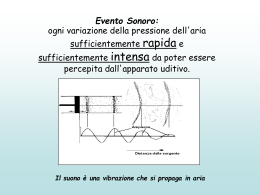
L’apparato uditivo umano e la percezione del suono 1. L’apparato uditivo Il suono come fenomeno fisico (oscillazioni delle molecole d’aria) viene percepito dal cervello umano per il tramite dell’apparato uditivo. Figura 1: L’apparato uditivo umano L’apparato uditivo è suddiviso in: - orecchio esterno, che comprende il padiglione auricolare, il canale uditivo, e termina con la membrana del timpano; - orecchio medio, costituito da una cavità piena d’aria in cui si trovano i tre ossicini detti martello, incudine e staffa. Questi collegano meccanicamente il timpano alla chiocciola (o coclea); - orecchio interno, costituito dalla coclea, che termina nel nervo acustico, diretto al cervello. Parti dell’apparato uditivo umano: 1) Padiglione auricolare: raccoglie il suono e fornisce al cervello elementi per la valutazione della direzione di provenienza dei suoni. Questa capacità è connessa alla particolare forma del padiglione auricolare umano, che si distingue da quello degli altri animali. 2) Canale uditivo: simile ad un cilindro del diametro di circa 0,7 cm e della lunghezza di circa 3 cm. Al termine del canale uditivo c’è la membrana del timpano. Le dimensioni del canale uditivo giocano un ruolo importante nella capacità dell’orecchio di percepire la voce umana e distinguerla dai rumori e dagli altri suoni. 3) Orecchio medio: ha il compito di trasmettere l’energia sonora proveniente dall’aria al fluido che riempie l’orecchio interno. I tre ossicini denominati martello, incudine e staffa, fanno sì che le oscillazioni sonore trasportate dall’aria mettano in vibrazione il fluido dell’orecchio interno. 4) Orecchio interno: è costituito dalla coclea, che trasforma gli impulsi di pressione provenienti dall’orecchio medio in impulsi nervosi (elettrici) che portano al cervello tutte le informazioni (frequenza, intensità...) relative al suono. Limiti fisiologici della percezione acustica L’orecchio non riesce a trasmettere al cervello informazioni sui suoni troppo gravi (meno di 20 oscillazioni al secondo) o troppo acuti (più di 20.000 oscillazioni al secondo – detti ultrasuoni) Inoltre i suoni di sottofondo (passi, voci lontane, musiche a basso volume, …) normalmente percepiti dall’orecchio, tendono a scomparire (non sono più trasmessi al cervello, pur essendo presenti) in presenza di suoni forti e chiari (ad esempio una voce o un suono emessi a pochi metri dall’ascoltatore). La conoscenza approfondita di questi limiti fisiologici dell’apparato uditivo umano permette oggi la rappresentazione e l’elaborazione al calcolatore di suoni e musiche che occupano poca memoria, pur presentandosi all’ascoltatore come di buona/ottima qualità, il che, come si vedrà in seguito, è di fondamentale importanza per la diffusione dell’audio digitale. I programmi e gli algoritmi che eliminano dalle registrazioni audio ciò che l’orecchio non recepisce, o a cui è poco sensibile, sono detti “algoritmi di compressione audio” perché riducono (“comprimono”) la quantità di memoria necessaria a rappresentare un suono o una voce al calcolatore. 2. Dal suono al computer Prima di tutto è necessario capire come è possibile inserire dei suoni in un computer. Un suono si propaga nell’aria sotto forma di onda. Questa onda viene trasformata da analogica a digitale attraverso un processo chiamato campionamento. Durante questa fase il suono viene scomposto in un certo numero di informazioni al secondo. Maggiori sono le informazioni, più fedele sarà la riproduzione digitale della forma d’onda. Le variabili su cui si può intervenire in fase di campionamento sono tre: • Tipo di canale (mono o stereo). • Frequenza del campione. Indica il numero di campioni presi al secondo. Esempio: 22 Khz=22.000 campioni al secondo. 11025 Hz è adatto per la registrazione della voce, 22050 Hz è adatto per la registrazione di qualità nastro mentre 44100 Hz si addice alla registrazione di qualità CD. Ridurre la frequenza di campionamento comporta una perdita di risoluzione, ovvero di qualità audio. • Dimensioni del campione di un'onda (8 – 16 bit). Possiamo immaginare il segnale campionato come formato da tanti livelli che visivamente somigliano ad una scala, la quale segue un andamento il più fedele possibile alla forma d’onda originale. Gli 8 bit offrono una qualità acustica inferiore rispetto a quella di un nastro perchè rendono in 256 valori le informazioni sui livelli dei campioni. I dati d'onda a 16 bit producono invece la massima qualità sonora (16 bit =65.536 valori sui livelli) paragonabile a quella di un CD. Convertendo campioni da 16 bit a 8 bit si dimezza il file originario ma contemporaneamente si riduce pesantemente la qualità della musica. Figura 2: Frequenza e dimensioni di un campione d’onda L’elaborazione di files audio L’elaborazione di files audio con un computer è sempre stata una delle attività più esose sia dal punto di vista della potenza di calcolo, sia dal punto di vista della memoria volatile (RAM) e di massa (Hard Disk) richieste. Questo deriva dal fatto che un segnale audio analogico, se tradotto in digitale con la qualità cosiddetta 'da CD', implica la memorizzazione di 176400 byte ogni secondo: una mole ragguardevole di dati, soprattutto per i computer di qualche anno fa. Per questo e per altri motivi oggi, nel mondo dei computer multimediali, c’è bisogno di dischi fissi e memorie sempre più capienti e sempre più veloci, nonché di processori in grado di sviluppare potenze di calcolo sempre maggiori. Ma perché un segnale audio richiede tanti byte/secondo per essere memorizzato? La risposta deriva dal teorema del campionamento, o 'Teorema di Shannon'. In breve questo dice e dimostra che, per non perdere informazione durante il campionamento (passaggio da analogico a digitale) di un segnale, la frequenza di campionamento, cioè la frequenza con cui si va a leggere il valore analogico del segnale e lo si traduce in digitale, deve essere almeno doppia della frequenza massima contenuta nel segnale. Se così non si fa, non solo si perde parte del segnale di partenza, ma si introducono frequenze spurie nel segnale campionato che saranno evidenti nel successivo passaggio da digitale ad analogico. Tornando in particolare al suono, l'orecchio umano riesce a sentire frequenze massime attorno ai 18KHz (la cosa è soggettiva e può variare da 17KHz a 19KHz, ma molto raramente si oltrepassano questi limiti). Per garantire quindi che un suono venga campionato completamente senza perderne la parte più acuta, supponendo una frequenza massima di 20KHz, si dovrà campionare ad una frequenza di almeno 40KHz. C’è però un particolare: un segnale sonoro analogico contiene anche frequenze superiori ai 20KHz (anche se noi non le sentiamo) che possono causare l'insorgere di altre frequenze nella gamma udibile se si campiona a 40KHz. Per questo è necessario, prima di campionare un suono, sottoporlo a filtraggio in modo da ridurre quanto più possibile le frequenze non desiderate, ovvero quelle superiori a 20KHz. Siccome i filtri analogici non hanno un andamento del tipo 'passa/nonpassa', ma hanno un'attenuazione che aumenta all'aumentare della frequenza seguendo una curva, bisognerà fare in modo che questo filtro non tagli troppo le frequenze uguali o inferiori a 20KHz, ma appena oltrepassato tale limite l'attenuazione aumenti parecchio. Si è calcolato che l'attenuazione diventa sufficiente a ridurre molto gli effetti indesiderati introdotti dalle alte frequenze quando si superano i 22KHz: per questo i CD e tutti gli apparati che trattano segnali audio digitali lavorano alla frequenza di 44.1KHz, un po' più del doppio di 22KHz. In realtà le apparecchiature professionali lavorano generalmente a 48KHz o anche a frequenze superiori, questo per garantire un'ottima qualità anche quando il segnale digitale viene manipolato più volte (cosa che a 44.1KHz porterebbe ad apprezzare la leggera attenuazione introdotta dal filtro e le distorsioni dovute alle alte frequenze indesiderate). Da quanto detto si può subito calcolare la quantità di dati risultante da un campionamento audio eseguito a 44.1KHz, 16bit (per garantire un ottimo dinamismo e un alto rapporto segnale/rumore) in stereofonia: Mole_di_dati=44100[Hz]*16[bit]*2[canali]=1411200bit/secondo Dividendo per 8 questo valore si ottengono i byte/secondo, ovvero 176400, che è il valore inizialmente citato. Ridurre la mole: i “famosi” files MP3 Su cosa si basa la codifica degli mp3? La codifica MPEG Layer 3 si basa sul principio che l'orecchio umano non è in grado di udire tutto lo spettro di frequenze sonore, a differenza degli apparecchi elettronici o digitali. Per cui taglia tutto ciò che l'orecchio non sente, riducendo notevolmente la quantità di informazioni da memorizzare. Sarà poi compito del software dedicato per la riproduzione ricostruire l'informazione sonora originale. Ciò ha reso possibile la trasmissione di audio ad alta qualità tramite Internet in tempi ragionevoli e anche la deprecabile pratica di siti Web, in cui si rendono disponibili tutte le ultime novità di artisti famosi, da scaricare sul proprio computer liberamente e senza pagare alcunché. Cosi ci si ritrova hard disk pieno di top "song", che potranno essere riprodotte tramite il PC o addirittura trasformate in normali CD Audio (e quindi ascoltabili in qualsiasi lettore CD, da auto o portatile). La situazione riportata è il lato illegale degli MP3: le persone oneste possono crearsi compilation dai propri CD e portarsele in ufficio su lettori appositi come il noto iPod, oppure scaricare da Internet nuove canzoni, da siti autorizzati, che esistono e sono reali. Come funziona la COMPRESSIONE Mpeg 1 Layer 3 (mp3)? Da sempre nel campo dell'elaborazione dell'informazione si è cercato di ridurre al minimo indispensabile la quantità di dati da memorizzare per evitare di sprecare spazio nei dispositivi di immagazzinamento di massa, un tempo molto meno capienti e molto più costosi di adesso. La stessa cosa dicasi nel campo della trasmissione dell'informazione (ovvero permettere di trasferire file audio via Internet), dove una riduzione dell'effettiva quantità di dati da trasmettere permette un aumento della velocità di trasmissione degli stessi. Per questi motivi sono stati messi a punto diversi algoritmi di compressione dati che permettono di ridurre i 'vuoti' o le ridondanze di informazione e, di conseguenza, di ridurre fisicamente la quantità di dati senza però perdere l'informazione utile. Esistono in generale due tecniche di compressione: non distruttiva e distruttiva. La prima permette di comprimere dei dati e di riottenerli identici dopo la decompressione, ma generalmente si hanno rapporti di compressione nell'ordine del 2:1, rapporto che può variare a seconda del tipo di dati che si stanno comprimendo. La seconda può arrivare a rapporti molto più elevati, a seconda della 'qualità' che si intende ottenere in fase di decompressione: infatti si basa su algoritmi che, essendo fatti per un particolare tipo di dati, ne riducono la quantità riducendo la qualità dell'oggetto che rappresentano, sia esso un'immagine o un suono. I metodi non distruttivi vengono utilizzati per la compressione di file contenenti archivi, database, programmi o qualsiasi altra cosa che non può tollerare alterazioni, mentre i metodi distruttivi servono per la compressione di immagini e suoni, cose che possono subire piccole alterazioni senza perdere il significato di ciò che rappresentano (un ottimo esempio, in tal senso, è il diffusissimo algoritmo di compressione delle immagini JPG che permette di ottenere immagini molto ridotte in termini di kilobytes con modifiche in alcuni casi appena percettibili dell’immagine stessa). Venendo al sodo, la compressione Mpeg fa parte di quelle a tecnica distruttiva, infatti si usa per ridurre la dimensione di filmati e/o suoni. Il più diffuso nella famiglia Mpeg è il formato Mpeg 1 Layer 3 (abbreviato in MP3), appositamente studiato per l'audio e in grado di dare risultati sorprendenti: basti pensare che si può comprimere un campionamento con un rapporto 11:1 senza praticamente perdita di qualità! Un minimo di differenza dall'originale lo si può avvertire solo se si è di orecchio fine, ma per la maggioranza delle applicazioni, escludendo l’utilizzo professionale, vale la pena di utilizzare questa compressione. Oltre a venire a vantaggio dello spazio occupato, la compressione MP3 favorisce la diffusione di materiale musicale tramite reti informatiche, soprattutto Internet. Infatti si può dire che comprimendo un file .WAV in qualità CD col rapporto 11:1 si ottiene un file .MP3 le cui dimensioni sono di circa 1MB al minuto: un intero brano musicale di 5 minuti, che normalmente occuperebbe più di 50MB, si può ridurre a meno di 5MB senza alterarne la qualità! La domanda che sorge spontanea a questo punto è: "Ma com’è possibile che si possa ridurre tanto la quantità di dati in un file audio senza perdere qualità?". A questa domanda si può dare una risposta pensando a quanto affermato in precedenza sui limiti dell’orecchio umano: tale algoritmo, a differenza dei precedenti che si basavano sulla riduzione della banda audio e della dinamica, trae primario vantaggio dal fatto che la compressione viene fatta tenendo conto delle imperfezioni e della limitata sensibilità dell'orecchio umano. Per approfondire il concetto di compressione audio digitale si può consultare la pagina di Wikipedia: http://it.wikipedia.org/wiki/Compressione_audio_digitale
Scaricare