☰
Esplorare
registrati
Iscriviti
Caricare
×
Scaricare
senza categoria
mpeg1_2005 - Dipartimento di Ingegneria dell`Informazione
Diapositiva 1
Le parole del potere. Il potere delle parole - CRIL
La complessità del terreno presente ad est del cratere
Scarica
Diapositiva 1 - Canavese Country Club
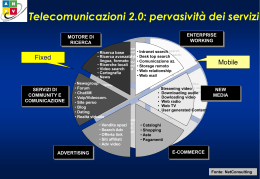
pervasività dei servizi slide rappresentativa di scenario