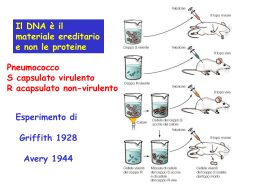
Bioinformatica - potenza elaborativa - facilità d’uso - creazione di specifici software di analisi, applicazioni ad hoc per risolvere specifici problemi biologici - accesso on-line attraverso il World-Wide Web Bioinformatics tools for Biologists Computational Biology World-Wide Web resources for Biologists La Biologia Moderna Progetti Genoma: Perchè? La determinazione e la conoscenza dell’intera sequenza genomica sembrano essere la condizione necessaria per comprendere la completa biologia di un determinato organismo In che modo? Sequenziamento del DNA significa determinazione della sequenza lineare delle basi che lo compongono, cioè A, T, C e G. Il DNA umano è composto da 3.12 miliardi di paia di basi JOE SUTLIFF Stanley Fields: Proteomics in Genomeland, Science 291, 1221, (2001). La Biologia Moderna: i Progetti Genoma Un requisito essenziale alla comprensione della biologia completa di un organismo è la determinazione della sequenza del suo intero genoma “A prerequisite to understanding the complete biology of an organism is the determination of its entire genome sequence” Fleischmann et al. 1995 2000-2001 Il Genoma Umano completamente sequenziato e assemblato LE TAPPE DEL PROGETTO GENOMA 1953 James Watson e Francis Crick determinano la struttura del DNA (La doppia elica) 1977 Gli scienziati americani Allan Maxam and Walter Gilbert e l'inglese Frederick Sanger mettono a punto 2 diversi metodi per sequenziare il DNA, cioè per "leggere" la successione di basi nucleotidiche che lo compongono. Il metodo di Sanger, oggi automatizzato, è quello tuttora utilizzato. 1985 Lo scienziato americano Kary Mullis inventa la PCR, una tecnica che permette di moltiplicare artificialmente il DNA, anche se presente in quantità minima. 1986Il premio Nobel Renato Dulbecco e Leroy Hood lanciano l'idea di sequenziare l'intero genoma Umano. 1990 Negli Stati Uniti nasce ufficialmente lo Human Genome Project (HGP), sotto la guida di James Watson. Negli anni successivi Regno Unito, Giappone, Francia, Germania, Cina si uniscono al progetto formando un consorzio pubblico internazionale. In Italia il progetto genoma nasce nel 1987 ma si interrompe nel 1995. 1992 Craig Venter lascia l'NIH e il progetto pubblico. Fonderà una compagnia privata, la Celera Genomics, portando avanti un progetto genoma parallelo. 1993 Francis Collins e John Sulston diventano direttori rispettivamente del National Human Genome Research Center negli USA e del Sanger Center in Inghilterra, i 2 principali centri coinvolti nel HGP. 1999 (Dicembre) Pubblicata su Nature la sequenza completa del cromosoma 22. 2000 (Maggio) pubblicata su Nature la sequenza completa del cromosoma 21. 2000 (Giugno) Francis Collins e Craig Venter annunciano congiuntamente di aver completato la "bozza" del genoma Umano. 2001 La bozza completa del genoma umano (che gli inglesi chiamano working draft) è pubblicata su Nature (quella del consorzio pubblico) e su Science (quella della Celera). Celera Genomics (Applera, Applied Biosystems) Istituzioni pubbliche in: USA, UK, China Francia Germania Il genoma di un virus è composto da poche migliaia di bp Dimensioni del Genoma in Megabasi Procarioti Mycoplasma genitalium Haemophilus influenzae Escherichia coli 0.58 1.83 4.7 Eucarioti Saccharomyces cerevisiae Caenorabditis elegans Drosophila melanogaster Homo sapiens 13.5 100 165 3300 La strategia che sta alla base del sequenziamento globale dei genomi viene definita “shotgun sequencing strategy” Shotgun Sequencing Strategy -Creazione di un libreria RANDOM di frammenti di DNA (taglio con nucleasi BAL 31 e non con enzimi di restrizione) -Sequenziamento di un numero SUFFICIENTEMENTE ALTO di frammenti selezionati in maniera random -Assemblaggio dei CONTIGS Assembling dei Contigs 28643 sequenze U65747 atgcaagcctacgtcctaccgcattaacagg U85746 gcattaacaggcgattagggcatcccagctgg atgccatgcaagcctacgtcctaccgcattaacagg gcattaacaggcgattagggcatcccagctgg 28643 reazioni di sequenza sono state effettuate da 8 persone utilizzando in media 14 DNA sequencer al giorno per 3 mesi. L’assembling di 24304 frammenti in 210 contigs ha richiesto 30 ore di processamento continuo su un computer SPARCenter 2000 con 512 Mb di RAM Il costo stimato è stato di 0.48 centesimi di dollaro/base sequenziata. Se la tecnologia attualmente applicata per il sequenziamento del Genoma Umano (2000-2001) venisse di nuovo applicata al genoma dell’Haemophilus influenzae il suo genoma potrebbe essere nuovamente sequenziato e assemblato in meno di un giorno! 6X coverage = 1.83 x 6 =10.98 Mbp 0.48 USD x 10 980 000 bp = 5 270 400 USD Pari a circa 5 850 144 EURO Pari a 11 327 458 322 Lire Italiane N.B. nel conteggio non sono inclusi i costi dello sviluppo della teconologia e dei software, ma soltanto i costi di reagenti e laboratori Sequenziamento di un numero SUFFICIENTEMENTE ALTO di frammenti selezionati in maniera random Il genoma dell’H. influenzae è composto da 1.83 Mbp, quante bp generate in maniera random devo sequenziare in modo da essere certo di aver sequenziato tutte le basi (tutti i frammenti) almeno una volta? 6X coverage Po =e-m Dove m è la copertura (coverage) della sequenza e Po la probabilità che una base non sia stata sequenziata Se m=1 cioè 1X coverage Po=0.37, cioè avrò il 37% del genoma non sequenziato Se m=5 cioè 5X coverage Po=0.0067, cioè avrò il 0.67% del genoma non sequenziato Bioinformatica - I Potenza elaborativa nella gestione di enormi quantità di dati di sequenza provenienti dai Progetti Genoma Dimensioni del Genoma in Megabasi Procarioti Mycoplasma genitalium Haemophilus influenzae Escherichia coli 0.58 1.83 4.7 Eucarioti Saccharomyces cerevisiae Caenorabditis elegans Drosophila melanogaster Homo sapiens 13.5 100 165 3300 Bioinformatica - II Archiviazione e organizzazione dei dati di sequenza ottenuti da vari organismi in “database” accessibili on-line attraverso il World-Wide Web www.corriere.it venerdi , 07 aprile 2000 BIOLOGIA Un «libro delle istruzioni» Un «libro delle istruzioni», la cura dei tumori è più vicina 2/5 Boncinelli Edoardo Questo messaggio contiene una gran mole di informazioni equivalenti al contenuto di un milione e mezzo di pagine stampate, un' impressionante serie di volumi che contengono il segreto della nostra realtà biologica. Questo messaggio può essere suddiviso in un certo numero di capitoli, circa 100.000, chiamati geni. Un gene è un' unità significante di senso compiuto che porta l' informazione per compiere una specifica funzione biologica (cioé una proteine, ndr). Adesso, grazie al Progetto Genoma, sapremo che cosa abbiamo nel nostro Dna, cioè quanti e quali geni abbiamo e, eventualmente, che cosa c' è fra un gene e un altro. ERA GENOMICA La sequenza completa del genoma sarà NECESSARIA a comprendere le funzioni (e disfunzioni) biologiche del nostro organismo ERA POST-GENOMICA La sola sequenza, anche se completa, del genoma sarà SUFFICIENTE a comprendere le funzioni (e disfunzioni) biologiche del nostro organismo? www.corriere.it martedi , 13 febbraio 2001 BIOLOGIA GENETICA Genoma umano, scontro sull' utilizzo dei dati Le due équipe litigano sulla disponibilità delle mappe. La Celera vuole un «pedaggio» Il gruppo di Venter ha annunciato anche la sequenza del Dna del topo Bazzi Adriana Le proteine, sono il prodotto dei geni: sono le proteine che servono a “fabbricare” un organismo, a farlo funzionare e, quando sono difettose, si rendono responsabili di malattie. Ed è proprio attraverso lo studio del funzionamento delle proteine che si potrebbe arrivare alla costruzione di nuovi farmaci…. COMPLESSITA’ BIOLOGICA METODI DI STUDIO DELLA COMPLESSITA’ BIOLOGICA 30.000? Progetti (30.000-100.000) Genoma Gene mRNA Splicing alternativo precursore proteico ?? 150.000?? Taglio della eventuale sequenza segnale Eventuali modificazioni post-traduzionali proteina matura (FUNZIONE) Interazioni proteina-proteina Network complessi ?? N.B. Il delicato equilibrio di un organismo dipende da una moltitudine di funzioni finemente organizzate e regolate da una moltitudine di proteine diverse che interagiscono tra loro in network complessi di interazioni reversibili www.repubblica.it Corsa al genoma l'ultimo traguardo I retroscena della più grande scoperta della scienza tra speranze per la medicina e interessi finanziari di CLAUDIA DI GIORGIO Un'immagine che illustra bene la situazione paragona lo stato attuale delle ricerche sul genoma alle mappe geografiche di cui disponevano i primi esploratori: sufficienti per intraprendere la navigazione del globo ma ben lontane da una rappresentazione integrale del mondo. www.corriere.it venerdi , 07 aprile 2000 BIOLOGIA Un «libro delle istruzioni» Un «libro delle istruzioni», la cura dei tumori è più vicina 3/5 Boncinelli Edoardo Nella fase immediatamente successiva si tratterà di cercare di sapere la funzione del maggior numero possibile dei nostri geni. Averli individuati tutti e conoscere la funzione di alcuni di essi non è chiaramente sufficiente a soddisfare la nostra curiosità e a venire incontro alle nostre aspettative per quanto riguarda le applicazioni alla nostra salute. Va detto subito che questa fase sarà m olto più lunga di quella che si sta per concludere e richiederà decenni, se non secoli. Il guadagno dovrebbe essere però straordinario soprattutto dal punto di vista conoscitivo. Sapremo che cosa fanno i geni di cui conosciamo qualcosa, cosa fanno qu elli che conosciamo appena e cosa fanno anche quelli che non conosciamo e che non immaginiamo nemmeno che possano esistere. La Bioinformatica ci potrà aiutare? Introni RNA ribosomali RNA transfer Regioni regolatrici (promotori, enhancer) Dimensioni del Genoma in Megabasi Numero di ORF (geni) Densità delle regioni codificanti Procarioti Mycoplasma genitalium Haemophilus influenzae Escherichia coli 0.58 1.83 4.7 473 1760 4100 1 ogni ca. 1200 bp 1 ogni ca. 1050 bp 1 ogni ca. 1150 bp Eucarioti Saccharomyces cerevisiae Caenorabditis elegans Drosophila melanogaster Homo sapiens 13.5 100 165 3300 5800 14000 12000 ?? 1 ogni ca. 2300 bp 1 ogni ca. 7000 bp 1 ogni ca. 13500 bp ?? Identificazione delle regioni codificanti meantnfmcosarjthyuyifkfmnsbzvcaxqswthyujuk bnpyoitjguryrtefdgvcbxnservejkamnsbegdfvrtty ghjukiolmmlabnvbcvxcsdfergrtbioinformatica?g jyiuoljpgkbidhgrtfydhsn meantnfmcosarjthyuyifkfmnsbzvcaxqswthyujuk bnpyoitjguryrtefdgvcbxnservejkamnsbegdfvrtty ghjukiolmmlabnvbcvxcsdfergrtbioinformatica? gjyiuoljpgkbidhgrtfydhsn
Scaricare