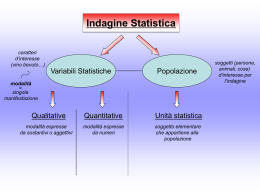
Trattamento delle Osservazioni Gli errori di misura Y A X B Enrico Borgogno Mondino [email protected] Tel. Uff. 011-6705523 Quali problemi si pongono 1) Misure ripetute della stessa grandezza NON coincidono (es. Se ripeto la misura di un angolo otterrò sempre misure leggermente diverse) esiste UNA misura VERA non conoscibile ed infinite STIME della MISURA VERA. Y Y Le misure sono affette da errori: A X B 1) Grossolani (A e B nel disegno) operatore 2) Sistematici strumento 3) Accidentali natura aleatoria del processo di misura Quale misura è quella vera?? Non si può dire. Ciò che si può dire è quale sia la miglior stima della misura vera. X Posso qualificare la mia misura definendone il valore e la precisione che la caratterizza? Quali problemi si pongono 2) Le misure reali non rispettano i criteri geometrici (es. La somma degli angoli interni di un triangolo non è 180° ) misure che devono rispettare vincoli geometrici si dicono MISURE DIRETTE CONDIZIONATE C b A v a B c Come faccio a recuperare la coerenza geometrica delle osservazioni?? La STATISTICA come possibile soluzione dei problemi Gli errori GROSSOLANI sono evidenti e possono essere facilmente rimossi sono, in genere, errori dell’operatore (di distrazione) Gli errori SISTEMATICI possono essere rimossi o minimizzati utilizzando accorgimenti procedurali in fase di misura (regola di BESSEL per es.) sono in genere errori connessi alle modalità operative degli strumenti utilizzati (srettifiche) Gli errori ACCIDENTALI non sono rimovibili possono essere minimizzati e gestiti. Lo strumento deputato a tale scopo è la STATISTICA. L’approccio statistico consente di : A) STIMARE il valore della MISURA B) STIMARE il valore della precisione della MISURA C) MINIMIZZARE e REDISTRIBUIRE gli errori rispettando i vincoli geometrici (compensazione) Che tipi di misure esistono? c a b 2 B=b C=c A=a 2 a c sin sin MISURE DIRETTE restituite dallo strumento (misuro con distanziometro a e b) MISURE INDIRETTE se derivate mediante formule a partire da misure dirette (ricavo c) MISURE DIRETTE CONDIZIONATE se devono soddisfare vincoli geometrici MISURE INDIRETTE CON ESUBERANZA DI OSSERVAZIONI ho più misure di quante ne servono, che danno luogo a più equazioni per la derivazione della stessa grandezza indiretta risolvendole separatamente senza precauzioni il valore che ottengo per la grandezza indiretta è diverso. VARIABILE STATISTICA TERMINOLOGIA: - POPOLAZIONE: è un insieme FINITO di individui ognuno dei quali è caratterizzato da un attributo X che può assumere valori diversi DISCRETI. - INDIVIDUI: sono i soggetti dell’indagine statistica (es. persone umane) - ATTRIBUTO: è una caratteristica discreta degli individui che viene analizzata statisticamente (colore capelli, colore degli occhi …) - VALORE ARGOMENTALE: è la misura dell’attributo X1 X I 2 ... X M X 1 x1 x2 ... xN La variabile statistica indica come i valori argomentali si distribuiscano fra gli individui di una popolazione reale VARIABILE STATISTICA x1 X 1 F1 f 1 x2 ... xN F2 ... FN f 2 ... f N N con N F N, f i 1 i i 1 i 1 Intervallo argomentale [ Dx = xi+1-xi ] Frequenza assoluta [ Fi ] : numero di individui con valore argomentale xi Fi N aventi valore argomentale xi Frequenza relativa fi : percentuale di individui sul totale (N) VARIABILE STATISTICA Una variabile statistica può essere rappresentata graficamente da un ISTOGRAMMA DI FREQUENZA (ASSOLUTA o RELATIVA): A TORTA 30 184-189 19% A BARRE 164-168 6% 25 179-183 26% 20 15 169-173 27% 10 5 174-178 22% 0 164-168 169-173 174-178 179-183 184-189 L’area dei rettangoli (o dei settori) definisce il numero di individui ricadenti in ciascuna CLASSE (può includere anche più valori incrementali) VARIABILE STATISTICA Si definisce FUNZIONE CUMULATIVA DI FREQUENZA (relativa o cumulata) O FUNZIONE DI DISTRIBUZIONE della variabile statistica C la seguente doppia successione x1 F C g1 1 N G F 1 1 x2 F F2 g2 1 N G2 F1 F2 ... xn F F2 ... Fn ... g n 1 N F F2 ... Fn ... G1 1 N 100 90 80 70 60 50 40 30 DIAGRAMMA CUMULATIVO DI FREQUENZA (ASSOLUTA o RELATIVA) 20 10 0 164-168 169-173 174-178 179-183 184-189 VARIABILE STATISTICA MODA: è quel valore argomentale per cui è massima la frequenza; MEDIANA: è quel valore argomentale che divide l’istogramma in due aree uguali MOMENTI Si definisce momento k-esimo rispetto al polo q (tipicamente 0) di una variabile statistica a una dimensione la seguente espressione: n mk ,q xi q f i k i 1 I momenti più significativi che descrivono una variabile statistica sono i seguenti: n m1, 0 xi f i i 1 Momento di I grado MEDIA n m2, 0 xi2 f i i 1 Momento di II grado VALORE QUADRATICO MEDIO VARIABILE STATISTICA Ad ogni variabile statistica ne è associabile una nuova detta variabile statistica SCARTO (vi) così definita: vi = xi - m1,0 la nuova variabile scarto V avrà lo stesso istogramma della variabile C ma l’origine delle ascisse coinciderà con il valore della media m1,0 (media nulla). Il momento di secondo grado della variabile scarto è detto varianza [ 2 ]: La radice quadrata della varianza viene detta SCARTO QUADRATICO MEDIO (s.q.m.) o DEVIAZIONE STANDARD m2,m xi m1,0 f i vi f i n 2 x i 1 2 2 n i 1 2 VARIABILE STATISTICA ATTENZIONE!! La media M è quel valore argomentale che rende minima la varianza 2. La media M ha il significato effettivo di “valore centrale”, di indice di posizione dei valori argomentali. La varianza 2 è invece un indice di “dispersione” e risulta tanto maggiore quanto più elevati sono gli scarti. Pertanto tale indice rispecchia la distribuzione dei valori argomentali. DALLA VARIABILE STATISTICA ALLA MISURA L’operazione di misura costituisce un’ESTRAZIONE CASUALE di valori argomentali da una popolazione IGNOTA. L’ESTRAZIONE CASUALE è un evento ALEATORIO (o STOCASTICO) cioè per il quale non è possibile prevedere l’esito. L’ESTRAZIONE è CASUALE solo se gli individui della popolazione sono identici (non riconoscibili) UN’ESTRAZIONE CASUALE da una popolazione costituisce un CAMPIONAMENTO e definisce una VARIABILE STATISTICA CAMPIONE (numero finito di individui) x X 1 1' F 1 x2 ... xN F ' 2 ... F ' N E’ possibile dal CAMPIONE dedurre informazioni circa la popolazione dalla quale è stato estratto? è possibile da poche misure ripetute dedurre (STIMARE) la vera misura? DALLA VARIABILE STATISTICA ALLA MISURA Legge EMPIRICA del CASO Quando si effettua un numero N (grande a piacere) di estrazioni da una popolazione e ogni volta si rimette l’individuo estratto nella popolazione, si constata che: A) tutti i valori argomentali della popolazione sono stati estratti; B) le frequenze relative della variabile statistica tendono a stabilizzarsi cioè: F’i (del campione) Fi (della popolazione “possibile”) Nel caso di fenomeni aleatori non è mai prevedibile la modalità di uscita di un singolo evento, mentre si può quasi sempre ottenere una buona previsione di come si distribuiranno i risultati di un grande numero di estrazioni. Si può affermare che un fenomeno aleatorio sarà conosciuto quando sarà nota la sua distribuzione. DALLA VARIABILE STATISTICA ALLA MISURA Legge EMPIRICA del CASO La distribuzione “POSSIBILE” (non reale ma potenziale) che definisce un fenomeno aleatorio viene chiamata VARIABILE CASUALE. La distribuzione è POSSIBILE perché ne si immagina l’esistenza attraverso la sperimentazione di successive estrazioni di variabili statistiche campione. La VARIABILE CASUALE gode di tutte le proprietà della VARIABILE STATISTICA ma le frequenze associate ai valori argomentali definiscono la PROBABILITA’ con la quale quel VALORE INCREMENTALE può essere estratto. X1 X 2 X 3 X n X p1 p2 p3 pn n p i 1 i 1 La probabilità, legata alla variabile casuale, è un concetto aprioristico assiomatico (PREVISIONALE), mentre la frequenza, legata alla variabile statistica, è un indice che misura a posteriori i risultati di una indagine statistica (DESCRITTIVO). LA MISURA DIRETTA DI UNA GRANDEZZA é UN EVENTO ALEATORIO !!! La ripetizione delle osservazioni di una stessa grandezza definisce una VARIABILE STATISTICA CAMPIONE attraverso la quale si vuole avere informazioni circa la POPOLAZIONE che rappresenta. LA POPOLAZIONE cui il processo di misura fa riferimento definisce una VARIABILE CASUALE (distribuzione) CONTINUA pertanto le definizioni del caso discreto assumono forma differenziale e integrale (vedere seguito). Riassumendo A) variabile statistica: solo discreta – costruita a posteriori da una popolazione reale; B) variabile casuale: discreta o continua – costruibile a priori da una popolazione possibile. VARIABILE CASUALE CONTINUA CASO DISCRETO i F ( xi ) p( x xi ) p j i 1,2,..., n CASO CONTINUO F ( x) p( x x0 ) j 1 p(x = xi) = pi x0 f ( x)dx A dp = f(x)dx b P(a x b) F (b) F (a) f ( x)dx a B f ( x)dx 1 A - La funzione y = f(x) è nota come densità di probabilità di X o funzione di frequenza. - La funzione g = F(x) è nota come Funzione di Distribuzione (analogo della Frequenza cumulata) VARIABILE CASUALE CONTINUA Momenti La funzione y = f(x) densità di probabilità di X o funzione di frequenza definita per il caso dell’evento aleatorio della MISURA si dimostra essere quella GAUSSIANA. L’operazione di MISURA DIRETTA ripetuta è un campionamento dalla popolazione la cui distribuzione (VARIABILE CASUALE) è quella GAUSSIANA (O NORMALE). Si tratta di un modello matematico avente la seguente formulazione x m 2 f x 1 2 2 e 2 2 MISURA DIRETTA DI UNA GRANDEZZA Eseguire una misura diretta di una grandezza significa confrontarla con l’unità campione esprimendola come suoi multipli e sottomultipli. f x 1 2 2 e x m 2 2 2 Misurare direttamente un grandezza vuol dire campionare (cerchi rossi) una popolazione GAUSSIANA di MEDIA E DEVIAZIONE STANDARD da determinare sulla base del campione estratto. N.B. A) E’ possibile operare campionamenti (gruppi di misure ripetute) diversi. B) Benchè si riferiscano alla stessa popolazione ciascun campionamento definirà una VARIABILE STATISTICA CAMPIONE diversa dall’altra Media e S.q.m diversi MISURA DIRETTA DI UNA GRANDEZZA Quali valori di M e utilizzo per descrivere la popolazione POSSIBILE?? Devo STIMARE quei particolari valori di M e che risultano i più idonei secondo il criterio della MASSIMA VEROSIMIGLIANZA Tale criterio stabilisce di definire M e in modo tale che sia massimizzata la PROBABILITÀ COMPOSTA di estrarre proprio le osservazioni compiute in fase di campionamento. Tale probabilità vale: P x1 , x2 , xn / m, 2 f x1 f x2 f xn 1 2 P(x) risulta massimizzata se risulta minimo l’esponente di e : 2 n/2 n 1 2 e 2 n xi m 2 1 2 2 i 1 x m i 1 2 i min Se la f(x) è una distribuzione GAUSSIANA, il principio di MASSIMA VEROSIMIGLIANZA conduce al principio dei MINIMI QUADRATI e la diretta applicazione di questo principio porta alla determinazione della stima più plausibile del parametro media n 2 x m min i i 1 PROPRIETA’ degli STIMATORI Si definiscono stimatori degli operatori matematici in grado di restituire le migliori stime dei parametri della distribuzione GAUSSIANA incognita a partire da VARIABILI STATISTICHE CAMPIONE (di cui conosciamo e possiamo calcolare tutto). Tali STIMATORI devono produrre STIME: 1) CONSISTENTI : se al tendere all’infinito del numero N degli elementi del campione la STIMA tende al suo valore teorico; 2) NON AFFETTI DA ERRORI SISTEMATICI: se la media della popolazione delle stime coincide con la media della popolazione dalla quale vengono estratti i campioni; 3) EFFICIENTI: se rispetto a tutte le possibili stime del parametro, la popolazione cui appartiene ha varianza minima. m h( x1, x2 ,..., xn ) 2 g ( x1, x2 ,..., xn ) POPOLAZIONI IN GIOCO NEL PROCESSO DI STIMA 1) Esiste il CAMPIONE di MISURE DIRETTE con tutte le sue statistiche 2) Esiste una popolazione incognita da cui il campione è stato estratto e di cui stiamo cercando le stime dei parametri che la definiscono 3) Esiste una popolazione delle medie dei campioni estratti (parametro 1) 4) Esiste una popolazione delle varianze dei campioni estratti (parametro 2) 3) E 4) esistono perché ogni n-pla di estrazioni che costituisce il campione definisce una propria coppia di parametri simili ma non identici. Sono possibili infiniti campioni dai quali è possibile derivare infiniti valori di media e varianza. Si dimostra che le migliori stime di media e varianza secondo i criteri sopra esposti sono: La misura della grandezza si esprimerà come: n m x i 1 n i 2 m m x m n m 2 i 1 i nn 1 Esempi 1° Esempio Si è eseguita una misura di distanza tramite bindella da 20m e si sono effettuate quattro serie di determinazioni. In tabella sono riportate le misure effettuate e gli indici descrittivi che ne conseguono: xi(m) 45.81 45.80 45.84 45.85 vi(mm) -15 -25 +15 +25 n v 0 m 45.82 m i 1 n m 2 m v i 1 i Vi2(mm2) 225 625 225 625 n v i 1 2 i 1700 2 i n (n 1) 141.667 11.9 mm il risultato della misura è quindi: 45.82 m 11.9 mm Esempi 2° Esempio Se la medesima misura viene eseguita con l’uso di un distanziometro ad onde elettromagnetiche e si effettuano nuovamente quattro determinazioni, si avranno i seguenti indici descrittivi: xi(m) 45.823 45.821 45.822 45.821 vi(mm) +1.3 -0.7 +0.3 -0.7 n vi 0.2mm 0 m 45.821 m i 1 n 2 v i 1 Vi2(mm2) 1.69 0.49 0.09 0.49 n v i 1 2 i 2.76 2 i n (n 1) 0.23 0.48 mm Il risultato della misura è quindi: 45821 . m 0.9mm L’intervallo di variabilità in questo secondo caso è molto più ridotto, il della bindella risulta di un ordine superiore a quello del distanziometro. Significato operativo dei parametri DISTRIBUZIONE GAUSSIANA f x 1 2 2 e x m 2 2 2 Significato operativo dei parametri P(m x m ) m f ( x)dx 0.68 m P(m 2 x m 2 ) m 2 f ( x)dx 0.95 m 2 m 3 m 2 m P(m 3 x m 3 ) m 3 f ( x)dx 0.997 m 3 All’intervallo m m è associato il concetto di precisione della misura (68% delle osservazioni). All’intervallo m 2 m è associato il concetto di affidabilità della misura (95% delle osservazioni) All’intervallo m 3 m è associato il concetto di tolleranza della misura (99.7% delle oss.) MISURA INDIRETTA DI UNA GRANDEZZA (Stima della media) Sia y la grandezza determinata in modo indiretto attraverso la misura diretta delle grandezze X1, X2, .., Xk y f ( X 1 , X 2 ,.. X k ) Stima della MEDIA della misura indiretta della grandezza X m f X 1m , X 2 m ,..., X nm Esempio a Si definisca la misura indiretta di a dopo aver misurato in modo diretto b, , . b b bm C b sin sin b m a a am a m m A c B a b sin sin E’ la stima del valore medio della misura indiretta di a MISURA INDIRETTA DI UNA GRANDEZZA Stima della VARIANZA: Legge di propagazione della varianza 2 2 2 f f f n2 12 22 ... X2 X 1 m X 2 m X n m Stima della varianza di una grandezza misurata indirettamente attraverso misure dirette NON CORRELATE fra loro f f f f f ij n2 2 12 22 ... X2 i j X i X j X 1 m X 2 m X n m 2 2 2 Stima della varianza di una grandezza misurata indirettamente attraverso misure dirette CORRELATE fra loro Tornando all’esempio precedente si tratta di calcolare le derivate parziali richieste: a a a ; ; b m m m MISURA INDIRETTA DI UNA GRANDEZZA CON MISURE ESUBERANTI Y Vogliamo determinare le coordinate planimetriche X,Y di un punto P visibile da due punti A e B di coordinate note (problema di intersezione semplice in avanti); la soluzione del problema avviene tramite la misura degli angoli azimutali in A e in B. In questo modo però, qualsiasi errore nella misura dei due angoli azimutali, provocherà un errore nella determinazione delle coordinate del punto P senza alcuna possibilità di accorgersene. P A B O X Se invece si esegue anche la misura del lato AP, avremo la possibilità di individuare eventuali errori nella misure degli angoli In tal caso però andiamo in ridondanza di osservazioni, cioè abbiamo più equazioni di quelle strettamente necessarie a risolvere il problema MISURA INDIRETTA DI UNA GRANDEZZA CON MISURE ESUBERANTI La situazione nella quale ci troviamo è analoga a quella di un sistema (che ipotizziamo lineare) in cui il n° di equazioni > n° incognite a1 X 1 b1 X 2 ... u1 X r L1 a X b X ... u X L 2 1 2 2 2 r 2 .............................. an X 1 bn X 2 ... un X r Ln = Termini noti Xi = incognite n>r Nel sistema tutte le grandezze, dirette e indirette, sono indicate con i rispettivi valori teorici di media (Li). In questo caso (mondo delle idee!!), del tutto teorico, una qualsiasi serie di r equazioni, scelte tra le n disponibili, è in grado di fornire una soluzione che soddisfa anche le restanti n-r equazioni. Nella realtà noi disponiamo solo delle stime delle grandezze misurate direttamente (Li) che partecipano al sistema pertanto le equazioni sono soddisfatte a meno degli scarti. Il sistema diventa allora: a1 X 1 b1 X 2 ... u1 X r L1 v1 a2 X 1 b2 X 2 ... u2 X r L 2 v2 .............................. a X b X ... u X L v n n r n n 1 n 2 La soluzione che andiamo cercando (stima delle grandezze incognite Xi) tra tutte le possibili è quella che minimizza la n quantità MINIMI QUADRATI v 2 min i 1 i e per la quale sia massima la probabilità di estrarre proprio quelle stime dalle rispettive popolazioni possibili. MISURA INDIRETTA DI UNA GRANDEZZA CON MISURE ESUBERANTI Esempio1 : equazione della retta passante per l’origine Esempio 2: equazione retta Esempio 3: LIVELLAZIONE GEOMETRICA MISURE DIRETTE DI DIVERSA PRECISIONE (misura di una grandezza fatta con strumenti di diversa precisione) Y 12 Il concetto di peso di una misura: quanto conta nel processo di stima O1 m 22 X mp i i p i 1 On m n n i 1 n ............... X mO 2 i Media stimata p2 2 0 n p i 1 X Estrarre un individuo (O1) dalla distribuzione che ha varianza 12 equivale ad estrarre p1 individui dalla distribuzione di varianza 02 e farne poi la media. Il peso assume il significato di fattore di omogeneizzazione. Mediante i pesi tutte le distribuzioni vengono riferite alla distribuzione 02 di peso unitario. 02 02 02 02 p1 2 , p 2 2 , p 3 2 ,, p i 2 1 2 3 i pO n2 Y Y i Deviazione standard con 02 p v i 1 i n 1 2 i
Scarica





![I dati e la statistica [d]](http://s2.diazilla.com/store/data/000019594_1-e054456b9f288c40956cf5ac39dc6ad4-260x520.png)