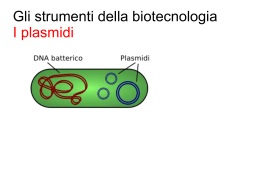
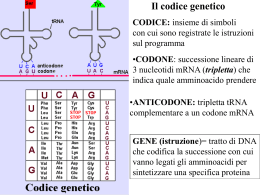
Ben presto anche la subunità maggiore si unisce al complesso e comincia così l’assemblaggio del polipeptide. Nella fase di allungamento i codoni scorrono uno per volta sul sito di lettura e i corrispondenti amminoacidi vengono uniti tra loro Una volta che il tRNA iniziatore ha occupato il suo posto nel ribosoma, il secondo tRNA carico occupa l’altro sito, ancora libero, appaiando il proprio anticodone con il secondo codone dell’mRNA che, nella Figura 9.11, è il codone CUC. Il suo complementare è il codone GAG del tRNA che trasporta l’amminoacido leucina. I due amminoacidi si vengono a trovare uno accanto all’altro e, a questo punto, avviene il trasferimento enzimatico del primo amminoacido, che si stacca dal tRNA e si lega covalentemente al secondo amminoacido, formando il primo legame peptidico. Il primo tRNA, che ha perso il suo amminoacido, si allontana e il ribosoma scorre in avanti di tre nucleotidi sull’mRNA, portando il terzo codone in corrispondenza di un sito per i tRNA. Naturalmente anche il tRNA carico dei due amminoacidi, essendo legato per appaiamento delle basi al secondo codone, slitta assieme a questo e va ad occupare il sito lasciato libero dal primo tRNA. Il resto del processo di allungamento della catena polipeptidica non è altro che il ripetersi più e più volte di questo ritornello: “Arriva una nuova molecola di tRNA che si lega al nuovo codone; la parte di catena polipeptidica già esistente si lega all’amminoacido trasportato da tale molecola e il tRNA a cui la catena era prima legata si libera e si allontana; il ribosoma si sposta di un codone lungo l’mRNA”. Il processo continua così, aggiungendo amminoacidi nella corretta sequenza, fin quando il polipeptide si è completamente formato secondo l’ordine dettato dalle istruzioni genetiche originali. La terminazione è determinata dalla comparsa di un codone d’arresto sull’mRNA La fine della sintesi del polipeptide è segnalata dalla presenza di un codone d’arresto nel filamento di mRNA. Poiché queste triplette non codificano un amminoacido, la loro presenza crea nell’mRNA una zona in cui non si può legare alcun tRNA e, di conseguenza, l’amminoacido inserito appena prima della comparsa del codone d’arresto è l’ultimo componente della catena polipeptidica. Il flusso ordinato dell’informazione genetica dalla sua forma stabile depositata nel DNA all’RNA nel quale viene trascritta e alla specifica proteina nella quale viene espressa è riassunta nella Figura 9.12. Come incrementare la produzione di proteina: far scorrere lo stesso mRNA attraverso più ribosomi A una catena polipeptidica in via di formazione vengono aggiunti circa cinque amminoacidi al secondo. Si tratta di un dato molto approssimativo dato che spesso un “nastro” di mRNA viene letto contemporaneamente da più ribosomi. Come si vede in Figura 6.14 lungo una stessa molecola di mRNA scorrono molti ribosomi e da ciascuno di essi si va sviluppando una catena polipeptidica. Una serie di ribosomi come questa è detta poliribosoma. 3) LA BASE MOLECOLARE DELLE MUTAZIONI GENICHE Le mutazioni geniche dipendono da cambiamenti di singoli nucleotidi causati da agenti fisici o chimici I cambiamenti della sequenza lineare dei nucleotidi modificano l’informazione contenuta nel DNA e sono la base molecolare delle mutazioni geniche. Per fare un esempio, l’anemia a cellule falciformi è un difetto genetico dovuto alla sostituzione di un amminoacido (acido glutammico) con un altro (un residuo di valina) nella proteina che trasporta l’ossigeno nel sangue, l’emoglobina. Il cambiamento di una tripletta del DNA da GAG a GTG determina un cambiamento del corrispondente codone dell’mRNA da GAG a GUG e ciò, a sua volta, comporta l’inserimento della valina al posto dell’acido glutammico nel polipeptide. A causa di questa semplice sostituzione di un nucleotide, viene prodotta una proteina che non funziona come dovrebbe. I globuli rossi delle persone affette da questa malattia genetica contengono infatti emoglobina S anziché la normale emoglobina A; questo è il risultato di una mutazione puntiforme che, modificando un codone, fa sì che, in due delle quattro catene polipeptidiche che formano l’emoglobina, il sesto amminoacido non sia più l’acido glutammico ma la valina (Figura 6.15). Tale modifica, apparentemente piccola, altera la conformazione dell’emoglobina al punto che le sue molecole tendono ad aderire tra loro in lunghe fibre che distorcono gli eritrociti. La sostituzione di una base del DNA è detta mutazione puntiforme, poiché influenza una sola tripletta, un solo “punto del gene”. Una simile mutazione può verificarsi durante la replicazione del DNA, se nella nuova catena viene inserito per errore un nucleotide sbagliato, o può essere la conseguenza di un danno al DNA in una cellula che non si sta dividendo. La probabilità di tali mutazioni aumenta notevolmente se il DNA entra in contatto con un agente mutageno, un agente fisico o chimico che determina modificazioni genetiche. Più grave è la mutazione che consegue all’aggiunta (inserzione) o all’eliminazione (delezione) di un nucleotide in un gene. Un simile evento scompagina la lettura dei messaggi genetici, cambiando tutti i codoni dal punto dell’alterazione in avanti. Il messaggio, letto come una sequenza scorretta di codoni, determina una proteina inservibile, perché da un certo punto in poi i suoi amminoacidi sono completamenti sbagliati. Queste mutazioni sono alla base di certe forme di anemia, come la talassemia (anemia mediterranea). A volte, la sostituzione di una base azotata con un’altra comporta la formazione di un codone di terminazione della catena polipeptidica: ciò provoca la fine prematura del processo di traduzione. Gli agenti mutageni possono avere effetti cancerogeni, ma le cellule sono protette da enzimi che riparano il DNA Un qualsiasi agente che causi mutazioni del DNA è anche un potenziale cancerogeno (un agente che provoca il cancro), dal momento che l’alterazione di certi geni può portare alla trasformazione di una cellula normale in una cellula maligna (vedi gli oncogeni nell’Obiettivo sull’uomo: Il cancro e la perdita del controllo del ciclo cellulare e i geni soppressori nell’Obiettivo sull’uomo: le aberrazioni cromosomiche e il cancro). Questa relazione tra le mutazioni e il cancro offre un modo per vagliare un gran numero di sostanze riguardo alla loro cancerogenicità, semplicemente determinandone gli effetti mutageni su organismi adatti a questo tipo di sperimentazione, come i batteri. In questo tipo di test, messo a punto da Bruce Ames dell’Università della California, i batteri vengono esposti all’azione della sostanza in questione e, dopo un certo periodo di incubazione, il numero di cellule mutate viene confrontato con il numero di mutanti comparsi in una coltura di controllo trattata allo stesso modo, tranne per l’esposizione dell’agente chimico in esame. Un numero più elevato di mutanti tra i batteri trattati con la sostanza chimica la connota come un potenziale cancerogeno per l’uomo. Il test di Ames ha permesso di individuare il potenziale cancerogeno di numerose sostanze con le quali molte persone vengono frequentemente in contatto, come certi componenti di alcune tinture per capelli, i conservanti presenti nelle carni insaccate, alcuni coloranti alimentari artificiali e il fumo di sigaretta. Il DNA è soggetto a mutazioni anche in seguito a irradiazione e, infatti, uno dei più comuni agenti mutageni è la radiazione ultravioletta (vedi Obiettivo sull’uomo: Il lato oscuro del sole). Anche in assenza di radiazione ultravioletta o di altri agenti mutageni la mutazione è inevitabile. Si stima che, in una cellula umana, il DNA sia soggetto ogni giorno a danni a varie migliaia di basi azotate! Ma le nostre cellule sopportano questo maltrattamento molecolare e mantengono le loro sequenze nucleotidiche, grazie a una serie di enzimi di riparazione che sorvegliano il DNA, individuando e riparando alterazioni e distorsioni della molecola. Durante la riparazione può occasionalmente verificarsi un errore e, di conseguenza, il DNA conterrà una mutazione. Nonostante molte mutazioni siano dannose, a volte si creano mutazioni vantaggiose, che aumentano la probabilità che un individuo sopravviva e trasmetta le sue caratteristiche ai discendenti. Queste mutazioni sono la materia prima utilizzata dall’evoluzione biologica, poiché introducono nuova informazione genetica in una popolazione, creando nuovi caratteri responsabili della diversità degli organismi. 4) L’ORGANIZZAZIONE DEL DNA NEGLI EUCARIOTI I lunghissimi filamenti di DNA devono essere ripiegati più e più volte per poter stare nel nucleo di una cellula eucariote L’unico “cromosoma” di una cellula procariote è una molecola di DNA circolare la cui lunghezza è dell’ordine del millimetro. Naturalmente questa molecola deve essere tutta ripiegata per poter stare all’interno di una cellula che, in media, ha un diametro di 1 micrometro. Se questa può sembrare davvero un’impresa, sappiate che non è nulla in confronto all’organizzazione di un cromosoma eucariote. Nelle cellule eucariote del nostro corpo ci sono circa due metri di DNA stipati in ogni nucleo, una sferetta 100'000 volte più piccola del puntino di questa “i”. Le gigantesche molecole devono quindi essere ripiegate in modo ben preciso, che consenta loro di dirigere la sintesi delle proteine e di replicarsi (e separarsi nelle due cellule figlie) senza aggrovigliarsi. I cromosomi eucarioti contengono una abbondante quantità di proteine, tra cui una serie di proteine basiche di piccole dimensioni chiamate istoni (i cui amminoacidi basici favoriscono il ripiegamento della molecola di DNA, che ha invece proprietà acide). Il filamento di DNA forma due avvolgimenti attorno a ogni nocciolo costituito dall’aggregazione di otto molecole di istone, formando i cosiddetti nucleosomi (Figura 9.13). I nucleosomi sono strettamente ravvicinati, come le perle di una collana. Nonostante l’avvolgimento del DNA nei nucleosomi riduca la sua lunghezza di circa un sesto, ciò non è sufficiente perché un filamento possa stare dentro al piccolo nucleo di una cellula che non si sta dividendo. Il filamento già avvolto si avvolge ulteriormente, formando fibre più spesse che, a loro volta, si ripiegano formando “domini (regioni) ad ansa”. La preparazione dei cromosomi (duplicati) alla separazione che ha luogo durante la mitosi richiede poi un’altra serie di passaggi che rendono il materiale ancora più compatto (i passaggi finali della Figura 9.13). 5) L’ENTITÀ DELL’ATTIVITÀ METABOLICA Il numero di proteine utilizzate dalle cellule Si stima che il genoma umano codifichi per un numero di proteine compreso tra 50'000 e 100'000, anche se una cellula umana ne produce solo una parte: da 5'000 a 20'000 circa. In ogni caso, 5'000 è il numero minimo di proteine individuate in una cellula eucariote. Tutte queste proteine possono sembrare molte, finché non si riflette su quante cose deve fare una cellula. Quasi tutte le cellule necessitano di proteine con cui costruire i propri ribosomi, le proprie membrane, il citoscheletro, in poche parole tutti i “pezzi” che permettono loro di funzionare; inoltre, devono essere in grado di reagire agli stimoli dell’ambiente circostante. Tutto ciò, assieme alle funzioni specifiche che le cellule sono chiamate a svolgere, spiega il numero elevato di proteine presenti nella maggior parte delle cellule eucariote. Alcune di queste proteine sono prodotte quasi in continuazione, mentre la produzione delle altre è “inducibile”. Le dimensioni del genoma Non sorprende quindi che, per codificare un numero così elevato di proteine, le cellule eucariote abbiano un genoma enorme. Il genoma umano contiene circa 3 miliardi di coppie di basi azotate. Per rendere questo numero un po’ meno astratto, immaginate di fare la seguente operazione: di comporre a stampa la sequenza di basi azotate dell’intero genoma umano, rappresentando tali basi con le loro iniziali, così: AATCCGTTTGGAGAAACGCGCCCTATTGGCACAAGGCTCTTCGGGTCTCTCAACGTATT AAACATATTCAAGGCTCTAGGTCCAGTAATCGTGGACTTTC… Ebbene, per scriverle tutte, occorrerebbero circa 1'000 guide telefoniche, di 1'000 pagine ciascuna, il che equivale a una successione di lettere che occupa un milione di pagine. La Tabella 6.1 riporta la dimensione dei genomi di alcuni organismi. 6) CHE COS’È UN GENE? Alla fine di questo capitolo possiamo dare una definizione più accurata del gene, l’unità fondamentale della genetica. Finora abbiamo considerato il gene come un tratto di DNA che codifica per una proteina. Ma, a proposito del processo di traduzione, abbiamo visto che i ribosomi sono composti in parte di RNA ribosomiale, codificato dal DNA. Anche in questo caso, un tratto della doppia elica del DNA si srotola e si divarica e a un dei due filamenti si appaiano i ribunonucleotidi a formare una sequenza di RNA ribosomiale; questo migra nel citoplasma e diventa parte di un ribosoma. È così grande il fabbisogno cellulare di ribosomi che c’è tutta una regione del nucleo, il nucleolo, in cui il DNA viene costantemente trascritto per produrre rRNA. Ciò premesso, ecco una definizione di gene che comprende sia le sequenze regolatrici del DNA sia i tratti di DNA in corrispondenza dei quali si ha un appaiamento di basi con ribunonucleotidi: un gene è un tratto di DNA che realizza la trascrizione di una molecola di RNA. 7) ADATTAMENTO ED EVOLUZIONE: IL FILO CONDUTTORE Il fatto che il DNA sia il materiale genetico di tutti gli organismi rivela tre aspetti significativi. In primo luogo testimonia che la sostanza è adatta a fungere da depositario delle vitali istruzioni genetiche in una forma ereditabile e “traducibile”. Non esisto altre sostanze che abbiano la stessa funzione, fatta eccezione per l’RNA di alcuni virus. Quindi, se ne è mai comparsa una, deve essere stata eliminata, probabilmente per selezione naturale. In secondo luogo la condivisione del DNA come materiale genetico riconferma che vi sono profonde relazioni tra tutti gli organismi. È praticamente impossibile che milioni di specie abbiano indipendentemente “puntato” con successo sul DNA. Più probabilmente gli organismi hanno ereditato dagli antenati non solo i caratteri, ma anche lo stesso meccanismo che li determina e ne permette l’eredità. Infine ci spiega come comparvero i caratteri che l’evoluzione plasmò in nuove specie e come gli organismi mantengono, d’altra parte, le loro caratteristiche per generazioni e generazioni. I cambiamenti nella sequenza delle molecole di DNA, cioè le mutazioni, possono creare un nuovo carattere vantaggioso e la replicazione del DNA assicura che le successive generazioni ne erediteranno il gene. Oltre che aiutarci a comprendere l’evoluzione, la genetica molecolare fornisce prove schiaccianti di questo processo. La più convincente è probabilmente l’universalità del codice genetico, per cui un certo codone determina l’inserimento nelle proteine di un determinato amminoacido in qualunque organismo, sia esso l’uomo o una pianta di lillà. Sembra proprio che tutti gli organismi della Terra abbiano ereditato il linguaggio genetico dalla stessa fonte, il comune antenato che devono aver condiviso in un momento iniziale della storia della vita. La comprensione del DNA, della sua replicazione e di come esso diriga la comparsa di un particolare carattere rafforza la rassicurante opinione che la vita possa essere spiegata razionalmente. Al suo più intimo livello la vita è governata da principi pienamente comprensibili alla mente umana, che ci spiegano non solo il funzionamento degli organismi, ma anche i meccanismi secondo i quali essi evolvono generando nuove specie.
Scaricare