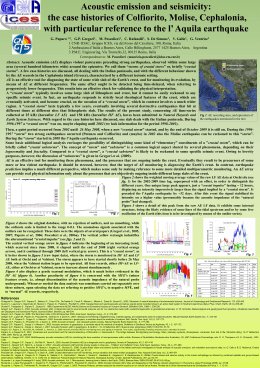
Prosodic prominence detection in Italian connected speech 1 2 2 Fabio Tamburini , Pier Marco Bertinetto , Chiara Bertini 1 2 FICLIT, University of Bologna, Italy Scuola Normale Superiore, Pisa, Italy [email protected], [email protected], [email protected] Prosodic Prominence A fairly uncontroversial definition of prosodic prominence due to [15] states: “prominence is the property by which linguistic units are perceived as standing out from their environment". There is also a large agreement among scholars to consider the syllable as the prominence bearing unit in connected speech. Automatic Prominence Detection Several recent contributions propose different models (both rulebased and machine learning systems - MLS) for the automatic detection of prominence in various languages (e.g.: [1, 2, 3, 6, 7, 8, 12, 13]). Some of them refer to Italian [1, 5, 9, 14]. In this paper we present a system for the identification of prosodic prominence in Italian in the framework of MLS, based on training procedures that extract data and models from annotated corpora by only considering acoustic features (nucleus and syllable duration, energy and spectral emphasis measures in the nuclei and specific pitch profiles in the utterance). Prominence identification requires MLS able to properly model sequences of events. Conditional Random Fields (CRF) have been successfully applied to such task with encouraging results [5, 11]. Despite these findings, CRF and their complex family of model variations have not yet been extensively studied, especially considering hidden or latent dynamics detection in label data and the extraction of high order relations among acoustic features. In this work we presents some experiments on Italian based on CRF and on Conditional Neural Fields (CNF) [10]. By inserting a small neural network between inputs and outputs, CNF models are able to capture nonlinearities in input speech features. Figure 1: The Probabilistic Graphical Models considered in this study. The task consisted in selecting the prominent syllables. Each sentence was presented on a screen with the linguistically stressed syllables marked as prominent; the subjects had to either confirm, or modify the initial proposal according to their own perception. Each sentence could be listened as many times as the individual subject liked. This yielded four different levels of inter-subject agreement: 60%, 70%, 80%, 90%, depending on how many subjects agreed in indicating the prominent syllables in the test sentences. 80% was chosen as the reference annotation. Experiments We made a number of experiments by using CRF and CNF (but we plan to test more models in the future) and different parameter configurations, in order to maximize the agreement with the human annotators, applying a random sub-sampling validation to define the training and test set (adopting a 3/1 proportion), repeating this procedure 10 times and averaging the results: Table 1: Results (Parameters: window length=2, g=20). Accuracy Precision Recall F-measure CRF 0.861 0.756 0.665 0.707 CNF 0.873 0.791 0.705 0.743 The accuracy and F-measure are very high, considering that a typical inter-human agreement reported in the literature, when using two levels (prominent, non-prominent), is in the range 7090%, and considering that: • the training corpus used to set up the model is rather small, as it contains only 45 utterances - about 900 syllables (in future work we shall increase the number of utterances); • we only used acoustic information although, as outlined by [4, 16], prominence perception is highly influenced by the listener’s linguistic expectations. References [1] Abete, G., Cutugno, F., Ludusan, B., Origlia, A. (2010). “Pitch behavior detection for automatic prominence recognition", in Proc. of Speech Prosody 2010, Chicago. [2] Al Moubayed, S., Beskow, J. (2010). “Prominence detection in Swedish using syllable correlates", in Proc. of Interspeech 2010, Makuhari, Japan. [3] Brenier, J.M., Cer, D.M., Jurafsky, D. (2005). “The detection of emphatic words using acoustic and lexical features", in Proc. of Interspeech 2005, Lisbon, 3297-3300. [4] Cole, J., Mo, Y., Hasegawa-Johnson, M. (2010). “Signal-based and expectation-based factors in the perception of prosodic prominence". Laboratory Phonology, 1, 425-452. [5] Cutugno, F., Leone, E., Ludusan, B., Origlia, A (2012). “Investigating syllable prominence with conditional random fields and latent-dynamic conditional random fields", in Proc. of Interspeech 2012, Portland (OR). Corpus building and data collection The Italian corpus used in our study consists of 60 sentences (30 read and 30 semi-spontaneous) stemming from the Pisa corpus of AVIP (Archivio Vocale dell’Italiano Parlato). The selected sentences, phonetically segmented in the original corpus, are in the range from 11 to 35 syllables. They do not contain intonation breaks of any sort and are characterized by plain intonation contour (no emphasis). They all feature declarative intonation. Each sentence was submitted to 10 subjects for a listening test. There were three groups of subjects, with each group evaluating 40 sentences (half read, half spontaneous). [6] Goldman, J-P., Avanzi, M., Auchlin, A., Simon, A.C. (2012). “A continuous prominence score based on acoustic features", in Proc. of Interspeech 2012, Portland (OR). [7] Kocharov, D. (2010). “Automatic detection of prominent words in Russian Speech", in Proc. of the IEEE International Multiconference on Computer Science and Information Technology, 435-438. [8] Li, K., Zhang, S., Li, M., Lo, W-K., Meng, H. (2011). “Prominence model for prosodic features in automatic lexical stress and pitch accent detection", in Proc. of Interspeech 2011, Florence, 2009-2013. [9] Ludusan, B., Origlia, A., Cutugno, F. (2011). “On the use of the rhythmogram for automatic syllabic prominence detection", in Proc. of Interspeech 2011, Florence, 2413-2417. [10] Peng, J., Bo, L. and Xu, J. (2009), ?Conditional Neural Fields?, in Proc. Neural Information Processing Systems (NIPS), Vancouver, Canada. [11] Shridar, V.K.R, Nenkova, A., Narayanan, S., Jurafsky D. (2008). “Detecting prominence in conversational speech: pitch-accent, givenness and focus", in Proc. of Speech Prosody 2008, Campinas, Brazil. [12] Tamburini F. (2006). “Reliable Prominence Identification in English Spontaneous Speech", in Proc. of Speech Prosody 2006, Dresden, PS1-9-19. [13] Tamburini F., Wagner P. (2007). “On Automatic Prominence Detection for German", in Proc. of InterSpeech 2007, Antwerp, 1809-1812. [14] Tamburini F. (2009). “Prominenza frasale e tipologia prosodica: un approccio acustico", in Proc. Linguistica e modelli tecnologici di ricerca, XL congresso internazionale di studi, Società di Linguistica Italiana, Vercelli, 437-455. [15] Terken, J. (1991). “Fundamental Frequency and Perceived Prominence", Journal of the Acoustical Society of America, 89, 1768-1776. [16] Wagner, P. (2005). “Great Expectations ? Introspective vs Perceptual Prominence Ratings and their Acoustic Correlates", in Proc. of Interspeech 2005, Lisbon, 2381-2384.
Scaricare