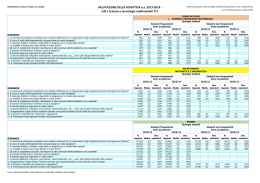
Statistica Descrittiva Alcune precisazioni Come si calcola «a mano» la moda? • si ordina il dataset in maniera crescente e si assegna a ciascun valore la sua posizione • si conta il numero di valori che stanno in ciascuna posizione • si determina la posizione «più affollata» • il valore relativo a questa posizione è la moda N.B. Nel caso in cui si trovi più di un valore, si sceglie il più piccolo 15 5 7 5 16 12 3 5 8 12 3 5 5 5 7 8 12 12 15 16 1 2 2 2 3 4 5 5 6 7 1 3 1 Moda= 5 1 2 1 1 Come si calcola «a mano» la mediana? • si ordina il dataset in maniera crescente e si assegna a ciascun valore la sua posizione • se il dataset è composto da un numero dispari di valori, la mediana è il valore che sta nella posizione (n+1)/2 • se il dataset è composto da un numero pari di valori, la mediana è dato dalla media dei due valori che stanno nelle posizioni n/2 e (n/2)+1 15 5 7 5 16 12 3 5 8 12 3 5 5 5 7 8 12 12 15 16 1 2 3 4 5 6 7 8 9 10 Mediana= (8+7)/2=7,5 Come si calcola «a mano» il percentile di ordine m ? • si ordina il dataset in maniera crescente e si assegna a ciascun valore la sua posizione • si arrotonda il risultato della formula m% 1 n 100 2 • il risultato che si ottiene è la posizione nella serie ordinata del percentile desiderato N.B. Questo è solo uno dei tanti modi disponibili 15 5 7 5 16 12 3 5 8 12 3 5 5 5 7 8 12 12 15 16 1 2 3 4 5 6 7 8 9 10 63 1 10 6,8 7 100 2 63-esimo percentile = 12 Analisi della varianza La situazione in teoria Campione di n*m elementi: x 1 1 , , x n 1 x 1 2 , , x n 2 x 1 m , , x n m n: numero di repliche m: numero di trattamenti Le formule m n Media del trattamento: Xj x i 1 i j Media totale: X n X j j 1 m m Devianza dovuta ai trattamenti (TRA): dev TRA n * ( X j X )2 j 1 m Devianza totale: s 2TRA dev TRA m 1 n dev ( x i j X )2 dev s m *n 1 2 j 1 i 1 Devianza interna ai trattamenti (IN): dev IN dev dev TRA m m n j 1 j 1 i 1 2 dev ( x X ) j j i j s 2 IN dev IN m *n m In generale L’analisi della varianza è una metodologia per verificare se due o più popolazioni sono caratterizzate dalla stessa media (o più medie sono estratte dalla stessa popolazione) In particolare Nell’analisi della varianza a una via si considera una sola causa di variazione (detta Fattore, Trattamento, Livello, etc…) nell’esito di ciascun esperimento Ipotesi Nulla: Le popolazioni da cui sono stati estratti i campioni hanno tutte la stessa media μ1= μ2 = … = μm Statistica del test: s 2TRA Rapporto F 2 s IN Se i campioni possono venir considerati estratti dalla stessa popolazione (o da popolazioni con media uguale, il Rapporto F dev’essere circa uguale a 1 e si comporta come una distribuzione di Fisher con m-1 e n-m gdl Se il valore calcolato Rapporto F è più grande del valore tabulato Fα(m-1, m-k), allora si può rifiutare l’ipotesi nulla all’ α % di significatività N.B. Quando questo si verifica, significa soltanto che almeno uno dei campioni si comporta in maniera diversa dagli altri. L’analisi della varianza si può usare quanto sono soddisfatte le seguenti 3 condizioni: • Osservazioni indipendenti • Distribuzione Normale della popolazione • Varianza omogenea per ciascuno dei campioni
Scaricare