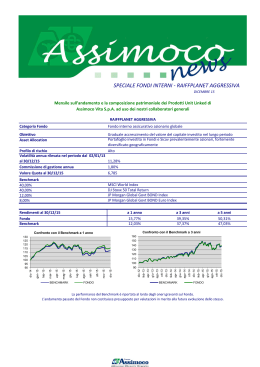
Anteprima Estratta dall' Appunto di Informatica Università : Università degli studi di Palermo Facoltà : Informatica Indice di questo documento L' Appunto Le Domande d'esame ABCtribe.com e' un sito di knowledge sharing per facilitare lo scambio di materiali ed informazioni per lo studio e la formazione.Centinaia di migliaia di studenti usano ABCtribe quotidianamente per scambiare materiali, consigli e opportunità Più gli utenti ne diffondono l'utilizzo maggiore e' il vantaggio che ne si può trarre : 1. Migliora i tuoi voti ed il tempo di studio gestendo tutti i materiali e le risorse condivise 2. Costruisci un network che ti aiuti nei tuoi studi e nella tua professione 3. Ottimizza con il tuo libretto elettronico il percorso di studi facendo in anticipo le scelte migliori per ogni esame 4. Possibilità di guadagno vendendo appunti, tesine, lezioni private, tesi, svolgendo lavori stagionali o part time. www.ABCtribe.com ABCtribe.com - [Pagina 1] L' Appunto A partire dalla pagina successiva potete trovare l' Anteprima Estratta dall' Appunto. Se desideri l'appunto completo clicca questo link. Il numero di pagina tra le parentesi tonde si riferisce a tutto il documento contenente l'appunto. Sull'appunto stesso in alcuni casi potrete trovare una altra numerazione delle pagine che si riferisce al solo appunto. Grafico dei voti medi per questo esame: Grafico dei giorni medi per la preparazione di questo esame: Grafico Copyright © ABCtribe.com. Vietata la riproduzione. Grafico Copyright © ABCtribe.com. Vietata la riproduzione. Clicca qui per i grafici aggionati su Informatica >> ABCtribe.com - [Pagina 2] Case Studies with Exercises by Diana Franklin ■ 61 In this set of exercises, you are to make sense of Figure 1.26, which presents the performance of selected processors and a fictional one (Processor X), as reported by www.tomshardware.com. For each system, two benchmarks were run. One benchmark exercised the memory hierarchy, giving an indication of the speed of the memory for that system. The other benchmark, Dhrystone, is a CPU-intensive benchmark that does not exercise the memory system. Both benchmarks are displayed in order to distill the effects that different design decisions have on memory and CPU performance. [10/10/Discussion/10/20/Discussion] <1.7> Make the following calculations on the raw data in order to explore how different measures color the conclusions one can make. (Doing these exercises will be much easier using a spreadsheet.) a. [10] <1.8> Create a table similar to that shown in Figure 1.26, except express the results as normalized to the Pentium D for each benchmark. co m b. [10] <1.9> Calculate the arithmetic mean of the performance of each processor. Use both the original performance and your normalized performance calculated in part (a). e. c. [Discussion] <1.9> Given your answer from part (b), can you draw any conflicting conclusions about the relative performance of the different processors? Ct rib d. [10] <1.9> Calculate the geometric mean of the normalized performance of the dual processors and the geometric mean of the normalized performance of the single processors for the Dhrystone benchmark. e. [20] <1.9> Plot a 2D scatter plot with the x-axis being Dhrystone and the yaxis being the memory benchmark. f. AB 1.12 [Discussion] <1.9> Given your plot in part (e), in what area does a dualprocessor gain in performance? Explain, given your knowledge of parallel processing and architecture, why these results are as they are. Chip # of cores Clock frequency (MHz) Memory performance Dhrystone performance Athlon 64 X2 4800+ 2 2,400 3,423 20,718 Pentium EE 840 2 2,200 3,228 18,893 Pentium D 820 2 3,000 3,000 15,220 Athlon 64 X2 3800+ 2 3,200 2,941 17,129 Pentium 4 1 2,800 2,731 7,621 Athlon 64 3000+ 1 1,800 2,953 7,628 Pentium 4 570 1 2,800 3,501 11,210 Processor X 1 3,000 7,000 5,000 Figure 1.26 Performance of several processors on two benchmarks. ABCtribe.com - [Pagina 3] Chapter One Fundamentals of Computer Design 1.13 [10/10/20] <1.9> Imagine that your company is trying to decide between a single-processor system and a dual-processor system. Figure 1.26 gives the performance on two sets of benchmarks—a memory benchmark and a processor benchmark. You know that your application will spend 40% of its time on memory-centric computations, and 60% of its time on processor-centric computations. a. [10] <1.9> Calculate the weighted execution time of the benchmarks. b. [10] <1.9> How much speedup do you anticipate getting if you move from using a Pentium 4 570 to an Athlon 64 X2 4800+ on a CPU-intensive application suite? c. [20] <1.9> At what ratio of memory to processor computation would the performance of the Pentium 4 570 be equal to the Pentium D 820? co m [10/10/20/20] <1.10> Your company has just bought a new dual Pentium processor, and you have been tasked with optimizing your software for this processor. You will run two applications on this dual Pentium, but the resource requirements are not equal. The first application needs 80% of the resources, and the other only 20% of the resources. e. a. [10] <1.10> Given that 40% of the first application is parallelizable, how much speedup would you achieve with that application if run in isolation? rib 1.14 b. [10] <1.10> Given that 99% of the second application is parallelizable, how much speedup would this application observe if run in isolation? c. [20] <1.10> Given that 40% of the first application is parallelizable, how much overall system speedup would you observe if you parallelized it? Ct ■ AB 62 d. [20] <1.10> Given that 99% of the second application is parallelizable, how much overall system speedup would you get? ABCtribe.com - [Pagina 4] m co e. rib Ct AB ABCtribe.com - [Pagina 5] m co e. rib Ct 2.9 2.10 2.11 2.12 2.13 Instruction-Level Parallelism: Concepts and Challenges Basic Compiler Techniques for Exposing ILP Reducing Branch Costs with Prediction Overcoming Data Hazards with Dynamic Scheduling Dynamic Scheduling: Examples and the Algorithm Hardware-Based Speculation Exploiting ILP Using Multiple Issue and Static Scheduling Exploiting ILP Using Dynamic Scheduling, Multiple Issue, and Speculation Advanced Techniques for Instruction Delivery and Speculation Putting It All Together: The Intel Pentium 4 Fallacies and Pitfalls Concluding Remarks Historical Perspective and References Case Studies with Exercises by Robert P. Colwell AB 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 ABCtribe.com - [Pagina 6] 66 74 80 89 97 104 114 118 121 131 138 140 141 142 2 rib “Who’s first?” e. co m Instruction-Level Parallelism and Its Exploitation “America.” Ct “Who’s second?” AB “Sir, there is no second.” ABCtribe.com - [Pagina 7] Dialog between two observers of the sailing race later named “The America’s Cup” and run every few years—the inspiration for John Cocke’s naming of the IBM research processor as “America.” This processor was the precursor to the RS/6000 series and the first superscalar microprocessor. Chapter Two Instruction-Level Parallelism and Its Exploitation Instruction-Level Parallelism: Concepts and Challenges e. co m All processors since about 1985 use pipelining to overlap the execution of instructions and improve performance. This potential overlap among instructions is called instruction-level parallelism (ILP), since the instructions can be evaluated in parallel. In this chapter and Appendix G, we look at a wide range of techniques for extending the basic pipelining concepts by increasing the amount of parallelism exploited among instructions. This chapter is at a considerably more advanced level than the material on basic pipelining in Appendix A. If you are not familiar with the ideas in Appendix A, you should review that appendix before venturing into this chapter. We start this chapter by looking at the limitation imposed by data and control hazards and then turn to the topic of increasing the ability of the compiler and the processor to exploit parallelism. These sections introduce a large number of concepts, which we build on throughout this chapter and the next. While some of the more basic material in this chapter could be understood without all of the ideas in the first two sections, this basic material is important to later sections of this chapter as well as to Chapter 3. There are two largely separable approaches to exploiting ILP: an approach that relies on hardware to help discover and exploit the parallelism dynamically, and an approach that relies on software technology to find parallelism, statically at compile time. Processors using the dynamic, hardware-based approach, including the Intel Pentium series, dominate in the market; those using the static approach, including the Intel Itanium, have more limited uses in scientific or application-specific environments. In the past few years, many of the techniques developed for one approach have been exploited within a design relying primarily on the other. This chapter introduces the basic concepts and both approaches. The next chapter focuses on the critical issue of limitations on exploiting ILP. In this section, we discuss features of both programs and processors that limit the amount of parallelism that can be exploited among instructions, as well as the critical mapping between program structure and hardware structure, which is key to understanding whether a program property will actually limit performance and under what circumstances. The value of the CPI (cycles per instruction) for a pipelined processor is the sum of the base CPI and all contributions from stalls: rib 2.1 Ct ■ AB 66 Pipeline CPI = Ideal pipeline CPI + Structural stalls + Data hazard stalls + Control stalls The ideal pipeline CPI is a measure of the maximum performance attainable by the implementation. By reducing each of the terms of the right-hand side, we minimize the overall pipeline CPI or, alternatively, increase the IPC (instructions per clock). The equation above allows us to characterize various techniques by what component of the overall CPI a technique reduces. Figure 2.1 shows the ABCtribe.com - [Pagina 8] Questo documento e' un frammento dell'intero appunto utile come anteprima. Se desideri l'appunto completo clicca questo link. ABCtribe.com - [Pagina 9] Preparati con le domande di ABCtribe su Informatica. 1. Reti LAN e Risposta: Le reti LAN (Local Area Network) sono [Clicca qui >> per continuare a leggere]. 2. Funzio Risposta: Una funzione hash prende [Clicca qui >> per continuare a leggere]. * Carica Appunti,Domande,Suggerimenti su : Informatica e guadagna punti >> * Lezioni Private per Informatica >> Avvertenze: La maggior parte del materiale di ABCtribe.com è offerto/prodotto direttamente dagli studenti (appunti, riassunti, dispense, esercitazioni, domande ecc.) ed è quindi da intendersi ad integrazione dei tradizionali metodi di studio e non vuole sostituire o prevaricare le indicazioni istituzionali fornite dai docenti. Il presente file può essere utilizzato in base alle tue necessità ma non deve essere modificato in alcuna sua parte, conservando in particolare tutti i riferimenti all’autore ed a ABCtribe.com; non potrà essere in alcun modo pubblicato tramite alcun mezzo, senza diverso accordo scritto con l’autore ed i responsabili del progetto ABCtribe.com. Per eventuali informazioni, dubbi o controversie contattate la redazione all’indirizzo [email protected]. ABCtribe.com - [Pagina 10]
Scaricare