 7.3. Numeri denormalizzati.
Un altro caso particolare è la divisione di un numero per zero, la quale viene riconosciuta dal
software come infinito ( ± ∞ ).
Tabella 7.1. Casi particolari.
Single Precision
Esponente E
Mantissa M
0
0
1-254
255
255
Double Precision
Esponente E
Mantissa M
0
non-zero
qualsiasi
0
non-zero
0
0
1-2046
2047
2047
0
non-zero
qualsiasi
0
non-zero
Rappresentazione
0
± numero denormalizzato
± numero floating point
±∞
NaN
7.3.3 Overflow e Underflow
L’insieme dei numeri in floating point rappresentabili è limitato ed è possibile che un numero
sia troppo grande o troppo piccolo per essere rappresentato. Quando il risultato di un calcolo
è troppo grande per essere rappresentato in un sistema di numeri in floating point, diciamo
che è avvenuto un overflow. Nello standard IEEE viene assegnato al risultato dell’operazione il
valore + ∞ o - ∞ a seconda del segno del risultato esatto. Se il risultato di un’ operazione
aritmetica genera un valore minore in modulo del più piccolo numero positivo rappresentabile,
si verifica un underflow. L’underflow dà come risultato dell’operazione il valore zero.
7.3.4 Double precision (64 bit)
Per consentire ai numeri in virgola mobile di assumere un campo valori più ampio, lo standard
IEEE specifica anche un formato in double precision, illustrato in figura 7.4, in cui si aumenta
l’insieme dei valori che possono essere assunti dall’esponente e dalla mantissa. La forma di
rappresentazione è la stessa utilizzata per lo standard single precision, (-1) S × 1, M × 2 E ,
con M intero rappresentabile su 52 bit ed E compreso tra –1023 e 1024.
7.3
1 bit
segno
11 bit
52 bit
esponente polarizzato
mantissa
Figura 7.4. Standard double precision.
L’ esponente viene rappresentato su 11 bit con fattore di polarizzazione 1023 (Ê = E + 1023); i
valori polarizzati dell’esponente Ê sono compresi tra 0 e 2047. La mantissa è rappresentata su
52 bit. Nella tabella 2 vengono riassunte le principali differenze tra i due formati standard.
Tabella 2. Caratteristiche a confronto.
Argomento
Bit di segno
Bit nell’esponente
Bit nella mantissa
Bit totali
Sistema di esponente
Fascia esponenziale
Numero più piccolo, normalizzato
Single precision
1
8
23
32
base 2 ad eccesso 127
da – 126 a 127
Numero più grande, normalizzato
Fascia decimale
Numero più piccolo, denormalizzato
~ 10
Double precision
1
11
52
64
base 2 ad eccesso 1023
da – 1022 a 1023
2
−126
2
−1022
2
128
2
1024
−38
~ 10
a 10
38
−45
−308
a 10
~ 10
−324
~ 10
308
Esempio:
Rappresentare il numero 11,5 10 in double precision.
Trasformare la parte frazionaria in complemento a due:
1011,1 × 2 0
Normalizzare il numero:
1,0111 × 2 3
La rappresentazione di un numero in double precision è data da:
(-1) S × 1, M × 2Ê - 1023
In questo caso:
S = 0 = segno positivo
Ê = 3 + 1023 = 1026 che in binario su 11 bit risulta 1 0 0 0 0 0 0 0 0 1 0
M = 0111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
Quindi il numero in double precision sarà così rappresentato:
0 10000000010 0111 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000.
7.4 OPERAZIONI BASE IN FLOATING POINT
I numeri floating point possono essere combinati tra loro tramite le operazioni base
dell’aritmetica. Analizziamo le varie fasi e i problemi derivanti dalla loro applicazione.
7.4.1 Addizione e Sottrazione
L’algoritmo di addizione e sottrazione in floating point si divide in quattro fasi fondamentali:
allineamento
addizione o sottrazione delle mantisse
7.4
normalizzazione
arrotondamento delle mantisse
L’addizione e la sottrazione sono due operazioni identiche a meno di un bit di segno; se
l’operazione da svolgere è una sottrazione, il processo inizia cambiando il bit di segno.
Prendendo in esame la somma (234 x 10 0 ) + (571 x 10 −2 ), passiamo alla fase successiva:
l’allineamento. Per eseguire l’addizione tra numeri in floating point non possiamo sommare le
mantisse direttamente perche’ devono occupare posizioni equivalenti, così si esegue
l’allineamento intervenendo sugli esponenti: si prende il numero con l’esponente più piccolo
(571 x 10 −2 ) e si fa scorrere la sua mantissa verso destra un numero di volte pari alla
differenza tra i due esponenti (5,71 x 10 0 ). Questa operazione può comportare la perdita di
cifre, per questo viene fatto scorrere il numero più piccolo, cosicche’ ogni cifra persa avrà
un’importanza relativamente bassa. Quindi (234 x 10 0 ) + (5,71 x 10 0 ). Procediamo alla somma
delle mantisse tenendo conto dei segni di entrambe: (234 + 5,71) x 10 0 = 239,71 x 10 0 .
Se necessario, normalizzare il risultato considerando che il numero di cifre che possiamo
memorizzare è limitato, quindi controllare eventuali overflow o underflow. Dall’esempio
avremo 2,3971 x 10 2 . Supponendo di non poter memorizzare più di 4 cifre per la mantissa,
dovremo procedere all’arrotondamento (2,397 x 10 2 ).
Inizio
Cambia il bit di segno (sottrazione). Confronta gli esponenti dei due numeri.
Esegui lo scalamento a destra del numero minore finchè il suo esponente non
corrisponde a quello maggiore.
Somma (sottrai) le mantisse
Normalizza la somma (sottrazione), o scalando a destra ed incrementando
l’esponente, o scalando a sinistra e decrementando l’esponente.
Overflow o
Underflow?
Si
Eccezione
No
Arrotonda la mantissa al numero opportuno di bit.
No
E’ ancora
normalizzato
?
Si
Fine
Figura 7.5. Addizione e sottrazione in floating point.
7.5
7.4.2 Accuratezza
Lo standard IEEE 754 prevede 3 ulteriori bit per migliorare l’accuratezza: 1 bit di guardia
(guard bit) e 1 bit di arrotondamento (round bit) e 1 sticky bit. Tali bit sono posizionati dopo
l’ultima cifra a destra della virgola e i loro valori vengono traslati nelle cifre significative della
mantissa e viceversa durante le operazioni. E’ possibile vederne l’utilità nel seguente esempio:
Esempio
Sottrarre i seguenti due numeri floating point in single precision con e senza bit di
guardia 1.00 x 21 – 1.11 x 20 (2 – 1.75 = 0.25):
-senza bit di guardia (ricordando che devo normalizzare il secondo operando)
1,00 x 21 - 0,11 x 21 = 0,01 x 21 = 1,00 x 2-1 (=0.5 ovvero commetto un errore del 100%)
-con bit di guardia
1,000 x 21 - 0,111 x 21 = 0,001 x 21 = 1,000 x 2-2 (=0.5 ovvero nessun errore!)
Dunque il bit (o in generale i bit) di guardia consente di confinare l’errore di macchina che si
genera durante i calcoli a cifre che non compaiono nelle cifre significative del risultato.
L’arrotondamento si può avere in 4 modalità:
• al valore pari più vicino
• verso + ∞
• verso - ∞
• troncamento (arrotondamento a zero)
Il primo tipo è quello più utilizzato, soprattutto per quanto riguarda i numeri esattamente a
metà tra le due rappresentazioni troncate più vicine (esempio: 0,50). Secondo lo standard
IEEE 754, se il bit meno significativo è dispari si deve aggiungere 1, se è pari si applica il
troncamento. Questo metodo crea sempre uno zero nel bit meno significativo. Le altre
modalità di arrotondamento si hanno quando il risultato è arrotondato verso l’alto (+ ∞ ), verso
il basso (- ∞ ) oppure direttamente a zero. A seconda del metodo scelto il bit di
arrotondamento verra’ opportunamente modificato.
Inoltre, lo standard prevede un ulteriore bit a destra del round bit chiamato sticky bit, che
ha lo scopo di perfezionare l’arrotondamento. Questo bit all’inizio dell’operazione deve essere
posto a 0, e se un 1 viene fatto scorrere su di esso, mantiene tale valore fino alla fine
dell’operazione svolta. In questo modo e’ come se l’arrotondamento fosse fatto su un numero
infinito di cifre.
7.4.3 Moltiplicazione e divisione
La moltiplicazione in floating point è un’operazione più semplice della somma e si articola in
varie fasi:
• somma degli esponenti
• eliminazione della polarizzazione
• prodotto delle mantisse
• normalizzazione
• arrotondamento delle mantisse
Inizialmente si devono sommare gli esponenti: se sono memorizzati in forma polarizzata la loro
somma raddoppia il fattore di polarizzazione, il quale dovrà essere sottratto dalla somma.
Successivamente si moltiplicano le mantisse tenendo conto dei loro segni; il prodotto avrà
lunghezza doppia rispetto agli operandi, però i bit in eccesso verranno persi durante
l’arrotondamento. Il prodotto verrà normalizzato ed arrotondato come è stato fatto per
7.6
l’addizione e la sottrazione. Infine, si forza il bit di segno a 1 se i segni degli operandi sono
diversi, a 0 se sono uguali. Si riporta in figura 7.6 lo schema riassuntivo delle fasi della
moltiplicazione in floating point.
Nella divisione in floating point l’esponente del divisore viene sottratto dall’esponente del
dividendo. Questa operazione cancella la polarizzazione, che dovrà essere ristabilita
sommando il fattore di polarizzazione alla differenza degli esponenti.
Il procedimento continua esattamente come quello della moltiplicazione: si prosegue dividendo
le mantisse, poi effettuando la normalizzazione e l’arrotondamento.
Inizio
Somma/Sottrai gli esponenti polarizzati dei due numeri, sottraendo/sommando la
polarizzazione dalla somma/differenza per ottenere il nuovo esponente polarizzato.
Moltiplica/dividi le mantisse
Normalizza il prodotto scalando a destra ed incrementando l’esponente.
Overflow o
Underflow?
Si
Eccezione
No
Arrotonda la mantissa al numero opportuno di bit.
No
E’ ancora
normalizzato?
Si
Forza il segno del prodotto al valore positivo se i segni degli operandi di partenza sono
uguali; se sono diversi rendi negativo il segno.
Fine
Figura 7.6. Moltiplicazione e divisione in floating point.
7.7
7.5 ISTRUZIONI FLOATING POINT NEL MIPS
Il MIPS supporta lo standard IEEE 754 con le seguenti istruzioni:
aritmetiche
confronto e branch
load/store.
move
Le istruzioni aritmetiche in floating point sono rappresentate nel MIPS su 32 e 64 bit.
Rappresentazione in single precision:
addizione = add.s
sottrazione = sub.s
moltiplicazione = mul.s
divisione = div.s
Rappresentazione in double precision:
addizione = add.d
sottrazione = sub.d
moltiplicazione = mul.d
divisione = div.d
In figura 7.7 sono riportati sia i registri per i numeri interi ($0, ... $31), sia quelli per i numeri
floating point. Tali registri sono tutti a 32 bit, ma nel caso dei regitri floating point e’ anche
possibile riferirsi alle coppie di registri che iniziano con un registro pari come se fosse un
registro a 64 bit ($f0-$f1, $f2-$f3,ecc.).
$0
$1
$f0
$f1
$31
$f31
($f0,$f1) = 64bit
32 bit
32 bit
Figura 7.7. Architettura operazioni in floating point.
Le funzionalita’ floating point sono raggrupate nel cosiddetto coprocessore 1, per evitare
un’eccessiva complessità della cpu ed eventualemente paralelizzare operazioni intere e
floating point. Originariamente tale coprocessore era disposto su un chip separata, ma
attualmente esso costituisce una parte del chip. I registri floating point resiedono appunto
nel coprocessore e le operazioni floating point operano solo su di essi. In tabella 3 sono
schematizzati i registri floating point e i relativi utilizzi.
7.8
Tabella 3. Registri floating point.
Registri
$f0…$f3
$f4…$f11
$f12...$f15
$f16…$f19
$f20…$f31
Utilizzo
Risultato della procedura
Provvisori
Passaggio dei parametri
Provvisori
Salvataggio dalla procedura chiamata
Per leggere o scrivere valori floating point dalla memoria si usano le istruzioni lwc1 (load) e
swc1 (store).
Per trasferire un valore fra i registri interi e quelli floating point sono presenti le istruzioni
mfc1 (move from coprocessor 1), e mtc1 (move to coprocessor 1). Tali istruzioni non
effettuano conversioni. Se l’intenzione e’ invece di convertire un valore intero in un valore
floating point (o viceversa) si fa uso delle istruzioni cvt, che opera solo su registri floating
point:
cvt.d.s converte da single a double
cvt.d.w converte da integer a double
cvt.s.d converte da double a single
cvt.s.w converte da integer a single
cvt.w.s converte da single a integer
cvt.w.d converte da double a single
Le istruzioni di confronto mettono il risultato (vero o falso) in un bit interno mentre il branch
decide il salto a seconda della condizione. Il confronto fra numeri floating point fa uso
dell’istruzione c.x.s in single precision e c.x.d in double precision. Al posto della x possiamo
trovare:
eq (uguale)
neq (non uguale)
lt (minore)
le (minore o uguale)
gt (maggiore)
ge (maggiore o uguale)
Il bit memorizzato internamente viene usato dalle seguenti due istuzioni di salto:
bc1t (branch true)
bc1f (branch false)
La tabella 4 riassume le istruzioni MIPS in floating point con esempi e commenti.
7.9
Istruzione
FP add single
FP subtract single
FP multiply single
FP divide single
FP add double
FP subtract double
FP multiply double
FP divide double
FP absolute value single
FP absolute value double
FP negative single
FP negative double
load word into c1
store word from c1
branch on FP true
branch on FP false
FP compare single
(eq,ne,lt,le,gt,ge)
FP compare double
(eq,ne,lt,le,gt,ge)
Move from c1 to c0
Move to c1 from c0
Convert double to
integer
Tabella 7.4: Istruzioni MIPS in floating
Esempio
Significato
add.s $f2, $f4,
$ f2 = $f4 + $f6
$f6
sub.s $f2, $f4,
$ f2 = $f4 - $f6
$f6
mul.s $f2, $f4,
$ f2 = $f4 × $f6
$f6
div.s
$f2, $f4,
$ f2 = $f4 / $f6
$f6
add.d $f2, $f4,
$ f2 = $f4 + $f6
$f6
sub.d $f2, $f4,
$ f2 = $f4 - $f6
$f6
mul.d $f2, $f4,
$ f2 = $f4 × $f6
$f6
div.d $f2, $f4,
$ f2 = $f4 / $f6
$f6
abs.s $f1
|$f1|
abs.d $f2
|$f2|
neg.s $f1
-$f1
neg.d $f2
-$f2
lwc1 $f1, 100
$f1 = Memory[$s2 +
($s2)
100]
swc1 $f1, 100
Memory[$f2 + 100] =
($s2)
$f1
if (cond == 1) go to PC +
bc1t 25
4 + 100
if (cond == 0) go to PC +
bc1f 25
4 + 100
if ($f2 < $f4)
c.lt.s $f2, $f4
cond == 1; else cond ==
0
if ($f2 < $f4)
c.lt.d $f2, $f4
cond == 1; else cond ==
0
mfc1 $2, $f4
$2 -> $f4
mtc1 $2, $f4
$f4 -> $2
cvt.w.d $f2, $f0
$f2 = (int)$f0
Convert double to single
cvt.s.d $f2, $f0
$f2 = (float)$f0
Convert single to double
cvt.d.s $f2, $f0
$f2 = (double)$f0
Convert single to integer cvt.w.s $f1, $f0
$f1 = (int)$f0
Convert integer to single cvt.s.w $f1, $f0
$f1 = (float)$f0
Convert integer to
double
$f2 = (double)$f0
cvt.d.w $f2, $f0
7.6 RIFERIMENTI BIBLIOGRAFICI
point.
Commento
somma single precision
sottrazione single precision
moltiplicazione single precision
divisione single precision
somma double precision
sottrazione double precision
moltiplicazione double precision
divisione double precision
valore assoluto single precision
valore assoluto double precision
valore negativo single precision
valore negativo double precision
trasferimento dati su 32 bit ad un
registro FP
trasferimento dati su 32 bit in
memoria
salto relativo al PC su condizione
vera
salto relativo al PC su condizione
falsa
confronto single precision
confronto double precision
Sposta il contenuto di $2 in $f4
Sposta il contenuto di $f4 in $2
Converte da double precision a
intero
Converte da double precision a
single
Converte da single precision a
double
Converte da single precision a
intero
Converte da intero a single
precision
Converte da intero a double
precision
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Sito www.dis.uniroma1.it/~salza/teaching.htm
7.10
LEZIONE 8
Assembly MIPS
8.1 INTRODUZIONE
Le prestazioni di un calcolatore si basano sulla valutazione del tempo totale di esecuzione che
offre un’indicazione consistente delle prestazioni complessive. L’evoluzione dei calcolatori è
incentrata sul miglioramento di alcuni parametri in base all’equazione fondamentale delle
prestazioni (vedi cap.4):
• Incremento della frequenza di clock se non va a discapito del CPI.
• Miglioramenti della struttura del processore che abbassano il CPI.
• Miglioramenti del compilatore che abbassano il numero totale delle istruzioni eseguite
dinamicamente da un programma.
La tendenza generale nell'architettura e nell'organizzazione dei calcolatori è stata per lungo
tempo rivolta verso una sempre maggiore complessità della CPU: set di istruzioni più vasto,
modi di indirizzamento più complicati, registri maggiormente specializzati, e così via. A
partire dagli anni ottanta, tuttavia, si è affermato un approccio innovativo all'architettura dei
calcolatori, noto col nome di Reduced Instruction Set Computer (RISC), che sembra
consentire una maggiore efficienza nell'implementazione di sistemi di elaborazione.
L'esposizione che segue è rivolta all'introduzione dei concetti che stanno alla base delle
architetture RISC. Un altro tipo di filosofia di progetto è rappresentato dal Complex
Instruction Set Computer (CISC) che per primo conquistò il mercato con l’avvento del
Personal Computer all’inizio degli anni ‘80 e che lentamente sta lasciando il passo.
Questi due approcci si differenziano per la loro Instruction Set Architecture (ISA) che è il
punto cruciale di interfaccia tra hardware e software.
Il livello ISA è posizionato tra il livello di microarchitettura e il livello del sistema operativo
(figura 8.1). Storicamente l’ISA fu sviluppato prima di tutti gli altri livelli e infatti
originariamente era l’unico livello esistente. Oggi viene chiamato semplicemente “architettura
di macchina” o a volte “assembly language”.
Programma
FORTRAN 90
Programma C
ISA
ISALIVELLO
LEVEL
Software
_________
Hardware
Hardware
hardware
Figura 8.1: Architettura di macchina.
Quali sono le caratteristiche di un buon ISA? In primo luogo dovrebbe definire un set di
istruzioni che possa essere implementato efficientemente nelle attuali e future tecnologie. In
secondo luogo dovrebbe facilitare la compilazione del codice. La regolarità e la completezza
dell’ISA sono tratti importanti che non sono sempre presenti. In breve l’ISA dovrebbe
8.1
soddisfare sia le esigenze dei progettisti hardware (facilitando un’implementazione più
efficiente) che dei programmatori (facilitando la generazione di un buon codice).
8.1.2 Classi principali di ISA
Le classi principali dell’ISA sono descritte in tab 8.1
Tabella 8.1: classi principali dell’ISA.
Sintassi
di una
istruzione tipo
Semantica
dell’istruzione
1
add A
acc Å acc + mem[A]
1+x
addx A
acc Å acc + mem[A + x]
0
add
tos Å tos + next
A registri di
uso generale
2
add A B
EA(A)Å EA(A) + EA(B)
3
add A B C
Ad
architettura
load/store
0
add Ra Rb Rc
Ra Å Rb + Rc
1
load Ra Rb
Ra Å mem[Rb]
1
store Ra Rb
mem[Rb] Å Ra
Ad
A
accumulato
stack
re
Indirizzi
contenuti
nell’istruzi
one
EA(A)Å EA(B) + EA(C)
CISC: Con questo termine si indica un tipo di CPU in cui la fase di decodifica di un'istruzione
avviene in passi successivi(µ-codice). Uno svantaggio di questa filosofia e' che la singola
istruzione può richiedere alcuni cicli di clock per essere interpretata dal processore,
diversamente da quello che accade nei processori con il set di istruzioni di tipo RISC. Un
vantaggio dei processori di tipo CISC e' quello di codificare un programma utilizzando un
numero munore di istruzioni e quindi di richiedere una quantita' minore di memoria-istruzioni.
Esempi di CPU CISC sono la famiglia Motorola 68000 installata sui modelli Macintosh
precedenti all'uscita del Power Mac (PowerPC) e la famiglia 80x86 della Intel.
RISC: E' un tipo di CPU che permette di eseguire delle operazioni piu' velocemente di un
processore CISC perchè si esegue almeno un'istruzione per ogni ciclo di clock. Il set di
istruzioni e' stato ridotto a quelle semplici ed utilizzate piu' frequentemente dai programmi,
eliminando istruzioni piu' complesse e poco usate(l’importanza di questo punto verrà analizzata
in dettaglio nel paragrafo 8.4.1 e tab.8.6). Queste ultime possono comunque essere ricreate
partendo da istruzioni semplici. Statisticamente il numero di istruzioni usate effettivamente
da una CPU è minore del numero di istruzioni definite nel set di una CPU CISC.
Storicamente RISC e' stata, ed e', una filosofia, un modo di concepire una CPU. L'idea e'
quella di fornire un processore con poche istruzioni e pochi modi di indirizzamento, ma
interamente implementato in hardware, in contrapposizione con le CPU CISC, dotate di
istruzioni piu' ad alto livello ed implementate in micro-codice. Oggi, si considerano spesso
RISC anche processori con istruzioni derivate da vecchie implementazioni CISC (68040/060
8.2
derivanti dai 680x0 fino allo 030, od il Pentium derivante dai 80x86), poiche' si bada piu'
all'implementazione completamente hardware delle istruzioni che all'instruction set.
Processori come il PowerPC, infatti, hanno portato a questa evoluzione del termine,
introducendo in un set di istruzioni tipico di altre CPU RISC (di nome e di fatto, quale il MIPS
o l'Alpha) istruzioni piu' complesse ma ugualmente implementate in hardware, che ne
incrementano notevolmente le performance rispetto ai concorrenti. Un'architettura RISC (nel
senso moderno) permette un'implementazione più efficienti, in quanto piu' complessa solo da
un punto di vista tecnologico, ma piu' facile da gestire. Da un punto di vista della sintassi
assembler, si distingue una CPU di filosofia CISC da una RISC, indipendentemente
dall'implementazione, se sono presenti istruzioni che permettono molti modi di indirizzamento
in sorgente ed in destinazione. Il PowerPC, ad esempio, si presenta con istruzioni ad operandi
fissi, ma gode di numerose varianti della stessa istruzione per operazioni piu' complesse.
Un confronto tra CISC e RISC è mostrato in tabella 8.2.
Tabella 8.2: confronto CISC e RISC.
Caratteristiche CISC
Caratterisitiche RISC
Approccio
fondamentale
La complessità si sposta dal codice
all'hardware
La complessità si sposta dall'hardware al
software, ovvero al compilatore che deve
essere molto efficiente
Conseguenze
della scelta
per il
programmatore
Il codice è molto compatto e occorre poca
memoria per contenerlo; è l'hardware che si
incarica di decodificare istruzioni anche
molto compatte e molto complesse
La dimensione del codice aumenta in favore
della semplificazione dell'hardware.
Conseguenze
della scelta a
livello hardware
-Pochi registri.
-Presenza di una ROM di decodifica.
-ISA molto articolato con centinaia di
istruzioni.
-Modalità di indirizzamento memoriamemoria
-Molti registri
-Non esiste la modalità di indirizzamento
memoria-memoria, ma alla memoria si accede
solo con il load e lo store
-ISA con qualche decina di istruzioni soltanto
-Direct execution
-Uso della pipeline per diminuire il ritardo del
critical path.
8.2 RICHIAMO SULL’ISA R 3000
Il MIPS R3000 presenta tre formati di istruzioni (formato R, formato I e formato J) aventi
lunghezza fissa pari a 32 bit come riportato in Figura 8.2.
6 bit
op
[31-26]
5 bit
rs
[25-21]
5 bit
rd
[20-16]
Formato I
op
[31-26]
rs
[25-21]
rd
[20-16]
Formato J
op
[31-26]
Formato R
5 bit
rd
[15-11]
5 bit
shamt
[10-6]
6 bit
funct
[5-0]
Indirizzo/immediato [15-0]
Indirizzo destinazione [25-0]
Figura 8.2: Formati delle istruzioni.
Questo processore supporta le seguenti categorie di istruzioni:
• Lettura/scrittura (load/store)
• Calcolo (aritmetiche,logiche)
• Salti e diramazioni (Jump, branch rispettivamente)
8.3
Commenti
Istruzioni aritmeticologiche su registri
Trasferimenti,
salti condizionati,
istruzioni aritmeticologiche con immediati
Istruzioni di salto
•
•
•
Floating point (istruzioni del coprocessore)
Gestione della memoria(TLB)
Istruzioni speciali (syscall,break)
8.3 VISIONE GENERALE DEI METODI DI INDIRIZZAMENTO
DELLA MEMORIA
Uno degli aspetti più importanti di un’architettura è dato dalle modalità di indirizzamento in
memoria, ovvero come vengono raggiunti gli oggetti dell’elaborazione (costanti, variabili) e
come viene passato il controllo tra parti diverse di programma.
Praticamente tutte le macchine oggi prodotte assegnano gli indirizzi ai byte (8 bit di dati),
anche se è possibile trasferire oltre al singolo byte, dati di 16 bit (semiparola), di 32 bit
(parola) e 64 bit (doppia parola). Se un’istruzione fa riferimento ad un oggetto che non è un
byte, si pone il problema di come vengono presi gli altri byte che compongono l’oggetto stesso,
oltre a quello che ne dà l’indirizzo. È quindi più conveniente mantenere l’accesso al byte
trasferendo meno dati in alcuni casi, o trasferire sempre e comunque word di dati mantenendo
comunque l’accesso al byte?
8.3.1 Metodo di indirizzamento (endiannes)
Considerando per esempio i riferimenti ad una parola, il byte che dà l’indirizzo alla word è
considerato nella posizione meno significativa o in quella più significativa? I due metodi di
ordinamento sono denominati Little Endian e Big Endian (fig.8.3), dove nel primo ad indirizzi
più bassi corrispondono i byte meno significativi (Intel 80x86,vax), mentre nel secondo ad
indirizzi più bassi corrispondono i byte più significativi (MIPS,68000).
Esempio: se scrivo la stringa 76543210 all’indirizzo 0 di memoria
indirizzi al byte
3
7
…
…
2
6
…
…
1
5
…
…
0
4
…
…
0
4
…
indirizzi alti
Little Endian
indirizzi al byte
0
4
…
…
1
5
…
…
2
6
…
…
3
7
…
…
0
4
…
indirizzi alti
Big Endian
Figura 8.3: metodi di ordinamento in memoria.
8.3.2 Allineamento
Supponiamo di trasferire di 4 byte, allora una data parola potrebbe iniziare ad indirizzo
0,1,2,. Nel caso in cui l’indirizzo sia multiplo della parola si dirà che tale parola è allineata in
memoria, negli altri casi si dirà che la parola è non allineata. Supponendo che le letture di
word avvengano solo ad indirizzi multipli di 4: allora nel caso di una parola non allineata, la sua
8.4
lettura/scrittura richiede almeno 2 cicli: prima per leggere/scrivere all’indirizzo i e
successivamente all’indirizzo i+4. Questa procedura rappresenta un rallentamento e richiede
la presenza della logica per rimettere in ordine i byte. Per questa ragione l’allineamento è
richiesto in molte architetture, in special modo nelle macchine RISC. L’unico motivo per usare
indirizzi non allineati è dato da ragioni di economia dello spazio utilizzato in memoria.
Aligned
Not
Aligned
Figura 8.4: parole allineate e non allineate.
8.3.2.1 Modi di indirizzamento
La modalità di indirizzamento si riferisce alla modalità in cui viene calcolato l’indirizzo
effettivo di un operando che sta in memoria. Alcune tipologie sono mostrate in tabella 8.3:
Tabella 8.3: Tipologie di indirizzamento.
Modo di indirizzamento
Esempio
Significato
Register
Add R4,R3
R4Å R4+R3
Immediate
Add R4,#3
R4Å R4+3
Displacement
Add R4,100(R1)
R4Å R4+Mem[100+R1]
Register indirect
Add R4,(R1)
R4Å R4+Mem[R1]
Indexed/Base
Add R3,(R1+R2)
R3Å R3+Mem[R1+R2]
Direct or absolute
Add R1,(1001)
R1Å R1+Mem[1001]
Memory indirect
Add R1,@(R3)
R1Å R1+Mem[Mem[R3]]
Auto-increment
Add R1,(R2)+
R1Å R1+Mem[R2]; R2Å R2+d
Auto-decrement
Add R1,–(R2)
R2Å R2-d; R1Å R1+Mem[R2]
Scaled
Add R1,100(R2)[R3]
R1Å R1+Mem[100+R2+R3*d]
Register: l’operando è il contenuto di un registro della CPU; il nome di questo registro è
specificato nell’istruzione.
Immediate: l’operando è definito esplicitamente nell’istruzione. Questa modalità è usata per
specificare indirizzi e dati costanti.
8.5
Register indirect: l’indirizzo effettivo dell’operando è il contenuto di una locazione di
memoria il cui indirizzo appare nell’istruzione. Nell’esempio questa indirezione è indicata
ponendo tra parentesi tonde il nome del registro o l’indirizzo della locazione di memoria
fornito con l’istruzione.
Offset/Displacement:: l’indirizzo effettivo dell’operando è calcolato sommando un valore
costante al displacement (o offset). Questo indirizzamento viene rappresentato
simbolicamente con N(R) dove N è una costante(displacement o offset) e R è il nome del
registro coinvolto. L’indirizzo effettivo dell’operando è quindi A= N+[R].
Indexed/base: in questo caso, al posto della costante indice N, viene usato il contenuto di un
secondo registro. L’indirizzo effettivo è la somma del contenuto dei registri R1 e R2.
Direct or absolute: l’operando è in una locazione di memoria il cui indirizzo è fornito
esplicitamente nell’istruzione.
Memory indirect: l’indirizzo effettivo dell’operando è il contenuto di una locazione di memoria
contenuta a sua volta in una locazione di memoria il cui indirizzo appare nell’istruzione.
Auto-increment: l’indirizzo effettivo dell’operando è il contenuto di un registro specificato
nell’istruzione. Dopo l’accesso all’operando il contenuto del registro viene incrementato per
puntare all’elemento successivo in una lista.
Auto-decrement: il contenuto di un registro specificato nell’istruzione viene decrementato. Il
nuovo contenuto viene poi usato come indirizzo effettivo dell’operando. Questa modalità
permette di accedere a operandi contigui in ordine di indirizzo decrescente e combinata con
l’indirizzamento Auto-increment è utile ad es. nella realizzazione di una struttura dati a pila.
Scaled: nell’indirizzare il generico elemento, si fa fare al secondo registro la funzione di
indice nella struttura,scalando in base alla dimensione “d” dell’elemento stesso
Questo indirizzamento è molto conveniente quando si ha a che fare con strutture dati
(vettori,matrici ecc.) proprio per la funzione di indice assunta dal secondo registro.
Esempio: N(R1)[R2] significa che l’indirizzo A= N+[R1]+d*[R2]
Per misurare l’uso effettivo dei vari modi di indirizzamento supponiamo di usare una macchina
avente tutti i modi di indirizzamento a disposizione sulla quale vengono fatti girare 3
programmi. Da questa analisi si può notare come l’indirizzamento Displacement e Immediate
siano i più usati (tab.8.4). Dall’analisi sono esclusi i modi che usano solo registri.
Tab.8.4: Uso effettivo dei modi di indirizzamento.
• Displacement
• Immediate
42% avg, (32% to 66%)
33% avg, (17% to 43%)
• Reg. Deferred(indirect)
• Scaled
• Memory indirect
• Misc
13% avg, (3% to 24%)
75% displacement &
immediate
88% displacement,
immediate & register
indirect
7% avg, (0% to 16%)
3% avg, (1% to 6%)
2% avg, (0% to 3%)
8.3.3 Dimensione del displacement
Attraverso analisi sperimentali condotte su 5 programmi SPECint92 e 5 programmi SPECfp92,
e considerando i bit come quantità con segno è stato rilevato che gli operandi che fanno uso di
displacement che necessitano di essere rappresentati su un numero di bit > di 15 è pari all’1%.
8.6
Da esperimenti di questo tipo si trae l’indicazione che la dimensione ragionevole per il
Displacement va da 12 a 16 bit.
Inoltre il numero degli operandi immediati rappresentabili in 8 bit è compreso tra il 50 e il
60%, mentre quelli rappresentabili con 16 bit sono compresi tra il 75 e l’80%.
___media SPECint92 ---mediaSPECfp92
Int. Avg.
FP Avg.
14
12
10
8
6
4
2
0
0,4
0,2
0
Figura 8.5: Bit di displacement.
8.3.4 Implicazioni sul ISA del MIPS
In base a considerazioni simili a quelle esaminate in paragrafi precedenti, nel MIPS sono
quindi stati scelti i seguenti modi di indirizzamento:
8.7
1. Immediate addressing
rs
Op
rt
addi, addiu,
andi, ori, slti,
sltiu, lui
Immediate
2. Register addressing (direct addressing)
op
rs
rt
Rd
…
add, sub,
mult, div,
addu,
subu,
multu,
divu, and,
or, sll, slr
slt, sltu,
mfhi, mflo
funct
Registers
Register
3. Base addressing
Op
rs
rt
Memory
address
byte
+
halfword
Word
lw, lh, lb,
lbu, sw,
sh, sb
Register
4. PC-relative addressing: PC=PC+(addressx4)+4
Op
rs
rt
Memory
address
Word
+
bne,
bnq
PC
5. Pseudodirect addressing: PC=PC[31..28] │address x 4
op
address (26 bit)
00
J, jal
OR
Word
PC
Figura 8.6: Modi di indirizzamento MIPS.
8.8
8.4 LUNGHEZZA DEI FORMATI DELL’ISTRUZIONE
Un’altra fase molto importante nella progettazione è la scelta della lunghezza del formato
delle istruzioni che si basa su tre diverse categorie: variabile, fissa e ibrida (come mostrato
in fig.8.5).
Figura 8.5: esempi di istruzioni con varie lunghezze di formato.
Questa scelta deve rappresentare un buon compromesso tra la dimensione del codice e le
prestazioni. Nel primo caso può essere più conveniente utilizzare istruzioni a formato
variabile mentre nel secondo indubbiamente sono migliori quelle a lunghezza fissa.
Recentemente i processori (ARM, MIPS) hanno aggiunto modalità di esecuzione opzionali che
consentono la decodifica di istruzioni lunghe metà parola (16 bit).
•
•
•
Tali istruzioni sono un subset del set di istruzioni principali.
Tali standard sono denominati Thumb e MIPS16 rispettivamente.
È possibile selezionare tale opzione a livello di funzione C.
8.4.1 Scelta nel MIPS
Il compromesso adottato dai progettisti del MIPS consiste nel mantenere invariata la
lunghezza per tutte le istruzioni predisponendo formati diversi per tipi di istruzioni diverse.
In particolare vengono utilizzati tre formati: R, I, J.
6 bit
5 bit
5 bit
5 bit
5 bit
6 bit
Commenti
Formato R
op
[31-26]
rs
[25-21]
Rd
[20-16]
Rd
[15-11]
shamt
[10-6]
funct
[5-0]
Formato I
op
[31-26]
rs
[25-21]
Rd
[20-16]
Istruzioni aritmeticologiche su registri
Trasferimenti,
salti condizionati,
istruzioni aritmeticologiche con immediati
Formato J
op
[31-26]
Indirizzo/immediato [15-0]
Indirizzo destinazione [25-0]
Figura 8.5.1: Formati delle istruzioni.
8.9
Istruzioni di salto
Se ci fossero molti operandi in memoria per ogni istruzione e molti modi di indirizzamento
sarebbe necessario avere una specifica di indirizzo per ognuno degli operandi.
Invece in una architettura load/store con al massimo un indirizzo per istruzione e pochi modi
di indirizzamento (max 1 o 2) posso codificare il modo di indirizzamento direttamente insieme
al campo “opcode” dell’istruzione.
A questo punto vediamo i criteri con cui può essere effettuata la scelta delle operazioni da
supportare (vedi tab.8.V). Dal 1960 ad oggi ci sono stati pochi cambiamenti sulle operazioni
tipiche del calcolatore.
Tabella 8.5: Principali operazioni supportate
Data Movement
Load (from memory)
Store (to memory)
memory-to-memory move
register-to-register move
input (from I/O device)
output (to I/O device)
push, pop (to/from stack)
Arithmetic
integer (binary + decimal) or FP
Add, Subtract, Multiply, Divide
Shift
shift left/right, rotate left/right
Logical
not, and, or, set, clear
Control (Jump/Branch)
unconditional, conditional
Subroutine Linkage
Call, return
Interrupt
trap, return-from-interrupt
Synchronization
test & set (atomic r-m-w)
Multimedia (MMX)
parallel subword ops (16bit addx4)
*1
*1. atomic r-m-w (read-modify-write) è l’operazione fondamentale per consentire la
sincronizzazione delle operazioni a livello di sistema operativo.
Ad esempio da un’analisi effettuata sul processore 80x86 è risultato che le istruzioni più
semplici sono anche le più usate (tab. 8.6) e che quindi devono essere supportate meglio a
8.10
livello di architettura. In tale tabella possiamo osservare inoltre come nel caso del processore
80x86 il 96% delle istruzioni eseguite è rappresentato dalle sole dieci indicate.
Tabella 8.6: Frequenza di utilizzo delle principali istruzioni.
Rank
Istruzione
Percentuale totale
1
load
22%
2
conditional branch
20%
3
compare
16%
4
store
12%
5
add
8%
6
and
6%
7
sub
5%
8
move register-register
4%
9
call
1%
10
return
1%
Total
96%
8.5 TIPI “PRIMITIVI” DI DATO E DIMENSIONE DEGLI OPERANDI
NEI PROGRAMMI
I tipi di dato possono essere divisi in due categorie: numerici e non numerici. Il tipo di dato
numerico più comune è l’intero che può essere rappresentato tramite 4, 8, 16, 32 o 64 bit. I
computer più moderni memorizzano gli interi tramite notazione in complemento a due. Alcuni
computer supportano interi sia senza segno (unsigned in linguaggio C) che con segno (int in
linguaggio C). Per numeri che non possono essere espressi come un intero (per esempio 3,5) si
usa la rappresentazione in virgola mobile che può essere di tre tipi: single precision, double
precision e extended precision (vedi lez.7). Alcuni linguaggi di programmazione permettono
l’uso di numeri decimali come tipi di dato. Le macchine compatibili con questi linguaggi
supportano spesso numeri decimali in hardware, codificando generalmente una cifra decimale
in 4 bit (formato BCD, Binary Coded Decimal).
Il più comune codice di caratteri non numerici è invece l’ASCII.
Per valutare la dimensione da assegnare agli operandi utilizzati nei programmi, possiamo fare
riferimento alla statistica riportata nella figura 8.6 (sempre in riferimento all’insieme dei
programmmi studiati nel paragrafo 8.3.3).
8.11
0.00%
Doubleword
Word
69.24%
74.33%
30.75%
18.79%
Halfword
0.00%
media SPECint92
media SPECfp92
6.88%
Byte
0.01%
0
0.2
0.4
0.6
0.8
Figura 8.6: Frequenza di utilizzo per ogni dimensione del dato.
Nei programmi che utilizzano numeri interi la dimensione di dato più frequente utilizzata è 32
bit, mentre nei programmi che utilizzano numeri floating point la dimensione di dato più
frequentemente utilizzata è 64 bit (con riferimento a SPEC92).
8.6 METODI PER FARE CONFRONTI
Spesso è necessario confrontare due valori e scegliere un percorso di esecuzione tra molti
possibili in base al risultato. Ciò viene fatto di solito mediante un’istruzione di confronto
seguita da una o più istruzioni di salto condizionato. Si possono individuare vari metodi per
testare le condizioni:
•
Metodi basati sui “Condition Codes”: i Condition Codes sono bit di stato (FLAG WORD)
modificati ad ogni ciclo dell’ALU e riflettono lo stato del risultato dell’operazione più
recente. La lettura di questi bit indica se e dove effettuare il salto. Sono
prevalentemente usati per confrontare con zero un certo risultato.
Es.
add r1,r2,r3
bz
label
•
Metodi basati sul “Condition Register” (approccio MIPS): utilizza un registro in cui
viene memorizzato il risultato di un confronto. Questo registro viene successivamente
confrontato con il registro 0 e viene valutato se e dove effettuare il salto.
Es. cmp r1,r2,r3
bne r1,r0,label
•
Istruzione diretta di tipo “Compare and Branch”: in questo caso non vengono utilizzati
né particolari codici né registri di appoggio ma esiste una istruzione diretta che
permette di effettuare sia il confronto che il salto.
Es.
bgt r1,r2,label
8.12
8.6.1 Vantaggi e svantaggi del “Condition Code”
Il vantaggio dei metodi basati sul “Condition Code” è quello di ridurre il numero di istruzioni
utilizzate.
Es. X:
....
....
addi r1,r2,1
bnz X
X:
invece di
….
….
addi r1,r2,1
cmp r1,r0
bne X
Gli svantaggi sono legati alla mancata modifica dei condition codes da parte di alcune
istruzioni e questo può creare ambiguità. Inoltre si genera implicitamente una dipendenza dati
fra l’istruzione che genera il codice e quella che lo usa.
Per esempio in una pipeline (Figura 8.7) si possono generare problemi se cerco di utilizzare
queste due istruzioni in sequenza (la pipeline verrà approfondita nel capitolo 20).
ifetch
read
write
compute
Usa il vecchio CC !
ifetch
Calcolo il nuovo CC
read
write
compute
Figura 8.7: problema di utilizzo di due istruzioni in sequenza in una pipeline.
8.6.2 Distanza di salto nei “Conditional Branch”
Usando la stessa metodologia dei paragrafi precedenti è stata valutata la distribuzione del
numero di bit necessario per rappresentare il displacement nei branch come mostrato in
Figura 8.8.
___media SPECint92 ---mediaSPECfp92
40%
30%
20%
10%
14
12
10
8
6
4
2
0
0%
Figura 8.8: dimensione in bit del displacement nei Branch.
Da questa statistica (sempre in riferimento ai benchmark usati nel paragrafo 8.3.3) si nota
che il 25% dei displacement dei branch conseguenti a confronti che operano su interi, ovvero
8.13
quelli rappresentabili con 3 bit, l’indirizzo target si trova più o meno distante 4 istruzioni dal
salto (in un intervallo che va da +4 a –4 istruzioni). In maniera analoga il 35% dei displacement
utilizzati nei branch per i numeri conseguenti a confronti che operano in floating point sono
rappresentabili con 2 bit. Utilizzando 8 bit per rappresentare il displacement si ha una
copertura quasi totale della casistica dei displacement dei branch.
8.7 TIPO DI INDIRIZZAMENTO NEL “CONDITIONAL BRANCH”
Il tipo di indirizzamento più usato nei Conditional Branch è il “PC-relative” in cui l’indirizzo è la
somma del contenuto del program counter e della costante nell’istruzione (vedi lezione 3),
visto che gli indirizzi target dei branch non si discostano molto dal valore attuale del PC.
LT/GE
7%
GT/LE
7%
EQ/NE
40%
media SPECint92
23%
37%
0%
50%
86%
media SPECfp92
100%
FIG. 8.9: Frequenza di alcuni tipi di confronto nel branch
Figura. 8.9: Frequenza di alcuni tipi di confronto nel branch.
Quando si opera sugli interi il tipo di confronto utilizzato più spesso in appoggio ad
un’istruzione di branch è l’EQUAL/NOT EQUAL come si nota dal grafico in figura 8.9.
Conviene quindi supportare preferibilmente l’ istruzione EQ/NE nei branch.
8.7.1 MIPS:completamento delle istruzioni di “Compare” e “Branch”
Per realizzare le istruzioni di confronto e salto si possono utilizzare vari metodi come
riportato in tab. 8.7.
Tab.8.7: Metodologie di confronto e salto.
1. Compare and Branch
BEQ rs, rt, offset
BNE rs, rt, offset
if R[rs] == R[rt] then PC-relative branch
!=
MIPS Hennessy
and patterson
2. Compare to zero and Branch (native, non pseudoistruzioni !)
BLEZ rs, offset
if R[rs] <= 0 then PC-relative branch
BGTZ rs, offset
>
BLT
<
MIPS LSI *
BGEZ
>=
Logic LR3000
BLTZAL rs, offset
if R[rs] < 0 then branch and link (into R31)
BGEZAL
>=
*(Da “LR3000 and LR3000 A MIPS RISC Microprocessor user’s manual”, 1990)
8.14
Come osservato nei capitoli precedenti può essere sufficiente utilizzare le due istruzioni beq,
bne e slt per effettuare confronti e salti. In implementazioni reali del processore MIPS (es.
LR 3000 della LSI LOGIC) sono supportate anche le istruzioni dirette di compare & branch.
8.7.2 MIPS: riepilogo delle principali istruzioni di jump, branch e compare
Le scelte effettuate per il MIPS sono riassunte in tabella 8.8:
Tab.8.8: Principali istruzioni di branch,jump,compare.
Istruzione
Esempio
beq $1,$2,100
if ($1 == $2)
go to PC+4+100
Significato
Commenti
Equal test; PC relative branch
branch on not eq.
bne $1,$2,100
if ($1!= $2)
go to PC+4+100
Not equal test; PC relative
set on less than
slt $1,$2,$3
if ($2 < $3)
$1=1; else $1=0
Compare less than; 2’s comp.
set less than imm.
slti $1,$2,100
if ($2 < 100)
$1=1; else $1=0
Compare < constant; 2’s comp.
set less than uns.
sltu $1,$2,$3
if ($2 < $3)
$1=1; else $1=0
Compare less than;
natural numbers
set l. t. imm. uns.
sltiu $1,$2,100
if ($2 < 100)
$1=1; else $1=0
Compare < constant;
natural numbers
jump
j 10000
go to 10000
Jump to target address
jump register
jr $31
go to $31
jump and link
jal 10000
$31 = PC + 4;
go to 10000
branch on equal
For switch, procedure return
For procedure call
ESERCIZIO: diversità tra confronti Signed e Unsigned
•Supponiamo che i registri r1, r2, r3 contengano i seguenti valori
r1= 0…00 0000 0000 0000 0001
r2= 0…00 0000 0000 0000 0010
r3= 1…11 1111 1111 1111 1111
•Dopo aver eseguito le seguenti istruzioni, trovare quanto valgono i contenuti dei registri r4,
r5, r6, r7
slt r4,r2,r1 # if (r2 < r1) r4=1; else r4=0
slt r5,r3,r1 # if (r3 < r1) r5=1; else r5=0
sltu r6,r2,r1 # if (r2 < r1) r6=1; else r6=0
sltu r7,r3,r1 # if (r3 < r1) r7=1; else r7=0
il contenuto dei registri risulta quindi:
r4 =0; r5 =1; r6 =0; r7 =0;
8.8 DETTAGLI DELL’ARCHITETTURA DEL SET DI ISTRUZIONI
MIPS
Tra le caratteristiche che contraddistinguono i registri della struttura MIPS si nota che il
registro zero contiene sempre il valore zero anche nel caso in cui si cerchi di sovrascriverlo.
8.15
L’ultimo registro (r31) invece è utilizzato dalle funzioni branch/jump and link per memorizzare
il valore dell’indirizzo di ritorno (PC+4).
Bisogna inoltre tener conto che tutte le istruzioni cambiano tutti i 32 bit del registro
destinazione (incluso la lui, lb, lh) e leggono tutti i 32 bit del registro sorgente (add, sub, and,
or,…).
Per ciò che concerne le istruzioni logiche i numeri che ne sono operandi sono estesi a 32 bit
con zero-padding, ovvero vengono inseriti tutti zeri nei bit più significativi non utilizzati,
mentre per gli operandi di istruzioni aritmetiche sono estesi a 32 bit attraverso l’estensione
del segno.
Analogamente le istruzioni lbu (load byte unsigned) e lhu (load half word unsigned) prevedono
l’estensione attraverso zero-padding mentre le istruzioni lb (load byte) e lh (load half word)
prevedono l’estensione del segno in complemento a 2.
I problemi dovuti all’overflow possono riguardare le istruzioni add, sub, addi, mentre ne sono
estranee addu, subu, addiu, and, or, xor, nor, shifts, mult, multu, div, divu.
8.8.1 Delayed Branches
li
sub
bz
addi
subi
LL: slt
r3, #7
r4, r4, 1
r4, LL
r5, r3, 1
r6, r6, 2
r1, r3, r5
Come si comporta realmente un processore MIPS in presenza di un branch? Nella realtà
l’istruzione che si trova dopo un branch viene sempre eseguita anche se il sato non viene
effettuato. Questo comportamento è causato dalla presenza della pipeline (vedi lez. 20).
Per tener conto di questo problema l’assemblatore del MIPS deve provvedere a modificare il
codice nel caso in cui l’operazione successiva al branch sia stata erroneamente eseguita.
8.8.2 Istruzioni varie dell’architetture MIPS I
•syscall
trasferisce il controllo a codice appartenente al sistema
operativo (modalita’ kernel) nella quale si ha completo
accesso alla macchina
•break
in corrispondenza di questa istruzione si verifica una “trap”
ovvero un trasferimento tipo “system call” verso il codice
dell’ exception handler
•istr. coprocessore
Supporto per i dati floating point
•istruzioni TLB
Supporto per la memoria virtuale
•rfe (return from exeception)
ripristina il precedente stato della interrupt mask e dei bit
di modalita’ kernel user all’interno dello status register al
termine della routine di servizio di un interact
•load word left/right
Supporto per il caricamento di word non-allineate
•store word left/right
Supporto per la scrittura di word non-allineate
ESERCIZIO
8.16
Obbiettivo: vediamo attraverso un esercizio pratico come cambiano le prestazioni apportando
delle modifiche al calcolatore:
Risultati delle misurazioni su una data macchina base:
Op
Freq
Cicli
ALU
50%
1
Load
20%
5
Store
10%
3
Branch
20%
2
/CPI
0.5
1.0
0.3
0.4
____
2.2
%Tempo
23%
45%
14%
18%
Ricordando che CPI (cicli di clock della CPU)= numero di istruzioni nel programma x
numero medio di cicli di clock per istruzione
Di quanto migliorerebbero le prestazioni:
• inserendo una cache che riduca il tempo medio per caricare un dato a 2 cicli ?
Con questa modifica CPI relativo al load si riduce a 0,4 mentre quello totale a 1,6.
• utilizzando una branch-prediction in grado di ridurre di 1 ciclo il tempo del branch ?
Con questa modifica CPI relativo al branch si riduce a 0,2 mentre quello totale a 2
• se fosse possibile eseguire 2 istruzioni aritmetico-logiche in un solo ciclo ?
Con questa modifica CPI relativo all’ ALU si riduce a 0,25 mentre quello totale a 1,95
8.9 CONFRONTI CON ALTRE ARCHITETTURE
Come già detto in precedenza,un alternativa al modello MIPS e quindi alla filosofia RISC è
offerta dalla filosofia CISC che fornisce operazioni più potenti, riduce il numero di istruzioni
eseguite ma causa un ciclo di clock più lungo e CPI più elevato.
Quest’ultimo approccio è quello seguito dai processori VAX che rendono l’assembly più facile e
minimizzano le dimensioni del codice grazie ad una più ampia gamma di istruzioni a
disposizione. Questo fattore ha però come risultato un incremento della lunghezza
dell’istruzioni stesse che spazia tra 1 e 54 byte.
8.9.1 PowerPC indirizzamento tramite indice (indexed addressing) indirizzamento
di tipo update
Il PowerPC,costruito da IBM e Motorola e montato sul Macintosh della Apple, ha forti
analogie con il MIPS: entrambi hanno i registri di 32 bit, le istruzioni lunghe 32 bit ed il
trasferimento dati possibile soltanto tramite operazioni di tipo load e store. La principale
differenza consiste invece in due modi di indirizzamento addizionali (indicizzato e di tipo
update) e in alcune operazioni in più.
8.17
8.9.1.1 Indirizzamento tramite indice(indexed addressing)
Questo indirizzamento permette di sommare valori di due registri.
Per esempio il codice MIPS:
add $to, $ao, $s3
lw
$t1, 0($t0)
nel PowerPC è sostituito da una sola istruzione:
lw
$t1, $a0+$s3
a. Indexed addressing
op
rs
rt
rd
...
Memor y
Register
+
Word
Register
Figura 8.10: Indexed Addressing.
8.9.1.2 Indirizzamento di tipo update
L‘idea di base di questo modo di indirizzamento è quella di avere una nuova versione delle
istruzioni per il trasferimento dei dati che automaticamente incrementi il registro di base in
modo da puntare alla parola successiva ogni volta che viene fatto il trasferimento di un dato.
Dato che il MIPS usa l’indirizzamento a byte e una parola è composta da 4 byte, questo nuovo
modo di indirizzamento è equivalente alla coppia di istruzioni
lw
$t0, 4($s3)
addi $s3, $s3, 4
il PowerPC include per questo un ‘istruzione del tipo
lwu
$t0, 4($s3)
che quindi aggiorna il valore del registro all’interno dell’istruzione di load.
Le istruzioni che il PowerPC implementa oltre a quelle del MIPS sono la load e la store multiplo
che possono trasferire fino a 32 parole in una singola istruzione e che utilizzate in modo
congiunto consentono di riallocare velocemente i dati da una porzione di memoria ad un’altra.
Il PowerPC ha inoltre un particolare registro distinto dagli altri 32 che ha le funzioni di
contatore e che è utilizzato per migliorare le prestazioni nell’esecuzione dei cicli for.
b. Update addressing
op
rs
rt
Register
Address
Memory
+
Figura 8.11: Update addressing.
8.18
Word
8.9.2 Intel 80X86
L’architettura dell’ 80x86 è frutto del lavoro indipendente di molti gruppi di persone ed è in
evoluzione dal suo ingresso nel 1978, con l’aggiunta progressiva di nuove funzioni al set di
istruzioni originale. Le tappe fondamentali della sua evoluzione sono:
1978: L’Intel 8086 e’ annunciato (16 bit architecture).
1980: Viene introdotto l’8087 floating point coprocessor.
1982: Il 286 aumenta lo spazio di indirizzamento a 24 bit, complesso modo di mappatura degli
indirizzi (segmnentazione).
1985: Il 386 porta tutto a 32 bits, paginazione, modo virtuale 8086.
1989: Il 486 integra cpu, coprocessore e cache su un unico chip
vengono aggiunte istruzioni per la multiprogrammazione (test-and-set).
1992: Pentium, 2 pipeline (prima cpu superscalare Intel).
1995: Pentium MMX (introduzione di istruzioni vettoriali e multimediali).
1997: Pentium-Pro, esecuzione fuori ordine (parallelismo a livello di istruzioni).
1998: Pentium-II, altre istruzioni multimediali (SSE). Cache piu’ grandi.
1999: Pentium-III, SSE2.
2001: Pentium-4, pipeline a 20 stadi, trace-cache, branch prediction migliorata, register
renaming, 7 ALU, operazioni SSE2 a 128 bit.
Alcuni commenti famosi su questa architettura:
• “La storia dell’x86 mostra l’impatto della ‘gabbia dorata ’ della compatibilità”
• “Le caratteristiche sono state aggiunte come nel riempire una valigia già chiusa”
• “Un’architettura difficile da spiegare e impossibile da apprezzare”
8.9.3 architettura del processore 386
L’evoluzione si nota chiaramente osservando i registri del 386: il 386 infatti estende tutti i
registri (a parte i registri di segmento) da 16 a 32 bit mettendo una E davanti al nome di
ciascuno per indicare la versione a 32 bit.
32
bit
EAX
GPR0
ECX
GPR1
EDX
GPR2
EBX
GPR3
ESP
GPR4
EBP
GPR5
ESI
GPR6
EDI
GPR7
Operandi (registri)
CS
SS
DS
ES
FS
GS
EIP
EFLAGS
Figura 8.12: Registri utilizzati nel 386.
8.19
8.9.3.1 Combinazioni degli operandi nel 386
Le istruzioni aritmetiche, logiche e di trasferimento dati hanno sempre un operando che
funge sia da sorgente che da destinazione (ad esempio ADD EAX,# 6765 che significa
EAX = EAX + 6765). Inoltre uno degli operandi può essere in memoria a differenza del MIPS
e del PowerPC (ad esempio MOVW EBX,[EDI+ 45] che significa EBX = M[EDI + 45].
Tabella 8.9: Utilizzo dei registri come operandi.
Primo operando
sorgente/destin
azione
Secondo
operando
solo sorgente
Registro
Registro
Registro
Immediato
Registro
Memoria
Memoria
Registro
Memoria
Immediato
8.9.3.2 Modi di indirizzamento del 386
I modi di indirizzamento relativi ai dati in memoria sono sette. Il displacement può essere di 8
o di 32 bit.
Ci sono inoltre delle restrizioni sui registri utilizzabili nei diversi modi come mostrato in
tabella 8.10
Tabella 8.10: Restrizioni sui registri.
Modo
Descrizione
Restrizione sui registri
Codice MIPS eqivalente
Register indirect
L’indirizzo e’ un registro
No ESP o EBP
lw $s0,0($s1)
Based mode con
displacement a 8
o 32 bit
L’indirizzo e’ il contenuto del
registro
di
base
piu’
il
displacement
No ESP o EBP
lw $s0,100($s1)
# displ<= 16 bit
Base plus scaled
index
L’indirizzo e’
base+(2scale x index)
dove ‘scale’ puo’ valere
0, 1 ,2 3
Base: qualsiasi GPR
Index: no ESP
sll $t0,$s1,2
add $t0,$t0,$s1
lw $s0,0($t0)
Base plus scaled
index
con
displacement a 8
o 32 bit
L’indirizzo e’
base+(2scale x index) +
displacement
dove ‘scale’ puo’ valere
0, 1 ,2 3
Base: qualsiasi GPR
Index: no ESP
sll $t0,$s1,2
add $t0,$t0,$s1
lw $s0,100($t0)
# displ<= 16 bit
Quasi tutte le operazioni possono lavorare su dati a 8 bit o di dimensioni maggiori (16 o 32
bit) a seconda del modo utilizzato. Alcuni programmi devono chiaramente operare su dati di 8,
16 e 32 bit e per questo il 386 fornisce un modo efficiente di specificare la loro dimensione
senza estendere il codice in modo significativo. La dimensione è specificata da uno dei bit del
registro di segmento del codice e per sovrascrivere l’opzione occorre precedere l’istruzione
da un prefisso di 8 bit che specifica all’elaboratore che il dato utilizzato ha dimensione
diversa da quella predefinita (16 o 32 bit). Un altro metodo di specificare la dimensione del
dato è quello di modificare un bit del registro CS.
8.20
8.9.3.3 Prefissi delle istruzioni nel 386
I prefissi possono essere utilizzati anche per modificare i registri di segmento predefiniti,
per impedire l’ accesso al bus nella realizzazione di un semaforo per trasferimenti
atomici(486) o per ripetere l’istruzione successiva fino a quando il registro ECX scendeva a
zero. Un altro prefisso serve infine per poter modificare la dimensione degli indirizzi.
8.9.3.4 esempi di istruzioni nel 386
Le operazioni sui numeri interi del 386 possono essere suddivise in quattro categorie:
• Istruzioni per lo spostamento dei dati (move, push, pop) (punti 4, 5, 6 in tab. 8.11).
• Istruzioni aritmetiche, logiche e di confronto (punti 7, 8 in tab. 8.11).
• Istruzioni di controllo di flusso (salti, chiamate a procedura e ritorno) (punti 1, 2, 3 in
tab. 8.11).
• Istruzioni per la gestione delle stringhe (9).
N.B: si supportano anche operazioni che nella realtà sono usate raramente.
Tabella 8.11: Istruzioni supportate dal 386.
Function
Instruction
JE name
If equal (CC) EIP = name};
EIP – 128 ≤ name < EIP + 128
2
JMP name
{EIP = NAME};
3
CALL name
SP = SP – 4; M[SP] = EIP + 5; EIP = name;
4
MOVW EBX,[EDI + 45]
EBX = M [EDI + 45]
PUSH ESI
SP = SP – 4; M[SP] = ESI
POP EDI
EDI = M[SP]; SP = SP + 4
ADD EAX,#6765
EAX = EAX + 6765
TEST EDX,#42
Set condition codea (flags) with EDX & 42
MOVSL
M[EDI] = M[ESI];
EDI = EDI + 4; ESI = ESI + 4
1
5
6
7
8
9
8.21
8.9.3.5 Riepilogo operazioni dell’architettura x86
Tabella 8.11: Riepilogo operazioni dell’architettura x86.
ISTRUZIONE
Significato
Controllo
Salti condizionati e incondizionati
JNZ, JZ
Salto condizionato a EIP+offset_8_bit;
JMP
Salto incondizionato; il displacement puo’ essere a 8 o a 16 bit
CALL
Chiamata a procedura con displ .. a 16 bit; ind. ritorno nello stack
RET
Preleva dallo stack l’ind di ritorno ed esegue il salto
LOOP
Ciclo: decrementa ECS e salta a EIP+offset_8_bit se ECX != 0
Trasferimento dati
Spostamento di dati tra registri e registri e memoria
MOV
Sposta un dato da registro a registro o da registro a memoria
PUSH, POP
Mette un dato nello stack ; preleva un dato dallo stack
LES
Carica nel registro ES
Aritmetiche logiche
Operazioni aritmentiche e logiche sui dati nei registri o in memoria
ADD, SUB
Somma/sottrae il sorgente dalla destinazione; formato
CMP
Confronta il sorgente con la destinazione; formato
SHL, SHR, RCR
Shift a sinistra/destra; rotazione verso destra con uso del
CBW
Converte il byte meno significativo di EAX in una word a 16 bit
TEST
Modifica i FLAG facendo un finto AND fra sorgente e destinazione
INC, DEC
Incrementa/decrementa; formato
OR, XOR
OR logico; OR esclusivo; formato
Stringhe
Trasferim . fra stringhe; lunghezza data dal prefisso di ripetizione
MOVS
Copia un byte dalla stringa puntata da ESI a quella puntata da E DI; i due puntatori
vengono incrementati; puo’ essere ripetuta
LODS
Carica un byte/word/ double_word in EAX
JNE=JNZ , JE=JZ
reg/mem
reg /mem
carry
reg/mem
reg/mem
Nel 386 i salti condizionati si basano sui codici di controllo o flag, modificati in seguito ad
un’operazione esplicitamente con l’istruzione test. Inoltre gli indirizzi di salto PC-relative
devono essere specificati come numero di byte poiché a differenza del MIPS, nel 386 non è
vero che tutte le istruzioni sono lunghe 32 bit.
Le istruzioni per la gestione delle stringhe nella maggior parte dei programmi non vengono
utlizzate essendo in generale più lente delle procedure software equivalenti (vedi paragrafo
8.9.5).
8.9.4 80x86: formati di istruzione
La codifica delle istruzioni è molto complessa, con molti formati diversi per le istruzioni, che
variano da un byte a 17 byte (è considerata la peggiore caratteristica di questa architettura).
La figura mostra il formato di molte delle istruzioni usate. Il byte del codice operativo
contiene solitamente un bit che indica se l’operando è da 8 o 32 bit. Il codice operativo di
alcune istruzioni include il modo di indirizzamento ed il registro; questo si verifica in molte
istruzioni. Altre invece utilizzano un “postbyte” o extra byte per il codice operativo, che
contiene le informazioni relative al modo di indirizzamento; questo byte aggiuntivo è presente
in molte delle istruzioni che accedono alla memoria. Il modo di indirizzamento base con indice
usa un secondo byte aggiuntivo.
8.22
a. JE EIP + displacement
4
4
JE
Condition
8
Displacement
b. CALL
8
CALL
32
Offset
c. MOV EBX, [EDI + 45]
1 1
8
6
r-m
d w
MOV
postbyte
8
Displacement
d. PUSHESI
5
3
Reg
PUSH
e. ADD EAX, #6765
4
3 1
ADD Reg w
f. TEST EDX, #42
7
1
TEST
w
32
Immediate
32
8
Postbyte
Immediate
Figura 8.13: Formati di istruzione.
8.9.5 conclusioni sull’80x86
L’ Intel ha costruito un processore a 16 bit due anni prima di quelli dei suoi
concorrenti(Motorola 68000), ma in generale realizzare l’ 8086 è più difficile di un
calcolatore di tipo MIPS. Quello che all’ 80x86 manca in stile è però compensato dalla
diffusione,rendendolo apprezzabile se visto dalla giusta prospettiva. Ciò che lo salva è che i
componenti dell’architettura usati più frequentemente non sono troppo difficili da
implementare, permettendo di migliorare rapidamente le prestazioni dei programmi. Per fare
ciò i compilatori devono però evitare le parti dell’ architettura difficili da implementare.
ESEMPIO: Attenzione: spesso le istruzioni più potenti non offrono le migliori prestazioni.
Nella tabella seguente sono mostrati tre metodi per effettuare il trasferimento di dati da 32
bit da una porzione di memoria ad un’altra. Nella prima colonna è riportata la velocità di
trasferimento dati per un processore pentium 133, DRAM EDO da 60 ns e cache da 256 KB
che utilizza la funzione move ripetuta (REPS MOVE). La seconda e la terza mostrano invece
come la velocità di trasferimento sia maggiore utilizzando le istruzioni standard (load e store)
presenti su tutti i calcolatori.
8.23
REPS MOVE
LOAD/STORE in
registri
+unrolling
LOAD/STORE in
registri FP (piu’ lunghi)
40 MB/s
60 MB/s
80 MB/s
Figura 8.14: Confronto tra metodi di trasferimento.
8.9.6 errori e trabocchetti (esempio)
Contrariamente a quanto si possa pensare programmare in Assembly non sempre permette di
ottenere prestazioni migliori come si deduce dal confronto effettuato tra le prestazioni della
versione in linguaggio C ed assembler delle procedure ordina e scambia
Linguaggio
TCPU
Assembly
37.9s
C
25.3s
Figura 8.15: Confronto tra linguaggi Assembly e C.
8.24
LEZIONE 9
Eccezioni ed interrupt
9.1 INTRODUZIONE
Le eccezioni sono eventi che cambiano il normale flusso di esecuzione delle istruzioni. Sono
utilizzate per gestire eventi inattesi e richieste di servizi da parte dei dispositivi di I/O,
trasferendo il controllo dell’esecuzione del programma ad una routine di gestione (v. Figura
9.1).
user program
Exception
return from
exception
normal control flow:
sequential, jumps, branches, calls, returns
Figura 9.1. Meccanismo di gestione di un’eccezione.
9.2 TERMINOLOGIA
Tipicamente si distingue fra eccezioni (traps o syscall) ed interruzioni (interrupts). Le
eccezioni sono causate da eventi interni al processore (ad es. un overflow aritmetico) mentre
le interruzioni sono causate da eventi esterni, e vengono utilizzate dai dispositivi di I/O per
comunicare al processore informazioni sulle operazioni di input/output.
Tra i due termini comunque non c’è molta distinzione, ad esempio molti autori e molte
architetture utilizzano il termine “interrupt” per identificare entrambi gli eventi. Ad esempio
nell’architettura Intel 80x86 si parla di interrupt per tutti gli eventi.
Nel caso dell’architettura MIPS (v. anche tab. 9.1), invece, si parla di:
• eccezione: quando si parla di un cambiamento inatteso del flusso di controllo senza
voler specificare se sia dovuto a cause interne o esterne;
• interrupt: eccezioni causate da eventi esterni .
Tabella 9.1. Classificazione usata nel MIPS.
TIPO DI EVENTO
Richiesta di un dispositivo di I/O
Chiamata al sistema operativo
programma utente
Overflow aritmetico
Uso di un’istruzione indefinita
Malfunzionamento dell’hardware
Malfunzionamento dell’hardware
da
parte
di
9.1
un
PROVENIENZ
A
Esterna
Interna
TERMINOLOGIA MIPS
Interruzione
Eccezione
Interna
Interna
Interna
Esterna
Eccezione
Eccezione
Eccezione
Interruzione
9.3 PRINCIPALI DIFFERENZE TRA INTERRUPT ED ECCEZIONI
La differenza principale tra le eccezioni interne e le eccezioni esterne (interrupt) è che le
prime sono sincronizzate con il programma, le seconde invece non lo sono.
Questo significa che, se il programma viene rieseguito milioni di volte con lo stesso input, le
eccezioni si verificano negli stessi punti e ogni volta; invece gli interrupt dipendono, per
esempio, da quando una persona al terminale preme il tasto “invio”.
Il motivo della riproducibilità delle eccezioni a differenza degli interrupt è dovuta al fatto
che solo le prime sono direttamente causate dal programma.
Come accennato, altra differenza fondamentale è quella dovuta alle cause che li provocano: gli
interrupt sono causati da cause esterne al processore, mentre invece le eccezioni sono
riconducibili ad eventi direttamente gestiti dal processore.
9.4 ROUTINE
HANDLER)
DI
GESTIONE
DELL'ECCEZIONE
(EXCEPTION
Nel progettare l’unità di controllo si deve fare molta attenzione a tenere in considerazione il
problema delle eccezioni. Infatti, tentare di aggiungere la gestione delle eccezioni potrebbe
ridurre notevolmente le prestazioni e rendere più difficile l’implementazione dell’unità stessa.
Per quanto riguarda le procedure per la gestione dell'eccezione esistono tre approcci diversi
in base all'architettura:
• Vettore di Interruzione (approccio tradizionale)
• Tabella della Routine di Gestione (approccio RISC)
• Salto ad indirizzo fisso (approccio MIPS)
9.5 VETTORE DI INTERRUZIONE
Il vettore di interruzione non è altro che l’indirizzo della routine di gestione dell’eccezione.
Per ogni tipo di eccezione esiste una routine specifica e per ciascuna routine può essere
specificato un indirizzo diverso. Tali indirizzi si memorizzano in una tabella chiamata tabella
dei vettori di interruzione (Figura 9.2). Nel momento in cui si verifica un’eccezione si
preleverà da tale tabella il corrispondente vettore. In corrispondenza di questa operazione il
processore non eseguirà più il codice del mio programma, ma quello specificato nella routine di
gestione.
Sia 'base' l'indirizzo base di questa tabella, nella fase di gestione dell’eccezione l'indirizzo di
PC (Program Counter) diventerà: MEM[base + causa*4].
Questo metodo viene utilizzato da processori quali Motorola 68000 e Intel 80x86, e già
molto tempo fa veniva utilizzato da sistemi come IBM 370 e Vax.
9.2
base
ind. routine 0
ind. routine 1
ind. routine 2
causa*4
…
Vettore di Interruzione
Routine di
Gestione dell’Eccezione
ind. routine causa
…
ind. routine m
Tabella dei
Vettori di Interruzione
Figura 9.2. Tabella dei vettori di interruzione.
9.6 TABELLA DELLA ROUTINE DI GESTIONE
In questo tipo di approccio, le routine di gestione associate ad ogni causa vengono
memorizzate direttamente in una tabella chiamata appunto tabella della routine di gestione
(Figura 9.3). Quando si verifica un’eccezione si preleva direttamente dalla tabella la routine
associata all’eccezione. Chiaramente, in questo caso la routine deve essere particolarmente
corta perché deve essere contenuta in una locazione di memoria limitata.
Sia 'base' l'indirizzo base di questa tabella, nella fase di gestione dell’eccezione l'indirizzo di
PC diventerà: MEM[base + causa*16].
Questo metodo è utilizzato da processori quali SunSparc, HP PA, Motorola M88K.
base
Routine 0
Routine 1
Routine 2
…
Routine di Gestione
causa*16
Routine causa
…
Routine m
Tabella delle
Routine di Gestione
Figura 9.3. Tabella della Routine di Gestione.
9.7 SALTO AD INDIRIZZO FISSO
Il salto ad indirizzo fisso è un metodo di gestione delle eccezioni che prevede, qualora si
verifichi un’eccezione, che il processore interrompa il programma in esecuzione per poi
lanciare la routine di gestione che si trova ad un indirizzo fisso, che nel MIPS vale sempre
0x8000’0080 (Figura 9.4). In questo approccio non viene usato lo stack per il salto; la routine
di gestione è unica e deve analizzare i vari casi di eccezioni ogni volta che si presentano.
Nella fase di gestione dell’eccezione l’indirizzo di PC sarà: 0x8000’0080.
9.3
Per distinguere la causa dell’eccezione si usa un registro di appoggio chiamato “cause” (causa),
la cui trattazione è rimandata al par. 9.8.3.
causa
0x8000’0080
…
Routine di Gestione
Figura 9.4. Salto ad indirizzo fisso.
9.8 GESTIONE DI ECCEZIONI ED INTERRUZIONI
La prima operazione che deve eseguire una routine di gestione delle eccezioni è salvare lo
stato in cui si trova il processore al verificarsi dell’eccezione. Il processore MIPS ha a
disposizione quattro registri speciali (a 32 bit) per il salvataggio dello stato (tab. 9.2).
Questi registri si trovano in una parte della CPU chiamata coprocessore 0.
Tabella 9.2. Registri del coprocessore 0.
NOME
REGISTRO
NUMERO
REGISTRO
BadVAddr
8
Stato
Causa
EPC
12
13
14
USO
Registro contenente l’indirizzo di memoria a cui è stato fatto
riferimento
Maschera delle interruzioni e bit di abilitazione
Tipo dell’interruzione e bit dell’interruzione pendente
Registro contenente l’indirizzo dell’istruzione che ha causato
l’interruzione
9.8.1 Registro di Stato: modalità user/kernel
Il sistema operativo è un programma speciale che ha il compito di gestire l’interfacciamento
hardware/software e le risorse del sistema, utilizzando una modalità privilegiata chiamata
“modalità kernel”; esiste un’altra modalità chiamata “ modalità utente” (o “user”). La modalità
kernel permette di accedere direttamente a tutte le risorse del calcolatore, mentre la
modalità utente, utilizzata da tutti gli altri software, non ha questo privilegio.
Al verificarsi di un’eccezione il processore:
1) salva l’indirizzo dell’istruzione responsabile dell’eccezione nell’EPC (Exception
Program Counter)
2) salva nel registro Causa il tipo di eccezione
3) eventualmente se c’è un indirizzo di memoria al quale è stato fatto riferimento
viene salvato nel registro BadVAddr
4) modifica opportuni bit del registro di stato (vedi par. 9.8.2)
9.4
5) trasferisce il controllo alla routine di gestione (nel kernel, non nello spazio di
indirizzamento dell’utente).
Questo codice esamina la causa dell’eccezione ed esegue un salto alla porzione appropriata del
sistema operativo che, in risposta all’eccezione, termina il processo che l’ha provocata o
svolge una determinata azione.
Il sistema operativo provvede poi a fornire un determinato servizio al programma utente, e a
seguire l’azione predeterminata in risposta alla causa dell’eccezione o a terminare l’esecuzione
del programma segnalando un errore. Dopo aver compiuto le azioni necessarie in risposta
all’eccezione, il sistema operativo può terminare il programma utente o riprenderne
l’esecuzione, utilizzando EPC per determinare lo stato da cui ripartire.
9.8.2 Registro di Stato
La figura 9.5 mostra i campi principali del registro Stato:
8
5
15
K
Maschera
delle interruzioni
4
E
Vecchi
3
K
2
E
Precedenti
1
K
0
E
Attuali
Figura 9.5. Campi del registro Stato.
Con riferimento al processore LR 33000 della LSI Logic, una implementazione commerciale
del processore MIPS, il campo maschera delle interruzioni contiene un bit per ciascuna delle
sei possibili sorgenti di interruzione hardware e delle due possibili sorgenti di interruzione
software; un bit a 1 abilita l’interruzione corrispondente, mentre un bit a 0 la disabilita. I 6
bit meno significativi del registro Stato implementano uno stack di profondità tre per i bit
kernel/utente (K) e abilitazione delle interruzioni (E).
Il bit kernel/utente vale 0 se il programma aveva richiesto servizi al kernel (nucleo del
sistema operativo), ed era quindi in esecuzione codice del kernel, quando si è verificata
l’interruzione, e 1 se era in modalità utente; se il bit di abilitazione delle interruzioni è a 1 le
interruzioni sono abilitate, se è a 0 sono disabilitate. Quando si verifica un’interruzione questi
6 bit sono scalati a sinistra di 2 posizioni, per cui i bit attuali diventano i bit precedenti, ed i
bit precedenti diventano bit vecchi (i bit vecchi vengono scartati). Entrambi i bit attuali sono
posti a 0, per cui il gestore delle interruzioni viene eseguito inizialmente nel kernel e con le
interruzioni disabilitate.
9.8.3 Registro Causa
La figura 9.6 mostra i campi principali del registro Causa:
15
10
Interruzioni
pendenti
5
2
Codifica
delle eccezioni
Figura 9.6. Campi del registro Causa.
Nei processori MIPS reali questo registro contiene dei campi aggiuntivi che riportano, ad
esempio, se l’istruzione che ha causato l’interruzione era eseguita in un branch delay slot
(viene eseguita l’istruzione che segue immediatamente il salto anche se questo non viene
fatto), quale coprocessore ha causato l’eccezione oppure se c’è un’interruzione software
pendente. Questa parte sarà approfondita nel capitolo 20 quando verrà trattata la pipeline.
9.5
I sei bit delle interruzioni pendenti corrispondono alle sei sorgenti di interruzione; un bit
assume il valore 1 quando si verifica un’interruzione non ancora servita del corrispondente
livello. Il campo codifica delle eccezioni descrive la causa dell’eccezione secondo la codifica
mostrata nella tabella 9.3.
Tabella 9.3. Codifica delle cause delle eccezioni.
NUMERO
NOME
0
4
INT
ADDRL
5
6
7
8
9
10
12
ADDRS
IBUS
DBUS
SYSCALL
BKPT
RI
OVF
DESCRIZIONE
Interruzione esterna
Eccezione dovuta ad errore di indirizzamento (caricamento o prelievo di
un’istruzione)
Eccezione dovuta ad errore di indirizzamento (memorizzazione)
Errore sul bus durante il prelievo di un’istruzione
Errore sul bus durante il caricamento o la memorizzazione di un dato
Eccezione dovuta ad una chiamata di sistema
Eccezione dovuta ad un breakpoint
Eccezione dovuta ad un’istruzione riservata
Eccezione dovuta ad un overflow aritmetico
9.9 INTERRUZIONI PRECISE/IMPRECISE
Un ‘interruzione che conserva lo stato della macchina, come se il programma avesse eseguito
fino all’istruzione “colpevole” esclusa, viene detta interruzione precisa, ed ha le seguenti
proprietà:
1. Il PC è salvato in un posto noto
2. Tutte le istruzioni precedenti a quella puntata dal PC sono state eseguite
completamente.
3. Nessuna istruzione successiva a quella puntata dal PC è stata eseguita.
4. Lo stato di esecuzione dell’istruzione puntata dal PC è noto.
In questo modo non si impedisce l’inizio dell’esecuzione delle istruzioni successive a quella
puntata dal PC, ma ogni cambiamento che esse apportano ai registri o alla memoria deve
essere annullato prima dell’interruzione.
Questa è una posizione adottata nei calcolatori IBM; ha il vantaggio di rendere il codice di
sistema trasportabile senza problemi su un’implementazione diversa dalla stessa architettura,
ma allo stesso tempo è difficile da implementare in presenza di pipeline, out-of-order
execution (v. Cap. 20).
Le interruzioni che non hanno queste caratteristiche vengono dette interruzioni imprecise; in
questo caso è il software di sistema che deve occuparsi di scoprire in che stato il sistema si
trova e quindi prendere le opportune decisioni.
I processori MIPS utilizzano questo tipo di interruzioni. Le macchine con interruzioni
imprecise solitamente riversano una gran quantità di stati interni sulla pila, per dare al
sistema operativo la possibilità di capire cosa stia succedendo.
Questa soluzione ha il vantaggio di snellire l’hardware del microprocessore nei casi più
frequenti, ma il fatto di dover salvare grandi quantità di informazioni in memoria ad ogni
interruzione, rende le interruzioni e i ripristini molto lenti. Ciò porta ad avere delle CPU
superscalari molto veloci che spesso non sono adatte a lavorare in real time a causa del fatto
che la gestione delle interruzioni è lenta.
Alcuni processori sono progettati in modo tale che alcune interruzioni e operazioni di trap
siano precise e altre no; ad esempio avere interruzioni di I/O precise e trap imprecise non è
9.6
grave, in quanto non si dovranno fare tentativi di far ripartire il processo in esecuzione.
Alcune macchine hanno un bit che può essere impostato per fare in modo che tutte le
interruzioni diventino precise; il lato negativo dell’impostare questo bit è che si forza la CPU a
tener traccia di ogni cosa che stia facendo, e a mantenere copie dei registri così che possa
generare interruzioni precise in ogni istante; tutto questo sovraccarico è di grande impatto
sulle prestazioni.
Avere interruzioni precise significa avere una logica delle interruzioni all’interno della CPU
estremamente complessa, e di conseguenza aumentare la complessità della progettazione
dell’unità di controllo; il tutto rende la CPU più lenta.
Il motivo principale per cui in alcuni processori si evita l’uso degli interrupt precisi è legato
essenzialmente a obiettivi di prestazioni elevate. D’altro canto, interruzioni imprecise rendono
il sistema operativo troppo lento e complicato.
9.10 INSERIMENTO DELLA LOGICA PER GESTIRE LE ECCEZIONI
Il processore MIPS finora studiato può essere descritto come una macchina a stati finiti
(finite state machine, FSM). L’unità di controllo a stati finiti corrisponde essenzialmente ai
cinque passi necessari al processore per eseguire un’istruzione, dove ciascun passo della
macchina a stati finiti corrisponde ad un ciclo di clock:
• IF (Instruction Fetch): prelievo dell’istruzione dalla memoria istruzioni
• ID (Instruction Decode): decodifica dell’istruzione e lettura dei registri
• EX (Execute): esecuzione dell’istruzione
• MEM (Memory): lettura/scrittura dei dati da/verso la memoria dati
• WB (Write Back): scrittura del risultato nei registri
Esistono cinque classi di istruzioni come mostrato dalla tabella 9.4, e ciascuna di esse richiede
passi diversi per essere eseguita.
Tabella 9.4. Schema riassuntivo dei passi intrapresi durante l’esecuzione delle diverse classi di istruzioni.
NOME DEL
PASSO
Prelievo
dell’istruzione
Decodifica
dell’istruzioni
e lettura dei
registri
Esecuzione
istruzione
Lettura e
scrittura dati
Scrittura
risultato
AZIONE PER
ISTRUZIONE
DI TIPO-R
AZIONE PER
ISTRUZIONI DI
LETTURA DATI
AZIONE PER
ISTRUZIONI DI
SCRITTURA DATI
AZIONE PER
SALTI
CONDIZIONATI
AZIONE PER SALTI
INCONDIZIONATI
IR <= MEM[PC]
PC <= PC + 4
A<=R[rs]
B<= R[rt]
S <= PC + SX
S <= A fun B
R[rd] <= S
S <= B + SX
S <= B + SX
M <= MEM[S]
MEM[S] <= A
R[rs] <= M
if A = B
then PC <= S
S <= PC op ZX
PC <= S
La macchina a stati finiti è composta da diverse parti: dato che i primi due passi di esecuzione
sono identici in tutte le istruzioni, i primi due stati della macchina saranno comuni a tutte le
operazioni; invece i passi da 3 a 5 dipendono dal tipo di istruzione da eseguire.
Al termine dell’esecuzione dell’ultimo passo di una particolare classe di istruzioni, la macchina
dovrà ritornare allo stato iniziale per cominciare a prelevare l’istruzione successiva (Figura
9.10)
9.7
Ciascun nodo rappresenta uno stato della macchina, mentre gli archi rappresentano le
transizioni da uno stato all’altro.
I nodi, per una più facile comprensione della macchina, sono etichettati da 0000 a 0111 e
contengono al proprio interno le operazioni che vengono svolte.
Richiamiamo brevemente i tre formati delle istruzioni del MIPS.
Per le istruzioni R-type (Figura 9.7) ci sono 6 campi:
• op: operazione base dell’istruzione, chiamata tradizionalmente codice operativo o
opcode
• rs: primo operando sorgente (registro)
• rt: secondo operando sorgente (registro)
• rd: registro destinazione che contiene il risultato dell’operazione
• shamt: valore dello scalamento (shift amount)
• funct: funzione. Seleziona una variante specifica dell’operazione base definita in op
op
rs
rt
rd
6 bit
5 bit
5 bit
5 bit
shamt
5 bit
Figura 9.7. Campi per le istruzioni di formato R-type.
funct
6 bit
Per il formato I (usato nelle istruzioni di lettura e scrittura della memoria (LW, SW e BEQ)
(Figura 9.8) ci sono 4 campi, i primi 3 sono gli stessi del precedente tipo (op, rs e rt), ma in
questo caso rt rappresenta una costante di offset, mentre l’ultimo è il campo address (SX),
che indica una locazione di memoria.
op
6 bit
rs
5 bit
rt
5 bit
address
16 bit
Figura 9.8. Campi per le istruzioni di tipo I.
Per le istruzioni di formato J ci sono 2 campi (Figura 9.9), op e il campo per l’indirizzo di salto,
address (ZX).
op
6 bit
address
26 bit
Figura 9.9. Campi per le istruzioni di tipo J.
La macchina quando si trova all’inizio nello stato 0000 preleva dalla memoria l’istruzione da
eseguire e la carica in IR (IR <= MEM[PC] ) e aggiunge 4 al PC in modo da far puntare al ciclo
successivo la prossima istruzione (PC <= PC + 4).
A questo punto transita nello stato 0001 il quale effettuerà la decodifica dell’istruzione
prelevata nello stato precedente.
In questo stato e nel precedente non si conosce ancora quale sia l’istruzione, quindi si possono
compiere solamente azioni applicabili a tutte le operazioni (come prelevare l’istruzione nello
stato 0000) o che non siano dannose, nel caso in cui l’istruzione non sia quella ipotizzata.
Quindi in questo stato si possono leggere i due registri rs e rt dell’istruzione, poiché non è
dannoso leggerli anche nel caso in cui non siano richiesti.
Quindi i campi rs e rt vengono letti dal register file e memorizzati nei registri temporanei A
(A <= R[rs]) e B (B <= R[rt]). Viene anche calcolato l’indirizzo di destinazione dei salti
9.8
condizionati, il che non è dannoso dal momento che si può ignorare tale valore se l’istruzione
non sia di branch (S <= PC+SX, dove S è un registro d’appoggio).
Dopodichè si passerà ad un diverso stato in base alla classe di istruzioni da eseguire.
Quando l’istruzione da eseguire è un salto incondizionato (J) si usa ZX e il registro PC per
calcolare l’indirizzo della prossima istruzione da eseguire, e questo viene caricato in S.
L’indirizzo è ottenuto concatenando i 26 bit dell’indirizzo con i 4 bit più significativi del PC
(S <= PC op ZX). Successivamente, prima di tornare nello stato di partenza, il contenuto di S
verrà caricato in PC.
Le istruzioni di lettura e scrittura seguono due stati diversi(1000 e 1011), ma con la stessa
funzione.
Il registro B è usato insieme a SX per calcolare l’offset (S <= B+SX) della memoria in cui il
MIPS andrà a prelevare o scrivere il contenuto.
IR <= MEM[PC]
PC <= PC + 4
0000
“instruction fetch”
Write-back
A<=R[rs]
“decode”
B<= R[rt]
S <= PC +SX
0001
R-type
J
Memory
S <=A fun B S<= PC op ZX
0100
0110
LW
BEQ
SW
S <= B + SX
1000
Execute
M <= MEM[S]
1001
S <= B + SX
1011
If A = B
then PC <= S
0010
MEM[S] <= A
1100
R[rd]<= S
0101
PC <= S
0111
R[rs]<= M
1010
R[rt]
<= M
1010
Figura 9.10. Macchina a stati finiti che descrive il MIPS.
Se si tratta di SW la macchina passa nello stato 1100, memorizza il contenuto di A nella
posizione di memoria indirizzata da S (MEM[S] <= A) e ritorna allo stato iniziale.
Se si tratta di una LW la macchina passa nello stato 1001, preleva il contenuto della memoria
all’indirizzo S e lo carica in un registro di appoggio M (M <= MEM[S]).
Passando allo stato 1010 il contenuto di M viene scritto nel registro rs (R[rs] <= M) e poi c’è il
ritorno allo stato iniziale.
Qualora l’istruzione da eseguire è un salto condizionato (BEQ) la macchina a stati finiti
transita nello stato 0010 e si effettua il controllo per determinare se il contenuto di A è
uguale al contenuto di B (if A=B).
9.9
Se il confronto dà esito positivo PC assumerà il valore di S (PC <= S), che contiene l’indirizzo di
destinazione del salto calcolato nello stato precedente e c’è il passaggio allo stato iniziale.
Altrimenti ci sarà direttamente la transizione allo stato iniziale senza eseguire altre
operazioni. Il grafo della macchina a stati finiti della figura 9.11 mostra l’aggiunta dello stato
1101 come sesta uscita dallo stato 0001.
Quando si verifica un’eccezione di tipo “Undefined Instruction” questa viene riconosciuta
nello stato 0001 e non avendo uno stato successivo dove andare quando c’è un op-code
sconosciuto, la macchina a stati finiti si porta nel nuovo stato 1101.
Le operazioni dello stato 1101 da eseguire sono: i) caricare l’indirizzo dell’istruzione che ha
causato l’eccezione in EPC (EPC <= PC-4), ii) mettere in PC l’indirizzo della routine di gestione
dell’eccezione (PC <= eh_addr) e iii) mettere nel registro causa la causa dell’eccezione
(Cause <= 10 (RI)). Infine, si torna allo stato iniziale.
IR <= MEM[PC]
PC <= PC + 4
0000
“instruction fetch”
undefined instruction
EPC Å PC- 4
PC Åeh_addr
CauseÅ10(RI)
Write-back
A<=R[rs] “decode”
B<= R[rt]
S <= PC +SX
0001
other
R-type
Memory
S <=A fun B
0100
J
S <=PC op ZX
0110
LW
SW
S <= B + SX
1000
Execute
M <= MEM[S]
1001
1101
BEQ
S <= B + SX
1011
If A = B
then PC <= S
0010
MEM[S] <= A
1100
R[rd]<= S
0101
PC <= S
0111
R[rs]<= M
1010
R[rt]
<= M
1010
Figura 9.11. Macchina a stati finiti con l’inserimento della gestione per l’eccezione “undefined instruction”.
La figura 9.12 mostra l’inserimento dello stato 1110 necessario per gestire l’eccezione di tipo
“overflow aritmetico”. Il nuovo stato può essere raggiunto dallo stato 0100 in caso di overflow
e la macchina esegue le seguenti operazioni: caricare l’indirizzo dell’istruzione che ha causato
l’eccezione in EPC (EPC <= PC-4), mettere in PC l’indirizzo della routine di gestione
dell’eccezione (PC <= eh_addr) e mettere nel registro causa la causa dell’eccezione
(Cause <= 12 (Ovf)). Infine, si torna allo stato iniziale.
9.10
IR <= MEM[PC]
PC <= PC + 4
0000
“instruction fetch”
undefined instruction
“decode”
EPC Å PC - 4
PC Å eh_addr
Write-back
Cause Å12 (Ovf)
1110
R-type
Memory
S <=A fun B
0100
EPC Å PC- 4
PC Åeh_addr
CauseÅ10(RI)
A<=R[rs]
B<= R[rt]
S <= PC +SX
other
0001
J
S <=PC op ZX
0110
LW
SW
S <= B + SX
1000
S <= B + SX
1011
overflow
Execute
M <= MEM[S]
1001
1101
BEQ
If A = B
then PC <= S
0010
MEM[S] <= A
1100
R[rd]<= S
0101
PC <= S
0111
R[rs]<= M
1010
R[rt]
<= M
1010
Figura 9.12. Macchina a stati finiti con l’inserimento della gestione per l’eccezione “overflow aritmetico”.
9.11 GESTORE DELLE INTERRUZIONI
Le seguenti istruzioni sono utilizzate per la lettura e/o la scrittura dei registri del
coprocessore 0:
• mtc0 xx, $2
→ xx <- $2
memorizza nel coprocessore 0 il contenuto del registro $2
• mfc0 $2, xx
→ $2 <- xx
memorizza nel registro $2 il contenuto del coprocessore 0
• lwc0 xx, 100($2)
→
xx <- MEM[$2 + 100]
carica nel coprocessore 0 una parola prelevata dalla memoria
• swc0 xx, 100($2)
→
MEM[$2 + 100] <- xx
salva nella memoria una parola prelevata dal coprocessore 0
Il codice dell’esempio che segue descrive un semplice gestore delle interruzioni.
Per prima cosa il gestore delle interruzioni salva il contenuto dei registri $a0 e $a1, che userà
in seguito per passare gli argomenti alla procedura di gestione.
Il gestore delle interruzioni non può memorizzare sullo stack i vecchi valori di questi registri,
come farebbe una normale procedura, perché la causa dell’interruzione potrebbe essere un
riferimento alla memoria attraverso un valore non consentito (ad esempio 0) del puntatore allo
stack. Invece di usare lo stack il gestore delle interruzioni salva il contenuto dei registri in
due locazioni di memoria, save0 e save1. Se la stessa procedura di interruzione può essere a
sua volta interrotta due locazioni non sono sufficienti, dato che la seconda interruzione
sovrascriverebbe i dati salvati durante la prima interruzione. Questo semplice gestore delle
interruzioni, però, termina l’esecuzione della procedura prima di riabilitare le interruzioni,
quindi il problema non sussiste.
9.11
.ktext 0x80000080
sw $a0, save0
# il gestore non è rientrante e non può usare
sw $a1, save1
# lo stack per salvare $a0 e $a1 non è necessario salvare $k0 e $k1
Quindi il gestore delle interruzioni sposta il contenuto dei registri Causa e EPC nei registri
della CPU. L’istruzione mfc0 $k0, $13 sposta il contenuto del registro 13 del coprocessore 0
(il registro Causa) nel registro $k0 della CPU. Si noti che il gestore delle interruzioni non deve
necessariamente salvare i registri $k0 e $k1 perché i programmi utente non usano tali
registri.
Il gestore delle interruzioni usa i valori all’interno del registro Causa per controllare se
l’eccezione è stata provocata da un’interruzione (vedere la tabella 9.3); in questo caso
l’interruzione è ignorata, mentre in caso contrario il gestore chiama la procedura.
mfc0 $k0, $13
mfc0 $k1, $14
# sposta Causa in $k0
# sposta EPC in $k1
andi $v0, $k0, 0x3C # prelevo il tipo dell’eccezione (bit da 5 a 2 del registro Causa
#memorizzato in $k0)
beq $v0, $0, fatto # ignora le interruzioni (ma non le eccezioni)
add $a0, $k0, $0 # memorizza Causa in $a0
add $a1, $k1, $0 # memorizza EPC in $a1
jal
gestione
# routine di gestione dell’eccezione, con parametri in ingresso $a0 e $a1
Prima di terminare, il gestore delle interruzioni ripristina il contenuto dei registri $a0 e $a1 e
poi esegue l’istruzione rfe (ritorno da un eccezione), che ripristina i bit della maschera delle
interruzioni e kernel/utente che erano presenti in precedenza nel registro Stato. Questo fa
sì che il processore ritorni allo stato precedente al verificarsi dell’eccezione e che si prepari
a riprendere l’esecuzione del programma. Il gestore delle interruzioni quindi restituisce il
controllo al programma saltando all’istruzione successiva a quella che ha causato l’eccezione.
fatto:
lw
lw
$a0, save0
$a1, save1
addiu
$k1, $k1, 4
rfe
jr
$k1
# non riesegue l’istruzione che ha provocato
# l’eccezione, ma salta a quella successiva
# ripristina lo stato delle interruzioni
.kdata
save0: .word0
save1: .word0
L’istruzione mfc0 (move from system control) può venire usata per copiare il registro EPC in
un registro general purpose, in maniera tale che il software del MIPS possa tornare
all’istruzione che ha causato l’eccezione attraverso un’istruzione di salto tramite registro.
9.12
Problema: se si deve copiare EPC in un altro registro per usarlo come registro di salto, come
fa il salto tramite registro a tornare al codice interrotto e ripristinare i valori originari di
tutti i registri? Due sono le opzioni:
1) Ripristinare i vecchi registri, distruggendo così l’indirizzo di ritorno contenuto in EPC
che era stato precedentemente copiato in un registro per essere usato in un salto
tramite registro
2) Ripristinare tutti i registri tranne quello con l’indirizzo di ritorno così da poter saltare,
con la conseguenza che un’eccezione comporta il cambiamento di quel registro in un
qualunque istante di esecuzione di un programma
Nessuna delle due opzioni risulta accettabile. Per ovviare a ciò, i programmatori del MIPS
hanno riservato i registri $k0 e $k1 per il sistema operativo: tali registri non sono ripristinati
durante le eccezioni. Le procedure di eccezione scrivono l’indirizzo di ritorno in uno di questi
registri e poi usano un salto tramite registro per ripristinare l’indirizzo dell’istruzione.
Nota: nei processori MIPS reali il processo di ritorno dal gestore delle interruzioni è più
complesso. L’istruzione rfe deve essere eseguita nel branch delay slot dell’istruzione jr che
restituisce il controllo al programma utente, in modo che nessuna istruzione di gestione delle
interruzioni venga eseguita con i bit della maschera delle interruzioni e kernel/utente propri
del programma utente. In più il gestore delle interruzioni non sempre può saltare all’istruzione
seguente a quella contenuta nel registro EPC; ad esempio se l’istruzione che ha provocato
l’eccezione era in un branch delay slot, l’istruzione seguente potrebbe non essere quella che si
trova nella posizione di memoria successiva.
9.11 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Andrew S. Tanenbaum, “Structured Computer Organization”, Fourth Edition, 1999
[3] Andrew S. Tanenbaum “Modern Operating Systems”, Second Edition, 2001
[4] LSI Logic, “LR33000 Self-Embedding Processor User’s Manual”, Second Edition, 1992, Order n.
J14001.A
9.13
LEZIONE 10
Implementazione di semplice CPU MIPS
10.1 INTRODUZIONE
Un processore consta generalmente di due parti principali:
• Data Path: costituito dai dispositivi di ALU, registri e bus e dai percorsi seguiti dai
dati;
• Control Path: costituito dai percorsi dei segnali di controllo verso i dispositivi del data
path, distinti in segnali di selezione e di temporizzazione.
Scopo del processore e’ di supportare un’efficiente esecuzione del software. Con riferimento
al modello di seguito considerato, i segnali di controllo vengono utilizzati per coordinare il
funzionamento di tutti gli elementi interni al processore (e in particolare del datapath) in
modo da massimizzare le prestazioni. Per riferimento, si considerera’ il caso del processore
MIPS. Nel seguito si introdurranno brevemente gli elementi principali che costituiscono il
data-path.
10.2 REGISTER FILE
La struttura intorno alla quale è costituita l'unità di elaborazione è il Register File (RF). Il
Register File (vedi fig. 10.1) è costituito da un insieme di registri che possono essere letti o
scritti fornendo il numero (o indice) del registro a cui fare accesso. In generale l’indice del
registro e’ un numero su k bit, mentre il dato e’ espresso su m bit (nel caso del processore
MIPS qua analizzato k=5, m=32).
Register file
k
Read register
number 1
k
Read register
number 2
k
Write
register
m
Write
data
Read
data 1
m
Read
data 2
m
Write
Figura 10.1 Struttura del Register File.
10.2.1 Logica di Lettura
Poiché la lettura di un registro non ne modifica lo stato, in ingresso occorre fornire solo il
numero del registro ed in uscita si otterrà il dato contenuto in esso. Nel RF vengono utilizzate
due porte di lettura che possono essere implementate con n (n=2k) registri mediante una
coppia di multiplexer ad n vie, ciascuno di ampiezza pari a m=32 bit . (vedi fig. 10.2).
10.1
Read
register
number 1
k
m
Register 0
Register 1
Register n – 1
M
u
x
Read
m da ta 1
M
u
x
Read
m data 2
Register n
Read
re gister
number 2
k
Figura 10.2 Porte di lettura dei registri per un Register File ampio 32bit.
10.2.2 Logica di Scrittura
Per la scrittura in un registro occorrono tre ingressi che sono, il numero del registro, il dato
da scrivere ed un segnale di scrittura, detto anche “gate” di scrittura (vedi fig. 10.3). Viene
utilizzato un decodificatore per generare un segnale in grado di determinare in quale registro
scrivere. Notare che lo stato dei registri può cambiare solo in corrispondenza di un fronte in
salita del gate di scrittura, essendo i registri realizzati con flip-flop di tipo D (v. Appendice
10.A).
Write
C
0
1
k
Register
number
Register 0
D
n-to-1
decoder
C
Register 1
D
n– 1
n
C
Register n – 1
D
C
m
Register n
D
Register
data
Figura 10.3 Logica di Scrittura.
10.3 ALU (UNITÀ ARITMETICO LOGICA)
La ALU (Arithmetic & Logical Unit) è il dispositivo che esegue le operazioni aritmetiche come
la somma o sottrazione, o operazioni logiche come AND o OR. Analizzeremo innanzitutto una
ALU da 1 bit (vedi fig. 10.4), considerando solo quattro operazioni (+,-,&,|) per poi considerare
una possibile estensione ad una ALU a 32 bit.
Per realizzare la ALU elementare ad 1 bit e’ possibile utilizzare un multiplexer in uscita che
selezioni il risultato di una delle tre reti che producono AND, OR, SOMMA (la sottrazione
puo’ essere vista come un caso particolare della somma) a seconda del valore assunto dal
segnale di controllo (‘Operation’ su 2 bit).
10.2
Operation
CarryIn
2
a
0
1
2
b
CarryOut
Figura 10.4 ALU ad 1 bit.
In particolare, il sommatore avra’ due ingressi per gli operandi ed un uscita ad un bit per la
somma; inoltre ci sara’ una seconda “uscita” per generare il riporto, CarryOut, ed un terzo
ingresso, CarryIn, per tener conto del CarryOut proveniente da un eventuale sommatore
adiacente.
I valori delle uscite del sommatore sulla base degli ingressi sono presentati in tabella 10.1.
Tabella 10.1 Algebra del sommatore.
a
0
0
0
0
1
1
1
1
INGRESSI
b
0
0
1
1
0
0
1
1
CarryIn
0
1
0
1
0
1
0
1
USCITE
CarryOut
Somma
0
0
0
1
0
1
1
0
0
1
1
0
1
0
1
1
COMMENTI
0+0+0 = 00
0+0+1 = 01
0+1+0 = 01
0+1+1 = 10
1+1+0 = 01
1+0+1 = 10
1+1+0 = 10
1+1+1 = 11
Il valore dell’uscita CarryOut può essere convertito in una equazione logica:
CarryOut = (b ∗ CarryIn) + (a ∗ CarryIn) + (a ∗ b) + (a ∗ b ∗ CarryIn)
1442443
assorbimento
CarryIn
a
CarryOut
b
Figura 10.5 Generatore di CarryOut.
Il CarryOut è generato da 3 porte AND ed una porta OR (vedi fig. 10.5). Le tre porte AND
corrispondono ai termini dell'espressione sopraindicata.
10.3
Il bit somma vale 1 quando un solo ingresso vale 1, oppure quando tutti e tre gli ingressi
valgono 1. Il segnale somma corrisponde quindi all'espressione booleana:
Somma = a * b * CarryIn + a * b * CarryIn + a * b * CarryIn + a * b * CarryIn
10.3.1 ALU a 32bit
La ALU a 32 bit può essere ottenuta collegando 32 ALU da 1 bit (vedi fig 10.6). Collegando
direttamente i riporti dei sommatori ad 1 bit, si ottiene il sommatore a propagazione di
riporto (Ripple Carry Adder).
Carr yIn
a0
b0
Operation
2
Carr yIn
ALU0
Result0
CarryOut
a1
b1
Carr yIn
ALU1
Result1
CarryOut
a2
b2
a31
b31
Carr yIn
Result2
ALU2
CarryOut
Carr yIn
Result31
ALU31
Figura 10.6 ALU a 32bit.
La sottrazione corrisponde alla somma con un operando negato:
a − b = a + (−b)
Per ottenere un numero negato ( −b ) basta fare il complemento a due di tale numero, che
consiste nel complementare ciascun bit del numero e poi sommarci 1.
Per sommare 1, CarryIn viene forzato ad 1; mentre per effettuare l’operazione di
complemento si imposta Binvert ad 1.
a − b = a + (−b) = a + (b + 1) = a + b + 1
Per decidere se negare o meno un bit si puo’ usare un mux a due ingressi che scelga tra b e b
a seconda del segnale di controllo Binvert (vedi fig 10.7).
10.4
Binvert
Operation
CarryIn
a
2
0
1
0
b
Result
2
1
CarryOut
Figura 10.7 Controllo Binvert.
Oltre a questo tipicamente si aggiunge la logica per il rilevamento dell’overflow (vedi fig. 10.8).
A questo punto, si puo’ facilmente aggiungere alla ALU anche il supporto per l’istruzione: "Set
on Less Than" (slt), che genera 1 se il primo operando è minore del secondo, 0 altrimenti. Per
fare questo si puo’ effettuare una sottrazione a − b , se a − b < 0 (e quindi a < b ) il bit meno
significativo varrà 1, mentre quando a − b > 0 (cioè a > b ) esso varrà 0. Bastera’ cosi’ portare
in uscita tale bit. Vediamo come si puo’ procedere nell’implementazione.
Innanzitutto, si espande la singola ALU da un bit aggiungendo un ingresso al multiplexer che
chiameremo Less (vedi fig. 10.8). Si aggiunge poi una nuova uscita al sommatore, denominata
Set.
Binvert
Operation
CarryIn 2
a
0
1
Result
b
0
2
1
Less
3
Set
Overflow
detection
Overflow
Figura 10.8 ALU a 32bit con riporto del bit più significativo.
Nel costruire la ALU a 32 bit, le [ALU1…ALU31] hanno il bit Less collegato a 0, mentre la
ALU0 ha l’ingresso Less che proviene dall’uscita Set della ALU31 (bit più significativo) (vedi
fig. 10.9). In questo modo si genera sull’uscita complessiva Result[0..31] il valore 1 quando il bit
piu’ significativo di a − b vale 1.
10.5
Operation
2
Binvert
a0
b0
CarryIn
ALU0
Less
CarryOut
a1
b1
0
CarryIn
ALU1
Less
CarryOut
a2
b2
0
CarryIn
ALU2
Less
CarryOut
Result0
Result1
Result2
CarryIn
a31
b31
0
CarryIn
ALU31
Less
Result31
Set
Overflow
Figura 10.9 Evoluzione ALU a 32bit.
Possiamo infine aggiungere il supporto per verificare se due operandi a e b sono uguali (vedi
fig. 10.10): cio’ e’ utile nelle istruzioni tipo beq dove viene effettuato un salto se il contenuto
di due registri è uguale.
Il modo più semplice per verificare l’uguaglianza tramite la ALU consiste nel sottrarre b da a
e nel guardare se il risultato è zero, dal momento che ( a − b = 0 ) ⇒ a = b . Per ottenere un
segnale che vale 1 se Result[0..31] e’ zero basta mettere in OR tutte le uscite delle ALU e far
passare il segnale attraverso un inverter (vedi fig. 10.10).
0 = (result 31 + result 30 + ... + result1 + result 0)
10.6
Binvert
Operation
2
a0
b0
CarryIn
ALU0
Less
CarryOut
32
Result0
32
a1
b1
0
CarryIn
ALU1
Less
CarryOut
Result1
a2
b2
0
CarryIn
ALU2
Less
CarryOut
Result2
a31
b31
0
CarryIn
ALU31
Less
3 ALUcontrol
Zero
ALU ALU
result
32
Zero
Result31
Set
Overflow
Figura 10.10 Evoluzione ALU a 32bit. L’ALU così ottenuta (parte sinista) può essere schematizzata con il
blocco a destra, dove il segnale ALUControl comprende i segnali Operation e Binvert.
10.3.2 Addizionatore Carry Look Ahead (CLA)
Nella ALU appena progettata, se si risale lungo la catena delle dipendenze, il bit più
significativo è collegato a quello meno significativo ed il bit più significativo della somma deve
attendere la valutazione sequenziale di tutti i 32 sommatori ad 1 bit. Tale reazione
sequenziale a catena è troppo lenta. Perciò si utilizza la tecnica del Carry Look Ahead dove i
riporti vengono propagati in parallelo. Sappiamo che il CarryIn per il bit 2 (ALU1) del
sommatore è esattamente il CarryOut del bit 1.
Perciò:
CarryIn2 = (b1 ∗ CarryIn1 ) + (a1 ∗ CarryIn1 ) + (a1 ∗ b1 )
ed analogamente:
CarryIn1 = (b0 ∗ CarryIn0 ) + (a0 ∗ CarryIn0 ) + (a0 ∗ b0 )
Ponendo:
c1 , c2 ,..., cn = CarryIn1 , CarryIn2 ,..., CarryInn
si può scrivere:
ci +1 = (bi ∗ ci ) + (ai ∗ ci ) + (ai ∗ bi ) = (ai + bi )ci + (ai ∗ bi )
Osserviamo che un valore 1 di questo può essere dovuto a due fatti mutuamente esclusivi:
1. Il riporto si genera localmente allo stadio i-esimo perché i due bit ai e bi sono
entrambi 1; questo è espresso dal termine prodotto ai ∗ bi che viene detto termine di
generazione; quando ciò accade l’altro termine (ai + bi ) ∗ ci è ininfluente.
2. Il riporto si genera nello stadio precedente (i-1)-esimo) e lo stadio i-esimo
semplicemente lo propaga al successivo, essendo ai o bi (ma non entrambi) 1: di ciò è
10.7
responsabile il termine (ai + bi ) che prende il nome di termine di propagazione; quando
il termine di propagazione vale 1, il termine di generazione è nullo.
Detti g e p i due termini sopra introdotti, possiamo scrivere il riporto ci +1 nella forma:
ci +1 = gi + pi ∗ ci
Iterando questa equazione per i = 0,1,..., n − 1 otteniamo (nota c0=CarryIn0, ...,cn-1=CarryInn-1
mentre Cn=CarryOutn-1):
c1 = g0 + p0c0
c2 = g1 + p1c1
c3 = g 2 + p2c2
...
cn −1 = g n − 2 + pn − 2cn − 2
cn = g n −1 + pn −1cn −1
Infine sostituendo c1 in c2, c2 in c3, e cosi’ via l’espressione di ci-1 data dall’equazione
precedente nell’equazione i-esima di ci, si arriva alle seguenti equazioni:
c1 = g 0 + p0 c0
c2 = g1 + p1 g 0
c3 = g 2 + p2 g1 + p2 p1 g 0
...
ci = g i −1 + pi −1 g i −2 + pi −1 pi −2 g i −3 + ... + pi −1 pi −2 ... p2 g1 + pi −1 pi −2 ... p2 p1 g 0
...
cn = g n−1 + pn−1 g n−2 + pn−1 pn−2 g n−3 + ... + pn−1 pn−2 ... p 2 g1 + p n−1 pn−2 ... p2 p1 g 0
le quali mostrano che il riporto
ci in uscita allo stadio i − 1 esimo è dovuto al termine di
generazione di quello stadio, oppure al termine di propagazione di quello stadio ed al termine
di generazione dello stadio (i − 2) esimo, oppure al termine di propagazione di quello stadio, al
termine di propagazione dello stadio (i − 2) esimo ed al termine di generazione dello stadio
(i − 3) esimo e così via.
Per ciascuna equazione possiamo costruire una rete combinatoria a due livelli di logica che
riceve in ingresso il termine di generazione e quello di propagazione prodotti nello stadio
dell’addizionatore ad essa relativo e genera il riporto per lo stadio successivo.
L’insieme di tali reti costituisce un modulo detto Carry Look-Ahead Generator (CLAG).
I vari stadi dell’addizionatore con CLAG possono operare in parallelo, producendo il risultato
con un ritardo costante pari a Δ s + 2Δ g dove Δ s è il tempo di propagazione dall’ingresso
all’uscita della somma e Δ g è il ritardo di una porta.
Questa tecnica può essere applicata fino a valori di n non superiori a 5 o 6, infatti al crescere
di n il numero di porte e dei segnali di ingresso ad esse associati cresce a livelli inaccettabili.
Per addizionatori di lunghezza maggiore è necessario trovare un compromesso tra complessità
realizzativa e velocità di risposta.
Una soluzione consiste nel dividere gli operandi in k gruppi di q bit, in modo che sia n = k ∗ q e
q ≤ 6 e nel propagare i riporti con tecnica CLA sia all’interno di ogni gruppo che tra i gruppi.
Occorre disporre di almeno 2 livelli di CLAG: al primo livello si trovano i generatori di riporti
anticipati che lavorano sui singoli gruppi; al secondo livello quelli che lavorano tra i gruppi
ricevendo i termini di generazione e di propagazione dai generatori del primo livello.
10.8
10.3 PROGETTAZIONE DEL DATAPATH
Analizziamo adesso la struttura di un’unità di elaborazione dati (datapath) elementare, a cui
aggiungeremo in seguito la relativa parte di controllo, fondendo in un’unica rete le unità di
elaborazione presentate in precedenza.
Questa semplice implementazione coprirà le istruzioni di load word (lw), store word (sw),
Branch on Equal (beq) e le istruzioni logico-aritmetiche add, sub, and, or e Set on Less Than
(slt).
10.3.1 Prelievo delle istruzioni
Il prelievo delle istruzioni (fetch) ha inizio caricando l’indirizzo memorizzato nel Program
Counter (PC – Figura 10.11a). Il PC è un registro a 32 bit che viene scritto alla fine di ogni ciclo
di clock.
L’indirizzo prelevato dal PC è quindi utilizzato per caricare l’istruzione vera e propria
dall’Instruction Memory (Figura 10.11b), in cui sono memorizzate tutte le istruzioni del
programma. L’Instruction Memory deve perciò essere in grado di fornire in uscita le istruzioni
a fronte di un indirizzo in ingresso.
Per prepararsi ad eseguire l’istruzione successiva, occorre inoltre incrementare il PC in modo
che punti alla prossima istruzione: è quindi essenziale un addizionatore (Add – Fig.11.10c) per
incrementarlo. Tale elemento combinatorio è generato a partire da un’ALU in cui uno degli
addendi è fissato a 4.
Instruction
address
PC
Sum
Instruction
memory
Add
Instruction
Figura 10.11 a) Instruction Memory.
b) Program Counter.
c) Addizionatore.
In figura 10.12 è mostrata la rete in grado di svolgere le suddette operazioni.
Add
4
PC
Instruction
address
Instruction
memory
Figura 10.12 Rete utilizzata per prelevare istruzioni ed incrementare il PC.
10.9
10.3.2 Decodifica
Proseguiamo analizzando in maniera approfondita ogni singola tipologia d’istruzione che il
nostro Datapath sarà in grado di gestire.
10.3.2.1 Supporto per le istruzioni in formato “R-Type”
Le prime istruzioni che esamineremo sono quelle che operano in formato R (R-Type) come add,
sub, and, or, e slt.
Tutte le istruzioni di questo genere seguono i seguenti passi:
1. leggono 2 registri;
2. eseguono un’operazione con l’ALU sui contenuti dei registri;
3. scrivono il risultato in un terzo registro.
I 32 registri del processore costituiscono il Register File (Figura 10.13).
Per compiere una lettura dobbiamo fornire un input al Register File che specifichi il numero
del registro da leggere (su Read-register-1 o Read-Register-2) ed prelevare dall’output
(Read-data-1 o Read-data-2 rispettivamente) il valore letto da tale registro, mentre per
un’operazione di scrittura ci servono due input al Register File: uno per specificare il numero
del registro da scrivere (Write-register) e l’altro per il dato da memorizzare (Write-data).
Gli ingressi che specificano il numero dei registri sono a 5 bit (25= 32), mentre i bus di input e
di output di dato sono a 32 bit ciascuno.
Per poter operare sui valori letti dai registri, è necessaria un’ALU con due ingressi ed un
output a 32 bit.
5
5
5
32
Read
register 1
32
Read
data 1
Read
register 2
Register
file
3
ALU Control
Zero
32
Write
register
Write
data
32
Data
Read
data 2
32
ALU
ALU
result
32
RegWrite
Figura 10.13 Elementi necessari per implementere istruzione in formato R.
10.3.2.2 Supporto per le istruzioni d’accesso alla memoria
Soffermiamoci adesso sulle istruzioni di load e di store, quali ad esempio:
lw
$t1, offset_value($t2)
sw
$t1, offset_value($t2)
Queste istruzioni calcolano un indirizzo di memoria sommando al registro base (in questo caso
$t2) il valore dell’offset “offset_value” (rappresentato su 16 bit con segno).
Poiché entrambe le istruzioni hanno bisogno di accedere ai registri (per un’operazione di
lettura nel caso dello store, per una di scrittura nel caso del load), per eseguirle sono
essenziali sia il Register File che l’ALU.
Occorre inoltre introdurre due nuove unità (Figura 10.14):
1. Un’unità, chiamata Sign-extend, che “estende” (con il segno corretto) l’offset da 16 a
32 bit per poterlo utilizzare nell’ALU;
2. Una memoria (Data memory) in cui scrivere durante operazioni di store, dotata perciò
di segnali di controllo sia per la scrittura che per la lettura.
10.10
MemWrite
Address
32
Read
data
Sign
extend
32
Write
data
16
32
Data
memory
32
RegWrite
Figura 10.14 Unità necessarie per implementare istruzioni di load e store.
La rete in figura 10.15 mostra come vengono connessi questi elementi nel costruire la rete per
le istruzioni lw e sw.
ALU Control
Istruzione
3
Read
register 1
Read
Read
data 1
register 2
Read
Write
data 2
register
Register
Write
file
data
ALU
ALU
result
Address
Read
data
Write
data
RegWrite
16
MemWrite
Sign
extend
32
Data
memory
MemRead
Figura 10.15 Datapath per istruzioni di load e store.
10.3.2.3 Supporto per le istruzioni di “Branch”
Analizziamo infine il supporto per l’istruzione di Branch on Equal.
L’istruzione beq ha tre operatori: due registri che sono confrontati per verificarne
l’uguaglianza ed un offset a 16 bit.
Per calcolare l’indirizzo di destinazione del salto (branch target) dobbiamo sommare al valore
del PC il nostro offset (esteso a 32 bit con segno). Rammentiamo che l’offset è riferito a
word: perciò è necessario traslarlo di 2 bit a sinistra (effettuando in pratica una
moltiplicazione per 4).
Oltre a calcolare il branch target, la rete dovrà essere capace di determinare se la prossima
istruzione da eseguire sia quella nella posizione di memoria successiva (PC+4) o quella
all’indirizzo specificato dal salto.
Nel caso in cui l’uguaglianza risulti verificata il branch target diventa il nuovo PC (in questo
caso si dice branch taken); altrimenti il PC incrementato và a rimpiazzare il PC attuale (branch
not taken) come per ogni altra istruzione.
I valori da confrontare sono caricati tramite il Register File. L’operazione di confronto vera e
propria avviene tramite l’ALU: poiché questa fornisce un segnale di output (Zero) che indica
se il risultato è pari a 0, effettuando una sottrazione tra i due operandi l’uguaglianza risulterà
verificata solo se il segnale di output Zero è 1.
In figura 10.16 è mostrato il datapath per tale classe d’istruzioni.
10.11
PC+4
Add
sum
Shift
left 2
Istruzione
3
Read
register 1
Read
register 2
Write
register
Write
data
Read
data 1
Destinazione del
branch
ALU
Control
Zero
Register
file
Read
data 2
1
M
u
x
0
Alla logica di
controllo del branch
ALU
RegWrite
16
Sign
extend
32
Figura 10.16 Datapath per istruzioni di Branch.
10.3.3 Creazione del Datapath
“Assembliamo” adesso i singoli componenti per creare un unico datapath in grado di eseguire
tutte le classi d’istruzioni viste in precedenza (lw, sw, beq, add, sub, and, or e slt).
Il nostro datapath elementare è in grado di eseguire tutte le istruzioni in un solo ciclo di
clock (implementazione single-cycle). Ciò comporta che nessuna unità possa essere utilizzata
più di una volta per ogni istruzione e che qualsiasi elemento di cui si ha bisogno più volte deve
essere duplicato. Sono perciò necessarie due unità di memoria esterne separate: l’Instruction
Memory ed il Data Memory.
Fortunatamente molti altri elementi possono essere invece condivisi tra differenti tipi
d’istruzioni: sono però necessari collegamenti multipli agli input di tali unità. Per fare ciò
utilizziamo dei multiplexer (vedi Figura 10.17) controllati tramite segnali che specificheremo
in seguito.
10.12
1
M
u
x
Add
4
0
Add
Shift
Left 2
Read
register 1
Instruction
address
PC
Instruction
memory
Instruction
Read
data 1
Read
register 2
0
M
u
x
Read
data 2
Write
register
Write
data
ALU
Register
file
16
Zero
ALU
result
0
M
u
x
Address
Read
data
1
Write
data
32
Data
memory
Sign
extend
0
M
u
x
1
Figura 10.17 Datapath elementare.
10.4 RETE DI CONTROLLO
Avendo completato il nostro Datapath elementare, aggiungiamo adesso la rete di controllo:
essa deve essere in grado di elaborare i propri ingressi e di generare un segnale di scrittura
per il Register File e la Data Memory, un segnale di controllo per la selezione di ogni
multiplexer (4) ed il segnale a 3 bit di controllo dell’ALU, per un totale di 2+4+3 segnali di
controllo.
Poiché il controllo della ALU è per molti versi particolare, conviene suddividere la rete di
controllo in due sottoreti: la rete “Main-Control” e la rete “ALU-Control”.
0
M
u
x
1
Add
Shift
left 2
Add
RegDst
4
4
Branch
MemRead
Mem toReg
Instruction [31:26]
Control
ALUOp
MemWrite
ALUSrc
RegWrite
Instruction [25:21]
PC
Instruction
address
Instruction
memory
Instruction
[31:0]
Read
register 1
Instruction [20:16]
0
Instruction [15:11]
Read
data 1
Read
register 2
M
u
x
1
Write
data
ALU
Read
data 2
Write
register
0
Zero
ALU
result
Address
M
u
x
1
Register
file
Read
data
Write
data
Instruction [15:0]
16
Sign
extend
32
3
ALU
Control
Instruction [5:0]
Figura 10.18 Datapath con la relativa rete di controllo.
10.13
Data
memory
0
M
u
x
1
10.4.1 Rete ALU-Control
Sappiamo che l’ALU ha 3 ingressi di controllo, ma soltanto 6 delle 8 possibili combinazioni sono
utilizzate. Nella tabella 10.2 sono elencate tali combinazioni.
Tabella 10.2 Operazioni eseguibili dalla ALU
Segnale di
controllo ALU
Operazione
000
001
010
110
111
AND
OR
add
sub
slt
Secondo il tipo d’istruzione, l’ALU dovrà eseguire una delle 5 funzioni.
Possiamo generare il segnale di controllo a 3 bit mediante un’unità di controllo con due
ingressi: un gruppo di fili derivato dal campo funct a 6 bit dell’istruzione e un’altro derivato
dal segnale ALUOp a 2 bit (generato a sua volta dalla rete Main-Control).
ALUOp indica se l’operazione da eseguire è una somma (00) per istruzioni di lw e sw, una
sottrazione (01) per beq oppure l’operazione codificata nel campo funct (10) per istruzioni RType. Nella tabella 10.3 è riassunto quanto appena detto.
Tabella 10.3 Generazione dei segnali di controllo in uscita alla rete ALU-control.
Istruzione
ALUOp
lw
sw
beq
00
00
01
10
10
10
10
10
R-Type
R-Type
R-Type
R-Type
R-Type
Operazione
dell’istruzione
load word
store word
branch equal
add
sub
AND
OR
slt
Campo
Operazione ALU
desiderata
add
add
sub
add
sub
AND
OR
slt
funct
xxxxxx
xxxxxx
xxxxxx
100000
100010
100100
100101
101010
Segnale di
controllo ALU
010
010
110
010
110
000
001
111
Poiché soltanto una piccola parte dei 64 (26) possibili valori del campo funct sono significativi
e dato che il campo funct è utilizzato solo quando i bit ALUOp sono 10, possiamo utilizzare un
semplice blocco logico che riconosca il sottoinsieme dei valori ammissibili.
Creiamo quindi la tabella di verità per tale rete (Tab.10.4).
Tabella 10.4 Tabella di verità per la rete ALU-Control.
Campo funct
ALUOp
ALUOp1
0
x
1
1
1
1
1
ALUOp2
0
1
x
x
x
x
x
F5
x
x
x
x
x
x
x
F4
x
x
x
x
x
x
x
F3
x
x
0
0
0
0
1
F2
x
x
0
0
1
1
0
F1
x
x
0
1
0
0
1
Operazione
F0
x
x
0
0
0
1
0
010
110
010
110
000
001
111
Per mantenere la tabella compatta consideriamo solo le combinazioni significative di input ed
includiamo dei don’t care.
10.14
E’ quindi possibile implementare il comportamento descritto dalla tabella 10.4 con il seguente
circuito logico (Figura 10.19):
ALUOp
ALU control block
ALUOp0
ALUOp1
Operation2
F3
F (5– 0)
F2
Operation1
Operation
F1
Operation0
F0
Figura 10.19 Rete ALU Control.
10.4.2 Rete Main-Control
Prima di procedere con l’implementazione vera e propria della rete, consideriamo in dettaglio il
formato delle classi di funzione che il nostro datapath può gestire:
• Il campo op (anche chiamato opcode) è sempre contenuto nei bit 31:26. Ci riferiremo a
questo campo con Instr[31:26].
• I registri che devono essere letti sono sempre specificati nei campi rs (bit 25:21) e rt
(bit 20:16). Questo per istruzioni R-Type, beq e sw.
• Per istruzioni sw e lw, il registro di base è sempre indicato nei bit 25:21 (rs).
• L’offset a 16 bit per istruzioni beq, lw e sw è sempre nelle posizioni 15:0.
• Per il registro di destinazione esistono due possibilità: per lw è in posizione 20:16 (rt),
mentre per istruzioni R-Type è in 15:11 (rd). Dobbiamo perciò aggiungere un
multiplexer sull’ingresso Write register del Register file per selezionare il campo
corretto.
Con queste informazioni è possibile aggiungere al nostro datapath le etichette che riportano i
numeri dei bit dell’istruzione ed un ulteriore multiplexer sull’ingresso Write register (vedi
Figura 10.20).
10.15
0
M
u
x
1
Add
Shift
left 2
Add
PCSrc
4
RegWrite
Instruction [25:21]
PC
Instruction
address
Instruction
memor y
Instruction
[31:0]
Read
register 1
Instruction [20:16]
0
Instruction [15:11]
Instruction [15:0]
M
u
x
1
RegDst
Read
data 1
Read
register 2
Write
register
Write
data
Read
data 2
Register
file
16
Sign
extend
MemWrite
ALUSrc
0
ALU
Zero
ALU
result
M
u
x
1
Read
data
Write
data
32
ALU
Control
MemtoReg
Address
3
Data
memor y
0
M
u
x
1
MemRead
Instruction [5:0]
ALUOp
Figura 10.20 Datapath completo di tutti i multiplexer necessari
e con l’identificazione di tutti i segnali di controllo.
Avendo già definito il funzionamento di ALUOp, resta da determinare come operano i restanti
segnali di controllo (vedi Figura 10.5).
Tabella 10.5 Effetti dei 7 segnali di controllo generati dalla rete Main-Control.
Nome del segnale
Effetti quando negato
Effetti quando affermato
RegDst
Il numero del registro di destinazione per Il numero del registro di destinazione per il
il Write register proviene dal campo rt (bit Write register proviene dal campo rd (bit
20:16).
15:11).
RegWrite
Nessuno.
Il valore presente sull'ingresso Write data
viene scritto nel registro specificato da
Write register.
ALUSrc
Il 2° operando della ALU è il 2° output del Il 2° operando della ALU è costituito dai 16
Register file (Read data 2).
bit meno significativi, estesi a 32 bit con
segno, dell'istruzione.
PCSrc
Il valore del PC è sostituito dal valore in
Il valore del PC è sostituito dall'uscita
uscita dall'addizionatore che calcola PC+4. dell'addizionatore che calcola il branch
target.
MemRead
Nessuno.
Il contenuto della cella del Data memory,
designata dall'ingresso Address, viene posto
in Read data.
MemWrite
Nessuno.
Il contenuto della cella del Data memory,
designata dall'ingresso Address, è sostituito
dal valore presente sull'ingresso Write data.
MemtoReg
Il valore inviato all'ingresso Write data del Il valore inviato all'ingresso Write data del
Register file proviene dalla ALU.
Register file proviene dalla Data memory.
10.16
L’unità Main-Control (vedi Figura 10.21) genera tutti i segnali di controllo, tranne uno, sulla
base dei bit Instr[31:26]. L’eccezione è il segnale PCSrc, che deve essere asserito se
l’istruzione è beq e se l’uscita Zero dell’ALU è pari a 1: dobbiamo perciò compiere
un’operazione di AND tra il segnale Branch proveniente dall’unità Control e l’uscita Zero
dell’ALU.
La tabella 10.6 definisce il valore dei segnali di controllo per ognuna delle classi di funzione
MIPS esaminate.
Tabella 10.6 Valore dei 7 segnali di controllo per le varie tipologie di istruzione.
Istruzione
Reg
Dst
ALU
Src
Memto
Reg
Reg
Write
Mem
Read
Mem
Write
Branch
ALUOp
1
ALUOp
2
R-Type
1
0
0
1
0
0
0
1
0
lw
0
1
1
1
1
sw
x
1
x
0
0
0
0
0
0
1
0
0
0
beq
x
0
x
0
0
0
1
0
1
10.4.2.1 Funzionamento del Datapath
Prima di procedere alla sintesi dell’unità logico-combinatoria Control, esaminiamo l’uso che
ciascuna istruzione fa del datapath.
•
Istruzioni “R-Type”
Analizziamo per esempio cosa accade per l’istruzione
add $t1, $t2, $t3.
Anche se tutte le operazioni avvengono in un unico ciclo di clock, risulta di più facile
comprensione pensare che l’istruzione sia eseguita attraverso una serie di passi:
1. viene prelevata un’istruzione dall’Instruction memory ed incrementato il PC
(vedi Figura 10.21 dove le unità attive ed i segnali di controllo affermati sono
evidenziati in rosso);
2. sono letti dal Register File due registri, nel nostro caso $t2 e $t3, mentre le
unità Main-Control calcola tutti i valori da attribuire alle linee di controllo
(anche quelli non necessari per questo tipo d’istruzione) (Figura 10.21 in verde);
3. la ALU elabora i dati letti dal Register file grazie ai segnali di controllo
provenienti dalla rete ALU-Control, che li genera utilizzando il codice funzione
(il campo funct dell’istruzione, bit 5:0) (Figura 10.21 in blu);
4. il risultato calcolato dall’ALU viene scritto nel Register file utilizzando i bit
15:11 dell’istruzione per selezionare il registro di destinazione ($t1) (vedi Figura
10.21 in viola).
10.17
0
M
u
x
1
Add
Shift
left 2
Add
Re gD st
Bran ch
4
PCS rc
Mem Re a d
Memto R eg
Instructi o n [31: 26]
Control
ALUO p
MemWr ite
AL USrc
Re gWrit e
Instructi o n [25: 21]
PC
Instructi o n
add res s
Instruction
me mo ry
Instructi o n
[31:0]
Re ad
regi ster 1
Instructi o n [20: 16]
0
Instructi on [1 5:1 1]
M
u
x
1
Re ad
data 2
Write
regi ster
Write
data
Sign
ext end
ALU
Zero
0
AL U
resu lt
Addr ess
M
U
X
1
Regis te r
file
16
Instructi o n [15: 0]
Re ad
data 1
Re ad
regi ster 2
Re ad
data
Write
Data
32
Dat a
me mo ry
1
M
u
x
0
ALU
Control
Instructi o n [5:0]
Figura 10.21 CPU completa.
•
Istruzioni di “Load” e “Store”
I passi da compiere in caso di istruzioni di load e store, come ad esempio
lw $t1, offset($t2)
sono i seguenti cinque:
1. è prelevata un’istruzione dall’Instruction memory ed incrementato il PC;
2. viene letto il valore di un registro ($t2) dal Register file;
3. la ALU somma il valore letto dal Register file ai 16 bit meno significativi
dell’istruzione (offset), esteso da 16 a 32 bit con segno dall’unità Sign extend;
4. la somma calcolata dalla ALU è utilizzata come indirizzo per la Data memory;
5. il dato proveniente dalla Data memory è scritto nel Register file: il registro di
destinazione è calcolato a partire dai bit 20:16 dell’istruzione.
•
Istruzioni di “Branch”
Esaminiamo infine i passi da compiere in caso di istruzioni di Branch, come ad esempio
beq $t1, $t2, offset
1. viene prelevata un’istruzione dall’Instruction memory ed incrementato il PC;
2. vengono letti dal Register file due registri ($t1 e $t2);
3. la ALU calcola la differenza fra i valori dei dati letti dal Register file, mentre il
valore di PC+4 viene sommato ai 16 bit meno significativi dell’istruzione (offset),
dopo averli estesi con segno a 32 bit e scalati a sinistra di due posizioni,
ottenendo così l’indirizzo di destinazione del salto;
4. il valore Zero calcolato dall’ALU è utilizzato per decidere da quale
addizionatore prelevare il nuovo valore da memorizzare nel PC.
10.4.2.2 Completamento dell’unità Main-Control
Ora che abbiamo visto come sono eseguite le istruzioni nei diversi passi, procediamo infine
all’implementazione dell’unità Main-Control.
10.18
Sappiamo che riceve in ingresso i 6 bit Op[5:0] (corrispondenti a Instr[31:26] e che le sue
uscite sono i 9 segnali di controllo.
Possiamo quindi creare la tabella di verità 10.7:
Tabella 10.7 Tabella di verità per l’unità Control.
Nome
Segnale
R-Type
lw
sw
beq
Op5
0
1
1
0
Op4
0
0
0
0
Op3
Op2
0
0
0
0
1
0
0
1
Inputs
Outputs
Op1
0
1
1
0
Op0
RegDst
0
1
1
0
1
x
0
x
0
AluSrc
0
1
1
MemtoReg
0
1
x
x
RegWrite
1
1
0
0
MemRead
0
1
0
0
MemWrite
0
0
1
0
Branch
ALUOp1
0
1
0
0
0
0
1
0
ALUOp2
0
0
0
1
Una possibile sintesi della tabella di verità 10.7 è rappresentata dal circuito in Figura 10.22.
Inputs
Op5
Op4
Op3
Op2
Op1
Op0
Outputs
R-format
Iw
sw
beq
RegDst
ALUSrc
MemtoReg
RegWrite
MemRead
MemWrite
Branch
ALUOp1
ALUOp
Figura 10.22 Unità Main-Control.
10.4.3 Perché non si utilizzano implementazioni a singolo ciclo (syngle-cycle)
Sebbene il progetto della CPU a singolo ciclo appena presentato funzioni correttamente, non è
utilizzato nelle implementazioni moderne a causa della sua scarsa efficienza.
10.19
Per comprendere ciò, basta osservare che il periodo di clock deve necessariamente avere la
stessa durata in tutte le istruzioni previste. Il periodo di clock è determinato dal “cammino”
più lungo nel sistema, che è dovuto quasi certamente ad un’istruzione di load, poiché utilizza 5
unità in serie: l’Instruction Memory, il Register File, l’ALU, la Data Memory e nuovamente il
Register File. Sebbene cosi’ facendo risulti un CPI sia pari ad 1, le performance complessive di
un implementazione single-cycle non sono molto buone poiché per molte classi di istruzioni
sarebbe sufficiente un periodo di clock più breve.
Inoltre, non è possibile sfruttare tecniche implementative che riducano il ritardo dei casi più
comuni ma solo del caso peggiore, visto che la durata del ciclo di clock deve essere pari al
ritardo massimo tra quelli generati dalle diverse istruzioni: viene violato perciò il principio
fondamentale di progetto di rendere più veloci i casi più frequenti.
Infine, poiché ciascuna unità non può essere utilizzata per più di una volta per ciclo di clock,
alcune unità dovranno essere necessariamente duplicate, contribuendo così ad un maggior
costo dell’implementazione.
Una progettazione a singolo ciclo è dunque inefficiente sia dal punto di vista delle
performance che da quello dei costi.
10.5 IMPLEMENTAZIONE MULTICICLO (MULTI-CYCLE)
Un implementazione di tipo multiciclo permette di realizzare un sistema composto da meno
hardware rispetto a quello single-cycle poichè ogni operazione verrà eseguita in più passi: ogni
passo richiederà un ciclo di clock completo. Tale implementazione, oltre ad un risparmio di
risorse hardware, porta con se la possibilità di avere istruzioni con diverso numero di cicli di
clock.
Le principali caratteristiche della versione multiciclo sono:
- una sola unità di memoria per istruzioni e dati;
- una sola ALU anziché una ALU e due sommatori;
- l’aggiunta di uno o più registri per ciascuna unità funzionale allo scopo di memorizzarne
l’uscita fino a quando questa sarà riutilizzata in un ciclo di clock successivo.
I dati utilizzati da istruzioni successive sono memorizzati nel RF, nel PC o nella memoria,
mentre i dati utilizzati nella stessa istruzione, ma in un ciclo di clock successivo, sono
memorizzati in uno dei registri aggiuntivi.
Nel progetto multiclico, il ciclo di clock conterrà un‘operazione di accesso in memoria,
un’operazione di accesso al RF o un’operazione della ALU: i dati prodotti da tali operazioni
verranno salvati in un registro temporaneo per poi essere utilizzati nei cicli di clock
successivi.
Il registro contente l’istruzione corrente (IR) ed il registro dei dati di memoria (MDR)
utilizzano il bus verso la memoria durante le operazioni di lettura di un istruzione e durante
quella di accesso a un dato rispettivamente. I registri A e B memorizzano i valori letti dal RF.
Il registro ALUOut memorizza l’uscita della ALU.
Avendo sostituito le tre ALU dell’unità di elaborazione a singolo ciclo con una sola ALU,
quest’ultima dovrà ricevere tutti gli ingressi che erano diretti alle diverse unità. Dovremo
quindi aggiungere un nuovo multiplexer sul primo ingresso della ALU che seleziona il registro A
oppure PC ed inoltre sostituire il multiplexer a due vie presente sul secondo ingresso della
ALU con uno a quattro vie in cui i due ingressi aggiuntivi sono la costante 4 (che incrementa
PC) ed il valore del campo offset esteso è scalato per il calcolo dell’indirizzo di salto.
Otterremo così un elaboratore con due sommatori ed un unità di memoria in meno (vedi fig.
10.23).
10.20
IorD
PC
0
M
u
x
1
MemRead MemWrite
RegDst
RegWrite
Memory
MemData
Instruction
[20– 16]
Instruction
[15– 0]
Instruction
register
Instruction
[15– 0]
Memory
data
register
ALUSrcA
0
M
u
x
1
Read
register 1
Instruction
[25– 21]
Address
Write
data
IRWrite
Read
Read
data 1
register 2
Registers
Write
Read
register
data 2
0
M
Instruction u
x
[15– 11]
1
0
M
u
x
1
A
B
4
Write
data
16
Sign
extend
32
Shift
left 2
Zero
ALU ALU
result
ALUOut
0
1 M
u
2 x
3
ALU
control
Instruction [5– 0]
MemtoReg
ALUSrcB ALUOp
Figura 10.23 Implementazione multiciclo.
Il PC, i registri ed il registro IR necessitano di segnali di controllo per la scrittura, mentre la
memoria richiede anche segnali di controllo per la lettura; anche il multiplexer a quattro vie
richiederà un segnale di controllo supplementare. Abbiamo così bisogno di sviluppare
ulteriormente la parte di controllo con tali segnali di controllo aggiuntivi.
10.5.1 Definizione dell’unità di controllo nel caso multiciclo
Nell’unità di controllo dell’implementazione multiciclo si ha maggiore complessita’ perche’
ciascuna istruzione viene eseguita in più passi: tale unita’ deve infatti specificare sia i segnali
da asserire al passo attuale, sia determinare quale sia il passo successivo della sequenza.
Si analizzano due tecniche di specifica dell’unità di controllo, una basata sulle macchine a
stati finiti, l’altra sulla microprogrammazione.
10.5.1.1 Unita’ di Controllo come Macchina a Stati Finiti
Una macchina a stati finiti è caratterizzata da un insieme di stati e da due funzioni dette
funzione di stato futuro e funzione di uscita.
L’insieme di stati corrisponde, nel nostro caso, a tutte le possibili situazioni in cui il
processore multiciclo si puo’ trovare durante l’elaborazione delle istruzioni (questo verra’
approfondito nei successivi paragrafi).
La funzione di stato futuro è una funzione combinatoria che, dato il valore dell’ingresso e
dello stato presenti, determina il prossimo stato assunto dal sistema.
La funzione di uscita produce invece le uscite a partire dallo stato presente e dagli ingressi.
Ciascuno stato specifica l’insieme delle uscite che vengono affermate quando la macchina si
trova in esso (si assume che le restanti uscite, non esplictiamente menzionate siano nonaffermate). In alcuni casi e’ importante che i valori delle uscite siano effettivamente 0 o 1,
evitando situazioni di “non-specificato” che potrebbero generare comportamenti indesiderati
nel processore: ad esempio,i segnali di controllo dei multiplexer selezionano un dato ingresso
se valgono 0 e un altro ingresso se valgono 1: non si deve lasciare il segnale di controllo “nonspecificato”.
Sicuramente, sono quindi presenti almeno cinque passi di esecuzione, corrispondenti a ciascuno
dei 5 cicli di clock necessari per eseguire l’istruzione piu’ lunga (lw).
10.21
I primi due passi di esecuzione sono comuni a tutte le istruzioni, mentre quelli da 3 a 5
dipendono direttamente dal codice operativo: alla fine dell’esecuzione dell’ultimo passo, la
macchina torna allo stato iniziale per prelevare la nuova istruzione. Inoltre sara’ presente uno
stato iniziale (stato 0).
Con riferimento alla figura 10.24, nello stato 0 si asseriscono i segnali MemRead e IRwrite per
leggere un’istruzione dalla memoria e scriverla in IR e si pone IorD (che determina se
l’indirizzo di accesso alla memoria proviene dal PC oppure dalla ALU) a 0 per selezionare PC
come sorgente dell’indirizzo.
I valori dei segnali ALUSrcA (0), ALUSrcB (01), ALUop (00), PCWrite e PCSource (00) fanno
si che PC+4 venga calcolato e memorizzato in PC.
Nello stato 1 si decodifica l’istruzione, si prelevano gli operandi dai registri (ponendoli nei
registri di appoggio A e B) e si calcola l’indirizzo di destinazione del salto (branch target
address) forzando ALUSrcB ad 11, ALUSrcA a 0 ed ALUop a 00: il risultato viene
memorizzato nel registro ALUout (che viene scritto ad ogni ciclo di clock).
Adesso ci troviamo di fronte a quattro possibili operazioni:
• accesso alla memoria (stati 2, 3, 4, 5)
• tipo R (stati 6 e 7)
• salto condizionato -ovvero diramazione- (stato 8)
• salto incondizionato –ovvero jump- (stato 9).
10.5.1.1 Accesso alla memoria
Nello stato 2 viene calcolato l’indirizzo di memoria effettivo, forzando ALUSrcA ad 1,
ALUSrcB a 10 e ALUop a 00 affinchè sul primo ingresso della ALU vada il registro A (che
conterra’ l’indirizzo base) e sul secondo ingresso si ottenga -tramite estensione del segno- il
valore dell’offset indicato nell’istruzione: il risultato viene scritto nel registro ALUout.
Dopo il calcolo dell’indirizzo di memoria, quest’ultima deve essere letta o scritta: se il codice
operativo dell’istruzione è lw allora lo stato 3 effettua la lettura (MemRead attivo); se invece
è sw lo stato 5 effettua la scrittura in memoria (MemWrite attivo).
Sia nello stato 3 che 5 il segnale IorD è posto ad 1 per forzare la provenienza dell’indirizzo di
memoria dal registro ALUout.
Dopo l’esecuzione della scrittura, l’istruzione sw è completa e lo stato futuro è lo stato 0.
Se l’istruzione è invece una load è necessario lo stato 4 per scrivere il risultato proveniente
dalla memoria nel RF (RegWrite attivo, MemtoReg=1, RegDst=0).
10.5.1.2 Istruzione di tipo R
Richiede due stati corrispondenti ai passi di Esecuzione (stato 6) e completamento
dell’istruzione di tipo R (stato 7).
Il primo passo (stato 6) pone ALUSrcA=1 e pone ALUSrcB=00, facendo si’ che i due registri
letti dal RF vengano utilizzati come ingressi della ALU: ALUop viene forzato ad 10 in modo da
istruire l’unità di controllo della ALU ad utilizzare il campo funzione nella determinazione dei
segnali di controllo della ALU.
Nello stato 7 viene attivato il segnale RegWrite per forzare una scrittura nel Register File,
RegDst viene posto a 1 in modo da utilizzare il campo rd come numero di registro
destinazione, mentre MemtoReg=0, in modo da selezionare il registro ALUout come sorgente
del valore che verrà scritto nel Register File.
10.22
10.5.1.3 Salto condizionato
Nel caso del salto condizionato è necessario un solo stato (stato 8), nel quale occorre forzare
i segnali di controllo in modo da causare il confronto dei registri A e B (ALUSrcA=1,
ALUSrcB=00, ALUOp=01) e la scrittura condizionale di PC con l’indirizzo presente nel registro
ALUout (PCWriteCond attivo e PCSource=01).
10.5.1.4 Salto incondizionato
Richiede un solo stato (stato 9) per il completamento: si attiva il segnale PCWrite per forzare
la scrittura di PC e si pone PCSource ad 10 in modo che il valore scritto sia costituito da i 26
bit meno signficativi dell’IR, a cui si concatenano 00due come bit meno significativi ed i 4 bit
più significativi di PC per determinare l’indirizzo effettivo di destinazione del salto (modalita’
di indirizzamento pseudo-indiretta).
Instruction decode/
re gister fetch
Instruction fetch
p
r (O
') o
'LW
=
( Op
2
W
= 'S
')
6
')
Q
'B
E
e)
t yp
R=
p
(O
Branch
com pletion
Exe cution
AL USrcA = 1
ALU SrcB = 10
AL U Op = 0 0
8
AL USrcA = 1
ALU SrcB = 00
ALUO p = 10
Jump
comp letio n
9
AL U Src A = 1
AL USrcB = 0 0
ALU O p = 0 1
PC WriteCond
PC Sourc e = 01
PC W rite
PCS ou rce = 10
(O
p
=
'S
W
')
( Op = 'LW')
AL US rcA = 0
AL U SrcB = 11
AL U Op = 00
(O p = 'J')
Me mory ad dress
com p utatio n
1
=
St art
M emRe ad
ALUSrcA = 0
IorD = 0
IR Write
AL USrcB = 0 1
ALU Op = 0 0
P C Write
PC Sou rce = 00
(O
p
0
Me mory
ac ce ss
3
Mem ory
access
5
M em R ead
Io rD = 1
R-type com ple tion
7
Mem W rite
IorD = 1
R e gD st = 1
Re gWrite
M em toReg = 0
W rite-back step
4
R egDst = 0
R eg Write
M em toReg = 1
Figura 10.24 Diagramma a stati finiti dell’unità di controllo del caso multiciclo.
10.5.1.5 Realizzazione dell’unita di controllo multiciclo con macchina a stati finiti
Una macchina a stati finiti può essere implementata mediante un registro temporaneo che
memorizza lo stato corrente ed un blocco di logica combinatoria che determina sia i segnali
che devono essere affermati nell’unità di elaborazione, sia lo stato futuro (vedi fig. 10.25).
10.23
PCWrite
PCWriteCond
IorD
MemRead
MemWrite
IRWrite
Control logic
MemtoReg
PCSource
Outputs
ALUOp
ALUSrcB
ALUSrcA
RegWrite
RegDst
NS3
NS2
NS1
NS0
Instruction register
opcode field
S0
S1
S2
S3
Op0
Op2
Op1
Op4
Op3
Op5
Inputs
State register
Figura 10.25 Implementazione macchina a stati finiti.
La medesima macchina può essere anche implementata attraverso una PLA (Programmable
Logical Array per la quale rimandiamo alla Appendice 10.A [1]) come in figura 10.26.
Op5
Op4
Op3
Op2
Op1
Op0
S3
S2
S1
S0
PCWrite
PCWriteCond
IorD
MemRead
MemWrite
IRWrite
MemtoReg
PCSource1
PCSource0
ALUOp1
ALUOp0
ALUSrcB1
ALUSrcB0
ALUSrcA
RegWrite
RegDst
NS3
NS2
NS1
NS0
Figura 10.26 Implementazione macchina a stati finiti tramite PLA.
10.24
E’ possibile implementare la macchina a stati finiti anche attraverso una ROM (Redable Only
Memory per la quale rimandiamo ugualmente all’Appendice 10.A [1]) nella quale però compaiono
più volte le stesse combinazioni di valori sulle uscite e per questo risulta non essere
ottimizzata come una PLA, in cui compaiono solo le righe affermate della tabella di verità e
vengono presi in considerazione gli opportuni “non-specificati” e gli eventuali termini prodotto.
Con la ROM otteniamo quindi una rete combinatoria ridondante e non opportunamente
semplificata.
10.5.2 Realizzazione dell’unita’ di controllo multiciclo con Microprogrammazione
Se si vuole implementare un intero set di istruzioni MIPS, l’unità di controllo può richiedere
migliaia di stati con centinaia di sequenze distinte, perciò l’implementazione tramite una
macchina a stati finiti diventerebbe poco gestibile. Si ricorre quindi alla
microprogrammazione che consiste nel progettare l’unità di controllo come un programma che
implementa le istruzioni macchina facendo uso di microistruzioni più semplici. La
microprogrammazione viene utilizzata anche nei processori Pentium .
Una microistruzione rappresenta l’insieme dei segnali di controllo che devono essere asseriti
in un determinato stato; eseguire una microistruzione significa affermare i segnali di
controllo da essa specificati. Nel nostro caso, esamineremo come la macchina a stati finiti
descritta in figura 10.24 possa essere implementata facendo ricorso alla
microprogrammazione.
10.5.2.1 Formato microistruzioni
Nel nostro caso, il formato delle microistruzioni è costituito da sette campi. I primi sei campi
controllano l’unità di elaborazione, mentre il campo Sequencing (il settimo) specifica la
modalità di selezione della microistruzione successiva.
I valori permessi per ciascun campo e l’effetto dei diversi valori dei campi sono riportati nella
tabella 10.8.
10.25
Tabella 10.8 Formato delle microistruzioni.
Field name
ALU control
Value
Signals active
Comment
Add
ALUOp = 00
Cause the ALU to add.
Subt
ALUOp = 01
Cause the ALU to subtract; this implements the compare for
Func code
ALUOp = 10
branches.
SRC1
SRC2
Use the instruction's function code to determine ALU control.
PC
ALUSrcA = 0
Use the PC as the first ALU input.
A
ALUSrcA = 1
Register A is the first ALU input.
B
ALUSrcB = 00
Register B is the second ALU input.
4
ALUSrcB = 01
Use 4 as the second ALU input.
Extend
ALUSrcB = 10
Use output of the sign extension unit as the second ALU input.
Extshft
ALUSrcB = 11
Use the output of the shift-by-two unit as the second ALU input.
Read two registers using the rs and rt fields of the IR as the
register
Read
numbers and putting the data into registers A and B.
Write ALU
Register
control
RegWrite,
Write a register using the rd field of the IR as the register number
RegDst = 1,
and the contents of the ALUOut as the data.
MemtoReg = 0
Write MDR
RegWrite,
Write a register using the rt field of the IR as the register number
RegDst = 0,
and the contents of the MDR as the data.
MemtoReg = 1
Read PC
Memory
Read ALU
MemRead,
Read memory using the PC as address; write result into IR (and
lorD = 0
the MDR).
MemRead,
Read memory using the ALUOut as address; write result into MDR.
lorD = 1
Write ALU
ALU
MemWrite,
Write memory using the ALUOut as address, contents of B as the
lorD = 1
data.
PCSource = 00
Write the output of the ALU into the PC.
PCWrite
PC write
control
ALUOut-cond
jump address
PCSource = 01,
If the Zero output of the ALU is active, write the PC with the
PCWriteCond
contents of the register ALUOut.
PCSource = 10,
Write the PC with the jump address from the instruction.
PCWrite
Sequencing
Seq
AddrCtl = 11
Choose the next microinstruction sequentially.
Fetch
AddrCtl = 00
Go to the first microinstruction to begin a new instruction.
Dispatch 1
AddrCtl = 01
Dispatch using the ROM 1.
Dispatch 2
AddrCtl = 10
Dispatch using the ROM 2.
10.5.2.2 Implementazione del microprogramma
Come possiamo vedere dalla figura 10.27, il microprogramma viene assemblato, memorizzato
nella Microcode Memory ed indirizzato dal contatore di microprogramma, nello stesso modo in
cui un normale programma è memorizzato nella memoria di programma e l’istruzione successiva
viene determinata dal PC. La Microcode Memory può consistere in una ROM oppure essere
implementata tramite una PLA. Le ROM sono modificabili con maggior facilità.
10.26
Control unit
Microcode memory
Outputs
Input
PCWrite
PCWriteCond
IorD
MemRead
MemWrite
IRWrite
BWrite
MemtoReg
PCSource
ALUOp
ALUSrcB
ALUSrcA
RegWrite
RegDst
AddrCtl
1
Microprogram counter
Adder
Op[5– 0]
Address select logic
Instruction register
opcode field
Figura 10.27 Implementazione del microprogramma.
10.27
Datapath
10.A APPENDICE
Poiché nel presente capitolo si fa ampio riferimenti a concetti, seppur basilari, di Reti
Logiche, può essere utile un richiamo veloce a queste nozioni così da rendere la lettura più
chiara.
10.A.1 Latch SR
In una rete sequenziale risulta indispensabile fare uso di elementi che mantengano nel tempo
le informazioni. Il più semplice di questi è il Latch SR che prende questo nome per le
operazioni che compie: il Set ed il Reset.
Il concetto che sta alla base di questa piccola rete sequenziale è un dispositivo che dia in
uscita il valore booleano 1 quando si esegue un Set (ingresso S ad 1 ed ingresso R a 0), il valore
0 quando si esegue un Reset (ingresso S ad 0 ed ingresso R a 1) ed il valore precedentemente
presente in uscita quando non si compie nessuna di queste due operazioni (entrambi gli
ingressi a 0).
S
Q’
R
Q
Figura 10.28 Latch SR.
La proprietà prima del Latch è quella di essere trasparente cioè mutare le uscite ad ogni
cambiamento degli ingressi: questo risulta scomodo specialmente quando dobbiamo essere
sicuri che la logica combinatoria abbia effettuato determinate operazioni prima che nuovi
valori vengano immessi nella rete.
Per fare ciò dovremo temporizzate il lavoro del Latch tramite un segnale di clock che abiliti o
disabiliti la sua commutazione. Ci troveremo così in presenza di un Latch con segnale di
abilitazione come in fig 10.29 detto Clocked Latch SR .
S
Q’
Ck
Q
R
Figura 10.29 Latch SR “clockato”.
L’evoluzione naturale di questo sistema è quello che prende il nome di Latch SR edge triggered
o più propriamente Flip-Flop Master Slave realizzato a partire da due Latch SR a cascata con
opposti segnali di abilitazione.
10.28
Q1
S
Q2
Ck
S
Q
Ck
Ck
R
Q
R
Q1
Figura 10.30: Flip – Flop Master Slave.
Latch SR edge triggered.
Questo si differenzia in due sottocategorie: SR positive edge triggered (”apre le orecchie”
sul fronte in salita del clock) e l’SR negative edge triggered (”apre le orecchie” su un fronte in
discesa del clock). La rappresentazione grafia dei due casi e’ riportata in figura 10.31.
Ck
Ck
Positive
Negative
Figura 10.31 Flip – Flop SR eccitati sul fronte in salita e sul fronte in discesa del clock.
10.A.2 Latch D
Poichè il Latch SR in presenza di una particolare combinazione di ingresso dei segnali
(entrambi 1) tende a divenire instabile, è possibile realizzare partendo da questo un
particolare latch che impedisce la comparsa di questa combinazione e funziona in modo ancora
più elementare del Latch SR impulsato: questo è il Latch D realizzato inviando il segnale che
vogliamo memorizzare, affermato sulla porta S e complimentato sulla porta R così che se
l’ingresso vale 1 avremo un operazione di Set, se vale 0 un operazione di Reset.
S
D
Q
Ck
Q
R
Figura 10.32 Latch D.
Analogamente al SR positive e negative edge triggered possiamo implementare un Flip-Flop D
positive e negative edge triggered.
D
S
Q
Ck
R
Q
Figura 10.33 Latch D edge triggered.
10.29
10.A.3 Multiplexer
Nella logica combinatoria, l’ operazione di “if” può essere realizzato tramite una rete logica
caratterizzata da un decodificatore ad n ingressi e 2^n uscite opportunamente collegate ai
2^n segnali tra cui vogliamo scegliere. Un dispositivo con queste caratteristiche è il Mux
(Multiplexer).
A
B
0
1
Figura 10.34 Multiplexer.
10.7 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] F. Fummi, M.G. Sami, C. Silvano, “Progettazione Digitale”
10.30
LEZIONE 11
BUS
11.1 INTRODUZIONE
In un sistema di elaborazione i vari sottosistemi (processore, memoria, dispositivi I/O)
devono essere interfacciati l’uno con l’altro per comunicare tra loro. Tale obiettivo è
normalmente ottenuto tramite l’uso di un BUS.
Il BUS è un canale di comunicazione condiviso che usa un insieme di fili per collegare diversi
sottosistemi (Fig.11.1).
CPU
RAM
ROM
BUS
n fili
PERIF.
I/O
PERF.
I/O
Figura 11.1 : Esempio di BUS.
11.2 DESCRIZIONE DEL BUS
Un BUS tipicamente contiene almeno un insieme di linee di controllo ed un insieme di linee per
trasferire i dati (Fig.11.2).
•
•
Linee di Controllo : sono utilizzate per avanzare delle richieste e segnalare la ricezione,
nonché per indicare il tipo di informazione presente sulle linee dati.
Linee Dati :
portano le informazioni dalla sorgente alla destinazione; tali
informazioni possono consistere in dati o indirizzi.
Linee di controllo
Linee dati
n
p
Figura 11.2 : n=numero di linee di controllo, p=numero di linee dati.
11.1
Esempio: se un disco vuole scrivere in memoria dei dati, le linee dati verranno utilizzate
per specificare l’indirizzo in memoria nel quale collocare i dati, nonché per
trasportare i dati effettivi provenienti dal disco; le linee di controllo saranno usate
per indicare quale tipo di informazione sia contenuta sulle linee di dato del BUS in
ciascun momento del trasferimento.
Alcuni BUS possiedono due insiemi di linee per trasferire separatamente dati e indirizzi nel
corso di un'unica fase di trasmissione su BUS (le linee di controllo continuano a svolgere la
stessa funzione). In questo caso si parla di BUS non-multiplexato.
11.3 VANTAGGI E SVANTAGGI DEL BUS
VANTAGGI
Versatilità : tramite definizione di un unico standard di connessione si possono
aggiungere facilmente nuovi dispositivi al BUS. Inoltre una data periferica può essere
usata su un calcolatore diverso che usa un BUS che segue lo stesso standard;
Basso costo : un unico insieme di fili può bastare per gestire i collegamenti con più
dispositivi;
Gestione complessità : suddividendo il sistema servendosi di più BUS si riduce la
complessità.
SVANTAGGI
“Collo di bottiglia” nelle comunicazioni : la banda del BUS limita il massimo throughput
ottenibile per I/O : è necessario minimizzare il tempo richiesto per l’accesso al BUS ma,
per garantire elevate prestazioni di I/O, si deve massimizzare l’ampiezza di banda;
Limiti sulla velocità : le caratteristiche fisiche del BUS (lunghezza, numero di dispositivi
collegati) non permettono velocità di lavoro arbitrarie che inoltre sono limitate dalla
necessità di supportare dispositivi aventi tempi di latenza e velocità di trasferimento dati
ampiamente variabili (es. tastiere, video,…).
11.4 CONNESSIONI TRA UNITÀ FUNZIONALI TRAMITE BUS
Il modo più semplice di interconnettere più unità funzionali tra di loro è quello di utilizzare un
unico BUS, detto BUS di Sistema, al quale sono collegati CPU, memoria e dispositivi di I/O
(Fig.11.3).
Bus di Sistema
CPU
PERIF.
I/O
PERIF.
I/O
Figura 11.3: BUS di sistema
11.2
MEMORIA
A volte può essere più efficace (ma sicuramente più costoso) collegare le varie unità usando
due o più BUS (Fig.11.4). In questo caso distingueremo:
• BUS di memoria, collegante CPU e unità funzionali di memoria;
• BUS di I/O, collegante CPU e unità funzionali di I/O.
BUS I/O
Input
CPU
MEMORIA
Output
BUS Memoria
Figura 11.4: BUS di Memoria e di I/O.
E’ opportuno, a questo punto, classificare i BUS in tre categorie : BUS processore-memoria,
BUS di I/O, BUS di backplane.
11.5 TIPI DI BUS
¾ BUS processore-memoria
: seguono di solito standard PROPRIETARI, ovvero
standard definiti ed utilizzati da una singola azienda, e sono caratterizzati da
lunghezza limitata ed alte velocità di lavoro; vengono ottimizzati rispetto alle
caratteristiche del sistema di memoria tale da memorizzare l’ampiezza di banda
memoria-processore (Fig.11.6,11.7);
¾
BUS I/O : diversamente dal BUS processore-memoria sono tipicamente abbastanza
lunghi e lenti, devono essere adatti a collegare dispositivi I/O molto diversi tra di loro
e quindi tollerano un ampio intervallo di banda dei dati di tali dispositivi; non si
interfacciano direttamente con la memoria, ma si connettono al BUS processorememoria o al backplane BUS tramite un adattatore di BUS (Fig.11.6);
¾
BACKPLANE BUS : sono progettati in maniera da permettere ai processori, alla
memoria e ai dispositivi di I/O di coesistere e cooperare tra di loro su un singolo BUS
ottenendo un notevole risparmio di risorse (Fig.11.5,11.7).
Backplane Bus
Processore
Memoria
Disp
.I/O
Disp
.I/O
Disp
.I/O
Disp
.I/O
Figura 11.5: Sistema con un solo tipo di BUS: semplice e a basso costo ma lento e genera un“collo di
bottiglia”.
11.3
Bus Processore-Memory
Processore
Memoria
Adattatore
di Bus
BUS
I/O
Adattatore
di Bus
Adattatore
di Bus
DispI
/O
DispI
/O
DispI
/O
DispI
/O
DispI
/O
DispI
/O
Figura 11.6 : Sistema con due tipi di BUS : i BUS di I/O si connettono al BUS processore-memoria attraverso
degli “adattatori” o “bridge” e forniscono gli slot di espansione per i dispositivi di I/O.
Bus Processore-Memory
Processore
Memoria
Disp
.I/O
Adattatore
di Bus #1
Backplane Bus
Adattatore
di Bus #2
Adattatore
di Bus #2
Disp
.I/O
Bus di I/O
Bus di I/O
Disp
.I/O
Disp
.I/O
Figura 11.7 : Sistema con tre tipi di bus : il carico sul BUS processore-memoria è fortemente ridotto.
Durante la fase di progetto, il progettista di un BUS processore-memoria conosce
esattamente il tipo di tutti i dispositivi che devono essere connessi al BUS, mentre il
progettista di un BUS di I/O o di backplane deve progettare il BUS in modo da poter
accettare dispositivi non noti a priori, con caratteristiche diverse in termini di latenza e
ampiezza di banda. Per questo motivo, di norma, un BUS di I/O presenta un’interfaccia
relativamente semplice e di basso livello verso il dispositivo.
11.6 CONTROLLO DEL BUS : MASTER/SLAVE
Una volta descritte le caratteristiche principali del BUS, valutiamo come un dispositivo che
desidera comunicare tramite il BUS possa utilizzarlo. E’ ovvio che è necessario uno schema
per controllare l’accesso dei vari dispositivi al BUS: se non ci fosse alcun controllo, dispositivi
diversi che volessero comunicare cercherebbero ciascuno di forzare sulle linee di controllo e
di dato i valori corrispondenti a trasferimenti diversi, rendendo di fatto impossibile l’uso. Per
gestire l’accesso è necessario che un’unità funzionale detenga il controllo del BUS: il BUS
MASTER. E’ questo dispositivo che controlla tutte le richieste sul BUS. Le rimanenti unità
funzionali, che non detengono il controllo del BUS, si dicono SLAVE. Generalmente la CPU
possiede il controllo del BUS, ma può anche cedere temporaneamente questo ruolo ad altre
11.4
unità funzionali. Viceversa la memoria è normalmente uno slave, dal momento che risponde alle
richieste di lettura e scrittura, ma non genera mai proprie richieste (Figura 11.8).
MASTER
CPU
CPU
CPU
I/O
Coprocessore
SLAVE
Memoria
Unità I/O
Coprocessore
Memoria
CPU
ESEMPIO
prelievo istruzione e lettura/scrittura dati
ricezione/invio dati da/a unità di I/O
la CPU dà istruzioni al coprocessore
accesso diretto alla memoria
il coprocessore legge operandi dalla CPU
Figura 11.8 Unità funzionali che detengono il controllo del BUS.
Il sistema più semplice tra quelli possibili è costituito da un singolo BUS MASTER che
controlla tutte le richieste di BUS. Il principale svantaggio di un simile sistema sta nel fatto
che il master deve essere coinvolto in ciascuna operazione. Lo schema alternativo a questo
consiste nell’avere più master, ognuno dei quali in grado di iniziare un trasferimento. In
questo caso, deve esistere un meccanismo per arbitrare l’accesso al BUS così che questo
avvenga in modo coordinato.
11.7 FUNZIONAMENTO DEL BUS : PROTOCOLLO E TRANSAZIONI
Un protocollo di BUS definisce come una parola o un blocco di dati debbano essere trasferiti
su un insieme di fili. L’operazione che permette a master e slave di comunicare tra loro sul
BUS è detta Transazione ed include due fasi:
•
•
la richiesta (dare il comando o l’indirizzo);
l’azione (trasferire i dati);
Il master inizia la transazione sul BUS dando il comando o specificando l’indirizzo; lo slave
risponde alla richiesta inviando i dati al master (se il master richiede dati) o prelevando i dati
inviati dal master (se il master vuole mandarli) (Figura 11.9).
BUS
MASTER
Il MASTER dà il comando
…i dati vanno in una delle direzioni…
BUS
SLAVE
Figura 11.9: Transazione MASTER/SLAVE
Più in dettaglio, Un trasferimento di dati si può generalmente scomporre nelle seguenti fasi:
selezione, durante la quale il master seleziona lo slave coinvolto nel trasferimento
precisandone l’indirizzo; attesa, fase che viene eseguita solo se lo slave è relativamente lento
e quindi richiede un tempo di accesso maggiore (stati di wait); infine, trasferimento dei dati
verso l’unità di destinazione.
11.5
11.8 ARBITRAGGIO DEL BUS
Una transazione, come visto, non può avere inizio se non si definisce chi è il MASTER e chi è lo
SLAVE. Che succede se si hanno più master in un BUS? Quale tra questi avanzerà per primo la
propria richiesta di accesso? Quale userà il BUS al ciclo di BUS successivo?
L’operazione che permette di decidere quale dispositivo tra i vari master utilizzerà il BUS
viene chiamata Arbitraggio del BUS. In un qualunque schema di arbitraggio, i vari master
inviano un segnale di richiesta del BUS (BUS request, BReq) ad un arbitro che invia solo ad
uno di questi un segnale di assegnazione del BUS (BUS grant, BGnt). Ricevuto tale “permesso”,
il dispositivo può utilizzare il BUS, segnalando poi all’arbitro il termine della sua transazione;
l’arbitro può quindi assegnare il BUS ad un altro dispositivo. La maggior parte dei BUS a
master multiplo possiede un insieme di linee per eseguire le richieste e le assegnazioni; ogni
dispositivo dovrà inoltre avere una linea per indicare il rilascio del BUS (BUS release, BRel).
Queste due linee hanno due linee lo stesso ruolo di richiesta e di acknowledge nei protocolli
asincroni (vedi 11.9.2). Nella scelta del dispositivo a cui assegnare il BUS, gli schemi di
arbitraggio tentano di trovare un compromesso tra due fattori : priorità e fairness. Ogni
dispositivo possiede una priorità per quanto riguarda il BUS ed il dispositivo con la priorità
più elevata deve essere servito per
primo. D’altra parte, si vorrebbe che tutti i dispositivi, anche quelli con bassa priorità, non
fossero mai completamente esclusi dal BUS; questa proprietà, chiamata fairness (equità),
garantisce che ciascun dispositivo che vuole usare il BUS prima o poi lo otterrà. Si cerca
inoltre di ridurre il tempo necessario per eseguire l’arbitraggio sul BUS, minimizzando i costi
aggiuntivi che questa operazione comporta.
Gli schemi di arbitraggio possono essere suddivisi in quattro principali categorie:
1)
2)
3)
4)
Arbitraggio
Arbitraggio
Arbitraggio
Arbitraggio
Centralizzato Daisy-Chain;
Centralizzato Parallelo;
Distribuito con Auto-Selezione;
Distribuito con Rilevamento delle Collisioni.
La scelta dello schema di arbitraggio più adatto è determinato da una varietà di fattori, tra
cui il livello di espandibilità che deve essere garantito dal BUS in termini di dispositivi di I/O
e di lunghezza del BUS, la velocità richiesta per l’arbitraggio, il grado di fairness richiesto.
11.8.1 Arbitraggio Centralizzato Daisy-Chain
In questo schema, l’abilitazione ad usare il BUS passa da un dispositivo all’altro a partire da
quello con priorità alta (la priorità è determinata dalla posizione sul BUS) tramite
l’attivazione del segnale di grant. Un dispositivo con priorità elevata, nel momento in cui
desidera accedere al BUS, disattiva il segnale di grant in uscita, impedendo ai dispositivi con
priorità inferiore di accedere al BUS (Fig.11.10).
11.6
Device 1
Device 2
Alta
priorità
BGnt
. . .
Device N
Bassa
priorità
BGnt
BGnt
BRel
Arbitro
BReq
Figura 11.10 : Organizzazione di un BUS in Daisy-Chain
Il vantaggio di questo schema di arbitraggio è la semplicità; gli svantaggi stanno nel fatto che
la propagazione “in catena” del segnale di assegnazione limita la velocità del BUS e nel fatto
che la fairness non può essere garantita : una richiesta a bassa priorità può restare bloccata
indefinitamente.
11.8.2 Arbitraggio Centralizzato Parallelo
Gli schemi appartenenti a questa categoria usano linee multiple di richiesta ed i dispositivi
avanzano indipendentemente le loro richieste (segnale Req) di BUS. L’ arbitro centralizzato
sceglie uno tra i dispositivi che hanno avanzato richiesta di accesso e gli comunica che a quel
punto diventa master del BUS inviando il segnale di grant (Figura 11.11).
DEVICE
DEVICE
2
1
BGnt
. . .
DEVICE
N
BReq
Arbitro
BUS
Figura 11.11 : Organizzazione di un BUS con arbitraggio centralizzato
Lo svantaggio di questo schema sta nel fatto che richiede un arbitro centralizzato che può
divenire “collo di bottiglia” nell’uso del BUS e inoltre limita il numero di dispositivi collegabili
(tipicamente fisso). Questo tipo di arbitraggio è usato nella quasi totalità dei BUS
11.7
processore-memoria e nei BUS di I/O ad alta velocità, nonché nei BUS PCI, EISA,
MULTIBUS I.
11.8.3
Arbitraggio Distribuito con Auto-Selezione
Questi schemi utilizzano anch’essi delle linee di richiesta multiple, ma i dispositivi che
richiedono accesso al BUS determinano essi stessi chi riceverà l’assegnazione del BUS.
Ciascun dispositivo che vuole accedere al BUS scrive sul BUS un codice che lo identifica.
Dall’esame del BUS, i dispositivi possono determinare qual è il dispositivo con priorità più
elevata tra quelli che hanno avanzato la richiesta. Non vi è necessità di un arbitro
centralizzato: ciascun dispositivo determina indipendentemente se è il richiedente con più
alta priorità. Questo schema non richiede comunque un numero più elevato di linee di richiesta
rispetto all’arbitraggio centralizzato (Fig.11.12).
DEVICE
1
DEVICE
2
. . .
DEVICE
N
BUS
Figura 11.12 : Schema arbitraggio distribuito
11.8.4 Arbitraggio Distribuito con Rilevamento delle Collisioni
In questo schema, ciascun dispositivo avanza indipendentemente la sua richiesta di controllo
del BUS. Richieste multiple simultanee provocano una collisione. La collisione viene rilevata e si
usa uno schema per la selezione di un dispositivo tra quelli che hanno causato la collisione. Se
un potenziale master prova a trasmettere e trova il BUS occupato non può dare inizio ad una
transazione e deve riprovare l’accesso al BUS in un secondo momento. Il tempo di attesa si
calcola con una legge di decadimento casuale esponenziale per evitare che si ripeta la stessa
combinazione di unità che tentano l’accesso. Un esempio di arbitraggio distribuito con
rilevamento delle collisioni è la rete Ethernet molto utilizzata oggi nelle schede di rete locale
(Figura : 11.12).
11.8.5 Ulteriori tecniche per incrementare le prestazioni del BUS
•
Arbitraggio sovrapposto: si guadagna tempo effettuando la fase di arbitraggio per la
transazione successiva a quella in corso.
11.8
•
•
•
“BUS parking”: il master mantiene il BUS ed effettua varie transazioni senza passare
nuovamente alla fase di arbitraggio fino a che qualche master non si fa avanti.
“Split – phase” (o “packet switched”) BUS: le fasi di indirizzamento e accesso sono
completamente separate ed ognuna necessita di un arbitraggio separato; durante
l’indirizzamento si produce anche un identificatore (tag) del pacchetto che verrà
associato ai dati in fase di risposta per permettere l’abbinamento indirizzo-dato.
Sovrapposizione delle fasi di indirizzamento e accesso (Figura 11.13).
Nei BUS moderni si usano tutte le tecniche precedenti eventualmente combinate tra di loro.
CLK
active
write
wait
data
XXX
RDATA1
addr
ADDR 1
ADDR 2
RDATA2
WR DATA3
ADDR 3
Figura 11.13 : Sovrapposizione fasi indirizzamento e accesso : esempio con singolo master (processorecache).Durante la fase di accesso ai dati inizio già a specificare l’indirizzo del trasferimento successivo.
RDATA1, RDATA2=dati letti, WR DATA=dati scritti, ADDR1, ADDR2, ADDR3=indirizzi associati ad
RDATA1, RDATA2, RDATA3.
11.9 BUS SINCRONI E BUS ASINCRONI
11.9.1 BUS Sincrono
Un BUS sincrono comprende tra le linee di controllo un segnale di clock (Φ) a frequenza
prestabilita, distribuito a tutte le unità funzionali collegate al BUS, ed un protocollo fisso per
la comunicazione basato sulla tempistica di clock. Il clock scandisce le varie transizioni di
segnale ed il passaggio da un ciclo di BUS a quello successivo. Poiché il protocollo è
predeterminato e richiede una quantità ridotta di logica, il BUS può lavorare molto
velocemente e la sua logica di interfaccia sarà altrettanto ridotta (Figura 11.14).
11.9
Protocollo Sincrono
BReq
BGnt
R/W
Address
Cmd+Addr
Wait
Data
Data1
Data1
Data2
Figura 11.14: Diagramma Temporale : lettura da memoria
BReq (BUS Request) : il Master comanda allo slave un’operazione di accesso; è attivo basso. WAIT : lo
Slave richiede al Master una proroga dell’operazione (cioè un ciclo di BUS aggiuntivo, o STATO di
ATTESA), perché ha bisogno di tempo; è attivo basso. BGnt : BUS Grant. R/W ADDRESS : indirizzo
lettura/scrittura.
11.9.2 BUS Asincrono
Un BUS asincrono non possiede un segnale di clock, quindi può supportare un’ampia gamma di
dispositivi ed il BUS può essere reso lungo a piacere senza che insorgano problemi di “clock
skew” 1 o di sincronizzazione. Per coordinare la trasmissione dei dati tra il trasmettitore ed il
ricevitore, un BUS asincrono usa un protocollo detto di Handshaking (“stretta di mano”)
(Figura 15,16). Tale protocollo consiste in una serie di passi nei quali il dispositivo che invia i
dati e quello che li riceve accedono al passo successivo solo quando ambedue le parti sono
d’accordo.
1
Il “clock skew” non e’ altro che un disallineamento del clock che si propaga su fili che raggiungono
periferiche diverse. A causa della differente lunghezza dei fili tali perifieriche non operano in perfetto
sincronismo.
11.10
Handshake Asincrono: Scrittura
Il Master specifica Address
Data
Next Address
Il Master specifica Data
Read
BReq
Ack
t0
t1
t2
t3
t4
t5
Figura 11.15 : t0 : il Master ha ottenuto il controllo e specifica l’indirizzo, la direzione e dati; attende poi
un certo intervallo di tempo affinche’ lo Slave capisca di essere coinvolto in quel trasferimento… t1 : il
Master attiva la linea “Request”. t2 : lo Slave attiva la linea “Ack”, per indicare di aver ricevuto il dato Æ
ha finito. t3 : il Master rilascia “Ack” Æ ha capito che lo Slave ha finito. t4 : lo Slave rilascia “Ack” Æ ha
capito che il Master ha capito. t5 : inizio nuova transazione.
Handshake Asincrono: Scrittura
Il Master specifica Address
Next Address
Data
Read
BReq
Ack
t0
t1
t2
t3
t4
t5
Figura 11.16 : t0 : il Master ha ottenuto il controllo e specifica l’indirizzo, la direzione e dati; attende poi
un certo intervallo di tempo affinche’ lo Slave capisca di essere coinvolto in quel trasferimento… t1 : il
Master attiva la linea “Request” . t2 : lo Slave attiva la linea “Ack”, per indicare che e’ pronto a
trasmettere il dato. t3 : il Master rilascia “Ack” avendo ricevuto il dato Æ ha finito. t4 : lo Slave rilascia
“Ack” Æ ha capito che il Master ha finito. t5 : inizio nuova transazione.
11.9.3 CONFRONTO Bus Sincroni/Asincroni
9 Il BUS sincrono ha il vantaggio di essere semplice da progettare e da controllare,
richiede pochissima logica e va molto veloce.
9 Il BUS sincrono ha lo svantaggio di portare a sprechi di tempo poiché ogni
operazione, anche se si potrebbe completare in meno di un ciclo di clock, si deve
svolgere in un numero intero di cicli. Inoltre ogni dispositivo sul BUS deve andare alla
stessa frequenza di clock e, nel caso di BUS lunghi, per evitare il “clock skew” (vedi
nota 1) si deve abbassare la velocità.
11.11
9 Il BUS asincrono ha il vantaggio di essere più efficiente nell’uso dei cicli: l’operazione
si completa nel tempo di cui necessita.
9 Il BUS asincrono ha lo svantaggio di essere complesso da progettare e da
controllare.
11.10 COME AUMENTARE LA BANDA DEL BUS
Le prestazioni del BUS sono influenzate sicuramente dal protocollo sincrono o asincrono e dai
parametri temporali caratteristici del BUS (caratteristiche fisiche). Per aumentare la banda
disponibile, altri parametri su cui agire sono:
1) Linee di indirizzo e di dato distinte oppure condivise: se si introducono delle linee
distinte per gli indirizzi e i dati potranno essere trasferiti in un singolo ciclo di BUS. In
questo modo, però, il sistema necessita di più fili e di conseguenza la sua complessità
aumenta.
2) Ampiezza del BUS Dati: aumentando l’ampiezza del BUS dati il trasferimento di parole
richiede un numero minore di cicli di clock. Anche in questo caso il sistema necessita di più
fili (ad esempio nello SPARCstation 20 il BUS di memoria è a 128 bit).
3) Trasferimento a Blocchi (burst transfer): questa soluzione permette di ridurre il tempo
necessario per il trasferimento di un blocco di grandi dimensioni, trasferendo più parole in
cicli di BUS consecutivi. In questo modo evito di ripetere l’indirizzo quando trasferisco più
parole successive specificando solo quello della prima parola; il BUS non viene rilasciato
fino a che l’ultima parola non è arrivata. La complessità del sistema aumenta come anche il
tempo di risposta nei casi di singola richiesta.
11.11 ESEMPIO DI BUS: IL BUS USB
Ai calcolatori sono spesso collegate numerose periferiche a bassa/media velocità: tastiere,
mouse, casse acustiche,cuffia, microfono, ecc. Inizialmente ognuna di queste periferiche
aveva un proprio BUS di I/O indipendente. Il BUS USB è stato ideato allo scopo di fornire un
BUS di I/O universale per le periferiche a bassa/media velocità.
11.11.1 Vantaggi e obbiettivi del BUS USB
I principali vantaggi e obbiettivi del BUS USB sono:
Facilità di connessione fisica;
Unico tipo di cavo di BUS;
Alimentazione fornita dal cavo del Bus;
Economicità;
Periferiche installabili a “caldo”;
Eliminazione dei cavallotti dalle schede di I/O.
11.11.2 Caratteristiche del BUS USB
Le caratteristiche principali del BUS USB sono:
BUS di I/O sincrono seriale (i dati vengono trasmessi un bit alla volta su un unico filo
di collegamento);
cavo elettrico a 4 fili;
banda dati a 12 Mbit/sec. (ver. 1.0) oppure a 480Mbit/sec. (ver. 2.0).
11.12
LEZIONE 12
BUS PCI, SCSI e USB
12.1 IL BUS PCI
La sigla PCI (Peripheral Component Interconnect) indica un bus sincrono a 32/64 bit,
caratterizzato da clock a 33/66 Mhz e alimentazione a 3.3V o 5V (fig. 12.1). Le specifiche
rilasciate da Intel per quanto riguarda il connettore (slot) PCI dichiarano 124 piedini (pin) per
la versione a 32 bit e di 188 piedini per la versione a 64 bit. Di questi, 8 (LOCK) hanno un
significato esclusivamente strutturale (sono necessari per il corretto alloggiamento delle
periferiche) e non corrispondono ad alcuna linea. I segnali in gioco, come vedremo in seguito,
sono perciò 116 o 180 (rispettivamente per la versione a 32 o 64 bit). Nella parte che segue
sono indicati i dettagli di funzionamento.
Figura 12.1. Connettori PCI.
12.1.1 Segnali PCI
Lo schema generale di interconnessioni di un dispositivo PCI è riportato in figura 12.2.
Figura 12.2. Segnali previsti dallo standard PCI (# indica i segnali attivi bassi).
Dal punto di vista elettrico i segnali possono appartenere a una di queste categorie:
12.1
•
•
•
•
•
IN : segnale di solo ingresso,
OUT : segnale di sola uscita,
T/S : segnale tristate bidirezionale (I/O),
S/T/S : segnale tristate pilotato da un solo agente per volta (un agente che lo attiva
deve anche disattivarlo per un ciclo di clock prima di lasciarlo in un terzo stato),
O/D : segnale open drain.
I segnali sono divisi inoltre in 2 classi: richiesti e opzionali. Quelli richiesti sono indispensabili
per realizzare le funzionalità base dell’interfaccia, mentre quelli opzionali non sono necessari
ma devono essere impiegati per realizzare funzionalità aggiuntive.
Segnali richiesti (47 per il target e 47 + 2 di arbitraggio per il master):
• 32 linee di address/data - AD[31..0],
• 4 linee per Comandi o Byte_Enable – C/BE[3..0],
• 1 linea per indicare la parità – PAR,
• 6 Linee di Controllo dell’interfaccia - FRAME#, TRDY#, IRDY#, STOP#, DEVSEL#,
IDSEL,
• 2 Linee di gestione Errori - PERR#, SERR#,
• 2 Linee di Arbitraggio - REQ#, GNT#, sono linee NON-condivise che vanno all’arbitro
PCI ,
• 2 Linee di Sistema - CLK, RST#, clock e reset.
Opzionali (52 linee di cui 37 per l’estensione a 64 bit e 15 comuni):
Estensione a 64 bit:
•
•
•
32 Linee aggiuntive per l’estensione del bus a 64 bit - D[63..32] usate per i 32 bit
aggiuntivi dei dati,
4 Linee per Byte_Enable sui 32 bit aggiuntivi - BE[7..4],
1 Linea per la parita’ sui 32 bit di dati aggiuntivi - PAR64.
Comuni:
•
•
•
•
•
•
2 Linee per la negoziazione di trasferimenti a 64 bit - REQ64#, ACK64# ,
1 Linea di supporto per transazioni multiple – LOCK,
2 Linee di supporto Cache Coherency - SBO, SDONE,
4 Linee di gestione delle Interruzioni - INTA#, INTB#, INTC#, INTD#,
5 Linee di JTAG/Boundary Scan (IEEE 11491) - TDI, TDO, TCK, TMS, TRST, usate per
testing e diagnostica,
1 Linea per indicare il funzionamento a 33 o 66 MHz - M66EN (solo presente nella
versione a 3.3V).
I rimanenti sono segnali di alimentazione, riservati o di I/O (52 comuni e altri 27 nella versione a 64
bit), per arrivare a un totale di 116 segnali sulla porzione a 32 bit e 180 su quella a 64 bit.
12.2
12.1.2 Principi di funzionamento
La funzione più importante è il trasferimento di dati in modalità ‘burst’, ovvero a pacchetti di
dati di lunghezza variabile, con il quale si raggiungono velocità di trasferimento di 132
Mbyte/s (per la versione a 32 bit, 33 Mhz) .
Naturalmente è possibile trasferire anche un dato alla volta con velocità di 66/33Mbyte/s
(R/W per la versione a 32 bit, 33 Mhz). Il clock sincronizza tutte le azioni del bus, e nella
versione 2.0 può raggiungere i 66 Mhz. I segnali sono campionati sul fronte in salita del clock
(positive edge).
12.1.2.1 Trasferimenti
Inizialmente il bus si trova in stand-by, ovvero in una fase di riposo in cui non viene compiuta
alcuna operazione. La negoziazione avviene tra un dispositivo master principale e un dispositivo
slave.
In ogni trasferimento possiamo individuare una fase di indirizzamento in cui vengono
comunicati gli indirizzi, il tipo di trasferimento che deve essere effettuato e una o più fasi di
trasferimento effettivo di dati che terminano con il ritorno allo stand-by.
Per effettuare un trasferimento il dispositivo che prende il controllo del bus (master o
initiator) deve essere autorizzato da un arbitro centralizzato e parallelo di cui parleremo in
seguito, mentre la verifica della disponibilità del bus spetta al suddetto dispositivo.
Cerchiamo di capire meglio, anche in relazione ai segnali in gioco (trattati nel paragrafo
successivo) come si struttura il trasferimento.
Il segnale FRAME# attivato dal master segna l’inizio della transazione (fig. 12.3):
•
•
•
Fase di indirizzamento : dura un periodo di clock; una volta che l’iniziatore ha attivato
FRAME# , identifica il dispositivo target (slave) tramite l’indirizzo su AD[0..31]
(Address/Data) e definisce il tipo di transazione tramite il bus dei comandi C/BE[3:0]
(Command/Byte Enable). Il target (ad es. una memoria) memorizza l’indirizzo e lo
autoincrementa per i successivi dati. Quando un dispositivo PCI si riconosce come
target, attiva il segnale DEVSEL# che, se non viene ricevuto entro un tempo limitato
dal master, provoca l’annullamento della transizione (timeout) da parte dell’initiator.
Fase Dati : ad ogni colpo di clock le linee C/BE[3:0] hanno la funzione di Byte Enable.
IRDY# e TRDY# indicano rispettivamente se iniziatore e target sono pronti. Se sono
entrambi attivati viene scambiato un dato per ciclo di clock, altrimenti viene introdotto
un ciclo di attesa. La durata totale del burst è sancita dal segnale FRAME#, attivo
dall’inizio della fase indirizzamento fino all’inizio dell’ultimo trasferimento dati.
Ritorno in stand-by : l’iniziatore disattiva il segnale FRAME# sul penultimo dato e
IRDY# dopo l’ultimo. Successivamente il bus torna in stato di stand-by.
12.1.2.2 Indirizzamento
Per quanto riguarda l’indirizzamento il PCI distingue tra spazio degli indirizzi di memoria,
spazio degli indirizzi I/O e spazio degli indirizzi di configurazione. Quest’ultimo (parte del
sottosistema I/O) è caratteristica dei dispositivi PCI, che permettono due tipi di decodifica.
•
•
Decodifica in positivo : il dispositivo controlla se l’indirizzo è all’interno del campo a lui
assegnato (metodo usuale).
Decodifica sottrattiva : il dispositivo risponde solo se tutti gli altri non hanno risposto.
12.3
12.1.3 Transazioni PCI (R/W)
Come detto in precedenza tutte le transazioni PCI partono dall’attivazione da parte del
master del segnale FRAME#. L’initiator specifica anche il tipo di transazione voluta sulle linee
C/BE nel primo ciclo di clock. A quello successivo può cominciare la fase di trasferimento dati.
La sorgente dei dati (master o slave rispettivamente per write o read) deve attivare il
corrispettivo segnale xRDY# (x = I o T per W/R) tutte le volte che i dati sono validi. I dati
sono trasferiti su tutti i fronti del clock nei quali sia IRDY# che TRDY# sono attivi. Se uno
dei due non lo è si genera un ciclo di wait (attesa). Nei diagrammi che seguiranno le 2
freccette che si susseguono su una linea interrotta stanno a indicare la fase di turnaround, in
cui un dispositivo rilascia il segnale che aveva pilotato fino a quel momento per permettere ad
un altro di entrarne in controllo.
12.1.3.1 Fase di Read (lettura)
Nella figura seguente (12.3) è illustrata la temporizzazione di una tipica fase di lettura.
1
2
3
4
6
5
7
8
9
CLK
FRAME#
a
b
AD
Address
C/BE#
Bus CMD
g
d
DATA-1
DATA-2
DATA-3
c
Byte Enable
Byte Enable
Byte Enable
f
IRDY#
h
e
TRDY#
DEVSEL#
Fase Indirizzi
Fase Dati
Fase Dati
Ciclo di attesa
Ciclo di attesa
Fase Dati
Ciclo di attesa
Transazione del bus
Figura 12.3. Temporizzazione della fase di lettura del bus PCI.
La transazione di read si svolge nel seguente modo: sul primo ciclo di clock viene attivato il
segnale FRAME# (a) dal master, che ha posto sulle linee AD[0..31] l’indirizzo e sulle linee
C/BE[0:3] il comando di lettura (b). Durante il secondo ciclo di clock il master asserisce
IRDY#, C/BE assume la funzione di Byte-Enable (c) e le linee AD cambiano proprietario,
richiedendo di lasciar passare il ciclo per stabilizzarsi. Con il terzo ciclo di clock ha inizio la
fase dati. Il dispositivo slave risponde al master attivando il segnale DEVSEL#, il segnale
TRDY# e disponendo i dati (d). Il primo dato, ritenuto valido sul fronte in salita del quarto
ciclo di clock, viene trasferito. Nel caso in cui lo slave non sia in grado di produrre un secondo
dato, come nel quinto ciclo di clock, disattiva TRDY# (e) causando un ciclo di attesa; tuttavia
12.4
il dato data-1 rimane sulle linee AD. Il periodo di wait finisce sul fronte in salita del sesto
ciclo di clock e lo slave trasferisce il secondo dato considerato valido dopo la sua disposizione
sulle linee (IRDY# e TRDY# attivi). Nel settimo ciclo di clock è l’initiator ad introdurre una
fase di wait disattivando IRDY# (f), mentre, in previsione della conclusione durante il ciclo
successivo, disattiva anche FRAME# (g). Il target mantiene i dati sul bus per un ciclo extra (il
ciclo 8), sul quale si conclude la transazione (h).
12.1.3.2 Fase di Write (scrittura)
Per quanto riguarda la fase di scrittura, il protocollo è del tutto simile a quello di lettura, ma
manca il turnaround sulle linee AD, che sono sempre pilotate dall’initiator (questo implica che
la scrittura del dato singolo avviene più velocemente rispetto alla lettura).
1
2
3
Address
DATA-1
5
4
6
7
8
9
CLK
FRAME#
AD
C/BE#
Bus CMD
Byte
En.
DATA-2
DATA-3
Byte Enable
Byte
En.
IRDY#
TRDY#
DEVSEL#
Fase Indirizzi Fase Dati
Fase Dati
Fase Dati
3 Cicli di attesa
Transazione del bus
Figura 12.4. Temporizzazione della fase di write.
Anche in questo caso si trasferiscono 3 dati, ma la transazione può iniziare a partire dal
secondo ciclo di clock per quanto appena detto.
Si noti (fig 12.4) che FRAME# sembra apparentemente disabilitato molto presto, ma in realtà
è disabilitato su quello che, trascurando i cicli di wait, è il penultimo ciclo di dati per il master.
12.1.3.3 Fine trasferimento
La richiesta di fine trasferimento può pervenire sia dal master che dallo slave, ma il
trasferimento e’ effettivamente concluso dalla disattivazione del segnale FRAME# da parte
del master.
12.5
•
Fine trasferimento comandata dal master: può avvenire per completamento come negli
esempi precedenti, per timeout se è finito il tempo a disposizione del master e il
segnale GNT# è stato disattivato dalla logica di arbitraggio, o per conclusione
anticipata (master abort), se i segnali TRDY# e DEVSEL# non vengono mai attivati
perchè nessun dispositivo risponde al master (che disasserisce IRDI# e FRAME#).
Inoltre si distinguono 3 categorie fra i dispositivi che decodificano in positivo in base
alla velocità con cui attivano DEVSEL# : Fast se rispondono al primo ciclo di clock dopo
FRAME#, Med se rispondono al secondo, Slow al terzo. Se al quarto ciclo non ha
ancora risposto nessun dispositivo a decodifica positiva e non risponde un dispositivo
con decodifica sottrattiva si ha appunto la conclusione anticipata.
•
Fine trasferimento comandata dallo slave : viene usato il segnale STOP# per chiedere
al master la fine del trasferimento. Esistono tre modalità: Retry , in cui lo slave chiede
al master di ritentare più tardi, Disconnect, dove lo slave chiede di interrompere il
trasferimento corrente e Target abort, con il quale lo slave indica che non vuole
riattivare il trasferimento nemmeno in un secondo tempo.
12.1.4 Arbitraggio
Lo schema dell’arbitraggio è del tipo centralizzato e parallelo, sovrapposto alla fine del
trasferimento precedente in modo che nessun ciclo di bus venga penalizzato. Per
comprenderne meglio il funzionamento ci riferiamo a questo esempio in cui il master B ha
priorità più alta rispetto ad A ma inoltra la richiesta di uso del bus dopo che A ne è già
entrato in controllo. La sequenza è schematizzata in fig. 12.5.
1
2
3
4
5
6
7
CLK
REQ#-A
REQ#-B
b
GNT#-A
a
GNT#-B
c
FRAME#
IRDY#
TRDY#
AD
Address
DATA
Dato di A
Address
Dato diB
Figura 12.5. Arbitraggio nel caso dell’esempio precedente.
12.6
DATA
GNT# è il segnale di grant, ovvero di assegnazione del bus da parte dell’arbitro, mentre
REQ# indica la richiesta di grant inoltrata da un master.
Come si vede inizialmente A ha il grant (a), ma in seguito alla richiesta da parte di B (b)
l’arbitro sposta i privilegi su di lui (c). Il trasferimento di A potrà riprendere quando sarà
finito quello di B (ovvero quando A riconoscerà il bus libero, in questo caso sull’ottavo fronte
in salita del clock).
Se il master mantiene asserito REQ# e gli viene mantenuto il GNT# per mancanza di
richieste a priorità più alta, può iniziare una serie di transizioni consecutive senza necessità di
arbitraggio (cicli back-to-back), impiegando al massimo il bus. Questo entra a far parte di una
tecnica di ottimizzazione PCI detta bus parking.
12.1.5 Bloccaggio risorse
Tramite il segnale LOCK# un master può bloccare uno slave a suo esclusivo utilizzo (lo slave
risponderà con il segnale STOP# ai master non proprietari). Il master che dispone del grant
dovrà sincerarsi che questa linea, utilizzabile solo da un initiator per volta, non sia già in uso,
mentre se è già stata attivata dovrà attendere che si liberi. I master possono comunque
accedere agli slave che non sono bloccati, infatti lo stato del segnale LOCK# non ha effetto
sull’abilità di un target di rispondere alle transizioni.
12.2 IL BUS SCSI
12.2.1 Introduzione
Il bus SCSI(Small Computer System Interface) è un tipico esempio di bus con protocollo
asincrono, I/O parallelo di basso costo e molto flessibile. E’ molto semplice dal punto di vista
costruttivo, infatti il bus è fisicamente un cavo piatto con i suoi connettori, lungo non più di 6
metri. A causa delle frequenze in gioco i conduttori possono presentare però dei
comportamenti irregolari (riflessione del segnale….); per minimizzare gli effetti di disturbo si
inseriscono due terminatori di linea agli estremi del bus, solitamente uno dentro la scatola del
sistema e l’altro connesso all’ultima periferica della catena. Infine è prevista una linea di
potenza che fornisce tensione alle reti resistive dei due terminatori.
La complessità del bus è quindi interamente ai controllori che equipaggiano i dispositivi e negli
eventuali adattatori al bus del sistema.
12.2.2 La configurazione
Terminatore
Z= 50 ohm
Bus SCSI
T
T
HOST
ADAPTER
7
Device
Controller
6
Device
Controller
5
COMPUTER
Device
Controller
0
ID
Figura 12.6 Configurazione del bus SCSI.
12.7
Occorre precisare che ogni dispositivo sul bus SCSI ha un suo identificativo (ID, fig. 12.6)
che entra in ballo durante le fasi operative. Poiché i dispositivi possono essere al massimo 8 si
è scelto di rappresentare l’identificatore con un bit che è trasmesso/ricevuto su uno degli 8
bit delle linee dati.
I dispositivi hanno tutti differente priorità: il dispositivo a priorità più alta è quello
identificato da DB(7), che è tipicamente l’”host adapter”, il meno prioritario identificato da
DB(0) tipicamente quello che fa il ”boot” del sistema.
12.2.3 Il funzionamento
Lo standard SCSI permette il collegamento di differenti periferiche (dischi, stampanti, ecc..)
per le quali è comunque richiesta una interfaccia conforme.
In un dato istante la comunicazione sul bus è consentita solamente a due dispositivi, un
dispositivo funziona come “Initiator” (iniziatore o master), l’altro funziona da “Target”
(obbiettivo o slave). Solitamente un dispositivo SCSI è o target o initiator ma esistono anche
apparecchiature che possono svolgere entrambi i ruoli.
Initiator: tipicamente ruolo svolto dal calcolatore (Host) ma in generale è il dispositivo che
ordina l’esecuzione di una certa operazione (es. lettura dei dati).
Target: dispositivo che esegue l’operazione ordinata dopo aver acquisito il controllo del bus.
Sul bus devono essere collegati almeno un initiator ed un target, ma possono essercene anche
di più. Il bus SCSI permette di collegare al massimo 8 dispositivi ma ogni loro controllore può
avere 8 unità logiche ed ognuna di queste puo’ avere 256 sottounità, quindi nel caso di singolo
host si arriva teoricamente a 7*8*256=14000 periferiche collegabili (Figura 12.7).
Bus SCSI
HOST
adattatore
Controller
scsi 0
Computer
Controller
scsi 6
Figura 12.7 Schema connessioni SCSI con più obbiettivi.
12.2.4 Modalità di trasferimento
Il trasferimento di informazioni sulle linee dati (che avviene a 8, 16, 32 bit) è asincrono, ed in
un singolo ciclo viene trasferito un byte.
La modalità di funzionamento permette l’esecuzione dei comandi in modo parallelo da parte di
diverse periferiche.
12.8
Normalmente l’host trasmette un comando al controllore SCSI della periferica selezionata
quindi si sconnette dal bus lasciandolo libero per altre transazioni; quindi la periferica tramite
il suo controllore si riconnette all’host per concludere la transazione.
12.2.5 Segnali SCSI
Il bus SCSI è più semplice rispetto agli altri tipi di bus; prevede infatti solamente 9 linee per
i dati (8 bit dati che sono indicati come DB(0)-DB(7), ed un bit di parità indicato con DB(P)), e
9 linee di controllo.
La semplicità del bus deriva dal fatto che i dispositivi SCSI si fanno carico della gestione del
traffico sul bus stesso, delle periferiche e dell’accesso alla memoria del sistema.
I segnali di controllo sono i seguenti:
•
•
•
•
•
•
•
•
•
/BSY (busy) Asserito da una o da entrambe le parti durante una transazione per
indicare che il bus è in uso (occupato). Questo segnale può essere collegato in modalità
wired-or (cablato).
/SEL (select) Asserito nelle fasi di arbitraggio, selezione e rielezione da parte di un
initiator o di un target. Segnale wired-or.
C/D (control data) Asserito dal target, in stato alto indica che sulle linee dati ci sono
informazioni di controllo, in stato basso che ci sono dati.
I/O (input/output) Pilotato dal target indica la direzione del trasferimento
relativamente all’initiator. Alto significa in ingresso, basso significa in uscita.
/MSG (message) Asserito dal target durante le fasi di invio messaggi.
/REQ (request) Asserito dal target per iniziare un trasferimento asincrono sul bus.
/ACK (acknowledgement) Asserito dall’initiator per indicare di aver accettato o fornito
dati in risposta ad un segnale di richiesta.
/ATN (attention) Asserito dall’initiator per avvisare il controllore che l’initiator ha un
messaggio ad esso destinato.
/RST (reset) Segnale wired-or; che può essere pilotato da qualsiasi dispositivo ed è
usato in genere dall’initiator all‘avvio quando il dispositivo selezionato non risponde.
12.2.6 Fasi del BUS
Il bus ha 8 distinti stati detti “fasi operative”:
1)
2)
3)
4)
5)
6)
7)
8)
Bus Libero,
Arbitraggio,
Selezione,
Riselezione,
Comando,
Dati,
Stato,
Messaggio.
Le ultime quattro fasi sono di trasferimento dell’informazione. Il bus è sempre inizializzato
allo stato 1 di Bus Libero, e ci ritorna ogni volta dopo un reset; in questa fase il segnale /BSY
non è asserito.
Un sistema SCSI può essere: (a) senza arbitraggio; (b) con arbitraggio del tipo daisy-chain. Si
preferisce un sistema senza arbitraggio, dove cioè non ci sono le fasi di Arbitraggio e di
12.9
Riselezione, nel caso di un host solo ed un solo controllore in modo da rendere più veloci le
operazioni.
Accensione o Reset
SELEZIONE O
RISELEZIONE
BUS LIBERO
Qualsiasi fase di trasferimento informazioni:
COMANDO, DATI, STATO o MESSAGGIO
Figura 12.8 Il diagramma di stato del bus SCSI senza arbitraggio.
• Fase di Arbitraggio
Ha lo scopo di assegnare ad un dispositivo SCSI il controllo del bus. Il dispositivo che
acquisisce il controllo può assumere il ruolo di initiator o di target.
Le fasi che si susseguono sono le seguenti (fig. 12.9):
1) il dispositivo che intende acquisire il bus attende che esso sia libero (BSY disasserito),
2) quindi asserisce /BSY e pone il proprio ID (a 8 bit) sul bus dati.
3) dopo un “arbitration delay” il dispositivo esamina le linee dati: se trova asserito un ID
con maggiore priorità allora tale dispositivo si disasserisce; vince il dispositivo che non
trova dispositivi con ID a priorita’ piu’ alta sul bus.
4) il dispositivo che vince la fase di arbitraggio asserisce /SEL.
5) infine ogni dispositivo in arbitraggio si ritira se riconosce /SEL asserito.
12.10
Accensione o Reset
SELEZIONE O
RISELEZIONE
BUS LIBERO
ARBITRAGGIO
Qualsiasi fase di trasferimento informazioni:
COMANDO, DATI, STATO o MESSAGGIO
Figura 12.9 Il diagramma di stato del bus SCSI con arbitraggio.
• Fase di Selezione
In questa fase un initiator seleziona un target allo scopo di inizializzare una qualche funzione
che il tgarget dovrà svolgere. Per un sistema privo di arbitraggio basta che l’initiator selezioni
il target asserendo i loro ID e /SEL. Invece, in un sistema con arbitraggio la fase di selezione
inizia con /BSY e /SEL asseriti dall’initiator che ha vinto dopo l’arbitration delay. Quindi la
fase di Selezione avviene con i seguenti passi :
1) l’initiator asserisce sul bus il proprio ID e quello dell’obiettivo; disasserisce /BSY e I/O
e si pone in attesa della risposta del target;
2) il target che vede il proprio ID sul bus, con /SEL asserito, con /BSY disasserito e I/O
asserito basso capisce di essere stato selezionato e di conseguenza asserisce /BSY;
3) l’initiator che vede tornare /BSY asserito, disasserisce /SEL ed i bit delle linee dati;
Alla fine della fase di selzione l’obiettivo ha il controllo del bus ed è responsabile d’ora in poi
del trasferimento dei dati fino alla fine della transazione.
• Fase di Riselezione
Questa fase è utile nel caso in cui un target abbia necessità di riconnettersi ad un initiator
per continuare un’operazione che richiede più passi per essere eseguita e che era stata in
precedenza interrotta dal target. Questa sospensione ha comportato il ritorno allo stato di
“bus libero” e vi potrebbero essere inseriti altri dispositivi. La riselezione è comandata, al
contrario della selezione, da un target verso un initiator e questo deve anzitutto vincere
l’arbitraggio. La fase inizia con /BSY e /SEL asseriti dall’obiettivo vincente:
1) iIl target disasserisce /BSY, mantiene /SEL, asserisce l’ID proprio, dell’iniziatore e I/O
alto;
2) l’initiator riconosce di essere stato selezionato e risponde asserendo /BSY;
3) il target vedendo /BSY asserito lo riasserisce mantenendolo fino a quando non vorrà
lasciare il bus e disasserisce /SEL;
4) l’initiator vedendo /SEL disasserito rilascia /BSY.
12.11
• Fase di Trasferimento dell’informazione
Dopo la selezione o riselezione, seguono una o più fasi di trasferimento dell’informazione in cui
/BSY è mantenuto asserito dal target che usa i segnali (/MSG, C/D, I/O).
Una tipica transazione SCSI consiste in una fase di Comando, con la quale il target ottiene un
comando dall’initiator, da una serie di fasi Dati, in cui si ha l’effettivo trasferimento e da una
fase di Messaggio durante la quale l’obiettivo invia il messaggio obbligatorio “Command
Complete” (fig. 12.10).
I byte costituenti i messaggi di comandi e i messaggi dati possono essere trasferiti sia in
modo sincrono che asincrono.
Nel trasferimento asincrono viene usato il meccanismo di handshake tramite la coppia
REQ/ACK, ma si può ottenere anche un trasferimento di tipo sincrono logico suddividendo il
trasferimento in finestre temporali dove il target commuta /REQ per oqni byte di dati e
l’initiator deve commutare /ACK lo stesso numero di volte.
Bus
Settle
Delay
Arbitration Delay
Bus Clear Delay + Bus Settle Delay
Bus free delay
Bus set delay
Asserzione di BSY da parte dell’Initiator
Bus clear delay
Asserzione di BSY da parte del Target
Nei sisemi senza arbitraggio, la temporizzazione inizia qui
BSY
SEL
C/D
I/O
MSG
REQ
ACK
ATN
RST
DB
(7-0,P)
Arb. Target
IDs +Init.
IDs
Bus Free
Arbitraggio
Selezione
Primo
Comando
Fase
Comandi
Ultimo
Comando
Byte di
Dati
Fase
Data IN
Byte di
Dati
Byte di
Status
Fase
Invio Status
Comandi
Completati
Fase
Message IN
Bus
Free
Figura 12.10 Transazione completa del bus SCSI.
12.3 BUS USB
Lo Universal Serial Bus (USB) è uno standard di comunicazione seriale nato nel 1995 dalla
collaborazione di quattro multinazionali dell’industria elettronica e informatica: Compaq (oggi
HP), Intel, Microsoft e NEC. Il sistema USB è asimmetrico, consiste di un singolo gestore e
molte periferiche collegate da una struttura simile ad un albero, attraverso dei dispositivi
chiamati hub (concentratori). Supporta fino ad un massimo di 127 periferiche per gestore, nel
computo vanno inclusi anche gli hub e il gestore stesso quindi in realtà il numero totale di
dispositivi collegabili è sensibilmente inferiore.
12.12
Lo standard prevede che il connettore porti anche un segnale per alimentare le periferiche a
basso consumo (fino a 0.5W). Le periferiche che hanno richieste energetiche più elevate di
questa vanno alimentate a parte. I limiti energetici dello standard vanno seguiti
scrupolosamente pena il probabile danneggiamento del gestore, dato che lo standard USB non
prevede nelle specifiche minime la sconnessione in caso di sovraccarico.
Il trasferimento dei dati avviene fisicamente attraverso le variazioni della tensione
differenziale fra due dei quattro fili costituenti l’USB. L’osservazione delle variazioni della
tensione differenziale consente di riconoscere la connessione/disconnessione degli apparati.
USB è stato pensato per consentire un semplice connessione e disconnessione. Lo standard è
stato progettato in modo da consentire un semplice aggiornamento dei sistemi sprovvisti di
USB attraverso una scheda PCI o ISA. Le porte USB supportano la rimozione “a caldo” (hot
swap) e il reinserimento delle periferiche senza dover riavviare il computer (plug and play).
USB può collegare periferiche quali mouse, tastiere, scanner macchine fotografiche digitali,
stampanti, casse acustiche, microfoni e altro ancora. Per i componenti multimediali oramai lo
standard USB è il metodo di collegamento più utilizzato mentre nelle stampanti sopravvivono
ancora molti modelli dotati anche di porta parallela per questioni di compatibilità.
Lo standard USB 1.0 supporta collegamenti a solo 1.5 Mbit/s, velocità adeguata per mouse,
tastiere e dispostivi lenti. La versione 1.1 aggiunge la modalità full speed che innalza la
velocità a 12 Mbit/s. Occorre però tener presente che la banda disponibile è sempre suddivisa
fra le periferiche connesse. Altro aspetto rilevante è che la priorità dipende dalla posizione
(il livello nella catena) del dispositivo.
All'interno del computer, il USB non ha rimpiazzato lo standard ATA (ovvero AT Attachment, è
un bus a 16 bit, nato originariamente per il collegamento di dischi fissi.) o SCSI per via della
sua lentezza. Il nuovo standard serial ATA per esempio consente trasferimenti dell'ordine di
1.2 Gbit/s, una velocità molto più elevata dello standard USB. L'USB viene molto usato negli
hard disk esterni dove si preferisce privilegiare la praticità di poter collegare e scollegare a
caldo il componente rispetto alla velocità di una connessione tipo ATA.
La maggior novità dello standard USB versione 2.0 è l'innalzamento della velocità di
trasferimento che arriva anche a 480 Mbit/s. Questa velocità cosi elevata consente all'USB
di competere con lo standard Firewire, un ulteriore tipo di bus seriale. I punti in comune tra le
due tecnologie sono molteplici. Entrambi supportano il plug and play. Una periferica Firewire o
USB collegata al PC verrà riconosciuta automaticamente e a installare i driver provvederà il
sistema operativo, l'unico intervento richiesto è di fornire il driver e specificarne la
posizione. Sono interfacce hot swap. Infine, entrambi supportano la modalità isocrona, uno
schema di trasmissione che assegna al dispositivo che sta trasmettendo una parte prestabilita
della banda a disposizione e la massima priorità.
Il forum che sovrintende allo sviluppo dello standard USB ha rinominato USB 1.1 come USB
2.0 Full Speed e USB 2.0 come USB 2.0 High Speed.
Un sistema USB si costituisce a partire da tre elementi (fig. 12.11):
• l’host, un PC equipaggiato con il controllore e il software USB; e’ solo grazie al
software USB che i programmi applicativi hanno accesso alle periferiche connesse:
questo può essere visto come uno strato che si interpone tra il controllore del bus e i
programmi applicativi e che detiene il controllo assoluto di ogni tipo di informazione
scambiata fra le applicazioni e le periferiche connesse al bus;
• i dispositivi USB compatibili (periferiche e hub);
• i cavi di interconnessione.
12.13
Host Usb
PC
HUB
HUB
HUB
scanner
mouse
Periferiche
webcam
modem
tastiera
HUB
HD esterno
fotocamera
Figura 12.11. Esempio di rete USB ad albero.
12.3.1 Organizzazione
I tre livelli che costituiscono il protocollo USB sono:
1. Livello di interfaccia al bus,
2. Livello di periferica logica,
3. Livello funzionale.
HOST
PERIFERICA
Livello
funzionale
Applicazione
Funzione
Livello
periferica
logica
Software Usb
di sistema
Livello
interfaccia
al BUS
Flusso Logico
Periferica
Logica USB
Controllore
USB
Interfaccia al
UBS USB
Flusso
Fisico
Figura 12.12 Organizzazione dei flussi dati.
Dal lato Host il controllore USB converte i segnali logici in segnali elettrici, da inviare sul
cavo. Il software USB di sistema è responsabile di tutto ciò che ha a che fare con
l’operatività del bus: la gestione della banda disponibile, l’alimentazione del bus, il
riconoscimento della connessione e della disconnessione. E’ costituito dal driver (che fornisce
una rappresentazione logica della periferica all’applicazione) e da una parte di controllo. Il
software utilizzatore comunica con uno dei due driver al livello inferiore tramite pacchetti.
Lo scambio di informazioni sul bus USB si basa su terminatori e canali. Tutti i dispositivi USB
devono necessariamente presentare lo speciale terminatore 0 (end-pointer 0). A esso sono
associate le informazioni richieste dall’host nella fase di riconoscimento e configurazione
12.14
della periferica. Tali informazioni sono costituite da parti regolamentate dallo standard (ad
es. tipo di dispositivo, consumo di potenza) e da parti a disposizione del costruttore. Il
terminatore 0 è a capo dei flussi della cosiddetta default control line, il canale che si instaura
all’atto del riconoscimento della presenza della periferica da parte del software USB. Questo
canale si instaura logicamente al livello periferica logica. Attraverso il terminatore 0 il
software USB è in grado di configurare la periferica.
12.3.2
Il cavo
Il cavo USB è costituito da quattro fili:
- D+ e D- utilizzati per il trasferimento dati,
- VSS e VBUS trasportano una piccola quantità di potenza (Max 0.5W).
Doppino non intrecciato d’alimentazione
Rivestimento esterno in PVC
Schermatura esterna a treccia di rame
D+
VBUS
VSS
Schermatura interna in poliestere e alluminio
D-
Doppino intrecciato dedicato ai segnali dati
Figura 12.13. Sezione del cavo USB.
La linea D+ è tenuta dall’host ad una tensione positiva e la linea D- è tenuta a massa. La
trasmissione dei dati avviene per variazioni di ΔV= (D+) - (D-) su quattro livelli (anziché su due
come altri standard prevedono). Le linee di alimentazione VSS e VBUS oltre a fornire una piccola
quantità di potenza per i dispositivi a basso consumo hanno un ruolo fondamentale nella fase di
connessione/disconnessone delle periferiche.
Z0= 90 ohm± 15%
VBUS
VBUS
RPU
D+
D+
RPD
D-
ZPD= 15 Kohm ± 5%
ZPU= 1,5 Kohm ± 5%
VSS= 0V
cavo USB
VSS
VSS
RPD
D-
Host
Figura 12.14. Struttura di una periferica veloce.
12.15
VBUS= 5V
VBUS
D+
RPD
D-
D+
cavo USB
VSS
VSS
RPD
DRPU
VBUS
Host
Periferica
Figura 12.15. Struttura di una periferica lenta.
Connessione di una periferica
Appena il cavo USB viene collegato al dispositivo (t0), la tensione di alimentazione trasportata
dal cavo si applica alla resistenza di pull-up Rpu. Si forma così un partitore resistivo fra VSS e
VBUS sulla linea D (D+ se il dispositivo è lento, D- se è veloce) che determina una caduta di
tensione del 10% su D in ingresso alla porta dell’Host. Questa caduta di potenziale è
sufficiente ad alzare il valore della tensione sul cavo ad un livello superiore della soglia VIH
(t1). Nella figura 12.16 si vede cosa accade nel tempo alla tensione di D+ durante la fase di
connessione.
VIH
t0
t1
t
TDCNN
Figura 12.16. Connessione di una periferica USB.
.Se questa condizione permane per un tempo TDCNN>2.5μs viene interpretata dall’hub come
avvenuta connessione di un dispositivo (t2). A questo punto inizia la fase di configurazione
della periferica da parte del software USB.
Disconnessione di una periferica
Durante il normale funzionamento una delle due linee D è sempre sopra ad una tensione di
soglia (VIHZ), mentre l’altra è prossima alla tensione di riferimento (VSS). Al momento della
disconnessione (t0) la resistenza di pull-down abbassa la tensione della linea da livello alto
sotto la soglia VIL (t1) e se vi permane per un periodo di tempo TDCNN>2.5μs l’host disabilita la
porta (t2). L’andamento temporale della tensione ai capi di una delle due linee D è illustrato in
figura 12.17.
12.16
VIHZ(min)
t1
VIL
t2
t0
t
TDDIS
Figura 12.17. Disconnessione di una periferica USB.
12.3.3 Configurazione delle periferiche
Il bus USB è in esclusivo controllo dall’host che, anche nella situazioni di riposo, lo mantiene
attivo trasmettendo un apposito segnale a intervalli regolari di 1 ms.
Successivamente al collegamento di una periferica e il relativo riconoscimento da parte
dell’hub, inizia la fase detta “enumerazione del bus”, che permette all’host di identificare il
dispositivo e di configurarlo. Questo processo si può schematizzare in quattro fasi:
1) l’hub informa l’host che c’è stata una variazione del suo stato;
2) il software USB riceve dall’hub l’identificativo della porta a cui è connessa la nuova
periferica;
3) l’host invia alla porta dell’hub identificata in precedenza un comando per la sua
abilitazione (la periferica può ora dialogare con l’host sul canale di base attraverso il
terminatore 0);
4) l’host assegna alla periferica un indirizzo univoco mentre il software USB determina la
frazione delle risorse da allocare alla periferica (in base alle informazioni ricevute sul
canale di base al passo precedente).
12.3.4 Formato dei pacchetti
Ogni pacchetto è diviso in campi di 8 bit (o multipli), inviati sul bus dal meno significativo al
più significativo. Tutti i pacchetti iniziano con un campo di sincronizzazione, del quale fa parte
il SOP (start of packet) che marca l’effettivo inizio del pacchetto. Successivamente al SOP
viene trasmesso un campo di 8 bit contenente il PID, ossia l’identificativo del tipo di
pacchetto (Tabella 12.1).
12.17
Tabella 12.1 Tipi di pacchetto previsti dal protocolla USB.
Tipo
Nome
bit [3:0] Descrizione
di PID
Token
OUT
0001B
IN
1001B
Indirizzo e numero di endpoint in una transazione host → funzione
Indirizzo e numero di endpoint in una transazione funzione → host
SOF
0101B
Indicatore di inizio frame e numero del frame
SETUP
1101B
Indirizzo e numero di endpoint in una transazione host → funzione per il
setup di un control pipe
Data
Handshake
Speciale
DATA0
0011B
Pacchetto data PID pari
DATA1
1011B
Pacchetto data PID dispari
ACK
0010B
Il ricevente ha accettato i pacchetti dati senza errori
NAK
1010B
Il ricevente non accetta i pacchetti dati
STALL
1110B
L'endpoint è bloccato o non è esaudibile una richiesta di control pipe
PRE
1100B
Preambolo della sessione host. Abilita il traffico sui bus in uscita verso le
periferiche lente.
•
Formato dei pacchetti di tipo ‘Token’:
PID
ADDR
8 bit
7 bit
ENDP
4 bit
CRC5
5 bit
Dove ADDR è l’indirizzo assegnato alla periferica, ENDP identifica il terminatore della
periferica indirizzata e CRC è il Cyclic Redundancy Check
•
•
Formato dei pacchetti di tipo ‘Data’:
PID
DATA
CRC16
8 bit
Max 1024 byte
16 bit
I pacchetti di tipo handshake sono costituiti solo dal campo PID e vengono utilizzati
come controllo per lo stato di una transizione.
12.4 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] G. Bucci, "Architettura dei Calcolatori Elettronici", McGraw-Hill, 2001, ISBN 88-386-0889-X.
[3] Sito web: http://www.usb.org.
[4] Sito web: http://pinouts.ru/data/PCI_pinout.shtml
12.18
LEZIONE 13
Tecniche di pilotaggio dei dispositivi I/O
13.1 GESTIONE DELL’I/O (CARATTERISTICHE GENERALI)
Le unità di I/O (o unità periferiche o semplicemente “periferiche”) consentono di collegare il
calcolatore con il mondo esterno (persone, dispositivi). L’immagine (Figura 13.1) riprende lo
schema di principio dei collegamenti tra le componenti di un calcolatore immaginando di avere
un bus come supporto fisico delle interconnessioni.
CPU
I/O
MEMORIA
Figura 13.1. Collegamento fra le componenti di un calcolatore.
Esistono numerosi tipi di unità di I/O con caratteristiche molto varie:
- trasferiscono differenti quantità di dati;
- funzionano a velocità diverse;
- hanno un formato dei dati, in genere, differente da quello utilizzato nell’unità centrale.
La tabella che segue riporta alcuni dei tipi oggi più comuni e fissa l’attenzione su di un
parametro importante: la velocità di trasferimento delle informazioni, espressa in byte/s.
Tabella 13.1. Velocità di trasferimento dei più diffusi dispositivi.
Vel. Trasferimento (MB/s)
Dispositivo
Tastiera
0.00001
Mouse
0.0001
Modem 56k
0.007
Canale telefonico
0.008
Doppia Linea ISDN
0.016
Stampante Laser
0.1
Scanner
0.4
Ethernet classica
1.25
USB (Universal Serial Bus)
1.5
Cinepresa Digitale
4
Disco IDE
5
6
CD-ROM 40x
Fast Ethernet
12.5
Bus ISA
16.7
Firewire (IEEE 1394)
50
Monitor XGA
60
Rete SONET OC-12
78
Disco SCSI Ultra2
80
Gigabit Ethernet
125
Bus PCI 32-bit/33MHz
133
Nastro Ultrium
320
533
Bus PCI-X
Sun Gigaplane XB backplane
13.1
20000
È bene rivelare che alcuni dispositivi sono in grado di compiere o solo operazioni di input o solo
operazioni di output mentre altri sia le une che le altre. Inoltre le velocità di trasferimento
sono molto inferiori a quelle possibili all’interno delle altre componenti (unità centrale,
memoria) e quindi le unità di I/O devono fronteggiare il problema della conversione tra la
rappresentazione interna ed esterna dell’informazione (operazioni di codifica e decodifica).
13.1.1
Architettura del sistema di I/O
I dispositivi di I/O sono costituiti da:
- un componente sensore (input) e/o un attuatore (output);
- componenti software;
- componenti elettronici (controller).
Per indirizzare le unità di I/O, l’unità centrale ricorre ad una delle tre seguenti tecniche:
a) Riservare all’unità di I/O uno spazio di indirizzamento indipendente: l’unità centrale
utilizza specifiche istruzioni nelle quali fornisce anche l’indirizzo identificativo del
dispositivo da utilizzare nell’operazione.
b) Riservare una porzione dello spazio di indirizzamento in memoria ai dispositivi di I/O,
in modo che ogni volta che l’unità centrale utilizza un indirizzo di questa porzione in
realtà indirizzi un dispositivo di I/O.
c) Soluzione ibrida.
0xFFFF
…
0
Memoria
(a)
Porte di I/O
Memoria
Memoria
(b)
Porte di I/O
(c)
Figura 13.2. Tecniche di indirizzamento di dispositivi I/O.
Se si usano le tecniche (a) e (c) per scambiare dati tra processore e memoria si rendono
necessarie:
- istruzioni speciali di I/O, che specificano il numero del dispositivo;
- il comando da dare al dispositivo.
Il primo può essere trasmesso come un indirizzo sul bus di I/O, il secondo come un dato sul
bus di I/O. Se si utilizza il metodo 2 non è necessario introdurre nuove istruzioni per
comunicare con l’I/O. È sufficiente riservare alcuni indirizzi di memoria e letture e scritture
a tali indirizzi sono interpretati dalle periferiche come comandi.
Per interagire con i dati provenienti da un dispositivo I/O è possibile procedere in tre modi
diversi:
13.2
-
polling;
interrupt;
DMA (Direct Memory Access).
13.2 POLLING
Il primo metodo non richiede hardware aggiuntivo: si chiama polling o interrogazione ciclica
dei sensori.
CPU
Dato
pronto?
no
si
Memoria
IOC
Disp.
Leggi dato
da DR
LEGENDA:
IOC = I/O Controller
DR = Data Register
MEM = Memoria Ram
DISP = Dispositivo
Scrivi dato
in MEM
fatto?
no
si
(b)
(a)
Figura 13.3. (a) Configurazione del bus con IOC. (b) Diagramma di flusso del polling.
La CPU richiede un’operazione di I/O. Il controller di I/O effettua l’operazione, attiva un bit
nello “status register” ma non informa né interrompe la CPU.
Come si vede dal diagramma di flusso sopra disegnato (Figura 13.3 (b)), in momenti opportuni
del programma, ed in modo sincrono con esso, si interroga lo stato del registro DR ed
eventualmente si fa intervenire la routine di servizio, cioè un breve programma che esegue il
trasferimento dati da /verso la periferica. Il ritardo tra l’effettiva interrogazione del
sensore (DR) è variabile, e nel caso peggiore pari al tempo fra due interrogazioni successive.
Inoltre la CPU impiega un tempo lungo a comunicare con tutti i sensori. Qualora il sensore
richieda un tempo di risposta minore o il microprocessore non abbia tempo per interrogare i
sensori, si ricorre al metodo di interrompere il programma principale su iniziativa della
periferica.
Vantaggi:
- non è richiesto hardware aggiuntivo;
- la CPU ha il controllo totale e fa tutto il lavoro.
Svantaggi:
- la gestione del polling può consumare molto tempo della CPU;
- richiesta e verifica periodica dello stato di tutti i dispositivi, compresi quelli
che non ne hanno bisogno;
13.3
- rischio di non soddisfare esigenze di urgenza (Real-Time, per esempio nel
polling vengono visitate le periferiche in modo ciclico e quindi non si possono
gestire eventi all’atto del loro verificarsi).
Per capire come funziona il Polling, riportiamo un esempio di stampa di una stringa con l’uso di
questo metodo (Esempio 13.1):
copy_from_user(buffer, p, count);
/* p e’ un buffer nel kernel */
for (k=0; k<count; ++k) {
/* ripeti per ogni carattere */
while (*printer_status_reg != READY);
/* attendi il bit di READY */
*printer_data_register = p[k];
/* uscita di un carattere */
}
return_to_user();
Esempio 13.1. Stampa di una stringa con Polling.
13.3 INTERRUPT
CPU
3
ROM
MEM
LEGENDA:
IOC = I/O Controller
MEM = Memoria Ram
I/O = Dispositivo I/O
IOC
I/O 1
I/O 2
I/O 3
Figura 13.4. Schema del principio di funzionamento dell’interrupt.
Il meccanismo di interrupt viene utilizzato per la gestione degli apparati di I/O, per
svincolare la CPU dal fare il polling.
La CPU è collegata direttamente con il controllore di interrupt tramite il bus di sistema, e
anche attraverso 3 piedini che vengono utilizzati per gestire le interruzioni.
Il primo piedino, INTR, serve per ricevere le richieste di interruzione dai dispositivi di I/O.
Il secondo, INTA, serve invece per comunicare al controllore la disponibilità della CPU a
gestire la routine di servizio per l’interrupt richiesto precedentemente.
L’ultimo piedino, NMI, serve per gestire interruzioni “non mascherabili” ovvero che hanno la
massima urgenza e provoca un’immediata interruzione dell’attività della CPU per dedicarsi alla
gestione di tali eventi.
13.4
Tutti questi meccanismi devono richiamare l’attenzione della CPU rapidamente e poter
trasferire i dati in modo veloce e efficiente.
Esistono vari tipi di interrupt che si dividono in due categorie principali:
- interrupt esterni;
- interrupt interni.
I primi sono legati alla gestione dei dispositivi nello spazio di I/O e servono per due motivi
principali:
- la CPU deve essere libera di operare senza controllare continuamente lo stato delle
periferiche;
- garantire un accesso diretto e rapido alla CPU per richiedere l’inizio di un’operazione o
comunicarne la fine.
I secondi possono derivare da situazioni particolari della CPU e possono essere di tre tipi:
- TRAP
- ABORT
- FAULT
In generale le interruzioni interne prendono il nome di eccezioni (Vedi lezione 9).
13.3.1 Trasferimento dati a Interrupt
Vediamo ora il meccanismo di gestione di un interrupt (Vedi anche Figura 13.6).
La presenza di un interrupt viene segnalata alla CPU mediante una dei due piedini INTR o
NMI. La richiesta viene memorizzata e testata alla fine di ogni ciclo di istruzioni e viene
deciso, in base alla urgenza, se occuparsi immediatamente della richiesta o se congelarla fino
al prossimo ciclo di istruzioni. Appena possibile la CPU risponde salvando il contenuto dei
registri in memoria e richiedendo al controllore informazioni sul tipo di interruzione o
analizzando l’eccezione intervenuta. In seguito la CPU avvia una procedura legata al tipo di
interrupt pervenuto. Terminata questa routine viene ricaricato in memoria lo stato
precedente e il processore torna ad occuparsi dei programmi precedentemente in esecuzione.
L’evento che causa l’interruzione è asincrono rispetto l’esecuzione del programma.
Per quanto riguarda le interruzioni interne di tipo software queste possono essere individuate
tramite un numero e fanno capo a una tabella IDT (Interrupt Descriptor Table) che si crea in
memoria durante l’inizializzazione del sistema operativo e all’interno della quale si trovano i
riferimenti agli indirizzi in memoria delle routine di servizio legate al singolo interrupt.
13.5
Add
Sub
And
Or
nop
(1)
I/O
inter
rupt
User
program
(2)
Salva PC
(3) interrupt
service addr
lw
sw
:
:
Interrupt
service
routine
rfe
Figura 13.5. Trasferimendo ad Interrupt.
Per determinare il dispositivo che ha generato l’interrupt giunto esistono diversi metodi.
Uso di differenti linee per ogni controller:
- PC (Personal Computer);
- limita il numero di dispositivi, in quanto il IOC ha tipicamente un numero limitato di
linee nelle quali accetta l’interrupt.
Software Poll:
- la CPU chiede a ognuno dei controllori se ha generato l’interrupt;
- lento.
Daisy Chain (Hardware Poll):
- il sistema di Interrupt Acknowledge viene inviato in daisy-chain;
- il controller è responsabile di mettere sul bus un “vettore”;
- la CPU usa il vettore per identificare la routine di servizio.
Bus Master:
- il controller richiede il bus prima di fare interrupt;
- ex PCI, SCSI.
La gestione di interruzioni multiple avviene tramite assegnazione di una priorità a ognuno degli
interrupt e solo quello con maggiore urgenza giunge alla CPU.
L’ordine di priorità degli interrupt tipicamente è il seguente:
- interni (eccezioni);
- non mascherabili;
- software;
- hardware esterni.
Ad esempio fanno parte della prima categoria:
la divisione per zero, ovvero quando nell’operazione DIV il divisore è nullo e il risultato di
questa divisione non può essere trascritto su registro;
la modalità di esecuzione in Single Step Trap in cui alla fine di ogni operazione viene bloccata
l’esecuzione del programma.
13.6
Nella seconda categoria troviamo interruzioni dovute a un calo di alimentazione o a un errore
di lettura in memoria.
Nella terza tutte quelle interruzioni che vengono chiamate dal programmatore tramite la
funzione INT (tipicamente nei processori x86) seguita dal numero dell’interrupt desiderato.
Infine l’ultima tipologia fa capo alle interruzioni generate dall’utilizzo di una periferica del
computer (ex mouse, tastiera, ecc).
E’ possibile impedire le interruzioni se non sono opportune, a ogni richiesta è associata una
urgenza ma la CPU accetta solo richieste con un dato livello di priorità o più elevato.
Per comprendere meglio questo metodo, possiamo riproporre l’esempio 13.1, utilizzando questa
volta l’interrupt (Esempio 13.2):
Routine di servizio dell’interrupt
If(count==0) {
Unblock_user();
} else{*printer_data_register=p[k];
count= count-1;
k=k+1;
}
acknowledge_interrupt();
return_from_interrupt();
copy_from_user(buffer, p, count);
enable_interrupts();
while(* printer_status_reg !=READY);
*printer_data_register = p[0];
scheduler();
Esempio 13.2. Stampa di una stringa ad interrupt.
13.3.2 Esempio – Architettura dei Personal Computer
Facciamo ora un esempio di funzionamento del meccanismo di interrupt per l’architettura
8086, usata a partire dal 1981 nei Personal Computer.
CPU
8086
INTC
INTR
INTA
8259A
DATA
IRQ
IRQ
IRQ
IRQ
IRQ
IRQ
IRQ
IRQ
0
1
2
3
4
5
6
7
Figura 13.6. Interrupt Controller con un’architettura 8086.
I processori della famiglia 80x86 hanno una solo linea di interrupt e sono collegati a un
Interrupt Controller che si chiama 8259A che presenta in ingresso 8 linee di interrupt (IRQ)
a ognuna delle quali può essere collegato un dispositivo (Figura 13.6), oppure a sua volta
collegati ad altri controllori annidati (massimo 2).
L’ 8259A accetta l’interrupt da una delle linee.
L’ 8259A ne determina la priorità secondo l’ordine precedentemente descritto e avvisa l’8086
attivando la linea INTR. La CPU invia la disponibilità a trattare la richiesta tramite il piedino
INTA.
13.7
L’ 8259A mette sul bus dei dati il “vettore” cioè il numero che identifica la sorgente
dell’interrupt e quindi la CPU può servire la richiesta pervenuta eseguendo la relativa routine.
13.4 DMA ( DIRECT MEMORY ACCESS )
Un problema che si verifica frequentemente nelle tecniche dell’ interrupt e del polling per
l’accesso alla memoria è quello di una limitata velocità di trasferimento e di un utilizzo
eccessivo della CPU.
La soluzione per ovviare a questo inconveniente è l’utilizzo del DMA (Direct Memory Access).
13.4.1 Funzionamento del DMA
Il DMA agisce come un master del bus, sostituendosi alla CPU, per il trasferimento di blocchi
di dati da e verso la memoria senza l’intervento da parte della CPU stessa.
Il DMAC deve essere programmato dalla CPU, che gli indica:
• l’indirizzo iniziale della zona di memoria coinvolta;
• l’indirizzo del controller del dispositivo (IOC);
• la direzione da seguire (Read/Write);
• la quantità di dati da trasferire.
CPU
Memori
a
DMAC
LEGENDA:
IOC = I/O Controller
DMAC = DMA Controller
IO
C
Disp.
Figura 13.7. Configurazione di un bus con DMA Controller.
Il DMA Controller genera tutti i segnali necessari per indirizzare la periferica e la memoria.
In questo modo la CPU può svolgere altro lavoro mentre il DMA Controller si occupa del
trasferimento. Quando questo ha finito manda un interrupt alla CPU.
13.4.2 Trasferimento dei dati
L’unità DMA può effettuare il trasferimento dei dati in uno dei seguenti modi: modo burst e
modo cycle stealing.
- modo burst: l’unità trasferisce l’intero blocco di dati, bloccando gli accessi da parte delle
altre periferiche di I/O e della CPU per tutta la durata del trasferimento.
Questo metodo realizza la più alta velocità di trasferimento tra dispositivi di I/O e memoria,
ma può impedire alle altre unità e alla CPU di accedere alla memoria anche per tempi lunghi.
- modo cycle stealing: l’unità trasferisce i dati una word alla volta, consentendo l’accesso alle
altre unità DMA e alla CPU tra una word e l’altra. Con riferimento alla CPU, questa si vede
13.8
sottrarre di tanto in tanto dei cicli di accesso alla memoria, con conseguente rallentamento
del suo funzionamento. Il processore può comunque evitare di fare accesso alla memoria nella
maggior parte dei casi utilizzando la memoria cache. Inoltre, questa modalità riduce la
velocità di trasferimento dei dati, ma anche l’interferenza tra unità di I/O e CPU, che non
dovrà fare il salvataggio/ripristino dello stato come nel caso dell’interrupt, ma al massimo
attendere di più quando dovrà accedere al bus.
13.4.3 Configurazioni
Una delle possibili configurazioni che si possono adoperare per l’utilizzo del DMA prevede
l’uso di una singola linea di Bus e del DMA controller con accesso a un bus comune agli I/O
Device e alla CPU (paragrafo 13.5) (Figura 13.8). In questo caso, ogni trasferimento occupa il
bus due volte: la prima per il trasferimento dal dispositivo di I/O al DMA e la seconda dal
DMA alla memoria. Quindi, in questo caso la CPU troverà il bus occupato per il doppio del
tempo per ogni trasferimento.
CPU
DMA
Controller
I/O
Device
I/O
Device
Main
Memory
Figura 13.8. Configurazione con DMAC separato dagli I/O device e dalla Cpu con accesso a bus comune.
Una seconda configurazione prevede sempre l’utilizzo di una sola linea di bus, ma con il DMA
controller integrato nei dispositivi di I/O (Figura 13.9). Con questa configurazione il
controller può gestire più di un dispositivo per volta e, inoltre, ogni trasferimento occupa il
bus una sola volta: per trasferire i dati dal DMA alla memoria. Questo porta a dimezzare le
volte in cui la CPU trova il bus occupato.
CPU
DMA
Controller
DMA
Controller
Main
Memory
I/O Device
I/O
Device
I/O
Device
Figura 13.9. Configurazione a singola linea di bus con il DMAC integrato negli I/O device.
Una terza possibile configurazione del DMA usa una linea di bus separata per i dispositivi di
I/O (Figura 13.10). Così facendo il DMA controller avrà a disposizione un bus dedicato che
supporta tutti i dispositivi abilitati al DMA. Come la seconda configurazione, anche questa
utilizza il bus ”principale” una sola volta per ogni trasferimento e inoltre dimezza le volte in
cui la CPU trova occupato il bus, rispetto al primo caso.
13.9
CPU
DMA
Controlle
r
I/O
Device
I/O
Device
I/O
Device
Main
Memory
I/O
Device
Figura 13.10. Configurazione con una linea di bus separata per gli I/O device.
13.4.4 I/O Processor
Per evitare ulteriormente di fare riferimento al processore per la gestione dei trasferimenti
di dati, il controllore DMA può essere un po’ più “autonomo” attraverso l’uso di dispositivi
chiamati Processori di I/O (IOP), che gestiscono al loro interno, attraverso un programma
implementato in hardware o salvato in memoria, alcune operazioni di I/O che definiscono
dimensione e indirizzo del trasferimento per le operazioni di lettura e scrittura. In questo
modo l’ IOP interrompe la CPU solo quando è effettivamente pronto per il trasferimento
(Figura 13.11).
13.10
CPU
Mem
IOP
D1
memory
D2
bus
. . .
I trasferimenti da/verso
la memoria sono controllati
direttamente dall’IOP
IOP effettua cycle stealing
Dn
I/O
bus
(a)
(1)
LA CPU
da’ una
istruzione
a IOP
CPU
IOP
(4) IOP
interrompe
la CPU quando
ha finito
(2)
(3)
memoria
(b)
dispositivo target
OP
dove sono i comandi
Device
Address
IOP trova il comando in memoria:
OP
cosa
fare
LEGENDA:
IOP = I/O Processor
MEM = Memoria Principale
D1,D2,…,Dn = Dispositivi I/O
DMAC = DMA Controller
Addr
dove
mettere
i dati
Cnt
Other
quanti
dati
richieste
speciali
(c)
Figura 13.11. (a) Configurazione dell’ IOP. (b) e (c) Funzionamento dell’ IOP
13.11
13.5 TIPI DI CONTROLLER DMA
Il DMA controller è la vera e propria periferica dedicata al trasferimento dei dati tra
memoria e I/O Device o tra due aree di memoria, ed è capace di controllare il bus. In pratica
agisce come una implementazione hardware della routine di gestione dell’ interrupt di bufferpieno o buffer-vuoto. Si posso individuare tre tipi principali di controllers DMA:
- 1D : con un singolo registro per gli indirizzi;
- 2D : con due registri per l’indirizzamento;
- 3D : con tre o più registri per l’indirizzamento.
13.5.1 Struttura di un DMA generico
Un DMA Generico è costituito da varie parti, ognuna specializzata a svolgere un compito
preciso:
• Address Generator :
Genera gli indirizzi di memoria o di periferica coinvolti nei trasferimenti. Generalmente
è costituito da un registro base e un contatore auto-incrementante.
• Address Bus :
Qui finiscono gli indirizzi generati per accedere ad una specifica locazione di memoria
o della periferica.
• Data Bus :
Viene utilizzato per trasferire dati dal DMA alla destinazione. Molto spesso, però, il
trasferimento avviene direttamente dalla sorgente alla destinazione, con il controller
DMA che seleziona solamente i due dispositivi.
• Bus Requester :
Questo dispositivo è utilizzato per richiedere l’utilizzo del bus alla CPU, cosa che si
rende necessaria quando si usa per la prima volta il DMAC.
• Local Peripheral Control :
Questo elemento permette al controller DMA di selezionare la periferica coinvolta nel
trasferimento di dati e di gestirla nel modo appropriato. Il Local Peripheral Control è
fondamentale per l’indirizzamento singolo o implicito.
• Interrupt signals :
Attraverso gli interrupt signals il controller DMA può interrompere la CPU appena il
trasferimento tra due periferiche è terminato o si è verificato un errore.
Il funzionamento di un controller DMA in generale si può dividere in due fasi: la fase di
programmazione e la fase di effettivo trasferimento. Queste due fasi non possono avvenire,
per ovvie ragioni, simultaneamente, nel senso che se si sta effettuando un trasferimento, non
è possibile programmare il controllore.
Riportiamo adesso l’esempio di stampa di una stringa, utilizzando questa volta il DMA (vedi
esempi 13.1 e 13.2):
13.12
copy_from_user(buffer, p, count);
setup_DMA_controller();
scheduler();
acknowledge_interrupt();
unblock_user();
return_from_interrupt();
Esempio 13.3a. Codice di preparazione alla stampa
Esempio 13.3b. Routine di servizio dell’interrupt
Esempio 13.3. Stampa di una stringa con DMA.
Nella fase di programmazione il controller viene visto come un normale dispositivo di I/O
dotato di registri, nei quali vengono definiti gli indirizzi base, la dimensione del trasferimento
da effettuare e le comunicazioni con il processore (ad esempio sulle condizioni su cui si
generano gli interrupt). In questa fase, il controller si comporta da slave e le operazioni da
eseguire vengono impartite dalla CPU (Figura 13.12, punto 1). Inoltre il DMA controller deve
anche comunicare con le periferiche coinvolte nel trasferimento dei dati, ad esempio, per
assegnare ad ognuna una linea di richiesta di DMA e decidere la politica di arbitraggio per le
richieste simultanee al DMA. La definizione del tipo di trasferimento dei dati da fare (per
esempio all-at-once, individuale od altro) chiude questa prima fase (Figura 13.12, punto 2).
Figura 13.12. Un esempio di trasferimento dati attraverso il DMAC.
Dopo aver definito tutti questi parametri si passa alla fase di trasferimento vero e proprio,
nella quale, dopo aver supposto che il controller DMA sia stato configurato correttamente,
inizia il trasferimento dei dati:
• direttamente verso il DMAC: in questo caso il DMAC avrà almeno un registro dati
(data register) dove registrare i dati;
• attraverso il processore (attivato su interrupt);
• utilizzando periferiche in grado di trasferire direttamente il dato verso la MEM.
A questo punto avviene la richiesta del bus da parte del DMAC alla CPU, che ne consente
l’utilizzo. Il processore, in generale, privilegia le richieste che provengono dall’esterno per
l’utilizzo del bus, rispetto alle necessità che possono essere proprie e che provengono
dell’interno: tutto questo fa sì che si evitino perdite di dati quando queste richieste
provengono proprio da un controllore DMA che deve effettuare trasferimenti di I/O ad alte
13.13
velocità. Nei processori che non supportano la gestione delle richieste del bus, il DMAC può
funzionare in “bus-stealing”, cioè il processore resta bloccato, per un breve periodo, su un
accesso al bus mentre il DMAC opera un trasferimento.
La maggior parte dei più recenti DMAC comunque sono progettati in modo da poter funzionare
con diverse famiglie di processori.
A questo punto il trasferimento dei dati può avvenire o attraverso un buffer interno al
controller o direttamente dalla periferica alla memoria come gia detto (Figura 13.12, punto 3).
Una volta terminato il trasferimento, viene calcolato il nuovo indirizzo per un successivo
trasferimento e viene quindi aggiornato il contatore dei trasferimenti.
Appena il DMAC termina di trasferire un blocco, oppure si accorge di un errore nel
trasferimento dei dati, invia alla CPU un’interrupt (Figura 13.12, punto 4).
13.5.2 Modelli del DMAC
Il funzionamento del controller varia in base a due caratteristiche:
- trasferimento dei dati, che può essere singolo o doppio;
- indirizzamento, che può essere singolo o complesso.
Con il trasferimento di dati singolo il DMA utilizza l’address bus per indirizzare la locazione
coinvolta nel ciclo di bus verso la memoria (Figura 13.13(1)). Esso utilizza il segnale di
selezione della periferica (Chip Select, C/S) per selezionare la periferica e rendere
disponibile il suo bus dati; in conseguenza dell’attivazione del Chip Select può essere
necessario un encoder per selezionare un dato indirizzo (implicito) della periferica (A0, A1,
A2 in Figura 13.13(2)). Se è proprio la periferica scelta ad iniziare, il controller attiva la linea
di request.
C/S
Periferica
Periferica
A0 A1 A2
R/W
Peripheral bus
Controller DMA
Data
bus
Address
bus
Encoder
Peripheral Select dal
controller
DMA
MEMORIA
Read/Write
dal controller
DMA
Peripheral bus
(1)
(2)
Figura 13.13. (1) Struttura di un trasferimento dati singolo (2) Selezione Periferica.
Il trasferimento di dati doppio si basa sull’utilizzo di due indirizzi e due accessi per
trasferire i dati dalla periferica ( o dalla memoria) a un’altra locazione di memoria (Figura
13.14).
Esso consuma due cicli di bus e utilizza un buffer temporaneo interno al controller.
13.14
Periferica
Controller DMA
Data bus
Address
bus
MEMORIA
Figura 13.14. Struttura di un trasferimento dati doppio
Un caso particolare è l’ 1D Model, che utilizza un indirizzo base ed un contatore per definire
la sequenza di indirizzi da usare nei cicli DMA.
Esso presenta uno svantaggio: una volta che il blocco di dati è stato trasmesso, l’indirizzo e il
contatore sono resettati potendo sovrascrivere accidentalmente dati precedenti; diventa
allora necessario un’ interrupt dal DMA alla CPU ogni volta che il contatore termina il
conteggio per cambiare l’indirizzo base.
E’ comunque vantaggioso in quanto si può implementare un buffer circolare con wrap around
automatico (Figura 13.15).
Locazione iniziale di
memoria
Reset
Locazione finale
di memoria
Figura 13.15. Buffer circolare con wrap around automatico
Altro modello è il 2D Model, che viene ad esempio utilizzato per l’implementazione di
protocolli di comunicazione basati sullo scambio di pacchetti, dove si devono spezzare grosse
quantità di dati in pacchetti e aggiungere gli header. Invece di riportare l’indirizzo in base al
valore originale, viene sommato un valore di “stride” alla fine di un trasferimento di un blocco
(Figura 13.16).
Questo metodo permette al DMA di utilizzare blocchi di memoria non contigui.
Il registro contatore è diviso in due parti distinte:
- un registro per l’offset all’interno del blocco;
- un registro per contare il numero totale di blocchi di byte trasferiti.
Con il modello 2D si possono facilmente spezzare i blocchi in pacchetti pronti per
l’inserimento degli header. Successivamente può essere usato un modello 1D per inviare i dati
alla scheda di rete.
13.15
Base Address
Incremento tramite contatore
Reset Counter &
change base address
Stride
Figura 13.16. Blocchi del modello 2D.
Infine abbiamo il 3D Model, che utilizza un meccanismo a “stride” come nel modello 2D.
Inoltre in esso può essere cambiato automaticamente lo stride per creare blocchi a indirizzi
variabili. Un modello 3D può essere semplicemente simulato con un modello 2D, al quale viene
applicato un software che programma ogni volta il DMAC per cambiare lo stride.
13.5.2 Canali DMA (Blocchi di controllo)
I 3 tipi di Controllers visionati sopra presentano però molti problemi, che portano ad avere un
notevole carico di lavoro sulla CPU per la programmazione e la gestione degli input:
- ogni DMA deve essere pre-programmata con un blocco di parametri per poter
funzionare correttamente;
- ogni periferica che necessita di un trasferimento deve chiedere alla CPU di
programmare correttamente il DMA (interrupt);
-
spesso una certa periferica programma il DMAC con lo stesso set di parametri.
Questo metodo è molto utile in quanto permette di ridurre l’overhead del processo. Ad ogni
periferica viene assegnata una linea esterna di request (canale DMA) per la quale vengono
programmati una sola volta i parametri per il corrispondente tipo di trasferimento (blocchi di
controllo) (Figura 13.17). Quando una periferica richiede un trasferimento, asserisce il suo
canale DMA e inizia il trasferimento in accordo con i parametri assegnati al canale stesso. Con
questo metodo è possibile anche condividere un singolo controller con più periferiche senza
eccessivo overhead per il processore. Il numero di canali DMA presenti in un Personal
Computer è almeno di 4.
13.16
Trasferimenti operati
con richieste sul
Canale DMA 1
Trasferimenti operati
con richieste sul
Canale DMA 2
Figura 13.17. Uso dei canali DMA.
Da un’estensione della struttura dei canali DMA deriva la concatenazione (chaining). Qui i
canali sono collegati a catena in modo da generare pattern più complessi e una volta terminato
il lavoro di un canale, il controllo passa a quello successivo concatenato. Questo metodo
garantisce la possibilità di utilizzare anche schemi molto complessi di indirizzamento.
13.5.3 Concorrenza di accesso ai canali DMA
Un problema che si può verificare nel DMAC è quello di ricevere richieste multiple di
trasferimento. Da qui nasce la necessità di un arbitraggio. Esso può essere effettuato per
esempio tramite la scelta dei canali con una priorità maggiore o tramite il servizio dei canali
attraverso la politica Rund-Robin (a rotazione), dove viene creata una coda di processi in
attesa che, una volta collegatisi alla CPU per un ciclo, vengono spostati in fondo alla lista in
attesa del nuovo collegamento.
Il DMAC compete con la CPU per quanto riguarda l’utilizzo del bus. Una CPU senza cache (per
esempio la 80286 o la MC68000) utilizza dall’80% al 95% della larghezza di banda del bus e la
condivisione di esso con la DMA porta gravi ritardi come aumenti di tempo di latenza degli
interrupt e lentezza nelle prestazioni. Per quanto riguarda i dispositivi con cache, in essi
l’interferenza del DMA sulle prestazioni è molto minore.
Per consentire il giusto compromesso, molti DMA utilizzano differenti tipi di accesso al bus.
Possiamo avere così tre modelli:
- Trasferimento singolo: con esso, il collegamento del bus ritorna alla CPU alla fine di ogni
singolo trasferimento. Un difetto deriva però dal tempo impiegato per la negoziazione del bus
e per iniziare e chiudere le transizioni di DMA.
- Trasferimento a blocchi (modo cycle stealing): qui il bus è restituito alla CPU dopo il
trasferimento di un blocco (che può essere anche molto lungo). Con questo metodo il DMAC
usa efficacemente il bus.
- Trasferimento su domanda(modo burst): qui il bus viene trattenuto dal DMA per tutto il
tempo che la periferica richiede (in teoria anche per un tempo lunghissimo!). Il DMAC può
usare il bus in maniera non ottimale, lasciando ad esempio dei “buchi”; se però ciò non avviene,
molto spesso questo tipo di trasferimento è migliore di quello a blocchi.
13.5.4 INTEL 8237
E’ il più comune modello di controller DMA attualmente in uso su tutti i PC IBM compatibili.
Esso utilizza 4 canali, ognuno dei quali può effettuare operazioni di trasferimento per un
13.17
massimo di 64K caratteri e può essere programmato in modo da autoreinizializzarsi al termine
di un trasferimento.
Nell’ultimo periodo esso viene direttamente integrato sul chipset della scheda madre.
Supporta 4 differenti modalità di trasferimento:
- trasferimento singolo;
- trasferimento a blocchi;
- trasferimento a domanda;
- trasferimento a cascata, in cui abbiamo più controllers DMA collegati in cascata, che
garantiscono più canali DMA.
Trasferimento di dati: viene garantito un trasferimento da periferica a memoria e quello da
memoria a memoria, che avviene unendo due canali fra loro (solitamente non in uso nei PC).
Verify Transfer Mode: questo è una speciale modalità di trasferimento dei dati. Esso viene
usato nei PC per generare indirizzi dummy per il refresh della memoria DRAM e viene guidato
da un interrupt ogni 15μs, derivato da un canale del timer 8253.
Gestione interna della concorrenza: per gestire tutte le possibili concorrenze interne
vengono utilizzati due differenti metodi:
- schema a priorità fissa;
- schema a priorità variabile;
13.5.5 MOTOROLA MC68300
Questo tipo di tecnologia si basa su processori Motorola MC68000 e MC68020 con controller
DMA integrato sul chip stesso.
La loro architettura è caratterizzata da due canali DMA completamente programmabili e da
una velocità di trasferimento dati che varia da 12.5 Mbytes/s in dual address mode a 25 MHz
a 50.0 Mbytes/s in single address mode a 25 MHz.
Grazie al fatto di trovarsi integrato sulla CPU, esso può gestire trasferimenti fra memorie (o
periferiche) interne ed esterne. Per quanto riguarda i trasferimenti interni è possibile
specificare la quantità di banda da occupare (25, 50, 75 o 100%); per i cicli esterni ho due
differenti modalità di trasferimento: la burst (modo di trasferimento continuo) e la single.
I registri sorgente e di destinazione possono essere programmati indipendentemente per
rimanere costanti o per essere incrementati.
13.5.6 USO DELLA CPU SEPARATA CON FIRMWARE
Una CPU di questo tipo può essere utilizzata quando non è disponibile un DMAC. Essa richiede
una propria memoria e un programma che la faccia funzionare senza creare occupazioni del
bus della memoria nel momento in cui deve essere programmata.
La CPU stabilisce come deve essere effettuato ogni trasferimento DMA.
Un notevole vantaggio che deriva dall’utilizzo di questa tecnica è che la CPU può essere
programmata con software di alto livello.
Molti dei processori usati nei sistemi embedded ricadono in questa categoria.
RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Sito web: http://www.ing.unisi.it/control
13.18
LEZIONE 14
Esempi di dispositivi di I/O: il timer e la porta seriale
14.1 TIMER INTEL 8254
Il Timer Intel-8254 è un generatore di ritardi, programmabili in maniera accurata; esso
implementa diverse funzioni:
- conteggio degli eventi;
- real time clock;
- generatore di frequenza programmabile;
- generatore di onda quadra programmabile;
- generatore di impulso rettangolare;
- moltiplicatore binario di sequenza;
- generatore di forma d’onda complessa;
- controllo di motori.
E’ costituito da tre contatori indipendenti a 16 bit, ognuno capace di generare segnali a
frequenza massima di 10 MHz . La figura 1.1 rappresenta il diagramma a blocchi del timer
8254 nella figura 14.2 si riassumono i segnali elettrici di ingresso e uscita del chip.
Fig 14.1 Diagramma a blocchi.
2
8
D7-D0
CLK2
GATE2
OUT2
/RD
CLK1
GATE1
OUT1
A1-A0
A1-A0: indirizzamento
D7-D0: scambio dati su
8 bit
/RD, /WR, /CS: Read,
Write, Chip-Select
Vcc-GND: alimentazione
CLKj: clock del timer j
GATEj: trigger
hardware o
congelamento conteggio
OUTj: forma d’onda
prodotta dal timer j
/WR
/CS
2
Vcc-GND
CLK0
GATE0
OUT0
Fig 14.2 i segnali elettrici di ingresso e uscita del chip.
14.1
Analizziamo il diagramma a blocchi (fig. 14.1):
il data bus buffer (8 bit) è utilizzato per interfacciare l’8254 con il bus di sistema; la
logica di scrittura e lettura (/RD,/WR) accetta ingressi dal bus di sistema e genera segnali di
controllo per gli altri blocchi funzionali. Un /RD basso (low) significa che la CPU sta leggendo
uno dei registri; un /WR basso indica che la CPU sta scrivendo. Il segnale /CS abilita sia /WR
che /RD, altrimenti vengono ignorati. A1 e A0 sono i segnali di indirizzamento che selezionano
uno dei tre contatori interni o il Control Word Register.
I bit A1 e A0 indirizzano 4 registri. Con A1,A0=00,01,10 si indirizzano rispettivamente CR0,
CR1, CR2 (vedi fig 14.3).
Il Control Word Register (CWR) è selezionato quando A1,A0=11. Il CWR può essere solo
scritto; si accede alle informazioni in esso contenute con il comando read back (paragrafo
14.4); inoltre il CWR determina il modo di operare del contatore, un contatore esegue delle
operazioni solo se viene programmato, quindi prima di essere utilizzato bisogna programmarlo.
A1-A0 /RD /WB
00
1
0
CR0
01
1
0
CR1
10
1
0
CR2
Counter Register 0
Scrivendo in questo registro fisso la Time Constant 0
Counter Register 1
Scrivendo in questo registro fisso la Time Constant 1
Counter Register 2
Scrivendo in questo registro fisso la Time Constant 0
11
1
0
Control Word Register
Scrivendo in questo registro fisso il funzionamento
di un dato contatore oppure do’ comandi particolari
CW
R
Fig 14.3 Visione logica del chip.
14.2 PROGRAMMAZIONE DEL TIMER
Per programmare il timer bisogna eseguire i seguenti passi:
- scrivere in CWR per selezionare uno dei contatori e il modo (vedi par. successivo);
- scrivere in CRj la costante di tempo (j=0,1,2);
- abilitare il conteggio con un segnale alto sul pin GATEj.
L’uscita OUT produrrà un segnale di uscita alla fine del (oppure durante il) conteggio a
seconda del modo prescelto.
14.3 MODI DI PROGRAMMAZIONE DEI CONTATORI
I contatori sono a 16 bit e supportano sei modi operativi:
- MODO 0: interrupt al termine del conteggio;
- MODO 1: programmable one shot;
- MODO 2: rate generator (divisore di frequenza);
- MODO 3: square wave rate generator (generatore d’onda quadra);
- MODO 4: software triggered strobe (generatore di impulso);
14.2
- MODO 5: hardware triggered strobe.
Analizziamo in dettaglio i sei modi operativi: (in tutti gli esempi si parte da un conteggio
iniziale pari a N).
14.3.1 Modo 0 (Interrupt al termine del conteggio)
Come mostrato in fig. 14.4, dopo che il CWR è stato scritto, l’uscita (OUT) è inizialmente
bassa e vi rimane per un ciclo di clock, dopo di che il contatore inizia il conteggio partendo dal
valore preimpostato. A questo punto, ad ogni ciclo di clock il contatore viene decrementato e
l’uscita (OUT) rimane bassa fino a quando il contatore raggiunge il valore 1, dopo di che
durante la transizione del contatore da 1 a 0 l’uscita (OUT) va a 1 e rimane in tale stato fino a
quando viene scritto un nuovo valore in CWR. In questa modalità, si genera un uscita alta dopo
N+1 cicli. GATE=1 abilita il conteggio, GATE=0 lo disabilita; il GATE non ha effetti sull’uscita.
CL
K
CWR,CRj,/WR
Counter
-
-
-
-
N
N-2
N-1
…
2
1
0
-
OUT
GATE
N+1
Fig 14.4 Rappresentazione del Modo 0.
14.3.2 Modo 1 (programmable one shot)
L’uscita è inizialmente alta e diventa bassa sull’impulso di clock che segue il trigger
(pulsazione one shot), e vi rimane fino a quando il contatore non raggiunge lo zero,
mantenendo tale stato fino alla pulsazione di clock che si verifica nel trigger successivo (fig
14.5).
14.3
CLK
CWR,CRj,/WR
Counter
-
-
N
-
…
N-2
N-1
2
1
0
-
OUT
GATE
N+1
Figura 14.5 Rappresentazione Modo 1
14.3.3 Modo 2 (divisore di frequenza)
Come mostrato in fig 14.6, l’uscita (OUT) è inizialmente alta quando il contatore arriva ad uno
l’uscita diventa bassa per un impulso di clock. Poi l’uscita diventa alta di nuovo, il contatore
ricarica il valore iniziale del conteggio e il processo si ripete. Il modo 2 è quindi periodico in
quanto la stessa sequenza è ripetuta in maniera indefinita. Il duty cycle della forma d’onda
d’uscita (OUT) è (N-1)/N. Se f e’ la frequenza del segnale di clock, la forma d’onda d’uscita
avra’ frequenza f/N.
CLK
CWR,CRj,/WR
Counter
-
-
-
N
N-1 N-2
…
2
1
N
N-1
…
2
OUT
Periodo = N
Fig 14.6 Rappresentazione Modo 2.
14.3.4 Modo 3 (generatore d’onda quadra)
L’uscita (OUT) rimane alta nei periodi N, N-1,……,(N+1)/2 e rimane bassa nei periodi N/2, (N1)/2, ….,2,1. Il duty cycle è ½ se N è pari , altrimenti vale ((N+1)/2)/N = ½+½N . In uscita (OUT)
abbiamo un’ onda quadra con un periodo di N cicli di clock. GATE = 1 abilita il conteggio, GATE
14.4
= 0 lo disabilita (fig 14.7). Se f e’ la frequenza del segnale di clock, la forma d’onda d’uscita
avra’ frequenza f/N.
CLK
CWR,CRj,/WR
Counter
-
-
-
N
N-1 N-2
…
2
1
N
…
N-1
2
1
OUT
Periodo = N
Fig 14.7 Rappresentazione Modo 3.
14.3.5 Modo 4 (Generatore d’impulso)
L’uscita (OUT) è inizialmente alta; diventa bassa per un impulso di clock e poi di nuovo alta.
GATE = 1 abilita il conteggio, GATE = 0 lo disabilita. Il GATE non ha effetto sull’uscita (fig.
14.8).
CL
K
CWR,CRj,/WR
Counte
r
-
-
-
N
N-1
…
N2
2
1
0
-
OU
T
GATE
N+
1
Fig 14.8 Rappresentazione Modo 4.
14.3.6 Modo 5 (Hardware triggered strobe)
Come si vede in fig. 14.9, l’uscita (OUT) è inizialmente alta e il conteggio inizia in
corrispondenza dell’impulso di gate. Quando il conteggio raggiunge lo zero, l’uscita (OUT)
rimane bassa per un impulso di clock e poi diventa nuovamente alta. I successivi impulsi di
GATE vengono ignorati.
14.5
CL
K
CWR,CRj,/WR
Counter
-
-
-
N
N-1
…
N-2
2
1
0
-
-
OUT
GATE
N+1
Figura 14.9 Rappresentazione Modo 5.
14.4 MODALITÀ DI LETTURA/SCRITTURA
I contatori hanno una precisione interna di 16 bit, ma il bus di accesso al chip è solo 8 bit, si
dovra’ perciò specificare se stò lavorando sul byte meno significativo (LSB) o sul byte più
significativo (MSB), oltre a questo è necessario programmare vari altri parametri (modo,
conteggio binario, BCD), ciò si effettua scrivendo alcune informazioni in CWR.
Un contatore è programmato per scrivere/leggere conteggi a 16 bit, nel seguente modo: un
programma non deve trasferire il controllo mentre sta scrivendo nel contatore ad un'altra
routine che a sua volta debba effettuarne la stessa operazione di scrittura; altrimenti il
contatore verrebbe caricato con un valore non corretto.
Se vogliamo scrivere in CWR i segnali da attivare sono:
A1-A0 =1 1, /CS =0, /RD =1, /WR = 0.
Mentre la programmazione di CWR avviene specificando i bit di tabella 14.1 secondo quanto
riportato nelle tabelle 14.2, 14.3, 14.4 e 14.5.
Tab. 14.1. Significato dei bit del registro CWR.
bit7
SC1
bit6
SC0
bit5
RW1
bit4
RW0
bit3
M2
bit2
M1
bit1
M0
bit0
BCD
I simboli presenti nella tabella 14.1 sono dettagliati nella tabella 14.2, 14.3, 14.4, 14.5.
Tab. 14.2. Selezione bit SC0, SC1 ai fini della programmazione.
SC0
0
0
1
1
SC1
0
1
0
1
Seleziona il contatore 0
Seleziona il contatore 1
Seleziona il contatore 2
Read Back Command (lo vedremo nella lettura)
14.6
Tab. 14.3 Selezione RW1 e RW2.
RW1
RW2
0
0
Counter Latch Command (lo vedremo nella lettura)
0
1
Read/Write soltanto il byte meno significativo
1
0
Read/Write soltanto il byte più significativo
1
1
Read /Write scrivi il byte meno significativo seguito da quello più significativo
Tab 14.4. Modi descritti nel paragrafo 14.3.
M2
0
0
X
X
1
1
M1
0
0
1
1
0
0
M0
0
1
0
1
0
1
Mode 0
Mode 1
Mode 2
Mode 3
Mode 4
Mode 5
Tab. 14.5. Bynary Coded Decimal.
0
1
Bynary Counter 16 – bit
Bynary Code Decimal (BCD)
Ogni tipo di programmazione (sequenza di bits) che segue la convenzione sopra è accettabile.
Ci sono tre metodi possibili per leggere i contatori: con operazioni di lettura, con il comando
Counter Latch Command oppure con il comando Read-Back Command:
- Il primo metodo consiste nell’attuare una semplice operazione di lettura del contatore
tramite gli input A1 e A0,
- Nel secondo metodo si utilizza il Counter Latch Command, che viene attivato facendo
accesso al CWR.
A1-A0=11, /CS = 0, /RD =1, /WR=0.
Quindi i bit di CWR, in questo caso i bit di CWR cambiano di significato come mostrato in
tabella 14.6.
Tab. 14.6. Inizializzazione di CWR per effettuare un Counter Latch Command.
bit7
SC1
-
bit6
SC0
bit5
0
bit4
0
bit3
-
bit2
-
bit1
-
bit0
-
Il terzo metodo, il Read Back Command, si attiva facendo ancora accesso al CWR
e si programma attivando i seguenti bits, come mostrato in tab. 14.7.
Tab. 14.7. Inizializzazione di CWR per effettuare un Read Back Command.
bit7
1
bit6
1
bit5
/COUNT
bit4
bit3
/STATUS CNT2
bit5: 0 = OL count of selected Counter(s);
bit4: 0 = Latch status of selected Counter(s);
bit3: 1 = Selezione del Contatore 2;
bit2: 1 = Contatore di selezione 1;
bit1: 1 = Contatore di selezione 0;
bit0: vale 0.
14.7
bit2
CNT1
bit1
CNT0
bit0
0
In fig. 14.10 viene infine mostrato un layout fisco del chip 82C54.
Fig 14.10 Layout fisico del chip 82C54.
14.5 USO DEL TIMER 8254 NEL PERSONAL COMPUTER
Inoltre, osserviamo che nei personal computer il timer viene mappato alle seguenti porte di
I/O e interrupt verificabili attraverso lo strumento di gestione delle periferiche del sistema
operativo windows.
In tabella 14.8 e’ riportato un riepilogo dell’uso dei registri del chip 8254 in un Personal
Computer.
Tab. 14.8. Inizializzazione di CWR per effettuare un Read Back Command.
Chip name
Intel 8254
Intel 8254
Intel 8254
Intel 8254
Register name
CR0
CR1
CR2
CWR
Counter Register 0
Counter Register 0
Counter Register 0
Comtrol Word Register
I/O port
0x0040
0x0041
0x0042
0x0043
Glue logic
SPR
Speaker Register
0x0061
IRQ
IRQ0
-
14.6 Esercizio
Scrivere un programma in linguaggio C per generare, su un Personal Computer, una
interruzione ogni 50ns.
SOLUZIONE
Si calcola innanzitutto la costante di tempo del timer Tc:
Tc=1/1.19MHz=840ns
Da cui si ricava N :
N+1=50·10-3/Tc Æ N=59499
14.8
Un programma in linguaggio C che esegue l’inizializzazione del time
int init_8254 (void)
{
int cr_l, cr_h;
outp(0x0043, 0x30); /* contatore 0, costante di tempo a 16 bit,
modo 0, conteggio binario */
cr_l = 59499 & 0x000000FF;
cr_h = (59499 >> 8) & 0x000000FF;
outp(0x0040, cr_l);
outp(0x0040, cr_h);
}
14.7 COMUNICAZIONE SERIALE ASINCRONA
Nella Comunicazione seriale asincrona l'informazione viene trasmessa come sequenza di
caratteri o di bit. Affinche’ il messaggio trasmesso venga correttamente interpretato, è
necessario che il ricevente abbia la capacità di individuare l'inizio e la fine delle entità logiche
che compongono il messaggio stesso. Tale aspetto della comunicazione prende il nome di
sincronizzazione. Ci sono due modalità di trasmissione:
1) trasmissione asincrona;
2) trasmissione sincrona.
La differenza fondamentale fra le due modalità è che, con la prima i clock dei terminali
comunicanti non sono sincronizzati con la seconda lo sono; inoltre nella trasmissione asincrona
la sincronizzazione di bit e di carattere (byte) è implicita nella modalità di trasmissione
stessa.
La trasmissione asincrona trova naturale impiego quando i caratteri da trasmettere sono
generati ad intervalli casuali, in questo caso nell'intervallo fra la trasmissione di un carattere
e il successivo la linea può rimanere inattiva per un tempo indeterminato, è dunque necessario
che il ricevente si risincronizzi all'istante iniziale del carattere ogni volta che ne riceve uno.
La comunicazione richiede un'unità master (o Tx) che funge da trasmettitore, e una o piu’
unità dette slave (o Rx) che agiscono da ricevitore. La trasmissione può utilizzare uno o più fili
elettrici o anche essere “senza fili” (in inglese wireless).
14.7.1 Caratteristiche principali
La velocità di comunicazione è caratterizzata dal numero di bit trasmessi per secondo o
bit-rate: se T è il tempo per trasmettere un bit, 1/T è il bit-rate.
I pacchetti vengono incapsulati in una trama (in inglese chiamata frame) prima di essere
trasmessi e sono racchiusi tra un preambolo (in inglese header) e una coda (in inglese trailer).
Il preambolo serve a marcare l'inizio della trasmissione, la coda serve per marcare la fine
della trasmissione e per trasmettere un codice di verifica (fig 14.11 in alto).
Le codifiche a correzione d'errore sono ampiamente usate per le trasmissione wireless,
notoriamente rumorosa rispetto ai cavi di rame o le fibre ottiche. Nel caso piu’ semplice si
ricorre pero’ ad alcuni bit (campo CRC, Ciclic Redundancy Code) che servono a verificare se la
trama ricevuta contiene errori o meno. Spesso un solo bit, chiamato “bit di parita’” viene
aggiunto a tale scopo. Il bit di parità viene calcolato in modo che il numero di bit a uno
14.9
(compreso il bit di parita’) nella sequenza di bit sia sempre pari (o dispari). Per esempio per
trasferire 1011010 con parità pari bisogna aggiungere uno zero alla fine (10110100), mentre
con parità dispari un uno (10110101).
1
2
3
4
5
1
5
4
3
2
3
4
5
1
trasmissione
seriale
2
3
2
4
1
5
Fig 14.11. Trama seriale (fig. in alto) e pacchettizzazione (fig. in basso).
14.7.2 Gestione delle reti
L’OSI (Open System Interconnection) è un modello utilizzato per la descrizione delle reti,
esso si fonda sulla proposta dell'International Standards Organization (ISO) come primo
passo della standardizzazione internazionale dei protocolli impiegati nei diversi strati. Si
chiama modello di riferimento ISO/OSI perche’ riguarda la connessione di sistemi aperti,
cioè sistemi che sono aperti verso la comunicazione con altri sistemi simili. Il modello OSI ha
7 strati (fig. 14.12):
14.10
applicazione
interfaccia utente
presentazione
formato dati
(tipi dei dati, trasformazione dei servizi)
sessione
comunicazione fra le applicazioni ai due
estremi (raggruppamento dati, checkpointing)
trasporto
connessione
(gestione connessione, ottimizzazione,
gestione di rete)
rete (network)
servizio end-to-end
(comunicazione dati multi-hop end-to-end)
data link
trasporto dati affidabile
(rilevazione errori e gestione singolo link
(single-hop))
fisico
caratteristiche meccaniche/elettriche
(connettori, codifica dei bit, …)
Fig 14.12. Modello OSI.
Lo strato fisico: si occupa della trasmissione di bit grezzi sul canale di comunicazione.
Lo strato data link: suddivide i dati di ingresso in data frame che vengono trasmessi
sequenzialmente; se l'operazione è andata a buon fine viene rimandato indietro un messaggio
di acknowledgement frame.
Lo strato networks: assegna un indirizzo universalmente unico a ogni unità e indica la strada
da seguire da un punto all’altro della rete.
Lo strato trasporto: ha il compito di preparare i dati da trasmettere. Fra le altre funzioni,
questo strato gestisce il controllo di flusso e la correzione degli errori e ripartisce i dati dalle
applicazioni in segmenti di dimensioni appropiate agli strati inferiori.
Lo strato sessione: permette agli utenti di computer diversi di stabilire fra loro una
sessione.
Lo strato presentazione: si occupa della sintassi e del formato dell'informazione trasmessa.
Lo strato applicazione: comprende una varietà di protocolli comunemente richiesti
dall'utente.
Un protocollo applicativo largamente usato è HTTP che è la base del world wide web.
14.7.3 Standard Ethernet
Ethernet e’ uno standard ampiamente utilizzato nelle reti locali (Local Area Netwrok o LAN)
ed e’ stato proposto agli inizi degli anni 70. Altri tipi reti standardizzate da IEEE si trovano
sotto il nome di “IEEE 802”. Alcune parti di questo standard sono:
1) 802.3 (Ethernet) velocità di trasmissione 10 Mb/s;
2) 802.11 (LAN wireless);
3) 802.15 (Bluetooth);
14.11
4) 802.16 (MAN wireless);
5) 802.3u (Fast Ethernet) velocità di trasmissione 100MB/s;
6) 802.3ab (Gigabit Ethernet) velocità di trasmissione 1 Gb/s.
Ad es., Ethernet (IEEE 802.3) prevede di utilizzare una rete a bus (fig. 14.13): ad ogni istante
può trasmettere al più una sola macchina (nodo), tutte le altre macchine devono astenersi dal
trasmettere. Per stabilire il nodo che trasmette si usa un protocollo di accesso, chiamato
CSMA/CD, spiegato nel paragrafo successivo. La trama Ethernet ha il formato di fig. 14.14.
PE 1
PE 2
PE 3
PE 4
Figura 14.13. Reti seriali a Bus.
header
address
data
ECC
Figura 14.14. Formato della trama su bus seriali tipo Ethernet.
14.7.4 CSMA/CD Carrier Sense Multiple Access with Collision Detection
Ogni stazione prova a trasmettere sul mezzo comune e controlla che non ci siano collisioni. Per
garantire che nessuna stazione trasmetta se il canale risulta occupato, ogni nodo annnulla la
propria trasmissione in caso di collisione: se due stazioni dopo avere controllato il canale
iniziano a trasmettere contemporaneamente, entrambe rilevano la collisione quasi
immediatamente e invece di completare la trasmissione dei rispetivi frame ormai danneggiati,
le stazioni interrompono bruscamente la trasmissione. La terminazione rapida dellla
trasmissione dei frame danneggiati consente di risparmiare tempo e banda del canale; tale
protocollo di accesso al mezzo si chiama CSMA/CD.
Nello specifico il modo di trasmissione è il seguente:
1) un nodo ascolta prima di parlare (Carrier Sense);
2) se il mezzo è libero si attende un tempo “Defer Time”;
3) se ci sono collisioni (Multiple Access) l'energia sul mezzo aumenta;
4) un nodo cerca di rilevare collisioni durante la trasmissione (Collision Detect);
5) se un nodo rileva una collisione, la trasmissione viene ripetuta dopo R*Δt per altri 15
tentativi;
6) dopo 16 tentativi l'errore viene segnalato ai livelli superiori ;
Δt è fisso mentre R viene ricalcolato secondo un algoritmo detto di back-off, illustrato nel
paragrafo successivo.
14.7.4.1 Algoritmo di back-off per il calcolo di R
Dopo una collisione il tempo è suddiviso in intervalli discreti la cui lunghezza è uguale al tempo
di propagazione di andata e ritorno nel caso peggiore sul mezzo di trasmissione. Dopo la prima
collisione, ogni stazione aspetta 0 o 1 intervalli temporali prima di ritentare; se due stazioni
collidono e ognuna sceglie lo stesso numero casuale, la collisione si ripeterà. Dopo la seconda
14.12
collisione ogni stazione sceglie 0 ,1, 2 o 3 a caso e rimane in attesa per quel numero di
intervalli temporali. Se abbiamo una terza collisione la volta successiva il numero di intervalli
di attesa è scelto a caso fra 0 e 23-1. In generale, dopo k collisioni viene scelto un numero
casuale R compreso fra zero e 2k-1 e si salta quel numero di intervalli; dopo 10 collisioni il
tetto massimo dell'intervallo di scelta rimane bloccato a 1023 intervalli (fig. 14.15). Dopo 16
collisioni il chip di controllo comunica al computer un errore.
tempo
di attesa
per
ritrasmissioni
numero di tentativi
Figura 14.15 Grafico tempo di attesa ritrassimssioni
14.7.5 Dettaglio sul formato della trama (pacchetto) Ethernet
In dettaglio, il pacchetto Ethernet contiene i seguenti campi (fig. 14.16):
• Preamble: 31 coppie di bit che vale 10;
• Start frame: 1 coppia di bit che vale sempre 11; (preamble+start_frame sono 8 byte);
• Source address (indirizzo Ethernet del nodo trasmittente): 6 byte;
• Destination address (indirizzo Ethernet del nodo ricevente): 6 byte;
• Lenght (lunghezza complessiva del pacchetto): 2 byte;
• Data payload: sono i dati veri e propri; hanno una lunghezza massima di 1500 byte;
• Padding: utilizzato per riempire il frame quando la parte dei dati è minore di 46 bytes;
• Checksum (CRC): permette di rilevare eventuali errori (non la loro correzione).
preamble
8 byte
start
frame
source
adrs
dest
adrs
length
6 byte
6 byte
2 byte
data
payload
padding CRC
46-1500 byte
4 byte
Figura 14.16. Dettaglio Pacchetto Ethernet.
I bit di ordine più elevato nel campo destination address sono zero per gli indirizzi ordinari,
uno per gli indirizzi di gruppo; questi ultimi permettono a molte stazioni di rimanere in ascolto
di un singolo indirizzo (multicast), invece l’indirizzo composto da tutti bit 1 è riservato per la
trasmissione broadcast; un frame broadcast è inviato a tutte le stazioni su ethernet invece
quello multicast è inviato ad un gruppo selezionato di stazioni su ethernet.
Ethernet richiede che i frame validi siano lunghi almeno 64 byte (dal source address al CRC
incluso), questo perche’ il ricetrasmettitore quando rileva una collisione tronca il frame
corrente, e ciò significa che sul cavo compaiono continuamente bit sparsi e pezzi di frame.
14.13
Imporre una lunghezza minima serve per impedire ad una stazione di completare la
trasmissione di un frame breve prima che il primo bit abbia raggiunto la fine del cavo, dove
potrebbe collidere con un altro frame.
Lo standard Ethernet non richiede l’installazione di alcun software (a parte i driver) e non
dipende da tabelle di configurazione difficili da gestire.
14.7.6 Prestazioni della rete Ethernet
La qualità del servizio (QOS o Quality of Service) tende a decrescere in maniera non lineare
ad alti livelli di carico. Una conseguenza dell’algoritmo di back-off è che non è possibile
stabilire il tempo massimo entro cui verrà trasmessa con successo una trama. Questo significa
che:
- non si possono garantire deadline real-time.
- si possono ottenere livelli molto buoni di servizi purchè si riesca a mantenere il carico
ad un livello appropriato.
14.8 PORTE SERIALI
Le porte seriali sono un tipo periferica per il trasferimento dei dati tra due dispositivi. Il chip
che implementa la porta seriale è tipicamente chiamato UART (Universal Asynchronous
Receiver-Transmitter).
Le UART dei PC hanno una lunga storia; i chip originali 8250 e 16450 non avevano una
bufferizzazione adeguata per memorizzare i caratteri in arrivo; questo non rappresentava un
problema con un sistema operativo tipo DOS, che non doveva gestire più processi, ma per
sistemi operativi che non sono semplici “caricatori di programmi”, questo è diventato un
problema per velocità superiori ai 2400 baud, poiché la UART spesso sovrascrive i dati in
arrivo prima che il kernel del sistema operativo abbia la possibilità di estrarre i dati dal
buffer. Per risolvere questo problema fu introdotta la UART 16550, che includeva un buffer
FIFO (first-in, first-out); sfortunatamente questo chip conteneva un errore che rendeva il
buffer FIFO inutile. Fu percio’ introdotta la UART 16550A in cui si è parzialmente risolto
tale problema.
L'uscita dei dati avviene attraverso alcuni connettori esterni presenti nei computer, (come si
può verificare dalla descrizione dei dati tecnici del PC), con il nome di porta seriale o porta
RS-232.
A tale porta e’ possibile collegare diversi tipi di dispositivi accessori, con i quali e’ possibile
effettuare uno scambio di dati in entrambe le direzioni. L'utilizzazione principale di questa
porta avviene nel caso di collegamenti con periferiche attive, come mouse, modem, scanner,
penne ottiche.
Il traffico dei dati attraverso la porta seriale può avvenire a diverse velocità. In particolare,
poiché spesso lo scambio dei dati avviene a distanza di qualche metro, è necessario prevedere
anche lo scambio di alcuni segnali di controllo che permettano di verificare che i bit ricevuti
siano uguali a quelli trasmessi. L'interferenza di macchinari elettrici, come monitor, computer
o stampanti, potrebbe danneggiare il flusso dei bit durante il loro viaggio lungo il cavo.
La velocità di trasmissione, insieme alla struttura dei pacchetti di bit inviati ed al tipo di
controllo effettuato, determinano il protocollo usato nella trasmissione dei dati. I diversi
protocolli sono stabiliti internazionalmente.
La porta seriale consente anche il collegamento fra computer, sia direttamente tramite un
cavo, che a lunghe distanze, tramite modem. In entrambi i casi è molto importante stabilire in
14.14
precedenza il protocollo di trasmissione da entrambe le parti. La banda di trasmissione che si
può ottenere è limitata dalla banda telefonica, in analogico si può arrivare fino a 56 k e in
ISDN fino a 128 k.
Fisicamente la porta seriale è costituita da 2 registri a scorrimento, uno per trasmettere Tx
e uno per ricevere Rx. L’uscita del Tx è collegata all’ingresso del Rx; quando Tx è vuoto o Rx è
pieno viene generato un interrupt (14.17).
Transmitter (Tx)
n
n+1
n+2
n+3
n+4
01 23
01 2
01
0
n+5
4
3
2
1
0
n+6
5
4
3
2
1
0
n+7
6
5
4
3
2
1
0
n+8
Receiver (RX)
7
6
5
4
3
2
1
0
n
7
6
5
4
3
2
1
0
n+1
7
6
5
4
3
2
1
n+2
7
6
5
4
3
2
n+3
7
6
5
4
3
n+4
7
67
567
4567
n+5
n+6
n+7
n+8
Interrupt: Rx full
Interrupt: Tx empty
Fig 14.17. Registro a scorrimento della porta seriale.
Per evitare di perdere i dati viene usato un buffer con struttura FIFO che può essere
implementata come un array circolare (buffer) dotato di due puntatori, uno relativo al
prossimo carattere da scrivere (Bufln), ed uno per il prossimo carattere da leggere (BuffOut)
(fig.14.18).
Device 1
Device 2
Rx Register
FIFO buffer
FIFO buffer
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
7 6 5 4 3 2 1 0
Rx Data
Rx Data
Tx Data
Tx Data
0 1 2 3 4 5 6 7
FIFO buffer
7 6 5 4 3 2 1 0
7 6 5 4 3 2 1 0
7 6 5 4 3 2 1 0
FIFO buffer
Tx Register
Fig 14.18. Registro a scorrimento della porta seriale.
14.15
Quando uno dei puntatori raggiunge la fine del buffer, viene messo nuovamente a puntare al
primo elemento della coda. Quando i due puntatori coincidono il buffer è vuoto. Quando il
puntatore di scrittura raggiunge quello di lettura, il buffer è pieno e si perdono i dati.
14.8.1 Trasmissione dati
La trasmissione di un byte avviene secondo il seguente schema:
Lato Tx:
• Il dato scritto nel buffer FIFO viene inviato al Tx che genera un
interrupt non appena il byte è stato trasmesso.
Lato Rx:
• il buffer riceve il byte, bit per bit;
• l’intero byte, viene trasferito nel Rx-register (fig. 14.18);
• viene generato un interrupt ed il byte viene letto.
Il flusso dei dati viene controllato per evitare che il trasmettitore (Tx) invii più dati di quelli
che il ricevitore (Rx) può ricevere e questo viene fatto in due modi:
• Controllo di flusso ad Hardware:
- il chip UART del Rx individua un potenziale intasamento e attiva una linea apposita
per avvertire il Tx;
- Tx interrompe la trasmissione;
- appena Rx può ricevere i dati, la linea viene disattivata.
• Controllo di flusso a Software:
- Il Rx invia caratteri speciali di controllo (XON e XOFF) al Tx;
- XOFF interrompe una trasmissione;
- XON riprende la trasmissione.
14.8.2 I Connettori
Secondo lo standard EIA-RS232C i connettori più comuni sono due :
- DB25: connettore a 25 pin
- DB9: connettore a 9 pin
14.16
Tab. 14.9. Significato dei segnali dei connettori DB9 e mappatura su DB25.
DB-25
1
2
Sigla
GND
TXD
Segnale
Chassis Ground
Trasmit Data
3
RXD
Received Data
4
RTS
Request to Send
5
CTS
Clear to Send
6
DSR
Data Set Ready
7
8
GND
DCD
Signal Ground
Data Carrier Detect
20
DTR
Data Terminal Ready
22
RI
Ring Indicator
Significato
Linea di trasmissione dei dati connessa
alla linea RXD del Rx
Linea di ricezione del dato, connessa
alla linea del TXD del Tx
Utilizzata in congiunzione con CTS
segnala che Tx è pronto ad inviare dati
Utilizzata in congiunzione con RTS
segnala che Rx è pronto a ricevere i
dati
Indica che il data-set (modem) è
pronto a stabilire la comunicazione
Viene usato quando è connesso un
modem; indica che il data set (modem)
ha rivelato la portante sulla linea
telefonica
Indica che il data –terminal UART è
pronto a stabilire la comunicazione
Viene usato quando è connesso un
modem e indica che ci sono degli squilli
in arrivo sulla linea telefonica
DB-9
Not Used
3
2
7
8
6
5
1
4
9
Tx
Rx
DTR
DSR
RT S
DCE
CT S
DTE
DCD
GND
Figura 14.19. Schema DCE/DTE.
Nella terminologia dello standard RS-232, DCE (Data Carrier Equipment) e ad es. è un modem,
mentre il DTE (Data Terminal Equipment) e’ ad es. un terminale, un computer o un video.
Inizialmente questi segnali furono pensati per connettere fra loro i modem. Per la connessione
fra due DTE (es. stampanti o altre periferiche) si utilizzavano dei cavi diretti oppure cavi
null-modem.
14.8.3 UART
Sono circuiti di interfaccia per gestire la comunicazione Asincrona, e sono noti come Universal
Asynchronous Receiver and Transmitter (UART).
14.17
L’attributo “universale” sta a significare che il dispositivo è programmabile e dunque l’utente
può specificare le caratteristiche operative richieste inviando una opportuna parola di
controllo.
14.8.3.1 UART 16550A
L’16550A è un’interfaccia seriale asincrona di tipo UART (il chip e’ prodotto da molti
costruttori, come ad es. la National Semiconductor) che permette di generare internamente il
bit-rate sulla base di un clock esterno. Fra le caratteristiche principali consente il
riconoscimento di errori di trasmissione. La visione elettrica del chip è:
3
8
SIN
A2-A0
SOUT
D7-D0
/RTS
/CTS
/DTR
/DSR
/DCD
/RI
/RD
/WR
/CS
INTR
2
CLK
Vcc-GND
Figura 14.20. Schema dell’16550A.
I pin hanno il seguente significato
• /RD: Read;
• /WR:Write;
• A0-A2: Address Bits;
• D0-D7: Data Bus;
• INTR: Interrupt Request;
• SIN: Serial Input;
• SOUT: Serial Output;
• /RTS: Request To Send;
• /CTS: Clear To Send;
• /DCD: Data Carrier Detect;
• /DTR: Data Terminal Ready;
• /DSR: Data Set Ready;
• /RI: Ring Indicator.
I registri interni del chip sono i seguenti:
• Receiver Buffer Register (RBR);
• Transmitter Holding Register (THR);
• Divisor Latch Registers (DLR, parte piu’ significativa DLM, parte meno significativa DLL);
• Interrupt Enable Register (IER);
• Interrupt Identification Register (IIR);
• Line Control Register (LCR);
• Modem Control Register (MCR);
• Line Status Register (LSR);
• Modem Status Register (MSR).
14.18
e sono identificabili secondo il seguente schema di tabella 14.10.
Tab. 14.10. Indirizzi dei Registri.
NOME REGISTRI
RBR
THR
DLL
N° BIT
8
8
8
A2
0
0
0
A1
0
0
0
A0
0
0
0
DLAB
0
0
1
DLM
8
0
0
1
1
IER
8
0
0
1
0
IIR
LCR
8
8
0
0
1
1
0
1
-
MCR
8
1
0
0
-
LSR
MSR
8
8
1
1
0
1
1
0
-
ACCESSO
LETTURA
SCRITTURA
LETTURA E
SCRITTURA
LETTURA E
SCRITTURA
LETTURA E
SCRITTURA
LETTURA
LETTURA E
SCRITTURA
LETTURA E
SCRITTURA
LETTURA
LETTURA
Per stabilire il bit-rate occorre scrivere una costante C all’interno dei registro DLR
(DLL+DLM), procedendo come segue:
1) Si mette a 1 il bit DLAB (il bit denominato “DLAB” (Divisor Latch Access Bit) è un bit
di indirizzo aggiuntivo implementato nel bit 7 del registro LCR. Esso è normalmente
tenuto a 0, tranne per la programmazione del Divisor Latch Register)
2) Detta FCK la frequenza del clock esterno e BR il bit-rate desiderato si definisce la
costante C come:
FCK
C=
16 * BR
LCR - Line Control Register
Definisce il formato del frame (sia in trasmissione che in ricezione).
DLAB
BE
SP
PS
PE
STOP
L2
L1
• L2, L1 (Number of Data Bits) definiscono il numero di bit di dato (bit per carattere): L2= 0
L1 =0: 5 bit, L2= 0 L1 =1: 6 bit, L2= 1 L1 =0: 7 bit, L2= 1 L1 =1: 8 bit.
• STOP (Number of Stop Bits) Numero di bit di stop: STOP=0: 1 bit di stop,STOP=1: 1.5 bit di
stop (se il carattere è di 5 bit), 2 bit di stop (se il carattere è di 6, 7 o 8 bit).
• PE (Parity Enable)= 1: presenza di un bit di parità. Se PE = 1 i bit SP (Sticky Parity) e PS
(Parity Select) assumono il seguente significato:
- SP=0 PS=0: bit di parità a 1 se nel dato c'è un numero dispari di bit a 1,
- SP=0 PS=1: bit di parità a 1 se nel dato c'è un numero pari di bit a 1,
- SP=1 PS=0: bit di parità a 1 se nel dato c'è un numero dispari di bit a 0,
- SP=1 PS=1: bit di parità a 1 se nel dato c'è un numero pari di bit a 0.
• BE (Break Enable) = 1: trasmissione di un segnale di break: il piedino SOUT si porta a 0 e
rimane in questo stato fino a che BE non viene posto a 0.
• DLAB (Divisor Latch Access Bit). DLAB = 1 per l’accesso ai registri DLR.
14.19
LSR - Line Status Register
È accessibile esclusivamente in lettura. Contiene le informazioni relative allo stato
dell'interfaccia.
-
-
EO
B
FE
PE
OE
FI
Dove:
• FI (Full Input) = 1: un nuovo carattere è stato ricevuto dall'interfaccia ed è disponibile in
RBR. Posto a 0 quando il processore legge RBR;
• OE (Overrun Error) = 1: errore di Overrun;
• PE (Parity Error) = 1: errore di Parità;
• FE (Frame Error) = 1: errore di Frame;
• B (Break) = 1: ricezione di un break, stato in cui la linea di dato è tenuta a 0 per un tempo
superiore al tempo necessario per trasmettere una parola (incluso il tempo di
trasmissione del bit di start, stop e parità);
• EO (Empty Output) = 1: il dato contenuto nel registro THR è stato trasmesso. Posto
a 0 quando il processore scrive in THR.
FCR - FIFO Control Register
1Æ abilita FIFO
1Æ Rx FIFO reset
1Æ Tx FIFO reset
00Æ genera interrupt quando c’e’ un dato nella FIFO,
01Æ genera interrupt quando ci sono 4 dati nella FIFO,
10Æ genera interrupt quando ci sono 8 dati nella FIFO,
11Æ genera interrupt quando ci sono 14 dati nella FIFO
MCR - Modem Control Register
Attraverso il registro MCR il programmatore può forzare lo stato dei corrispendenti due
piedini di uscita del chip seriale (bit 0 e 1). Il bit MIE e’ il bit per l’abilitazione generale degli
interrupt. Per gli altri bit si rimanda ai data-sheet dei costruttori.
-
-
-
-
MIE
-
/RTS
/DTR
MSR - Modem Status Register
Il registro MSR permette di avere informazioni sullo stato e sulle variazioni dei piedini di
input DCD, RI, DSR e CTS.
DCD
RI
DSR
CTS
DDCD
DRI
DDSR
DCTS
I bit 0-3 se ad 1 indicano che lo stato del rispettivo segnale è cambiato nell'intervallo di
tempo che va dalla precedente lettura all'attuale lettura. I bit 4-7 riflettono lo stato del
rispettivo segnale: 1 indica che il piedino ha assunto il valore 0.
14.20
IER - Interrupt Enable Register
Il registro IER permette di abilitare le generazione di richieste di interruzioni su determinati
eventi.
-
-
-
-
SINP
ERBK
TBE
RDR
• RDR (Received Data Ready) = 1: abilitazione ad effettuare una richiesta di interruzione
quando un byte è pronto in RBR;
• TBE (Transmitter Buffer Empty) = 1: abilitazione ad effettuare una richiesta di
interruzione quando THR è vuoto;
• ERBK (Error & Break) = 1: abilitazione ad effettuare una richiesta di interruzione quando
viene rilevato un errore o un segnale di break;
• SINP (Serial Input) = 1: abilitazione ad effettuare una richiesta di interruzione quando uno
dei segnali di input del protocollo RS-232 (CTS, DSR, DCD, RI) cambia stato;
• I bit 4-7 sono sempre riservati.
IIR - Interrupt Identification Register
Il registro IIR è accessibile esclusivamente in lettura e permette di identificare lo stato
delle richieste di interruzioni.
FEI1
FEI0
-
-
FT
ID1
ID0
PND
• PND (Pending Bit) = 1: nessun interrupt è pendente; PND = 0 interrupt pendente;
• ID1, ID0 (Identify Bits): bit di identificazione delle richieste di interruzione.
ID1 = 0 ID0 = 0: variazione dei bit 0-3 di MSR;
ID1 = 0 ID0 = 1: THR vuoto (dato trasmesso);
ID1 = 1 ID0 = 0: RBR pieno (dato ricevuto);
ID1 = 1 ID0 = 1: errore in ricezione o break.
• FT (FIFO Timeout): interrupt per timeout di un interrupt in modalita’ FIFO;
• FE1-FE0 (FIFO Enable Indicator): valgono 11 quando FCR-bit0=1.
Esempio di programma che utilizza la porta seriale
Per provare il programma serialtest.c (riportato nella pagina successiva):
1) utilizzare due workstation che abbiano la seconda porta seriale collegata con cavo
null-modem;
2) fare il boot sotto linux e entrare col proprio account linux;
3) copiare il programma serialtest.c dalla directory /opt/serialtest;
4) compilare il programma avendo cura di modificare la porta usata da ttyS0 a ttyS1
all'interno del programma:
cc serialtest.c
5) su uno dei due PC lanciare:
./a.out -e
6) sull'altro PC lanciare:
./a.out
14.21
#include <sys/types.h>
#include <sys/stat.h> /* open */
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h> /* stdin, stdout, stderr */
#include <sys/ioctl.h>
#include <termios.h>
#include <stdlib.h>
#include <sys/time.h> /* timeval */
#include <stdlib.h>
#include <string.h> /* memset used by FD_ZERO */
#define DEFAULT_DEV "/dev/ttyS0"
#define DEFAULT_SPEED 115200
Else
{
printf("Running as echo server.\n");
while (!error) {
len = 0;
/* wait for 127 chars */
while (len < 127)
{
len += read(serfd, rxdata+len, 127);
printf("Got [%d/127]...\r", len);
fflush(stdout);
}
/* now compare the received data */
printf("-%d- Checking RX data... ", c++);
if (memcmp(txdata, rxdata, 127) == 0)
{
printf("OK...echoing.\n");
write(serfd, rxdata, 127);
}
else
{
printf("ERROR\n");
error = 1;
}
}
}
printf("Not OK !\n");
for (i=0;i<127;i++)
printf("%c", txdata[i]);
printf("\n");
int translate_speed(int spd);
void fd_setup(int fd, int speed, int flow);
int main(int argc, char **argv)
{
int serfd, i, c=0, error=0, len, do_echo = 0;
char txdata[127], rxdata[256];
if (argc > 2) {
printf("wrong syntax ! ./sertest [-e]");
exit(1);
}
if (argc == 2) {
if ((strcmp("-e", argv[1]))==0) do_echo=1;
else printf("wrong syntax ! ./sertest [-e]\n");
}
exit(1);
}
printf("Opening %s\n", DEFAULT_DEV);
serfd = open(DEFAULT_DEV, O_RDWR);
int translate_speed(int spd)
{
int speed_c = 0;
switch(spd) {
case 9600: speed_c = B9600; break;
case 19200: speed_c = B19200; break;
case 38400: speed_c = B38400; break;
case 57600: speed_c = B57600; break;
case 115200: speed_c = B115200; break;
case 230400: speed_c = B230400; break;
case 460800: speed_c = B460800; break;
default: printf(
"Bad baudrate %d is not valid.\n", spd); break;
}
return speed_c;
}
if (serfd < 0) exit(1);
fd_setup(serfd, DEFAULT_SPEED, 1);
for (i=0;i<127;i++) txdata[i]=i+64;
if (!do_echo)
{
while (!error){
len = 0;
i=0;
printf("-%d- Sending data...", c++);
write(serfd, txdata, 127);
printf("done.\n");
/* wait for 127 chars */
while (len < 127)
{
len += read(serfd, rxdata+len, 127);
printf("Got [%d/127]...\r", len);
fflush(stdout);
}
void fd_setup(int fd, int speed, int flow)
{
struct termios t;
if (fd < 0) { perror("fd_setup"); exit(1); }
/* now compare the received data */
printf("Got response, comparing... ");
if (memcmp(rxdata, rxdata, 127) == 0)
printf("OK.\n");
else
error = 1;
}
if (tcgetattr(fd, &t) < 0)
{ perror("tcgetattr"); exit(1); }
cfmakeraw(&t);
t.c_cflag &= ~CBAUD;
t.c_cflag |= translate_speed(speed) | CS8 | CLOCAL;
t.c_oflag = 0; /* turn off output processing */
t.c_lflag = 0; /* no local modes */
if (flow) t.c_cflag |= CRTSCTS;
else t.c_cflag &= ~CRTSCTS;
if (tcsetattr(fd, TCSANOW, &t) < 0)
{ perror("fd_setup : tcsetattr"); exit(1); }
}
return;
}
14.22
14.9 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[3] Andrew S. Tanenbaum “Modern Operating Systems”, Second Edition, 2001.
[4] Intel 8254 PROGRAMMABLE INTERVAL TIMER.
[5] M. Rebaudengo - M. Sonza Reorda Politecnico di Torino Dip. di Automatica e
Informatica
[6] Byte runner technology Link: http://www.byterunner.com/16550.html
[7] Seas education Link: www.seas.ucla.edu /classes
[8] Pklab, società informatica e robotica presso http: //www.pklab.net
[9] Exar data comunication application note http:// www.exar.com/ products/
[10] Ing . Marco Carli corso di reti di telecomunicazioni - http:// www.comlab.ele.uniroma3.it
/Sistemi1.
[11] William Stallings, 'Trasmissione dati e reti di computer,' Jackson 2000
[12] Sistemi di elaborazione università di Ferrara presso il sito http: //www.ing.unife.it / elettr/ SE/
MatDid.htm
[13] Datasheets Intersil presso il sito http: //www.intersil.com /cda /home /
[14] Dontronics presso il sito www.dontronics.com
[15]Università degli studi di Palermo corso di reti di calcolatori tenuto dal Dott. Giuseppe Lo Re slides
disponibili presso il sito http: //www.pa.icar.cnr.it /~lore/RC/
[16] Internet e Reti di Calcolatori", James F. Kurose, Keith W. Ross, MacGraw-Hill seconda edizione
[17] IEEE 802.3 CSMA/CD (ETHERNET) disponibile presso il sito http://www.ieee802.org/3/
[18] Università degli studi di Parma corso di reti di calcolatori corso dal Dott. Luca Veltri materiale
didattico disponibile presso il sito http :// www.tlc.unipr.it /veltri/reti-tlc-a /#slides
[19] Andrew S. Tanenbaum “Reti di calcolatori” 4° edizione.
14.23
LEZIONE 15
Hard disk
15.1 DESCRIZIONE GENERALE
Un hard disk (o disco magnetico) consiste di un insieme di piatti che ruotano attorno ad un
asse ad una velocità compresa tra 3600 e 7200 giri al minuto (oggi anche fino ad 15000). I
piatti, in metallo (recentemente in vetro2) con diametro che può variare da un pollice (2.5cm)
ad otto (20cm), sono coperti su ambedue le facce da materiale magnetico in grado di
memorizzare informazioni. La scrittura su disco è quindi non volatile, ossia i dati vengono
conservati anche quando viene tolta l’alimentazione.
Per leggere e scrivere informazioni su un hard disk al di sopra di ciascuna superficie è
posizionato un braccio mobile contenente una piccola bobina elettromagnetica chiamata
testina (head) di lettura/scrittura. Ciascuna superficie del disco è divisa in cerchi concentrici
chiamati tracce, tipicamente ogni superficie contiene dalle 1000 a 5000 tracce (track). Una
traccia è a sua volta divisa in settori che contengono le informazioni, ognuna di esse può
contenere da 64 a 200 settori, ed il settore è l’unità minima di lettura e scrittura (vedi fig.
15.1). Se sono disponibili piu’ superfici di memorizzazione, si puo’ immaginare che queste
costituiscano un cilindro (cylinder), tale termine viene usato in questo contesto come sinonimo
di traccia. Inoltre nell’accesso a superfici di memorizzazione distinte si fa riferimento alla
testina scrivente.
Piatti
Tracce
Settori
Piatto
Traccia
Figura 15.1
I dischi si suddividono in piatti, tracce e settori.
L’uso di componenti meccanici fa si che i tempi di accesso per i dischi magnetici siano molto
più alti che per le DRAM; per i dischi variano da 5 a 20 millisecondi, per le DRAM si hanno
tempi di accesso compresi tra 5 e 100 nanosecondi, il che rende le DRAM circa 100000 volte
più veloci, tuttavia a parità di capacità di immagazzinamento il costo per megabyte di un disco
è 50 volte minore di quello di una DRAM. Nella figura 15.2 e’ riportato l’andamento dei costi
del disco per MByte.
2
Il substrato in vetro presenta alcuni vantaggi, infatti si ha una:
− maggiore uniformità della pellicola magnetica superficiale, che produce, quindi, un miglioramento
dell’affidabilità del disco;
− riduzione dei difetti della superficie con conseguente riduzione degli errori di lettura/scrittura;
− minore distanza tra testina e supporto;
− maggiore rigidità;
− maggiore resistenza ad urti e danneggiamenti.
15.1
2057.61 $
0.001 $
1965
1975
1985
1995
2005
Figura 15.2 Andamento costo per MByte
15.1.1 Meccanismi di lettura e scrittura magnetica
Il meccanismo di scrittura si basa sul fatto che l’elettricità, fluendo attraverso la bobina
produce un campo magnetico; la testina di scrittura pertanto riceve impulsi, e nella superficie
sottostante vengono registrati schemi magnetici differenti dipendenti dalla corrente
(positiva o negativa).
La testina di scrittura è composta da materiale facilmente magnetizzabile ed ha la forma di
un ferro di cavallo attorno al quale sono avvolti pochi giri di conduttore filiforme (vedi fig.
15.3). Una corrente elettrica nel filo induce, attraverso gli estremi del ferro di cavallo, un
campo magnetico che magnetizza una piccola area del mezzo di registrazione; logicamente
l’inversione della direzione della corrente inverte l’orientamento del campo magnetico sul
supporto di registrazione.
Il meccanismo di lettura è basato sul fatto che un campo magnetico in movimento relativo
rispetto ad una bobina produce in essa una corrente elettrica. La porzione di superficie del
disco passante sotto la testina genera una corrente della stessa polarità di quella che
precedentemente era stata registrata.
Si può utilizzare la stessa testina e per la scrittura e per la lettura poiché hanno la stessa
struttura. Le testine singole sono utilizzate dai floppy disk e dai vecchi sistemi a disco rigido.
Tuttavia i sistemi a disco rigido odierni richiedono una testina di lettura distinta
comprendente un sensore magnetoresistivo (MR) parzialmente schermato.
Il materiale magnetoresistivo presenta una resistenza elettrica che dipende dalla
magnetizzazione del mezzo che si trova sotto di esso; tramite il passaggio della corrente
attraverso il sensore vengono rilevati, come segnali di tensione, i cambiamenti di resistenza.
Questo metodo garantisce maggior densità di memorizzazione e velocità operative piu’
elevate.
15.2
Corrente
di lettura
Corrente di
scrittura
Schermatura
Ampiezza
della traccia
Elemento
di scrittura
a induzione
Magnetizzazione
N
S
N
S
N
S
Sensore
MR
Supporto di
registrazione
N
S
N
S
N
S
N
S
Figura 15.3
Testina di scrittura induttiva e lettura magnetoresistiva.
15.1.2 Organizzazione e formattazione dei dati
Come precedentemente accennato la testina è un dispositivo relativamente piccolo in grado di
leggere e di scrivere su una porzione del disco rotante; ed è ciò che è all’origine della
disposizione fisica dei dati in anelli concentrici chiamati tracce. Esse sono tanto larghe quanto
la testina. Come detto, si usa il termine cilindro per far riferimento a tutte le tracce che in un
certo istante si trovano al di sotto delle testine sulle varie superfici.
Fisicamente, tracce adiacenti sono separate da spazi per prevenire, o quanto meno
minimizzare, gli errori dovuti al disallineamento della testina o all’interferenza tra i campi
magnetici.
Il trasferimento dati avviene per settori; che sono di lunghezza fissa o variabile (la maggior
parte dei sistemi odierni usa tipicamente settori a lunghezza fissa pari a 512 byte). Anche in
questo caso per ridurre eventuali imprecisioni i settori adiacenti sono separati da spazi vuoti
(vedi fig. 15.4).
Sector
S3
Intersector Gap
S4
Track
S3
S4
S5
S2
S2
S5
S1
S6
Intratrack Gap
S6
S1
S8
S8
S7
S7
Figura 15.4 Struttura del disco
I bit vicini al centro del disco ruotano più lentamente di quelli più esterni. E’ possibile
compensare la variazione di velocità, incrementando lo spazio tra i bit registrati sul disco man
15.3
mano che ci si allontana dal centro del disco, in modo tale che la testina possa leggere tutti i
bit alla stessa velocità (tecnica a velocita’ angolare costante).
Questa tecnica da’ come vantaggio che i singoli blocchi di dati possono essere indirizzati per
traccia e settore. Per spostare la testina verso un indirizzo specifico è sufficiente un suo
movimento verso la traccia desiderata e attendere che il settore specificato venga a trovarsi
sotto la testina. Come svantaggio si ha che la quantità di dati immagazzinabili deve essere la
stessa e per le tracce interne e per quelle esterne.
Essendo la densità, in bit per centimetro lineare, crescente man mano che ci si sposta dalla
traccia più esterna a quella più interna la capacità di memorizzazione dei dischi a velocità
angolare costante è limitata dalla massima densità ottenibile dalla traccia più interna. In
figura 15.5 è riportato l’andamento della crescita della densità per anno.
Year
Areal Density
1.7 100000
7.7
10000
63
3090
1000
17100
Areal Density
1973
1979
1989
1997
2000
100
10
1
1970
1980
1990
2000
Year
Figura 15.5 Andamento della densità.
Per incrementare tale densità si utilizza una tecnica nota come registrazione a più zone
(multiple zone recording) in cui la superficie è ripartita in un certo numero di aree (16
solitamente) all’interno delle quali il numero di bit per traccia è costante; le zone più lontane
dal centro contengono un numero maggiore di settori e quindi di bit rispetto a quelle più
centrali, ciò consente una capacità di memorizzazione più elevata a discapito di una logica
circuitale più complessa.
Poiché la testina si muove da una zona all’altra la lunghezza (lungo la traccia) dei singoli bit
varia, provocando così un cambiamento nei tempi di lettura e scrittura.
E’ logico che vi deve essere un criterio per localizzare la posizione del settore all’interno della
traccia, quindi un punto di partenza sulla traccia per poter identificare l’inizio e la fine di ogni
settore (Figura 15.6). Questi requisiti vengono rispettati tramite dati di controllo
memorizzati sul disco. Ossia il disco viene inizializzato con dei dati utilizzabili solo dal suo
sistema di controllo e non accessibili all’utente.
15.4
17
7
Gap1
Id
Sync
Byte
1
Track
#
2
41
515
20
17
Gap2 Data Gap3 Gap1
Head Sector CRC
#
#
1
1
2
7
Id
41
515
20
Bytes
Gap2 Data Gap3
Sync
Byte
Data
CRC
1
512
2
Bytes
Figura 15.6. Formato della traccia nel disco ‘ST506’.
15.2 CARATTERISTICHE FISICHE
La testina, rispetto alla direzione radiale del piatto, potrebbe essere fissa o mobile. Nei
dischi a testina fissa e’ presente una testina di lettura-scrittura per ciascuna traccia: tali
testine sono montate su un braccio rigido che si estende attraverso tutte le tracce (questi
sistemi attualmente sono rari). Nei dischi a testina mobile ve ne è una sola montata su un
braccio, quest’ultimo può estendersi o ritrarsi in quanto la testina deve essere in grado di
raggiungere una qualsiasi traccia.
Il disco è montato su un telaio comprendente il braccio, l’albero che fa ruotare il disco e i
circuiti per l’ingresso e l’uscita dei dati. I dischi non removibili restano montati nel proprio
telaio mentre quelli removibili possono essere asportati e sostituiti con altri dischi; il
vantaggio consiste nel poter disporre di quantità illimitate di dati pur avendo quantità limitate
di memorie disco, inoltre tali dischi possono essere spostati da un calcolatore ad un altro
come avviene con i floppy disk. I dischi magnetici removibili tendono oggi ad essere sostituite
da memoria a stato solido dette ‘memorie flash’.
Se la patina magnetizzabile è applicata ad entrambe le facce dei piatti i dischi sono detti a
doppia faccia (double-sided) altrimenti a singola faccia (single-sided). Nei modelli con più
piatti (multiple platter) disposti verticalmente a distanza di pochi centimetri sono presenti più
bracci; questi dischi utilizzano una testina mobile di lettura/scrittura per ogni superficie dei
piatti, le testine sono fissate meccanicamente in modo tale da trovarsi alla stessa distanza dal
centro del disco e muoversi contemporaneamente. Così, in ogni istante, tutte le testine sono
posizionate sulle tracce che presentano uguale distanza dal centro del disco.
A seconda del meccanismo della testina i dischi vengono classificati in tre tipi. Un un primo
tipo di disco, la testina di lettura/scrittura viene posizionata a distanza fissa sopra il piatto
lasciando un’intercapedine d’aria. All’altro estremo si trova un tipo di disco (floppy disk) in cui
il meccanismo che viene a contatto fisico con il supporto durante le operazioni di lettura o
scrittura. Per il terzo tipo va detto che la testina deve generare o leggere un campo
elettromagnetico di intensità sufficiente alla scrittura e alla lettura. Più è stretta la testina e
più è vicina alla superficie del piatto, quindi tracce più ravvicinate e pertanto maggiore densità
dei dati. Tuttavia più la testina è vicina al disco e maggiore è il rischio d’errore per impurità o
imperfezione. Per un miglioramento della tecnologia venne sviluppato il disco Winchester (esso
si trova comunemente all’interno di personal computer e workstation); le sue testine sono
utilizzate negli assemblaggi di dischi ermeticamente sigillati, praticamente privi di
contaminanti. Esse operano più vicino alla superficie rispetto a quelle convenzionali
consentendo così una maggiore densità dei dati.La testina è in realtà una foglia aerodinamica
15.5
che si appoggia leggermente alla superficie del piatto quando il disco è fermo. La pressione
dell’aria generata da un disco in rotazione è sufficiente per allontanare la foglia dalla
superficie. Il sistema risultante, privo di contatto, può quindi utilizzare testine più strette
che operano più vicino alla superficie del piattello.
15.3 CARATTERIZZAZIONE DELLE PRESTAZIONI DEL DISCO
Per accedere ai dati il sistema operativo deve pilotare i dischi attraverso un processo
composto da tre fasi.
Nella prima si posiziona la testina sopra la traccia più opportuna, operazione denominata seek
(letteralmente ricerca) ed il tempo necessario richiesto è denominato tempo di seek. I
produttori di dischi riportano nei loro manuali il tempo di seek minimo, massimo e medio. I
primi due sono facilmente misurabili, mentre la media si presta a diverse interpretazioni
poiché dipende dalla distanza di posizionamento. Le industrie si sono accordate nel calcolare il
tempo di seek medio come la somma di tutti i possibili tempi di seek divisa per il numero di
posizionamenti possibili. I tempi di seek medi che vengono dichiarati oscillano tra 8 ms e 20
ms, tuttavia a causa della località dei riferimenti al disco i valori medi reali possono anche
essere solo il 25-33% di quelli dichiarati; il fenomeno della località si manifesta sia a causa di
accessi consecutivi allo stesso file, sia perché il sistema operativo tenta di far eseguire
insieme tali accessi.
Una volta che la testina ha raggiunto la traccia corretta (seconda fase) è necessario
attendere che il settore desiderato si muova (ruotando) sotto la testina di lettura/scrittura;
questo tempo viene chiamato latenza di rotazione o ritardo di rotazione. La latenza media per
raggiungere l’informazione desiderata corrisponde a mezza rotazione del disco e poiché questi
ruotano ad una velocità compresa tra 3600 RPM e 7200 RPM la latenza di rotazione media
varia tra:
latenza di rotazione media = 0.5 rotazioni/3600 RPM = 8.3 ms
latenza di rotazione media = 0.5 rotazioni/7200 RPM = 4.2 ms
I dischi caratterizzati da diametri più piccoli sono più attraenti, poiché possono
ruotare a velocità maggiori senza un consumo eccessivo, riducendo così la latenza di
rotazione.
L’ultima fase che caratterizza un accesso ad un disco e’ denominata tempo di
trasferimento: è il tempo necessario per trasferire un blocco di bit, che corrisponde
solitamente ad un settore. Il tempo di trasferimento è una funzione della dimensione
del settore (oggi in realta’ molti trasferimenti da disco hanno una lunghezza pari a più
settori), della velocità di rotazione e della densità di memorizzazione di una traccia. Il
calcolo si complica di più se si considera che la maggior parte dei dischi possiedono una
cache integrata che memorizza i settori man mano che questi vengono acquisiti.
Il controllo del disco ed il trasferimento dei dati tra il disco e la memoria vengono
gestiti da un controllore di disco. Esso è responsabile dell’aggiunta di un’ulteriore
componente al tempo di accesso al disco, nota come tempo del controllore, che
corrisponde al ritardo che il controllore impone all’esecuzione degli accessi di I/O.
Quindi il tempo medio per eseguire un’operazione di I/O è determinato da queste
componenti oltre ad eventuali tempi di attesa dovuti al fatto che altri processi stanno
utilizzando il disco.
15.6
Esempio:
Calcolare il tempo medio per la scrittura o la lettura di un settore di 512 byte
per un disco che ruota a 5400 RPM ed in cui il tempo medio di seek e’ pari a 12
ms, il tempo di trasferimento e’ 5 MB/s, il tempo aggiuntivo causato dal
controllore risulta 2 ms.
Il tempo medio di accesso al disco è pari al tempo medio di seek + la latenza di
rotazione media + il tempo di trasferimento + il tempo del controllore.
Tempo medio accesso disco = 12 ms + 5.6 ms + (0.5 KB)/(5 MB/s) + 2 ms = 19.7
ms
Se il tempo medio di seek misurato fosse pari al 25% del tempo medio indicato il
risultato sarebbe:
Tempo medio accesso disco = 3 ms + 5.6 ms + (0.5 KB)/(5 MB/s) + 2 ms = 10.7
ms
Da notare è che quando si prende in considerazione il tempo medio di seek misurato,
anziché quello indicato dal costruttore, la latenza di rotazione può divenire la
componente principale del tempo di accesso.
Ciascuna traccia contiene lo stesso numero di bit, tuttavia quelle esterne sono più
lunghe. Queste, quindi, memorizzano le informazioni con una minore densità per
centimetro rispetto alle tracce più vicine al centro del disco. In alcuni tipi di hard
disk, quali tipicamente quelli basati sull’interfacctia SCSI (Small Computer Systems
Interface) si usa invece una tecnica detta densità di bit costante, basata sulla
memorizzazione di un numero maggiore di settori nelle tracce esterne rispetto a
quelle interne. La velocità alla quale si muove l’unità di lunghezza della singola traccia
sotto la testina è pertanto variabile ed è maggiore per le tracce esterne. Di
conseguenza, se il numero di bit per unità di lunghezza è costante, la frequenza alla
quale i bit devono essere letti/scritti è variabile, quindi, la parte elettronica del
dispositivo deve tener conto di questo fattore.
15.4 STANDARD DI COMUNICAZIONE
Le tecnologie utilizzate per gli hard disk sono oramai molto sofisticate, dovute direttamente
dalla maggiore richiesta di elevate prestazioni e capacità. L’evoluzione costante di processori
e memorie incrementa la quantità di dati da elaborare e gli hard disk sono costretti a ospitare
e spostare moli sempre maggiori di Mbyte. Le innovazioni tecniche riguardanti vari
componenti, come dischi e testine, condizionano la capacità degli hard disk oltre che le loro
prestazioni.
I vari sistemi d’interfacciamento sono importanti per evitare l’insorgere di limitazioni dal
punto di vista delle prestazioni. Attualmente (anno 2005) il sistema di interfacciamento più
diffuso utilizza il bus parallelo dello standard ATA (AT Attachment). Ad esempio, nello
standard ATA/100 e’ possibile ottenere una velocita’ di trasferimento dal controller all’hard
15.7
disk pari a 100. Una tale velocità è ragguardevole in quanto non ci sono, per ora, applicazioni
che richiedono tutta questa larghezza di banda.
Il trend degli hard disk per Personal Computer è orientato verso un nuovo standard
denominato S-ATA (Serial ATA), il quale usa un bus di comunicazione seriale anziché parallelo.
Il 29/08/2001 sono state rilasciate le specifiche della versione 1.0 dello standard Serial
ATA. Questa evoluzione fornisce prestazioni più elevate permettendo di superare alcune
limitazioni dovute ai precedenti protocolli di comunicazione, quali l’elevato numero di pin da
utilizzare per i collegamenti, la complessità (e quindi i costi) dei cavi usati e le tensioni in
gioco relativamente elevate. La prima evidente differenza è nei cavi, i quali utilizzano una
connessione punto-punto con lunghezza massima di un metro; inoltre, il Serial ATA, concepito
per collegare unità interne, usa due coppie di fili contro i 40/80 necessari con lo standard
ATA parallelo.
I sistemi operativi attuali sono compatibili poiché questo bus è trasparente rispetto alle
applicazioni; sarà, quindi, solamente necessario istallare i corrispondenti driver per il
controller così come accade per qualunque altro dispositivo. Un altro aspetto interessante è
che per il suo funzionamento necessita di una tensione di 500 millivolt picco-picco, inferiore a
quella di 5 V richiesta dagli standard ATA paralleli. Le conseguenze si ripercuotono sui
produttori di chipset; infatti, essendo il controller per gli hard disk ormai integrato nel
chipset principale del calcolatore, il non esser costretti a utilizzare una tensione di 5 V
permette di costruire chip con minori dimensioni e pertanto con un risparmio in termini di
costi di produzione. Questa riduzione di tensione torna anche utile per il mondo dei portatili
con conseguente prolungamento dell’autonomia delle batterie.
Per quanto riguarda la topologia di collegamento usata da Serial Ata ci si trova di fronte a una
configurazione a stella. Ossia da un connettore del controller parte un cavetto che va
direttamente all’hard disk, per collegare un secondo hard disk serve un secondo connettore e
un altro cavetto analogo al primo. Tra le conseguenze di questo tipo di collegamento c’è la
possibilità di evitare collisioni di segnali sullo stesso cavo, con diversi vantaggi per le
prestazioni.
A livello software non ci sono sconvolgimenti dato che il comportamento dei registri di
controllo e dei comandi, i trasferimenti dati, i reset e gli interrupt sono tutti emulati
dall’unità.
15.5 DIREZIONI FUTURE
I dischi magnetici hanno capacità che crescono rapidamente anche se il tempo di
accesso migliora molto più lentamente. Una delle spiegazioni sta nel fatto che i dischi
magnetici hanno un’evoluzione più veloce nella fascia bassa piuttosto che in quella alta
del mercato, ed è la fascia bassa a registrare una spinta maggiore verso un limitato
costo per megabyte. Questo mercato ha dato il suo contributo alla riduzione nella
dimensione dei dischi dai piatti da 14 pollici (35 cm) usati per i dischi dei mainframe ai
dischi di 1.3 pollici (3.5 cm) sviluppati per i calcolatori portatili e palmari. Questa
elevatissima richiesta di dischi piccoli ha portato ad un’accelerazione per il
miglioramento della densità dei dischi.
Oltre al miglioramento della densità sono cresciute anche le velocità di trasferimento,
man mano che i dischi aumentavano la propria velocità di rotazione e miglioravano le
interfacce. Inoltre, ogni disco ad alte prestazioni prodotto oggi contiene un buffer di
15.8
traccia o di settore che implementa un meccanismo di cache che memorizza i settori
quando la testina passa sopra di essi.
Un’importante novità per ciò che concerne l’organizzazione dei dischi è costituita dai
sistemi RAID (Redundant Array of Inexpensive Disks o letteralmente schiere di
dischi piccoli ed economici). La motivazione che spinge a ciò è che, poiché il prezzo per
megabyte è indipendente dalla dimensione del disco, il throughput potenziale può
essere migliorato utilizzando più unità disco e quindi più testine: la distribuzione dei
dati su più dischi fa sì che gli accessi avvengano su più dischi; mentre l’uso delle
schiere migliora il throughput , la latenza non viene però necessariamente ridotta.
L’aggiunta dei dischi ridondanti offre la possibilità di scoprire un disco guasto e
recuperare automaticamente l’informazione perduta. Le schiere possono quindi
migliorare l’affidabilità e le prestazioni dei sistemi di elaborazione. Ad esempio IBM
offre sia la soluzione basata su RAID sia un sottosistema di dischi che utilizza i dischi
più grandi prodotti dall’azienda.
Nonostante questo continuo sviluppo va sottolineato come il disco rimanga il vero collo
di bottiglia dei moderni Personal Computer: con tempi di accesso ai dati dell’ordine di
una decina di millisecondi, un moderno processore può sprecare qualche milione di cicli
utili in attesa del dato giusto da elaborare. Le piattaforme multiprocessore di
prossima introduzione non faranno che esasperare questo problema, necessitando di
maggiori quantità di dati da elaborare.
Le nuove generazioni di dischi rigidi hanno,tuttavia, tutte le carte in regola per stare
al passo con le future piattaforme. Infatti basti osservare le nuove tecnologie dei
protocolli di comunicazione. Ad esempio, la tecnologia NCQ (Native Command
Queueing) è la caratteristica più avanzata del futuro standard Serial Ata II. NCQ è
un protocollo che permette all’hardware di controllo del disco di mantenere in sospeso
più comandi allo stesso tempo. I dischi che lo supportano dispongono di un buffer dove
i comandi pervenuti possono essere accodati, riordinati e infine essere eseguiti in
modo dinamico per ottimizzare i tempi di accesso e scrittura dei dati sulla superficie
magnetica. Il protocollo Serial Ata II si basa su tre nuove funzioni integrate atte a
migliorare le prestazioni dei dischi: Race Free Status Return Mechanism, Interrupt
Aggregation e First Party Dma.
La prima funzione consiste nella possibilità di comunicare la risposta, o status, ad un
qualunque comando dell’host in ogni momento senza che questo resti in attesa per
riceverlo; in questo modo il drive può soddisfare comandi multipli e restituirne lo
stato consecutivamente o perfino nello stesso momento.
La seconda funzione, aggregazione degli interrupt, consente di superare il problema
che riguarda il drive per ciò che concerne la produzione di un segnale d’interruzione
per l’host ogni volta che completa un comando: se un drive con NCQ completa più
comandi in un tempo molto breve, i singoli segnali di interrupt vengono aggregati per
produrne uno solo affinché l’host sia interrotto una volta sola per più comandi.
Infine la funzione First Party Dma consiste in un sofisticato sistema che permette al
drive di eseguire un’operazione di accesso diretto alla memoria centrale per
trasferirvi dati senza l’intervento del software dell’host ed è alla base della
15.9
possibilità di riordinare la sequenza di esecuzione dei comandi. Infatti, il drive può
scegliere di propria iniziativa il buffer da trasferire e preparare il comando
appropriato per il sistema DMA, il controller dell’host si limita quindi a copiare nel
controller DMA la direttiva che arriva dal drive in modo che venga avviato il
trasferimento hardware dei dati.
E’ evidente che, con il sistema NCQ, l’host può trasmettere comandi mentre il disco
sta ancora eseguendo quelli precedenti, offrendo così un miglior supporto al software
multithread per Windows o Linux. In pratica la coda delle richieste di accesso al disco
viene riordinata e eseguita tenendo conto della posizione delle testine sui dischi, in
modo da ridurre al minimo il numero di rotazioni dei dischi e di spostamenti delle
testine, il che comporta migliori prestazioni e minore usura meccanica. La logica NCQ
del drive può decidere di eseguire subito una richiesta appena arrivata, facendole
saltare una lunga coda di attesa, se determina che la testina sia già nella giusta
posizione, magari integrando la richiesta a quelle che riguardano lo stesso settore su
disco. Le prove di laboratorio hanno evidenziato come, anche in mancanza di software
appositamente ottimizzato, l’incremento di prestazioni è di almeno il 15%.
Per ciò che concerne i futuri supporti ottici sono da menzionare due formati, che sono
il Blu-Ray e HD-DVD (entrambi basati su laser blu, cioe’ a lunghezza d’onda piu’ bassa
rispetto ai laser attualmente utilizzati nelle memorie ottiche) che sono in concorrenza
per succedere agli attuali formati per DVD. I supporti Blu-Ray possono contenere fino
a 50 GByte di dati, mentre gli HD-DVD possono registrare fino a 32 GByte di dati. Il
supporto fisico ha lo stesso spessore di un normale DVD (1.2 millimetri) e i
masterizzatori di DVD esistenti si potrebbero modificare con poca spesa. Blu Ray e
HD-DVD sono, quindi, una soluzione interessante per il backup dei dati. E’ interessante
notare come anche nella variante Double Layer (7.9 GByte) il DVD non riesca ad
eguagliare la capacità di archiviazione offerta da Blu Ray e HD-DVD.
15.6 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
15.10
LEZIONE 16
Introduzione al sottosistema di memoria
16.1 INTRODUZIONE
Il sottosistema di memoria rappresenta una parte fondamentale per il funzionamento di un
calcolatore ed influenza consistentemente le sue prestazioni.
Esistono varie tipologie di memorie e varie tecnologie sono utilizzate per implementarle.
Le memorie ad accesso casuale (RAM –Random Access Memory) consentono di leggere e
scrivere informazioni con un tempo di accesso che risulta indipendente dalla locazione di
memoria effettivamente indirizzata. Questo tipo di memorie possono essere volatili, cioè se
ne perde il contenuto quando viene spento il calcolatore, oppure non-volatili.
Le memorie ad accesso semicasuale possiedono come caratteristica il fatto che il tempo di
accesso è dipendente, sia dalla locazione fisica dell’informazione, sia dal particolare istante in
cui viene effettuato l’accesso. Alcuni esempi che utilizzano questo tipo di modalità sono i
dischi-fissi (Hard Disk) e i CD-ROM.
Nelle memorie ad accesso sequenziale, i dati vengono memorizzati in modo sequenziale nelle
locazioni di memoria; quindi il tempo di accesso dipende in maniera lineare dalla locazione
fisica. I nastri sono delle componenti hardware che utilizzano questo tipo di modalità.
16.2 RANDOM ACCESS MEMORY (RAM)
Esistono diverse tecnologie con cui vengono realizzate memorie ad accesso casuale, quali le
DRAM (Dynamic Random Access Memory), le SRAM (Static Random Access Memory) e le
memorie non volatili (es. ROM, EPROM e varianti, Flash). Questi tipi di memoria prevedono un
meccanismo fisico per l’accesso alla locazione di memoria che consente di ottenere un tempo
di accesso relativamente basso rispetto agli altri tipi di tecnologie di accesso ed inoltre tale
tempo risulta lo stesso qualunque sia la locazione di memoria alla quale sia necessario
accedere. I vari tipi di memoria RAM si differenziano principalmente per la diversa tecnologia
usata per l’implementazione fisica della locazione di memoria, detta anche “cella di memoria”.
A seconda della tecnologia usata, la cella risultera’ piu’ veloce, piu’ compatta, in grado di
mantenere o meno le informazioni in assenza di alimentazione.
Il tipo di cella piu’ compatto si realizza con la tecnologia DRAM: in questo caso la cella e’
realizzata con un semplice condensatore (come vedremo in dettaglio nel capitolo 16.4 ogni bit
puo’ essere memorizzato mediante un condensatore). Per questo motivo le memorie DRAM
sono spesso usate per realizzare la memoria principale, in modo da ottenere una grande
capienza a bassi costi. Il tipo di cella piu’ veloce si realizza con la tecnologia SRAM: in questo
caso la cella e’ realizzata utilizzando anche 6 transistor. Le memorie SRAM, che verranno
approfondite nel capitolo 16.3, sono normalmente usate per realizzare memorie veloci, come la
memoria cache dato che i tempi di accesso sono relativamente bassi (circa 5 ns con le
tecnologie attuali). Se non c’e’ bisogno di variare il contenuto della cella di memoria si fa’ uso
delle memorie non volatili, che hanno il vantaggio di mantenere i dati memorizzati anche in
assenza di alimentazione della cella. Esistono diversi tipi di memorie non volatili, quali le ROM
(Read Only Memory), le PROM (Programmable ROM), le EPROM (Erasable PROM), le EEPROM
(Electrical EPROM) e infine le memorie Flash.
Nelle ROM, che come indica il nome sono memorie di sola lettura, i dati vengono memorizzati
quando viene fabbricato il circuito e non possono più essere alterati. Le PROM sono ROM
programmabili, ovvero la memoria può essere scritta soltanto una volta e normalmente questo
viene fatto dal costruttore.
Invece le EPROM, le EEPROM, e le memorie flash sono riscrivibili, tipicamente attraverso due
passi: cancellazione e scrittura. Questi tre tipi di memoria usano procedimenti diversi per
16.1
eseguire la cancellazione dei dati. Le EPROM sono cancellabili a livello di chip attraverso
l’esposizione di raggi UV (Ultra Violetti). Le EEPROM sono cancellabili a livello di byte
elettricamente, applicando un determinato potenziale alla cella di memoria, mentre le memorie
Flash sono cancellabili sempre elettricamente, ma a livello di blocco. Queste ultime hanno una
struttura simile a quella delle DRAM, ovvero hanno un singolo transistor per cella di memoria,
e sono caratterizzate da un alta densità di celle. Inoltre, il tempo di lettura è paragonabile a
quello delle DRAM (circa 100 ns con le tecnologie del 2004).
Nella tabella 16.1 vengono evidenziate le differenze fra i vari tipi di memorie ad accesso
casuale (RAM).
Tabella 16.1. Riepilogo caratteristiche memorie ad accesso casuale
Tipo
SRAM/DRAM
ROM
PROM
EPROM
Flash
EEPROM
Categoria
read/write
read only
read only
read only
read mostly
read mostly
Cancellazione
elettricamente
impossibile
impossibile
luce UV
elettricamente
elettricamente
Scrittura
elettricamente
maschere
elettricamente
elettricamente
elettricamente
elettricamente
Volatilità
volatile
non volatile
non volatile
non volatile
non volatile
non volatile
16.3 CELLA DI RAM STATICA (SRAM)
La cella di RAM statica e’ costituita da circuiti capaci di rispondere rapidamente all’accesso e
al tempo stesso di mantenere l’informazione in essa contenuta per tutto il periodo in cui la
stessa e’ alimentata. La figura 16.1 rappresenta la tipica struttura di una cella di memoria di
una RAM statica (SRAM). Due buffer invertenti sono formano un latch. Il latch è collegato
alla linea su cui transita il dato (fisicamente composta da due linee bit e /bit, per ragioni di
efficienza di pilotaggio della cella) tramite i due transistor di passo. Questi ultimi hanno la
caratteristica di agire da interruttori controllati della linea di indirizzamento della cella
(word line). Quando, ad esempio, la word line è a massa i transistor di passo sono chiusi e di
conseguenza il latch mantiene il proprio stato.
word line
Cella a 6 Transistor
word line
0
0
bit
1
1
bit
bit
bit
Figura 16.1: Cella SRAM
Per poter eseguire un’operazione di lettura dalla cella SRAM, dopo aver precaricato entrambe
le bitline alla tensione di alimentazione VDD, la word line deve essere attivata aprendo i
transistor di passo. Se la cella si trova nello stato logico 1, il segnale sulla linea bit restera’
alto, mentre quello sulla linea /bit diventera’ basso. La situazione è opposta nel caso in cui la
16.2
cella sia nello stato logico 0. Le due linee bit e /bit pilotano un “sense amplifier” (un circuito in
grado di amplificare la differenza tra i due segnali) che fornisce in uscita il dato letto.
Per quanto riguarda le operazioni di scrittura, lo stato della cella viene aggiornato portando la
linea bit (e conseguentemente /bit) al valore da scrivere, e successivamente attivando la word
line. A questo punto il contenuto della cella viene forzato nello stato desiderato.
16.3.1 Organizzazione delle celle SRAM
Per formare una memoria di una certa dimensione, la cella viene replicata secondo uno schema
bidimensionale come mostrato in figura 16.2: tutti i latch di una certa colonna della memoria
siano collegati alla stessa linea in output (es. Dout 1) attraverso un Sense–Amplifier. Quando il
sense amplifier rileva la piccola variazione di tensione determinata dalla “apertura” della cella
in lettura, sbilancia completamente la sua tensione di uscita verso un valore alto o basso di
tensione, in base al segno della variazione rilevata.
Din 3
Din 2
Din 1
Din 0
Wr Driver &
- Precharger +
Wr Driver &
- Precharger +
Wr Driver &
- Precharger +
Wr Driver &
- Precharger +
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
WE_L
Precharge
‘_L’ Æ
attivo basso
Word 0
A1
A2
A3
Address Decoder
A0
Word 1
:
:
:
:
Word 15
SRAM
Cell
SRAM
Cell
SRAM
Cell
SRAM
Cell
- Sense Amp +
- Sense Amp +
- Sense Amp +
- Sense Amp +
Dout 3
Dout 2
Dout 1
Dout 0
Figura 16.2. Struttura celle SRAM (16 word x 4 bit)
La funzione dell’Address Decoder è quella di selezionare e abilitare in lettura o scrittura una
determinata word line della memoria (dalla word 0 alla word 15, nell’esempio). Per abilitare il
processo di scrittura o lettura viene usato il segnale WE_L3 (Write Enable).
Il segnale precharge serve ad attivare il circuito precharger che si occupa di caricare le linee bit e
/bit entrambe alla tensione VDD. Successivamente, il sense-amplifier rilevera’ la leggera differenza
di carica che si puo’ generare all’accesso della cella. Poiché la linea dati viene tipicamente mappata
su un unico segnale di ingresso/uscita DQ, completano lo schema coppie di buffer tri-state (uno per
ogni coppia Din e Dout) pilotati dal segnale OE_L (Output Enable), come in figura 16.3.
3
Con il simbolo “_L” si indica che il segnale è ATTIVO BASSO, ossia assume il significato di attivo se il valore sulla linea è basso.
16.3
OE_L
Din o D
DQ
Dout o Q
Figura16.3. SRAM Bus dati
Attivando o disattivando i segnali di controllo WE_L e OE_L si hanno varie combinazioni
possibili (Tabella 16.2).
Tabella 16.2: Controllo del bus dati SRAM
WE_L
Basso
Alto
OE_L
Alto
Basso
Significato
Scrittura con ingresso in DQ
Lettura con uscita in DQ
Attivando WE_L (basso) e disattivando OE_L (alto) si abilita la scrittura in memoria e si
assume DQ come ingresso. Disattivando WE_L (alto) e attivando OE_L (basso) si abilita la
lettura e si assume DQ come uscita. Deve essere evitato di attivare sia WE_L (Write Enable)
che OE_L (Output Enable) poiché si viene a verificare uno stato di indeterminazione.
Infine, si usa un ulteriore segnale di controllo, CE_L (Chip Enable) per disattivare (alta
impedenza), il bus dati in modo che non vada a costituire un inutile carico sul bus comune ad
altri chip.
Si osservi che la struttura esaminata in figura 16.2 ha soprattutto una valenza didattica in
quanto una memoria di maggiori dimensioni dovra’ invece essere suddivisa in modo da evitare
decoder di enormi dimensioni.
16.3.2 Temporizzazione delle SRAM
In figura 4, viene riportata la temporizzazione del ciclo di lettura e di quello di scrittura di
una SRAM.
Write Timing:
Read Timing:
High Z
DQ
Data In
A
Write Address
Data Out
Junk
Read Address
Data Out
Read Address
OE_L
WE_L
Write
Setup
Time
Write
Pulse
Time, tWP
Read
Access
Time
Write
Hold
Time
Write Cycle Time, tWC
Read
Access
Time
Read Cycle Time, tRC
Figura 2. Temporizzazione SRAM
Il tempo di accesso sull’operazione di lettura (Read Access Time) è definito come il tempo
necessario ad avere i dati stabili all’uscita, ed è calcolato a partire dall’istante in cui gli
indirizzi A ed i segnali di controllo (OE_L e WE_L) sono stabili agli ingressi. Dopo che il
16.4
segnale di controllo OE_L viene attivato, l’uscita esce dallo stato di alta impedenza (High Z), e
dopo un certo tempo (Read Access Time), i dati sono stabili sull’ uscita (Data Out). Trascorso
il tempo trc (Read Cycle Time), si può iniziare un nuovo ciclo di lettura.
Per quanto riguarda l’operazione di scrittura, è necessario che sia fornito l’indirizzo A,
abilitato il segnale di controllo chip enable (CE_L) e che siano presenti i dati in ingresso da
scrivere. Il tempo che si deve attendere prima di poter attivare WE_L per abilitare l’impulso
di scrittura (Write Pulse) è detto Write Setup Time. Il tempo che WE_L deve rimanere
attivo per completare la scrittura è detto Write Pulse Time (twp). Per completare l’operazione
si deve attendere un ulteriore tempo detto Write Hold Time. Con twc (Write Cycle Time) si
indica il tempo dopo il quale può cominciare un nuovo ciclo di scrittura.
16.4 CELLA DI RAM DINAMICA (DRAM)
Allo scopo di ottenere memorie particolarmente dense si usa la tecnologia DRAM (Dynamic
Random Access Memory) in cui la cella e’ costituita sostanzialmente da un solo condensatore
(figura 16.5). Quando il condensatore è carico la cella assume il valore logico 1; viceversa
quando è scarico il valore logico è 0. Tuttavia, tali celle non possono mantenere il loro stato
per un tempo indefinito, ma solo per pochi millesecondi, per questo motivo sono chiamate
memorie RAM dinamiche. Il loro contenuto deve essere quindi periodicamente “rinfrescato”,
rigenerando così la carica intera del condensatore.
Cella D RAM a 1 transistor
word
line
T ransistor di passo
bit
Condensatore
Figura 16.5. Struttura della cella di DRAM
16.4.1 Funzionamento della cella a 1 transistor DRAM
Per poter memorizzare le informazioni in questa cella, il transistor di passo deve essere
aperto (tramite il controllo sulla word line), e deve essere applicata una tensione adeguata alla
linea di bit. Questa operazione provoca il caricamento del condensatore fino ad un
determinato valore.
Purtroppo, anche quando il transistor di passo si trova nello stato OFF, il condensatore tende
a scaricarsi. Questo è dovuto alla resistenza parassita del condensatore stesso e al fatto che
il transistor continua a condurre e a far circolare un piccolo quantitativo di corrente
(dell’ordine di pA), anche dopo essere stato disattivato.
Le informazioni memorizzate nella cella possono essere lette in modo corretto solo se vi si
accede prima che la carica del condensatore sia scesa sotto un valore prefissato.
16.5
Durante l’operazione di lettura, la linea di bit viene pre-caricata ad un valore pari a Vdd/2 e
viene attivato il transistor di passo. Un sense amplifier, collegato alla linea di bit, determina
se la carica del condensatore sia sopra o sotto il valore prefissato.
L’operazione di lettura distrugge il valore contenuto nella cella a cui si accede. Per mantenere
le informazioni memorizzate, la memoria DRAM comprende circuiti appositi che riscrivono il
valore appena letto. Quindi, tutte le celle collegate ad una determinata word line vengono
rinfrescate ogni volta che la word line viene attivata.
16.4.2 Organizzazione logica di memoria DRAM a 4 Mbit
Nella figura 16.6 possiamo osservare lo schema dell’organizzazione logica di una memoria
DRAM a 4Mbit. Le celle di memoria sono organizzate in una griglia bidimensionale. Per
individuare una determinata cella si utilizzano due segnali: l’indirizzo di riga, RAS_L (Row
Address Strobe) e l’indirizzo di colonna CAS_L (Column Address Strobe). Come già visto, il
circuito di precarica accumula la carica per poi indirizzarla alle celle. I circuiti Row Decoder e
Column Decoder permettono di ridurre la complessità (e le dimensioni) di una DRAM. Infatti,
invece di usare un decoder con dimensione 22, (2²²=4194304), si usano due decoder con
dimensione 11, (2¹¹x2=4096). I Row Latches e Column Latches mantengono l’indirizzo.
A0…A10
e dopo…
A11…A21
R
o
w
11
L
a
t
c
h
e
s
Precharge circuit
R
o
w
11
11
D
e
c
o
d
e
r
C
o
l.
Storage Cell
Memory Array
(2048 x 2048)
DQ
Sense Amp. & I/O Circuits
Data
IN
L
a
t
c
h
e
s
word line
Data
OUT
C
T
R
L
bit line
RAS_L
CAS_L
WE_L
Column Decoder
11
Figura 16.6. Schema dell’organizzazione logica DRAM
16.4.3 Diagramma Logico della DRAM
Le memorie SRAM possiedono una interfaccia logica leggermente diversa da quella delle
DRAM, come si può vedere dalla figura 16.7. I pin A servono per specificare sia gli indirizzi di
riga che quelli di colonna. Se RAS_L va basso, i latch di riga memorizzano i pin A. Se invece
CAS_L va basso, i latch di colonna memorizzano i pin A.
16.6
RAS_L
WE_L
CAS_L
A
OE_L
256K x 8
DRAM
9
DQ
8
Figura 16.7. Interfaccia logica di un chip di DRAM
Analogamente alle SRAM, i segnali Din e Dout passano attraverso un multiplexer e vanno a
formare un unico segnale DQ. Come già visto per la SRAM, il segnale OE_L viene utilizzato
per controllare i buffer tri-state.
Se WE_L è attivo e OE_L è disattivo viene abilitato il processo di scrittura, e si assume il
segnale DQ come ingresso. Se invece WE_L è disattivo e OE_L è attivo viene abilitato il
processo di lettura, e DQ è un’uscita (Tabella 16.3).
Tabella 16.3: Controllo del bus dati DRAM
WE_L
Basso
Alto
OE_L
Alto
Basso
Significato
DQ è un ingresso
DQ è una uscita
16.4.4 Ciclo di scrittura DRAM
Nelle memorie DRAM il ciclo di scrittura viene controllato principalmente dai segnali CAS_L,
RAS_L e WE_L.
Write Cycle Time
RAS_L
CAS_L
A
Row Address
Col Address
Junk
Data In
Junk
Row Address
Col Address
Junk
OE_L
WE_L
DQ
Junk
Data In
Write Access Time
Junk
Write Access Time
Early Write Cycle: WE_L attivato prima di CAS_L
Late Write Cycle: WE_L attivato dopo CAS_L
Figura 16.8. Ciclo di scrittura DRAM
L’operazione di scrittura inizia asserendo RAS_L ed inviando sui pin A i bit piu’ significativi
dell’indirizzo (indirizzo di riga). Trascorso un certo lasso di tempo, si pongono sui pin A i bit
meno significativi dell’indirizzo (indirizzo di colonna) e si asserisce il segnale CAS_L, da
questo istante in poi ha inizio la scrittura (Write Access Time). Dopo poco, il ciclo di scrittura
è terminato e un altro ciclo può iniziare. Il tempo di accesso in scrittura (Write Access Time)
è definito come l’intervallo di tempo fra l’attivazione di RAS_L e la disattivazione di RAS_L (e
CAS_L).
16.7
Se il segnale WE_L viene attivato prima di CAS_L, si avrà un ciclo di scrittura anticipata
(Early Write Cycle), mentre se viene attivato dopo CAS_L si avrà un ciclo di scrittura
ritardata (Late Write Cycle). Una scrittura puo’ essere seguita da una nuova operazione
(lettura o scrittura) dopo che sia trascorso un tempo il tempo Write Cycle Time dall’inizio
della scrittura precedente.
16.4.5 Ciclo di lettura DRAM
La figura 16.9 mostra la temporizzazione di un ciclo di lettura di una memoria DRAM. La
procedura per il caricamento degli indirizzi è la medesima di quella usata per la scrittura.
Dopo il tempo Read Cycle Time si può effettuare un altro ciclo di lettura.
Come si può osservare dalla figura 16.9, il tempo di accesso al ciclo di lettura (Read Access
Time) termina quando sia RAS_L e CAS_L vengono disattivati. A seconda che OE_L sia
attivato prima o dopo CAS_L si avrà rispettivamente un Early Read Cycle o un Late Read
Cycle.
Read Cycle Time
RAS_L
CAS_L
A
Row Address
Col Address
Junk
Row Address
Col Address
Junk
WE_L
OE_L
DQ
High Z
Junk
Read Access
Time
Data Out
High Z
Output Enable
Delay
Early Read Cycle: OE_L attivato prima CAS_L
Data Out
Late Read Cycle: OE_L attivato dopo CAS_L
Figura 16.9. Ciclo di lettura DRAM
16.4.6 Tempi di accesso DRAM; trc,trac,tcac e tpc
Come già visto in precedenza, trc (Read Cycle Time) è il tempo minimo fra due accessi alle
righe. Questo dipende dal segnale RAS_L; infatti inizia con il primo fronte in discesa di
quest’ultimo e termina con il successivo fronte in discesa (figura 16.10). Per una DRAM a 4
Mbit, trc tipicamente ha un valore ad esempio di110 ns (considerando le tecnologie del 2004).
16.8
tRC = Read Cycle Time
RAS_L
CAS_L
A
Row Address
Col Address
Junk
Row Address
Col Address
Junk
WE_L
OE_L
DQ
High Z
Junk
Data Out
High Z
Output Enable
Delay
tCAC = Read
Access Time from CAS
Data Out
tRAC = Read
Access Tim e from RAS
Figura 16.10. DRAM: Temporizzazione
I tempi trac e tcac sono chiamati rispettivamente Access Time from RAS e Access Time from
CAS e dipendono rispettivamente dai segnali RAS_L e CAS_L. Il tempo trac ha inizio dal
fronte in discesa di RAS_L, e termina al fronte in discesa di DQ, cioè quando i dati sono
validi, mentre tcac inizia dal fronte in discesa di CAS_L, cioè quando anche l’indirizzo sono
validi. La velocità della DRAM normalmente è definita da trac . Con le attuali tecnologie si ha
ad esempio trc=110ns e trac=60ns.
La figura 16.11 illustra il “Page Cycle Time”. Il Page Cycle Time è il tempo che trascorre
dall’inizio dell’accesso ad una colonna e l’inizio dell’accesso alla colonna successiva.
tPC = Page Cycle time
RAS_L
CAS_L
A
Row Address
Col Address
Junk
Row Address
Col Address
Junk
WE_L
OE_L
DQ
High Z
Junk
Data Out
High Z
Output Enable
Delay
Figura 16.11. DRAM: Page Cycle Time
16.9
Data Out
Il tpc (Page Cycle Time) ha inizio dal primo fronte in discesa di CAS_L e termina al successivo
fronte in discesa di RAS_L. In una DRAM a 4Mbit con trac equivalente a 60 ns, si ha un un
“Page Cycle Time” equivalente tpc=60 ns (con le tecnologie attuali).
Una DRAM con trac=60 ns effettua un accesso a righe distinte ogni 110 ns (trc) ed accede ad
una colonna in 15 ns (tcac). E’ necessario però considerare anche il tempo tpc, cioè il tempo
minimo tra due accessi ad una colonna, che puo’ essere circa 35 ns; inoltre si deve tenere
conto anche dei ritardi di indirizzamento esterni, ovvero il tempo necessario per inviare
l’indirizzo all’esterno del microprocessore, e dei tempi di “turnaround” sul bus che fanno
aumentare tpc a 40-50 ns.
Nel calcolo del tempo di latenza, se si tiene conto del ritardo introdotto dal controller della
memoria, o di fattori come il pilotaggio dei chip di DRAM, del controller esterno,bus modulo
SIMM e numero dei pin da pilotare, per una DRAM con trac=60 ns si può arrivare ad un tempo
di 180-250 ns4.
16.4.7 Terminologia delle DRAM
Le DRAM possono essere catalogate in base alla loro capacità, al costo per bit, alla banda e al
tempo di latenza. Nella tabella 16.4 è illustrato un parallelo fra le metriche delle DRAM e
quelle dei microprocessori. Il trend di sviluppo (fino ad oggi) delle memorie DRAM è
caratterizzato da un aumento della capacità del 60% ogni anno, una diminuzione del costo per
bit del 25%, un incremento della banda del 20% ed una riduzione della latenza del 7%, sempre
per anno. Con maggiore dettaglio e’ riportata in tabella 16.5 la situazione di evoluzione
tecnologica delle DRAM nel corso degli anni.
Tabella 16.4. Terminologia DRAM
Standard
Parametri di merito
Tassi di variazione
per anno
4
DRAM
Pinout, package, refresh rate,
capacita’
1) capacita’
2) costo per bit
3) banda
4) latenza
1) +60%
2) -25%
3) +20%
4) -7%
I tempi considerati sono riferiti alle tecnologie del 2004
16.10
microprocessori
Compatibilita’ binaria,
IEEE 754,
bus di I/O
1) quanti SPEC
2) costo
1) +60%
2) circa costante
Tabella 16.5. Evoluzione delle DRAM nel tempo
Primi esemplari
‘84
‘87
‘90
‘93
‘96
‘99
Capacita’ (x 1bit)
1 Mb
4 Mb
16 Mb
64 Mb
256 Mb
1 Gb
Area chip (mm2)
55
85
130
200
300
450
Area Memoria (mm2)
30
47
72
110
165
250
22.84
11.1
4.26
1.64
0.61
0.23
Area Cella di memoria (µm2)
(da Kazuhiro Sakashita, Mitsubishi)
16.5 CONSIDERAZIONI DI RIEPILOGO SULLE RAM
Le memorie DRAM (Dynamic Random Access Memory) hanno prestazioni più basse, ma hanno
costi inferiori e capacità maggiori rispetto alle memorie SRAM. Per questi motivi le DRAM
vengono tipicamente utilizzate per realizzare la memoria principale di un calcolatore.
Le memorie SRAM (Static Random Access Memory) hanno prestazioni elevate, ma anche un
alto livello di mercato (più costose), inoltre hanno una capacità ridotta e dissipano 5 volte più
energia rispetto alle memorie DRAM. In conclusione le SRAM dovrebbero essere utilizzate
con attenzione, ovvero solo nel caso in cui risulta essere molto importante il tempo di accesso
ai dati.
16.6 TECNICHE
MEMORIA
PER
MIGLIORARE
LE
PRESTAZIONI
DELLA
16.6.1 Bus Semplice (Organizzazione diretta)
CPU
MEM
Figura 16.12. Schema a Bus semplice
La figura 16.12 mostra la più semplice organizzazione (Organizzazione diretta o “Bus
semplice”) del sottosistema di memoria. In questo schema, CPU, cache, memoria e BUS hanno
tutti lo stesso parallelismo ovvero il bus ha una larghezza fissa di 32 bit (cioè la dimensione di
una word).
16.11
16.6.2 Bus Largo (Organizzazione estesa)
CPU
MUX
MEM
Figura 16.13. Schema a Bus largo
La figura 16.13 mostra un’opzione per aumentare la larghezza di banda verso la memoria che si
basa sull’ampliamento della memoria e del bus tra il processore e la memoria. Tale situazione
permette l’accesso in parallelo a tutte le parole di un blocco. La logica tra la cache e la cpu
consta di un multiplexer (MUX) usato per le letture e di una logica di controllo per aggiornare
le parole opportune della cache durante le operazioni di scrittura. Il bus fra CPU e cache
conserva sempre una larghezza di banda di 1 word ma il parallelismo avviene tra gli altri
componenti dove è possibile lo scambio di N word in parallelo.
L’aumentare dell’ampiezza della memoria e del bus fa aumentare proporzionalmente la
larghezza di banda, riducendo la latenza associata in caso agli accessi. I principali costi
associati a questo miglioramento sono il bus più ampio ed il possibile aumento nel tempo di
accesso dovuto al multiplexer ed alla logica di controllo tra la cpu e memoria.
16.6.3 Interleaving
CPU
MEM
BANK
0
MEM
BANK
1
MEM
BANK
2
MEM
BANK
3
Figura 16.14: Schema Interleaving
La figura 16.14 mostra un bus che non presenta nessun tipo di parallelismo (larghezza pari ad 1
word), ma una memoria con interleaving. Questa soluzione consente di aumentare la larghezza
di banda ampliando la larghezza della memoria, ma non quella del bus di interconnessione. La
memoria e’ organizzata in banchi sui quali si possono distribuire in maniera opportuna gli
accessi. Per illustrare il funzionamento in caso di interleaving ricordiamo che in generale,
quando si fa accesso ad una memoria si possono individuare:
16.12
Cycle Time - Tempo di Ciclo della DRAM (Read/Write): rappresenta il periodo di
tempo tra un accesso e l’altro, ovvero indica la frequenza con cui si possono fare
accessi in memoria (figura 16.15).
•
Access Time - Il Tempo di Accesso della DRAM (Read/Write): rappresenta il
tempo necessario alla memoria per accedere alla cella indirizzata, ovvero quanto tempo
occorre per poter ottenere il dato richiesto rispetto alla fase iniziale dell’accesso.
Come si può notare il Cycle Time risulta essere notevolmente maggiore rispetto all’Access
Time, creando così problemi alle prestazioni della memoria.
•
Cycle Time
Access Time
Time
Figura 16.15. Tempo di Ciclo DRAM
In un modello senza interleaving (figura 16.16) l’inizio dell’accesso al dato D2 avviene solo alla
fine del tempo di ciclo della DRAM, attendendo un tempo inutile in cui il dato D1 è già pronto.
Senza interleaving:
CPU
Memory
Dato D1 disponibile
Inizio dell’accesso al dato D1
Inizio dell’accesso al dato D2
Figura 16.16. Metodo "Senza Interleaving"
Per rendere l’accesso in memoria più veloce, si adotta il modello con interleaving, in cui si inizia
un nuovo accesso, ma su un banco diverso, non appena e’ terminato il tempo di accesso.
Memory
Bank 0
4-way Interleaving:
Accesso al Banco 0
CPU
Accesso
al Banco 1
Memory
Bank 1
Memory
Bank 2
Memory
Bank 3
Accesso
al Banco 2 Accesso
al Banco 3 Posso di nuovo fare accesso al Banco 0
Figura 16.17. Metodo "4 - Way Interleaving”
Considerando il caso in cui la memoria sia divisa in 4 banchi (4-way Interleaving) si presenta
la situazione di figura 16.17: mentre la CPU finisce di usare il 1° banco di memoria, sta
simultaneamente usando gli altri tre banchi.
16.13
16.6.4 Confronto fra le tecniche
Confrontiamo le tre tecniche viste per valutare le differenza di prestazioni. Consideriamo
come blocco minimo di trasferimento 4 word ed il seguente modello dei tempi di accesso:
• 1 ciclo per inviare l’indirizzo,
• 6 cicli per accedere al data,
• 1 ciclo per ricevere il data.
I tempi per il trasferimento del blocco minimo considerato (4 word) sono:
• “Bus Semplice” : 32 cicli.
n° words x
(n° cicli per inviare l’indirizzo +
n° cicli per accedere al data +
n° cicli per ricevere il data) =
=4 x (1+6+1) = 32 cicli.
•
“Bus Largo” : 8 cicli.
(n° cicli per inviare l’indirizzo +
n° cicli per accedere al data +
n° cicli per ricevere il data) =
=(1 + 6 + 1) = 8
• 4-way interleaving: 11 cicli.
n° cicli per inviare l’indirizzo +
n° cicli per accedere al data +
n° cicli per ricevere il data x n° words =
=1 + 6 + 1 x 4 = 11.
Per ottimizzare la struttura del modello “interleaving” dovrebbe essere scelto un numero di
banchi di memoria pari al numero di periodi di clock per accedere ad una word di un banco; in
questo modo si otterrebbe una word ad ogni ciclo di clock. Il problema per cui cio’ non e’
sempre attuabile (ad es. nei PC) e’ il fatto che il numero di banchi di cui si dispone tende a
diminuire perche’ da un lato le capacita’ dei chip aumentano e dall’altro la memoria totale
necessaria tende ad essere relativamente minore (Tabella 16.6). Nelle attuali DRAM lo
sfruttamento dell’interleaving e’ trasferito all’interno dei chip di memoria (v. Cap. 16.7)
16.14
Tabella 16.6: Evoluzione DRAM
4 MB
‘86
1 Mb
‘89
4 Mb
32
8
Memoria tipica di un PC
8 MB
16 MB
16
‘92
‘96
‘99
‘02
16 Mb 64 Mb 256 Mb 1 Gb
4
8
2
32 MB
4
1
64 MB
8
2
128 MB
4
1
256 MB
8
2
(da Pete MacWilliams, Intel)
16.6.5 Prestazioni del sottosistema di memoria
Per analizzare le prestazioni del sottosistema di memoria dobbiamo innanzitutto stabilire un
parametro di misurazione. Una scelta possibile e’:
PMEM =
1
t RC
Se consideriamo il caso di una DRAM con tRAC = 50ns, e tRC = 84ns, si ottiene:
1
PMEM =
≅ 12MB / s .
84 ⋅ 10 −9
Nel caso invece della EDO DRAM, assumendo per il primo accesso 50ns, ma per quelli
1
successivi 30ns, si ottiene PMEM =
≅ 33MB / s .
30 ⋅ 10 −9
16.15
16.7 DRAM SINCRONE
16.7.1 SDRAM (Synchronous DRAM)
Le SDRAM sono la naturale evoluzione delle EDO DRAM. Hanno dei segnali in più rispetto alle
DRAM: CLK(clock), che da la temporizzazione, il CKE (clock enable) che decide se attivare o
meno il segnale di clock,il DQM (DQ mask) che agisce su DQ principalmente come un Output
Enable, il BA (bank address) che regola gli accessi ai banchi interni (per maggiori dettagli si
veda ad es. [5]) Inoltre il clock abilita il pipelining nel datapath fra gli array interni e DQ.
Nelle SDRAM sono presenti banchi interni che si possono selezionare dall’esterno. Il primo
accesso ha una latenza di 1-3 cicli, ma gli accessi sequenziali consentono di ottenere i dati ad
ogni ciclo di clock, sfruttando una sorta di interleaving interno al chip.
Considerando una latenza media di 2 cicli, per una SDRAM a 100MHz, si ottiene:
PMEM =
100MHz
≅ 50Mb / s .
2
16.7.2 DDR (Double Data Rate) SDRAM
Sono la naturale evoluzione delle SDRAM. L’output ha luogo su entrambi i fronti del clock,
consentendo quindi di raddoppiare la banda di uscita. Anche qui si hanno segnali in più rispetto
alle SDRAM: si ha il CLK#(clock complementare) che permette di ricevere i dati anche sul
fronte in discesa, BA[1…0] (indirizzo di banco su due bit), VDDx8, VSSx8. Sono presenti 4
banchi interni indipendenti. Per fornire più banda interna si usa un datapath interno più largo.
(per maggiori dettagli si veda ad es. [6]) Con un clock esterno a 100MHz si ha un clock interno
a 143MHz. Altri piccoli accorgimenti interni consentono di operare a frequenze così alte.
Per una DDR SDRAM a 100MHz si ottiene come prestazione massima:
PMEM = 286 MB / s (143 × 2) .
16.7.3 SLDRAM (Sync-Lynk DRAM)
Sono una combinazione tra le memorie SDRAM e quelle DDR SDRAM, in modo da ottenere
attraverso, l’aggiunta di un protocollo a pacchetti command/address/control, le prestazioni di
picco PMEM = 400 Mb / s a 400MHz. I segnali esterni hanno caratteristiche totalmente diverse
da quelle delle DRAM.
16.7.4 DRDRAM (Direct RDRAM Rambus)
Queste memorie presentano una configurazione simile alle SLDRAM per quanto riguarda il
protocollo a pacchetti, ma la sua struttura concettuale risulta essere molto diversa dalle
DRAM. Le prestazioni di picco PMEM = 400 Mb / s a 400MHz.
16.7.5 SIMM (Single In-line Memory Module)
Sono state il primo tentativo di fornire uno standard per raggruppare chip di memoria.
Inizialmente furono prodotte con 30 pin, in seguito fu estesa a 72 pin, in modo da consentire
un bus dati fino a 32 bit.
16.7.6 DIMM (Dual In-line Memory Module)
Hanno 168 pin disposti su una schedina su cui sono collocati i chip di memoria,
caratterizzata da un bus dati da 64 bit; i moduli DIMM stanno sostituendo i moduli SIMM
(Single In-Line Memory Module), nei quali il bus dati è da 32 bit. Nei moduli SIMM (72 pin), i
contatti opposti, sulle 2 facce della scheda, sono uniti e formano un contatto unico; nei DIMM
16.16
(168 pin), i contatti opposti sono elettricamente isolati e formano due contatti separati. Negli
standard successivi (2004) i moduli DIMM hanno 184 pin.
16.7.7 RIMM(marchio del consorzio Rambus)
Questo standard prevede una larghezza di bus di 32bit e ha lo stesso connettore delle DIMM
a 100MHz standard. Questo standard non ha avuto molto successo.
16.10 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] V. Hamacher, G. Vranesic, G. Zaky, “INTRODUZIONE ALL’ARCHITETTURA DEI CALCOLATORI”
McGraw-Hill 1997.
[3] G. Bucci, "Architettura dei Calcolatori Elettronici", McGraw-Hill, 2001, ISBN 88-386-0889-X.
[4] P. Corsini “DALLE PORTE AND OR NOT AL SISTEMA CALCOLATORE” Edizioni ETS 2000
[5] SITO JEDEC: http://www.jedec.org/download/search/4_20_02R13.PDF
[6] SITO JEDEC: http://www.jedec.org/download/search/JESD79E.pdf
16.17
LEZIONE 17
Introduzione alla memoria cache (parte prima)
17.1 INTRODUZIONE
Le cinque componenti classiche di un calcolatore sono l’unità d’ingresso, l’unità di uscita, la
memoria, l’unità di elaborazione e l’unità di controllo.
La figura 17.1 mostra l’organizzazione tipica di un calcolatore, la quale è indipendente dalla
tecnologia hardware utilizzata. In questo capitolo analizzeremo le unità di memoria.
Processore
Input
Parte di
Controllo
Memoria
Memoria
Parte
Datapath
Output
Figura 17.1 Struttura di un Calcolatore.
Esistono almeno due tipi di memoria: la memoria principale e la CACHE.
La memoria principale è tipicamente una memoria ampia ma lenta, mentre la memoria CACHE è
una memoria più piccola e più veloce. Come visto nel Capitolo 16, anche i costi sono diversi.
17.1.1 Principio di localita’ dei programmi
Questo principio sta alla base del modo in cui funzionano i programmi, e dice che in un dato
istante di tempo i programmi fanno accesso ad una porzione relativamente piccola del loro
spazio di indirizzamento. Ovvero un programma ad un certo istante non ha la necessità di
accedere a tutto il suo codice ed a tutti i suoi dati con uguale probabilità.
Il principio di località viene sfruttato implementando la memoria di un calcolatore sotto forma
di gerarchie di memoria.
I principali tipi di località individuabili in un programma sono:
- la Località Temporale
- la Località Spaziale
17.1.1.1 Localita’ temporale
E’ probabile che un oggetto a cui il programma ha fatto riferimento venga nuovamente
richiesto in tempi brevi.
Per esempio molti programmi contengono dei cicli, per cui le istruzioni ed i dati saranno
probabilmente richiesti ripetutamente, portando ad un buon grado di località temporale.
17.1.1.2 Localita’ spaziale
E’ probabile che gli oggetti che si trovano vicino ad un oggetto a cui il programma ha fatto
riferimento vengano richiesti in tempi brevi.
Per esempio, poiché durante l’esecuzione di un programma le istruzioni sono normalmente
richieste in modo sequenziale, i programmi hanno un’elevata località spaziale.
17.1
17.1.2 Gerarchia di memoria
Conseguenza del principio di località è che risulta vantaggioso organizzare la memoria secondo
una gerarchia.
La gerarchia di memoria trae vantaggio dalla località temporale mantenendo i dati a cui si è
fatto accesso di recente in posizioni più vicine alla CPU, e dalla località spaziale spostando
verso i livelli superiori della gerarchia blocchi composti da molte parole consecutive.
CPU
Livelli della
Gerarchia
di Memoria
Livello 1
Livello 2
Tempo di Accesso
(distanza dal
processore)
Livello N
Dimensione della Memoria a ciascun livello
Figura 17.2 Struttura generale della gerarchia di memoria.
Come mostrato in figura 17.2, una gerarchia di memoria usa memorie più piccole e di
tecnologia più veloce vicino al processore.
Se i dati richiesti dal processore compaiono in qualche blocco nel livello superiore, si dice che
si è verificato un successo nell’accesso (ovvero hit) e vengono quindi elaborati velocemente. Se
il dato non è presente ai livelli superiori, la richiesta viene classificata come fallimento
nell’accesso (ovvero miss) e si deve ricorrere ai livelli inferiori nella gerarchia per recuperare
il blocco contenente il dato richiesto, tali livelli sono più capienti ma più lenti.
Il caso migliore si ha quando la frequenza di hit (hit rate) è sufficientemente elevata, in tal
caso la gerarchia di memoria ha complessivamente un tempo di accesso effettivo vicino a
quello del livello più alto (quindi la più veloce) ed una capacità vicina a quella del livello più
basso (quindi la più capiente).
A partire da queste differenze è vantaggioso costruire il sottosistema di memoria come una
gerarchia di livelli, con la memoria più veloce vicina alla CPU e quella più lenta e meno costosa
ai livelli inferiori, come mostrato in figura 17.3.
17.2
Velocità
Più veloce
CPU
Memoria
CACHE
Capacità
Costo
Più piccola
Più alto
Più grande
Più basso
Memoria
RAM
Più lenta
Dischi Magnetici
Figura 17.3 Struttura fondamentale della gerarchia delle memorie.
La gerarchia di memoria può consistere di più livelli, ma in ogni istante di tempo i dati sono
copiati solamente tra ciascuna coppia di livelli adiacenti. Per cui per analizzare il
comportamento del passaggio dei dati tra i vari livelli è conveniente concentrarsi solo su due
di essi.
Attualmente vi sono tre tecnologie principali per la costruzione della gerarchia di memoria: la
prima è l’utilizzo delle DRAM (Dynamic Random Access Memory) nella realizzazione della
memoria principale, la seconda è l’utilizzo delle SRAM (Static Random Access Memory) nella
realizzazione delle CACHE e la terza tecnologia è utilizzata per implementare il livello più
capiente e più lento della gerarchia, ovvero i dischi magnetici.
Il tempo di accesso ed il costo per bit cambiano notevolmente tra queste tre tecnologie.
La DRAM ha un costo per bit inferiore alla SRAM, ma d’altra parte risulta essere più lenta.
I dischi magnetici, a loro volta, hanno un costo per bit inferiore alle prime due tecnologie, ma
il loro tempo d’accesso è di gran lunga più elevato.
Come si evince dalla figura 17.3, il livello superiore è più piccolo e veloce (poiché usa una
tecnologia più costosa) rispetto a quello inferiore. Ad un certo istante il nome dell’entità di
informazione considerata è chiamata blocco o pagina.
Il blocco è costituito da un insieme di indirizzi di memoria adiacenti, la cui dimensione è
dipendente dalla tecnologia scelta dal costruttore dell’hardware.
17.2 FONDAMENTI SULLE CACHE
Il termine CACHE è stato usato per la prima volta per indicare il livello della gerarchia tra la
CPU e la memoria principale nel primo calcolatore commerciale dotato di tale livello [1]. Esso
indica anche qualsiasi tipo di gestione della memoria che trae vantaggio dalla località degli
accessi.
17.3
17.2.1 Funzionamento di una cache
Esamineremo una CACHE semplificata in cui la CPU richiede una parola per volta e ciascun
blocco contiene una sola parola. In figura 17.4 è mostrata una CACHE di questo tipo prima e
dopo la richiesta di un dato, inizialmente non presente nella CACHE stessa.
Prima del riferimento a Xn
Dopo il riferimento a Xn
X4
X1
Xn-2
X4
X1
Xn-2
Xn-1
X2
Xn-1
X2
Xn
X3
X3
Figura 17.4 CACHE prima e dopo il riferimento ad una parola Xn inizialmente non presente.
Inizialmente la CACHE contiene un insieme di dati richiesti di recente (X1, X2, …, Xn-1).
Ad un certo punto il processore richiede la parola Xn non presente nella CACHE: questo è un
classico esempio di miss e la parola Xn viene quindi trasferita dal livello di gerarchia di
memoria sottostante alla CACHE, ovvero, basandoci sulla struttura della gerarchia vista nella
figura 17.3, si ha un trasferimento da un livello inferiore ad uno superiore.
17.2.1.1 Posizionamento dei dati nella cache
Il modo più semplice per associare una posizione della CACHE a ciascuna parola di memoria è
di determinare la posizione della CACHE sulla base dell’indirizzo della parola in memoria. Tali
CACHE sono dette a corrispondenza diretta, poiché a ciascun blocco di memoria corrisponde
esattamente una posizione nella CACHE.
Come esempio la figura 17.5 mostra una CACHE a corrispondenza diretta di otto elementi e
con blocchi di dimensione esattamente pari ad una parola.
Si possono notare le corrispondenze tra gli indirizzi di memoria compresi tra 00001due (1dieci) e
11101due (29dieci) e le posizioni 001due (1dieci) e 101due (5dieci) nella CACHE.
Poiché a ciascuna locazione nella CACHE corrispondono più indirizzi (ad esempio alla posizione
001 corrispondono i quattro indirizzi della memoria che terminano proprio con 001), per poter
riconoscere a quale degli indirizzi possibili di memoria corrisponde l’indirizzo di CACHE
cercato, si aggiunge un tag, che indicheremo notazionalmente con T, nell’indirizzo di CACHE,
contenente esattamente i bit dell’indirizzo di memoria non deducibili dall’indirizzo di CACHE.
17.4
000
001
010
011
100
101
110
111
Cache
Memoria
00001
00101
01001
01101
10001
10101
11001
11101
Figura 17.5 Cache a corrispondenza diretta di otto elementi.
17.2.2 Definizioni generali sulle cache
Esistono anche CACHE con più blocchi memorizzati allo stesso indirizzo di CACHE dette
CACHE associative (verrano esaminate nel capitolo successivo). In tal caso il numero di blocchi
appartenenti allo stesso indirizzo è detto:
A = “grado di Associatività” della CACHE o “numero di vie”, con A є {1,2, …, Amax}
Inoltre definiamo:
B = dimensione del blocco di CACHE in byte
C = capacità della CACHE in byte
Tipicamente, ma non necessariamente B, C sono una potenza di 2. In tal caso:
B = 2b con b є {1,2, …, bmax}
C = 2c con c є {1,2, …, cmax}
e sussistono le seguenti relazioni:
NC = C / B = 2c-b Æ Numero di blocchi della CACHE
NS = C / (A*B) = 2c-(a+b) Æ Numero di indirizzi disponibili nella CACHE (Numero di SET)
NM = M / B = 2m-b Æ Numero di blocchi della Memoria
dove M è la dimensione della memoria in byte e m = log2(M).
Nel caso di CACHE ad accesso diretto si ha A pari ad 1 e quindi NS = NC.
Bit di validita’
E’ necessario anche un meccanismo per il riconoscimento dei blocchi della CACHE che non
contengono informazioni valide, come ad esempio accade all’accensione del sistema. Il valore
del tag di tali blocchi deve essere ignorato, perché privo di significato. Il metodo più comune
è quello di aggiungere un bit di validità (bit V) per indicare se una cella della CACHE contiene
un indirizzo valido. Se il bit non vale 1, il blocco non viene considerato corrispondente ad alcun
indirizzo. Quando il blocco viene caricato in CACHE viene posto a 1 il bit di validità.
17.5
17.2.3 FORMALIZZAZIONE DEL FUNZIONAMENTO DELLA CACHE
Siano:
XM = l’indirizzo di un blocco di memoria
XS = l’indirizzo di un blocco di CACHE
Definiamo inoltre (usando una sintassi C-like) le varie informazioni che troveremo all’indirizzo
di cache XS:
D = contenuto del blocco memorizzato in CACHE = XS->D = YD
T = tag del blocco memorizzato in CACHE = XS->T= YT
V = bit di validità del blocco memorizzato in CACHE = XS->V= YV
Supponiamo per il momento, per semplicita’, di fare soltanto accessi in lettura per prelevare
informazioni. La cache, oltre a fornire la memoria i blocchi (D), i tag (T), e i bit ausiliari (quali
il bit V) dovra’ fornire un meccanismo per leggere il blocco in cache in maniera simile alla
funzione FM(XM) che consente leggere il blocco dalla memoria. Tale meccanismo dovra’ essere
quasi sempre piu’ veloce a fornire il dato rispetto ad un accesso in memoria; chiameremo tale
funzione:
• FC Funzione di prelievo del dato in Cache
La funzione FC permette di ottenere il contenuto del blocco richiesto (D) una volta specificato
un determinato indirizzo di memoria (XM). Mentre sappiamo che FM: MEM[.] ovvero per
ottenere D dall’array di memoria MEM basta indicizzare tale array con l’indirizzo XM, per
esplicitare FC occorre introdurre altre tre funzioni: FT per generare il tag a partire da XM, FS
per ricavare il potenziale indirizzo del blocco di cache a partire XM ed infine una funzione FH
che permetta di sapere se un blocco è presente in CACHE o meno, cioè che verifichi se sia
avvenuto un hit od un miss. Quindi:
• FT Funzione di generazione del tag
La funzione FT a partire dall’indirizzo del blocco di CACHE XM genera XT:
XT = FT(XM)
• FS Funzione di piazzamento del blocco
La funzione FS a partire dall’indirizzo del blocco di CACHE XM genera XS:
XS = FS(XM)
• FH Funzione di Hit
La funzione FH a partire da XT, T (ovvero XS->T) e V (ovvero XS->V) fornisce hit (1) o miss (0):
FH = (XT == T && V == 1 ? 1 : 0)
Una volta stabilito che il dato e’ in cache risulta possibile prelevarlo, quindi:
FC : (FH == 1 ? D : ‘----’)
Chiaramente FC = FC(XM) infatti, con le debite sostituzioni si ricava:
FC : ((FT (XM) == FS(XM)->T && FS(XM)->V == 1 ? 1 : 0) == 1 ? FS(XM)->D : ‘----’)
Nel caso delle cache fino a qui esaminate (ad accesso diretto) si ha:
FS: (mod NS) ovvero
FS (XM) = XM mod NS
17.6
FT: (div NS)
ovvero
FT (XM) = XM div NS
Nel capitolo successivo vedremo come generalizzare le funzioni FC ,FS, FT, FH al caso di cache
con piu’ vie.
17.2.2.1 Esempio1
Analizzando la CACHE di figura 17.6, ovvero una CACHE ad accesso diretto con A = 1, B = 4
byte, C = 4 Kbyte, M = 4 Gbyte e dove X è l’indirizzo al byte, si possono calcolare gli indirizzi
del blocco di memoria DRAM (XM ), del blocco di CACHE (XS) e del tag (XT) sfruttando le relazioni
ricavate nei paragrafi precedenti. Si ha infatti:
XM = X / B = X / 22
XT = XM / NC = XM / (C / B) = XM / 210
XS = XM mod NS = XM mod C / B = XM mod 210
XM
13 12 1 1
31 30
210
X
Byte
offset
Tag
10
20
=XT
Index =X
S
Index Valid Tag
Data
0
1
2
1021
1022
1023
V
T
FH
Hit
20
D
32
Data
Figura 17.6 Schema logico di una CACHE ad accesso diretto.
17.2.4 Esempio2: cache a cui e’ presentata una sequenza di indirizzi
Prendiamo in esame una CACHE ad accesso diretto con: A=1, B=4, C=32. Descriviamo
sinteticamente il funzionamento, in tabella 17.1, in seguito ad una serie di richieste da parte
del processore. Si sa inoltre che:
XT = XM / NS = XM / (C / (A * B)) = XM * (A * B) / C = XM * 4 / 32
17.7
Tabella 17.1 Azione intrapresa in seguito a ciascun accesso alla memoria.
(XM)dieci
(XM)due
XT
XS
FH
22
26
22
26
16
3
16
18
10110
11010
10110
11010
10000
00011
10000
10010
10
11
10
11
10
00
10
10
110
010
110
010
000
011
000
010
0 (MISS)
0 (MISS)
1 (HIT)
1 (HIT)
0 (MISS)
0 (MISS)
1 (HIT)
0 (MISS)
Quando la parola di indirizzo 18 (10010) è portata nel blocco 2 (010) della CACHE, la parola
dell’indirizzo 26 (11010), che si trovava nel blocco 2 (010), deve essere sostituita dai dati
appena richiesti. Questo comportamento permette alla CACHE di trarre beneficio dalla
località temporale, infatti le parole richieste più di recente sostituiscono quelle a cui si è
fatto riferimento meno di recente. In una CACHE ad accesso diretto esiste un solo posto in
cui porre il dato appena richiesto, perciò vi è una sola possibile scelta a riguardo di che cosa
debba essere sostituito. Nel caso di una CACHE associativa esistono A possibili posti liberi in
cui rimpiazzare il blocco richiesto (vedi capitolo 18).
Il numero totale dei bit richiesti per una CACHE è funzione della sua dimensione e della
lunghezza degli indirizzi della memoria.
Nell’architettura MIPS abbiamo indirizzi a 32 bit, quindi una CACHE ad accesso diretto di
capacità pari a 2n word e con blocchi di una word (4 byte) richiederà un tag di ampiezza pari a
32 – (n + 2) bit, poiché 2 bit sono usati per l’offset del byte ed n bit per l’indice.
Il numero totale di bit in una CACHE ad accesso diretto è quindi:
2n x (dimensione blocco + dimensione tag + dimensione bit di validità)
Nel caso di architetture MIPS il numero di bit è pari a:
2n x (32 + (32 – n – 2) + 1) = 2n x (63 – n )
17.2.3 Come trarre beneficio dalla localita’ spaziale
Per poter trarre beneficio dalla località spaziale è necessario che i blocchi della CACHE siano
più ampi di una sola parola, contrariamente al tipo di CACHE considerata finora.
Quando si verifica un miss, si leggeranno quindi diverse parole adiacenti, che hanno un’elevata
probabilità di essere richieste a breve termine. Confrontando la figura 17.7, che riporta una
CACHE con 64 KB di dati organizzata in blocchi di quattro parole (16 Byte) ciascuno, con la
figura 17.6, che riporta una CACHE delle stesse dimensioni ma con blocchi di una sola parola,
notiamo che nella CACHE di figura 17.7 l’indirizzo ha un campo aggiuntivo per indicizzare il
blocco, detto Offset nel Blocco. Tale campo viene utilizzato per controllare il multiplexer
(MUX) che seleziona la parola richiesta tra le quattro del blocco prescelto. Il numero totale
di campi tag e di bit di validità è inferiore nella CACHE con blocchi di più parole, perché
ciascuno di essi viene usato per quattro parole. Per ricavare il blocco di CACHE relativo ad un
17.8
dato indirizzo si può utilizzare lo stesso metodo che si era utilizzato nella CACHE con blocchi
di una parola, ovvero si utilizzano FS e FT come nel caso di CACHE con blocchi di una sola
parola. L’indirizzo del blocco è l’indirizzo stesso espresso in byte diviso la dimensione del
blocco espressa in byte.
31
16 15
16
4 32 10
12
2 Byte
offset
Tag
Index
V
Block offset
16 bits
128 bits
Tag
Data
•A = 1
•B = 16 byte
•C = 64 Kbyte
•M = 4 Gbyte
X indirizzo al byte
XM = X / B
= X / 24
4K
entries
16
32
32
32
32
XT = XM / NS
= XM / (C / B)
= XM / 212
XS = XM mod NS
= XM mod C / B
= XM mod 212
Mux
32
Data
Hit
Figura 17.7 CACHE di 64 KB che utilizza blocchi di quattro parole (16 byte).
17.2.5 Il miss rate
Le condizioni di miss nel caso delle letture sono trattate allo stesso modo sia per CACHE con
blocchi di più parole che per CACHE con blocchi di una sola parola, infatti quando avviene un
miss si preleva sempre l’intero blocco. Mentre, durante le scritture, gli hit ed i miss devono
essere gestiti diversamente nei due casi. Questo perché, nelle CACHE con blocchi di più
parole, non è possibile scrivere all’interno di ogni singolo blocco solamente il tag ed il dato.
Per capirne il motivo, si ipotizzi che vi siano due indirizzi di memoria, X1 ed X2, entrambi
corrispondenti al blocco XS della CACHE, il quale sia un blocco di quattro parole che al
momento contiene X2. Si consideri ora una scrittura all’indirizzo X1 che sovrascriva
semplicemente il dato ed il tag all’interno del blocco XS: dopo la scrittura, il blocco XS avrà il
tag corrispondente ad X1, mai dati contenuti in XS corrisponderanno ad una parola di X1 ed a
tre parole di X2.
In generale la frequenza di miss si riduce all’aumentare della dimensione dei blocchi come si
evince dal grafico in figura 17.8, tuttavia la località spaziale tra le parole dello stesso blocco
si riduce all’aumentare della sua dimensione, per cui il miglioramento della frequenza di miss si
ridurrà sempre di più fino a che essa non tenderà ad aumentare.
Un ulteriore problema associato all’aumento della dimensione dei blocchi è l’aumento del costo
dei miss, infatti la penalità dovuta ad un miss è determinata dal tempo necessario a caricare il
blocco dal livello immediatamente inferiore nella gerarchia di memoria e scriverlo nella
CACHE. Questo tempo è composto da: la latenza per leggere la prima parola ed il tempo di
17.9
trasferimento per il resto del blocco. Se non si modifica il sottosistema di memoria il tempo
di trasferimento (quindi il costo di una miss) aumenta al crescere della dimensione del blocco.
Perciò l’aumento della penalità introdotta da una miss supera la riduzione della frequenza di
miss stessi quando i blocchi sono troppo grandi, riducendo di conseguenza le prestazioni della
CACHE.
Capacità
della
CACHE
40%
35%
30%
1 KB
8 KB
16 KB
64 KB
25%
256 KB
M
i
s
s
r
a
t
e
20%
15%
10%
5%
0%
4
16
64
256
Dimensione del blocco (byte)
Figura 17.8 Dipendenza del Miss rate dalla dimensione del blocco.
17.3 VALUTAZIONE DELLE PRESTAZIONI DELLE CACHE
Possiamo definire un tempo medio di accesso alla memoria come:
AMAT (Average Memory Access Time) = tH * h + tM * m
dove:
tH = tempo di hit, h = probabilità di avere un hit (hit rate)
tM = tempo di miss, m = probabilità di avere un miss (miss rate)
Estendendo i risultati del capitolo 4, non considereremo più una memoria perfetta, cioè che
risponde in un tempo tH, ma considereremo un tempo di penalty (tPENALTY), dovuto all’attesa dei
dati dalla memoria principale, che influirà sulla risposta della CPU. Quindi poiché:
tM = tH + tPENALTY
si ha:
AMAT = tH * h + (tH + tPENALTY) * m = tH * (h + m ) + tPENALTY * m = tH + tPENALTY * m
L’equazione delle prestazioni di una CPU (vedi capitolo 4) è nel caso ideale:
TCPU = CCPU x TC = NCPU x /CPIideale x TC
dove:
TCPU = tempo di esecuzione della CPU
17.10
CCPU = cicli di esecuzione della CPU
TC = periodo di clock
NCPU = numero di istruzioni dinamicamente eseguite dal processore
/CPIideale = cicli per istruzione medi nel caso ideale
Considerando il caso non ideale in cui, come detto precedentemente, non vi sia un passaggio
immediato dei dati dalla memoria alla CPU (caso reale), otterremo un CPIeffettivo (medio).
Definendo:
NREF = numero totale di riferimenti alla memoria
/RINST = (NREF / NCPU) = riferimenti medi per istruzione
CPEN = cicli di penalty della CPU
si ha:
/CPIstallo = /RINST x m x CPEN
/CPIeffettivo = /CPIideale + /CPIstallo
TCPU = NCPU x /CPIeffettivo x TC =
= NCPU x (/CPIideale + /CPIstallo) x TC =
= NCPU x (/CPIideale + (/RINST ) x m x CPEN)) x TC
Per comprendere il significato di /RINST, consideriamo il seguente codice MIPS:
ADD R1, R2, R3
LW R1, 0(R2)
genera 1 riferimento (alla memoria istruzioni)
genera 2 riferimenti (1 alla memoria istruzioni + 1 alla memoria dati)
Quindi NREF = 3 e conseguentemente: /RINST = (NREF / NCPU) = 3 / 2 = 1,5
Ciascuna classe di istruzioni genera un certo numero di riferimenti.
RINST,K = numero di riferimenti generati dalla classe K
•
•
RINST, LOAD = 2
RINST, ADD = 1
Quindi nel nostro esempio:
type
RINST =
∑
k =1
RINST,K = 1+2 = 3
17.3.1 Esempio di impatto sulle prestazioni
Supponiamo di avere un processore a 200 MHz (5 ns per ciclo) con:
/CPIideale = 1,1
50% aritmetico/logiche
30% load/store
20% control
17.11
Supponiamo che il 10% delle operazioni in memoria subisca miss con CPEN = 50 cicli di clock.
Sappiamo che:
/CPIeffettivo = /CPIideale + (/RINST x m x CPEN) = 1,1 + (0,30 * 0,10 * 50) = 1,1 + 1,5 = 2,6 cicli
Per il 58% (1,5 / 2,6) del tempo il processore attende la memoria. Un 1% di miss rate per le
istruzioni aggiunge 0,5 cicli al CPI (medio)effettivo. In tal caso la situazione è quella mostrata in
figura 17.9.
Miss Istruzioni
(0,5)
CPI Ideale
(1,1)
16%
35%
Miss Dati
(1,5)
49%
Figura 17.9 Diagramma della composizione del CPI effettivo.
17.4 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
17.12
LEZIONE 18
Introduzione alla memoria cache (parte seconda)
18.1 COME ORGANIZZARE I BLOCCHI DELLA CACHE
La memoria cache può essere organizzata in vari modi mantenendo costante la dimensione
totale.
18.1.1 Cache direct-mapped (ad accesso diretto)
Con questo tipo di organizzazione, il tag (XT) ricavabile dall’indirizzo di memoria richiesto (X)
viene confrontato con quello memorizzato in cache (T), all’indirizzo di cache selezionato
dall’indice (XS), ricavato dall’indirizzo specificato
B lo c k
T ag
D a ta
0
1
2
3
4
5
6
7
Figura 18.1: Esempio, cache direct mapped (o direct access) ad 8 blocchi.
18.1.2 Cache Set-Associativa (Set-Associative)
Per ridurre i conflitti sullo stesso indirizzo di cache (XS), è possibile organizzare i blocchi in
modo diverso raggruppandoli in insiemi o set in corrispondenza dello stesso indirizzo di cache
(Xs). Il numero totale di blocchi appartenenti allo stesso set è detto numero di vie e indica il
grado di associatività della cache (v. figura 18.2).
Set
Ta g
D a ta
Ta g
D a ta
0
1
S et
2
T ag
D a ta
T ag
D a ta
Tag
D a ta
Tag
D a ta
0
3
1
(a)
(b)
Figura 18.2: Esempio, Cache set-associative a 8 blocchi: (a) cache a 2 vie (A=2); (b) cache a 4 vie (A=4).
Detti quindi:
A
B
C
X
XM
XT
XS
si ha che:
=
=
=
=
=
=
=
Associatività (numero di blocchi raggruppati nello stesso set)
Dimensione del blocco
Dimensione totale della cache
Indirizzo al byte
Indirizzo in memoria del blocco (=X/B)
Indirizzo del tag
Indirizzo del set
18.1
NS
XS
XT
dove :
NS
=
=
=
=
C/(B•A)
XM mod NS
XM div NS
Numero di set complessivi della cache
Per individuare il blocco all’interno dello set è necessario a questo punto confrontare in
parallelo i tag dei vari blocchi del set con quello (XT) ricavabile dall’indirizzo (X). La funzione
di hit per una cache set-associative risulta quindi essere:
FH : (∀k=1…A, XT == YT,k && YV,k == 1 ? 1 : 0)
dove:
YT,k:
YV,k:
Tag del k-esimo blocco del set
Bit di validità del k-esimo blocco del set
XM
31 30
12 11 10 9 8
3210
X
XT
Index
0
1
2
V
Tag
Data
8
XS
22
V
Tag
Data
V
Tag
Data
V
Tag
Data
253
254
255
YT,0
YT,1
YD,0
YT,2
YD,1
YT,3
YD,2
22
32
YD,3
YV,0
YV,1
YV,2
YV,3
4-to-1 multiplexer
Hit
Data
Figura 18.3: Cache set-associative a 4 vie di dimensione 4KB e dimensione del blocco 4 byte.
18.1.3 Cache Completamente Associativa (Fully-Associative)
E’ possibile organizzare i blocchi anche in modo tale da avere un unico grande set contenente
tutti i blocchi; si parla in questo caso di cache completamente associativa.
18.2
T ag
D a ta
Tag
D a ta
Tag
D a ta
Tag
D a ta
Tag
D a ta
Tag
D a ta
Tag
D a ta
Tag
D a ta
Figura 18.4: Esempio, cache full-associative a 8 blocchi.
Poiché in questo caso si ha solo un set, si ha che:
NS = 1 Æ
XT = XM
XS = 0 (non occorre indirizzare il set)
18.2 POLITICA DI RIMPIAZZAMENTO
Quando il dato non è in cache e il set in cui si dovrebbe collocare tale dato è pieno, è
necessario fare preventivamente posto per il nuovo dato. In tal caso, si parla di
rimpiazzamento con riferimento al blocco da scartare per far posto al nuovo blocco. In
dettaglio, i passi da seguire per effettuare questa operazione sono:
1. scelta del blocco da rimpiazzare ;
2. eventuale riscrittura in memoria principale (si parla di “eventuale” riscrittura perché
adottando alcuni particolari politiche è possibile, sotto certe condizioni, evitare la
riscrittura in memoria);
3. caricamento del nuovo blocco nella locazione liberata.
18.2.1 Scelta del blocco da rimpiazzare
La scelta del blocco da rimpiazzare può seguire varie politiche:
• Random: Si sceglie blocco a caso;
questa politica è veloce ed economica ma ha delle scarse prestazioni.
• LRU (Least Recently Used): Si sceglie il blocco usato meno recentemente;
questo approccio garantisce ottime prestazioni ma tuttavia può essere costoso da
implementare in quanto sono necessari dei circuiti aggiuntivi per individuare il blocco
meno recentemente usato. In dettaglio, per tenere traccia dell’utilizzo dei blocchi è
necessario inserire dei bit addizionali per ogni blocco e dell’hardware aggiuntivo che ne
gestisca l’evoluzione dell’uso dei blocchi. Spesso vengono usate delle versioni
semplificate (es. Intel usa pseudo-LRU) che hanno prestazioni leggermente inferiori.
• FIFO: Si sceglie il blocco caricato meno recentemente;
la politica ha prestazioni intermedie fra random e LRU, ma non è molto usata. A livello
di implementazione è necessario gestire la lista FIFO.
Analizziamo piu’ in dettaglio il funzionamento della politica LRU. Supponiamo di avere A
blocchi all’interno di un set. Per ordinare i blocchi in funzione del loro uso si rendono necessari
ceil(log2(A)) bit (es. A=4 occorrono 2 bit di LRU). Ad ogni accesso occorrerà aggiornare tutti i
bit associati ad ogni blocco del set, in modo da mantenere sempre aggiornata una lista dei
blocchi dal meno recentemente usato al più recentemente usato. Nel momento in cui si sceglie
il blocco la logica selezionerà il primo blocco della lista (es. il blocco con i bit LRU tutti a
zero).
Da esperimenti su molte applicazioni (es: benchmark SPEC) si rileva che questa politica è la più
vantaggiosa tra le tre qui analizzate poiché si avvantaggia maggiormente della località degli
accessi. Come svantaggio abbiamo però una complicazione dell’hardware richiesto soprattutto
18.3
all’aumentare dell’associatività ed inoltre un lieve rallentamento nell’accesso alla cache
rispetto al caso di accesso diretto.
18.3 GESTIONE DELLE SCRITTURE SU HIT
E’ possibile ridurre il costo delle operazioni di rimpiazzamento osservando che se un blocco
non viene modificato, non e’ necessario riscriverlo in memoria. Ciò si può fare introducendo un
bit, detto ‘bit M’ o anche ‘bit D’ (rispettivamente Modified o Dirty) che tiene traccia della
necessità o meno di effettuare la riscrittura in memoria. Cio’ comporta che durante
l’operazione di scrittura (nel caso in cui si abbia hit) si preveda di adottare una politica ben
precisa. Nel caso si faccia uso del bit M, si parlera’ di politica di scrittura su hit di tipo Write
Back (WB), mentre nel caso in cui non si faccia ricorso a questo bit si parla di politica di
scrittura su hit di tipo Write Through (WT).
Ricapitando sono possibili due approcci per gestire le politiche di scrittura su hit (v. figura
18.5):
• Write Back (WB): nel momento in cui si debba rimpiazzare un blocco, si verifica se il
bit M è attivo. Se lo è si procede al rimpiazzamento come si sarebbe fatto
normalmente, se non lo è si può evitare l’operazione di riscrittura in memoria in quanto
il blocco in cache contiene già lo stesso valore presente in memoria (questo tipicamente
accade quando il processore fa operazioni si sola lettura o fetch su quel blocco). Si
risparmia così del traffico fra cache e memoria. Come già detto, per implementare
questa soluzione è necessario aggiungere un ulteriore bit per ogni blocco (M=Bit di
modifica) per indicare se sia o meno necessario riscrivere il dato in memoria al
momento del rimpiazzamento.
• Write Through (WT): se il dato del blocco in cache viene scritto, si effettua
immediatamente la scrittura anche in memoria. Notare che l’impegno del bus in questo
caso non e’ per un intero blocco (o piu’ blocchi) ma solo per la parola (o dato) coinvolta
nell’operazione di scrittura. Questo approccio risulta essere più semplice da
implementare, ed inoltre puo’ comportare vantaggi se le operazioni di scrittura non
sono molto frequenti.
CPU
CPU
W
CACHE
W
(1) hit
CACHE
(1) hit e
rimpiazzamento
(2) rimpiazzamento
MEM
MEM
(a)
(b)
Figura 18.5: Gestione delle scritture su hit: (a) Politica Write Back, (b) Politica Write Through
18.4 GESTIONE DELLE SCRITTURE SU MISS
Anche nel caso di una operazione di scrittura, se si presenta un miss e’ possibile adottare
diversi tipi di politiche (v. figura 18.6):
• Write Allocate (WA): Il blocco viene caricato nella cache e poi viene effettuata la
scrittura.
18.4
•
Write Not-Allocate (WNA): Il blocco viene modificato direttamente nel livello
inferiore di memoria e poi viene caricato in cache.
CPU
CPU
W
CACHE
MEM
W
(1) miss e scrittura in
memoria
(1) miss
(3) scrittura in cache
CACHE
(2) lettura blocco
(2) lettura blocco
MEM
(a)
(b)
Figura 18.6: Gestione delle scritture su miss: (a) Politica Write Allocate, (b) Politica Write Not-Allocate
Anche in questo caso, vantaggi e svantaggi dei due approcci dipendono fortemente dal tipo di
applicazione che gira sulla macchina.
18.3 CACHE A PIÙ LIVELLI
Nel progetto delle memorie cache, così come in quello di tutto il sottosistema di memoria di
un calcolatore, ci sono esigenze contrapposte. In particolare a parità di capacità, le memorie
più veloci sono più costose di quelle lente, perciò sono in genere più piccole.
In termini architetturali, e’ possibile utilizzare piu’ livelli di cache per generare una memoria
cache al tempo stesso grande e con un buon tempo di accesso medio, in maniera (gerarchica)
del tutto simile a come si e’ strutturata la memoria in termini di cache e memoria principale.
Si usano così più livelli di memoria cache, ordinati in modo tale che man mano che si scende di
livello, le cache siano sempre più capienti anche se più lente. Solitamente viene adottato uno
schema che prevede almeno due livelli di cache (figura 18.6).
L1
L1 hit
time
L2
L2 hit
time
DRAM
Proc
L2 Miss Rate
L2 Miss Penalty
L1 Miss Rate
L1 Miss Penalty
Figura 18.6: Architettura a due livelli di cache
Ovviamente ogni singola latenza dovrà essere considerata separatamente, con il relativo miss
rate, nel calcolo del tempo medio di accesso alla memoria. Nel caso di due livelli di cache si
ottiene, ad esempio:
AMAT
=
L1 Hit Time + L1 Miss Rate * L1 Miss Penalty
L1 Miss Penalty
=
L2 Hit Time + L2 Miss Rate * L2 Miss Penalty
da cui:
AMAT
=
L1 Hit Time + L1 Miss Rate *
(L2 Hit Time + L2 Miss Rate * L2 Miss Penalty)
18.5
Valori tipici per architetture di questo tipo sono:
• L1 Æ Capacità: decine di KB
Hit-time: 1 (o 2) cicli di clock
Miss-rate (tipici): 1-5%
• L2 Æ Capacità: centinai di KB
Hit-time: qualche ciclo di clock
Miss-rate (tipici): 10-20%
In una struttura a più livelli, il tempo medio di hit si assesterà ad un valore intermedio fra
quelli delle due cache prese singolarmente.
18.6
LEZIONE 19
Memoria virtuale
19.1 INTRODUZIONE
I processori attuali sono in grado di indirizzare una memoria (logica) spesso molto più estesa
di quella (fisica) effettivamente presente.
Fino a che la quantità di memoria necessaria per eseguire un programma non supera quella
della memoria fisica è possibile fare in modo che gli indirizzi generati dal processore siano
compresi entro i limiti della memoria disponibile.
Il caso in cui sia necessaria più memoria rispetto a quella disponibile potrebbe venire trattato,
come succedeva prima che esistessero i sistemi di memoria virtuale, lasciando al
programmatore il problema di individuare quelle parti di programma che non hanno bisogno di
essere contemporaneamente presenti e prevedere esplicitamente il caricamento nella
memoria di quelle parti che di volta in volta servono (tecnica di overlay).
I sistemi di memoria virtuale forniscono una soluzione generale al problema di consentire
l’esecuzione di programmi che richiedono più memoria di quella effettivamente disponibile,
evitando particolari accorgimenti nella programmazione e permettendo una condivisione
efficiente e sicura della memoria fra molti programmi.
19.2 MEMORIA VIRTUALE
La memoria virtuale è basata, per quanto riguarda i trasferimenti tra memoria centrale e
memoria secondaria, su un meccanismo simile a quello che c’è tra memoria cache e memoria
centrale: cioè in modo tale da assicurare che nella prima (di estensione inferiore alla seconda)
siano copiate dalla seconda solo le informazioni che servono e solo negli intervalli di tempo in
cui servono.
Il programma viene caricato in uno spazio di memoria completamente vuoto dato che ogni
programma ha a disposizione tutti gli indirizzi di uno proprio spazio virtuale privato. In questo
modo si ottiene “gratuitamente” anche una esecuzione protetta dei programmi dato che un
programma non puo’ accedere allo spazio di indirizzamento privato di un altro programma.
19.2.1 Funzionamento.
In presenza della memoria virtuale, la CPU genera un indirizzo virtuale che viene tradotto da
un insieme di componenti hardware e software in un indirizzo fisico da utilizzare per accedere
alla memoria principale. Questa associazione prende il nome di MEMORY MAPPING (figura
19.1)
19.1
I n d iriz z i F isic i
I n d iriz z i V irtu al i
M em o ria
P rin cip al e
s w ap-i n
M eccani s mo di
t r aduzi one degli i ndir i zzi
DIS K
s w ap-out
s w ap-i n: por tar e
pagi na
i n m em or i a
s w op-out : por tar e
pagi na s ul
di s co
Figura 19.1. L’unità di trasferimento fra memoria e disco è la pagina che ha una dimensione
tipica di 4-16 KB. La Pagina Virtuale può essere sul disco anziché nella memoria fisica.
Nella memoria virtuale i blocchi di memoria (detti pagine) sono posti in corrispondenza tra un
insieme di indirizzi (indirizzi virtuali) e un altro (indirizzi fisici); questo perché una pagina può
trovarsi sulla memoria fisica oppure sul disco.
Nel caso in cui una pagina virtuale non sia presente nella memoria principale ma sul disco si
parla di PAGE FAULT.
Una delle funzioni più importanti della memoria virtuale, è di permettere a più processi la
condivisione di un’unica memoria principale, fornendo contemporaneamente la protezione della
memoria tra questi processi, e tra i processi e il sistema operativo. Le pagine fisiche sono
condivisibili facendo in modo che a due indirizzi virtuali corrisponda lo stesso indirizzo fisico:
questo permette a programmi diversi di condividere dati o codice. Questo meccanismo deve
anche garantire che un singolo processo non possa scrivere nello spazio di indirizzamento di un
altro processo utente, sia intenzionalmente che accidentalmente.
È necessario anche evitare che un processo possa leggere i dati di un altro processo. Non
appena si permette la condivisione della memoria principale, è necessario garantire la
protezione dei dati da parte di un processo dalle letture e scritture di altri processi; infatti
un processo potrebbe accidentalmente danneggiare i dati di un altro processo. Quando i
processi devono condividere informazioni secondo modalità controllate, il sistema operativo li
deve assistere, per evitare di accedere alle informazioni di un altro processo. Per limitare la
condivisione della memoria in lettura, possiamo utilizzare il bit di accesso in scrittura e
lettura, poiché questo può essere modificato soltanto dal sistema operativo.
19.2.2 Memoria virtuale: schema logico.
La Tabella delle Pagine (PAGE TABLE) realizza il meccanismo di traduzione delle pagine da
indirizzi virtuali a fisici.
La Tabella delle Pagine, che risiede in memoria, è una sorta di schedario dove accanto al nome
del libro c’è la sua collocazione fisica (che può essere nella stessa biblioteca o in altre
biblioteche).
19.2
Le pagine vengono caricate a blocchi di dimensione fissa; sia l’indirizzo virtuale che quello
fisico hanno due componenti:
• un numero di pagina virtuale;
• un offset interno alla pagina.
Il meccanismo di mapping non interviene per cambiare l’offset, e quindi p-bit meno
significativi degli indirizzi, relativi all’offset, non vengono modificati dall’operazione di
mapping e restano invariati (figura 19.2).
n + p = 32
I n d ir iz z o V ir t u a le
I d e n t if ic a t o r e d i
P a g in a V ir t u a le (V P N )
n
F u n z io n e d i M a p p in g
V ir t u a le Æ F is ic o
I d e n t if ic a t o r e d i
P a g in a F is ic a (P P N )
p
O f f s e t d i p a g in a
m
I n d ir iz z o F is ic o
m + p
Figura 19.2. Processo di traduzione del numero di pagina virtuale in un numero di pagina fisico.
Il numero di pagina fisica rappresenta la parte più significativa dell’indirizzo fisico mentre l’offset interno
alla pagina, che non viene modificato, ne costituisce la parte meno significativa; il numero di bit nel campo di
offset nella pagina determina quindi la dimensione delle pagine.
19.3
GESTIONE DEL PAGE FAULT
Per poter leggere una locazione della memoria principale si deve presentare un indirizzo
virtuale al sistema di memoria, dopodiché si accede alla Tabella delle Pagine per vedere se la
pagina è presente nella memoria.
Se la pagina è presente in memoria, accedo nuovamente alla RAM per prendere il dato.
Viceversa, se il processo tenta di accedere ad una pagina che non era stata caricata nella
memoria si ha un accesso ad una pagina contrassegnata come non valida e questa causa
un’eccezione di pagina mancante (PAGE FAULT TRAP). L’architettura di paginazione, Tabella
delle Pagine, una volta constatato attraverso un apposito bit di validità che la pagina non è
valida attiva bit di eccezione (PAGE FAULT) del processore ed avvia un’apposita routine del
sistema operativo denominata PAGE-FAULT HANDLER. Tale routine si occupa di effettuare
l’operazione di PAGE-SWAP, ossia di trasferire la pagina richiesta in memoria principale e
conseguentemente riscrivere su disco di una pagina che si presume non serva piu’ (pagina
“vittima”). A questo punto viene ripetuto l’accesso e questa volta la pagina si troverà nella
RAM.
L’indirizzo virtuale non è sufficiente per determinare dove la pagina si trova nel disco. Nei
sistemi con memoria virtuale occorre tener traccia della collocazione su disco di tutte le
pagine dello spazio di indirizzamento virtuale.
Dato che non possiamo conoscere in anticipo quando una certa pagina in memoria verrà
sostituita, il sistema operativo tipicamente genera uno spazio su disco per tutte le pagine di
un processo all’atto stesso della creazione di questo; tale struttura dati può far parte della
19.3
Tabella delle Pagine oppure può essere una struttura dati ausiliaria indicizzata nello stesso
modo in cui si indicizza la Tabella delle Pagine.
19.3.1 Collocazione e ritrovamento delle pagine
Ciascun processo ha la propria Tabella delle Pagine; per indicare la posizione della Tabella
delle Pagine in memoria, l’hardware comprende un registro che punta alla sua locazione iniziale:
tale registro viene detto registro della Tabella delle Pagine.
Poiché la Tabella delle Pagine contiene un elemento per ciascuna possibile pagina virtuale non
vi è necessità di un campo tag. Nella terminologia della memoria cache l’indice, che è utilizzato
per accedere alla Tabella delle Pagine, corrisponde all’intero indirizzo di blocco, ossia del
numero della pagina virtuale (figura 19.2).
La Tabella delle Pagine può essere molto grossa, e quindi devono essere trovate tecniche per
ridurla. Queste tecniche mirano a ridurre la quantità totale dello spazio richiesto e a
minimizzare la parte della memoria principale dedicata alla Tabella delle Pagine.
• Registro di limite - La tecnica più semplice dispone di un registro di limite che delimiti
la dimensione della tabella per un dato processo: se il numero di una pagina virtuale
diviene più grande del contenuto del registro di limite occorre aggiungere degli
elementi alla Tabella delle Pagine. Questa tecnica permette alla Tabella delle Pagine di
crescere man mano che il processo richiede più spazio. In questo caso la Tabella delle
Pagine sarà grande solo se il processo sta usando molte pagine dello spazio di
indirizzamento virtuale e lo spazio di indirizzamento si espande in una sola direzione.
• Due tabelle e due limiti - Molti linguaggi richiedono due aree di dimensioni espandibili;
una contenente lo STACK e l’altra detta HEAP contiene i dati allocati dinamicamente. A
causa di questa dualità risulta conveniente dividere la Tabella delle Pagine e lasciarla
crescere dall’indirizzo più alto a quello più basso e viceversa, in questo modo avremo
due tabelle e due limiti. L’uso di due tabelle divide lo spazio di indirizzamento in due
zone, di solito il bit più significativo dell’indirizzo determina quale zona e quale tabella
si debbano usare. Ciascun segmento può crescere fino a metà dello spazio di
indirizzamento. Questo tipo di suddivisione è usato in molte architetture tra cui quella
dei MIPS ed è invisibile al programma applicativo anche se non lo è al sistema
operativo.
• Tabella delle Pagine inversa - Un altro approccio alla riduzione della dimensione della
Tabella delle Pagine prevede di applicare una funzione di hash all’indirizzo virtuale in
modo che la struttura dati della Tabella delle Pagine abbia una dimensione determinata
solo dal numero delle pagine fisiche nella memoria virtuale; ovviamente il processo di
ricerca in una Tabella delle Pagine inverse è più complesso perché non è sufficiente
indicizzare la tabella delle pagine. In pratica nella Tabella delle Pagine c’è una entry
per ogni pagina fisica. I vantaggi di questo approccio sono che la dimensione scala con
la dimensione della memoria fisica anziché con quella della memoria virtuale e che la
dimensione è fissa a prescindere dal numero di processi. La tecnica è chiamata
“inversa” perche’ le entry sono indicizzate per pagina fisica (PPN) anziche’ per pagina
virtuale (VPN); in ogni caso la ricerca avviene fornendo un VPN e ottenendo un PPN che
è dedotto dalla posizione della VPN trovata.
19.4
VPN
V
D
V irtual Address
Virtual Page 10
PPN 0
1 0
PPN 1
PPN 2
0 0
1 1
Virtual Page 16
PPN 3
1 0
Virtual Page 520
PPN K
0 0
K=Numero di elem enti della tabella
V = bit di validità
D = dirty bit: bit che indica
se la pagina è stata
m odificata
C
O
M
P
A
R
E
Physical
Page
N um ber
PPN = physical page number
VPN = virtual page number
Figura 19.3. Tabella Inversa delle Pagine.
•
•
Paginazione della Tabella delle Pagine - La maggior parte degli elaboratori permette
alle tabelle delle pagine di venire a loro volta paginate. E’ sufficiente applicare lo
stesso principio fondamentale della memoria virtuale, permettendo alla tabella della
pagine di risiedere nello spazio di indirizzamento virtuale. Cio’ comporta pero’ la
generazione di un maggior numero di page-fault. Questo puo’ essere evitato ponendo
tutte le tabelle delle pagine nello spazio di indirizzamento del sistema operativo e
ponendo alcune tabelle delle pagine di sistema in una parte della memoria principale che
sia indirizzata fisicamente e che sia sempre presente e mai su disco.
Paginazione su piu’ livelli - Possiamo anche utilizzare più livelli di tabelle delle pagine in
modo da ridurre la quantità totale dello spazio. In questo schema la Tabella delle
Pagine e’ organizzata ad albero: il primo livello fornisce la corrispondenza per grossi
blocchi di dimensione fissa dello spazio di indirizzamento virtuale da 64 a 256 pagine
ciascuno; questa tabella viene detta tabella radice anche se questi sono invisibili agli
utenti. Ciascun elemento della tabella radice, indica se una o più pagine delle foglie
siano allocate; in caso affermativo punta ad una Tabella delle Pagine per quel segmento.
Per tradurre gli indirizzi si ricerca il segmento nella tabella radice mediante i bit più
significativi dell’indirizzo; se l’indirizzo del segmento è valido i successivi bit più
significativi servono ad indicizzare la Tabella delle Pagine foglia indicata dall’elemento
dalla tabella dei segmenti. Questo metodo permette di usare lo spazio di
indirizzamento in modo sparso senza dover allocare l’intera. Ciò risulta particolarmente
utile con spazi di indirizzamento molto ampi ed in sistemi software che richiedono
l’allocazione non contigua. Uno svantaggio del modello di corrispondenza a più livelli è la
maggiore complessità del processo di traduzione degli indirizzi (figura 19.4 e 19.5).
19.5
1K
foglie
Indirizzo a 32 bit
10
P1 index
10
P2 index
4KB
1 radice
12
page offest
4 bytes
P1 index = puntatore all’interno della
radice
P2 index = puntatore all’interno delle foglie
Radice = tabella di primo livello
Foglie = tabelle di secondo livello (non
tutte saranno presenti all’interno
della memoria)
4 bytes
Figura 19.4. Tabella delle Pagine a due Livelli.
Indirizzo VIRTUALE a 64-bit
selector
Level 1 Level 2 Level 3 page offest
PAGE TABLE
BASE REGISTER
+
+
+
L1
page table
L2
page table
L3
page table
PHYSICAL
PAGE NUMBER
page offest
64-bit PHYSICAL address
Figura 19.5. Tabella delle Pagine a Tre Livelli:
specializzazione dello schema a due livelli
19.6
19.4
TLB
Dato che le tabelle delle pagine risiedono nella memoria principale, ciascun accesso in memoria
potrebbe richiedere il doppio del tempo (a causa della presenza della Tabella delle Pagine);
infatti servirebbe un primo accesso per ottenere l’indirizzo fisico ed un secondo per caricare
il dato.
Per velocizzare il meccanismo di traduzione i calcolatori contengono una cache speciale per
tener traccia delle traduzioni effettuate di recente. Questa cache prende il nome di TLB
(Translation Look aside Buffer) (figura 19.6).
Virtual Address
N
Virtual to Physical
Page Map
TLB
P
M
Physical Address
L1 Cache
Data
Figura 19.6. Schema TLB.
19.4.1 Caratteristiche del TLB
Il TLB è una cache che contiene solo le corrispondenze della Tabella delle Pagine più recenti.
Il campo tag nel TLB contiene il numero di pagina virtuale, mentre il campo dati contiene il
numero di pagina fisica (figura 19.7)
Dato che non sarà più necessario accedere alla Tabella delle Pagine, facendo accesso in
memoria al TLB ogni accesso in memoria dovrà includere dei bit aggiuntivi, come il bit di uso
ed il bit di modifica.
Ad ogni riferimento si consulta il numero di pagina virtuale nel TLB: se il valore è presente il
numero di pagina fisica viene usato per formare l’indirizzo ed il bit di uso corrispondente
viene posto ad 1; se il processore sta effettuando una scrittura si pone ad 1 anche il bit di
modifica.
Se invece si verifica un miss nel TLB occorre determinare se siamo di fronte ad un page fault
o più semplicemente ad un miss del TLB. Per determinarlo basta vedere se il bit V della
Tabella delle Pagine; se esso è a 1, allora la situazione indica un miss nel TLB. In questo caso la
traduzione va comunque avanti e la CPU può risolvere il riferimento caricando nel TLB la
traduzione presa dalla Tabella delle Pagine, e ripetere successivamente l’accesso.
Se invece la pagina non è presente in memoria indica un reale page fault e la CPU invoca il
sistema operativo per mezzo di un’eccezione.
19.7
Il TLB ha un numero di elementi molto minore del numero di pagine della memoria principale
(128-256 elementi) ed i page fault saranno molto più frequenti dei miss in TLB.
I miss nel TLB possono essere gestiti via hardware o software; in pratica vi è poca differenza
di prestazioni tra i due approcci poiché le operazioni principali da compiere sono le stesse in
entrambi i casi.
Non appena si verifica un miss nel TLB, e si è letta la traduzione corrispondente dalla Tabella
delle Pagine, occorre scegliere un elemento del TLB da sostituire. Dato che i bit di uso e di
modifica sono contenuti nel TLB si devono ricopiare anche questi nell’elemento corrispondente
della Tabella delle Pagine nel momento in cui si sostituisce tale elemento.
Questi bit sono l’unica parte del TLB che può venir modificata durante l’uso di quella pagina.
L’uso di una strategia write-back (ossia ricopiando tali bit solo quando si verifica un miss
anziché ad ogni scrittura) si rivela molto efficiente poiché la frequenza del miss che ci si
aspetta dal TLB è molto bassa.
T L B : O r g a n iz z a z io n e L o g ic a
VPN
V
D
1
0
1
1
0
0
1
0
V
D
1
1
0
0
1
0
0
0
U
U
Tag
P h y s ic a l A d d r e s s
M e m o r ia
F is ic a
P h y s ic a l P a g e o r D is k A d d r e s s
1 1
0 0
1 0
D IS C O
U = b it c h e in d ic a s e la p a g in a è s t a t a u s a t a
Figura 19.7. Organizzazione del TLB.
Nelle implementazioni reali si usa un ampio spettro di possibili valori di associatività nei TLB.
Alcuni sistemi utilizzano dei piccoli TLB completamente associativi, poiché la completa
associatività permette una frequenza di miss minore. Altri elaboratori utilizzano dei TLB più
capienti, non associativi o con bassa associatività.
Con una corrispondenza completamente associativa diviene più complesso sostituire un
elemento, i miss devono essere gestiti più velocemente, e non si può fare affidamento su di un
algoritmo software.
19.4.3 Interazione del TLB con la cache.
I sistemi di memoria virtuale ed il sistema di cache collaborano : il sistema operativo elimina il
contenuto di una pagina dalla cache quando e’ necessario trasferire tale pagina su disco (swap-
19.8
out). Allo stesso tempo il sistema operativo aggiorna la Tabella delle Pagine ed il TLB in modo
da riflettere tale cambiamento.
In uno schema di base, se il TLB genera un hit, si può accedere alla cache con l’indirizzo fisico
corrispondente. Se l’operazione è una scrittura l’elemento della cache viene sovrascritto ed il
dato è inviato verso il buffer delle scritture. Nel caso di lettura la cache può generare un hit
o un miss e rispettivamente fornire il dato oppure causare uno stallo. E’ da notare che un hit
nel TLB ed un hit nella cache sono eventi indipendenti e che l’accesso alla cache non è neppure
tentato quando avviene un miss nel TLB, infine si noti che un hit nelle cache si può verificare
solo dopo un hit nel TLB (figure 19.8 e 19.9).
VA
h it
PA
TLB
Lookup
CPU
m is s
M a in
M em ory
Cache
m is s
h it
T ransla t io n
d ata
tC
1/2 tC
20 tC
V A = V i r t u a l A d d re s s
P A = P h y s ic a l A d d re s s
Figura19.8. Schema e Interazione con la Cache.
V irt u a l a d d r e s s
T L B a cc e ss
T L B m is s
e x c e p tio n
No
Yes
T L B h it?
P h y s ic a l a d d re s s
No
T ry to r e a d d a ta
f ro m c a c h e
C a c h e m is s s ta ll
No
C a c h e h it?
Yes
W r ite ?
No
Yes
W r ite p ro te c tio n
e x c e p tio n
W rite a c c e s s
b it o n ?
Y es
W r it e d a t a in t o c a c h e ,
u p d a te th e t a g , a n d p u t
th e d a t a a n d th e a d d re s s
in to th e w rite b u ffe r
D e liv e r d a ta
to th e C P U
Figura 19.9 Diagramma di funzionamento del TLB + Cache.
19.9
Per evitare di generare cammini critici in cui siano presenti possibili stalli dovuti al tempo
necessario alla traduzione da indirizzo virtuale a fisico una possibile soluzione e’ di utilizzare
cache di dimensioni non superiori a quelle di una pagina (figura 19.10).
32
index
assoc
lookup
TLB
10
1 K
Cache
4 bytes
2
00
PA
Hit/
M iss
Data
PA
12
disp
20
page #
Hit/
M iss
=
Figura 19.10. Sovrapposizione dell’accesso alla Cache e al TLB
Alternativamente la CPU può indicizzare la cache con un indirizzo che sia completamente o
parzialmente virtuale; nel momento in cui si verifica un miss nella cache, il processore deve
tradurre l’indirizzo in un indirizzo fisico, in modo da poter prelevare il blocco della cache dalla
memoria principale (figura 19.11).
Quando si accede alla cache con indirizzi virtuali e le pagine sono condivise con altri
programmi, è possibile che si presenti il fenomeno di aliasing, il quale si verifica quando uno
stesso oggetto ha due nomi; in questo caso si hanno due indirizzi virtuali per la stessa pagina:
un programma potrebbe scrivere un dato, senza che il secondo programma si renda conto che
il dato è cambiato.
Virtual Address
N
TLB
Virtual to Physical
Page Map
P
L1 Cache
M
Physical Address
Figura 19.11 Cache con indirizzamento virtuale.
19.10
Data
Le cache completamente indicizzate virtualmente, introducono dei vincoli progettuali sulla
cache e sul TLB per non introdurre il problema dell’aliasing, o impongono al sistema operativo
di adottare dei provvedimenti per garantire che non possano esistere degli alias. Ad esempio,
per risolvere il problema, si effettua l’accesso in parallelo alla cache al TLB, confrontando i
campi tag dell’indirizzo fisico provenienti dalla cache con l’indirizzo fisico ottenuto dal TLB
(figura 19.12). Il segnale reale di hit della cache sara’ allora il risultato del confronto fra il
Phisical Page Number (PPN) ottenuto dal TLB e quello ricavato dalla cache (purche’ ovviamente
la cache abbia fornito un hit in corrispondenza dell’indirizzo Virtuale fornitole.
Virtual Address
N
TLB
P
Virtual to Physical
Page Map
L1 Cache
M
Physical Address
PPN
=
Data
PPN (tag)
L1 HIT
Figura 19.12. Cache con indirizzamento virtule ma tag fisici.
I processi indicizzati virtualmente ma con tag fisici, tendono ad ottenere vantaggi in termini
di prestazioni delle cache indicizzate in modo del tutto virtuale, mantenendo la semplicità
strutturale di una cache indirizzata fisicamente.
19.4.6 TLB: valori tipici
Alcuni valori tipici del TLB possono essere i seguenti:
¾ Dimensioni del blocco: 8 byte
¾ Hit-time: 0.5 – 1 ciclo
¾ Miss-penalty: 10 – 50 cicli
¾ Hit-rate: 99% - 99.99%
¾ Dimensione della TLB: 32 – 1024 elementi
19.5 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145-1.
[2] Abraham Silberschatz, Peter Baer Galvin, Greg Gagne,“Sistemi Operativi, concetti ed esempi”
19.11
LEZIONE 20
Pipeline
20.1 INTRODUZIONE
Il concetto di pipeline fu introdotto da Henry Ford (il famoso costruttore di automobili) agli
inizi del 1900. L’idea era di creare una catena di montaggio nelle sue industrie allo scopo di
produrre il maggior numero di autovetture per unità di tempo. Per chiarire il concetto si può
pensare ad una lavanderia dove il processo di lavaggio di un capo si suppone composto di 4 fasi
(fig. 20.1).
A
• Ann, Brian, Cathy, Dave
devono:
B
C
D
• Lavare
• Asciugare
• Stirare
• Mettere a posto
Figura 20.1 Fasi del processo di lavaggio.
Ogni fase richiede trenta minuti per essere eseguita, quindi l’intero processo richiederebbe
due ore per completarsi. Supponiamo che nella nostra lavanderia entrino quattro clienti,
utilizzando una classica tecnica sequenziale (fig. 20.2) il primo cliente terminerebbe dopo due
ore, il secondo dopo quattro e cosi via, questo perché si considerano le quattro fasi come un
unico blocco della durata di due ore. Quindi in totale la lavanderia dovrebbe restare aperta
otto ore per servire i quattro clienti.
6 PM
A
7
8
10
9
11
12
1
30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30
Tempo
B
C
D
Figura 20.2 Lavanderia sequenziale.
Si può notare che ogni fase del processo è indipendente dalle altre, questo ci suggerisce un
modo per minimizzare l’attesa dei nostri clienti: una volta che un cliente completa una fase, la
lascia disponibile per il cliente successivo. Come si può vedere dalla figura 20.3 dopo solo tre
ore e mezza avremmo servito tutti e quattro i nostri clienti. Suddividere un ciclo operativo in
fasi distinte ed indipendenti sta alla base delle tecniche di pipelining.
20.1
6 PM
7
8
9
30 30 30 30 30 30 30
10
11
12
1
Tempo
A
B
C
D
Figura 20.3 Lavanderia con pipeline.
20.2 VANTAGGI E SVANTAGGI DELLA PIPELINE
Da quanto vedremo nei prossimi paragrafi la tecnica della pipeline apporta sicuramente
notevoli vantaggi all’interno di un processore, consente di aumentare il numero di istruzioni
eseguite al secondo rallentando però il tempo di esecuzione di ogni singola istruzione
dovendosi adattare allo stadio più lento. Esistono in realtà altri limiti ai benefici che una
pipeline può apportare all’architettura di un sistema:
• I costi salgono in quanto la pipeline necessita di alcune risorse hardware in più.
• Una ulteriore suddivisione in fasi ancora più elementari diventa più difficile.
• La parallelizzazione crea conflitti che spesso riducono l’efficienza della pipeline.
20.3 LA PIPELINE NEL PROCESSORE MIPS
Gli stessi concetti visti nel caso della lavanderia sono applicabili al processore ma questa volta
in ingresso alla pipeline troviamo l’esecuzione delle istruzioni. La tecnica del pipelining
consente di sovrapporre l’esecuzione delle istruzioni senza ridurre effettivamente il tempo di
esecuzione di ogni singola istruzione, ma piuttosto aumentando il throughput ovvero il numero
di operazioni eseguite nell’unità di tempo. Il throughput è sicuramente la metrica più
importante nella valutazione di un processore.
In altri termini questa tecnica permette di disaccoppiare momenti logicamente a sé stanti
dell’elaborazione eseguendoli in parallelo con altri. Il lavoro che deve essere svolto, in una
pipeline, da un’istruzione è spezzato in piccole parti ciascuna delle quali richiede una frazione
del tempo necessario al completamento dell’intera istruzione, ciascun passo prende il nome di
stadio di pipeline.
La velocità della pipeline è limitata dallo stadio più lento proprio perché tutti gli stadi sono in
successione e lavorano in maniera sincrona quindi la frequenza con cui le istruzioni escono non
può superare quella con cui entrano nella pipeline. Ogni stadio viene quindi calibrato in modo
tale che le operazioni da esso svolte si compiano entro un ciclo di clock del processore. Un
ciclo di clock corrisponde al tempo necessario all’avanzamento dell’istruzione di un passo lungo
la pipeline cioè, ad ogni clock ci si sposta nello stadio successivo.
Se gli stadi fossero perfettamente bilanciati, condizione ottimale, l’accelerazione dovuta alla
pipeline sarebbe direttamente proporzionale al numero di stadi che compongono la pipeline
stessa, ma questa situazione di ottimalità è difficilmente raggiungibile.
Esaminiamo con un esempio le differenze che esistono tra l’esecuzione sequenziale di
istruzioni e quella in pipeline. Nella tabella 1 abbiamo un’insieme di istruzioni con i rispettivi
20.2
tempi di esecuzione per ogni stadio.
Tabella 1. Durata di singoli stadi per istruzione.
Tipo di
istruzione
Lw
Sw
add,sub,and,or
Beq
Memoria
istruzioni
2ns
2ns
2ns
2ns
Lettura
registro
1ns
1ns
1ns
1ns
Operazione
ALU
2ns
2ns
2ns
2ns
Memoria
dati
2ns
2ns
Scrittura
registro
1ns
Tempo
totale
8ns
7ns
6ns
5ns
1ns
Prendiamo come esempio un programma costituito da tre istruzioni lw. La figura 20.4 illustra
l’esecuzione delle tre istruzioni in maniera sequenziale, ovvero senza pipeline, il tempo
impiegato per svolgere le tre lw è di 24 ns.
2
T ime
lw $1, 100( $0)
In structi on
R eg
fe tch
lw $2, 200( $0)
4
6
8
AL U
D ata
ac cess
10
12
14
AL U
D ata
ac cess
16
18
Re g
In structi on
R eg
fe tch
8 ns
lw $3, 300( $0)
Re g
In structi on
fetch
8 ns
8 ns
Figura 20.4 Stadi sequenziali.
Adesso rivediamo lo stesso esempio utilizzando una pipeline a cinque stadi (figura 20.5).
Program
execution
Time
order
(in instructions)
lw $1, 100($0)
Instruction
fetch
lw $2, 200($0)
2 ns
lw $3, 300($0)
2
4
Reg
Instruction
fetch
2 ns
6
ALU
Reg
Instruction
fetch
2 ns
8
Data
access
ALU
Reg
2 ns
10
14
12
Reg
Data
access
Reg
ALU
Data
access
2 ns
2 ns
Reg
2 ns
Figura 20.5 Pipeline a cinque stadi.
Da questo esempio si può notare che la pipeline riesce ad eseguire le cinque istruzioni in 13ns
(senza pipeline ne servivano 24) nonostante la necessità di adattamento allo stadio più lento.
Questo adattamento viene messo in evidenza dai 9ns necessari per eseguire una singola
istruzione mentre ne servivano soltanto 8 nell’esempio senza pipeline: si è dovuto adottare uno
stadio di ciclo di clock da 2ns anche se alcuni stadi ne richiedevano soltanto 1, una scelta
tecnica impiegata per impedire che gli stadi che vanno poi a sovrapporsi nell’esecuzione non
20.3
finiscano i tempi diversi.
Questo esempio mostra anche come lo sbilanciamento degli stadi non consenta, in questo caso,
un miglioramento teorico di cinque volte che ci si aspetterebbe da una pipeline a cinque stadi.
Osservando le figure 20.4 e 20.5 quello che si può notare è il passaggio da un ciclo di clock
pari a 8ns ad uno pari a 2ns, il miglioramento ottenuto è quindi di quattro volte. Il
miglioramento apportato dalla pipeline diventa più evidente aumentando il numero di istruzioni.
20.3.1 Processore basato su pipeline
La figura 20.6 rappresenta un processore a singolo ciclo. Volendo implementare lo stesso
processore ricorrendo ad una pipeline a cinque stadi, occorrerà suddividere la rete logica
rappresentata in fig. 20.6 in cinque sottoreti più semplici.
Una suddivisione possibile risulta la seguente (fig. 20.6 e 20.7):
1. F: (Istruction Fetch) prelievo dell’istruzione
2. D: (Istruction Decode) decodifica dell’istruzione e prelievo operandi dai registri
3. X: (Execute) esecuzione o calcolo di un indirizzo effettivo specificato nell’istruzione
4. M: (Memory access) accesso alla memoria
5. W: (Write back) scrittura del risultato
F: prelievo istruzione
D: Decodifica istruzione
X: esecuzione
M: accesso in Memoria W: Write-back
0
M
u
x
1
Add
Add
4
Add
result
Shift
left 2
PC
Read
register 1
Address
Instruction
Instruction
memory
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Write
data
0
M
u
x
1
Zero
ALU ALU
result
Address
Data
memory
Write
data
16
Sign
extend
Read
data
1
M
u
x
0
32
Figura 20.6 Processore a singolo ciclo.
In figura 20.7:
• IM rappresenta la memoria da cui vengono prelevate le istruzioni (stadio F);
• REG rappresenta i registri (stadio D in lettura e decodifica, stadio W nella fase di
scrittura dei risultati);
• ALU è l’unita in cui vengono effettuate le operazioni logiche e aritmetiche (stadio X);
• DM e’ la memoria dati (stadio M).
20.4
Time (in clock cycles)
Program
execution
order
(in instructions)
CC 1
CC 2
CC 3
IM
Reg
ALU
lw $10, 20($1)
sub $11, $2, $3
IM
Reg
CC 4
CC 5
DM
Reg
ALU
DM
CC 6
Reg
Figura 20.7 Schema delle unità di calcolo.
La figura 20.8 rappresenta uno schema più dettagliato, in cui sono mostrate le risorse fisiche
di ogni stadio. Affinché ogni stadio operi autonomamente rispetto agli altri stadi è necessario
introdurre dei registri intermedi (denominati in funzione degli stadi che essi separano: es.
F/D e’ il registro che separa gli stadi F e D). Tali registri intermedi dovranno essere in grado
di bufferizzare tutti i segnali che e’ necessario passare da uno stadio al successivo. Ad ogni
ciclo di clock, tutte le istruzioni avanzano da un registro di pipeline al successivo. Tali registri
intermedi vengono sincronizzati (ovvero ricaricati) ad ogni ciclo di clock.
F: prelievo istruzione
D: Decodifica istruzione e
lettura dei registri
M: accesso
in Memoria
X: esecuzione
W: Write-back
0
M
u
x
1
Add
4
Add
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
16
F/D
F/D
Sign
extend
Zero
ALU ALU
result
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
32
D/X
X/M
X/M
M/W
M/W
Figura 20.8 Unità di calcolo con registri di pipeline.
20.3.1.1 Esempio: istruzione Load Word (lw)
I passi svolti possono essere diversi in base all’istruzione eseguita: ad es. la lw comporta i
seguenti cinque passi:
1. Prelievo dell’istruzione : viene letta l’istruzione nella memoria usando l’indirizzo del
20.5
Program Counter PC, dopodiché il PC viene incrementato di quattro, rendendolo pronto al
nuovo ciclo di clock (è necessario che l’incremento del PC venga memorizzato anche nel
registro F/D perché nel caso di un salto incondizionato il calcolatore non sa a priori quale
tipo di istruzione verrà caricata). Nel registro di pipeline F/D viene scritta l’istruzione
letta (comprensiva del numero del registro che specifica l’indirizzo base della lw e del
valore immediato che specifica l’offset su 16 bit).
2. Decodifica dell’istruzione e lettura dei registri: si preleva il contenuto del registro base
mentre l’offset viene esteso a 32 bit. Questi valori e l’indirizzo incrementato del PC
vengono salvati nel registro di pipeline D/X (il numero del registro in cui si memorizzerà il
risultato continua ad essere “propagato” di stadio in stadio).
3. Esecuzione (calcolo dell’indirizzo effettivo del dato): in questa fase l'istruzione load
riceve dal registro D/X il contenuto del registro base e l’offset, che vengono sommati
usando l’ALU . Il risultato della somma viene memorizzato in X/M.
4. Accesso in memoria.: si legge dalla memoria il dato usando l’indirizzo effettivo del dato
calcolato allo stadio precedente e lo si carica nel registro di pipeline M/W.
5. Scrittura del risultato: il dato letto al passo precedente viene scritto nel registro dove si
vuole inserire il risultato.
Quello che si nota da questi cinque passi è come i registri intermedi consentano di trasferire
tutta l’informazione che potrebbe risultare utile in cicli di clock successivi.
20.3.1.2 Esempio: istruzione Store Word (sw)
Di seguito vengono illustrati i passi necessari ad effettuare l’operazione di memorizzazione:
1. Prelievo istruzione: questo passo e’ del tutto analogo al caso dell’istruzione load word. Nel
registro di pipeline F/D viene scritta l’istruzione letta (comprensiva del numero del
registro che specifica l’indirizzo base della lw e del valore immediato che specifica l’offset
su 16 bit).
2. Decodifica istruzione e lettura registri: oltre alle operazioni analoghe all’istruzione load
word, viene anche letto il contenuto del registro dell’operando da scrivere in memoria. Tale
valore viene bufferizzato nel registro di pipeline D/X.
3. Esecuzione (calcolo dell’indirizzo effettivo del dato): anche questo passo e’ del tutto
analogo al caso dell’istruzione load word (il valore da memorizzare viene “propagato” di
stadio in stadio).
6. Accesso in memoria.: in questo passo si scrive in memoria il dato usando l’indirizzo
effettivo del dato calcolato allo stadio.
4. Scrittura risultato: in questo stadio l’istruzione store word non deve fare niente.
20.3.1.3 Esempio: sequenza di istruzioni lw+sub
Qui di seguito si propone un esempio che prende in considerazione la sequenza di istruzioni:
lw $10, 20($1)
sub $11, $2, $3
20.6
Time (in clock cycles)
Program
execution
order
(in instructions)
lw $10, 20($1)
CC 1
CC 2
CC 3
IM
Reg
ALU
sub $11, $2, $3
IM
Reg
CC 4
CC 5
DM
Reg
ALU
DM
CC 6
Reg
Figura 20.9 Pipeline a più cicli di clock.
La figura 20.9 mostra una rappresentazione schematica della pipeline a più cicli di clock, il
colore grigio indica attività delle risorse corrispondenti. Inoltre, il colore grigio nella prima
metà della risorsa indica che la risorsa corrispondente e’ occupata solo nella prima metà del
ciclo di clock; analogamente, il colore grigio nella seconda metà della risorsa indica che la
risorsa corrispondente e’ occupata solo nella seconda metà del ciclo di clock. Tale
informazione e’ fondamentale per consentire un uso allo stesso ciclo di clock di alcune risorse
come i registri del processore: tali registri risultano quindi disponibili anche nello stesso ciclo
in due stadi diversi (stadio D e stadio W). In Figura 20.10 viene mostrato in dettaglio la fase
di prelievo (Fetch) dell’istruzione lw con la convenzione di colorare in grigio le risorse
impegnate. Notare, in particolare, che il registro di pipeline F/D risulta impegnato nella prima
[meta’] metà del ciclo di clock. Notare inoltre che, rispetto alla fig. 20.8 e’ stato introdotto un
filo (in basso) che consente di propagare l’indice del registro in cui si andrà ad effettuare la
memorizzazione del risultato (write-back). La figura 20.10 illustra il prelievo dell’istruzione
lw, l’incremento del PC e la scrittura dei valori necessari agli altri quattro stadi nel registro di
pipeline F/D.
F: prelievo istruzione
lw $10, 20($1)
D: Decodifica istruzione
X: esecuzione
M: accesso in Memoria W: Write-back
0
M
u
x
1
Add
Add
4
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
Zero
ALU ALU
result
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
16
F/D
Sign
extend
32
D/X
X/M
Figura 20.10 Fetch dell’istruzione lw.
20.7
M/W
Nella figura 20.11 la lw si trova ormai allo stadio di decodifica dell’istruzione e
contemporaneamente si ha il prelievo dell’istruzione sub.
F: sub $11, $2, $3
D: lw $10, 20($1)
X: esecuzione
M: accesso in Memoria W: Write-back
0
M
u
x
1
Add
4
Add
Add
result
Shift
left 2
Read
register 1
Address
PC
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
Zero
ALU ALU
result
Read
data
Address
1
M
u
x
0
Data
memory
Write
data
16
Sign
extend
32
D/X
F/D
M/W
X/M
Figura 20.11 Decode lw, Fetch sub.
F: prelievo istruzione
X: lw $10, 20($1)
D: sub $11, $2, $3
M: accesso in Memoria W: Write-back
0
M
u
x
1
Add
Add
4
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
Zero
ALU ALU
result
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
16
F/D
Sign
extend
32
D/X
X/M
M/W
Figura 20.12 Execute lw, Decode sub.
Nella figura 20.12 la lw legge dal registro di pipeline D/X i contenuti del registro 1 e il valore
immediato esteso in segno che vengono sommati usando l’ALU e salvando il risultato nel
registro X/M. Nel frattempo l’istruzione sub è ancora in fase di decodifica.
20.8
F: prelievo istruzione
D: Decodifica istruzione
M: lw $10, 20($1)
X:sub $11, $2, $3
W: Write-back
0
M
u
x
1
Add
4
Add
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
Zero
ALU ALU
result
0
M
u
x
1
Write
data
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
16
Sign
extend
32
D/X
F/D
M/W
X/M
Figura 20.13 Memory lw, Execute sub.
Nella figura 20.13, per quanto riguarda la lw, il dato viene letto dalla memoria grazie
all’indirizzo contenuto in X/M e caricato nel registro M/W. L’istruzione sub si trova in fase di
esecuzione.
F: prelievo istruzione
D: Decodifica istruzione e
lettura dei registri
M:sub $11, $2, $3
X: esecuzione
W:lw $10, 20($1)
0
M
u
x
1
Add
Add
4
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
Zero
ALU ALU
result
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
16
F/D
Sign
extend
32
D/X
X/M
Figura 20.14 Write-Back lw, Memory sub.
M/W
La lw effettua la scrittura nei registri centrali come si nota nella figura 20.14 mentre
l’istruzione sub termina nella figura 20.15.
20.9
D: Decodifica istruzione e
lettura dei registri
F: prelievo istruzione
M: accesso
in Memoria
X: esecuzione
W:sub $11, $2, $3
0
M
u
x
1
Add
Add
4
Add
result
Shift
left 2
PC
Read
register 1
Address
Read
data 1
Read
register 2
Registers Read
Write
data 2
register
Instruction
Instruction
memory
0
M
u
x
1
Write
data
Zero
ALU ALU
result
Address
Read
data
1
M
u
x
0
Data
memory
Write
data
16
F/D
Sign
extend
32
D/X
X/M
Figura 20.15 Write-Back sub.
M/W
20.4 CRITICITA’ SUI DATI E PROPAGAZIONE
La suddivisione di un’istruzione in cinque fasi comporta che in ciascun periodo di clock vi
potranno essere fino a cinque istruzioni in esecuzione. D’altra parte ogni componente logico
dell'unità di elaborazione viene usato in un solo stadio della pipeline per evitare conflitti di
accesso alla stessa risorsa (anche chiamati criticità strutturali). Fino ad ora, si è visto il
comportamento ideale ed ottimale della pipeline, avendo considerato solo istruzioni
indipendenti tra di loro. Nei programmi reali la situazione è ben diversa: spesso le istruzioni
sono dipendenti l'una dall'altra. Si consideri, ad esempio, il seguente programma in assembly (i
registri sono indicati con ‘rX’ anziché con ‘$X’):
add
sub
and
or
xor
r1,r2,r3
r4,r1,r3
r6,r1,r7
r8,r1,r9
r10,r1,r11
Le ultime quattro istruzioni dipendono tutte dal risultato scritto in r1, perché bisogna
considerare che ad un certo istante le cinque istruzioni sono tutte in esecuzione in stati
diversi della pipeline e tutte hanno bisogno del valore del registro r1 (che ancora non e’ stato
memorizzato). Se ciò può non sembrare ovvio proviamo a vederlo graficamente in figura 20.16.
20.10
Tempo (cicli di clock)
F
Dm
Im
Reg
Dm
Im
Reg
Dm
Im
Reg
Dm
Im
Reg
ALU
Reg
Reg
ALU
and r6,r1,r7
W
ALU
sub r4,r1,r3
Im
M
ALU
O
r
d
e
r
add r1,r2,r3
X
ALU
I
n
s
t
r.
D
or r8,r1,r9
xor r10,r1,r11
Reg
Reg
Reg
Dm
Reg
Figura 20.16 Criticità sui dati.
Come si vede in figura i valori che si tentano di leggere da r1 nelle istruzioni sub, and, or, non
possono essere il risultato corretto della add a. Un possibile modo per evitare questo
problema potrebbe essere di ritardare tutte le istruzioni successive alla add di tre cicli,
perdendo pero’ un po’ di vantaggi della pipeline. Questi tipi di dipendenze prendono il nome di
"criticita’ sui dati" e sono uno dei motivi per cui è difficile progettare pipeline ad elevate
prestazioni.
L’approccio tipico per la risoluzione di questo tipo di criticità consiste nel propagare il valore
corretto agli altri stadi della pipeline, dove questo si rende necessario. Analizzando
attentamente ci si accorge che l’istruzione sub cerca di leggere r1, nello stadio di X, ma tale
registro non è stato ancora scritto dall’istruzione precedente, è quindi necessario disporre di
quei valori all’ingresso della ALU utilizzando appositi circuiti di propagazione (forwarding)
connessi tra le varie unità logiche. In questo caso il segnale deve essere propagato dall’uscita
della ALU verso l’ingresso della stessa tramite un collegamento “all’indietro” che giunga su un
registro di flip-flop, come illustrato in figura 20.18.
20.11
D/ X.MemRead
Hazard
detection
unit
D/ X
F / D W rit e
WB
Control
0
M
u
x
PC
Instruction
memory
In s tr u c tio n
P C W r ite
F/ D
X/M
M
WB
EX
M
M/W
WB
M
u
x
Registers
ALU
Data
memory
M
u
x
M
u
x
F/ D.RegisterRs
F/ D.RegisterRt
F/ D.RegisterRt
Rt
F/ D.RegisterRd
Rd
D/ X.RegisterRt
Rs
Rt
M
u
x
X/M.RegisterRd
Forwarding
unit
M/W .RegisterRd
Figura 20.18 Logica necessaria per il forwarding
Come mostrato in figura 20.19, e’ possibile ad ogni ciclo prelevare il dato giusto (se e’ stato
gia’ prodotto) da qualche parte all’interno della pipeline, perlomeno per le istruzioni
considerate. Inoltre, ricordando che il register file viene scritto nella prima meta’ del ciclo di
clock e letto nella seconda meta’ del ciclo, e’ possibile risolvere la criticita’ dell’istruzione ori
di questo esempio senza far ricorso al circuito di propogazione ora introdotto.
20.12
Tempo (cicli di clock)
F
Dm
Im
Reg
Dm
Im
Reg
Dm
Im
Reg
Dm
Im
Reg
ALU
Reg
Reg
ALU
sub r4,r1,r3
W
ALU
Im
M
ALU
O
r
d
e
r
add r1,r2,r3
X
ALU
I
n
s
t
r.
D
and r6,r1,r7
or r8,r1,r9
xor r10,r1,r11
Reg
Reg
Reg
Dm
Reg
Figura 20.19 Propagazione dei dati
20.4.1 Classificazioni dei conflitti di dati
I conflitti che possono insorgere in una pipeline si schematizzano in tre categorie:
RAW (Read After Write)
Un’istruzione successiva cerca di LEGGERE un registro prima che l’istruzione
precedente lo abbia scritto
WAR (Write After Read)
Un’istruzione successiva cerca di SCRIVERE un registro prima che l’istruzione
precedente lo abbia letto
WAW (Write After Write)
Un’istruzione cerca di SCRIVERE un registro prima che l’istruzione precedente lo abbia
scritto (se questo avviene, il valore non sarà più associato all’istruzione più recente)
20.4 CRITICITA’ SUI DATI E SITUAZIONI DI STALLO
Come è possibile immaginare la propagazione non può risolvere tutti i problemi possibili. Un
esempio semplice può essere un istruzione che tenta di leggere un registro subito dopo un
istruzione di load.
Time (clock cycles)
F
M
W
Reg
Reg
Dm
Im
Reg
ALU
sub r4,r1,r3
Im
X
ALU
lw r1,0(r2)
D
Dm
Figura 20.20 Criticità sui dati
20.13
Reg
Come si vede in figura 20.20 non è possibile propagare il dato non essendo ancora disponibile.
L’unico modo per ovviare a questo tipo di problema consiste nel ritardare di un ciclo
l’istruzione sub e far intervenire quindi la propagazione per non perdere un ulteriore ciclo,
come mostrato in figura 20.21.
Time (clock cycles)
F
X
Reg
Bub
ble
Im
M
W
Dm
Reg
Reg
ALU
sub r4,r1,r3
D
ALU
lw r1,0(r2)
Im
Dm
Reg
Figura 20.21 Soluzione con bolla
20.5 CRITICITA’ SUI SALTI DI TIPO “BRANCH”
Fino ad ora abbiamo considerato criticità che coinvolgono le operazioni aritmetiche ed i
trasferimenti di dati. Esistono anche criticità che coinvolgono i salti condizionati. La prima
soluzione che ci viene in mente potrebbe essere simile a quella utilizzata per le situazione di
stallo, cioè fare attendere l’istruzione di salto fino a quando non sia stata completata
l’istruzione precedente. Se la logica di decisione del salto si trova nello stadio di ALU,
avremmo al momento del salto due istruzioni già all’interno della pipeline. Questa prima
soluzione fa sì che si generi in pipeline un ritardo di due cicli di clock.
Dato che la logica di decisione del salto e’ data da un comparatore e da una somma per
calcolare l’indirizzo effettivo del salto (target del salto), un’idea per salvare un ciclo di clock
potrebbe essere di spostare il comparatore e il calcolo del branch target nello stadio di
decodifica. Non appena l’istruzione viene decodificata si puo’ cosi’ decidere se saltare o meno.
Quindi, il ritardo in pipeline associato ad salto di tipo branch diventerà di un ciclo, come
mostrato nelle prossime due figure (20.21 e 20.22) dove viene anche illustrato il circuito
logico che anticipa la decisione dei salti nello stadio di decode.
Beq
Load
I$
Reg
I$
D$
Reg
Reg
D$
Reg
bub
ble
I$
Reg
ALU
Add
ALU
O
r
d
Time (clock cycles)
ALU
I
n
s
t
r.
Figura 20.21 Criticità sui salti
20.14
D$
Reg
F.Flush
Hazard
detection
unit
M
u
x
D/ X
WB
Control
0
M
u
x
F/ D
4
M
WB
EX
M
M/W
WB
Shift
left 2
Registers
PC
X/M
M
u
x
=
Instruction
memory
ALU
Data
memory
M
u
x
M
u
x
Sign
extend
M
u
x
Forwarding
unit
Figura 20.22 Schema logico per l’anticipo del salto durante lo stadio di decodifica
Dato che il processore MIPS non fa niente per bloccare l’istruzione di salto il compito di
ritardare di un ciclo le istruzioni successive ad un salto di tipo “branch” e’ lasciato al
programmatore, il quale dovra’ inserire dopo una istruzione beq (ma anche j e jal per motivi
diversi) una istruzione di tipo nop (no operation) o nei casi piu’ fortunati una istruzione
precedente il cui spostamento non provochi effetti collaterali. Questa tecnica non apporta
nessun rischio nell’esecuzione corretta del codice e sfrutta questo ciclo di attesa associato
alle istruzioni di branch (chiamato Branch Delay Slot), in quanto inserendo una bolla otteniamo
lo stesso comportamento visto nella figura 20.22. I compilatori moderni riordinano il codice
proprio per approfittare di questo slot inserendo istruzioni che andrebbero eseguite a
prescindere dall’esecuzione del salto e tipicamente riescono ad utilizzare questa tecnica nel
50% dei casi. Un esempio è mostrato nella figura 20.23.
20.15
Nondelayed Branch
or
$8, $9 ,$10
Delayed Branch
add $1 ,$2,$3
add $1 ,$2,$3
sub $4, $5,$6
sub $4, $5,$6
beq $1, $4, Exit
beq $1, $4, Exit
or
xor $10, $1,$11
xor $10, $1,$11
Exit:
$8, $9 ,$10
Exit:
Figura 20.23 Situazioni di stallo
Se i salti non sono eseguiti nella metà dei casi e se costa poco scartare le istruzioni, questa
ottimizzazione dimezza il costo delle criticità sul controllo.
20.6 GESTIONE ECCEZIONI IN PRESENZA DI PIPELINE
Durante l’esecuzione in pipeline possono esser generate eccezioni di vario tipo come visto nel
capitolo 9: indirizzi errati, istruzioni sbagliate, overflow e indirizzi sbagliati dei dati. Quando
si genera un’eccezione, bisogna gestirla eseguendo una procedura idonea al controllo della
stessa, in modo tale da non avere dati non validi nei registri. Generalmente nella pipeline
abbiamo in esecuzione cinque istruzioni nei cinque diversi stadi, stando così le cose se viene
generata un’eccezione sorgono alcuni problemi aggiuntivi: i) come interrompere l’esecuzione
della pipeline e ii) come riprendere l’esecuzione. In tabella 2 e fig. 20.25 sono mostrati gli
stadi in cui i vari tipi di eccezione possono essere generati.
Tabella 2. Stadi ed eccezioni.
Stadio
IF
ID
EX
MEM
Eccezioni
page fault durante il fetch dell’istruzione; disallineamento nell’accesso alla
memoria istruzioni; violazione della protezione della memoria istruzioni
codice d’istruzione (opcode) non definito
eccezione aritmetica
page fault durante il fetch del dato; disallineamento nell’accesso alla memoria
dati; violazione della protezione della memoria dati; errore di memoria dati
20.16
IAU
npc
I mem
Regs
lw $2,20($5)
rivelare indirizzo sbagliato dell’ istruzione
PC
rivelare istruzione sbagliata
B
A
im
n op
rd
rivelare overflow
alu
S
rivelare indirizzo sbagliato dei dati
D mem
M
Regs
Permettere l’eccezione
Figura 20.24 Gestione delle eccezioni
Se ci troviamo nella condizione di dover eseguire una routine di gestione dell’errore, è chiaro
che dalla pipeline va eliminata l’istruzione successiva a quella che ha generato l’errore e al suo
posto va inserita l’istruzione del nuovo indirizzo (quella che deve gestire l’eccezione), mentre
l’indirizzo dell’istruzione che ha generato l’eccezione viene salvato nell’EPC (Exception
Program Counter), inoltre la pipeline viene svuotata in modo da riportarsi all’ultimo stato
sicuro dell’esecuzione del programma. In pratica viene congelata la parte iniziale della pipeline
e nella parte di pipeline coinvolta nell’eccezione (dallo stadio in cui si è verificata fino in
fondo) vengono inserite delle bolle come si vede in figura 20.25.
IAU
npc
I mem
Regs
op rw rs rt
freeze
PC
bubble
B
A
im
n op rw
alu
S
n op rw
D mem
m
n op rw
Regs
Figura 20.25 Soluzione alla gestione delle eccezioni
In realtà potrebbero anche verificarsi eccezioni simultanee. Normalmente si associa una
priorità alle eccezioni in modo da sapere quale deve essere gestita per prima, questo tipo di
strategia funziona anche per i calcolatori con pipeline, in particolare nelle implementazioni
20.17
MIPS dove i circuiti ordinano le eccezioni in modo che venga interrotta l’istruzione eseguita
per prima.
20.7 CENNI A PIPELINE PIU’ LUNGHE E SUPERSCALARI
Idealmente il massimo incremento di velocità su una pipeline è legato al numero degli stadi che
possiede come già detto in precedenza (vedi figura 20.26), è per questo che sono state
progettate le superpipeline ovvero pipeline più lunghe. Concettualmente. tornando all’esempio
della lavanderia, è possibile dividere il processo di lavaggio su tre macchine differenti, una
che lava, una che risciacqua e una che centrifuga, a questo punto è possibile cercare di
suddividere qualcuna delle fasi sopradescritte in due o più microfasi, allo stesso modo la
pipeline passa da cinque a più stadi.
Prestazioni Relativi
Too
Deep!
2.5
2.0
1.5
Superpipelined
1.0
0.5
1
2
4
8
16
Profondita’ della pipeline
Come si vede dalla figura 20.26 questo è vero solo in parte, perché se la pipeline è troppo
profonda allora le criticità sono più frequenti e conseguentemente le prestazioni scendono,
inoltre più la pipeline è profonda più diventa difficile eseguire istruzioni che utilizzano i
risultati di altre che con pipeline piu’ brevi sarebbero gia’ pronti.
Un’altra direzione in cui si sono evoluti i processori durante gli anni 90 sono le pipeline
superscalari: esempio molto noto di processore superscalare e’ l’Intel Pentium. Realizzare
copie dei componenti interni del calcolatore in modo che sia possibile lanciare l’esecuzione di
un’istruzione da parte di più stadi della pipeline sta alla base del concetto di pipeline
superscalare, un po’ come se nella nostra solita lavanderia avessimo tre lavatrici e tre
asciugatrici. Lo svantaggio sta nel lavoro addizionale che serve per tenere occupate tutte le
macchine e per trasferire il lavoro da uno stadio all’altro. Inoltre per programmi sequenziali
diventa veramente difficile riuscire a parallelizzare le istruzioni. Se cio’ riesce sarebbe
effettivamente possibile eseguire più istruzioni contemporaneamente ad ogni clock.
Alcuni studiosi hanno cercato di capire se nei programmi sia effettivamente possibile lanciare
piu’ istruzioni in parallelo (Istruction Level Parallelism o ILP). Nel corso degli anni, molti hanno
dato la propria valutazione del numero di istruzioni che si puo’ mandare in parallelo
mediamente (figura 20.27).
20.18
Weiss and Smith [1984]
1.58
Sohi and Vajapeyam [1987]
1.81
Tjaden and Flynn [1970]
1.86 (Flynn’s bottleneck)
Tjaden and Flynn [1973]
1.96
Uht [1986]
2.00
Smith et al. [1989]
2.00
Jouppi and Wall [1988]
2.40
Johnson [1991]
2.50
Acosta et al. [1986]
2.79
Wedig [1982]
3.00
Butler et al. [1991]
5.8
Melvin and Patt [1991]
6
Wall [1991]
7 (Jouppi disagreed)
Kuck et al. [1972]
8
Riseman and Foster [1972]
51 (no control dependences)
Nicolau and Fisher [1984]
90 (Fisher’s optimism)
Figura 20.27 Istruction Level Parallelism
In fig. 20.28 e’ mostrato un confronto fra le tecniche di superpipelining e superscalare.
SUPERSCALAR
Key:
IFetch
SUPERPIPELINED
0
1
2
3
4
5
6
7
Time in Cycles (of Base Machine)
8
9
Dcode
Execute
Writeback
10
11
12
13
Figura 20.28 Confronto tra Superscalari e Superpipeline
Una pipeline superscalare, per poter funzionare correttamente ha necessita’ di ricorrere a
tecniche quali la schedulazione dinamica della istruzioni : utilizzando circuiti addizionali si può
permettere alle istruzioni pronte di essere eseguite in parallelo. Le istruzioni possono cosi’
essere eseguite negli stadi di esecuzione anche in ordine diverso da quello del programma
(completamento fuori ordine): uno stadio finale fara’ in modo di riordinare le istruzioni che
abbiano via via completato la lor esecuzione. Il processore Alpha 21264 con l’uso di pipeline
più lunghe, superscalari e della schedulazione dinamica, esegue sei istruzioni per clock e nel
1997 raggiungeva i 600 MHz di frequenza.
Altri tipi di processori sono il VLIW (Very Long Istruction Word) nel quale le istruzioni
formate da pacchetti preschedulati dal compilatore in modo tale che le istruzioni di ogni
pacchetto possano essere eseguite in parallelo; in questo caso si hanno miglioramenti di
efficienza e maggior velocita’ di elaborazione rispetto ad un processore supercalare.
20.19
Altri tipi di parallelilismo (figura 20.29) che possono essere sfruttati riguardano i
comportamenti vettoriali dei dati: i sistemi SIMD (Single Istruction Multiple Data) realizzano
operazioni vettoriali come nel caso i processori grafici, o nelle istruzioni di supporto alla
multimedialita’, come negli standard MMX, SSE, SSE2, SSE3 di Intel.
Infine, spesso vengono abbinati tecniche predittive e speculative per cercare di prevedere il
flusso delle istruzioni e ridurre l’impatto di eventuali svuotamenti della pipeline dovuti a cause
varie.
Tipologia
Struttura
Pipelining
IF D Ex M
IF D Ex
IF D
IF
Super-pipeline
W
M W
Ex M W
D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
-Issue one instruction per
(fast) cycle
- ALU takes multiple cycles
Super-scalar
IF D Ex M W
IF D Ex M W
- Issue multiple scalar
instructions per cycle
Limitazioni
Issue rate
FU stalls
FU depth
Clock skew
FU stalls
FU depth
Hazard resolution
IF D Ex M W
IF D Ex M W
Packing
VLIW
-Each instruction specifies
multiple scalar operations
-Compiler determines
parallelism
IF D Ex
Ex
Ex
Ex
M
M
M
M
W
W
W
W
Applicability
SIMD
- Each instruction specifies
series of identical operations
IF D Ex M W
Ex M W
Ex M W
Ex M W
Figura 20.29 Pipelining nei processori
Invece, la tendenza della prima decade degli anni 2000 è quella di sfruttare lo spazio sul chip
non per aumentare la frequenza, ma per inserirvi altri processori in modo da poter sfruttare il
parallelismo di due o più processori.
20.9 RIFERIMENTI BIBLIOGRAFICI
[1] D.A. Patterson, J.L. Hennessy, "Struttura e Progetto dei Calcolatori" 2a edizione ITALIANA
(traduzione della 3a edizione inglese), Zanichelli, Luglio 2006, ISBN 978-88-08-09145
20.20
Scaricare