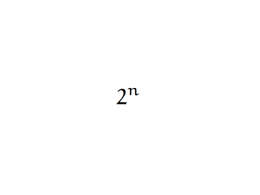Complessità di un algoritmo
La complessità di un algoritmo è una misura del tempo
necessario per eseguire l’algoritmo stesso.
La complessità asintotica è una funzione che esprime la
dipendenza del tempo di esecuzione dalla dimensione
dei dati.
La funzione f(x) è O(g(x)) se e solo se
x0.m.x>x0.f(x) < mg(x).
g(x)
f(x)
x0
Come calcolare la complessità di un algoritmo A
1) individuare la dimensione dei dati n
2) individuare l’operazione principale O eseguita da A, nel senso che
il numero di esecuzioni di tale operazione sia proporzionale al tempo
totale di esecuzione di A
3) determinare una funzione che conti l’ordine di grandezza del
numero di esecuzioni di O in dipendenza dalla dimensione dei dati.
Esempio: trovare il massimo elemento di un array di interi
dimensione dei dati: numero degli elementi dell’array
operazione principale: confronto tra due numeri
numero di confronti effettuato: n-1, in quanto per poter dichiarare che
un elemento è il massimo devo confrontarlo con tutti gli altri elementi
dell’array
Complessità: CA(n) O(n)
Tipo di dato array
in C
Formato generale della dichiarazione di un array:
tipo nome_variabile[dimensione]
(riserva in memoria un numero uguale a “dimensione” di spazi consecutivi per
allocare gli elementi dell’array)
es.
- int v[10] dichiara un array di 10 elementi di tipo intero, denotati
v[0],v[1],…,v[9]. Poiché il tipo base int occupa 16 bit (2 byte), vengono riservati
160 bit
- v genera un puntatore all’inizio dell’array (cioè alla variabile v viene assegnato
come valore l’indirizzo di memoria che contiene l’elemento v[0])
- nessun controllo viene effettuato sul limite dell’array (se indirizzo v[13] non c’è
segnalazione di errore). Il controllo deve essere effettuato dal programmatore.
Puntatori
Una variabile è una locazione di memoria a cui è assegnato un nome.
Un puntatore è una variabile che contiene un indirizzo di memoria.
La dichiarazione int v[3]
genera in memoria la seguente situazione:
Indirizzo:
vv[0]
v[1]
v[2]
contenuto
(valore)
indefinito
indefinito
indefinito
L’istruzione:
for(i=0;i=2;i++) v[i]=i;
modifica la memoria nel modo seguente:
Indirizzo:
contenuto
(valore)
v v[0]
v[1]
0
v[2]
1
2
Le funzioni in C
Dichiarazione di funzione:
tipo_risultato nome_funzione(elenco dei parametri formali)
{
corpo della funzione
}
tipo_risultato: è il tipo del risultato della funzione
void indica che la funzione dà un risultato indefinito;
nome_funzione: identificatore o variabile;
elenco dei parametri formali: per ogni parametro bisogna indicare il tipo e una variabile che
ne definisce il nome.
Es. la funzione che prende in input un intero e ne restituisce il quadrato:
int quadrato(int n){
n=n*n;
return n;
}
Chiamata di funzione
void main(void){
int i; int t=20;
i=quadrato(t);
printf(“%d %d”,i,t);
}
int quadrato(int n){
n=n*n;
return n;
}
(il formato “%d %d” indica che vogliamo
stampare 2 numeri decimali interi con segno)
Simulazione (assolutamente approssimata) dell’esecuzione: il programma (compilato) sia allocato in
posizioni contigue di memoria.
Sia I l’indirizzo a cui viene allocata l’istruzione di assegnazione “i=quadrato(t) “, e K l’indirizzo della
funzione “quadrato”.
programma
void main(void){
int i; int t=20;
I:
i=quadrato(t);
printf(“%d %d”,i,t);
})
K: int quadrato(int n){
n=n*n;
return n;
}
pila di esecuzione (*) (ad ogni chiamata di funzione, sulla cima [qui a destra] della pila viene
memorizzato l’indirizzo di ritorno, i parametri della funzione e l’indirizzo della memoria dove è
allocata la funzione stessa):
- il richiamo della funzione alloca sulla pila l’indirizzo K e il parametro formale t:
[I,t,K]
- l’esecuzione dell’istruzione “return”, oltre ad assegnare all’espressione quadrato(t) il valore 400,
cancella t e K dalla pila, e lascia solo l’indirizzo I. Inoltre dopo l’esecuzione di return si va ad eseguire
l’istruzione il cui indirizzo si trova sulla cima della pila, quindi I. In mancanza di return, la chiusura
dell’ultima parentesi graffa realizza il ritorno.
(*) pila di esecuzione
(la struttura dati pila sarà studiata in seguito, questa breve introduzione serve solo per simulare
l’esecuzione della chiamata di funzione).
Una pila è una sequenza di dati, con una estremità detta cima. Ogni operazione (inserire o estrarre un
dato) è effettuata sulla cima della pila.
Es. pila di numeri interi (la cima viene rappresentata sulla destra della sequenza).
pila vuota
[]
inserisco 1
[1]
inserisco 2
[1,2]
inserisco 3
[1,2,3]
estraggo un elemento e lo assegno alla variabile x
[1,2]
x assume il valore 3
estraggo un elemento e lo assegno alla variabile y
[1]
y assume il valore 2
Iterazione e ricorsione
Definizione iterativa della funzione fattoriale:
fatt(n)=1*2*…*(n-1)*n
(n>0)
Funzione corrispondente in C:
int fatt(int n){
int t,ris=1;
for(t=1;t<=n;t++)ris=ris*t;
return ris;
}
fatt(1)=1
fatt(n+1)=(n+1)*fatt(n)
Definizione ricorsiva della funzione fattoriale:
(n>0)
Funzione corrispondente in C:
int fatt(int n){
int ris;
if(n = 1) return 1;
ris = n*fatt(n-1);
return ris;
}
Esecuzione (manuale)
fatt(n) = 1*2*…*(n-1)*n
(n>0)
voglio calcolare fatt(3):
1) sostituisco 3 a n nella definizione della funzione:
fatt(3) = 1*2*3
(1 sostituzione)
2) eseguo i prodotti: fatt(3)=1*2*3=2*3=6
(2 prodotti)
fatt(1)=1
(n>0)
fatt(n+1)=(n+1)*fatt(n)
voglio calcolare fatt(3):
1) sostituisco 3 a n nella definizione della funzione:
fatt(3) = 3*fatt(2) = 3*2*fatt(1) = 3*2*1
(3 sostituzioni)
2) eseguo i prodotti: fatt(3) = 3*2*1 = 3*2 = 6
(2 prodotti)
N.B. Il computer NON esegue mai sostituzioni! (sono troppo costose in termini di spazio e difficili da
realizzare in quanto possono modificare fortemente la dimensione delle espressioni).
Esecuzione (da parte della macchina)
void main(void){
int i; int t=3;
I: i=fatt(t);
printf(“%d %d”,t,i);
}
K: int fatt(int n){
int ris;
if(n = 1) return 1;
H: ris = n*fatt(n-1);
return ris;
}
Pila di esecuzione
I,3,K
I,3,K,H,2,K
I,3,K,H,2,K,H,1,K
I,3,K,H,2,K,H
I,3,K,H
I,3,K
I
richiamo della funzione fatt con parametro 3;
al punto H, devo calcolare ris= n*fatt(n-1) con n=3 : richiamo di fatt con parametro
2 e indirizzo di ritorno H
... esecuzione di fatt fino all’istruzione H
al punto H, devo calcolare ris= n*fatt(n-1) con n=2 : richiamo di fatt con parametro
1 e indirizzo di ritorno H
esecuzione di if...return: fatt(1)=1 e ritorna all’indirizzo H,
H: ris=2*fatt(1) =2, e esecuzione di return: assegna a fatt(2) il valore 2
e ritorna all’ind. H
H: ris=3*fatt(2) =6, e esecuzione di return: assegna a fatt(3) il valore 6 e ritorna
all’ind. I
a i viene assegnato il valore 6.
Il problema dell’ordinamento degli elementi di un
array
in loco
Dato un array di n elementi, su cui è definita una relazione d’ordine
totale <=
ordinare gli elementi in ordine crescente, usando spazio aggiuntivo
costante (cioè non dipendente da n).
dimensione dei dati: n
complessità: funzione di n, che conta il numero di operazioni di
confronto effettuate
Una analisi più accurata della complessità usa anche una seconda
funzione,
che conta il numero di scambi effettuati.
algoritmo di ordinamento selection-sort
Idea:
Dato l’ array:
v[0],…,v[n-1]
- cercare l’elemento minimo dell’array;
- scambiarlo con l’elemento v[0], a meno che v[0]
stesso non sia già il minimo;
- ordinare l’array v[1],…,v[n-1], dato che
l’elemento v[0] è già nella sua posizione
definitiva.
Richiamo:
- concetto di correttezza di un algoritmo;
- dimostrazione di correttezza;
- tecnica: dimostrazione per induzione.
Dimostrazione di correttezza:
- se n=1, l’array è già ordinato
- se n>1, l’algoritmo sposta nella posizione 0 l’elemento minimo, e
ordina l’array
v[1],…,v[n-1]; per induzione assumiamo che l’array v[1],…,v[n-1]
venga ordinato
correttamente dall’algoritmo; poiché in un array ordinato l’elemento
minimo è
sempre l’elemento iniziale, l’array risultante è correttamente ordinato.
L’idea dell’algoritmo è stata espressa in modo ricorsivo (piu’ facile sia il
disegno che la dimostrazione di correttezza).
Ne vedremo una versione iterativa in C (più efficiente l’esecuzione).
selection sort
in C
void selezione(int v[], int n)
{
int a,b,c,scambio,t,j;
for(a=0; a<n-1;a++){
scambio=0;
c=a;
t=v[a];
for(b=a+1;b<n;b++){
if(v[b]<t){
c=b;
t=v[b];
scambio=1;
}
}
if(scambio){
v[c]=v[a];
v[a]=t;
}
}
}
Complessità di selection sort
void selezione(int v[], int n)
{
int a,b,c,scambio,t,j;
for(a=0; a<n-1;a++){
scambio=0;
questo ciclo e’
c=a;
eseguito n volte
t=v[a];
for(b=a+1;b<n;b++){ questo ciclo
if(v[b]<t){
è eseguito n-1 volte
c=b;
per a=1
t=v[b];
n-2 volte per a=2
scambio=1;
1 volta per a=n-1
} }
if(scambio){
v[c]=v[a];
v[a]=t;
} } }
Per ogni ciclo interno viene fatto un confronto tra due elementi dell’array.
In totale il numero dei confronti è: (n-1)+(n-2)+…+1= n(n+1)/2.
Quindi la complessità è dell’ordine di n2, cioè C selection-sort(n) O(n2).
Complessità di selection sort (numero di scambi)
Caso migliore (array in ingresso già ordinato):
non si effettuano scambi
Caso peggiore (array in ingresso ordinato in ordine inverso:
si effettua 1 scambio per ogni ciclo interno, cioè:
n*(n-1)*(n-2)*…*1=n*(n-1)/2 O(n2)
Caso medio: sempre dell’ordine di n2, come il caso peggiore.
Algoritmo di ordinamento bubblesort
Idea:
- leggere l’array v[0],…,v[n-1], da sinistra a destra, confrontando tra di
loro ogni coppia di elementi contigui, e, se questi non sono in ordine tra
di loro, scambiarli di posto;
- a fine lettura l’elemento massimo si troverà al posto n-1;*
- se non si sono effettuati scambi, l’array è già ordinato, altrimenti
ordinare con lo stesso metodo l’array v[0],…,v[n-2].
*
Infatti ad ogni confronto, qualunque elemento segua il massimo sarà
minore di questo, e quindi verrà scambiato.
Dimostrazione di correttezza:
- se n=1, l’array è già ordinato
- se n>1, l’algoritmo sposta nella posizione n-esima
l’elemento massimo, e ordina l’array v[0],…,v[n-2]; per
induzione assumiamo che l’array v[0],…,v[n-2] venga
ordinato correttamente dall’algoritmo; poiché in un array
ordinato l’elemento massimo è sempre l’elemento finale,
l’array risultante è correttamente ordinato.
bubblesort
in C
void BubbleSort(unsigned int v[],int n){
int i=-1,t,another;
do {
another=0;
for (i=1;i<n;i++){
if ((v[i-1]>v[i])) {
t=v[i-1];
v[b-1]=v[b];
v[b]=t;
another=1;}
n=n-1;
}
} while (another);
}
Complessità di bubblesort
void BubbleSort(unsigned int v[],int n){
int i=-1,t,another;
do {
another=0;
questo ciclo ogni volta confronta
tutte le coppie di
elementi consecutivi, e viene
eseguito n volte alla prima
esecuzione del ciclo esterno, (n-1) alla seconda, e così via
for (i=1;i<n;i++){
if ((v[i-1]>v[i])) {
t=v[i-1];
v[i-1]=v[i];
v[i]=t;
another=1;}
n=n-1;
}
} while (another);
questo ciclo viene eseguito
finchè non vengono più
effettuati scambi.
Caso migliore (gli elementi sono già ordinati): si fa un solo ciclo esterno, senza che siano effettuati scambi, e quindi vengono
fatti (n-1) confronti, quindi Cbubblesort(n)O(n);
Caso peggiore (gli elementi sono ordinati in ordine inverso): ad ogni ciclo interno l’elemento massimo viene posto nella sua
posizione finale, mentre il resto dell’array rimane ordinato in ordine inverso , quindi C bubblesort(n)=n+(n-1)+…+1O(n2);
Caso medio: è dell’ordine di n2, come il caso peggiore.
Complessità di bubblesort (numero di scambi)
Caso migliore (l’array è già ordinato):
non si effettuano scambi;
Caso peggiore (l’array è ordinato in ordine inverso):
si effettua uno scambio ad ogni ciclo, cioe’:
(n-1)+(n-2)+…+1O(n2)
Caso medio:
come il caso peggiore
Algoritmo di ordinamento quicksort
Idea:
- scegliere un elemento dell’array a caso (es. il mediano, cioè quello
nella posizione mediana, cioè con indice p=[(n-1)/2)];
- sia v[p]=x
- ordinare parzialmente tutti gli altri elementi rispetto al mediano, cioè
produrre l’array:
v[0],…,v[h-1], v[h],…,v[n-1].
dove tutti gli elementi in rosso sono minori di x e quelli in azzurro sono
maggiori o uguali di x;
- ripetere lo stesso procedimento sugli array, se hanno lunghezza >1:
v[0],…,v[h-1] e v[h],…,v[n-1].
L’ordinamento parziale può essere effettuato nel modo seguente:
- leggere, con un indice i, l’array da sinistra a destra, e
contemporaneamente, con un indice j da destra a sinistra;
- ad ogni passo, se v[i]>x e v[j]<x, scambiarli tra loro;
- dopo l’ordinamento parziale, l’array risultante sarà:
v[0],…,v[h], v[h+1],…,v[n-1]
dove gli elementi in rosso sono <=x e quelli in verde sono >x.
Infatti (dim. di correttezza), se l’array non fosse parzialmente
ordinato rispetto a x, ci sarebbe o un elemento >x alla sua sinistra
o un elemento <x alla sua destra. Ma questo non è possibile in
quanto tutti gli elementi sono stati confrontati con x.
Dimostrazione di correttezza
Se n=1, l’array è già ordinato.
Altrimenti, per induzione, assumiamo che
v[0],…,v[h-1] e v[h],…,v[n-1].vengano ordinati correttamente
dall’algoritmo. Poiché l’algoritmo di ordinamento parziale è corretto,
l’array
v[0],…,v[h-1], v[h],…,v[n-1].
è correttamente ordinato.
Quicksort in C
void QuickSort(int v[], int n)
{
qs{v,0,n-1);
}
void qs(int *v,int sinistra, int destra)
{
int i,j,x,y;
i=sinistra; j=destra;
x=v[sinistra+destra)/2];
do{ while(v[i]<x && i<destra) i++;
while(x<v[j] && j>sinistra) j--;
if(i<=j){
y=v[i];
v[i]=v[j];
v[j]=y;
i++;j--;
} } while(i<=j);
if(sinistra<j) qs(v,sinistra,j);
if(i<destra) qs(v,i,destra);
}
Complessità di quicksort
Il numero di confronti eseguiti da quicksort è la somma di quelli effettuati durante
l’esecuzione del do..while + quelli effettuati dai due richiami ricorsivi di quicksort sui
due pezzi di array che contengono rispettivamente gli elementi minori-uguali o
maggiori del mediano.
void qs(int *v,int sinistra, int destra){
int i,j,x,y;
i=sinistra; j=destra;
x=v[(sinistra+destra)/2];
do{ while(v[i]<=x && i<destra) i++;
k confronti
while(x<v[j] && j>sinistra) j--;
<=n-K+1 confronti
if(i<=j){ y=v[i];v[i]=v[j];v[j]=y;i++;j--; }
} while(i<=j);
il numero totale di confronti effettuati nel ciclo
do..while è dell’ordine di n, perché tutti
gli elementi sono confrontati col mediano
if(sinistra<j) qs(v,sinistra,j);
dipende dal valore del mediano
if(i<destra) qs(v,i,destra);
dipende dal valore del mediano
}
Complessità di quicksort (continuazione)
Caso migliore: ad ogni passo, il numero degli elementi minori (o uguali) del mediano è
uguale al numero degli elementi maggiori. qs viene richiamata ricorsivamente su due
array ciascuno di lunghezza [n/2].
Cqs(1)=0
Cqs(n)=n+2*Cqs(n/2)
Assumiamo n=2m.
Cqs(n)=n+2*Cqs(n/2)= 2m +2* Cqs(2m-1)= 2m +2*(2m-1+
2* Cqs(2m-2)= 2m +2*(2m-1+2*(2m-2+ Cqs(2m-3)))=
2m +2*(2m-1+2*(2m-2+ ….+2*(22+Cqs(2m-m-1))))=m* 2m=log(n)*n.
(si puo’m provare che tale complessità vale anche per n qualunque,anche non uguale ad
una potenza di 2, cioè Cqs(n) O(n*log(n)).
Complessità di quicksort (caso-migliore-esempio)
Sia v= 1,3,2,4. L’elemento mediano e’ v[1]=3. Dopo la prima esecuzione del ciclo do,
i=2 e j=1, e l’array è 1,2,3,4 (e si sono fatti 4 confronti). Quindi qs viene richiamata sui
due array v[0],v[1]=1,2 e v[2],v[3]=3,4 (in ciascuno 2 confronti). Non si fanno più
richiami ricorsivi. Totale: 4 confronti nella 1^ chiamata + 2 confronti per ciascuna delle
2 chiamate ricorsive = 4+4=8=4*2=4*log(4).
inizio
dopo i while
1 3 2 4
i
dopo il ciclo do
1 3 2 4
j
i
inizio
1 2
j
j
3
4
i
dopo i while
dopo il ciclo do
1 2 - 3 4
1 2 - 3 4
1 2 -3 4
i
i,j
j
i
j
i,j
E non si fanno più richiami ricorsivi.
j
i j
i
Complessità di quicksort (continuazione)
Caso peggiore: ad ogni passo tutti gli elementi (tranne il mediano stesso) sono o
maggiori o minori del mediano. qs viene richiamata ricorsivamente un array di
lunghezza 1 e un array di lunghezza n.
Cqs(1)=0
Cqs(n)=n+ Cqs(0) +Cqs(n-1)= n+Cqs(n-1)= n+(n-1) + Cqs(0)+ Cqs(n-2)= n+(n-1)+(n2)+…+1=n*(n+1)/2O(n2).
Il caso medio è dello stesso ordine del caso migliore.
Complessità di quicksort (caso peggiore-esempio)
Sia v= 4,1,2,3. L’elemento mediano e’ v[1]=1. Dopo la prima esecuzione del ciclo do, i=1 e j=0 e l’array è 1,4,2,3. Quindi qs viene
richiamata sull’array v[1],v[2],v[3]=4,2,3 (e si sono fatti 4 confronti).
Sia v= 4,2,3 . L’elemento mediano e’ v[1]=2. Dopo la prima esecuzione del ciclo do, i=1 e j=0 e l’array è 2,4,3. Quindi qs viene richiamata
sull’array v[1],v[2]=4,3 (e si sono fatti 3 confronti).
Sia v=4,3. L’elemento mediano è v[0]=4. Dopo la prima esecuzione del ciclo do, i=0 e j=1 e l’array è 3,4.
4 confronti nella 1^ chiamata + 3 confronti nella seconda + 2 confronti nella terza = 4+3+2=9=4*(4+1)/2.
inizio
dopo i while
dopo il ciclo do
4 1 2 3
4 1 2 3
1 4 2 3
i
i
j
j
inizio
j
dopo i while
1- 4 2 3
i
j
inizio
dopo il ciclo do
1- 4 2 3
i
1- 2 4 3
j
j
dopo i while
1- 2- 4 3
i
j
i
dopo il ciclo do
1- 2- 4 3
i
i
j
1- 2- 3 4
j
i
Un algoritmo ottimo di ordinamento (ma non in loco): mergesort
Idea:
- dividere l’array dato in metà, cioè in due array v[0],…,v[(n1)/2],v[(n-1)/2+1],…,v[n-1];
- ordinare i due array separatamente;
- unire i due array ordinati in un unico array
t[0],…,t[n-1] (operazione detta merge).
Algoritmo di merge:
- scorrere l’array v[0],…,v[(n-1)/2], con un
indice i e contemporaneamente scorrere
l’array v[(n-1)/2+1],…,v[n-1] con un indice j,
confrontando ad ogni passo v[i] e v[j]; il
minore tra i due elementi sarà inserito in
sequenza in un array t di servizio.
Dimostrazione di correttezza di merge:
- al primo passo, viene inserito in posizione t[0] l’elemento
minimo tra i due puntati dagli indici i e j, cioè il minimo dei due
array v[0],…,v[(n-1)/2] e v[(n-1)/2+1],…,v[n-1];
- all’iesimo passo, assumiamo per induzione che
t[0],…,t[i] contengano i primi i elementi dell’array ordinato
totale. merge allora inserisce il minimo elemento tra quelli puntati
da i e j, cioè il minimo tra tutti gli elementi dell’array dato che
non sono ancora stati inseriti in t. Quindi
t[0],…,t[i],t[i+1]contiene ora i primi i+1 elementi dell’array dato.
Quindi quando i=n-1, l’array t contiene gli elementi di v ordinati.
Dimostrazione di correttezza di mergesort
- se l’array ha un solo elemento allora è già ordinato, altrimenti
assumiamo, per ipotesi induttiva, che mergesort ordini
correttamente i due array:
v[0],…,v[(n-1)/2] e v[(n-1)/2+1],…,v[n-1]
Poiché abbiamo dimostrato che l’algoritmo merge è corretto,
allora il risultato finale, cioè merge applicato ai due sotto array
ordinati, genera l’array ordinato voluto.
mergesort
in C
void merge(int a,int m,int b, int v[]){
int t[n];
int i=a,j=m+1,k=0;
while (i<=m)
if (j<=b && v[j]<v[i]){t[k]=v[j];j=j++;}
else {t[k]=v[i];i=i++}
for (i=0;i<k;i++) v[a+i]=t[i];
}
void ms(int a, int b, int v[]){
int m;
if (a>=b) return;
m=(a+b)/2;
ms(a,m,v);
ms(m+1,b,v);
merge(a,m,b,v);
}
void mergesort(int v[],int n){
ms(0,n-1,v);
}
Complessità di mergesort
Cmergesort(n)= Cms(n)= 2* Cms(n)= =
Cms(1)=0
Cms(n)= Cmerge(n)+2*Cms([´n-1)/2])= n-1+ Cms([(n-1)/2])
Assumiamo n-1=2m.
Cmst(1)=0
Cms(n)=(n-1)+2*Cms((n-1)/2)= 2m +2* Cms(2m-1)= 2m +2*(2m-1+
2* Cms(2m-2)= 2m +2*(2m-1+2*(2m-2+ Cms(2m-3)))=
2m +2*(2m-1+2*(2m-2+ ….+2*(22+Cms(2m-m-1))))=m* 2m=log(n)*(n-1).
(si puo’m provare che tale complessità vale anche per n qualunque, cioè Cms(n)
O(n*log(n)).
Un problema intrattabile: il gioco della torre di hanoi
Dati 3 sostegni, S(orgente), A(iuto) e D(estinazione), e n dischi di misure diverse
infilati sul sostegno S, in modo che ogni disco sia appoggiato su uno più grande,
trasferire tutti i sostegni da S a D, usando A come base di appoggio, mantenendo
invariata la proprietà che ogni disco sia appoggiato su uno più grande.
Algoritmo (ricorsivo):
- se n=1, sposta l’unico disco da S a D;
- se n>1, sposta da S a A la pila di n-1 dischi,
sposta da S a D il disco rimanente (che è il più grande),
sposta da A a D la pila di n-1 dischi.
correttezza
Se n=1, l’algoritmo è ovviamente corretto.
Altrimenti, per ipotesi induttiva assumiamo che lo spostamento da S ad A dei primi
n-1 dischi avvenga rispettando il vincolo dell’ordinamento. Ovviamente lo
spostamento del disco maggiore da S a D rispetta il vincolo. Ancora per ipotesi
induttiva assumiamo che lo spostamento da A a D degli n-1 dischi avvenga
rispettando il vincolo dell’ordinamento. Il risultato è quello voluto e tutti i dischi
ora si trovano su D, con il vincolo rispettato.
complessità
- se n=1, sposta l’unico disco da S a D;
- se n>1, sposta da S a A la pila di n-1 dischi,
sposta da S a D il disco rimanente (che è il più grande),
sposta da A a D la pila di n-1 dischi.
C(1)=1
C(n)=C(n-1)+1+C(n-1)=1+2* C(n-1)=1+2*(1+2*C(n-2))=
1+2*(1+2*(1+2*C(n-3)))=1+(2*(1+2*(1+2*(…….(1+2*C(1))…))))=
1+21+ 22+…+ 2n-1= 2n
Scaricare

![A[1]](http://s2.diazilla.com/store/data/000060822_1-5911e2a71daeb1fb5dd4e6960c2bdc02-260x520.png)