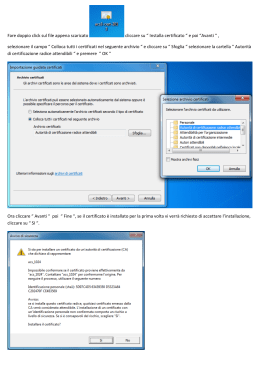
Materiali didattici: ANALISI
E PREVISIONI
NEI MERCATI FINANZIARI
a.a. 2014-2015
DISPENSA N.3
(Prof. Giovanni Verga)
1.
2.
3.
4.
5.
6.
7.
8.
Le previsioni
Il grado d’integrazione delle variabili e la cointegrazione
Come effettuare le regressioni con le variabili I(0) e I(1)
La previsione del tasso d’interesse mediante la struttura dei tassi.
La previsione del tasso mediante l’utilizzo di variabili economiche
La relazione tra Euribor e Repo
Un altro esempio di previsione: i tassi a lunga
modelli VAR per le previsioni
1
1. Le previsioni
Si consideri la relazione
(1)
Yt = F( Xt, Yt-1 , Xt-1 ) + t
(t è l’errore della stima che, in presenza di una costante
fra i regressori, si suppone abbia media nulla) 1
E si supponga che questa relazione sia stata scelta per prevedere nel momento t il valore di Y in
qualche periodo futuro t+j. La stima effettuata in t del valore in t+j della variabile Y si indica con
Et[Yt+j] (che si legge “il valore atteso in t di Yt+j”)
Si supponga inoltre che nell’istante t i valori di Xt , Yt e tutti i loro valori passati siano noti. (v.
figura) più eventualmente le stime che riguardano alcuni loro valori futuri.2
PASSATO E PRESENTE
Variabili note in t (momento attuale o
presente)
Yt, Xt, Yt-1, Xt-1, Yt-2,
Xt-2, .....
FUTURO
t+1, t+2, t+3, ...
Variabili non note in t
Yt+1, Xt+1, Yt+2, Xt+2, Yt+3, Xt+3, .....
Variabili che potrebbero essere note in t
(previsioni fatte da altri previsori, o anche
da noi stessi, sui futuri valori delle
variabili)
Et[Yt+1], Et[Xt+1], Et[Yt+2], Et[Xt+2],
Et[Yt+3], Et[Xt+3], ...
In questo caso, per effettuare in t una previsione per il successivo t+1 occorre utilizzare la relazione
(1), valida per il presente, adattata per il momento t+1, cioè con gli indici spostati in avanti di 1:
(2)
Et[Yt+1] = F( Xt+1, Yt , Xt )
Qui supponiamo per semplicità che l’errore sia di tipo additivo, il che nella realtà non è sempre vero.
In molti casi questo non è vero perché i valori di molte variabili sono noti solo con ritardo (per es. il prodotto interno
lordo con circa 5 mesi di ritardo). In questo caso le variabili Yt e Xt vanno interpretati come i valori più recenti di X
e Y disponibili in t. Il simbolo Et[Zt+j] indica la stima (o valore atteso o aspettativa) effettuata in t (suffisso sotto la
lettera E) del valore in t+j (suffisso sotto la lettera Z) della variabile Z.
1
2
2
Ma, a differenza delle variabile indipendenti Yt e Xt che in t sono note, la variabile Xt+1 non lo è.
Una previsione in t di Yt tramite la (1) è quindi possibile se e solo se è disponibile da qualche fonte
(eventualmente anche una nostra stima) una previsione Et[Xt+1] di X+1. In questo caso la previsione
di Yt+1 sarebbe data da:
(3)
Et[Yt+1] = F( Et[Xt+1], Yt , Xt )
E’ ovvio che la “bontà” di questa previsione, e quindi il grado di fiducia che possiamo accordarle,
dipende sia dalla “bontà” (precisione) delle stime dell’equazione (1), sia dalla “bontà” della stima
Et[Xt+1] della variabile Xt+1 .
Come illustrazione di questo si supponga una relazione di tipo lineare della (2):
(3’)
Yt = 0 + 10 Xt + 21 Yt-1 + 11 Xt-1 + t
Che, portata in t+1 diventa
(3’’) Yt+1 = 0 + 10 Xt+1 + 21 Yt + 11 Xt + t+1
E, ponendo Xt+1 = Et[Xt+1] + t+1
(3’”)
(dove t è l’errore della stima di Xt+1 ) si ha:
Yt+1 = 0 + 10 (Et[Xt+1] + t+1 ) + 21 Yt + 11 Xt + t+1
= 0 + 10 (Et[Xt+1] + 21 Yt + 11 Xt + (t+1 + 10 t+1 )
La varianza dell’errore complessivo (t+1 + t +1) dell’errore della nuova previsione basata sulla
stima Et[Xt+1] di Xt+1 (a parte l’improbabile caso di una forte correlazione negativa tra le due
componenti (t+1 e t +1 ) è maggiore di quella basata sul suo vero valore Xt+1 .
Ovviamente la situazione si complica ulteriormente per le previsioni in t relative al tempo t+2,
t+3,… perché in questo caso sono ancora più numerose le variabili i cui “veri” valori non sono
disponibili. Per es., per stimare il valore di Y in t+2 mediante la (1), si dovrebbe utilizzare la
relazione:
(4)
Et[Yt+2] = F( Xt+2, Yt+1 , Xt+1 )
Ma in t nessun valore dei regressori è conosciuto perché i valori di Xt+2, Yt+1 e Xt+1 saranno noti
solo nel futuro.
L’unica possibilità per usare la (4) diventerebbe quindi quella di possedere in t le stime delle
variabili indipendenti. Se queste previsioni (Et[Xt+2], Et[Yt+1], Et[Xt+1] sono disponibili, allora, ma
solo allora, è possibile effettuare in t una previsione relativa a t+2 della variabile Y:
(5)
Et[Yt+2] = F( Et[Xt+2], Et[Yt+1], Et[Xt+1] )
E’ comunque ovvio che equazioni come le (3) e la (5) saranno sempre di qualità inferiore alla (1) e
alla (2): utilizzando delle approssimazioni al posto dei veri valori dei regressori le stime
sicuramente peggiorano.
3
2. IL GRADO L’INTEGRAZIONE DELLE
VARIABILI E LA COINTEGRAZIONE
Che cosa sono le variabili I(0) (= “integrate di ordine zero” o “stazionarie”)
Si consideri una successione di variabili casuali {εt} con media nulla (E[εt+i]=0), indipendenti nel
tempo (cioè E[{εt εt-i] per ogni t e per ogni i) e varianza σ2 costante.
Una variabile casuale di questo tipo si chiama integrata di ordine zero I(0) con media nulla
perché continua ad oscillare attorno allo zero.
La variabile ut=k+ εt , si direbbe che la variabile è integrata di ordine 0 I(0) con costante perché
perché il suo valore continuerebbe ad oscillare attorno alla costqnte k. Se oscillasse attorno a
un trend lineare, come ad esempio ut=k+ht+ εt , si direbbe che è integrata di ordine zero con
trend lineare (questa caratteristica può essere indicata con I(0,T), se il trend fosse quadratico si
può scrivere I(0, T2) ).
La variabile u serebbe integrata di ordine 0 anche se fosse del tipo
ut=k+ ut-1 + εt con <1
ma in questo caso la variabile presenterebbe una certa persistenza (integrata di ordine 0 I(0) con
persistenza) dal momento che il valore in t di u risente del suo valore precedente, anche se
continuerebbe ad oscillare attorno a k.
Che cosa sono le variabili I(1) e I(2) (= “integrate di ordine 1 e 2” dette anche “non
stazionarie” o “trend stocastici”)
Si consideri il caso precedente ma con = 1.
In questo caso le caratteristiche di ut=k+ ut -1+ εt cambierebbero drasticamente. La nuova ut
diventerebbe infatti
ut=k+ ut -1+ εt
ovvero
ut - ut-1 = k+ εt
ut = k+ εt
Il valore atteso di ut sarebbe così
Et[ut]=k+ ut -1
E non esisterebbe alcun valore di equilibrio a cui tende la variabile ut . Infatti, per t+1 sarebbe:
ut+1 = k+ ut+ εt+1 = k + (k+ ut-1+ εt ) + εt+1 = 2k + ut-1+ εt + εt+1
che in t+2 diventerebbe
ut+2 = 3k + ut-1+ εt + εt+1 + εt+2
In generale, per t+i si ha:
ut+i = (1+i)k + ut 1+ (εt + εt+1 + εt+2 + …. + εt+i )
La presenza di un k0 introdurrebbe un trend lineare (1+i)k , cui si aggiungono il valore “storico”
ut-1 della variabile u e la componente stocastica (εt + εt+1 + εt+2 + …. + εt+i ).
Supponiamo ore che k=0, cioè nel caso il trend lineare non esistesse.
La relazione si ridurrebbe a:
ut+i = ut-1+ (εt + εt+1 + εt+2 + …. + εt+i )
e qualunque sia i (con i0) il valore atteso di ut+i , dato che E[εt+i]=0, sarebbe
E[ut+i ] = ut-1
4
Non esisterebbe pertanto alcun valore deterministico attorno cui la successione {ut} tende ad
oscillare. Semplicemente ogni volta la variabile oscilla attorno al suo valore precedente. Una
variabile di questo genere si dice integrata di prim’ordine I(1).
La sua varianza per i diventa
Var(lim ut+i) = Var(lim (εt + εt+1 + εt+2 + …. + εt+i )) = (σ2 + σ2 + σ2 + …. σ2 ) = i σ2 =
La successione {ut} non ha quindi varianza finita. Qualunque varianza campionaria (che è
necessariamente finita) non può essere una buona approssimazione della varianza della popolazione
(che è infinita).
Si arriva quindi alla situazione paradossale che il valore atteso dei futuri valori della variabile
corrisponderebbe all’ultima osservazione disponibile, ma il futuro valore effettivo tende ad
allontanarsi sempre più da questo valore (varianza infinita) anche se non è possibile prevederne la
direzione.
Se k fosse diverso da zero, all’andamento della u di aggiungerebbe un trend (1+i)k , ma anche in
questo caso non esisterebbe pertanto alcun valore deterministico attorno cui la successione {ut}
tende ad oscillare. Ogni volta la variabile oscillerebbe attorno al suo valore precedente + k.
La presenza di un k0 aggiungerebbe infatti un trend alla relazione, ma non muterebbe la sostanza
del problema: non esiste alcun valore deterministico cui tende la successione{ut}. Una variabile
costituita dalla somma di un I(1) con un trend è detta anche integrata di ordine 1 con un trend
I(1,T).
Le variabili integrate di ordine 1 (o superiori ad 1) sono dette anche variabili non stazionarie o
trend stocastici. La caratteristica di queste variabili è quella di muoversi lentamente nel tempo,
senza alcuna tendenza verso un valore di equilibrio.
E’ evidente che se ut è di ordine I(1), la sua variazione ut è I(0) (stazionaria), infatti:
ut = ut - ut-1 =(k+ ut -1+ εt ) - ut-1 = (k + εt )
Si dice che una variabile è I(n) ( = integrata di ordine n) se occorre effettuare n variazioni per
ottenere una variabile stazionaria.
Tra le variabili non stazionarie, in economia sono importanti solo e I(1) e, qualche volta, le I(2).
In particolare, i prezzi e le quantità nominali sono generalmente I(1) o I(2); le grandezze reali sono
generalmente I(1) o I(0) con trend; i rendimenti sono generalmente I(1) o I(0), come anche le
crescite.
Una serie I(2) (integrata di ordine 2) ha un andamento di tipo particolarmente smussato in quanto
per definizione anche la sua variazione non ha alcuna tendenza a riportarsi vero un valore
deterministico.
Nella figura è riportato un esempio dell’andamento di una variabile I(0), I(0) con persistenza
generata da ut=k+ 0.8 ut-1 + εt , I(1) e I(2). Come si nota, quando il numero di osservazioni è basso,
una I(0) con persistenza può assomigliare a una I(1), ma quando le osservazioni sono numerose la
differenza è ben visibile
5
Esempio dell’andamento di variabili I(0), I(1) e I(2)
Grado
d’integrazione
I(0)
100 osservazioni
1000 osservazioni
4
3
3
2
2
1
1
0
0
-1
-1
-2
-2
-3
-3
4
-4
6
3
4
2
2
1
I(0) con
persistenza
0
0
-2
-1
-2
-4
-3
-6
-4
14
-8
90
12
80
10
70
60
8
I(1)
50
6
40
4
30
2
20
0
13
10
80
12
70
11
60
10
50
I(2)
9
40
8
7
30
6
20
5
10
Ecco come si stabilisce se le variabili sono I(0) o I(1) [il caso di I(2) è più raro e quindi è
generalmente sufficiente discriminare fra I(0), cioè variabili stazionarie, e I(1), cioè variabili non
stazionarie: nel caso si voglia accertarsi che la variabili sia I(1) e non I(2) basta eseguire il test di
integrazione sulla variazione della variabile che deve risultare stazionaria].
6
L’impiego dei test
La valutazione dei test dipende dalla cosiddetta “ipotesi nulla” H0. In altri termini, i test sono stati
costruiti nell’ipotesi che la variabile soggetta a test segua un certo comportamento: se la differenza
tra il valore effettivo del test e quello teorico è così elevata che è quasi impossibile che questa
differenza sia dovuta al caso, l’ipotesi nulla H0 viene respinta e si accetta il suo opposto, cioè la
cosiddetta ipotesi alternativa H1. Per esempio, se H0 è che un certo valore sia nullo e il vero valore è
così lontano dallo zero che la probabilità che questo fenomeno sia dovuto a un puro caso è molto
bassa, si rifiuta l’ipotesi H0 (il valore è nullo) a favore dell’ipotesi H1 (il valore non è nullo).
I test, però, possono essere sia diretti che indiretti in relazione all’ipotesi nulla di partenza. Con i
test diretti siamo interessati all’ipotesi H0 che accettiamo quando la probabilità che sia vera è
sufficientemente “alta” (cioè maggiore di un certo valore α , es. il 5%). Con i test indiretti noi
siamo invece interessati all’ipotesi alternativa H1 che accettiamo quando viene respinta H0, cioè
quando la probabilità che H0 sia vera è “bassa” (per esempio inferiore al 5%). Tutto questo, in
alcuni casi, può generare perplessità sul risultato. A questo si aggiunga che i test talvolta sono a
due code (bilaterali), talvolta a una sola coda (centrali).
La seguente tabella e la successiva figura danno alcune informazioni su come vanno interpretati i
test, anche se il pacchetto econometrico da noi utilizzato indica spesso il significato del test
eseguito.
H0
H1
X = X0 X X0
X X0
X X0
X > X0
X < X0
accetta H0 se:
Rifiuta H0 in favore di H1 se:
tipo di test
T(α/2) T T(1-α/2)
T < T(α/2) oppure T > T(1-α/2)
α/2 Pr(T) 1-α/2
Pr(T) < α/2 oppure Pr(T) > 1-α/2
A due code
(bilaterale)
T T(1-α)
T > T(1-α)
Pr(T) 1-α
Pr(T) > 1-α
T T(α)
T < T(α)
Pr(T) α
Pr(T) < α
Coda a destra
Coda a sinistra
7
8
Procedimento per stabilire il grado d’integrazione di una
variabile con Gretl:
Determiniamo il grado d’integrazione dell’euribor a scadenza mensile R1M.
Apriamo il file dati_mensili_tassi.wf1
1) Facciamo innanzitutto il grafico
Clicchiamo su Visualizza, poi su Grafico (o su Grafici multipli), poi su Serie storica…
series… . A questo punto si clicca sulla serie R1M e la si porta nella finestrella di destra con la
freccia verde e si dà l’OK.
In alternativa si può prima evidenziare la variabile R1M, poi si clicca su Variabile e Grafico
serie storica, poi si dà l’OK.
9
A questo punto appare il grafico:
Dall’ispezione del grafico si ottiene già qualche informazione sul suo grado d’integrazione: se
continua a andare su e giù è probabilmente I(0), se si muove lentamente, come in questo caso, e i
suoi valori tendono a rimanere alti o basso per molto tempo sono probabilmente I(1). Inoltre non
sembra visibile la presenza di un trend
2) Effettuiamo per conferma un test di integrazione
Dopo aver evidenziato R1M, clicchiamo su Variabile, poi scegliamo un test tra Test DickeyFuller aumentato, Test ADF-GLS o Test KPS. A questo punto si dà l’OK
Attenzione: nei primi due test l’ipotesi nulla è che la serie sia I(1), quindi per accettare l’ipotesi di
non stazionarietà occorre che la probabilità sia elevata (se è bassa si accetta l’ipotesi che sia I(0)).
Nel test KPSC (Kwiatkowski-Phillips-Schmidt-Shin test ) invece, l’ipotesi nulla è che la serie sia I(0),
10
quindi per accettare l’ipotesi di non stazionarietà occorre che la probabilità sia bassa (se è elevata
bassa si accetta l’ipotesi che sia I(0)).
Scegliamo per esempio il test Test Dickey-Fuller aumentato e diamo l’OK.
Scegliamo come tipo di test quello con costante (i tassi non hanno normalmente trend e infatti nel
grafico non appaiono), poi diamo l’OK
Il risultato del test appare in una nuova finestra. Si ricordi che la probabilità indicata dal test ADF
rappresenta la probabilità che la relazione non sia stazionaria I(0), cioè sia I(1) (o di grado
superiore a 1)
In questo caso la probabilità 0.5594 è alta (maggiore non solo del 5% e, ovviamente, anche
dell’1%, ma anche del 10%) e quindi accettiamo l’ipotesi che sia I(1).
Se la probabilità fosse stata bassa (inferiore al 5% e, meglio ancora, inferiore all’1%) avremmo
respinto l’ipotesi di I(1), ovvero avremmo accettato l’ipotesi di stazionarietà I(0)
11
3.Come effettuare le regressioni con le
variabili I(0) e I(1)
Problemi logici per la regressione in presenza di variabili non stazionarie e la cointegrazione
La non stazionarietà delle variabili crea dei problemi per le regressioni. Nel caso di variabili I(0)
senza trend, l’errore u della regressione
u = Y-(a-bX+cZ)
è sicuramente stazionario perché tutte le variabili Y, X e Z oscillano attorno a un valore
deterministico e quindi anche ogni loro combinazione lineare deve oscillare attorno a qualche
valore deterministico.
Se però le variabili fossero I(1), nessuna di loro oscillerebbe attorno a un valore deterministico e
pertanto nulla ci garantisce che l’errore u debba oscillare attorno a qualche valore deterministico. Se
però il residuo u fosse un I(1) la regressione non sarebbe valida (si parla in questo caso di
regressione “spuria”) perché il procedimento dei minimi quadrati minimizzerebbe una varianza
campionaria dei residui che, essendo finita, non può essere una buona stima di quella della
popolazione che è infinita. Qualunque fossero le stime si a, b e c, non esisterebbe nessun motivo per
cui Y debba tendere ad avvicinarsi alla sua stima a+bX+cZ !!
Può però capitare che le componenti I(1) delle variabili si compensino fra loro e che quindi il
residuo u sia I(0). In questo caso tutte le variabili Y, X e Z tendono ad allontanarsi sempre più dal
loro valore di partenza, ma la il movimento della Y oscilla attorno al valore della relazione (a + bX
+ cZ) che ne rappresenta quindi la relazione di equilibrio (si pensi alla terra che è vincolata ad
oscillare attorno al solo il quale a sua volta si muove nell’universo).
Nel caso le variabili Y, X e Z siano I(1), ma esista qualche loro relazione u = Y –a –bX –cZ che sia
I(0) si direbbe che le variabili Y, X e Z sono cointegrate e il vettore dei loro coefficienti [1, -a, -b, c] si chiamerebbe vettore di cointegrazione. In questo caso particolare (ma solo in questo caso) è
possibile procedere a una stima della relazione tra Y e le sue variabili esplicative Si noti, comunque,
che se il vettore = [1, -a, -b, -c] è un vettore di cointegrazione lo sarà anche il vettore h = [h, -ah,
-bh, -ch] (con h0); quindi, per esempio, se b0, anche /(-b) = [-1/b, a/b, 1, c/b] è equivalente a .
Date tre variabili Y, X e Z, è però possibile che i vettori di cointegrazione siano addirittura due, uno
per ogni coppia di variabili. Potrebbero per esempio essere singolarmente cointegrate le coppie
(X,Y) e (Y,Z). In questo caso vi sarebbero due relazioni di equilibrio, con la X che oscilla attorno a
una trasformazione lineare della Y che, a sua volta, oscillerebbe attorno a una trasformazione
lineare della Z.
E’ evidente che non è possibile che una variabile I(1) possa essere cointegrata con una variabile
I(0): è infatti impossibile che una variabile che si muove liberamente nello spazio sia vincolata ad
oscillare attorno ad una variabile che oscilla attorno a un punto ben definito.
Uno dei metodi più usati per determinare se delle variabili I(1) sono cointegrate, cioè per
stabilire se tra loro esiste una (o più) relazioni di equilibrio (vettori di cointegrazione) radici
unitarie), è il metodo di Johansen, col quale si calcolano anche i valori dei coefficienti di
12
equilibrio. Il metodo verrà spiegato direttamente all’interno degli esempio concreti (in particolare
vedi i casi della relazione tra Euribor e Repo e la stima del tasso a lunga). Si ricordi che tra le
alternative che questo procedimento usa per individuare il numero di vettori di cointegrazione
quello considerato migliore è quello della traccia ed è quindi a questo test che è meglio fare
riferimento.
Detto questo, per eseguire delle regressioni in forma appropriata al tipo di variabili che si stanno
utilizzando (I(1) o I(0) ), ci si può attenere a questi principi:
-
Quando c’è già un modello teorico ben definito(come per es. nel caso fra tasso implicito e
tasso futuro) non c’è da preoccuparsi: basta eseguire una normale regressione
-
Quando siamo di fronte a un caso non ben conosciuto è utile determinare innanzitutto il
grado d’integrazione delle variabili per stabilire se sono I(0) o I(1) [le variabili economiche
sono spesso I(1), le loro differenza (spread) sono invece spesso I(0) ] mediante l’ispezione
visione del grafico e il test d’integrazione.
a) Se le variabili sono I(0) i loro valori vanno messi nelle regressioni in livelli.
Yt = a0 + a10 Xt + a20 Zt + a01 Yt-1 + a11 Xt-1 + a21 Zt-1 + a02 Yt-2 + a12 Xt-2 + a22 Zt-2 + ....
b) Nel caso di variabili I(1) X, Y, Z (dove Y è la dipendente) la stima va invece eseguita nella
forma
(5)
∆Yt = a0 + a10 ∆Xt + a20 ∆Zt + b0Yt-1+b1Xt-1+ b2 Zt-1 + a01 ∆Yt-1 + a11 ∆Xt-1 + a21 ∆Zt-1 +
a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
le variabili sono espresse in variazioni e i livelli delle variabili entrano come variabili indipendenti
solo in t-1.
Attenzione: le variazioni delle variabili indipendenti in t possono essere messe nella regressione
solo se sappiamo che il loro andamento in t non dipende dal contemporaneo andamento in t della
variabile dipendente (spesso è la teoria economica che è in grado di suggerirci se queste variabili
sono o no esogene rispetto alla dipendente). In caso contrario non vanno introdotte e, se introdotte,
le stime vanno effettuate con le tecniche dette “per le equazioni simultanee”
Nel casi esista una relazione di equilibrio (cointegrazione) tra i livelli delle variabili Y, X e Z, e la
variazione della dipendente è sensibile all’equilibrio preesistente, questo valore può essere ricavato
tenendo presente che, in equilibrio, le variazioni delle variabili sono nulle (a parte dei trend interni)
e i valori al tempo t dei livelli sono uguali a quelli al tempo t-1. Ne deriva che, in equilibrio, la
nostra equazione si riduce a:
0 = 0 + b0Y+b1X+ b2 Z + 0, da cui Y = -(b1/b0)X - (b2/b0)Z
ovvero Y = 1Xt + 2 Z dove 1 = -(b1/b0) e 2 = (b2/b0)
In altri termini, i coefficienti di equilibrio si ottengono dividendo i coefficienti dei livelli delle
variabili indipendenti ritardate per il coefficiente del livello della dipendente ritardata cambiato
di segno.
Analogamente, l’espressione + b0Yt-1+b1Xt-1+ b2 Zt-1 contenuta nella regressione può anche essere
scritta, mettendo in evidenza b0 come + b0 (Yt-1+ b1/b0 Xt-1+ b2/b0 Zt-1) = b0 (Yt-1- 1 Xt-1- 2 Zt-1), ma
l’espressione (Yt-1- 1 Xt-1- 2 Zt-1) non è altro che la differenza in t-1 tra il valore effettivo di Y e il
suo valore di equilibrio (1 Xt-1 + 2 Zt-1): essa, cioè, non è altro che il disequilibrio in t di Y rispetto
al suo valore di equilibrio.
Una maniera alternativa di esprimere la relazione (5) è quindi mediante l’equazione
13
∆Yt = a0 + a10 ∆Xt+a20 ∆Zt + b0(Yt-1- 1 Xt-1- 2 Zt-1) + a01 ∆Yt-1 + a11 ∆Xt-1 + a21 ∆Zt-1 +
a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
in cui oltre alle variazioni delle variabili figura il disequilibrio in t-1. Da quest’ultima relazione
risulta chiaro che b0, il coefficiente di Yt-1 della (5), può essere anche interpretato come la velocità
con cui la variabile Y in t reagisce al suo disequilibrio in t-1. Il valore dev’essere quindi negativo
perché in questo caso a un valore eccessivo di Y in t-1 rispetto al suo valore di equilibrio segue una
riduzione di Y in t (∆Yt < 0), a un valore di Y in t-1 troppo basso rispetto al suo valore di equilibrio
segue un aumento di Y in t (∆Yt > 0).
E’ ovvio che quanto detto è vero solo se l’equilibrio esiste e Y reagisce al disequilibrio. Se
l’equilibrio non dovesse esistere e/o b0 =0, il valore di b0(Yt-1- 1 Xt-1- 1 Zt-1) si ridurrebbe
identicamente a 0 e l’equazione (6) potrebbe essere espressa solo nelle variazioni:
(6)
(6’)
∆Yt = a0 + a10 ∆Xt+ a20 ∆Zt + a01 ∆Yt-1 + a11 ∆Xt-1 + a21 ∆Zt-1 +
a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
Lo stesso succederebbe anche alla (5), dal momento che questa e la (6) sono equivalenti: se
mancano dei regressori nella seconda equazione devono mancare anche nella prima!
Per stimare il modello (5)/(6) si possono seguire due procedimenti, diretto e indiretto:
Metodo diretto:
- Si stima direttamente l’equazione (5), cioè
(5)
∆Yt = a0 + a10 ∆Xt + a20 ∆Zt + b0Yt-1+b1Xt-1+ b2 Zt-1 + a01 ∆Yt-1 + a11 ∆Xt-1 + a21 ∆Zt-1 +
a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
Se però si sa già priori che l’equilibrio non c’è, o che Y non reagisce al disequilibrio (b0 = 0) è
inutile mettere (anzi: meglio non mettere) tra i regressori i livelli ritardati.
Attenzione: col metodo diretto si può utilizzare la forma alternativa, con la dipendente espressa in
livello invece che in variazioni, mediante l’identità ∆Yt-1 Yt - Yt-1 :
(5’) Yt = a0 + a10 ∆Xt + a20 ∆Zt + b0Yt-1 - Yt-1+b1Xt-1+ b2 Zt-1 + a01 ∆Yt-1 + a11 ∆Xt-1 + a21
∆Zt-1 + a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
(5’’)
= a0 + a10 ∆Xt + a20 ∆Zt + (1 + b0 ) Yt-1 +b1Xt-1+ b2 Zt-1 + a01 ∆Yt-1 + a11 ∆Xt-1 + a21
∆Zt-1 + a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
In questo caso, però, il coefficiente della ritardata corrisponde a (1 + b0 ), dove b0 è il coefficiente
con la dipendente espressa in variazioni e di questo si deve tener conto nel valutare i risultati e
nell’effettuare i test sui coefficienti. Per esempio, i coefficienti di equilibrio non corrispondono ai
vari coefficienti dei livelli in t-1 dei regressori diviso il coefficiente della dipendente ritardata
cambiato di segno, ma diviso 1 meno il coefficiente della ritardata. Siccome b0 dovrebbe essere
negativo e non superiore ad 1 (se il valore della Y è troppo alto va sua successiva variazione
dev’essere negativa) il coefficiente dalla ritardata Yt-1 della (5”) dovrebbe essere un numero
positivo compreso tra zero e 1.
Metodo indiretto:
Si verifica prima se l’equilibrio esiste e lo si stima con le tecniche di cointegrazione (es. Johansen).
- a) Se l’equilibrio c’è (il che significa che il disequilibrio è una variabile I(0), cioè stazionaria) ed è
uno solo (esiste un solo vettore di cointegrazione) si mette il disequilibrio in t-1 come un
regressore al posto dei livelli presi separatamente. Per esempio, si supponga di aver trovato che
l’equilibrio esiste, è unico e è dato da Y=1.212 X – 0.571 Z, ovvero il disequilibrio è dato da (Y 1.212 X + 0.571 Z); la stima delle variazione ∆Yt viene allora effettuata stimando la seguente
regressione (detta anche “dinamica” o “finale” o “di breve periodo):
14
(7)
∆Yt = a0 + a10 ∆Xt+a20 ∆Zt + b0(Yt-1-1.212 X t-1+0.571 Z t-1) + a01 ∆Yt-1 + a11 ∆Xt-1
+ a21 ∆Zt-1 + a02 ∆Yt-2 + a12 ∆Xt-2 + a22 ∆Zt-2 + ....
- b) Se l’equilibrio non c’è (non esiste nessun vettore di cointegrazione) nell’equazione si
mettono solo le variazioni delle variabili.
- c) Se vi è più di equilibrio (c’è più di un vettore di cointegrazione) vi conviene usare il metodo
diretto con i livelli ritardati delle variabili (eq. 5). Questo problema è infatti troppo difficile da
trattare per chi è alle prime armi e in questo caso, comunque, il metodo diretto funziona
normalmente bene.
3 – Il procedimento di stima che si consiglia di seguire nei casi concreti e i relativi test
In generale, il procedimento consigliato per stimare un’equazione (a meno che le relazioni si
conoscano già a priori come nel caso della previsione dell’Euribor effettuata mediante la struttura
dei tassi per scadenza - v. dispensa precedente) è il seguente:
- Eseguire i test per stabilire il grado d’integrazione delle variabili (nel caso non lo si
conoscesse già). Le variabili I(0) vanno introdotte nei loro livelli, le variabili I(1), invece, nelle
variazioni, a parte i loro livelli al tempo t-1 nel metodo diretto e il disequilibrio al tempo t-1 nel
caso del metodo di stima indiretto.
- Nel caso in cui almeno due variabili sono I(1) si può procedere
a) col metodo di stima diretto (v. eq. 5 precedente)
b) col metodo di stima indiretto che consiste nello stabilire prima se esiste una relazione di
equilibrio tra le variabili (metodo di Johansen o altro). Se questa relazione esiste ed è unica
procedere come nell’eq. (7); se non esiste procedre come nell’eq. (6’); se esiste più di un vettore di
cointegrazione (più relazioni di equilibrio) passare al metodo diretto (eq.5).
Una volta eseguita la regressione è opportuno effettuare dei test sulla bontà della stima
eseguita. Più test “passano”, più il caso che si sta analizzando è vicino alle condizioni ideali in cui il
metodo di stima è valido e efficiente.
- Controllare che non ci siano outliers (residui anomali) mediante il grafico dei residui
(eventualmente eliminarli in qualche modo, per esempio mediante una dummy o, più
semplicemente, cambiando il valore della variabile che crea problemi). E’ meglio eseguire
immediatamente questo controllo perché se vi sono outliers tutta la stima può essere sbagliata e i
test non valgono più.
- Controllare che il numero dei ritardi sia quello ottimale. Provare ad eseguire la regressione
senza ritardi, poi con un ritardo, poi con due, etc. Il numero ottimo di ritardi corrisponde alla
regressione con i più bassi valori dei test di Akaike, Hannan-Quinn e Schwarz: In caso di ambiguità
preferire il test di Schwarz, in caso d’indecisione tra introdurre h e h+1 ritardi scegliere h+1.
- Controllare il valore dell’R2 corretto (che corrisponde alla % della varianza della variabile
dipendente spiegata dalla nostra regressione): un valore troppo basso (es. =0,01) è impresentabile:
la nostra stima non spiega quasi niente del fenomeno.
Controllare che i residui siano indipendenti nel tempo
- Controllare il DW (coefficiente di Durbin Watson) che dev’essere vicino a 2 (in assenza delle
apposite tabelle potete accettare un valore compreso tra 1,7 e 2,3). Se il DW è lontano da 2
(normalmente troppo basso, di rado troppo alto) significa che il residuo al tempo t è correlato con
quello al tempo t-1 e i coefficienti stimati e i test sono meno precisi. Un DW lontano da 2 indica
spesso che tra i regressori manca qualche variabile indipendente importante (spesso non sono
15
sufficienti i ritardi introdotti nella regressione): un basso valore del DW è gravissimo soprattutto
quando tra i regressori vi è la dipendente ritardata. In questo caso, infatti, le stime, oltre che
imprecise sono anche distorte. Se non vi è la dipendente ritardata il fatto è meno grave perché
l’effetto è di rendere meno efficienti le stime ma non distorte (con l’istruzione di Eviews LS(n),
comunque, le probabilità dei coefficienti sono corrette). Si noti, comunque, che se la dipendente è
una variazione del tipo (Yt - Yt-T ) con T>1 e i regressori vanno dal tempo t-T indietro, il DW basso
è la naturale conseguenza del tipo di variazione eseguito: le stime sono imprecise ma non distorte!!!
In alcuni casi nella regressione appare automaticamente l’”h di Durbin” anziché il DW. In questo
caso la regola pratica è che l’ipotesi di indipendenza dei residui è respinta al 5% se l’h è in valore
assoluto >2, all’1% se è in valore assoluto >3
- Eseguire gli altri test sull’autocorrelazione dei residui (si noti che una forte autocorrelazione dei
residui con dati mensili in corrispondenza a un ritardo di 12 indica spesso la presenza di
stagionalità. In questo caso usare dati destagionalizzati oppure introdurre tra i regressori anche i
valori delle ritardate di 12). Per il problema della presenza di autoregressione nei residui vedi anche
sopra. I principali test sono: Test LM serial correlation, correlogramma Q-statistics. Come
numero di ritardi da usare, con i dati mensili 12 ritardi sono normalmente più che sufficienti, ma
anche meno se si sa che non c’è stagionalità.
- Controllare che la distribuzione dei residui sia una normale (test di Jarque-Bera. Se la
distribuzione non è normale le stime e i test sono meno precisi. Spesso la non-normalità è dovuta
all’eteroschedasticità dei residui (varianza dei residui non costante nel tempo). L’importante,
comunque, è che la distribuzione non sia troppo lontana dalla normale (quando è molto lontana
dalla normale lo si vede anche dal grafico dei residui). Nel caso di presenza di numerosi valori
estremi (code della distribuzione molto “grasse”, più essere utile ricorrere a metodi diversi dagli
OLS (minimi quadrati). In particolare, utilizzando Eviews, poò essere utile il metodo QREG
(quantile regression), utilizzando GRETL andare su Modello, Stima robusta e utilizzare il metodo
LAD (minime deviazioni assolute) che si trova
- Controllare che la varianza dei residui sia omoschedastica
Se la varianza dei residui non fosse omoschedastica le stime dei coefficienti sarebbero meno precisi
e le relative probabilità sono distorte. Usando però con Eviews i comandi LS(h) o LS(n) le
probabilità risultano corrette. Lo stesso scegliendo l’opzione Errori standard robusti di GRETL. Si
possono comunque usare metodi di stima ARCH-GARCH che eliminano il problema.
I casi di eteroschedasticità sono due. Nel primo caso la varianza non è costante nel tempo. Il test
più usato per la verifica dell’omoscheasticità (varianza costante nel tempo) è il test l’ARCH (di
solito è sufficiente introdurre 1 o 2 ritardi). Nel secondo caso la varianza è legata al valore dei
regressori. I Test più usati sono in questo caso sono: Breusch-Pagan, Breusch-Pagan-Godfrey,
White.
- Controllare che la relazione sia stabile. Si possono eseguire vari test, tra cui il CUSUM (è
sensibile alla stabilità dei coefficienti) e il CUSUM dei quadrati dei residui. Il CUSUM dei quadrati
è sensibile sia alla stabilità dei coefficienti che alla stabilità della varianza
Ovviamente, se si sa che per qualche motivo la relazione non è statile il test diventa ridondante.
Attenzione che se una variabile è inizialmente costituita da tutti zeri (o una costante) il test
considera solo i valori a partire da quando la variabile ha cominciato a diventare diversa da zero
- Controllare che la forma della funzione utilizzata sia accetabile. Il test più usato è il RamseyRESET. Dare 2 come fitted terms, ovvero richiedere l’uso di “quadrato e cubo”.
- Eseguire il test di Wald (o altro) per la verifica di eventuali vincoli tra i coefficienti e, in caso
di accettazione, ristimare eventualmente l’equazione tenendo conto dei vincoli. Se è instabile
modificare l’equazione per tenr conto di eventuali fenomeni strutturali.
16
4. La previsione del tasso d’interesse
mediante la struttura dei tassi.
L’unico caso in cui il problema delle previsioni delle variabili esplicative di un modello non esiste
si ha quando il valore della futura variabile da stimare è legato soltanto al valore in t dei regressori,
cioè quando l’equazione è del tipo:
(6)
Yt = F( Yt-h, Xt-h ) (con h 0)
Utilizzando questa relazione, è facilissimo stimare in t il valore che la Y assumerà in t+h:
(7)
Et[Yt+h] = F( Yt, Xt )
dal momento che i regressori Yt, Xt sono perfettamente noti in t e non è necessario mettere al loro
posto dei valori approssimati.
Un esempio del caso (6)-(7) è rappresentato dalla stima dei tassi mediante la cosiddetta “struttura
per scadenza”.
Detto R il tasso, nel caso valga l’ipotesi “delle aspettative col premio di liquidità”, e fossero
disponibili in t i tassi a scadenza 1,2,3,… mesi (per es il tasso sull’Euribor da 1 a 12 mesi) sarà:
(8)
Et[R1t+1 mese]
Et[R1t+2 mesi]
Et[R1t+3 mesi]
etc.
= (2 × R2t – R1t ) - h1
= (3 × R3t – 2 × R2t) - h2
= (4 × R4t – 3 × R3t) - h3
(dove R1 è tasso mensile, R2 quello bimestrale, R3 quello trimestrale, R4 quello a scadenza 4 mesi,
etc.; h1, h2, h3, … sono i “premi per la scadenza” da togliere per avere le aspettative. I valori (2 ×
R2t – R1t ), (3 × R3t – 2 × R2t), etc. sono detti anche tassi impliciti mensili al tempo t relativi
al tempo t+1, t+2, etc. .
Nel caso fossimo abbastanza “certi” della correttezza di queste formule, la stima e le previsioni
sarebbero semplicissime visto che l’unica componente della relazione da stimate sarebbe il premio
di h (per il breve periodo, comunque, per i tassi dell’Euribor, quest’ipotesi è più che accettabile).
Per esempio, nel caso di previsione a un mese del tasso mensile, utilizzando dati mensili
l’equazione
(9)
Et[R1t+1 mese] = (2 × R2t – R1t ) - h1
può essere stimata come segue:
Si deve cercare il valore di h1 che nel passato aveva dato la miglior stima del rendimento mensile in
funzione della differenza (con pesi 2 e 1) dei valori dei rendimenti a scadenza 2 e 1 mese del mese
17
precedente. Tenendo presente che il vero valore di R1t+1 mese = Et[R1t+1 mese] + t+1 3, da cui
Et[R1t+1 mese] = R1t+1 mese - t+1 si ha, per il passato:
(10)
R1t = (2 × R2t-1 mese – R1t-1 mese ) - h1 + t (dove qui ε t ≡ -t)
da cui:
(11)
[ R1t - (2 × R2t-1 mese – R1t-1 mese ) ] = - h1 -t
(dove h1 è il premio per la scadenza e nel mercato dell’Euribor e ε t è il residuo (errore) della
regressione)
Fino all’inizio della crisi finanziaria il premio h1 del mercato dell’Euribor (mercato interbancario
europeo) era praticamente costante, sia per la mancanza del rischio di insolvenza e di illiquidità nel
mercato interbancario, sia perché la BCE manteneva la liquidità del sistema bancario sempre
vicina al suo valore “normale”. A partire dalla crisi, però, h1 è diventata una funzione positiva del
rischio Riskt presente nel mercato dell’Euribor (maggiore è il rischio Riskt e maggiore è h1 perché
il rischio si ripercuote maggiormente sulla scadenza più lunga – nel nostro caso 2 - che ha anche
coefficiente doppio). Inoltre h1 risente della liquidità LIQt presente nel sistema bancario (LIQt ha
un impatto negativo sui tassi che, in valore assoluto, è maggiore per le scadenza più brevi, e quindi,
in questo caso, dato che il peso della scadenza 2 è però il doppio della scadenza breve, l’impatto su
h1 potrebbe essere sia positivo che negativo).
Supponendo che la relazione tra h1 e il rischio e la liquidità sia lineare:
(11’) h1 = α0 + α1 Risk t-1 + α2 LIQ t-1 + t (con α1 <0; α2 può essere invece qualunque cosa)
La (11) diventa
(11’’) [ R1t - (2 × R2t-1 mese – R1t-1 mese ) ] = - (α0 + α1 Risk t-1 mese + α2 LIQt-1 mese + t ) -t
(11’’’) [ R1t - (2 × R2t-1 mese – R1t-1 mese ) ] = β0 + β1 Riskt-1 mese + β2 LIQ t-1 mese + ε t
Dove β1 <0, mentre β2 potrebbe essere qualunque cosa e l’errore della regressione è ε t ≡ - t -t )
Per stimare la relazione (11’’) utilizzando Gretl si deve prima generare la variabile dipendente R1M
- (2*R2M(-1) – R1M(-1)) dandole per esempio il nome DIFF1 e poi eseguire la regressione.
Nelle formule di Gretl i valori passati sono indicati con (-n) dove n è il ritardo che interessa.
Attenzione : Gretl fa distinzione tre le maiuscole e le minuscole. Si ricordi che in
GRETL i simboli delle funzioni log, abs, etc. sono tutti con la minuscola
In questo esempio non dobbiamo preoccuparci dell’ordine d’integrazione delle variabili, etc.
Questo modello è standard e considerato generalmente valido e, quindi, possiamo passare
direttamente alle stime.
Si ricordi che, per definizione, per ogni variabile Z vale la definizione: Z = E[Z] + εt dove Z è il vero valore della
variabile, E[Z] e εt il suo errore di stima.
3
18
Prima di tutto si deve richiamare il file dati_mensili_tassi.wf1 che contiene i dati di fine mese
dei tassi, del rischio e della liquidità che vanno dal gennaio 1999 al dicembre 2009.
Col programma GRETL le istruzioni sono le
seguenti:
Cliccare su File, poi Apri dati e infine Importa:
A questo si clicca su Eviews… (i nostri dati sono stati messi in un file di formato Eviews .wf1)
Fatto questo si entra nella cartella dove è stato messo il file dati_mensili_tassi.wf1, gli si clicca
sopra due volte e il file con i dati si apre (cancellare l’eventuale messaggio che appare, cliccandogli
sulla crocetta in alto a destra).
(Alla fine delle elaborazioni, volendo, il file potrà essere salvato per evitare di ripetere ogni volta
tutti i passaggi).
A questo punto si possono iniziare le elaborazioni
-
Innanzitutto occorre generate il differenziale DIFF1 = R1M - (2*R2M(-1) – R1M(-1))
Per fare questo:
19
-
cliccare su Aggiungi poi Definisci nuova variabile
e immettere nella finestrella la definizione di DIFF1, poi dare l’OK (la nuova variabile DIFF1
viene aggiunta alla lista come ultima in basso)
-
Conviene innanzitutto definire il periodo relativo (SMPL) alle nostre analisi che corrisponde ai
dati disponibili nel file (i dati vanno dal gennaio 1999 al dicembre 2009). L’operazione, in
questo caso, non sarebbe comunque necessaria perché il campione è già considerato del
programma che utilizza automaticamente tutti i dati disponibili)
Si clicca su Campione (in alto), poi Imposta intervallo e si regola la data, poi si dà l’OK:
Ora si immetttono la variabile dipendente e le indipendenti nel loro posto (non preoccuparsi dei
ritardi delle variabili indipendenti che si sistemano dopo)
20
Cliccare su Modello in alto, poi su OLS – Minimi quadrati ordinari… .
A questo punto si immettono le varibili cliccando sopra alle variabili che interessano e
immettendole con le frecce (se li vogliono fare altre regressioni con la stessa dipendente conviene
cliccare sul quadratino di Imposta come predefinito che è sotto il nome della dipendente)
21
A questo punto si mettono i ritardi voluti per le indipendenti (RISK1 e LIQ) cliccando su
Ritardi…
(nel nostro caso sono 1)
E si dà l’OK.
La schermata con i ritardi si chiude e riappare la schermata della regressione.
Per avere stime migliori degli SE dei coefficienti e delle probabililità cliccare su Errori statistici
robusti (lasciar perdere la configurazione Configura se non conoscete bene la teoria)
22
A questo punto date l’OK. Ecco quello che appare:
Il DW (1,82) è vicino a 2 e l’R-quadro è abbastanza alto.
Prima di proseguire è però meglio controllare ad occhio che non ci siano valori anomali guardando
il grafico dei residui (cliccare su Grafici in alto e poi su Residui e scegliere l’opzione Rispetto
al tempo)
Dal grafico non si rilevano anomalie rilevanti e quindi la regressione può essere accettata
23
Tutti i parametri stimati sono altamente significativi (la probabilità che siano nulli è bassissima per
i tre coefficienti), e infatti sono seguiti da tre asterischi (*** = significativo all’1%, ** =
significativo al 5%, * = significativo all1%). Questo significa che sono significativamente diversi
da zero, ovvero che la probabilità che siano zero è trascurabile, e quindi si accetta l’ipotesi che
siano diversi da zero.
I segni dei coefficienti stimati sono quelli previsti: sia la costante che il rischio hanno infatti valori
negativi (-0.057 e -0.810)
Per ottenere una stima del rendimento mensile che ci sarà fra un mese basta quindi calcolare
l’attuale valore di (2*R2M – R1M) e sommargli -0.0573-0.810*RISK1-1.828e-06*LIQ
Per quanto riguarda il gennaio 2010 (il primo valore dopo l’ultimo disponibile che è quello del
dicembre 2009), la previsione può anche essere ottenuta direttamente cliccando su Analisi in alto,
poi su Previsione… Il periodo della previsione è già a posto, quindi è inutile modificarlo
Basta dare l’OK e appaiono sia un grafico (la previsione riporta in verde l’intervallo di confidenza)
e una tabella (il dato che interessa è quello relativo al 2010.01
24
5.La previsione del tasso mediante
l’utilizzo di variabili economiche
L’unico caso in cui il problema delle previsioni delle variabili esplicative di un modello non esiste
si ha quando il valore della futura variabile da stimare è legato soltanto al valore in t dei regressori,
cioè quando l’equazione è del tipo:
Si riconsideri ancora il caso delle eqq. (6) o (7) viste in precedenza, qui ripetute per comodità:
(6)
Yt = F( Yt-h, Xt-h )
Ovvero
(7)
Et[Yt+h] = F( Yt, Xt )
Un altro importante esempio della (7), in cui in t sono disponibili tutte le informazioni che entrano
nella previsione del futuro valore di Y riguarda le previsioni del Repo, il nostro tasso ufficiale, e fa
riferimento alla possibilità di stimare il tasso futuro in relazione ai valori di certe variabili
economiche conosciute al momento delle previsioni. In particolare, è possibile considerare le
variabili economiche che si ritengono importanti per le decisioni della nostra Banca Centrale.
Nel caso della zona-Euro, queste variabili economiche misurano il pericolo che, nel futuro,
l’inflazione e la crescita divergano dagli obiettivi di politica monetaria (si ricordi che l’obiettivo
primario della BCE è un’inflazione minore ma vicina al 2% nel medio periodo, l’obiettivo
secondario è la crescita economica). Leggendo le documentazioni in cui la Banca Centrale Europea
spiega e giustifica il suo operato, è possibile avere un’idea delle principali variabili che analizza al
momento di prendere le decisioni:di conseguenza la nostra conoscenza del valore di queste variabili
ci consente di prevedere il futuro valore del tasso d’interesse.
Ovviamente, il valore delle variabili che la BCE conosce in un certo momento sono (a parte le sue
eventuali informazioni riservate) quelle disponibili in quel momento. Quindi, nelle nostre
regressioni, dobbiamo utilizzare lo stesso criterio: nell’equazione devono entrare solo i valori
effettivamente disponibili al tempo t. Il file messo su internet è già stato costruito con questo
criterio: per ogni mese il valore riportato in ogni serie è quello effettivamente disponibile.
In particolare, tra le variabili più importanti che la Banca considera nella sua decisione ralativa alla
variazione del tasso ufficiale vi sono:
1) L’attuale valore del tasso ufficiale (REPOB) (più è alto e già il tasso e più è difficile che sia
ancora aumentato); (segno -).
2) L’inflazione (ovvero la crescita dell’indice dei prezzi al consumo) GPCONS (più alta è
l’inflazione corrente e più è probabile che nel futuro ci sia pericolo per la stabilità dei prezzi;
inoltre, a parità di tasso d’interesse, più alta è l’inflazione e più è basso il tasso d’interesse
reale, con effetto espansivo sul sistema economico. (segno +).
3) La crescita del cambio dollaro/euro (GDOLLAROM): più l’euro si rafforza e meno costano
per noi le materie prime, inoltre aumenta la concorrenza estera alle nostre imprese che così
non possono aumentare i loro prezzi. (segno -).
4) La crescita del prezzo del petrolio GPOIL: l’effetto di questa variabile è però ambiguo e
potrebbe risultare non significativo. Se il prezzo del petrolio sale aumenta l’inflazione e
quindi la BCE dovrebbe aumentare i suoi tassi; d’altra parte, se aumenta il prezzo del
25
petrolio aumentano i costi per le imprese con effetto negativo sulla crescita economica, e
quindi la BCE dovrebbe ridurre i suoi tassi per aiutare le imprese. (segno ?).
5) Un indicatore della crescita economica (SENTIMENT) (la crescita del PIL è conosciuta con
molto ritardo ed è quindi meglio utilizzare il più aggiornato indice di Eurostat. Quando la
crescita è bassa la BCE dovrebbe aumentare i suoi tassi per favorire le imprese, quando è
alta dovrebbe aumentarli per raffreddare l’economia ed evitare che le imprese aumentino i
loro prezzi (segno +).
6) La crescita della moneta (GM33): più elevata è la crescita della moneta e maggiore è il
pericolo inflazionistico di medio-lungo termine. (segno +)
7) Una variabile che ha potrebbe recentemente avere avuto effetto sulla determinazione dei
tassi durate il periodo di crisi finanziaria è il rischio finanziario RISK1 (misurato dalla
differenza tra il rendimento del mercato interbancario “non garantito”[Euribor] e quello
garantito [Eurepo o OIS].
I valori di queste variabili sono quelli disponibili prima della riunione della BCE.
Anche in questo esempio, trattandosi di un modello già ben sperimentato, non dobbiamo
preoccuparci dell’ordine d’integrazione delle variabili, etc. e, quindi, possiamo passare
direttamente alle stime.
In definitiva, una funzione che ci permette di prevedere come il tasso si muoverà nel prossimo
futuro potrebbe essere una relazione del tipo:
(20)
REPOBt+i - REPOBt-1 =F(REPOAt, GPCONSt, GDOLLAROMt, GPOILt,
SENTIMENT t, GM33 t RISK1)
Dove REPOB è il nuovo valore del REPO
I dati si trovano del file c_repo_e_variabil_economiche
Una stima per effettuale una previsione del movimento del REPO deciso nella prossima riunione è
per esempio una regressione del tipo (dove t+i = 0)
REPOBt = a0 + a1 REPOBt-1 + a2 GPCONSt, + a3 GDOLLAROMt, + a4 GPOILt,
+ a5 SENTIMENTt, + a6 GM33 t + a7 RISK1
I segni attesi sono: a1 < 0, a2 > 0, a3 < 0, a4 = ? (forse nullo), a5 > 0, a6 >0, a7 < 0.
In alternativa, poiché REPOBt = REPOBt - REPOBt -1 , si può portare a destra REPOBt -1 ed
esprimere la dipendente nel suo livello:
REPOBt = a0 + REPOBt-1 + a1 REPOBt-1 + a2 GPCONSt, + a3 GDOLLAROMt,
+ a4 GPOILt, + a5 SENTIMENT t, + a6 GM33 t + a7 RISK1
Ovvero:
REPOBt = a0 + b1 REPOBt-1 + a2 GPCONSt, + a3 GDOLLAROMt, + a4 GPOILt,
+ a5 SENTIMENT t, + a6 GM33 t + a7 RISK1
(dove i segni attesi sono gli stessi di prima, con l’eccezione del coefficiente della ritardata della
dipendente REPOBt-1 dal momento che b1 = (1- a1), e, pertanto, se a1 < 0, b1 dev’essere un
numero positivo minore di 1: 0 < b1 < 1.)
26
A questo si possono aggiungere la seguenti informazioni:
1) La BCE ha deciso che il valore minimo del tasso ufficiale è l’1%;
2) Il tasso ufficiale viene mosso di multipli di 25 punti base
3) L’inflazione è tanto più pericolosa quanto il suo valore è più lontano dall’obiettivo del 5%.
Ne consegue che:
1) Si deve utilizziamo un metodo di stima che tiene conto che il tasso non può scendere sotto
l’1% (es. la stima “censored” con Eviews) oppure, in mancanza di meglio, si deve limitare la
stima dei coefficienti della nostra regressione ai casi in cui il valore stimato è > oppure = 1.
2) E’ possibile utilizzare dei metodi di stima che tengano conto che il tasso si muove solo per
valori discreti. Per avere un risultato più preciso, con Eviews si può utilizzare il metodo di
stima “ordered” invece del metodo OLS. Con Gretl il procedimento da usare è Modello,
Modelli non lineari, Logit, Multinomiale…. 4
3) Si può dare un peso maggiore alla differenza tra GPCONS e il suo obiettivo utilizzando
l’espressione (GPCONS-2)*abs(GPCONS-2) al posto del semplice GPCONS o
(GPCONS-2).
Nella nostra analisi non considereremo il punto (2) e pertanto ci limitiamo a tener presente solo i
punti (1) e (3) e pertanto è più comodo introdurre la dipendete nel suo livello dal momento che è più
facile imporre che il tasso stimato non dev’essere inferiore a 1
Nel caso di Gretl il procedimento più
semplice è il seguente:
Definiamo innanzitutto il periodo di stima e passiamo poi a stimare il tasso che sarà deciso
nell’odierna riunione della BCE. Questa istruzione non è strettamente necessaria in quanto il
programma utilizza automaticamente tutti i dati disponibili.
Clicchiamo su Campione, poi Imposta intervallo e nella finestrella si indica il periodo
1999.01 2009.12:
4
I metodi qui elencati richiedono che la dipendente sia formata da numeri interi. Nel nostro caso, pertanto, la variazione
del Repo, che è un multiplo di 25 punti base, va moltiplicata per 4.
27
Ora creiamo la variabile gpcons_scarto, rappresentativa dell’importanza dello scarto tra
l’inflazione effettiva e quella obiettivo (2% annuo).
Si clicca su Aggiungi, poi Definisci nuova variabile e nella finestrella gpcons_scarto=
abs(GPCONS-2)*(GPCONS-2), poi dare l’OK
28
A questo punto siamo pronti per eseguire la stima.
Poiché non è possibile con l’attuale versione di Gretel imporre facilmente il vincolo che il Repo non
può scendere sotto l’1% si può procedere il due diversi modi.
ALTERNATIVA DI STIMA N.1: LIMITAZIONE DEL
PERIODO DI STIMA AL CASO DI REPOB>1
Tenendo presente che il valore minimo del Repo è dell’1% e che questo valore è stato raggiunto a
partire da maggio si può supporre che da giugno in avanti il tasso possa solo rimanere all’1% o
salire.
Cominciamo ad eseguire la nostra regressione limitandola al periodo gennaio in cui REPOB è
maggiore di zero.
Per far questo cliccare su Campione, poi Imposta in base a condizione… e nella finestrella si
indica il periodo REPOB>1:
La regressione si esegue cliccando su Modello, poi su OLS – Minimi quadrati ordinari… .
Quando si apre la finestra delle regressione si introducono la variabile dipendente e le indipendenti
29
Poi si clicca sul quadratino di “imposta come predefinito” per evitare di rimettere la dipendnete
ogni volta che si apre la regressione, su quello di “Errori standard robusti” per avresti stime più
precise dei test e infine su Ritardi…
Quando si apre la finestra dei ritardi si immette tra i regressori la dipendente ritardata di uno, poi si
dà l’OK.
30
Quando si chiude la finestra dei ritardi si dà un altro OK per avere il risultato della regressione.
I coefficienti hanno tutti i segni corretti, con GPOIL che non è significativo (la probabilità che il
suo coefficiente sia nullo è dell’81,89% e quindi alta) e che potrà essere eliminato. L’R2 è molto
alto (98%)
Prima, però, vediamo i residui. Basta cliccare su Grafici, poi su Residui e Rispetto al tempo.
31
A occhio, non emergono grossi outliers, anche se la varianza non sembra costante.
Cliccando su su Grafici, poi su Correlogramma dei residui e dando un ritardo massimo di 12
(in realtà ne basterebbero 5 o 6) si ottiene l’autocorrelogramma dei residui. La probabilità è sempre
maggiore dell’1%, quindi possiamo accettare l’ipotesi di indipendenza (anche se non l 5%):
Rifacendo la regressione senza la variabile GPOIL il cui coefficiente non era significativo
Il risultato che si ottiene è il seguente (ricordarsi su cliccare su Errori standard robusti prima di
32
dare l’OK):
Ora tutte le stime sono altamente significative (i tre asterischi stanno a indicare che i coefficienti
sono significativi all’1%; si ricordi, comunque, che normalmente sia accetta anche il 5% di
significatività [due asterischi] e qualche colta anche il 10% [1 asterisco]).
Si può quindi procedere alla previsione per il primo mesi fuori campione, il gennaio 2010. Cliccare
su Analisi, poi su Previsione… , e quando si apre la finestra scegliere l’alternativa previsione
statica, poi indicare il periodo 2010.01 2010.01 (oppure lasciare il SMPL di default) e dare
l’OK.
Nel caso in cui non esistessero limiti inferiori al valore del Repo, la previsione di REPOB per il
gennaio 2010.01 sarebbe 0,76. Poiché questo valore è inferiore al minimo del tasso ufficiale (che è
1) si deve prendere come previsione il maggiore tra 0,76 e 1, cioè 1
In modo analogo a quello visto ora si procede per le previsioni di febbraio 2010 e marzo 2010,
relativo al Repo deciso nelle riunioni della BCE del prossimo mese e del mese successivo.
I ritardi da utilizzare nelle regressioni saranno rispettivamente i seguenti:
33
e
Le previsioni si eseguono come visto per la stima relativa al 2010.01.
Anche per febbraio e marzo 2010 il valore previsto del Repo risulta essere di 1 punto.
Si noti che qualora la dipendente sia al tempo t e la dipendente ritardata sia al tempo t-h-1 mentre i
regressori si riferiscono al tempo t-h, il DW perde di significato perché risulta automaticamente
molto minore di 2 dal momento che si introduce automaticamente una media mobile nei residui.
In questo caso è solo rilevante che i valori del test Correlogram-Q-statistics… risultino
compresi tra le barrette a partire dal ritardo h+1 (come peraltro risulta nel nostro esempio: nel
primo caso le barrette tendono ad essere contenute negli intervalli a partire dal secondo ritardo,
nell’altro caso dal terzo).
34
Il motivo di questa autocorrelazione dei residui fino al ritardo h può essere spiegato con un
esempio. Si supponga che gli errori della previsione a un mese siano i seguenti:
0, 0, 1,8, 0. 0. -0,5
0,
0
Gli errori delle previsioni a due mesi corrisponderanno (con qualche approssimazione) alla somma
degli errori delle due previsioni a 1 mese adiacenti e pertanto, nel nostro esempio, saranno:
., 0, 1,8, 1,8. 0. -0,5 -0,5, 0
(es. se considerano le variazioni mensili appare un grosso errore nel mese di febbraio, con le
variazioni bimestrali questo errore elevato si riscontrerà sia nel bimestre gennaio-febbraio che nel
bimestre febbraio-marzo, con l’effetto di rendere positivamente autocorrelati i residui)
ALTERNATIVA DI STIMA N.2: utilizzo di una stima
“non lineare”
Il procedimento sinora utilizzato è abbastanza semplice ma fa perdere delle osservazioni.
L’alternativa è l’impiego del metodo per le stime non lineari che consente di modellare esplicitaente
qualunque relazione.
Per esempio, la rappresentazione non lineare della nostra equazione diventa
1) REPOB = b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL +
b4*SENTIMENT + b5*GM33+ b6*RISK1 + b7*REPOB(-1)
(al posto di b0, b1, …. si può usate qualunque simbolismo a piacere; ricordarsi che i valori
ritardati vanno indicati col ritardo tra parentesi: il valore ritardato di REPOB è REPOB(-1))
A questo punto di deve considerare che una relazione del tipo (X>Z) dà valore 1 quando la
relazione è vera e zero quando è falsa.
Nel nostro caso il Repo non può scendere sotto il valore 1, quindi quando il valore a destra
dell’equazione (1) è superiore a uguale a 1 il valore va bene. Quando invece è inferiore a uno va
riportato a 1.
Tenendo presente che l’espressione
2) (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT +
b5*GM33+ b6*RISK1 + b7*REPOB(-1) >= 1)
assume valore 1 se la condizione > = è soddisfatta, mentre diventa zero se non è soddisfatta, la
relazione
3) (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT +
b5*GM33+ b6*RISK1 + b7*REPOB(-1))* (b0 + b1*gpcons_scarto +
b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT + b5*GM33+ b6*RISK1 +
b7*REPOB(-1) >= 1)
corrisponde al termine di destra della (1) quando la condizione è soddisfatta, altrimenti diventa
uguale a zero.
D’altra parte, la relazione
35
4) (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT +
b5*GM33+ b6*RISK1 + b7*REPOB(-1) < 1)
corrisponde a 1 quando il membro di destra della (1) è più piccolo di uno, mentre diventa nullo
quando il membro di destra della (1) è maggiore o uguale a 1.
Combinando la (3) e la (4) si ha:
5) (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT +
b5*GM33+ b6*RISK1 + b7*REPOB(-1))* (b0 + b1*gpcons_scarto +
b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT + b5*GM33+ b6*RISK1 +
b7*REPOB(-1) >= 1) + (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL
+ b4*SENTIMENT + b5*GM33+ b6*RISK1 + b7*REPOB(-1) < 1)
Quest’espressione corrisponde al membro di destra della (1) quando questo è > oppure =1 e diventa
uguale a 1 (il valore minimo del Repo) quando esso è inferiore ad 1. Questa espressione è quindi
quella che va stimata.
Per far questo prima mettere il SMPL 1999.01 2009.12 perché ora utilizziamo tutti i dati a
disposizione, poi cliccare su Model, Nonlinear Model e infine su Nonlinear Least Squaree…
E si apre la seguente finestrella. Clicchiamo su Errori Standard robusti per una maggior precisione
36
A questo punto mettiamo nella finestrella:
1- I valori da cui vogliamo che partenza l’iterazione del programma per arrivare alla stima. Si
potrebbero mettere i risultati dell’equazione stimata con l’altro metodo, ma in questo caso i
valori di partenza non sono molto rilevanti: mettiamo 1 al coefficiente di REPOB (che è
vicino ad 1) e zero a tutti gli altri. I coefficienti devono essere preceduti dall’istruzione genr
2- L’equazione da stimare
3- L’istruzione params seguita dall’elenco dei coefficienti
4- L’istruzione end nls che indica la fine del procedimento.
genr b0=0
genr b1=0
genr b2=0
genr b3=0
genr b4=0
genr b5=0
genr b6=0
genr b7=1
nls REPOB = (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL +
b4*SENTIMENT + b5*GM33+ b6*RISK1 + b7*REPOB(-1))* (b0 + b1*gpcons_scarto +
b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT + b5*GM33+ b6*RISK1 + b7*REPOB(1) >= 1) + (b0 + b1*gpcons_scarto + b2*GDOLLAROM + b3*GPOIL + b4*SENTIMENT
+ b5*GM33+ b6*RISK1 + b7*REPOB(-1) < 1)
params b0 b1 b2 b3 b4 b5 b6 b7
end nls
37
Ecco il risultato:
38
Di nuovo il coefficienze del prezzo del petrolio non è più significativo e può essere eliminato.
Con la stima non lineare i test disponibili sono meno numerosi.
Comunque se si va a vedere i valori effettivi e si può notare che effettivamente gli ultimi valori
effettivi e stimati sono tutti 1: il vincolo che REPOB non possa scendere sotto 1 è rispettato.
La previsioni si effettua esattamente come nel caso della stima lineare:
39
6.La relazione tra Euribor e Repo
Un caso più complicato dei prevedenti, in cui occorre conoscere le previsioni dei regressori per
effettuare la stima delle variabile di nostro interesse è quello del legame tra Euribor e Repo.
La Banca Centrale Europea decide il tasso ufficiale (Repo) nelle prima riunione di ogni mese (a
parte casi eccezionali come l’8 ottobre scorso in cui le principali banche centrali si sono accordate
per una modifica dei rispettivi tassi ufficiali al di fuori delle riunione prevista dal calendario della
BCE).
Questo significa che il giorno successivo la riunione della BCE gli operatori sanno che per un mese
i tasso ufficiale rimarrà fermo. Di conseguenza, il valore dell’Euribor con scadenza 1 mese (R1M)
non risentirà delle aspettative sul futuro andamento del Repo perché per tutta la durata del contratto
il valore del Repo si manterrà costante.5
Ne consegue che, in condizioni normali, l’interbancario a 1 mese R1M sarò legato al valore del
tasso ufficiale. Unica eccezione è stato il periodo dalla crisi finanziaria in avanti, L’Euribor non è
un contratto garantito il cui rendimento ha risentito del rischio del mercato monetario (misurato
dalla variabile RISK1). Negli ultimi mesi, invece, l’enorme livello della liquidità (misurata dalla
variabile DEPOSIT_FACILITY) introdota dalla BCE ha portato a un rendimento dell’Euribor
particolarmente basse e inferiore al Repo
Nota: I dati immessi nel file vanno dal gennaio 1999 al dicembre 2009. E’ opportuno far iniziare
l’analisi dal 2000 in quanto durante il 1999 sia l’interbancario cje le aggiudicazioni nele operazioni
di rifinanziamento principali avevano manifestato alcuni problemi “tecnici”, etc.
6
R1M
REPO
5
4
3
2
1
0
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
Dal grafico emerge un parallelismo tra l’andamento del Repo REPO e del’Euribor a 1 mese R1M.
Durante la prima fase della crisi finanziaria (2007-fallimento di Lehman Brothers) i tasso a un mese
è nettamente sopra il Repo per l’effetto del rischio (RISK1); nella fase successiva della crisi,
quando la BCE ha creato un enorme ammontare di liquidità detenuta dalle banche sotto forma di
Deposit facilities (DEPOSIT_FACILITY), R1M risulta stabilmente sotto il REPO. Da questo
5
In realtà questo è vero solo in via approssimata perché la riunione della BCE, e quindi la fissazione del Repo, non
avviene sempre esattamente nello stesso giorno del mese.
40
risulta chiaro che sia RISK1 che DEPOSIT_FACILITY vanno introdotte tra le variabili esplicative
della relazione tra Euribor a 1 mese e Repo.
L’andamento di queste due variabili è riportato nella figura seguente:
400,000
300,000
200,000
100,000
1.2
0
1.0
0.8
0.6
0.4
RISK1
DEPOSIT_FACILITY
0.2
0.0
-0.2
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
Dalla prima figura emerge che i tassi sembrano comportarsi da I(1) (un andamento lento che non
oscilla attorno a un valore deterministico.
Più complicato è dare un giudizio sulle altre due variabili che appaiono rilevanti solo nell’ultimo
periodo. Normalmente quando questo accade le variabili sembrano comportarsi da I(0), anche se, in
realtà, la loro caratteristica non è stabile perché è cambiata nel tempo.
Procedimento mediante il
programma Gretl
Importare il file repo_euribor.wf1 (i dati disponibili vanno dal 1999.01 al 2009.12)
(cliccare su File, Apri dati, Importa, Eviews. Poi cerca le cartella dove c’è il file e clicca due
volte sul file repo_euribor.wf1; Cancella la finestrella di messaggio che esce
Per utilizzare come periodo di stima l’intervallo gennaio 2000 - dicembre 2009 l’istruzione è:
Cliccare su Campione, poi su Imposta intervallo e sistemare l’intervallo dal 2000.01 al
2009.12, poi dake l’OK
Le istruzioni per i grafici sono
Clicca su Visualizza, poi Grafico, Serie storica; fatto questo immetti mediante la freccia verde
41
le serie che ti interessano e dai l’OK per far apparire il grafico
Passiamo ora ai test di integrazione per accertarci che quando sembra dall’osservazione del grafico
sia corretto:
Cominciamo da R1M:
L’istruzione è
Evidenzia R1M cliccandogli sopra, poi clicca su Variabile e Test Dickey-Fuller aumentato.
Scegli l’alternativa con costante e metti un paio di ritardi. Poi dai l’OK.
La probabilità che l’ipotesi nulla di I(1) (non stazionarieà) sia accettabile è del 67,03%, cioè molto
alta (è persino superiore al 10%), quindi accettiamo l’ipotesi che la variabile R1M sia I(1).
42
Ora procediamo allo stesso modo con le altre variabili
La probabilità che REPO sia I(1) è del 55,88%, cioè molto alta (persino sopra il 10%) e accettiamo
quindi l’ipotesi che anche REPO sia I(1), cioè non stazionaria.
La probabilità che RISK1 sia I(1) è 0,018, ovvero dell’1,8%, cioè inferiore al 5% ma superiore
all’1%. Si tratta di un caso ambiguo. Dato anche il grafico supponiamo che sia I(0), cioè stazionaria.
La probabilità che DEPOSIT_FACILITY sia I(1) è 0,02016, ovvero del 2% , cioè inferiore al 5%
ma superiore all’1%. Si tratta di un caso ambiguo. Dato anche il grafico supponiamo che sia I(0),
cioè stazionaria.
A questo punto possiamo eseguire la nostra regressione tenendo presente che R1M e REPO sono
I(1), mentre per RISK1 e DEPOSIT_FACILITY abbiamo accettato l’ipotesi che sono I(0).
Usando il metodo diretto, nella nostra stima metteremo quindi come regressori i livelli ritardati in t1 sia di R1M che di REP , che sono I(1), insieme alle loro variazioni, mentre per RISK1 e
DEPOSIT_FACILITY, che sono I(0), metteremo solo i livelli. Per avere una stima più precisa
daremo inoltre l’istruzione Ls(n) e LS(h). Dato che si tratta del mercato interbancario introduciamo
un solo ritardo (eventualmente se ne mette uno in più per un controllo; quando si parlerà della
previsione dei tassi a lunga il problema del numero ottimo dei ritardi sarà trattato in maniera più
completa)
Dobbiamo però innanzitutto calcolare le variazioni di R1M e REP ,
Evidenziamo queste due variabili cliccando loro sopra, poi clicca su Aggiungi, Differenza delle
variabili selezionate. Le variazioni sono state chiamate d_R1M e d_REPO.
A questo punto eseguiamo la regressione. L’istruzione è: cliccare su Modello, poi OLS-Minimi
quadrati ordinari… . Quando appare la finestra immettere la variazione della dipendente e i
regressori
43
Clicchiamo su Imposta come predefinito (per non dover continuamente rimettere la
dipendente) , su Errori standard robusti (per una maggior precisione dei risultati e su Ritardi
per sistemate i ritardi dei regressori (I livelli delle I(1) vanno al tempo t-1, i livelli delle I(0) li
mettiamo al tempo t e al tempo t-1, la variazione del Repo va al tempo t e t-1, quella
dell’interbancario solo al tempo t-1:
44
Dando l’OK 2 volte appare la regressione:
(Ogni volta che si fa le regressione ricordarsi di controllare che ci sia l’opzione su Errori
45
standard robusti !!!).
L’R2 è alto (0,95) e l’h di Durbin (è un’aternativa al DW) è basso (se in valore assoluto è
minore di 2 si accetta l’ipotesi di assenza di autocorrelazione di prim’ordine al 5%, se è
minore di 3 si accetta l’assenza di autocorrelazione all’1%). Qui in valore assoluto è molto
basso (-0,35) e quindi i residui in t e t-1 non sono autocorrelati.
Per vedere il DW basta comunque clicare su Test, poi P-value di Durbin-Watson e il DW
appare insieme alla probabilità che non ci sia autocorrelazione
Il DW è molto vicino a 2 e infatti la probabilità che sia 2 è molto elevata.
A questo punto si clicca su Grafici poi Residui e infine su Rispetto al tempo per controllare
che non ci siano outliers. Dal grafico non si notano valori anomali (outliers), ma la varianza non
sembra stabile nel tempo (gli scarti sembrano essere elevati in assoluto al0inizio e alla fine del
periodo considerato). Questo porta a una distribuzione con curtosi alta che indebolisce le nostre
stime. In ogni caso il procedimento utilizzato (Errori standard robusti) ci dà dei valori corretti
46
per quanto riguarda la probabilità che le stime siano significative
A questo punto cominciamo ad eliminare uno per volta i coefficienti non significativi partendo da
d(R1M(-1)) che ha la massima probabilità di non essere significativamente diverso da 0 (35,94%,
ben sopra il 10%). Cliccare in alto della tabella della regressione su Modifica, poi Modifica
modello, eliminare d_R1M(-1) e dare l’OK.
A questo punto va eliminato d_REPO(-1), e, fatto questo, tutti i coefficienti restano significativi
almeno al 5%.
47
I segni sono quelli attesi: positivo per REPO(-1) e d(REPO) (l’Euribor mensile si aggiusta al tasso
ufficiale e ne segue i movimenti); negativo per DEPOSIT_FACILITY (maggior è la liquidità delle
banche e minore è il tasso interbancario); prevalentemente positivo per RISK1 (il coefficiente
0,893815 è in assoluto maggiore del coefficiente -0,426705); megativo per R1M(-1) (se il livello
del tasso interbancario è troppo alto ol suo valore deve diminuire nel periodo successivo, cioè la sua
variazione dev’essere negativa).
Inoltre l’R2 è alto, il DW vicino a due e, facendo il grafico dei residui non emergono anomalie.
Per quanto riguarda i valori di equilibrio, occorre dividere i vari coefficienti per il coefficiente di
R1M(-1) cambiato di segno (0.428704).
In particolare, essendo i due coefficienti di R1M(-1) e REPO(-1) molto vicini in valore assoluto, il
loro legame di equilibrio risulta vicino a 1:
R1M = … (0.426534 / 0.428704) * REPO(-1) … = … 0.994938 * REPO …
Per verificare che l’ipotesi di valore 1 sia accettabile (anche se in questo caso non sarebbe
necessario visto che è già praticamente 1), basta verificare l’ipotesi che i due coefficienti siano
uguali in valore assoluto ma di segno opposto, ovvero che la loro somma sia nulla.
Il test da utilizzare è quello di Wald. Si clicca su su Test, poi su Vincoli lineari
Quando si apre la finestra del test di deve introdurre la condizione che la somma del coefficiente
b[2] della seconda variabile + il coefficiente b[3] della terza variabile sia nullo.
48
L’ipotesi nulla passa a una probabilità molto alta 68.89% e quindi si può accettare l’ipotesi che il
coefficiente di equilibrio tra Euribor e Repo sia 1.
49
In alternativa a questa verifica, basata sulla stima dei movimenti dell’Euribor, si sarebbe
potuto anche utilizzare il metodo della cointegrazione per arrivare direttamente alla stima del
coefficiente di equilibrio senza dover stimare la regressione.
Il caso in esame è però complicato dalla presenza, nell’ultimo periodo, delle due variabili RISK1 e
DEPOSIT_FACILITY che sono I(0)
Conviene allora utilizzare tre diversi espedienti e controllare che i risultati siano coerenti.
Applichiamo la cointegrazione ai due tassi limitatamente al periodo precedente la crisi finanziaria,
cioè al periodo 2000.01 2007.07)
Definiamo quindi questo più ristretto l’intervallo di stima:
Cliccare su Campione, poi su Imposta intervallo e sistemare l’intervallo dal 2000.01 al
2007.07, poi dare l’OK
Passiamo al test di cointegrazione in cui entreno solo R1M e REPO.
Cliccare su Modello, Serie storiche, COINT – test di cointegrazione, Johansen…
Introdurre la variabili R1M e REPO e mettere 2 ritardi (per il calcolo del numero ottimo dei ritardi
50
si veda il vaso dei tassi a lunga). Poiché i tassi non presentano trend nella cointegrazione scegliamo
la seconda alternativa Costante vincolata (sarebbe comunque accettabile anche la terzo opzone
“Costante non vincolata” che si usa più propriamente quando nelle variabili sono presenti dei trend
deterministici); poi diamo l’OK
Poiché appare una solo probabilità bassa (minore dell’1 o del 5%) come p-value del test traccia
[0.0000] mentre l’altro è 0,9553 che è alto, accettiamo l’ipotesi che ci sia uno e un solo vettore di
equilbrio.
Il disequilibrio (Beta rinormalizzato) va letto in colonna e è:
R1M – 1.0026 *REPO – 0.0099723.
L’equilibrio è quindi (cambiano i segni)
R1M = 1.0026 *REPO + 0.0099723.
E quindi il coefficiente di eqilibrio tra R1M è REPO è 1,0026, cioè praticamente 1.
51
Anche se in questo caso sembra inutile, è comunque possibile verificare se è accettabile l’ipotesi
che 1,0026 non sia significativamente diverso da 1.
Il procedimento è il seguente:
Cliccare su Modello, Serie storiche, VECM… A questo
A questo punto riappare la schermata della cointegrazione. Rimettiamo 2 come ordine dei ritardi e
lasciamo 1 come rango di cointegrazione perché esiste un solo vettore di equilibrio. L’opzione
“costante vincolata” appare già automaticamente. A questo punto diamo l’OK.
52
Diamo l’OK.
A questo punto per eseguire il test si deve cliccare su Test poi su Vincoli lineari. Quando si apre
la finestra si mettono i vincoli (si ricordi che il primo coefficiente va chiamato b[1], il secondo
b[2], etc.
53
E metti il vincolo che il coefficiente di R1M sia 1, mentre quello di REPO sia -1 anziché -1,0026
Una volta dato l’OK esce la seguente tabella finale, da cui risulta che l’ipotesi è accettabile al
66,2388%. Poiché questa probabilità è ben superiore al 10% (e quindi anche al 5% e all’1%)
accettiamo l’ipotesi che il coefficiente sia 1 e che quindi, nel periodo in cui la crisi economica era
assente, il valore di equilibrio dell’Euribor a 1 mese R1M era legato a quello del tasso ufficiale
REPO da una relazione del tipo R1M = REPO + costante
54
In assenza di crisi economica esiste quindi un legane di 1 a 1 tra l’Euribor a un mese e il Repo.
In alternativa si possono usare tutti i dati disponibili, compreso il periodo della crisi, mettendo
RISK1 DEPOSIT_FACILITY RISK1(-1) DEPOSIT_FACILITY(-1) nella finestrella delle
esogene
Il vantaggio è che così utilizziamo tutti i dati ma, d’altra parte, i test perdono di validità (i “veri”
valori dei test risultano ignoti e quindi quindi le significatività sono solo indicative. Includiam
quindi queste variabili ra le esogene d diamo l’OK
Allarghiamo di nuovo il periodo di stima dal 2000.02 al 2009.12:
Cliccare su Campione, poi su Imposta intervallo e sistemare l’intervallo dal 2000.01 al
2009.12, poi dare l’OK
Passiamo al test di cointegrazione in cui nel’equilibrio entrano solo le variabili I(1) R1M e REPO,
mentre le variabili I(0) RISK1 DEPOSIT_FACILITY RISK1(-1) DEPOSIT_FACILITY(-1)
entrano come esogene, cioè contribuiscono a influenzare la relazione ma non sono
influenzate da R1M e REPO. In questo caso, però, visto che mettiamo due ritardi, dobbiamo
prima creare le variabili ritardate di RISK1 e DEPOSIT_FACILITY oppure, il che è più semplice,
le loro variazioni d introdurre insieme ai livelli in t. Per fare questo basta evidenziare queste due
variabili e poi cliccare su Aggiungi e Differenze della variabili selezionate. Le nuove
variabili si chiamano d_RISK1 e d_DEPOSIT_FAC.
Clicchiamo ora su Modello, Serie storiche, COINT – test di cointegrazione, Johansen…
e operiamo esattamente come nel caso precedente tranne per il fatto che introduciamo le variabili
I(0) tra le esogene. Queste esogene vanno messe in forma “non vincolata”, che è per altro quella che
appare automaticamente.
55
Di nuovo, il coefficiente del REPO è vicino a 1
Le relazioni così utilizzate possono essere impiegate per prevedere i tasso a un mese date le
previsioni del tasso ufficiale. Per quanto riguarda il prossimo futuro, sia in base alle aspettative
degli operatori (si veda per es. il sito di bfinance), sia in base alle dichiarazioni della BCE, il Repo
resterà all’’1% mentre la liquidità rimarrà elevata e il rischio rimarrà vicino a zero. Di conseguenza
L’Euribor a 1 mese resterà inferiore a 1 punto (per avere stime più precise utilizzare la relazione di
equilibrio che emerge dalle nostre stime). Successivamente la liquidità verrà progressivamente
eliminata e l’Euribor a 1 mese salirà a un livello leggermente superiore all’1% per poi seguire i
successivi movimenti (verso l’alto) del tasso ufficiale.
56
7. Un altro esempio di previsione: i tassi a
lunga
1 - introduzione a un caso più complicato
Un esempio di previsione (più complicato dei precedenti) riguarda il tasso a lunga (decennale)
europeo. Quest’esempio, come vedremo, s’inquadra nello schema:
(1)
Yt = F( Xt, Yt-1 , Xt-1 )
In tale schema, come già sottolineato nella prima dispensa, sorge il problema della “conoscenza” in
t del futuro valore della variabile X, cioè del reperimento di qualche sua stima o previsione Et[Xt+1]
indispensabile, a sua volta, per la previsione di Yt+1 tramite l’impiego della (1):
(2)
Et[Yt+1] = F( Et[Xt+1], Yt , Xt )
L’analisi teorica condotta sui tassi a lunga e basata sull’ipotesi di sostituibilità fra i titoli della
diverse scadenze e delle diverse valute suggerisce infatti la seguente relazione di equilibrio:
(3)
RY10t = F(UY10 t, REPOt , FED_FUNDMED t )
(+)
(+)
(-)
Dove RY10 e UT10 sono rispettivamente i rendimenti interbancari decennali (swaps) della zonaEuro e negli USA; REPO e FED_FUNDMED sono rispettivamente il tasso ufficiale europeo e
quello americano (per il periodo dal dic. 2008 in avanti come tasso americano si è preso il valor
medio della fascia obiettivo della Fed che corrisponde a 12,50 punti base. Come tassi a breve si è
preferito utilizzare i tassi ufficiali anziché i tassi dell’interbancario (Euribor e Libor sul dollaro)
perché i rendimenti decennali qui utilizzati, in quanto swaps, poco sensibili al rischio.
Le ragioni teoriche di questa relazioni sono già state analizzate nel corso di Economia dei mercati
finanziari.
Senza voler entrare nei particolari, la relazione (3) è basata sulle ipotesi che:
- i futures (o i tassi impliciti) relativi a una consegna molto differita nel tempo sono sensibili
agli analoghi futures in dollari.
- i futures (o i tassi impliciti) relativi a una consegna vicina nel tempo risentono soprattutto
dell’andamento del tasso ufficiale della zona Euro (Repo)
- il tasso decennale RY10, che corrisponde alla media dei futures (ovvero dei tassi impliciti) a
consegna da 0 a 10 anni in euro, sono quindi una media ponderata del futures a consegna
molto differita in euro (che è legata al rendimento del corrispondente future in dollari
UFY10) e del REPO, cioè del tasso a breve (tasso ufficilale) della zona Euro. Ne consegue
che RY10 = q1 UFY10 + q2 REPO
- Il tasso decennale americano UY10 corrisponde alla media dei futures (ovvero dei tassi
impliciti) a consegna da 0 a 10 anni; essi sono quindi una media ponderata del futures a
consegna molto differita in dollari UFY10 e del tasso a breve FED_FUNDMED. Ne
consegue che UY10 = q1$ UFY10 + q2$ FED_FUNDMED.
- Risolvendo per UFY10 si ottiene UFY10 = UY10/q1$ - q2$ FED_FUNDMED / q1$ .
57
Sostituendo quest’ultima relazione nell’equazione di RY10 si ottiene quindi
RY10 = q1 UY10/q1$ - q1 q2$ FED_FUNDMED/ q1$ + q2 REPO
ovvero:
(4)
RY10 = h1 UY10 + h2 REPO + h3 FED_FUNDMED
Dove h1 = q1 /q1$ , h2 = q2 e h3 = - q1 q2$ /q1$
Poiché 10 anni sono una scadenza “lunga”, ci aspettiamo che h1 > h2 e h1 > abs( h3 ).
Inoltre, se i mercati europeo ed americano si comportassero al loro interno in maniera analoga
dovrebbe essere q1 q1$ e q2 q2$ . Se quest’ipotesi fosse realistica, allora h1 = q1 /q1$ 1 e h3
= - q1 q2$ /q1$ q2$ ; da cui h2 = q2 - h3 dato che q2 q2$.
In definitiva, nel caso i due mercati dei decennali europeo e americano avessero le stesse
caratteristiche di comportamento, nella (4) si dovrebbe poter trovare che h1 1 e h3 - h2.
In questo caso la (4) potrebbe anche essere semplificata in:
(4’)
RY10 = UY10 + h2 (REPO - FED_FUNDMED)
Ovvero
(4’’) (RY10 - UY10) = h2 (REPO - FED_FUNDMED)
3
RY10 - UY10 (scala a sinistra)
REPO - FED_FUNDMED (scala a destra)
2
2
1
1
0
-1
0
-2
-1
-3
-2
99
00
01
02
03
04
05
06
07
08
09
Effettivamente, dal grafico sembra che I due differenziali siano paralleli come previsto dalla (4’’) e
l’ipotesi, almeno apparentemente, sembra valida.
2 - Il grado d’integrazione delle variabili
Prima di eseguire la stima della nostra relazione è assolutamente consigliabile individuare il grado
d’integrazione delle variabili. Nel caso in questione l’analisi potrebbe essere evitata perché
notoriamente i tassi sono considerati I(1). In effetti il grafico del tasso a lunga europeo (RY10)
presenta una notevole persistenza nei movimenti, tipica di queste variabili. In ogni caso, possiamo
effettuate il relativo test come ulteriore conferma di quanto già appare probabile da una semplice
osservazione del grafico, e il risultato accetta l’ipotesi di I(1). Dato che si tratta di dati mensili di
tassi, con il test ADF 6 ritardi o anche meno sono più che sufficienti
58
6.5
Rendimento dell'EURIRS decennale (RY10)
6.0
5.5
5.0
4.5
4.0
3.5
3.0
99
00
01
02
03
04
05
06
07
08
09
Col programma GRETL dobbiamo cliccare su RY10 , poi sul tasto Variabile posto in altro della
finestra, poi su Test Dickey-Fuller aumentato (o un altro test di integrazione)
59
Il programma sceglie un ordine di ritardo pari ad 1 (eventualmente proviamo per prudenza a rifare
il test con qualche ritardo in più, es. 3)
Visto che i tassi normalmente non presentano trend scegliamo la condizione “con costante”, poi
diamo l’OK.
L’ipotesi nulla di radice unitaria ha una probabilità del 51%. Accettiamo quindi l’ipotesi che il
tasso sia un I(1) perché la probabilità è alta (addirittura sopra il 10%)
La verifica del grado d’integrazione delle altre variabili procede nello stesso modo, e tutte risultano
I(1). La stima va quindi effettuata mediante un’equazione che tenga conto di questa caratteristica
delle variabili.
60
Il procedimento utilizzando Gretl
Importare il File: tassi_a_lunga.wf1
Per semplicità non eseguiamo i test d’integrazione sulle singole variabili perché sappiamo già che
sono I(1): v. la precedente dispensa per relative istruzioni.
Per prudenza indichiamo anche il periodo di stima anche se non necessario il quanto il programa
automaticamente utilizza tutte le osservazioni disponibili
Cliccare in alto su Campione, poi su Imposta intervallo e sistemate il periodo 1999.01 –
2009.12 nella finestrella che si apre:
Generiamo le variazioni delle nostre variabili. Selezioniamo le variabili che c’interessano, poi
clicchiamo Aggiungi e successivamente su poi su Differenze delle variabili selezionate. Le
variazioni vengono generate e messe alla fine del file
61
Le variazioni delle variabili si formano automaticamente e vanno in fondo (il nome è lo stesso
delle variabili preceduto da “d_”
a) Il metodo diretto
Si stima direttamente la dinamica dell’equazione. Prima di tutto cerchiamo il numero ottimo di
ritardi.
Partiamo innanzitutto dalla relazione che come dipendente la variazione d_RY10 e come
indipendenti, oltre alla costante, e i livelli di tutte le variabili in t-1 e le variazioni delle variabili
esogene in t d_UY10 d_REPO d_FED_FUNDMED
La nostra regressione deve avere d_RY10 come variabile dipendente e come variabili
indipendenti c RY10(-1) UY10(-1) REPO(-1) FED_FUNDMED(-1) d(UY10) d(REPO)
d(FED_FUNDMED)
Cliccare su Modello poi OLS- Minimi quadrati ordinari… , poi metti nel modello mediante le
frecce la dipendente d_RY10 e le indipendenti RY10 UY10 REPO FED_FUNDMED
d_UY10 d_REPO d_FED_FUNDMED (ricordarsi che utilizzando Gretl la dipendente d_RY10
e i suoi ritardi non vanno mai introdotti manualmente messi tra i regressori).
62
Cliccare anche su Imposta come predefinito vicino al nome della dipendente per non dover
continuamente rimmettere d_Ry10 a ogni ristima dell’equazione.
A questo punto occorre porre il livelli delle variabili con ritardo 1. Per far questo cliccare su
Ritardi e sistemare i ritardi nella finestra che si apre, poi dare l’OK. La finestra dei ritardi si
chiude
A questo punto nella finestrella delle variabili della regressione cliccare su Errori standard
robusti per avere stime più precise delle probabilità che i vari coefficienti siano diversi da zero.
Poi dare l’OK.
63
A questo punto eseguire la regressione cliccando su OK
64
Prendere nota dei criteri di Akaike (-178,3071), di Schwarz (-155,3057) e Hannan-Quin (168,9067. Il numero ottimo di ritardi si ha per la regressione con i più bassi valori di questi tre
criteri (in caso di ambiguità si preferisce il criterio di Schwarz)
Introdurre ora anche i ritardi in t-1 di tutte le variazioni.
Cliccare di nuovo su Modello poi OLS- Minimi quadrati ordinari… Cliccare su Ritardi e
sistemare i ritardi:
Dare l’OK; si torna alla schermata delle variabili delle regressione
Cliccare su Errori standard robusti per avere stime più precise delle probabilità che i vari
coefficienti siano diversi da zero. Poi dare l’OK. Appare il risultato della nuova regressione
65
I valori dei criteri di Akaike (-170.7937), di Schwarz (-136,3833) e Hannan-Quin (-156,8181) sono
tutti aumentati, quindi l’introduzione dei ritardi in t-1 delle variazioni delle variabili ha peggiorato
le stime. La regressione senza questi ritardi era quindi migliore ed è quella che useremo per le
nostre stime.
Si potrebbe fare un ulteriore controllo introducendo i ritardi in t-3 e t-4, ma i risultati
peggiorerebbero ancora. Si noti che nel caso di variabili con forte stagionalità (es. la moneta) non
destagionalizzati occorrerebbe sempre provare, con i dati mensili, il ritardo t-12.
Il numero ottimo di ritardi per le variazioni delle variabili è quindi zero (mettere tra le indipendenti
soltanto le variazioni in t delle variabili esogene)
In alternativa a questo metodo si può cercare il numero ottimo dei ritardi ricorrendo a un
VAR
- Cliccare su Modello in alto, poi su Serie storiche , poi su Quick e infine su Scelta
ritardi VAR
66
Quando si apre la finestra del Selezioni ritardi del VAR mettere nella sezione Variabili
endogene solo i livelli delle variabili RY10, UY10, REPO e FED_FUNDMED(-1) senza
ritardi. A questo punto mettere nella finestrella Ordine dei ritardi in numero massimo di ritardi
che vuoi considerare (qui c’è 12, ma 6 o 8 sono più che sufficienti), poi dare l’OK.
A questo punto mettere nella finestrella Ordine dei ritardi in numero massimo di ritardi che vuoi
considerare (qui c’è 12, ma 6 o 8 sono più che sufficienti), poi dare l’OK.
67
Appare una tabella e il numero ottimo di ritardi relativo ai livelli delle variabili corrisponde a
quello con i valori più bassi di ogni colonna. In caso di ambiguità considerare il BIC (Criterio
bayesiano di Schwartz). In questo caso il numero ottimo dei ritardi è 1
Poiché il numero ottimo di ritardi dei livelli è 1, il numero ottimo della variazioni da
includere nella regressione diventa zero. Infatti, per definizione di variazione, le variazioni
fanno sempre riferimento a due livelli adiacenti (il primo meno il secondo) e quindi il numero
ottimo di variazioni da considerare è uguale a quello che emerge dal test sui livelli meno uno.
Questo numero ottimo di ritardi è comunque coerente con quello già trovato prima.
A questo punto resta confermato che possiamo eseguire la nostra regressione con la dipendente
espressa in variazione e utilizzando come regressori i valori in t-1 dei livelli di tutte le varizbili cui
si aggiungono le sole variazioni in t delle esogene, esattamente come avevamo fatto all’inizio.
Cliccare su Modello poi OLS- Minimi quadrati ordinari… , poi metti nel modello mediante le
frecce la dipendente d_RY10 e le indipendenti RY10 UY10 REPO FED_FUNDMED
d_UY10 d_REPO d_FED_FUNDMED (ricordarsi che utilizzando Gretl la dipendente d_RY10
e i suoi ritardi non vanno mai introdotti manualmente messi tra i regressori).
68
Cliccare anche su Imposta come predefinito vicino al nome della dipendente per non dover
continuamente rimmettere d_Ry10 a ogni ristima dell’equazione.
A questo punto occorre porre il livelli delle variabili con ritardo 1. Per far questo cliccare su
Ritardi e sistemare i ritardi nella finestra che si apre, poi dare l’OK. La finestra dei ritardi si
chiude
A questo punto nella finestrella delle variabili della regressione cliccare su Errori standard
robusti per avere stime più precise delle probabilità che i vari coefficienti siano diversi da zero.
Poi dare l’OK.
69
A questo punto eseguire la regressione cliccando su OK ed ecco il risultato.
70
I segni dei livelli sono quelli che ci aspettiamo in base alla nostra teoria e all’ipotesi che il mercato
tenda sempre all’equilibrio (= il coefficiente di RY10_1, cioè del valore ritardato RY10(-1),
dev’essere negativo).
L’R2 corretto (0,530) è abbastanza buono considerando che la dipendente è espressa in
variazioni). Il DW = 1.958 è ottimo (molto vicino a 2).
Vediamo ora che i residui per un controllo visivo dell’assenza di outliers. Si clicca su Grafici (in
alto), poi Residui, infine su Rispetto al tempo. (Per vedere il grafico con i valori effettivi e
stimati cliccare su Valori effettivi e stimati anziché su Residui )
I residui sembrano a posto. Non si rilevano punte particolarmente anomali
Vediamo anche gli altri principali test, tenendo presente che, una volta effettuato un test, il
suo risultato viene automaticamente aggiunto sotto la tabella con la stima della regressione
(per vederli spingere eventualmente il cursore verso il basso.
1) La normalità dei residui: cliccare su Test (terzo pulsante in alto)
71
Si apre una finestra:
Cliccare su TESTUHAT – Normalità residui.
L’asimmetria e la curtosi sembrano ottime e infatti la probabilità che la distribuzione dei nostri
residui una sia normale è alta (48,7%)
72
Possiamo quindi accettare l’ipotesi di normalità dei residui
2) Per verificare che la varianza sia costante nel tempo e non sia legata ai valori dei
regressori facciamo i test di omoschedasticità. Cominciamo dal primo per verificare che
la varianza sia costante nel tempo. Cliccare su Test (terzo pulsante in alto) del risultato
della regressione, poi su ARCH – Eterochedasticità condizionale.
73
Mettere 2 nella finestrella che si apre per l’ordine dei ritardi e dare l’OK
La probabilità che la varianza sia costante nel tempo è alta (0,392) e quindi si accetta
l’ipotesi di omoschedasticità. Un test alternativo è l’ LMTEST-eteroschedasticità:
cliccando sopra esce la finestrella
I test di White servono per verificare che la varianza sia indipendente dai regressori.
Entrambi passano al 5% perché la probabilità che il legame con ci sia è oltre questo valore.
Il test di Breusch-Pagan passa: la probablilità che la varianza sia costante è del 0,262841,
nettamente superiore persino al 10%. Idem la sua versione come test di Koenker (la probabilità
di varianza costante è pari 0,193486, cioè del 19%)
74
Possiamo quindi concludere che i nostri residui sono omoschedastici. Tutti i test sono
soddisfatti.
3) Indipendenza dei residui nel tempo
Abbiamo già visto che il DW è vicino a due e non vi è quindi autocorrelazione di prim’ordine. La
probabilità esatta che il valore del DW non sia significativamente diverso da 2 la si ottiene
comunque cliccando su Test (terzo pulsante in alto) del risultato della regressione, poi su pValue di Durbin-Watson. La probabilità che si ottiene p-value = 0,28058, quindi maggiore
persino del 10% e possiamo possiamo accettare l’ipotesi che il DW sia 2.
Per verificare l’indipedenza del residui nel tempo oltre il primo ordine cliccare sul testo Grafici in
alto della tabella col risultato della regressione, poi su Correlogramma dei residui e mettere 6
come ritardo massimo (se vi fossero delle variabili con una forte stagionalità occorrerebbe mettere
12, ma questo non è il nostro caso)
Tutte le probabilità sono alte e quindi l’indipendenza dei residui è garantita autocorrelazione
nulla fino al sesto ordine
75
In alternativa di potrebbe cliccare su Test (terzo pulsante in alto) del risultato della
regressione, poi su LMTEST - Autocorrelazione. Nella finestrella che si apre mettere 6
come ordine di ritardi, che è sufficiente. Poi dare l’OK
Tutte le probabilità sono alte e quindi il test di indipendenza dei residui passa anche ben oltre
il 10%
76
In definitiva possiamo accettare l’ipotesi che i residui siano indipendenti nel tempo.
4) Per la correttezza della forma della relazione si può fare il test RESET: cliccare su su
Test (terzo pulsante in alto) del risultato della regressione, poi su RESET-Ramsey.
Lasciare l’opzione automatica “quadrati e cubi” e dare l’OK
La probabililità che la forma delle relazione dia corretta è elevata e quindi si può accettare
l’ipotesi nulla di correttezza della forma della funzione utilizzata (non occorrono log, etc.)
77
5) La stabilità della funzione può essere verificata con i due test CUSUM. Cliccare su su
Test (terzo pulsante in alto) del risultato della regressione, poi su CUSUM - stabilità
parametri e dare l’OK. Fatto questo test si può passare al CUSUMQ – Stabilità
parametri e dare l’OK. Questo secondo test verifica che siano congiuntamente stabili sia i
coefficienti che la varianza dei residui
Per entrambi i test il grafico è all’interno dell’intervallo di confidenza del 5% e quindi si può
accettare l’ipotesi che i coefficienti siano stabili (test CUSUM) e che siano
contemporaneamente stabili sia i coefficienti che la varianza (test CUSUMQ):
78
Altri test possono essere eseguiti a richiesta:
79
Per far questo cliccare su Test (terzo pulsante in alto della tavella con i risultati della regressione)
Si apre una finestra e si sceglie il test che si vuole effetuare
Ritornando nella tabella con i risultati della regressione, basta spingere col cursore verso il
basso per veder apparire automaticamente i principali risultati dei test effettuati:
Test per la normalità dei residui Ipotesi nulla: L'errore è distribuito normalmente
Statistica test: Chi-quadro(2) = 1,4382
con p-value = 0,487191 OK: probabilità molto alta (> 10%)
Test per l’omoschedasticità (varianza dei residui costante bel tempo)
Test per ARCH di ordine 2 Ipotesi nulla: non sono presenti effetti ARCH
Statistica test: LM = 1,87026
con p-value = P(Chi-Square(2) > 1,87026) = 0,392535 OK: probabilità molto alta (> 10%)
Test per l’omoschedasticità (varianza dei residui indipendente dal valore dei regressori)
Test di White per l'eteroschedasticità Ipotesi nulla: eteroschedasticità non presente
Statistica test: LM = 48,4778
con p-value = P(Chi-Square(35) > 48,4778) = 0,0644525 OK: probabilità maggiore del 5%
Test di White per l'eteroschedasticità (solo quadrati) Ipotesi nulla: eteroschedasticità non presente
Statistica test: LM = 21,0812
con p-value = P(Chi-Square(14) > 21,0812) = 0,0995709 OK: probabilità maggiore del 5%
Test per l’omoschedasticità (varianza dei residui costante bel tempo)
Test di Breusch-Pagan per l'eteroschedasticità Ipotesi nulla: eteroschedasticità non presente
Statistica test: LM = 8,86031
con p-value = P(Chi-Square(7) > 8,86031) = 0,262841 OK: probabilità molto alta (> 10%)
Test di Breusch-Pagan per l'eteroschedasticità (variante robusta) Ipotesi nulla: eteroschedasticità non presente
Statistica test: LM = 9,91423
con p-value = P(Chi-Square(7) > 9,91423) = 0,193486 OK: probabilità molto alta (> 10%)
80
Test LM per l'autocorrelazione fino all'ordine 6 Ipotesi nulla: Non c'è autocorrelazione
Statistica test: LMF = 0,778314
con p-value = P(F(6,117) > 0,778314) = 0,588538 OK: probabilità molto alta (> 10%)
Test RESET di specificazione – (correttezza della forma della relazione stimata)
Ipotesi nulla: la specificazione è adeguata
Statistica test: F(2, 121) = 0,61682
con p-value = P(F(2, 121) > 0,61682) = 0,541346 OK: probabilità molto alta (> 10%)
Test CUSUM per la stabilità dei parametri Ipotesi nulla: nessun cambiamento nei parametri
Statistica test: Harvey-Collier t(122) = 2,50474
con p-value = P(t(122) > 2,50474) = 0,0135733 Accettabile: probabilità > 1% ma < 5%
A questo punto, visto che la nostra regressione è “ottima” dal punto di vista statistico (tutti i
test passano), possiamo cercare di migliorare ulteriormente le stime cominciando
dall’eliminare le variabili inutili (attenzione: non eliminare mai la costante se non alla fine).
Gretl suggerisce automaticamente il consiglio su qual variabile cominciare ad eliminare.
Subito dopo la regressione appare infatti la scritta
“Escludendo la costante, il p-value è massimo per la variabile 6 (d_REPO)”
Poiché la probabilità che il coefficiente di d_REPO sia nullo è oltre il 10% (la probabilità è
0,9349: si veda il risultato della regressione), infatti la probabilità non è contrassegnata da
asterischi (* = significativa al 10%, ** = significativa l 5%, *** = significativa all’1%) conviene
rifare la regressione senza questa variabili.
Per far questo cliccare sul tasto Modifica in alto sulla tabella della regressione
Poi clicca su Modifica modello…
81
E a questa punto evidenzia d_Repo e eliminalo cliccano sulla freccia rossa
Dando l’OK la regressione viene rifatta e a questo punto emerge che può essere eliminato anche
D(FED_FUNMED) che, nella nuova regressione, ha una probabilità di 0.792 di essere non
significativa. Eliminata anche questa variabile si arriva alla regressione “pulita” (per prudenza
lasciamo la costante anche se non è significativa). Il programma infatti con consiglia più di
eliminare variabili e tutte le probabilità (a parte la costante) sono asteriscate.
82
Qui tutti i coefficienti sono significativi (nessuno ha probabilità maggiore al 5% e tantomeno al
10%. La costante non è significativa ma può essere anche lasciata.
Non resta ora che verificare, se lo si ritiene utile, se sia accettabile l’ipotesi che nella relazione di
equilibrio
RY10 = h1 UY10 + h2 REPO + h3 FED_FUNDMED
il coefficiente di UY10 sia 1 e che il coefficiente (negativo) di FED_FUNDMED sia in valore
assoluto uguale a quello di quello di REPO
Poiché i coefficienti di equilibrio sono dati dai coefficienti dei livelli delle variabili indipendenti
ritardate di 1 divise per il coefficiente della dipendente, i coefficiente di equilibrio delle variabili
esplicative saranno dati (tenendo conto che il coefficiente di RY10(-1) è -0.164099) da:
h1 = 0.136887 / 0.164099 (terzo coefficiente b[3] dall’alto diviso il secondo b[2] cambiato di
segno)
h2 = 0.058393 / 0.164099 (quarto coefficiente dall’alto b[4] diviso il secondo b[2] cambiato di
segno)
h3 = -0.030193 / 0.164099 (quinto coefficiente dall’alto b[5] diviso il secondo b[2] cambiato di
segno)
E’ quindi evidente che affinché il coefficiente di equilibrio h1 di UY10 sia 1, occorre che
-b[3]/b[2]=1, cioè che il terzo coefficiente b[3] sia uguale a –b[2], ovvero che b[2]+b[(3] = 0
A sua volta, affinché h3 = - h2 occorre che -b[5]/b[2] sia uguale a –[-b[4]/b[2]] = b[4]/b[2],
ovvero che -b[5]=b[4], cioè b[4]+b[5]=0
La verifica di queste ipotesi sui coefficienti si fa con il test di Wald.
Cliccare su Test in altro nel riquadro del risultato delle regressione, poi cliccare su Vicoli
lineari.
E a questo punto introdurre i vincoli (il numero tra parentesi quadra indica il coefficiente partendo
dall’alto in basso). Dopo ogni vicolo andare a capo
83
Una volta dalto l’OK appare il testo di Wald per i vincoli sui coefficienti e la stima vincolata
La probabilità che i vincoli siano validi è del 23% e quindi i vincoli possono essere accettati. Dopo
l’introduzione dei vincoli sembrerebbe che anche REPO_1 e FED_FUNDMED_1 non siano più
significativi (mancano gli asterischi e infatti la probabilità è di 11,95%, cioè maggiore del 10%). I
due coefficienti rimarrebbero significativi limitando il vincolo a b[2] + b[3]=0
In ogni caso, dato il numero basso di coefficienti rispetto al numero dei dati, la nostra
previsione può benissimo essere basata sull’equazione non vincolata dove tutti i coefficienti
84
sono lasciati liberi, dal momento che il guadagno di efficienza delle stime ottenuto introducendo
i vincoli è comunque modesto.
a) Il metodo indiretto
Col metodo indiretto prima si trova l’equilibrio e poi si passa a studiare la dinamica.
I passaggi sono questi:
-
Determinare il numero ottimo dei ritardi ricorrendo a un VAR (vedi la relativa
istruzione riportata per il metodo diretto). Nel nostro caso il numero ottimo di ritardi per i
livello delle variabili risulta 1
-
Stimare il vettore di cointegrazione mettendo come ritardi il numero ottimo di ritardi
trovato nel passo precedente. L’istruzione è:
Andare su Modello, poi Serie storiche e infine COINT-test di Cointegrazione e
Johansen.
85
Quando si apre la finestra del il test di cointegrazione mettere i livelli delle variabili
(dipendenti e indipendential) tempo t nello spazio per le variabili da testare.
Come ordine dei ritardi va messo 1 che è il numero ottimo che avevamo già trovato
Infine nella finestrella in basso mettiamo “costante vincolata”, questo perché i nostri
tassi non hanno trend. In caso contrario si metterebbe “costante non vincolata”
A questo punto si da l’OK ed ecco il risultato:
86
Sfortunatamente i vettori di cointegrazione risultano essere tre, come risulta dal fatto che la
colonna di Test traccia p-value ha tre probabililità inferiori agli usuali valori di
significatività (0,000; 0.000; 0,0016, tutti inferiori all’1% di probabilità)
Tra le nostre variabili ci sarebbero quindi tre equilibri. La cosa è spiacevole perché quando gli
equilibri sono più di uno diventa difficile trattare il problema dal lato economico (a meno di
una notevole esperienza!). Quando questo succede è meglio normalmente lasciar perdere il
metodo indiretto e utilizzare il metodo diretto.
Volendo comunque a provare il metodo indiretto, nel nostro caso un’alternativa potrebbe essere
quella di provare a stimare la relazione di equilibrio soggetta ai vincoli teorici (vedi la precedente
(4’’) (RY10 - UY10) + h2 (REPO - FED_FUNDMED) )
Definiamo quindi le due nuove variabili chiamando al prima per es. DIFFLUNGO (data da
(RY10 - UY10) ) e la seconda DIFFBREVE (data da (REPO - FED_FUNDMED) ) )
Le istruzione per generare queste variabili è la solita già viste in precedenza:
Tornando alla schermata iniziale si clicca su Aggiungi, poi su Definisci nuova variabile e si
mette infine la definizione della prima variabile nella finestrella.
87
E poi si scrive la definizione della seconda variabile
A questo punto riproviamo la cointegrazione basata sul vincolo teorico tra le variabili:
88
Questa volta la soluzione è unica. C’è un solo p-value del test della traccia che probabilità bassa (il
primo) e quindi, se si accetta il vincolo teorico tra le variabili, la soluzione esiste ed è unica.
89
Il disequilibrio è dato dal “Beta rinirmalizzato” (se non si vede spingere verso il basso la
finestra).
Il disequilibrio è quindi DIFFLUNGO – 0.38523*DIFFBREVE +0,59904
E l’equilibrio è pertanto DIFFLUNGO = 0.38523*DIFFBREVE - 0,59904
Resta però il dubbio che vi potrebbero essere altri disequilibri che influenzano le variazione del
tasso europeo.
La significatività dei coefficienti, come pure i loro eventuali test, si ottengono ripetendo il
procedimento Modello, poi Serie storiche. Poi però si deve andare su VECM (anziché su
COINT-test di Cointegrazione) e si dà l’OK. Esce una schermata con il risultato
90
Cliccando su Salva e poi su Termine EC1 il programma calcola automaticamente e salva il
disequilibrio in t-1 che viene chiamato EC1. (il nome può comunque essere modificato a piacere)
91
-
A questo punto si esegue una regressione sulle variazioni come per il metodo diretto
(“dinamica”), tranne che al posto dei valori ritardati del livelli delle variabili si mette il
disequilibrio al tempo t-1 che è stato chiamato EC1. Il numero ottimo dei ritardi si è già
visto che è 1 per i livelli (e quindi zero per le variazioni) e quindi:
Dando l’OK esce il risultato
92
A questo punto si procede come già visto per il metodo diretto eseguendo i vari test ed
eliminando le variabili non significative.
6 – Che cosa occorre per poter effettuare la previsione per il caso della nostra equazione dei tassi
a lunga
La nostra equazione del tasso a lunga europeo che spiega (RY10t) contiene come regressori le
variabili contemporanee (UY10t) = UY10t - UY10t-1 e le variabili ritardate di un mese di
RY10t-1, UY10 t-1, REPOt-1 e FED_FUNDMEDt-1.
Questo significa che per stimare la variazione del tasso europeo in t+h occorre conoscere i valori in
t+h-1 di U10Y, di REPO e FED_FUND_MED e della variazione di U10Y in t+h.
In pratica, se la stima si riferisce a un periodo molto lontano, è sufficiente utilizzare la relazione di
equilibrio, in quanto è realistico supporre che in un periodo abbastanza lungo il mercato si sia
pressoché totalmente aggiustato:
RY10 = h0 + h1 UY10 + h2 REPO + h3 FED_FUNDMED
Dove
h1 = -0.041488 / 0.164099 = -0.252
h1 = 0.136887 / 0.164099 = 0.834
h2 = 0.058393 / 0.164099 = 0.356
h3 = -0.030193 / 0.164099 = -0.184
93
cioè
RY10 = -0.252 + 0.834*UY10 + 0.356*REPO -0.184*FED_FUNDMED
Se invece il periodo future fosse più vicino, o se avessimo tutta le serie delle previsioni dall’ultimo
dato disponibile in avanti, sarebbe più opportuno utilizzare la stima dinamica applicata a tutte le
serie disponibili.
Per esempio, supponiamo di essere ad aprile 2010.
I dati di REPO, FED_FUNDMED, RY10 e UY10
Sono già tutti disponibili su interne (vedi per gli indirizzi il sito
economia.unipr.it/DOCENTI/VERGA/docs/files/quotazioni_fonti1_ter.doc )
Dati di fine mese:
REPO
FED_FUNDMED
RY10
UY10
(Swaps)
1
1
1
0.125
0.125
0.125
3.440
3.360
3.260
3.77
3.70
3.83
2010.01
2010.02
2010.03
Titoli di
Stato USA
10 anni
3.65
3.61
3.84
Per le previsioni, invece, le stime dei tassi a lunga americani e sul rendimento dei Fed Fund si può
far ricorso a quele già disponibili su internet. Per esempio, il sito http://www.forecasts.org/ di the
Financial Forecast CenterTM riporta le due serie di previsioni fino a novembre 2010
rispettivamente in http://www.forecasts.org/10yrT.htm e http://www.forecasts.org/ffund.htm :
Per quanto riguarda il tasso a lunga americano, quello cui fanno normalmente riferimento le
previsioni è il decennale sui titoli di stato americani. Nelle nostre regressioni, però, abbiamo
utilizzato, per omogeneità con i dati europei (Eurirs) quello degli swaps
(http://www.federalreserve.gov/releases/h15/data/Business_day/H15_SWAPS_Y10.txt). Questo,
però, non rappresenta un grave problema dal momento che le variazioni dei rendimenti dei due tassi
sono pressoché sovrapponibili e per passare dal rendimento dei titoli di stato decennali agli swaps
basta togliere dalla serie della previsione dei titoli di Stato l’ultimo valore disponibile della
differenza tra il rendimento dei tioli e quello degli swaps che, nel nostro caso, è praticamente nullo
(3,84 – 3,83 = 0,01) e quindi non richiede alcuna correzione.
10 Year U.S. Treasury Securities Yield Forecast
Constant Maturity Rate Average of Month Percent
Month
Date
Forecast
Value
50%
Correct +/-
80%
Correct +/-
0
1
2
3
4
5
6
7
8
Mar 2010
Apr 2010
May 2010
Jun 2010
Jul 2010
Aug 2010
Sep 2010
Oct 2010
Nov 2010
3.730
3.94
4.12
4.30
4.47
4.57
4.55
4.45
4.31
0.00
0.18
0.23
0.26
0.28
0.31
0.33
0.34
0.36
0.00
0.40
0.51
0.58
0.64
0.69
0.73
0.77
0.80
94
Updated Sunday, April 11, 2010
Fed Funds Interest Rate Forecast
Effective Interest Rate. Percent Average of Month.
Month
Date
0
1
2
3
4
5
6
7
8
Feb 2010
Mar 2010
Apr 2010
May 2010
Jun 2010
Jul 2010
Aug 2010
Sep 2010
Oct 2010
Forecast
Value
0.130
0.18
0.17
0.12
0.13
0.15
0.14
0.19
0.22
50%
Correct +/-
80%
Correct +/-
0.00
0.15
0.19
0.22
0.24
0.26
0.27
0.29
0.30
0.00
0.34
0.42
0.48
0.53
0.57
0.61
0.64
0.67
Updated Monday, March 29, 2010
Queste ultime previsioni sono coerenti con l’affermazione della Fed che il tasso sui Fed fund sarà
mantenuto ancora a lungo all’attuale basso livello.
Altre informazioni si possono avere da altri siti, per esempio bfinance (vedi sotto).
Repo
RY10
Feb. 2010 (effettivo)
1,00
3,10
Maggio 2010
1,00
3,43
Agosto 2010
1,00
3,49
Media delle previsioni; tra parentesi la mediana
Fed Fund
0-0,25
0,17 (0,13)
0,23 (0,25)
UY10
3,64
3,70
3,81
Può essere interessante confrontare le previsioni di RY10 del consensus di bfinance con le nostre,
pur se i valori non sono perfettamente omogenei.
95
Inoltre, mentre i dati sui tassi ufficiali americani i dati di bfinance e Financial Forecast CenterTM
sono simili, per i tassi a lunga le previsioni di consensus di bfinance danno valori minori (maggio:
3,70 vs/ 4,12, agosto: 3,81 vs/ 4,57).
In ogni caso, i dati da aggiungere alle nostre serie potrebbero essere i seguenti
Data
Effettivo
RY10
Eurirs
UY10
Swaps
2010.01
3.440
3.77
2010.02
3.360
3.70
2010.03
3.260
3.83
Previsione
2010.04
2010.05
2010.06
2010.07
2010.08
2010.09
2010.10
2010.11
(FFC = Financial Forecast Center, BF = bfinance)
Titoli di stato USA
REPO
(FFC)
(BF)
3.65
3.61
3.84
3.94
4.12
3.70
4.30
4.47
4.57
3.81
4.55
4.45
4.31
(BF)
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
FED_
FUND
MED
(FFC)
0.125
0.125
0.125
0.18
0.17
0.12
0.13
0.15
0.14
0.19
0.22
Il modo migliore di effettuare le previsioni mediante la nostra equazione è innanzitutto quella di
aggiornare i dati (quelli disponibili da gennaio fino a marzo 2010 [questi appunti sino stati scritti ad
aprire 2010]) e di aggiungere le previsioni ricavate da internet sulle variabili esplicative. Occorre
ricordarsi, però, che per “prudenza”, cioè per essere certi di non cancellare i dati originali, è
opportuno salvare il file con un nuovo nome, oppure definire della nuove variabili uguali alle
vecchie, ma con un nome diverso (per esempio aggiungendo loro una x finale) nelle quali, a partire
da aprile, si aggiungono le previsioni.
Qui, per semplicità, utilizziamo la prima soluzione. Supponiamo quindi di avere salvato il file con
un nome diverso. A questo punto non resta che procedere con l’analisi:
96
Il procedimento con Gretl è il seguente:
Per aggiornate le serie e immettere le previsioni il procedimento è il seguente:
- Selezionare le serie da aggiornare
- Cliccare su Dati, poi Modifica valori per introdurre i nuovi valori (nel caso non ci fosse
spazio, prima occorre spostare in avanti la data finale cliccando su Aggiungi
osservazioni per poi indicare nella finestrella che si apre quante osservazioni si vogliono
aggiungere)
- Aggiungere i dati
97
-
Una volta aperta la finestra di Modifica valori si aggiungono i dati (i nuovi dati vanno
aggiunti uni per volta, non è possibile usare il copia/incolla)
Fatto questo chiudere la finestra cliccando sull’x in alto a destra.
aggiornamenti
previsioni
Fatto questo si può procedere a ristimare l’equazione e ad effettuare le previsioni. Nel caso si voglia
usare il procedimento automatico previsto da GRETL conviene esprimere la dipendente in livelli,
anziché in variazioni. Infatti la generica equazione
Yt = …. + β Yt-1 …..
equivale a
Yt - Yt -1 = …. + β Yt-1 …..
Yt = …. Yt -1 + β Yt-1 …..
Yt = …. + (1 + β) Yt-1 …..
Il coefficiente della ritardata nel caso la dipendente sia espressa nei suoi livelli anziché in variazioni
è (1 + β) anziché β e quato non ha nessuna rilevanza per le previsioni.
Per quanto riguarda le previsioni, conviene quindi partire dalla regressione con RY10 come
variabile dipendente anziché la sua variazione, dato che con GRETL la previsione automatica si
riferisce alla dipendente della regressione e, in effetti, la variabile che ci interessa è RY10 piuttosto
che la sua variazione.
Prima, però, si deve calcolare la variazione del tasso USA che è l’unica variazione dei regressori
che appare nella syima in aggiunta al loro livello ritardato:
RY10 cost RY10(-1) UY10(-1) REPO(-1) FED_FUNDMED(-1) (UY10)
98
Per fare questo prima evidenziare UY10, poi cliccare su Aggiungi
poi su Differenza delle variabili selezionate
(la variazione viene automaticamente denominate d_UY10)
Nel caso il campione non si sia già ampliato automaticamente, occorre procedere a
quest’operazione in modo da includere l’aggiornamento dei dati (fino al marzo 2010). Se si
preferisce si può allargare il campione sino alla fine del 2010, perché, comunque, la regressione è
limitata alle osservazioni per cui esistono tutte le variabili (e dall’aprile 2004 la dipendente non è
più disponibile)
Per far questo cliccare su Campione, poi sistemate la data finale nella finestrella che si apre
poi
99
Ora andare su Modello, OLS-Minimi quadrati ordinari,
E sistemare i ritardi delle indipendenti
100
A questo punto si può dare l’OK.
Quando appare la finestra con la stima della regressione si deve cliccare su Analisi, poi su
Previsione… a dare l’OK.
101
102
A questo punto appaiono le previsioni:
Ed ecco il corrispondente grafico:
103
8. I modelli VAR per le previsioni
Il caso peggiore che possa capitare si ha quando il valore futuro della variabile Y dipende dai valori
futuri di altre variabili di cui però son si possiede nemmeno una stima:
(1)
Yt = F( Xt, Yt-1 , Xt-1 )
da cui:
(1’)
Yt+3 = F( Xt+3, Yt+2 , Xt+2 )
In questo caso uno dei pochi modi per affrontare il problema è mediante un modello VAR.
I modelli VAR (Vector AutoRegression, da non confondere con il VaR !!! [dove la lettera “a” è
minuscola], che è il Value at Risk) rappresentano una possibile soluzione al problema: la loro
ipotesi base è che l’andamento di certe variabili (es. X,Y,Z) dipenda dal loro andamento passato (e
ovviamente la bontà di questa stima dipende dal realismo di questa assunzione). Quest’ipotesi
permette, per via ricorsiva, di stimarne l’andamento futuro anche se non è possibile limitare l’analisi
a una singola equazione (nel caso di un cambiamento strutturale le previsioni diventano ovviamente
scadenti anche se rimangono utili per avere un’idea di come si sarebbero mosse le variabili in
assenza di quel fenomeno destabilizzante)
Si consideri il caso più semplice di due variabili con un solo ritardo e si supponga di essere
interessati a prevedere l’andamento della variabile Y. Per costruire il VAR vanno stimate
contemporaneamente queste due equazioni:
(2a) Yt = F( Yt-1 , Xt-1 )
(2b) Xt = G( Yt-1 , Xt-1 )
Mediante i valori disponibili in t di X e Y è possibile avere le stime al tempo t+1 di queste due
variabili:
(2a)
(2b)
E[Yt+1 ] = F( Yt , Xt )
E[Xt+1 ] = G( Yt , Xt )
da cui:
(2a)
(2b)
E[Yt+2 ] = F(E[Yt+1] , E[Xt+1] )
E[Xt+2 ] = F(E[Yt+1] , E[Xt+1] )
(2a)
(2b)
E[Yt+2 ] = F(E[Yt+2] , E[Xt+2] )
E[Xt+2 ] = F(E[Yt+2] , E[Xt+2] )
etc.
Il procedimento consigliato nel caso di stime VAR è il seguente:
a) Le variabili integrate di ordine 0 vanno immesse nei loro livelli. Le variabili integrate di
ordine 1 che, in base al test di Johansen non sono cointegrate fra loro, vanno immesse
nelle loro variazioni. Le variabili integrate di ordine 1, ma che in base al test di
Johansen risultano cointegrate, vanno messe bei loro livelli.
104
b) Le variabili integrate di ordine 1, ma che non si sa se siano o non siano cointegrate,
vanno messe nei loro livelli (con almeno due ritardi) (adattissimo per i principianti
perché risolve tutti i loro problemi !!!). (la stima può essere un meno precisa e meno
efficiente che con (b) e (c) perché non si sfruttano tutte le informazioni sulle
caratteristiche delle variabili utilizzate). Questo procedimento è noto anche come
UVAR.
Ritornando all’esempio precedente (quello dal tasso a lunga europeo), si supponga ora di essere
interessati alle previsioni del tasso a lunga europeo RY10 ma di non avere a disposizione le
previsioni del REPO, del tasso americano decennale UY10 e del FED_FUNDMED.
Ecco come si può procedere, sapendo che si tratta di variabili non stazionarie.
Utilizzando GRETL le istruzioni per eseguire le
previsioni con un VAR sono le seguenti:
Importare il File: tassi_a_lunga.wf1
Nella Stima dei Var tenere presenti queste regole pratiche:
c) Le variabili integrate di ordine 0 vanno immesse nei loro livelli.
d) Le variabili integrate di ordine 1 che, in base al test di Johansen non sono cointegrate
fra loro, vanno immesse nelle loro variazioni.
e) Le variabili integrate di ordine 1, ma che in base al test di Johansen risultano
cointegrate, vanno messe bei loro livelli, ma in questo caso sarebbe meglio usare non
ma il VAR libero, ma il VECM che è più preciso
f) Le variabili integrate di ordine 1, ma che non si sa se siano o non siano cointegrate (o
qualora non si vogliano sfruttare i risultai della cointegrazione) possono essere messe
nei loro livelli e utilizza il VAR libero. Ovviamente questo metodo è meno efficiente
dei precedenti che utilizzano la conoscenza del grado d’integrazione delle variabili,
ma può essere conveniente per i “dilettanti alle prime armi”.
Usiamo allora quest’ultimo approccio (j) per la nostra previsione sui tassi europei e
americani:
Cominciamo a stabilire il numero ottimo di ritardi del VAR (è uno dei due procedimenti
alternativi già visti per la stima del numero ottimo di ritardi nel caso della regressione OLS dei
tassi a lunga)
-
Cliccare su Modello in alto, poi su Serie storiche , poi su Quick e infine su Scelta
ritardi VAR
105
Quando si apre la finestra del Selezioni ritardi del VAR mettere nella sezione Variabili
endogene solo i livelli delle variabili RY10, UY10, REPO e FED_FUNDMED(-1) senza
ritardi. A questo punto mettere nella finestrella Ordine dei ritardi in numero massimo di ritardi
che vuoi considerare (qui c’è 12, ma 6 o 8 sono più che sufficienti), poi dare l’OK.
A questo punto mettere nella finestrella Ordine dei ritardi in numero massimo di ritardi che
vuoi considerare (qui c’è 12, ma 6 o 8 sono più che sufficienti), poi dare l’OK.
106
Appare una tabella e il numero ottimo di ritardi relativo ai livelli delle variabili corrisponde a
quello con i valori più bassi di ogni colonna. In caso di ambiguità considerare il BIC (Criterio
bayesiano di Schwartz). In questo caso il numero ottimo dei ritardi è 1
Poiché il numero ottimo di ritardi dei livelli è 1, il numero ottimo della variazioni da
includere nella regressione diventa zero. Infatti, per definizione di variazione, le variazioni
fanno sempre riferimento a due livelli adiacenti (il primo meno il secondo) e quindi il numero
ottimo di variazioni da considerare è uguale a quello che emerge dal test sui livelli meno
uno.
A questo punto si riparte daccapo per passare alla stima del VAR:
1) cliccare su Modello (in alto alla finestra); poi cliccare su Serie storiche.
107
2) Quando appare la finestra dopo aver cliccato cliccare su Serie storiche cliccare su , poi
su VAR - Autoregressione vettoriale
A questo punto mettere nello spazio per le variabili endogene i livelli di tutte le nostre variabili
(sono tutte endogene perché le stimiamo noi tutte quante insieme)
In Ordine dei ritardi metti il numero ottimo di ritardi trovato in recedenza (che era 1)
Clicca su “Errori Standard robusti” per avere risultati più precisi
108
3) dai l’OK
Esce la tabella col risultato del VAR che serve per fare le previsioni di tutte le variabili in
automatico
109
4) A questo punto per la previsione occorre cliccare su Analisi (in alto a destra), poi su
Previsioni e infine sulla variabile che interessa (es. Ry10 nel nostro caso)
110
5) Ora indicare il l’intervallo relativo alle previsioni (in pratica conviene lasciare quello
scelto direttamente dal programma). La data iniziale va lasciata inalterata.
6) Dare l’OK
Ecco la previsione. Contemporaneamente alla tabella compare anche un grafico con le previsioni
gli intervalli di confidenza al 95% in verde. I tassi sono previsti in rialzo durante il 2010.
Veri valori
passati
111
Minimo e massimo previsti
al 95% di probabilità
previsione
Attenzione: per le previsioni occorre che il file abbia sufficiente spazio. Quando si caricano i dati
è quindi opportuno (come è stato fatto nei nostri workfile di esempio) immettere uno spazio
maggiore di quello corrispondente ai dati disponibili. Per es. nel nostro caso, i dati disponibili si
fermano al 2009.12, ma il file va fino al 2010.12 dove per il 2010 le variabili contengono spazi
vuoti.
Nel caso non vi fosse abbastanza spazio, comunque, il file può essere ampliato in modo molto
semplice:
Cliccare su Dati (in alto nel file di dati)
112
Poi cliccare su Aggiungi osservazioni, indicare quante osservazioni aggiungere e dare OK.
Fatto questo si può passare alle previsioni.
Fine
113
Scarica