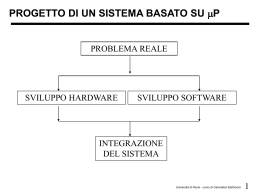
Control Loop (addendum 1 alla slide n. 45)
C code:
MIPS code:
L1:
add $t1,
add $t1,
add $t1,
lw $t0,
add $s1,
add $s3,
bne $s3,
$s3, $s3
$t1, $t1
$t1, $s5
0($t1)
$s1, $t0
$s3, $s4
$s2, L1
L1:
g = g + A[i];
i = i + j;
if (i != h) goto L1;
#
#
#
#
#
#
#
=
=
=
=
g
i
a
$t1
$t1
$t1
$t0
g =
i =
vai
2 * i
4 * i
indirizzo di A[i]
A[i]
+ A[i]
+ j
L1 se i h
Attribuzione dei registri alle variabili:
g = $s1, h = $s2, i = $s3, j = $s4, indirizzo di inizio del vettore A = $s5
Università di Pavia - corso di Calcolatori Elettronici
1
Ciclo While (addendum 2 alla slide n. 45)
C code:
MIPS code:
Loop: add $t1,
add $t1,
add $t1,
lw $t0,
bne $t0,
add $s3,
j Loop
Exit:
while (save [i] == k)
i = i + j;
$s3, $s3
$t1, $t1
$t1, $s6
0($t1)
$s5, Exit
$s3, $s4
#
#
#
#
#
#
#
$t1
$t1
$t1
$t0
vai
i =
vai
=
=
=
=
a
i
a
2 * i
4 * i
indirizzo di save[i]
save[i]
Exit se save[i] k
+ j
Loop
Attribuzione dei registri alle variabili:
i = $s3, j = $s4, k = $s5, indirizzo di inizio del vettore save = $s6
Università di Pavia - corso di Calcolatori Elettronici
2
Case/Switch (addendum alla slide n. 47)
Switch (k)
case 0:
case 1:
case 2:
case 3:
f=i+j;
f=g+h;
f=g-h;
f=i-j;
break;
break;
break;
break;
L0:
L1:
L2:
L3:
Exit:
slt $t3, $s5, $zero # k <0?
bne $t3, $zero, Exit
slt $t3, $s5, $t2 # k >3?
beq $t3, $zero, Exit
add $t1, $s5, $s5
add $t1, $t1, $t1 # $t1=4*k
add $t1, $t1, $t4
lw $t0, 0($t1)
jr $t0 #vai a indir. letto
add $s0, $s3, $s4 #k=0, f=i+j
j Exit
add $s0, $s1, $s2 #k=1, f=g+h
j Exit
sub $s0, $s1, $s2 #k=2, f=g-h
j Exit
sub $s0, $s3, $s4 #k=3, f=i-j
f = $s0, g = $s1, h = $s2, i = $s3, j = $s4, k = $s5; $t2 = 4 ;$t4 =indirizzo tabella etichette
Università di Pavia - corso di Calcolatori Elettronici
3
Uso dello stack (addendum 1 alla slide n. 48)
int proc (int g, int h, int i, int j)
{ int f;
f=(g+h)-(i+j);
proc: addi $sp, $sp, -12 # 3 push
return f;
sw $t1, 8($sp)
}
sw $t0, 4($sp)
g, h, i, j = $a0…$a3
sw $s0, 0($sp)
f = $s0
add $t0, $a0, $a1 # calc. f
add $t1, $a2, $a3
sub $s0, $t0, $t1
add $v0, $s0, $zero # $v0=f
lw $s0, 0($sp) # 3 pop
Per convenzione:
lw $t0, 4($sp)
$t0-$t9 temporanei da non salvare
lw $t1, 8($sp)
$s0-$s7 da conservare
addi $sp, $sp, 12
jr $ra # ritorno
si potevano risparmiare 2 push/pop
Università di Pavia - corso di Calcolatori Elettronici
4
Procedure annidate (addendum 2 alla slide n. 48)
int fatt (int n)
fatt:
{
if (n<1) return(1);
else return(n*fatt(n-1));
}
n = $a0
L1:
addi $sp, $sp, -8
sw $ra, 4($sp)
sw $a0, 0($sp)
slti $t0, $a0, 1
beq $t0, $zero, L1
addi $v0, $zero, 1
addi $sp, $sp, 8
jr $ra
addi $a0, $a0, -1
jal fatt
lw $a0, 0($sp) # ind. = L1+8
lw $ra, 4($sp)
addi $sp, $sp, 8
mul $v0, $a0, $v0
jr $ra
Università di Pavia - corso di Calcolatori Elettronici
5
Procedure annidate (addendum 3 alla slide n. 48)
Gestione dello stack:
Al 1° richiamo salva nello stack:
1) l’indirizzo di ritorno che è nella zona del chiamante
(nome attribuito JALM + 4);
2) il valore di $a0 = n.
Al 2° richiamo salva nello stack:
1) l’indirizzo della procedura fatt (indicato da L1+8);
2) il valore di $a0 = n-1.
Al 3° richiamo salva nello stack L1+8 e $a0 = n-2.
. . . . .
Al n-mo richiamo salva nello stack L1+8 e $a0 = 0.
Università di Pavia - corso di Calcolatori Elettronici
6
Procedure annidate (addendum 4 alla slide n. 48)
Esempi di esecuzione al variare di n:
n = 0
$ra = JALM+4
$a0 = n = 0
n = 1
$ra = JALM+4
$a0 = n = 1
$ra = L1+8
$a0 = n-1 = 0
1^ esecuzione
2^ esecuzione
Alla 1^ iterazione:
salta a L1; a0 = 0;
ra=L1+8.
Alla 2^ iterazione:
non salta a L1; v0=1 e
ritorna a L1+8, dove
a0=1; ra=JALM+4; v0*1=v0
e ritorna al main.
Università di Pavia - corso di Calcolatori Elettronici
7
Procedure annidate (addendum 5 alla slide n. 48)
Esempi di esecuzione al variare di n:
n = 2
$ra = JALM+4
$a0 = n = 2
$ra = L1+8
1^ esecuzione
2^ esecuzione
$a0 = n-1 = 1
$ra = L1+8
$a0 = n-2 = 0
3^ esecuzione
Alla 1^ iterazione:
salta a L1; a0 diventa 1;
ra=L1+8.
Alla 2^ iterazione:
salta a L1; a0 diventa 0;
ra=L1+8.
Alla 3^ iterazione:
non salta a L1, quindi v0=1
e torna a L1+8, a0=1;
ra=L1+8; v0*1=v0; torna a
L1+8, a0=2, ra=JALM+4,
v0=1*a0=2 e torna al main
program.
Università di Pavia - corso di Calcolatori Elettronici
8
Procedure annidate (addendum 6 alla slide n. 48)
fatt.
Salva indirizzo di
ritorno e valore a0
nello stack
sì
a0<1
v0=1
Richiamo fatt
no
dec a0
Preleva a0
Ultima iterazione
Ritorno
Ritorno all’ultima
chiamata
effettuata (2 casi:
n-1 volte si ritorna
alla routine fatt.
all’indirizzo L1+8
e si preleva a0
dallo stack, solo
l’ultima si torna al
main (JALM+4))
e si aggiorna SP
Iter. intermedie
Fatto con il
ritorno alla
routine fatt che
aveva chiamato
v0=a0*v0
Università di Pavia - corso di Calcolatori Elettronici
9
Fattoriale senza ricorsione (addendum 7 a n. 48)
n nello stack
FATT=1
no
sì
a0<2
FATT=FATT*a0
n dallo stack
a0=a0-1
ritorno
Università di Pavia - corso di Calcolatori Elettronici
10
Fattoriale senza ricorsione (addendum 8 a n. 48)
n = $a0
fatt:
Ciclo:
L1:
addi $sp, $sp, -4
sw $a0, 0($sp)
addi $v0, $zero, 1
slti $t0, $a0, 2
beq $t0, $zero, L1
lw $a0, 0($sp)
addi $sp, $sp, 4
jr $ra
mul $v0, $a0, $v0
addi $a0, $a0, -1
j Ciclo
#
#
#
#
#
#
#
agg.$SP per salvat. n
salvataggio n
$v0 = fattoriale =1
test per $a0 < 2
salta se $a0 >= 2
ripristino n
aggiornamento $SP
# fatt = fatt * $a0
# $a0 = $a0 -1
Università di Pavia - corso di Calcolatori Elettronici
11
Gestione caratteri (addendum 9 alla slide n. 48)
void strcpy (char
{
int i;
i = 0;
while ((x[i] =
i = i
}
strcpy:
addi
sw
add
L1:
add
lb
add
sb
addi
bne
lw
addi
jr
Indirizzo stringa
x[], char y[])
y[i]) != 0) /* copia e test byte */
+ 1;
$sp, $sp, -4
$s0, 0($sp)
#
$s0, $zero, $zero
#
$t1, $a1, $s0
#
$t2, 0($t1)
#
$t3, $a0, $s0
#
$t2, 0($t3)
#
$s0, $s0, 1
#
$t2, $zero, L1
#
$s0, 0($sp)
#
$sp, $sp, 4
$ra
#
x = $a0; ind. y = $a1;
salva $s0 nello stack
i = 0
ind. y[i] in $t1
$t2 = y[i]
ind. x[i] in $t3
x[i] = y[i]
i = i + 1
se y[i] 0 vai a L1
ripristina $s0 dallo stack
ritorno
i = $s0
Università di Pavia - corso di Calcolatori Elettronici
12
Pseudo Istruzioni (addendum 1 alla slide n. 57)
•
Versioni modificate delle istruzioni vere, trattate dall’assemblatore
•
Esempi:
Pseudo istruzione:
Istruzione vera:
Pseudo istruzione:
Istruzioni vere:
•
move
add
$t0, $t1 # $t0 = $t1
$t0, $zero, $t1
blt
slt
bne
$s1, $s2, Label
$at, $s1, $s2
$at, $zero, Label
Altri esempi:
bgt, bge, ble; branch condizionati a locazioni distanti trasformati
in un branch e una jump, li, etc.
Università di Pavia - corso di Calcolatori Elettronici
13
Vettori e puntatori (addendum 2 alla slide n. 57)
azz1 (int vett[], int dim)
{
int i;
for (i=0; i<dim; i++)
vett[i] = 0;
}
azz1: move
$t0, $zero
L1:
add
$t1, $t0, $t0
add
$t1, $t1, $t1
add
$t2, $a0, $t1
sw
$zero, 0($t2)
addi
$t0, $t0, 1
slt
$t3, $t0, $a1
bne
$t3, $zero, L1
jr
$ra
# i = 0
# 4 * i
#
#
#
#
#
$t2 = indirizzo di vett[i]
vett[i] = 0
i = i + 1
i < dim ?
se i < dim vai a L1
Indirizzo vett = $a0, dim = $a1, i = $t0
Università di Pavia - corso di Calcolatori Elettronici
14
Vettori e puntatori (addendum 3 alla slide n. 57)
azz2 (int *vett, int dim)
{
// *p è l’oggetto puntato da p
int *p;
// &vett è l’indirizzo di vett
for (p=&vett[0]; p<&vett[dim]; p++)
*p = 0;
}
azz2: move
$t0, $a0
# p = indir vett[0]
add
$t1, $a1, $a1
# 4 * dim
add
$t1, $t1, $t1
add
$t2, $a0, $t1
# $t2 = indir di vett[dim]
L2:
sw
$zero, 0($t0)
# mem puntata da p = 0
addi
$t0, $t0, 4
# p = p + 4
slt
$t3, $t0, $t2
# p < &vett[dim] ?
bne
$t3, $zero, L2
# se è vero vai a L2
jr
$ra
Indirizzo vett = $a0, dim = $a1, p = $t0
Università di Pavia - corso di Calcolatori Elettronici
15
Operazioni logiche (addendum 1 alla slide n. 71)
•
Shifts:
shift left logical 8 bit 00000000D 000000D00
shift right logical 4 bit 000000D00 0000000D0
•
sll $t2, $s0, 8
srl $t2, $s0, 4
Formato R per l’istruzione sll $t2, $s0, 8 :
000000
00000
op
rs
10000
rt
01010
rd
01000
000000
shamt
funct
•
AND bit a bit
$t1=00003C00
AND $t0, $t1, $t2
$t2=00000D00
$t0=00000C00
•
OR bit a bit
OR $t0, $t1, $t2
$t0=00003D00
Università di Pavia - corso di Calcolatori Elettronici
16
CLA: propaga e genera (addendum 1 alla slide n. 84)
c1 = b0c0 + a0c0 + a0b0; c1 = a0b0 + (a0 + b0)c0
c2 = b1c1 + a1c1 + a1b1; c2 = a1b1 + (a1 + b1)c1 =
= a1b1 + (a1 + b1) (a0b0 + (a0 + b0)c0)
c3 = b2c2 + a2c2 + a2b2; c3 = a2b2 + (a2 + b2)c2 =
= a2b2 + (a2 + b2)c2 = a2b2 + (a2 + b2) (a1b1 + (a1 + b1)
(a0b0 + (a0 + b0)c0))
c1 = g0 +
c 2 = g1 +
c 3 = g2 +
= g2 +
c 4 = g3 +
p0c0
p1c1; c2 = g1
p2c2; c3 = g2
p2g1 + p2p1g0
p3c3; c4 = g3
+
+
+
+
p1 (g0 + p0c0) = g1 + p1g0 + p1p0c0
p2(g1 + p1g0 + p1p0c0) =
p2p1p0c0
p3g2 + p3p2g1 + p3p2p1g0 + p3p2p1p0c0
Università di Pavia - corso di Calcolatori Elettronici
17
CLA a 4 bit (addendum 2 alla slide n. 84)
Realizziamo un “super” sommatore a 4 bit (CLA a 4
bit).
I “super” segnali “propaga” Pi sono dati da:
P0 = p3 p2 p1 p0;
P1 = p7 p6 p5 p4
P2 = p11 p10 p9 p8; P3 = p15 p14 p13 p12
I “super” segnali “genera” Gi sono dati da:
G0 = g3 + p3g2 + p3p2g1 + p3p2p1g0
G1 = g7 + p7g6 + p7p6g5 + p7p6p5g4
G2 = g11 + p11g10 + p11p10g9 + p11p10p9g8
G3 = g15 + p15g14 + p15p14g13 + p15p14p13g12
Università di Pavia - corso di Calcolatori Elettronici
18
CLA a 4 bit (addendum 3 alla slide n. 84)
I riporti in ingresso ai 4 CLA del sommatore a 16
bit sono simili ai riporti in uscita da ciascun
bit del sommatore a 4 bit c1, c2, c3, c4
C1
C2
C3
C4
=
=
=
=
G0
G1
G2
G3
+
+
+
+
P0c0
P1G0 + P1P0c0
P2G1 + P2P1G0 + P2P1P0c0
P3G2 + P3P2G1 + P3P2P1G0 + P3P2P1P0c0
Università di Pavia - corso di Calcolatori Elettronici
19
Velocità RCA e CLA a 16 bit (addendum 1 alla slide n. 85)
Hp. D = tempo di risposta di AND e OR
Sia Ttot = # porte del cammino più lungo * D
RCA
Ttot = 16 * 2 D = 32 D
CLA
Ttot = tempo per produrre C4
2 D per produrre C4 a partire da Gi, Pi e c0;
2 D per Gi a partire da gi e pi, 1 D per Pi da pi;
1 D per gi e pi a partire da ai e bi
Ttot = 5 D
Per 16 bit CLA è 6 volte più veloce di RCA
Università di Pavia - corso di Calcolatori Elettronici
20
Registri e istruzioni in virgola mobile del MIPS
(addendum 1 alla slide n. 91)
Registri
Commento
$f0, $f1, $f2, … $f31
In doppia precisione un
registro corrisponde ad una
coppia pari e dispari,
identificato dal nome del
registro pari
ISTRUZIONI ARITMETICHE
Singola precisione
Doppia precisione
add.s $f1, $f2, $f3
add.d $f0, $f2, $f4
sub.s $f1, $f2, $f3
sub.d $f0, $f2, $f4
mul.s $f1, $f2, $f3
mul.d $f0, $f2, $f4
div.s
div.d
$f1, $f2, $f3
$f0, $f2, $f4
Università di Pavia - corso di Calcolatori Elettronici
21
Istruzioni in virgola mobile del MIPS (addendum 2 alla
slide n. 91)
ISTRUZIONI DI TRASFERIMENTO DATI
lwc1 $f1, 100 ($s2)
swc1 $f1, 100 ($s2)
ISTRUZIONI COMPARE
(x = eq, ne, lt, le, gt, ge)
c.x.s $f1, $f4
c.x.d $f2, $f4
ISTRUZIONI DI SALTO
bc1t 25
Branch on FP true
bc1f 25
Branch on FP false
Università di Pavia - corso di Calcolatori Elettronici
22
Numeri in virgola mobile secondo lo standard IEEE 754
(addendum 1 alla slide n. 92)
Singola Precisione
Doppia Precision
e
Oggetto
rappres.
Exp.
Mantissa
Exp.
Mantissa
0
0
0
0
0
0
#0
0
#0
Subnumber
1254
#
12046
#
#normaliz
zato
255
0
2047
0
+/-
255
#0
2047
#0
NaN (Not
a Number)
Università di Pavia - corso di Calcolatori Elettronici
23
Scaricare