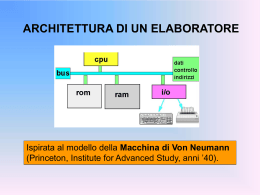
Informatica Generale Marzia Buscemi [email protected] Ricevimento: Giovedì ore 16.00-18.00, Dipartimento di Informatica, stanza 306-PS o per posta elettronica Pagina web del corso: http://www.di.unipi.it/~buscemi/IG07.htm (sommario delle lezioni in fondo alla pagina) 1 Struttura di un calcolatore RAM (memoria centrale) 5 Processore bus Linee dati, indirizzi e controllo Interfaccia di I/O Interfaccia di I/O Interfaccia di I/O Interfaccia di I/O schermo dischi mouse modem 2 Il processore: struttura base M e m o r i a c e n t r a l e PC Bus controllo Bus indirizzo Bus dati Operazione M A R Esegui IR Unità di controllo Registro/i coinvolti M D R R0 R1 R2 ... R16 ALU Registri generali clock Esito Processore 3 Interazione con la CPU: esempi Supponiamo di avere una CPU con parallelismo a 16 bit, cioè tutte le operazioni di lettura/scrittura in memoria riguardano parole (word) composte da 2 byte. Vedremo tre esempi: instruction fetch: il codice operativo dell’istruzione viene copiato dalla memoria principale in IR immediate operand fetch: il dato che segue in memoria il codice operativo viene copiato (es. istruzione “MOVE 1,R0”) memory store: un dato contenuto in un registro viene scritto in memoria all’indirizzo contenuto in un altro registro 4 Instruction fetch Indirizzo della istruzione memoria Bus controllo 40 40 111..01 41 001..01 Bus indirizzo Bus dati M A R PC Esegui IR Parte controllo Registro/i coinvolti M D R R0 R1 R2 ... R16 codifica Operazione ALU Registri generali Esito Processore 5 Instruction fetch 2 Indirizzo della istruzione memoria Leggi! 42 40 111..01 Operazione PC Esegui IR 41 001..01 Parte controllo 40 Bus indirizzo Bus dati MAR M D R Registro/i coinvolti R0 R1 R2 ... R16 codifica ALU Registri generali Esito Processore 6 Instruction fetch 3 memoria 42 40 111..01 PC 111..01 001..01 41 001..01 Bus indirizzo MAR Bus dati MDR Operazione Esegui IR Parte controllo Registro/i coinvolti R0 R1 R2 ... R16 ALU Registri generali Esito Processore 7 Immediate operand fetch: MOVE 1, R0 Indirizzo della istruzione memoria Leggi! 44 40 111..01 41 001..01 42 000..00 Bus 43 000..01 indirizzo Bus dati PC Esegui IR Parte controllo 42 MAR M D R Registro/i coinvolti R0 R1 R2 ... R16 codifica Operazione ALU Registri generali Esito Processore 8 Immediate operand fetch: MOVE 1, R0 2 memoria 44 40 111..01 PC 111..01 001..01 41 001..01 Operazione Esegui IR Parte controllo 42 000..00 Bus 43 000..01 indirizzo MAR Registro/i coinvolti 000..00 000..01 Bus dati MDR R1 R2 ... R16 Registri generali ALU Esito Processore 9 Memory store: STORE R1, R0 1 memoria 44 40 111..01 PC 111..01 001..01 41 001..01 Operazione Esegui IR Parte controllo 42 000..00 Bus 43 000..01 indirizzo Registro/i coinvolti MAR 44 R0 45 Bus dati 44 R1 000..00 000..01 R2 MDR ... Registri R16 generali ALU Esito Processore 10 Memory store: STORE R1, R0 memoria 44 40 111..01 Operazione PC 111..01 001..01 41 001..01 2 Esegui IR Parte controllo 42 000..00 Bus 43 000..01 indirizzo Registro/i coinvolti MAR 44 000..00 R0 45 000..01 Bus dati MDR 44 000..00 000..01 R2 ... Registri R16 generali ALU Esito Processore 11 Pipelining Ogni istruzione può essere decomposta in varie fasi; es. ADD 1, R0: 1. 2. 3. 4. 5. instruction fetch instruction decode operand fetch execute operand store Eseguire queste fasi sequenzialmente è inefficiente ll processore esegue fasi diverse di più istruzioni contemporaneamente organizzando ALU e CU come in una catena di montaggio (pipeline) Es. decodifica di un’istruzione I1, lettura dalla memoria dell’istruzione I2, lettura dati che saranno necessari per I1. 12 Pipelining 2 Problema: per le istruzioni di salto condizionato la CPU non può sapere a priori se dovrà eseguire il salto prima di aver eseguito le istruzioni precedenti ( ritardi ). Possibile soluzione usata dai compilatori: riempire le fasi immediatamente successive al salto con istruzioni che non dipendono dal test (delayed load) Es. a := b + c if b < c if b < c a := b + c then S1 then S1 13 Architetture di CPU Ci sono due tipi di architetture CISC (complex instruction set computer) CU e istruzioni più complesse pochi registri RISC (reduced instruction set computer) set di istruzioni elementari molti registri 14 Architettura CISC un processore CISC ha un numero scarso di registri generali (una decina) e una unità di controllo microprogrammata. registro istruzioni registro istruzioni clock circuiti logici sequenziali CU tradizionale unità di decodifica unità di decodifica clock circuiti di generazione indirizzi memoria decoder CU microprogrammata NB. Linguaggio macchina più vicino a linguaggi di alto livello (salti condizionali) 15 Architettura RISC caratteristiche: istruzioni più semplici e uso di molti registri obiettivo: avere solo istruzioni semplici (logico-aritmetiche) che possano essere eseguite in un solo ciclo di clock le istruzioni hanno tutte un formato fisso e l’operazione di decodifica è realizzata da una semplice tabella l’unità di controllo è organizzata come una pipeline (catena di montaggio) i registri generici vanno da centinaia a migliaia e sono organizzati in file 16 CISC vs RISC CISC RISC istruzioni complesse (più cicli) istruzioni semplici (un ciclo) qualsiasi istruzione può referenziare la memoria sono le istr. LOAD e STORE referenziano la memoria no pipeline pipeline spinte istruzioni interpretate dal microprogramma istruzioni eseguite dall’HW istruzioni a formato variabile istruzioni a formato fisso pochi registri molti registri (organizzati in file) 17 Prestazioni dei processori Dipendono da diversi fattori 1. insieme delle istruzioni: istruzioni più semplici richiedono basso numero di cicli di clock 2. dimensione dei registri: determinano il parallelismo della CPU, cioè la dimensione delle word (da 16 a 64 bit) 3. numero di registri: maggior numero implica meno accessi alla memoria 4. scalarità: numero di fasi sovrapponibili (più istruzioni per cicli di clock) 5. frequenza di clock: velocità con cui si susseguono i cicli di macchina (quindi velocità di esecuzione delle istruzioni). Dipende dalla velocità di propagazione dei segnali elettrici (GHz). 18 Processore Intel Pentium Intel Pentium: architettura CISC superscalare possiede 2 pipeline, una per tutte le istruzioni, una per quelle più semplici può eseguire due istruzioni per ciclo di clock parole da 64 bit (doppia quantità di informazione che può essere caricata) branch prediction 19
Scaricare